
基于F⁃DFCC融合特征的语音情感识别方法
2024-09-14 00:00:00何朝霞朱嵘涛罗辉
现代电子技术 2024年6期

摘 "要: 结合神经网络、并行多特征向量和注意力机制,有助于提高语音情感识别的性能。基于此,从前期已经提取的DFCC参数入手,提取I⁃DFCC和Mid⁃DFCC特征参数,利用Fisher比选取特征参数构成F⁃DFCC;再将F⁃DFCC特征参数与LPCC、MFCC特征参数进行对比并融合,输入到含双向LSTM网络及注意力机制的ECAPA⁃TDNN模型中;最后,在CASIA和RAVDESS数据集上验证F⁃DFCC融合特征参数的有效性。实验结果表明:与单一的F⁃DFCC特征参数相比,F⁃DFCC融合特征的准确率WA、召回率UA、F1⁃score在CASIA数据集上分别提高0.035 1、0.031 1、0.031 3;在RAVDESS数据集上分别提高0.024 5、0.035 8、0.033 2。在两个数据集中,surprised情感的识别准确率最高,为0.94;F⁃DFCC融合特征参数的6种和8种情感识别率与其他特征参数相比均有所提升。
关键词: 语音情感识别; DFCC; F⁃DFCC; 融合特征; 特征提取; Fisher比; ECAPA⁃TDNN
中图分类号: TN912.3⁃34 " " " " " " " " " " " " " 文献标识码: A " " " " " " " " " " "文章编号: 1004⁃373X(2024)06⁃0131⁃06
Speech emotion recognition based on F⁃DFCC fusion feature
HE Zhaoxia1, ZHU Rongtao1, LUO Hui2
(1. College of Arts and Science, Yangtze University, Jingzhou 434023, China;
2. College of Computer and Control Engineering, Northeast Forestry Univesity, Harbin 150040, China)
Abstract: The performance of speech emotion recognition can be improved by combining neural networks, parallel multiple feature vectors, and attention mechanisms. On this basis, starting from the previously extracted DFCC parameters, I⁃DFCC and Mid DFCC feature parameters are extracted, and Fisher's ratio is used to select feature parameters to form F⁃DFCC. F⁃DFCC feature parameters are compared and fused with LPCC and MFCC feature parameters, and then they are inputted into the ECAPA⁃TDNN model with bidirectional LSTM network and attention mechanism. The effectiveness of F⁃DFCC fusion feature parameters is verified on the CASIA and RAVDESS datasets. The experimental results show that in comparison with single F⁃DFCC feature parameter, the accuracy WA, recall UA, and F1⁃score of F⁃DFCC fusion features are improved by 0.035 1, 0.031 1, and 0.031 3 on the CASIA dataset, respectively, improved by 0.024 5, 0.035 8, and 0.033 2 on the RAVDESS dataset, respectively. In the two datasets, the highest recognition accuracy was realized for supervised emotions, at 0.94. In comparison with other feature parameters, the recognition rates of the 6 and 8 emotions fused by F⁃DFCC are improved.
Keywords: speech emotion recognition; DFCC; F⁃DFCC; fusion feature; feature extraction; Fisher ratio; ECAPA⁃TDNN
0 "引 "言
语音情感识别(Speech Emotion Recognition, SER)在人机交互和计算机辅助人际交流等应用中发挥着重要作用。然而,由于自发情感表达的微妙性和模糊性,要使机器完全正确地解释出语音信号中所包含的情感是具有挑战性的。尽管SER已经得到了广泛的应用,但它的性能远远低于人类,识别过程仍然受到很多因素的困扰,因此,有必要进一步提高SER系统的性能。深度学习网络,例如卷积神经网络(CNN)和递归神经网络(RNN)等[1],在SER任务中表现出较高的效率,识别精度较传统方法也有了很大的提高。注意力机制可以动态地聚焦于某些部分,目前已经被应用于神经网络中。S. Mirsamadi等将局部注意力机制引入语音神经网络,使其关注语音信号的情感显著区域[2]。L. Tarantino等提出了一种带有自注意力机制的系统,以改善SER性能[3]。近年来,注意力机制引起了广泛关注,例如:Li Y等对语谱图的显著周期采用自我注意力机制[4];Xie Y等提出了一种基于时间和空间特征维注意力的长短期记忆(Long Short Term Memory, LSTM)输出加权算法[5];Li R等结合深度残差网络和多头注意力模型的内部依赖,将算法模型的最后一个时间步输出作为下一层的输入[6];B. Desplanques等提出了ECAPA⁃TDNN模型,该模型更加注重通道之间的注意力、信息的传播和聚合[7]。上述研究表明,与神经网络结合,并行多特征向量和引入注意力机制有助于提高SER性能。
MFCC参数是根据人耳听觉特性提出的,是识别语音信号最常用的特征[8]。针对MFCC特征参数在情感分析问题时存在的中、高频识别精度不高这一缺陷,王思羽、吴虹蕾选取MFCC、I⁃MFCC、Mid⁃MFCC特征参数,通过降维算法Fisher比准则,计算三种Mel倒谱系数对语音情感识别贡献度的高低,选取贡献度最高的参数进行融合后得到F⁃MFCC特征参数,并在此基础上对语音情感特征参数做进一步改进[9⁃10]。为了进一步提高系统的SER性能,本文从前期已经提取的DFCC参数入手,提取I⁃DFCC和Mid⁃DFCC参数,融合到一起构成F⁃DFCC特征;再适当地将F⁃DFCC特征与LPCC、MFCC特征通过CNN网络融合,得到基于F⁃DFCC的融合特征,增加每一个特征的情感信息量;同时将双向的LSTM网络应用到含有注意力机制的ECAPA⁃TDNN模型中,进一步选择有用的情感特征信息;最后,在CASIA数据集和RAVDESS数据集上,通过实验验证了F⁃DFCC融合特征参数和ECAPA⁃TDNN⁃LSTM模型的有效性。
1 "特征提取
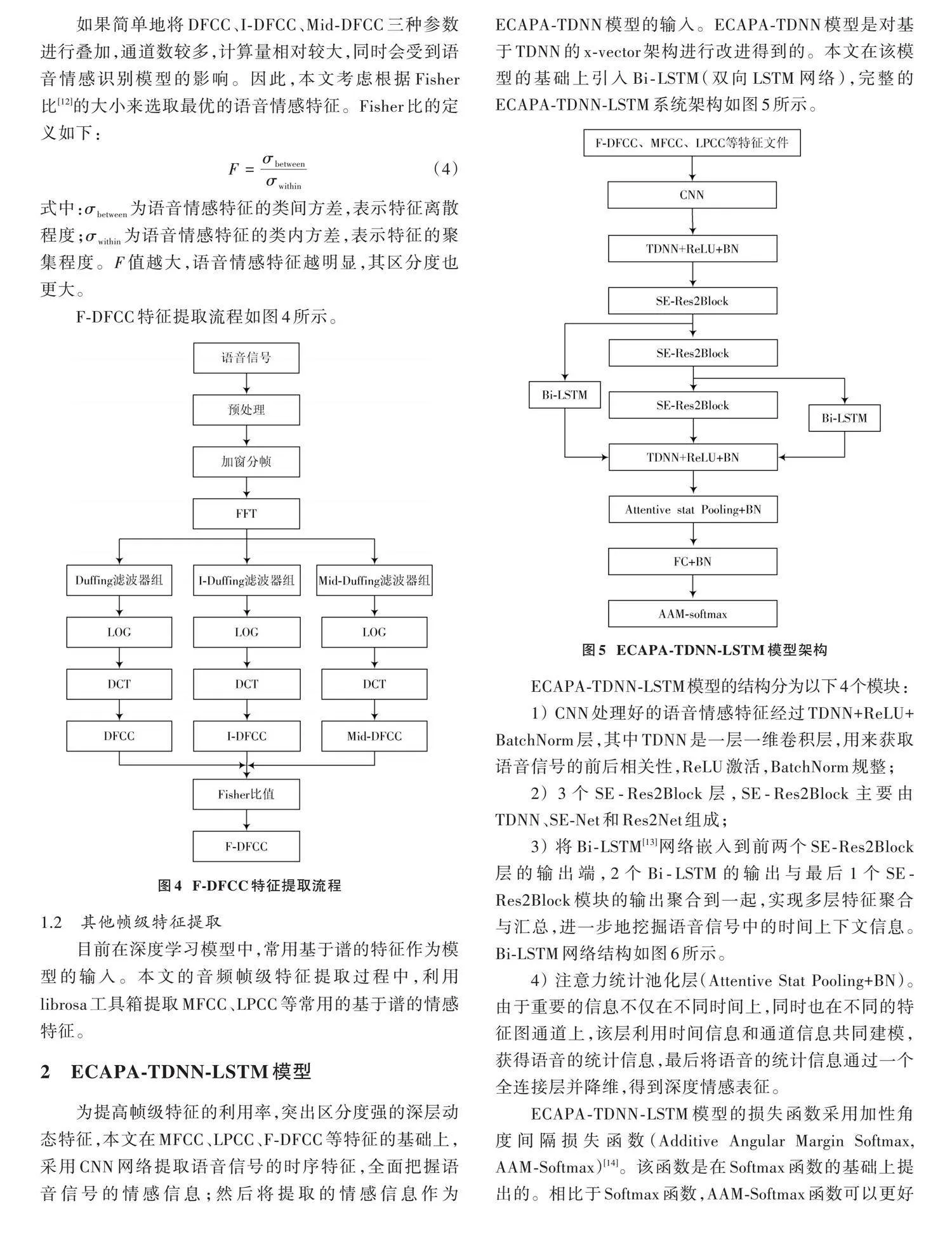
1.1 "F⁃DFCC特征提取
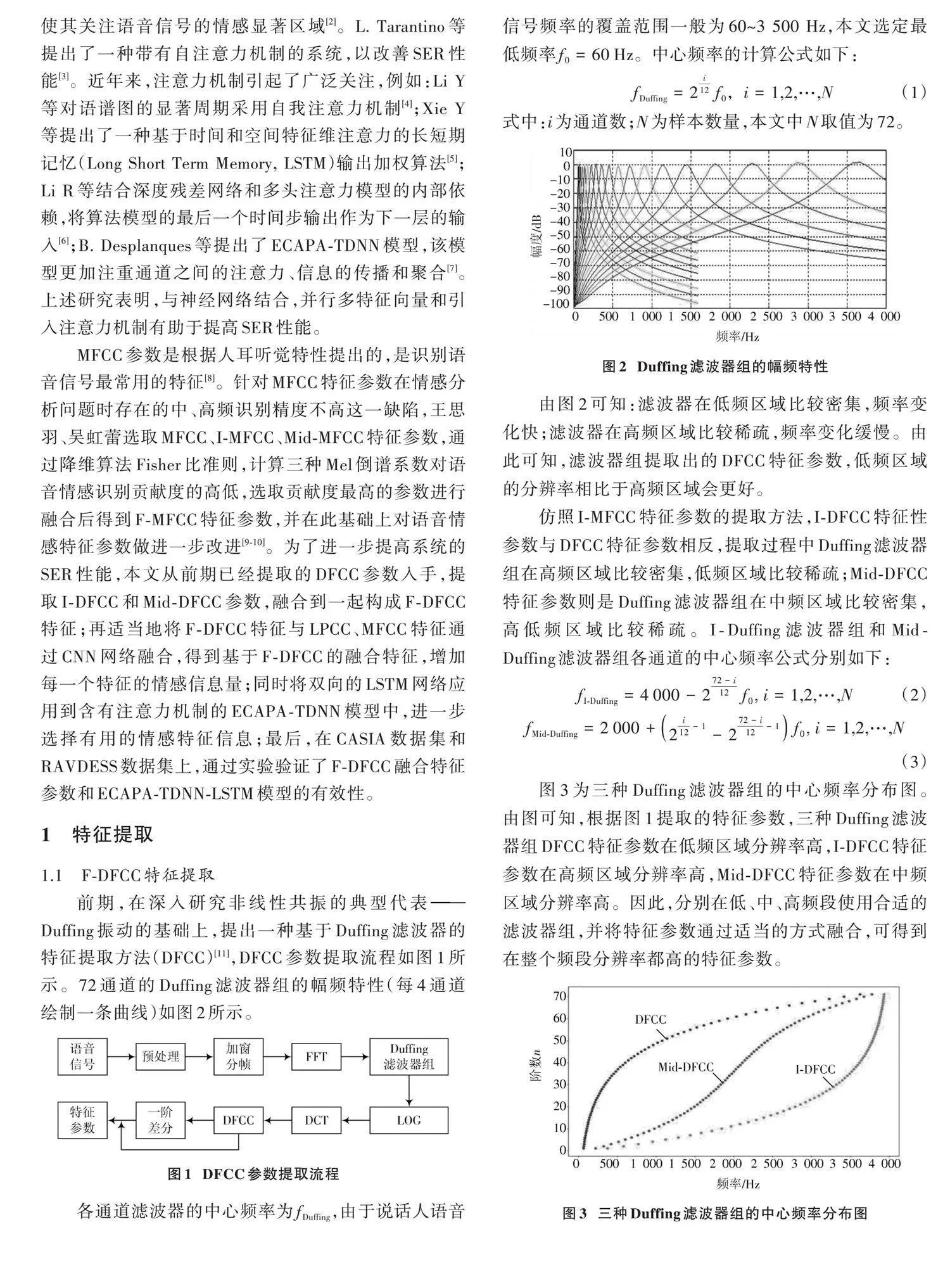
前期,在深入研究非线性共振的典型代表——Duffing振动的基础上,提出一种基于Duffing滤波器的特征提取方法(DFCC)[11],DFCC参数提取流程如图1所示。72通道的Duffing滤波器组的幅频特性(每4通道绘制一条曲线)如图2所示。
各通道滤波器的中心频率为[fDuffing],由于说话人语音信号频率的覆盖范围一般为60~3 500 Hz,本文选定最低频率[f0=60 Hz]。中心频率的计算公式如下:
[fDuffing=2i12f0,i=1,2,…,N] " " (1)
式中:i为通道数;N为样本数量,本文中N取值为72。
由图2可知:滤波器在低频区域比较密集,频率变化快;滤波器在高频区域比较稀疏,频率变化缓慢。由此可知,滤波器组提取出的DFCC特征参数,低频区域的分辨率相比于高频区域会更好。
仿照I⁃MFCC特征参数的提取方法,I⁃DFCC特征性参数与DFCC特征参数相反,提取过程中Duffing滤波器组在高频区域比较密集,低频区域比较稀疏;Mid⁃DFCC特征参数则是Duffing滤波器组在中频区域比较密集,高低频区域比较稀疏。I⁃Duffing滤波器组和Mid⁃Duffing滤波器组各通道的中心频率公式分别如下:
[fI⁃Duffing=4 000-272-i12f0, i=1,2,…,N] (2)
[fMid⁃Duffing=2 000+2i12-1-272-i12-1f0, i=1,2,…,N] " (3)
图3为三种Duffing滤波器组的中心频率分布图。由图可知,根据图1提取的特征参数,三种Duffing滤波器组DFCC特征参数在低频区域分辨率高,I⁃DFCC特征参数在高频区域分辨率高,Mid⁃DFCC特征参数在中频区域分辨率高。因此,分别在低、中、高频段使用合适的滤波器组,并将特征参数通过适当的方式融合,可得到在整个频段分辨率都高的特征参数。
如果简单地将DFCC、I⁃DFCC、Mid⁃DFCC三种参数进行叠加,通道数较多,计算量相对较大,同时会受到语音情感识别模型的影响。因此,本文考虑根据Fisher比[12]的大小来选取最优的语音情感特征。Fisher比的定义如下:
[F=σbetweenσwithin] " " " (4)
式中:[σbetween]为语音情感特征的类间方差,表示特征离散程度;[σwithin]为语音情感特征的类内方差,表示特征的聚集程度。F值越大,语音情感特征越明显,其区分度也更大。
F⁃DFCC特征提取流程如图4所示。
1.2 "其他帧级特征提取
目前在深度学习模型中,常用基于谱的特征作为模型的输入。本文的音频帧级特征提取过程中,利用librosa工具箱提取MFCC、LPCC等常用的基于谱的情感特征。
2 "ECAPA⁃TDNN⁃LSTM模型
为提高帧级特征的利用率,突出区分度强的深层动态特征,本文在MFCC、LPCC、F⁃DFCC等特征的基础上,采用CNN网络提取语音信号的时序特征,全面把握语音信号的情感信息;然后将提取的情感信息作为ECAPA⁃TDNN模型的输入。ECAPA⁃TDNN模型是对基于TDNN的x⁃vector架构进行改进得到的。本文在该模型的基础上引入Bi⁃LSTM(双向LSTM网络),完整的ECAPA⁃TDNN⁃LSTM系统架构如图5所示。
ECAPA⁃TDNN⁃LSTM模型的结构分为以下4个模块:
1) CNN处理好的语音情感特征经过TDNN+ReLU+BatchNorm层,其中TDNN是一层一维卷积层,用来获取语音信号的前后相关性,ReLU激活,BatchNorm规整;
2) 3个SE⁃Res2Block层,SE⁃Res2Block主要由TDNN、SE⁃Net和Res2Net组成;
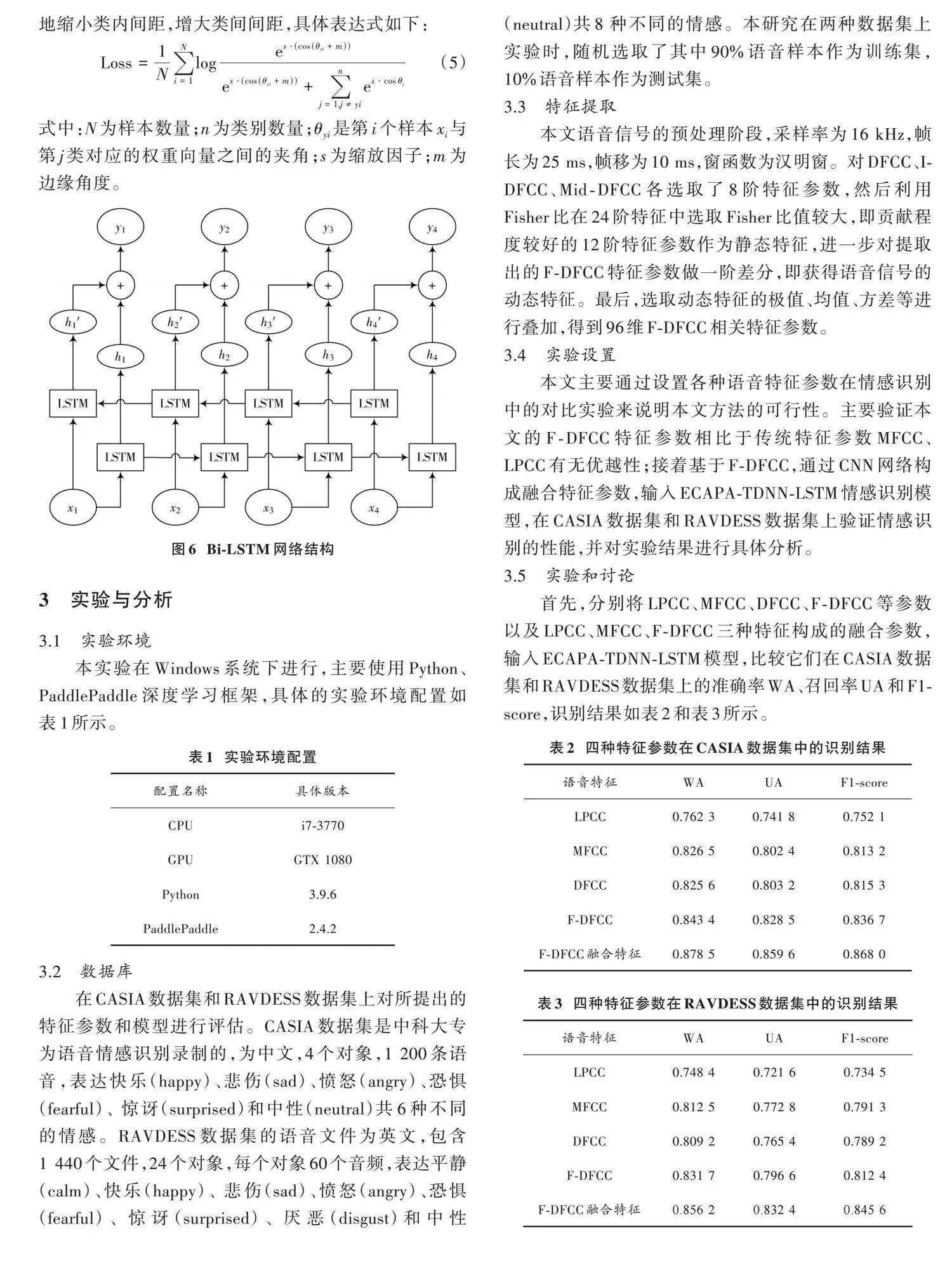
3) 将Bi⁃LSTM[13]网络嵌入到前两个SE⁃Res2Block层的输出端,2个Bi⁃LSTM的输出与最后1个SE⁃Res2Block模块的输出聚合到一起,实现多层特征聚合与汇总,进一步地挖掘语音信号中的时间上下文信息。Bi⁃LSTM网络结构如图6所示。
4) 注意力统计池化层(Attentive Stat Pooling+BN)。由于重要的信息不仅在不同时间上,同时也在不同的特征图通道上,该层利用时间信息和通道信息共同建模,获得语音的统计信息,最后将语音的统计信息通过一个全连接层并降维,得到深度情感表征。
ECAPA⁃TDNN⁃LSTM模型的损失函数采用加性角度间隔损失函数(Additive Angular Margin Softmax, AAM⁃Softmax)[14]。该函数是在Softmax函数的基础上提出的。相比于Softmax函数,AAM⁃Softmax函数可以更好地缩小类内间距,增大类间间距,具体表达式如下:
[Loss=1Ni=1Nloges⋅(cos(θyi+m))es⋅(cos(θyi+m))+j=1,j≠yines⋅cosθj] (5)
式中:N为样本数量;n为类别数量;[θyi]是第i个样本xi与第j类对应的权重向量之间的夹角;s为缩放因子;m为边缘角度。
3 "实验与分析
3.1 "实验环境
本实验在Windows系统下进行,主要使用Python、PaddlePaddle深度学习框架,具体的实验环境配置如表1所示。
3.2 "数据库
在CASIA数据集和RAVDESS数据集上对所提出的特征参数和模型进行评估。CASIA数据集是中科大专为语音情感识别录制的,为中文,4个对象,1 200条语音,表达快乐(happy)、悲伤(sad)、愤怒(angry)、恐惧(fearful)、 惊讶(surprised)和中性(neutral)共6种不同的情感。RAVDESS数据集的语音文件为英文,包含1 440个文件,24个对象,每个对象60个音频,表达平静(calm)、快乐(happy)、 悲伤(sad)、愤怒(angry)、恐惧(fearful)、 惊讶(surprised)、 厌恶(disgust)和中性(neutral)共8 种不同的情感。本研究在两种数据集上实验时,随机选取了其中90%语音样本作为训练集,10%语音样本作为测试集。
3.3 "特征提取
本文语音信号的预处理阶段,采样率为16 kHz,帧长为25 ms,帧移为10 ms,窗函数为汉明窗。对DFCC、I⁃DFCC、Mid⁃DFCC各选取了8阶特征参数,然后利用Fisher比在24阶特征中选取Fisher比值较大,即贡献程度较好的12阶特征参数作为静态特征,进一步对提取出的F⁃DFCC特征参数做一阶差分,即获得语音信号的动态特征。最后,选取动态特征的极值、均值、方差等进行叠加,得到96维F⁃DFCC相关特征参数。
3.4 "实验设置
本文主要通过设置各种语音特征参数在情感识别中的对比实验来说明本文方法的可行性。主要验证本文的F⁃DFCC特征参数相比于传统特征参数MFCC、LPCC有无优越性;接着基于F⁃DFCC,通过CNN网络构成融合特征参数,输入ECAPA⁃TDNN⁃LSTM情感识别模型,在CASIA数据集和RAVDESS数据集上验证情感识别的性能,并对实验结果进行具体分析。
3.5 "实验和讨论
首先,分别将LPCC、MFCC、DFCC、F⁃DFCC等参数以及LPCC、MFCC、F⁃DFCC三种特征构成的融合参数,输入ECAPA⁃TDNN⁃LSTM模型,比较它们在CASIA数据集和RAVDESS数据集上的准确率WA、召回率UA和F1⁃score,识别结果如表2和表3所示。
观察表2和表3可知,无论是在CASIA数据集还是RAVDESS数据集上,DFCC特征参数的识别效果都明显优于LPCC,略逊于MFCC特征参数,但是F⁃DFCC特征参数的效果优于MFCC。F⁃DFCC准确率WA、召回率UA、F1⁃score三个指标,在CASIA数据集上分别高于MFCC特征0.016 9、0.026 1、0.023 5;在RAVDESS数据集上分别高于MFCC特征0.019 2、0.023 8、0.021 1。
进一步,将LPCC、MFCC、F⁃DFCC三种特征文件输入CNN模型中,提取F⁃DFCC融合特征中的高级特征。F⁃DFCC融合特征的准确率WA、召回率UA、F1⁃score较单一的F⁃DFCC特征参数,在CASIA数据集上分别高0.035 1、0.031 1、0.031 3;在RAVDESS数据集上分别高0.024 5、0.035 8、0.033 2。由此证明F⁃DFCC融合特征能够较全面地把握语音信号的情感信息。
接着,将F⁃DFCC融合特征参数输入ECAPA⁃TDNN⁃LSTM模型,分别在CASIA和RAVDESS数据集上对比其训练损失函数,结果如图7所示。
对比图7中两条损失函数曲线,在RAVDESS数据集上下降比较缓慢,主要原因是RAVDESS数据集较CASIA数据集情感类型更多。整体而言,当step为4 000时,两个训练集上的损失函数基本稳定。
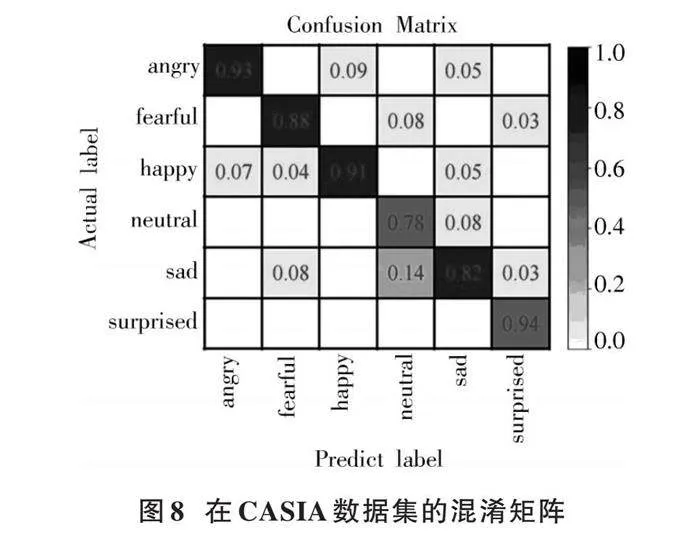
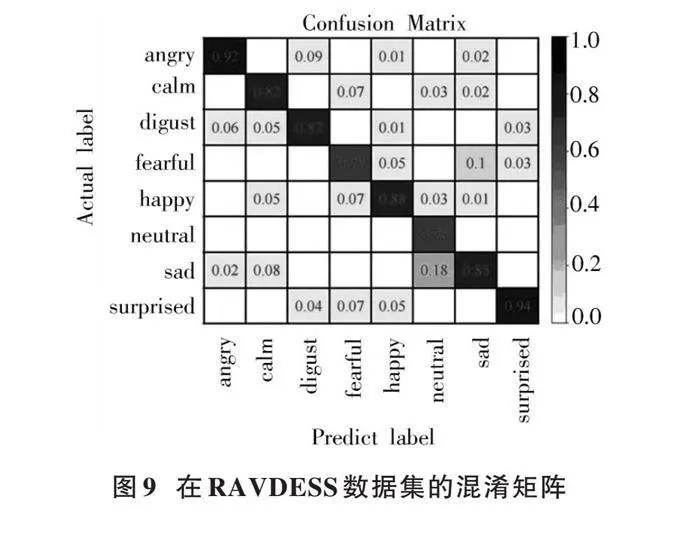
同时,得到在两个数据集上的混淆矩阵,分别如图8和图9所示。
混淆矩阵可以更加直观地展现出F⁃DFCC融合特征参数输入ECAPA⁃TDNN⁃LSTM模型进行语音情感识别的性能,两图中对角线表示情感识别率,其他数值表示某种情感被误判为其他情感的比例。
从图8和图9中可以看出,无论是在CASIA数据集还是RAVDESS数据集,surprised情感的识别准确率最高,识别率高达0.94。从整体上看,情感之间存在比较轻度的相互干扰,在两种数据集上的neutral情感的识别率相比于其他情感识别率低,最高误判率达到了0.10以上。从整体性能来看,F⁃DFCC融合特征参数的6种和8种情感识别率与其他特征参数相比均有所提升。
4 "结 "论
本文仿照F⁃MFCC特征参数提取方法,引入DFCC、I⁃DFCC、Mid⁃DFCC特征参数,并对其特点、提取方法分别做详细介绍;再利用Fisher比计算三种特征参数对语音情感识别的贡献度,选取贡献度最高的12阶参数进行融合降维,得出F⁃DFCC特征参数。
将F⁃DFCC特征参数与LPCC、MFCC融合后进行情感识别实验,实验结果表明:F⁃DFCC融合特征的准确率WA、召回率UA、F1⁃score与单一的F⁃DFCC特征参数相比,在CASIA数据集上分别高0.035 1、0.031 1、0.031 3;在RAVDESS数据集上分别高0.024 5、0.035 8、0.033 2。证明F⁃DFCC融合特征能够较全面地把握语音信号的情感信息。
将F⁃DFCC融合特征参数输入ECAPA⁃TDNN⁃LSTM模型,得出无论是在CASIA数据集还是RAVDESS数据集,surprised情感的识别准确率最高,为0.94。从整体性能来看,F⁃DFCC融合特征参数的6种和8种情感识别率与其他特征参数相比均有所提升。
注:本文通讯作者为罗辉。
参考文献
[1] TRIGEORGIS G, RINGEVAL F, BRUECKNER R, et al. Adieu features?End⁃to⁃end speech emotion recognition using a deep convolutional recurrent network [C]// IEEE International Conference on Acoustics,Speech and Signal Processing. Shanghai: IEEE, 2016: 5200⁃5204.
[2] MIRSAMADI S, BARSOUM E, ZHANG C. Automatic speech emotion recognition using recurrent neuralnetw orks with local attention [C]// IEEE International Conference on Acoustics,Speech and Signal Processing. New Orleans, LA, USA: IEEE, 2017: 2227⁃2231.
[3] TARANTINO L, GARNER P N, LAZARIDIS A. Self⁃attention for speech emotion recognition [C]// Interspeech. Graz, Austria: IEEE, 2019: 2578⁃2582.
[4] LI Y, ZHAO T, KAW AHARA T. Improved end⁃to⁃end speech emotion recognition using self attention mechanism and multitask learning [C]// Interspeech. Graz, Austria: IEEE, 2019: 2803⁃2807.
[5] XIE Y, LIANG R, LIANG Z, et al. Speech emotion classifi cation using attention⁃based LSTM [J]. IEEE/ACM transactions on audio, speech, and language processing, 2019, 27(11): 1675⁃1685.
[6] LI R, WU Z, JIA J, et al. Dilated residual network with multi⁃head self⁃attention for speech emotion recognition [C]// IEEE International Conference on Acoustics, Speech and Signal Processing. Brighton, UK: IEEE, 2019: 6675⁃6679.
[7] DESPLANQUES B, THIENPONDT J, DEMUYNCK K. Ecapa⁃TDNN: emphasized channel attention, propagation and aggregation in TDNN based speaker verification [C]// International Speech Communication Association. Shanghai: IEEE, 2020: 3830⁃3834.
[8] 崔琳,崔晨露,刘政伟,等.改进MFCC和并行混合模型的语音情感识别[J].计算机科学,2023,50(z1):166⁃172.
[9] 王思羽.语音情感识别算法研究[D].南京:南京邮电大学,2019.
[10] 吴虹蕾.基于深度学习的语音情感识别算法的设计与实现[D].哈尔滨:黑龙江大学,2021.
[11] 何朝霞,潘平,罗辉.音色变换音频信号的篡改检测技术研究[J].中国测试,2017,43(2):98⁃103.
[12] 孙肖然.阻塞性睡眠呼吸暂停低通气的鼾声识别与分类[D].广州:华南理工大学,2022.
[13] 王佳慧.基于CNN与Bi⁃LSTM混合模型的中文文本分类方法[J].软件导刊,2023,22(1):158⁃164.
[14] 张悦.基于深度学习的语音情感识别[D].成都:电子科技大学,2022.
[15] SCHULLER B, STEIDL S, BATLINER A, et al. The INTER SPEECH 2010 paralinguistic challenge [C]// Interspeech.
Makuhari, Japan: IEEE, 2010: 2794⁃2797.
猜你喜欢
计算技术与自动化(2024年3期)2024-10-10 00:00:00
中国特种设备安全(2021年5期)2021-11-06 05:09:00
装备制造技术(2021年4期)2021-08-05 07:39:54
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2018年16期)2018-09-26 03:26:50
制造技术与机床(2017年11期)2017-12-18 06:46:39
数学物理学报(2017年5期)2017-11-23 07:51:31
火控雷达技术(2016年2期)2016-02-06 02:29:00
