
无人机输电线路巡检照片号牌文字识别方法
2024-09-19 00:00:00李有春汤春俊梁加凯林龙旭徐敏谢敏
无线电工程 2024年6期






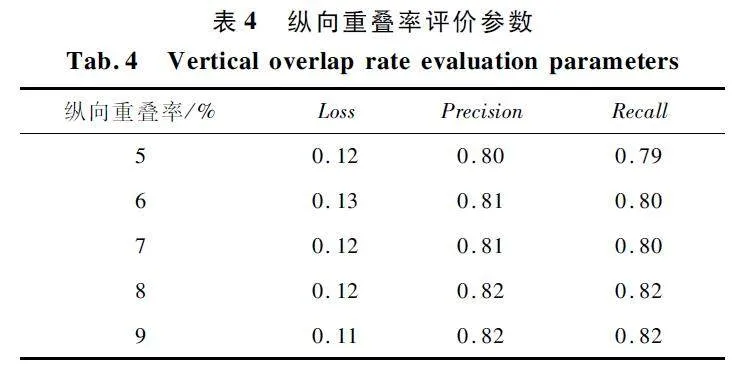

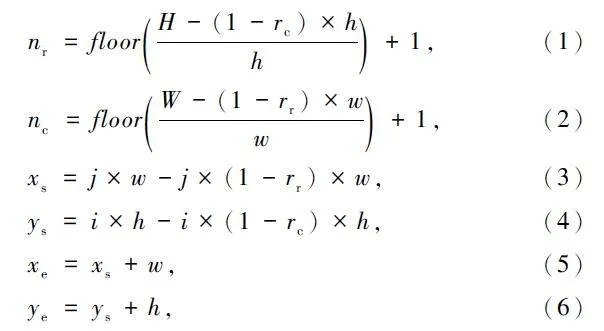



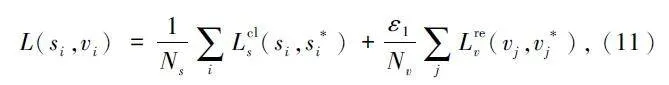


摘 要:针对无人机巡检拍摄的高像素电力杆塔照片中杆塔号牌文字识别成功率低的问题,提出了一种改进连接文本区域网络(Connectionist Text Proposal Network,CTPN) 算法。利用二维重叠滑动切割方法对输入图像进行切割,将主干网络Vgg16 改为MobilenetV2 对切割后图片进行卷积处理,同时在其中加入深度适配网络(Deep Adaptation Network,DAN)的注意力机制得到特征图;将卷积得到的特征图转化成序列输入至双向长短期记忆神经(Bi-directional Long Short-TermMemory,Bi-LSTM) 网络学习序列特征,并通过全连接层得到建议框;加入重映射方法将建议框映射回原图,筛选整合映射到原图的建议框后,得到号牌文本框。将得到的文本框内的图像截取输入到卷积循环神经网络(Convolutional RecurrentNeural Network,CRNN) 进行文字识别。实验结果表明,当切割框为456 pixel×256 pixel、横向重叠率为9% 、纵向重叠率为8% 时,识别精度可以达到87% 。
关键词:深度学习;高像素;场景文字识别;小目标
中图分类号:TP391. 4 文献标志码:A 开放科学(资源服务)标识码(OSID):
文章编号:1003-3106(2024)06-1560-09
0 引言
随着无人机在输电线路运行检修中的普及应用,巡检过程中无人机会拍摄大量照片,再由人工识别出照片中电力杆塔缺陷并明确电力杆塔的位置,到现场对缺陷部分进行检修。无人机巡检照片中杆塔号牌具有电力杆塔的线路名称以及属于该线路第几座塔的文字信息,如果能通过场景文字识别方法对杆塔号牌中的文字进行自动识别获取信息,则可以大幅减轻人工负担。无人机因安全原因无法靠近电力杆塔进行拍摄,因此无人机拍摄的高像素照片中号牌区域只占原图的1% 左右,如何高效地提取电力杆塔照片中号牌的文字信息就成为了亟待解决的问题。
传统的场景文字识别方法可以分为3 种:第一种方法基于纹理对文字进行识别[1-3],将文字当作特殊纹理,利用其纹理特征进行处理,通过对图像中的区域进行穷举以确定纹理特征。基于纹理的文字识别方法存在特征构造方法较简单、检测精度较低、且计算量大的缺点。第二种方法基于成分对文本进行识别。以笔划宽度变换(Stroke Width Transform,SWT)[4]为例,以联通组件为基础进行文字识别,能够更快速地找到文字所在的区域。然而,由于场景中存在图片的仿射变换以及文字断连等因素,使该方法的鲁棒性较低。第三种方法融合了前2 种方法的文字识别方法[5-6],首先通过联通组件找到文字所在区域,再利用纹理方法辅助识别文字,但该方法在复杂背景情况下文字识别成功率仍然较低[7]。
随着深度学习的迅速发展,场景文字识别模型将识别文字的过程分为2 步:第一步文本检测;第二步文本识别。目标检测方法是文本检测参考的方向之一,例如,基于Faster R-CNN[8]模型的连接文本区域网络(Connectionist Text Proposal Network,CTPN)[9]模型。CTPN 模型通过卷积神经网络(ConvolutionalNeural Network,CNN)与循环神经网络(RecurrentNeural Network,RNN)的结合对图像特征进行提取,其中CNN 模型选用Vgg16 作为图像空间特征的提取的网络,RNN 则使用双向长短期记忆(Bi-directional Long Short-Term Memory,Bi-LSTM)[10]对图像序列特征进行提取,将提取的图像特征输入至CTC[11]计算出预测序列与目标序列之间的条件概率。Deeptext[12]、R2CNN[13]等模型都是基于FasterR-CNN 的场景文字识别。在该方法的启发下选用CTPN 的架构对号牌文字进行识别,能够将文本识别和文本检测分成2 步,完成对号牌文字的识别。
在复杂图像背景中检测小目标是图像分析处理领域的一个重要研究方向,小目标广泛存在于远距离拍摄的航空航天影像或视频监控中,利用计算机对捕获的高质量图像数据进行有效分析和处理,识别出不同类别的目标并标注其所在的位置。目前专门针对小目标检测的算法研究较少,现有的小目标检测算法一般是在通用目标检测方法的基础之上通过加深网络的层数,设计能够提取到更丰富特征的主干网络[14-15]、复杂化特征融合过程[16-17]来增强模型对多尺度目标的鲁棒性。电力杆塔照片中号牌文字同样属于小目标,识别方法可参考现有的小目标检测方法。
高像素图片若不经过尺寸调整将原图输入至网络会导致模型运行速度过慢,因而现有的深度学习模型先将输入图片尺寸调整到一定尺寸,例如224 pixel×224 pixel。调整后的图片像素丢失过多,会导致小目标特征不明显,从而使网络无法识别高像素图片中的小目标。针对这一问题,提出了一种二维重叠的滑动切割方法并改进CTPN,用于对高像素图片中小目标号牌文字识别,二维重叠的滑动切割方法能够提高找到号牌图像中小目标文字的成功率;针对切割后图片存在特征不明显的情况则通过多尺度特征融合,增加号牌特征深度,提高模型对号牌文本检测精度;对应切割方法提出建议框的重映射方法用于文本框生成。
1 基于CTPN 的电力杆塔号牌文字识别方法
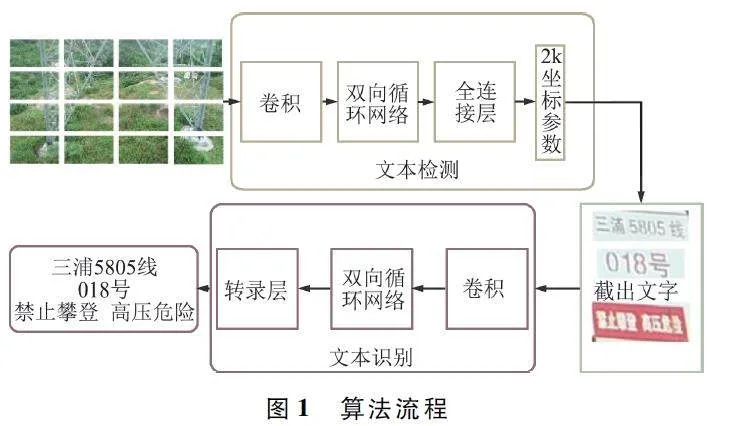
图1 为电力杆塔号牌文字识别方法的流程,其中主要包括三部分:图像切割、改进CTPN、CRNN 网络。首先,将输入图像进行二维重叠切割;其次,将切割后的图像依次输入至改进CTPN 网络得到文本框;最后,截取文本框中的图像,并将该图像输入至CRNN 网络对其文字内容进行识别。
1. 1 二维重叠的滑动切割模块
图片调整示例如图2 所示,将无人机拍摄图片调整至544 pixel×544 pixel 大小后截取号牌得到的结果,大图为原图样例,小图为对应的大图中截取出的号牌图片。
为了解决上述问题,提出二维重叠的滑动切割方法。原始图像的分辨率为5 472 pixel×3 078 pixel,遵循一定命名规范将一张图片裁成一组图片用以输入至特征提取网络。截取出来的每张图片的命名规范为Image[height width row column],表示记录下切割窗口左上角点的横纵坐标。其中,height、width 表示纵坐标,row、column 表示横坐标。在图像切割过程中需要保证文字的完整性,因此切割过程中加入横向重叠率和纵向重叠率参数,以解决文字被截断的问题。在同一行的图像切割过程中,下一个窗口的切割范围与上一个窗口存在横向重叠。在新的一行切割过程中,该行的切割窗口与上一行的切割窗口有纵向重叠。
将图片输入后,程序自动读取图像的总高度为H,总宽度为W。对图像进行切割时,每行的切割高度为h,每列的切割宽度为w。每一行的切割数量为nr,每列的切割数量为nc。横向重叠率为rr,纵向重叠率为rc,floor()为向下取整。
式中:xs、ys 为左上角的横纵坐标,i、j 为第i 行和第j列的切割区域,xe、ye 为右下角的横纵坐标。
最终切割得到区域坐标可表示为:
(xs ,ys ,xe ,ye )。(7)
切割示例如图4 所示,展示了切割过程中小图与大图的对应关系。
1. 2 多尺度特征融合模块
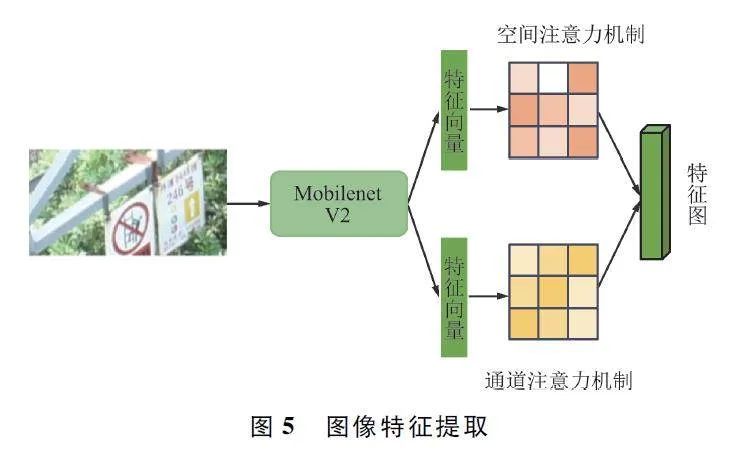
原始的CTPN 以Vgg16 为主干网络对输入图像进行特征提取,该网络对图像特征的利用率不高,并且号牌文字特征信息较少,导致特征随卷积加深逐渐稀疏。改进CTPN 将主干网络换为MobilenetV2,该网络使用倒残差结构加强了网络各层之间的联系,且此网络是轻量级网络,能够有效减少运行时间。
针对号牌图像不清晰的图片识别成功率不高,但号牌图片前景与背景区别大,在改进的CTPN 的卷积层加入深度适配网络(Deep AdaptationNetwork,DAN)中的结构,用以聚焦关键区域。DAN中引入了2 个注意力机制:一个是空间注意力机制,用于选择图像中的关键区域;另一个是通道注意力机制,用于选择关键通道。图5 展示了图像特征提取流程[18]。
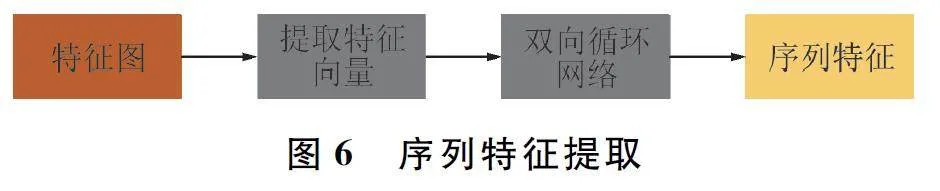
由于文字的连续性,既需要学习图像的空间特征,也需要学习序列特征,因此在通过卷积得到特征图后引入Bi-LSTM 神经网络。CNN 用于学习感受野内的空间信息,Bi-LSTM 则用于学习序列特征。通过卷积获得一个N×C×H×W 的特征图,对该特征图通过3 ×3 滑动窗口提取特征向量,得到一个N×9C×H×W 的特征向量。将特征向量输入到Bi-LSTM得到N ×512 ×H ×W 的序列。序列特征提取如图6所示。
融合了“空间+序列”特征后,将特征输入到全连接层,并将输出接入类似区域建议网络的网络结构。由于在最后会输出文本框,因此需要生成建议框对文字的位置进行预测。与二阶段目标检测类似,改进CTPN 通过欧几里得回归检测推荐框(anchor),以得到文字的边界框。网络在获取了anchor的基础上,使用激活函数(softmax)来判断anchor 中是否包含文本。另一个分支则通过边界框回归修正包含文本的anchor 的中心y 坐标和高度。
式中:cay、ha 分别为anchor 的y 坐标中心和高度,cy和h 分别为预测出的y 坐标中心和高度。k 个边框调整参数,用来精修文本行的2 个端点,表示每个建议框的水平平移量。
o = xside - cax/wa , (9)
式中:xside 为预测出的距离anchor 水平坐标最近的坐标,cax为anchor 的x 坐标中心,wa 为anchor 的宽度。
1. 3 二维重叠切割重映射模块
通过特征提取和anchor 边界框的预测,网络可以得到若干个预测框,拼接预测框能够得到完整的文本预测框。由于最初图片经二维重叠的滑动切割后输入网络,因此需要对得到的预测框做重映射,将预测框映射回到原图的位置。预测框坐标加上图片输入时保存的左上角横纵坐标即为映射至原图的方法,其计算如下:
[cox,coy] = [cax,cay]+ [rcx,hcy], (10)
式中:cox表示anchor 在原图的y 坐标,coy表示anchor在原图的x 坐标,cay表示原图切片后anchor 的y 坐标,cax表示原图切片后anchor 的x 坐标,rcx表示原图切片后图片左上角y 坐标,hcy表示原图切片后左上角x 坐标。
由于图片切割时为有重叠的切割,且原图中存在一定预测框重叠,因此可通过非极大抑制(NonMaximum Suppression,NMS)方法对预测框通过激活函数得到的数值进行筛选。选取第一个框为候选框,沿正方向寻找候选框与剩余推荐框之间水平距离小于50 的推荐框并保留与候选框横向重叠率大于0. 5 的推荐框,同时选取水平距离小于50 的推荐框中最右边的推荐框作为候选框,相同的方法沿反方向再进行一次查找,将结果拼接得到连续文本的完整文本框作为最后结果输出。重映射示例如图7所示。
训练时需要通过损失函数对训练的结果进行评估,该损失函数由两部分组成,2 个分支对应两部分的损失函数。
第一部分是逻辑回归损失用于监督学习推荐框中是否包含文本,此处使用交叉熵函数;第二部分是边界框的回归,此处使用平滑的平均绝对值误差函数(smooth L1)。
1. 4 基于CRNN 的文本识别模块
早期的深度学习光学字符识别(OpticalCharacter Recognition,OCR)通过单独切割字母并进行多类标的分类任务以识别文本,而CRNN 则使用端到端深度学习进行文本识别,将文本转化为序列并输入到深度学习网络中,通过CNN 和RNN 对输入图像进行特征学习,解决了不同图像尺度和文本长度出现的识别问题[19]。
改进CTPN 可以得到图像中的文本框,再提取出该位置中的文本图像输入到CRNN。CRNN 的第一层是CNN,用卷积网络从图像中提取图像特征。该卷积层共有4 个最大池化层,最后2 个池化层的窗口尺寸由2×2 改为1×2,以适应文本图像大多为宽度较长的矩形的长度。通过卷积网络得出的图像特征序列不能直接输入至RNN 中,需要对图像特征序列进行提取出单列的向量,每个特征向量在特征图上按列从左到右生成。CRNN 中的RNN 同样使用Bi-LSTM,将提取出来的特征向量输入至RNN中。RNN 最后输出每个字符的softmax 概率分布。然后将该向量输入至转录层连接主义时间分类(Connectional Temporal Classification,CTC ),使用CTC 解码以归纳字符的连接特性,解码则是基于最大似然的损失函数。
2 实验
2. 1 数据集
训练文本检测部分的数据集已具备多条线路的电力杆塔号牌的图片,由于该数据集为自行通过无人机拍摄的数据集,因此训练网络前需要对图片中线路名称、塔号和警示语的中文进行标注。
数据集标注采用ICDAR2017 的标注方式,存储至txt 文件中,每行向量化文本表示图片中文字的标注框4 个点的坐标,左上角为原点记录横纵坐标并以顺时针将各个点排列记录,同时包含图片的文字内容和其所用的语言,其结构如图8 所示,为多座塔的号牌信息标注。
由于电力杆塔巡检环境恶劣,且存在人员操作不规范等原因会对图像的文字识别产生影响,例如图片过曝、号牌掉落和文字不清楚等情况,因此需要对图像进行图像增强工作。同时对本身没有拍摄到号牌的图片进行剔除,经过剔除后对图像进行图像增强工作,能够一定程度丰富数据集。
数据增强示例如图9 可示,颜色扰动方法如图9(a)所示,即对图片的亮度、对比度、饱和度调整扩增数据,这一方法是模拟环境光线变化对号牌识别产生的影响。翻转方法如图9(b)所示,即对已有图片水平翻转和垂直翻转,由于号牌摆挂方式不是固定不变的,因此加入翻转方法。添加噪声如图9(c)所示,其中添加噪声会选择添加黑色噪点或者白色噪点。
数据集中共有1 388 张图片,其大小均为5 472 pixel×3 078 pixel,按如下划分:训练集1 110 张,测试集139 张,验证集139 张,对训练集以及测试集进行数据增强之后的数据集总数可以达到3 886 张。
训练文本识别部分时则在使用号牌文字的标注信息的同时加入公开数据集ICDAR2017,共12 263 张图像,其中8 034 张作为训练集,4 229 张作为测试集。使用四边形框标注文本行,ICDAR2017 数据集绝大多数是相机拍的自然场景,一些是屏幕截图,包含了大多数场景,如室外街道、室内场景和手机截图等。
2. 2 评价指标
改进CTPN 中计算损失的方法为:
第一部分使用交叉熵损失函数用以判断anchor 中是否含有文本,第二部分为smooth L1 函数用以判断边界框的回归。在判断精度时可以借鉴目标检测中的查准率/ 精度(Precision)计算方法,Precision =TP / (TP+FP),其中TP 表示判断为正的样本数量,FP 表示为负样本误判为正样本的数量。同时目标检测中还有查全率(Recall)作为评价指标,Recall =TP / (TP+FN),其中FN 表示正样本误判成负样本的数量。
2. 3 实验设置
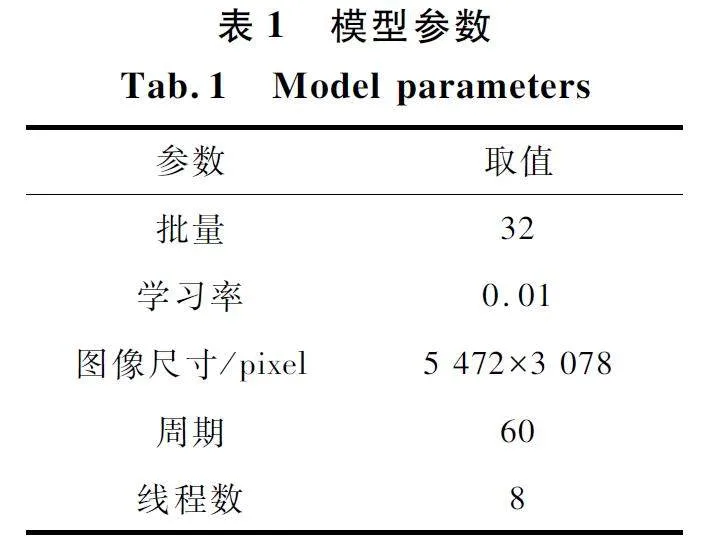
实验环境配置如下:Intel (R) Core (TM) i711800H 处理器,16 GB 内存,nVIDIA3060 显卡,操作系统为Windows 10,开发语言为Python3. 8. 8,开发工具PyCharm,网络的初始参数采用随机初始化,表1 为训练时超参数的选择。
2. 4 二维重叠切割参数实验
图像切割方法中窗口大小作为重要参数,对图像的文本检测会产生影响,切割窗口过大会在输入网络后导致像素丢失过多,特征不明显,切割窗口过小会导致特征被切割造成学习特征错误,故需通过实验确定切割窗口大小。最终经过实验得到窗口大小为456 pixel×256 pixel,横向重叠率为9% ,纵向重叠率为8% 时能够达到所需效果。
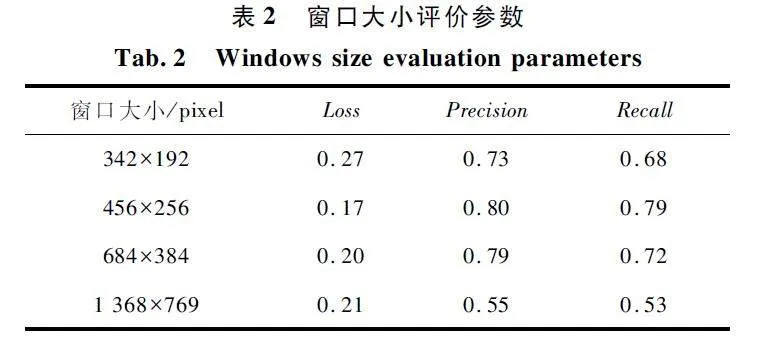
在设定窗口大小的实验中,每组的横向重叠率以及纵向重叠率都为0% ,并且主干网络选用Vgg16。在使用杆塔号牌数据集时,窗口大小的参数选定为原图的长宽为基础按比例选择。分析精度折线如图10 所示,具有预训练参数的条件下,不同窗口大小的切割图片在训练过程中精度总体呈上升趋势,图中窗口大小1 368 pixel×769 pixel 为精度最低的折线,窗口大小456 pixel×256 pixel 为精度最高的折线。
窗口大小评价参数如表2 所示。可以看出,窗口大小456 pixel×256 pixel 时识别精度最高,并且精度接近正常图片输入时CTPN 所达到的精度。
图像切割过程中,在窗口大小固定为456 pixel×256 pixel 的情况下为确保特征的完整性,用二维重叠的滑动切割方法可以保证切割后文字特征完整性,有利于后续特征提取。实验中,窗口大小宽度为上一个实验结果的456 pixel,横向重叠率为号牌中文字宽度与窗口大小宽度的比例,则最小比例为6% ,后续以1% 为步长做实验。
横向重叠率实验如图11 所示。在具有预训练参数,固定窗口大小为456 pixel×256 pixel,且纵向重叠率为0% 的条件下,横向重叠率参数改变,精度伴随训练轮数的增加平稳上升,横向重叠率越高精度越高,但其精度较窗口大小对精度的影响较小。
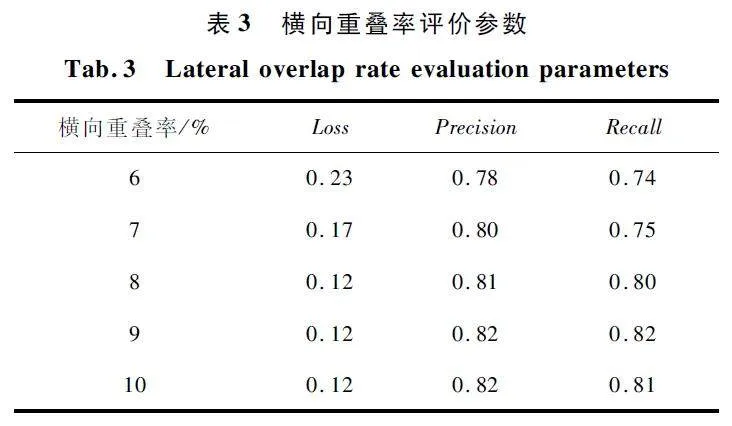
横向重叠率评价参数如表3 所示。当横向重叠率为9% 时可以得到最佳精度及召回率,横向重叠率高能提高识别的精度,但横向重叠率小可以提高训练速度。
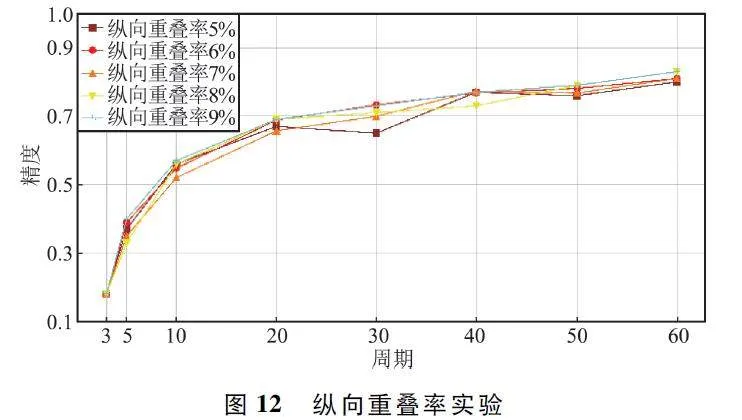
纵向重叠率最小为号牌中文字的高度与窗口大小的高度的比例,实验中,窗口的高为256 pixel,纵向重叠率最小取5% ,后续以1% 为步长做实验。纵向重叠率实验如图12 所示,在具有预训练参数,固定窗口大小为456 pixel×256 pixel 且横向重叠率为9% 的条件下,纵向重叠率参数变化,精度伴随训练轮数的增加平稳上升。纵向重叠率越高精度越高,但其精度较窗口大小对精度的影响同样较小。
纵向重叠率评价参数如表4 所示,当纵向重叠率为8% 时,识别精度以及召回率效果最佳,纵向重叠率高同样能提高识别的精度。
2. 5 对比实验
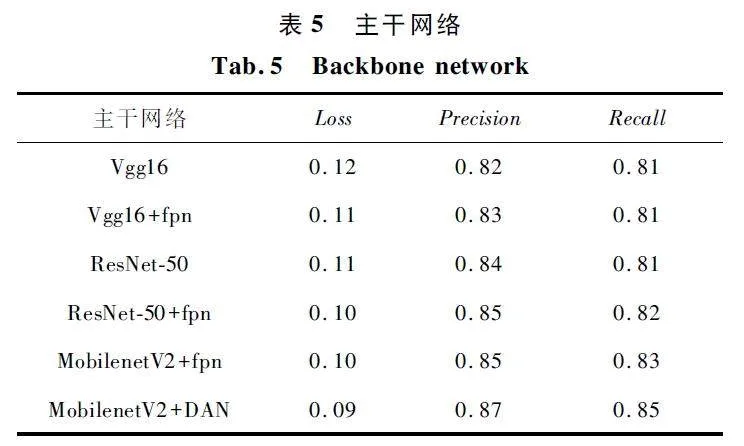
主干网络实验如图13 所示,使用不同的主干网络训练过程中,随着训练轮数的增加,精度基本呈稳步上升的趋势,主干网络选用MobilenetV2+DAN 可以达到最佳的效果,同时该网络具有轻量化的特点。
主干网络如表5 所示,在添加切割窗口的情况下,分别调用不同的主干网络搭配。经实验发现,加入多尺度融合的网络可以提高识别精度。
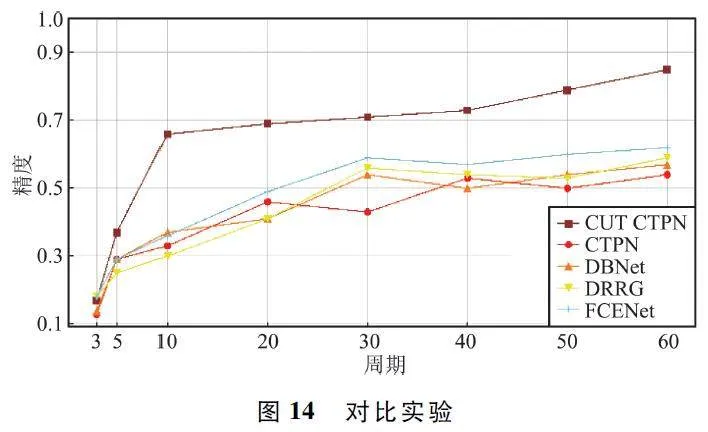
将不同场景文本识别模型不加切割方法进行训练,与切割加改进CTPN 模型进行对比。切割参数为上述实验的结果,窗口大小456 pixel×256 pixel,横向重叠率为9% ,纵向重叠率为8% 。实验时输入图像大小皆为5 472 pixel×3 078 pixel,对比实验如图14 所示。训练过程中精度基本呈稳步上升趋势,但从精度折线图上能够明显看出,在加入二维重叠的滑动切割方法后精度显著提高。同时对比其他现有深度学习场景文字识别模型,二维重叠的滑动切割方法能够提高小目标文本检测精度。
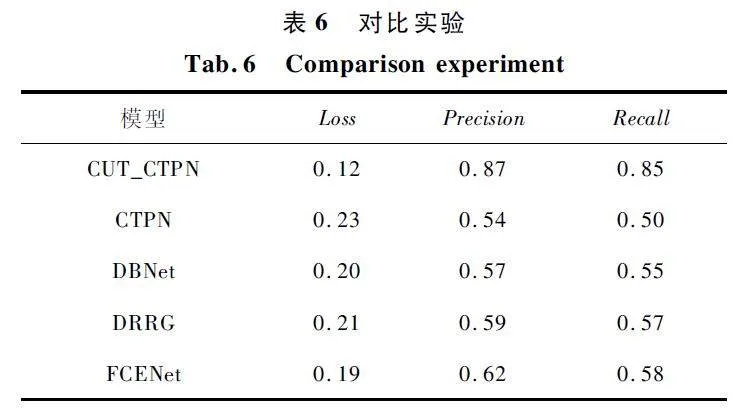
对比实验如表6 所示,可以看出加入二维重叠的滑动切割方法后,损失、精度以及召回率有效提高。
聚焦效果如图15 所示,通过二维重叠的滑动切割方法同时改进CTPN 主干网络,加上二维重叠的重映射方法,能够对号牌文字进行有效识别。
3 结束语
传统的场景文字识别方法和基于深度学习的场景文字识别方法都难以识别无人机巡检拍摄的电力杆塔照片中高像素、小目标号牌文字。为解决此问题,提出二维重叠滑动切割的改进CTPN 算法。通过实验确定切割的窗口大小以及切割时的横向以及纵向重叠率,确保切割时较大保留文字的完整性同时提高文本检的精度。加入建议框的重映射方法,以达到在原图上完整框出文本框的目的。将主干网络改为MobilenetV2+DAN 的多尺度融合结构,最终能够达到87% 的精度。虽然在文本检测方面取得了一定成果,但在文本识别方面还有提升空间,下一个阶段将着重研究优化CRNN,提高文本识别精度。
参考文献
[1] ZHONG Y,KARU K,JAIN A K. Locating Text inComplex Color Images [J]. Pattern Recognition,1995,28(10):1523-1535.
[2] KIM K I,JUNG K,KIM J H. Texturebased Approach forText Detection in Images Using Support Vector Machinesand Continuously Adaptive Mean Shift Algorithm [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2003,25(12):1631-1639.
[3] LYU M R,SONG J Q,CAI M. A Comprehensive Methodfor Multilingual Video Text Detection,Localization,andExtraction [J ]. IEEE Transactions on Circuits andSystems for Video Technology,2005,15(2):243-255.
[4] EPSHTEIN B,OFEK E,WEXLER Y. Detecting Text inNatural Scenes with Stroke Width Transform[C]∥2010IEEE Computer Society Conference on Computer Visionand Pattern Recognition. San Francisco:IEEE,2010:2963-2970.
[5] LIU Y,GOTO S,IKENAGA T I,et al. A ContourbasedRobust Algorithm for Text Detection in Color Images [J].IEICE Transactions on Information and Systems,2006,89(3):1221-1230.
[6] PAN Y F,HOU X,LIU C L. A Hybrid Approach to Detectand Localize Texts in Natural Scene Images [J]. IEEETransactions on Image Processing,2010,20(3):800-13.
[7] 于君娜,单子力,李方方,等. 多源图像融合技术在无人机中的应用[J]. 无线电工程,2019,49(7):581-586.
[8] GIRSHICK R G. Fast RCNN [C]∥2015 IEEE International Conference on Computer Vision. Santiago:IEEE,2015:1440-1448.
[9] TIAN Z,HUANG W L,HE T,et al. Detecting Text in NaturalImage with Connectionist Text Proposal Network [C]∥14th European Conference. Amsterdam:ACM,2016:56-72.
[10] OLAH C. Understanding LSTM Networks [EB / OL ].[2023 - 07 - 05]. http:∥ colah. github. io / posts / 2015 -08-UnderstandingLSTMs / .
[11] PATERLINIBRECHOT P,BENALI N L. CirculatingTumor Cells (CTC)Detection:Clinical Impact and FutureDirections[J]. Cancer Letters,2007,253(2):180-204.
[12] BUTA M,NEUMANN L,MATAS J. Deep Textspotter:An EndtoEnd Trainable Scene Text Localization andRecognition Framework [C]∥ 2017 IEEE InternationalConference on Computer Vision. Venice:IEEE,2017:2223-2231.
[13] JIANG Y Y,ZHU X Y,WANG X B,et al. R2CNN:Rotational Region CNN for Orientation Robust Scene Text Detection[EB/ OL]. (2017-06-29)[2023-07-01]. https:∥arxiv. org / abs / 1706. 09579.
[14] HE K M,ZHANG X Y,REN S Q,et al. Deep ResidualLearning for Image Recognition [C]∥2016 IEEE Conference on Computer Vision and Pattern Recognition. LasVegas:IEEE,2016:770-778.
[15] HUANG G,LIU Z,VAN DER MAATEN L,et al. DenselyConnected Convolutional Networks[C]∥2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu:IEEE,2017:2261-2269.
[16] LIN T Y,DOLLR P,GIRSHICK R,et al. FeaturePyramid Networks for Object Detection [C]∥2017 IEEEConference on Computer Vision and Pattern Recognition.Honolulu:IEEE,2017:936-944.
[17] FU C Y,LIU W,RANGA A,et al. DSSD:DeconvolutionalSingle Shot Detector [EB / OL]. (2017-01-13)[2023 -07-02]. https:∥arxiv. org / abs / 1701. 06659.
[18] FU J,LIU J,TIAN H J,et al. Dual Attention Network forScene Segmentation [C]∥2019 IEEE / CVF Conferenceon Computer Vision and Pattern Recognition. LongBeach:IEEE,2019:3141-3149.
[19] 韦泰丞,谭颖韬. 基于视觉语义关联的卷烟零售终端文字识别[J]. 无线电工程,2022,52(10):1848-1856.
作者简介
李有春 男,(1968—),硕士,高级工程师。主要研究方向:电力调度、电网运行检修、现场安全管控等。
汤春俊 男,(1979—),硕士,高级工程师。主要研究方向:输电线路建设、施工、运行、带电检修、精益化运检管理等。
梁加凯 男,(1983—),高级工程师。主要研究方向:带电作业、安全防护、线路检修精益化管理等。
林龙旭 男,(1998—),硕士研究生。主要研究方向:图像处理和文字识别。
徐 敏 女,(1983—),硕士,高级工程师。主要研究方向:电力系统信息化。
(*通信作者)谢 敏 女,(1975—),硕士,讲师。主要研究方向:温度计量、无人机控制与应用。
基金项目:金华八达集团有限公司科技项目(BD2022JH-KXXM007)
猜你喜欢
课外语文·中(2022年3期)2022-04-21 23:03:14
作文通讯·高中版(2022年3期)2022-04-08 01:05:14
光学仪器(2016年5期)2017-01-12 18:21:37
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
科学之友(2016年10期)2016-10-21 23:57:13
瞭望东方周刊(2016年35期)2016-10-17 18:22:22
IT经理世界(2016年19期)2016-10-12 12:12:37
