
基于威焱831平台的H.264视频解码优化
2024-09-16 00:00:00王聪张昊刘世巍黄朴
现代电子技术 2024年10期



摘" 要: 为提高威焱831平台的多媒体处理能力,解决H.264解码器解码效率低的问题,在提出SIMD指令级优化方法的同时,提出一种面向帧拷贝的优化方法。通过分析开源软件FFmpeg中H.264解码器的并行化特性,使用威焱平台性能分析工具解析影响视频解码性能的热点函数。采用手工嵌入SIMD汇编指令的方式对关键模块热点函数进行优化,通过FFmpeg源码编译过程链接汇编实现的内存操作函数memcpy提升内存拷贝速度。实验结果表明,威焱831平台视频解码的平均性能提高26%,推动了威焱831处理器在多媒体应用领域的发展。
关键词: 威焱831平台; SIMD; H.264解码器; FFmpeg; 热点函数; 解码效率
中图分类号: TN919.81⁃34" " " " " " " " " " " " " 文献标识码: A" " " " " " " " " " "文章编号: 1004⁃373X(2024)10⁃0086⁃05
H.264 video decoder optimization based on Weiyan 831 platform
Abstract: In order to improve the capability of multimedia processing and the decoding efficiency of H.264 decoder on Weiyan 831, an optimization method for frame copy is proposed while the SIMD instruction level optimization method is proposed. By analyzing the parallel characters of the H.264 decoder in the open source Ffmpeg, the performance analysis tool on Weiyan platform is used to analyze the hot functions that influence the video decoding. The key module hotspot functions are optimized by manually embedding SIMD assembly instructions, and the memory operation function memcpy is implemented by means of FFmpeg source code compilation linked to assembly, so as to improve memory copying speed. The experimental results show that the average video decoding performance on Weiyan 831 platform is improved by up 26%, which can effectively promote the development of Weiyan 831 processors in multimedia applications.
Keywords: Weiyan 831 platform; SIMD; H. 264 decoder; FFmpeg; hotspot function; decoding efficiency
0" 引" 言
随着科技的发展和社会的进步,人们对高质量视频的需求不断增加,传统的编解码模式已难以保证高质量视频的流畅播放[1]。
SIMD(Single Instruction Multiple Data)可以高效地对多媒体数据进行处理,通过一条SIMD指令实现对向量寄存器中所有数据的并行处理[2]。为增强计算机多媒体处理能力,SIMD技术被广泛应用于各种类型的处理器。
Intel公司率先在Pentium处理器中应用了支持MMX[3]的SIMD技术,通过不断改进SIMD扩展部件,发展到现在的AVX2技术。威焱831处理器是我国自主设计、具有完全自主知识产权的通用处理器[4],该处理器支持的SIMD数据处理长度为256位。
H.264编解码器不管是在视频编码的压缩效率上,还是在网络适应性上,表现都比较优秀[5]。针对H.264解码器的优化研究,主要集中在X86和ARM平台[6],而在国产化CPU平台上相关研究并不多见[7]。文献[8]设计了一种在X86平台使用SIMD技术对视频处理子系统进行优化的方法,缩短了视频流处理过程中图像缩放的处理时间;文献[9]设计了一种基于FPGA的视频处理系统,充分利用ARM平台SIMD技术对Sobel算法进行优化加速。
针对上述问题,本文基于SIMD技术,开展了H.264解码器的优化设计,进而提升威焱831平台的多媒体处理能力。实验结果表明威焱831平台视频解码的平均性能提高了26%。CPU开销中环路滤波模块占比的降低,验证了SIMD优化方法的可行性;帧拷贝优化方法的提出,使得解码器各个阶段都可以获益。
1" 基于FFmpeg的H.264解码器
1.1" H.264标准
H.264是由ISO图像专家组和ITU视频编码专家组共同提出的数字视频编解码器标准。H.264最大的优势是在高压缩比方面,在相同条件下,采用H.264技术压缩后的数据量比MPEG⁃2、MPEG⁃4、H.263的数据量小得多。
视频解码可分为软件解码和硬件解码。硬件解码依靠专门的解码芯片,解码效率高;软件解码则可以支持不同的视频编解码标准,系统兼容性好。当然软件解码对CPU的性能要求较高。
1.2" FFmpeg解码
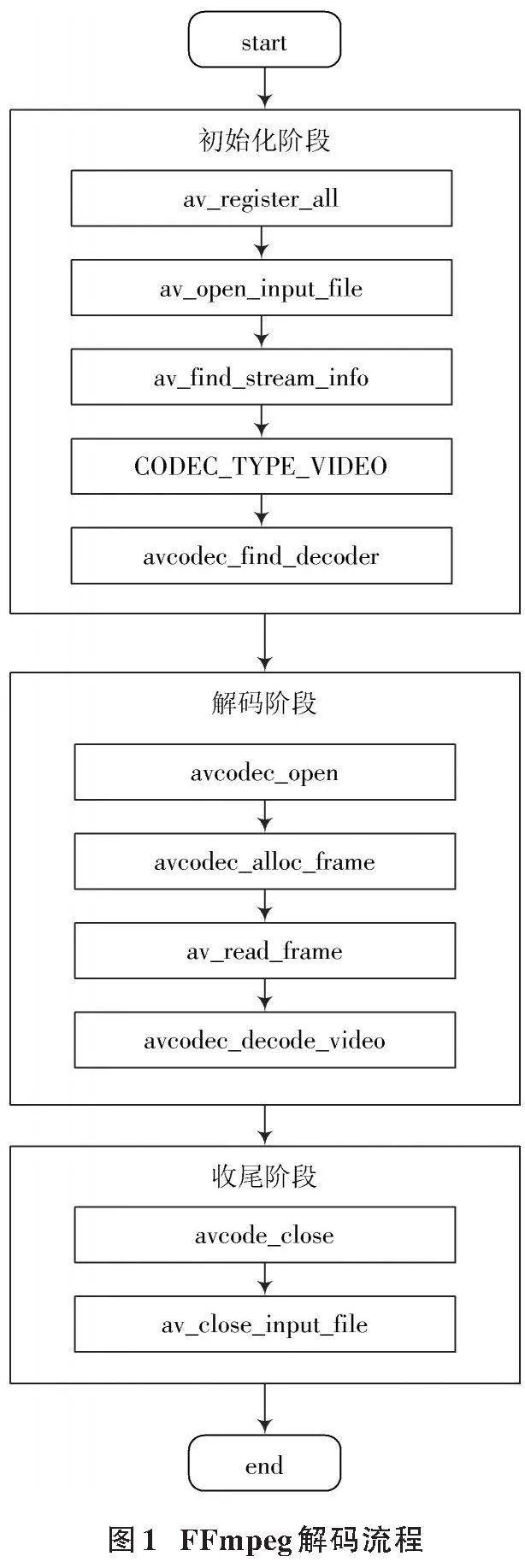
FFmpeg作为一款主流的音视频编解码基础软件,开发者能够很容易使用其提供的音视频处理方案[10⁃11]。目前,多媒体软件FFmpeg中的AVCodec模块除了支持H.264解码器,还支持H.265[12]、MPEG⁃4[13]、VP9[14]等编解码标准。FFmpeg调用H.264的解码流程如图1所示。
FFmepg调用H.264的解码流程可以分为3个阶段:
1) 初始化阶段,由av_register_all函数来注册解码器,通过av_open_input_file函数打开视频序列文件,av_find_stream_info函数用来提取视频文件的信息,调用avcodec_find_decoder函数来查找CODEC_TYPE_VIDEO类型的解码器;
2) 解码阶段,通过avcode_open函数打开解码器,通过avcodec_alloc_frame函数来分配内存空间,通过av_read_frame函数读取视频码流中的帧数据,然后调用avcodec_decode_video函数进行解码;
3) 收尾阶段,调用avcodec_close函数关闭解码器,调用av_close_input_file函数关闭输入视频文件。
2" H.264解码器优化
2.1" 性能瓶颈分析
perf是官方的Linux性能分析工具,能够辅助用户快速定位和处理软件性能问题[15]。在程序运行过程中,被多次调用且长时间执行的一系列函数,通常被称为热点函数。H.264解码运算的CPU消耗主要集中在avcodec_decode_video函数,该函数包含熵解码[16]、反变换与反量化、帧间和帧内预测[17]、环路滤波[18]四个模块。
1) 熵解码
熵解码模块的功能在于解析码流。熵解码作为解码过程的第一步,利用熵编码的反向操作,将编码端写入输出码流的语法元素解析出来,并按照H.264的语法和语义规则将其分配到解码器相应的变量中。其中熵解码方面的函数有ff_h264_decode_mb_cabac和ff_h264_decode_mb_cavlc,分别用于解码CABAC编码方式和CAVLC编码方式的H.264数据。
2) 反变换与反量化
在变换方面,H.264采用了整数IDCT变换,只使用整数和定点数运算,从而消除了浮点数IDCT变换造成的误差累计。在量化方面,H.264将放大系数移到量化阶段进行,根据图像的动态范围大小确定量化参数。
3) 帧间和帧内预测
帧间预测和帧内预测的目的都是为了尽可能去除时间和空间上的冗余信息,以减小视频数据的大小。
4) 环路滤波
环路滤波函数loop_filter的功能是对解码后的数据进行滤波操作,去除图像变换后可能存在的块状视觉效应。调用filter_mb_edgev和filter_mb_edgecv函数,分别对亮度和色度的垂直边界进行滤波,调用filter_mb_edgeh和filter_mb_edgech函数,分别对亮度和色度的水平边界进行滤波。
2.2" 优化实现
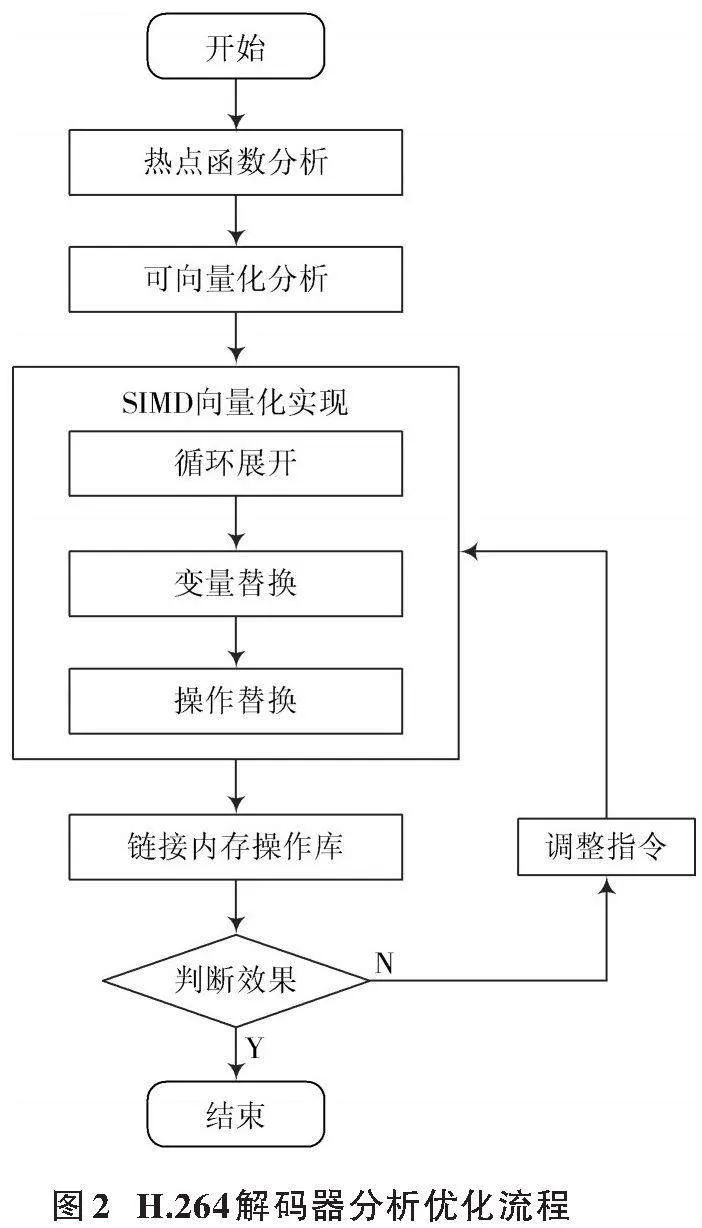
H.264解码器在威焱831平台进行优化的流程如图2所示。
首先,在威焱831平台使用性能分析工具对H.264解码器进行性能瓶颈分析;根据数据相关性、内存对界要求等向量化条件,筛选可以进行向量化的热点函数;FFmpeg源码编译过程链接汇编实现的内存操作函数memcpy来提升内存拷贝速度;结合威焱831平台指令流水线特点,以更高效的指令进行替换。重复上述步骤对程序进行不断改进,达到最佳优化效果。
2.2.1" 向量化条件
理论上来说,对于完全SIMD向量化的程序,32×8的向量运算性能可以达到标量的8倍,64×4 的向量运算性能可以达到标量的4倍。但是,程序向量化通常存在一定限制,很难做到完全向量化。对热点函数进行向量化改写,受限于以下条件。
1) 硬件限制。访存操作的内存地址在进行向量化操作时必须是连续的,并且要满足32 B(单精度浮点向量为16 B)的内存对界要求。
2) 数据相关性限制。向量化必须要求数据在迭代过程中可以满足并行执行条件,并且不能改变原始循环的语义。
3) 循环结构的限制。向量化要求循环体只能有一个入口和一个出口,并且循环的迭代次数是有限的。
2.2.2" 优化过程
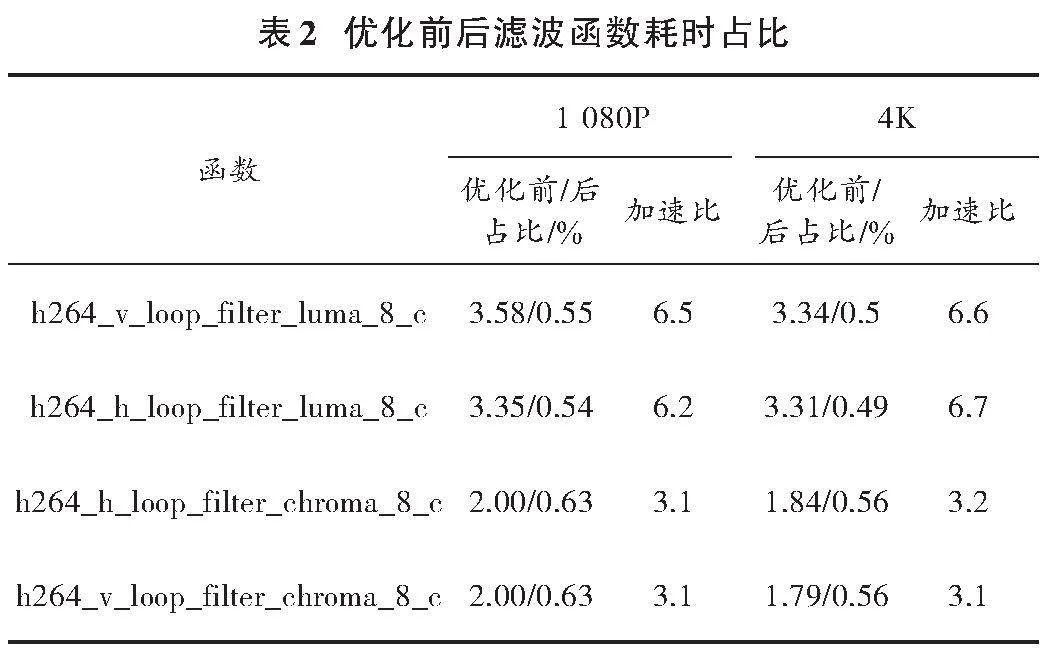
本研究针对环路滤波函数和内存操作函数进行优化,使用perf工具,采用cpu⁃clock事件对1 080P视频序列进行解码采样,列出环路滤波函数和内存操作函数热点占比,如表1所示。
1) SIMD优化
申威SIMD扩展指令集提供VLDD、VSTD对齐装入、存储指令。使用VLDD指令可以从对界内存中读取32个8 bit或8个32 bit元素到256位向量寄存器中,同时支持不同长度的移位、加减等运算。以函数h264_v_loop_filter_chroma_8_c为例,程序1显示了函数原型的部分代码。
使用访存装入指令VLDD,从原像素点src_p0、src_q0起始地址读取8个32位整数像素点到向量寄存器中,使用VSUBW指令进行src_p0-src_q0、src_q0-src_p0减法操作,VSELLTW是字整数向量小于零选择指令,用于实现FFABS(src_p0-src_q0)求绝对值的功能。VCMPLTW是字整数向量小于比较指令,用于实现条件判断功能。最后使用VSTD指令,将比较结果存储到result目的内存地址中。使用SIMD方式完成一组数据计算,相当于标量多次循环完成的计算。对环路滤波模块采用手工嵌入SIMD汇编指令的方式,减少了目标代码的循环次数,提高了解码器的解码性能。
2) 帧拷贝优化
视频输出部分,大量的帧拷贝操作同样占据了较多的CPU开销。帧拷贝过程大量使用memcpy函数,系统库中memcpy函数接口为标量实现。在威焱831平台使用SIMD实现的memcpy接口可以提高帧拷贝的速度。
对FFmpeg源码进行适配,在源代码的configure配置文件中添加与申威体系结构相关的选项,并使用⁃⁃extra⁃ldflags编译选项链接SIMD汇编实现的内存操作函数memcpy。帧拷贝优化属于通用优化方法,各个阶段都可以获益,尤其是在解码后的视频输出阶段。
3" 实验与分析
3.1" 软硬件环境
实验硬件环境为国产威焱831平台,搭配国产uos20操作系统。威焱831为64位字长的国产高性能八核通用处理器,该处理器集成了8个64位RISC 结构的申威处理器核心,采用Core3B核心指令系统,主频为2.5 GHz,配置16 GB DDR3内存。使用perf性能分析工具对解码器进行瓶颈分析。实验选取高分辨率的4K、1 080P视频序列进行测试。
3.2" 实验数据
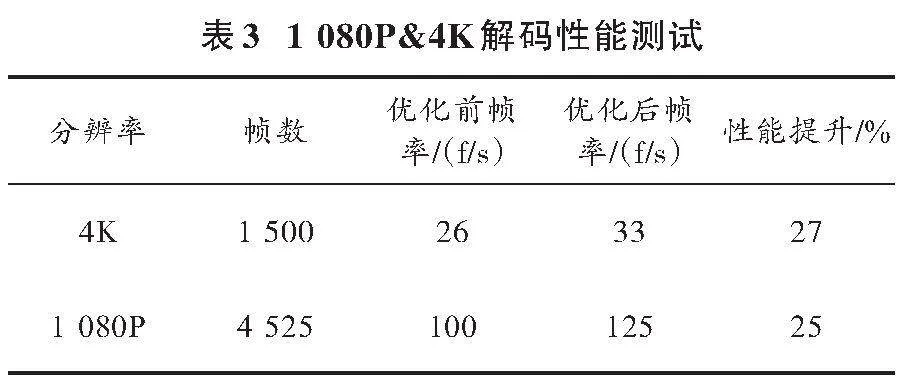
表2统计了环路滤波函数向量化前后的CPU耗时占比,以10亿个CPU周期(G Cycles)为单位。表3统计了优化前后视频的整体解码性能,主要以解码时的FPS作为性能比较基准单位。
通过实验对比,对环路滤波模块和帧拷贝过程进行优化,提高了解码器的解码性能。从表2可知,优化后,环路滤波模块计算效率明显改善。其中,h264_v_loop_filter_luma_8_c系列函数优化前后的加速比达到了6以上,而指令更加复杂的h264_v_loop_filter_chroma_8_c系列函数,加速比也达到了3以上,并且分辨率越高,优化的效率越明显。
从表3可知,优化后解码器整体解码性能明显改善,其中解码帧率是指100%的CPU资源用于解码能够达到的帧率。使用容易量化的解码帧率作为性能指标,测试视频序列中,4K视频的解码帧率提升了27%,1 080P视频解码帧率提升了25%。需要说明的是,H.264解码效率依赖于视频序列的内容变化程度,不同视频序列的优化效果并不一样。总的来说,视频序列的分辨率越高,优化的效率越明显。
4" 结" 语
本文在威焱831平台使用SIMD扩展部件对环路滤波系列函数和帧拷贝过程进行了优化,提高了H.264解码器的解码性能,威焱831平台视频解码的平均性能提高了26%。CPU开销中环路滤波模块占比的降低,验证了SIMD优化方法的可行性;帧拷贝优化方法的提出,使得解码器各个阶段都可以获益。下一步工作将针对SIMD非对界内存读取情况进行分析,更深层次地挖掘热点函数向量化的可行性。
在国家大力发展自主可控技术的背景下,国产CPU将迎来更大的舞台,高效的解码效率将会推动威焱831平台在多媒体领域的发展。
参考文献
[1] 杨华,赵香华.基于x264编码的码率控制模型优化方法[J].计算机仿真,2023,40(8):249⁃253.
[2] 韦薇,罗敏,白野,等.基于SIMD指令集的SM2数字签名算法快速实现[J].密码学报,2023,10(4):720⁃736.
[3] AMIRI H, SHAHBAHRAMI A. SIMD programming using Intel vector extensions [J]. Journal of parallel and distributed computing, 2009, 135(2): 134⁃135.
[4] 李善荣,孙超,韩娇,等.一种基于申威平台的全国产化计算机设计方法[J].工业控制计算机,2023,36(1):17⁃19.
[5] 周新虹,宋维.基于协议分析技术的多点H.264视频显示终端的设计与实现[J].电子技术与软件工程,2022(24):112⁃116.
[6] 谷一鑫.面向ARM架构的图像高性能计算库研究与移植优化[D].西安:西安电子科技大学,2023.
[7] 阳飞.基于龙芯2K1000B的H.264视频解码系统软件适配与优化[D].南京:东南大学,2022.
[8] 于向前.基于GSireamer框架的视频处理子系统设计与实现[D].南京:东南大学,2022.
[9] 陈炎,袁国顺,刘小强.基于NEON优化技术的视频处理系统设计[J].微电子学与计算机,2018,35(7):62⁃66.
[10] 张桢,梁军,贾海鹏,等.基于RISC⁃V的FFmpeg多媒体算法库优化策略[J].计算机工程,2023,49(4):159⁃165.
[11] 刘引涛,刘楠.基于ARM与4G网络的视频监控设计与实现[J].电子设计工程,2019,27(3):146⁃149.
[12] 李宇峰,李平安,欧泽强.H.265视频压缩算法优化设计与实现[J].电子技术与软件工程,2022(23):193⁃197.
[13] 徐福涛.基于MPEG4下多硬盘视频存储系统的解析[J].电子世界,2018(10):76.
[14] 黄永铖,宋利,解蓉.基于深度残差网络的VP9超级块快速划分算法[J].电视技术,2019,43(8):10⁃14.
[15] 李殿涛.Linux内核性能诊断分析[J].电脑编程技巧与维护,2021(10):47⁃48.
[16] 冯德邦.支持超高清的H.264熵解码器的设计与验证[D].哈尔滨:哈尔滨工业大学,2022.
[17] 方凌峰.针对AVS3的帧内预测优化技术的研究[D].北京:北京邮电大学,2022.
[18] 胡建华,吴伟美,杨忠明,等.用于视频编码的低复杂度自适应环路滤波方法[J].信息技术与信息化,2021(11):196⁃198.
猜你喜欢
中国石油石化(2022年12期)2022-07-16 08:28:28
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
中国外汇(2019年19期)2019-11-26 00:57:32
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
上海公路(2018年4期)2018-03-21 05:57:46
电测与仪表(2014年8期)2014-04-04 09:19:36
