
基于特征采样引导和集成RFELM的道路高排放源识别模型
2024-09-14 00:00:00周汉胜段培杰李泽瑞周金华
现代电子技术 2024年6期




摘 "要: 机动车排放的污染气体会对环境造成严重危害,其中尾气排放超标的车辆是主要污染来源,因此实现对道路高排放源的有效识别具有重要意义。针对尾气遥测数据,提出一种基于特征采样引导和集成随机傅里叶特征极限学习机(RFELM)的道路高排放源识别模型。首先对遥测数据进行多次随机采样,构建多组训练子集;然后对每组训练子集进行多次特征采样,并训练对应的子分类器,根据组内最优子分类器的输入特征更新特征采样的概率与特征权重;最后对所有子分类器的验证分数进行排序,筛选出一定比例的RFELM组成分类器集合,采用加权投票法预测数据的标签。实验结果表明,相比于RFELM和随机森林等算法,所提模型在真实的道路遥测数据上具有更好的识别效果,还有着更强的抗噪能力。
关键词: 道路高排放源识别; 遥测数据; 特征采样; 集成学习; 随机傅里叶特征极限学习机; 子分类器
中图分类号: TN957.52+3⁃34; X734.2 " " " " " " " " 文献标识码: A " " " " " " " "文章编号: 1004⁃373X(2024)06⁃0124⁃07
On⁃road high⁃emitter identification model based on guided feature sampling and ensemble RFELM
ZHOU Hansheng1, 2, DUAN Peijie2, 3, LI Zerui1, 2, ZHOU Jinhua1
(1. School of Biomedical Engineering, Anhui Medical University, Hefei 230023, China;
2. Institute of Artificial Intelligence, Hefei Comprehensive National Science Center, Hefei 230088, China;
3. AHU⁃IAI AI Joint Laboratory, Anhui University, Hefei 230601, China)
Abstract: The pollution gas emitted by vehicles causes serious harm to the environment, among which the vehicles with excessive exhaust emissions are the major sources of pollutions. Therefore, it is of great significance to realize the effective identification of high⁃emitters on the road. A high⁃emitter identification model based on guided feature sampling and ensemble random Fourier feature extreme learning machines (RFELM) is proposed to classify the on⁃road remote sensing data. The remote sensing data is randomly sampled several times to construct multiple training subsets. Then, each training subset is sampled several times to train corresponding subclassifiers. The sampling probability and weight of feature are updated according to the input features of the optimal subclassifiers in the group. The validation scores of all subclassifiers are sorted, a certain proportion of RFELM is selected to form the classifier set, and the weighted voting method is used to predict the labels of the test data. The experimental results show that in comparison with RFELM, random forest and so on, the proposed model has better recognition performance and stronger noise resistance on real road remote sensing data.
Keywords: on⁃road high⁃emitter recognition; remote sensing data; feature sampling; ensemble learning; random Fourier feature extreme learning machine; subclassifier
0 "引 "言
据统计,机动车在行驶过程中排放的有害气体已成为大气污染的主要来源[1]。为改善空气质量,需要加强对尾气排放超标机动车的快速检测和监管控制。目前,越来越多的地区利用尾气遥测技术实现对道路高排放源的识别。根据对机动车排放遥测数据处理方法的不同,可以将道路高排放源识别方法分为设定限值方法和基于机器学习的方法。设定限值方法对限值的设置需要依赖一定的人工经验,而机器学习方法通过挖掘机动车尾气监测数据之间的内在联系和规律进行决策,具有更高的科学性[2]。
基于机器学习算法的高排放源识别方法可以实现对道路高排放源的自动识别与分类,极大地减少人力和物力成本,具有较高的研究价值和应用前景。目前,已有研究人员根据尾气遥测数据进行有针对性的研究。曾君等人根据车辆怠速检测结果和道路遥测数据构建高排放车辆识别模型,通过引入主成分分析、K最近邻思想、遗传算法和机动车比功率,实现了对高排放车辆的有效识别[3]。Guo等人将机动车尾气遥测数据和怠速检测结果输入到反向传播神经网络中[4],可以正确识别移动污染源的比例达到81.63%。Wang等人引入了一个表征记忆模块,通过迭代学习保留关键数据特征,并且重构移动源的时间序列特征,提高了对高排放源和正常排放源的识别准确率[5]。Li等人研究了一种基于加权极限学习机的道路高排放源识别模型,通过主动学习的方式选择有价值的样本进行标记。实验结果证明,该方法能够提高对道路高排放源的识别性能[6]。Kang等人使用可信度高的高排放遥测数据构建了基于单分类支持向量机和半监督的单分类支持向量机的移动污染源识别模型[7]。实验结果显示,该方法提升了对道路高排放源和正常排放源识别的准确性。
在道路高排放源识别任务中,所获取到的数据除排放污染物浓度外,通常还包括机动车信息与当前环境信息。但是这类信息庞杂,一些特征会对模型性能起到相反的作用,降低模型的识别精度[8],而重要特征与相关特征的组合可能达到最好的效果,但是在缺乏先验的前提下,无法判断特征与特征组合的重要性。为此,本文提出一种基于特征采样引导和集成RFELM的道路高排放源识别模型(RF⁃RFELMBagging)。首先,构建多组训练子集与验证子集,在每组训练集上进行特征的多次随机采样,并训练对应的RFELM子分类器;然后,根据上一组数据集特征采样的概率和最优子分类器所使用的特征计算得到下一组特征采样的概率,实现特征采样引导;最后,在测试集上选取部分性能优异的子分类器,通过加权投票的方式决定最终预测结果。根据实验结果,RF⁃RFELMBagging在道路高排放源识别任务中取得了较高的分类精度并具有较好的稳定性,并对特征与特征组合的重要性进行了分析。
1 "算法介绍
极限学习机(Extreme Learning Machine, ELM)是一种单隐含层前馈神经网络[9],只需设置隐含层节点个数,随机生成隐含层输入权值与偏置,不用进行迭代即可得到最优解,具有泛化能力强和识别精度高的优点。KELM是基于ELM 并引入核函数所提出的改进算法,核函数能够将特征映射到较高维空间,提高数据的可分性,已经广泛应用于多个领域[10⁃11]。随机傅里叶特征(Random Fourier Feature, RFF)[12]将数据特征映射至一个相对低维的特征空间,近似实现核映射的效果。受此启发,本文通过RFF映射生成ELM的隐含层节点,构建以RFELM为子分类器的集成学习算法。
1.1 "RFELM
具体来说,对于数据[x∈RN×m],N表示样本数, m表示输入数据的维度。对应标签的one⁃hot编码[y∈RN×c],c表示类别数。RFELM的隐含层节点通过RFF映射生成,RFF公式如下所示:
[fxi=2D[cosxiw1+b1,…,cosxiwj+bj,…,cosxiwD+bD], "i=1,2,…,N] "(1)
式中:[fxi∈R1×D];[xi]是输入数据[x]中第[i]条数据,输入数据[x]=[xT1,xT2,…,xTNT];D为经过RFF映射后的维度。
为满足RFF映射结果接近高斯核函数,[wj]和[bj]符合以下要求:[wj∈Rm×1]服从高斯分布[N0,σ2],[bj]服从均匀分布[U0,2π],其中[j=1,2,…,D];[σ2]是预定义的方差。输入数据通过RFF映射生成ELM的隐含层节点,公式如下:
[A=fx1T,fx2T,…,fxNTT] " " (2)
目标函数如下:
[min 12Aβ-y2+C2β2] "(3)
式中C为正则项系数,输出层权重[β]公式为:
[β=IC+ATA-1ATy, "Ngt;D;I∈RD×DATIC+AAT-1y, "N≤D;I∈RN×N ] " " "(4)
1.2 "RF⁃RFELMBagging
1.2.1 "样本采样
首先在数据集上划分出30%的测试集,随后在剩余样本中按照设定比例进行K次随机采样,得到K组不同的训练集与验证集。
1.2.2 "特征采样引导
在每一组训练集上进行特征采样时,为了能够偏向选择重要特征,本文会根据上一组训练集下子分类器的验证结果,对下一组的特征采样进行优化,这一过程称为特征采样引导。
令[counti=counti1,…,countij,…,countim],当i=1时,设[count1=1,1,…,1];当igt;1时,会根据第i-1组训练集下对应的最优子分类器的输入特征,将对应[countij=counti-1j+1]。[pij]表示第i次特征采样时,第j个特征的采样概率,公式如下:
[pij=countijj=1mcountij] " " " " " (5)
同时,为了让重要特征的作用放大,对特征进行加权。由于采样概率[pij]一定程度上能反映特征的重要性,因此对采样概率进行缩放,得到特征权重。具体公式为:
[wij=exppij-meanpistdpi] " " " " (6)
式中:[pi=pi1,…,pij,…,pim];[wij]表示第[i]组训练集中第[j]个特征的权重,会放大一部分当前认为重要的特征,并缩小其他特征。
1.2.3 "训练与预测
在每组训练集上经过L次特征随机采样后,分别训练得到L个子分类器,采用每个子分类器预测验证集得到验证分数。最后在L×K个子分类器中根据验证分数进行排序,以选取一部分性能较好的子分类器,并利用它们的验证分数作为权重,通过加权投票的方式决定最终的预测结果。
算法流程如图1所示。
2 "实验与分析
2.1 "数据处理与评价指标
2.1.1 "数据处理
本文采用道路遥测数据作为实验数据,数据特征包括机动车类型、燃油规格、标识类型、基准质量、最大总质量、车检年限、遥测年限、识别置信度、行驶速度、加速度、车长、CO、HC、NO、CO2的实测浓度、不透光烟度、风速、风向、温度、湿度、气压、不透光系数、最大不透光烟度和平均不透光烟度等,具体信息如表1所示。数据中高排放移动源数量为138,其余为正常排放移动源,数量为3 964。
由于原始数据存在缺失的情况,为了得到更多的训练数据,本文对数据进行缺失值补全。使用KNN算法对缺失值进行补全,具体过程为:计算缺失值所在样本k个最近邻居,根据所有邻居对应特征的均值来进行填充;再对所有数据进行标准化,使其均值为0,方差为1。
2.1.2 "评价指标
实验数据不同类别间样本数量差异较大,存在类别分布不均衡的情况,在这种情况下,使用准确率来评估算法的性能不够全面。为了更客观地评估模型的性能,在本文中使用F1分数作为评价指标。F1分数是一个综合考虑模型的精确率和召回率的指标,其中精确率(Precision, P)定义为模型预测为高排放的样本中真实高排放样本的比例,召回率(Recall, R)定义为在真实高排放样本中被模型正确检测出来的比例。F1分数公式如下:
[F1=2PRP+R] " " " " " " "(7)
通过使用F1分数来评估模型性能,可以更好地衡量模型在本实验数据集上的表现。F1分数越大,证明模型性能更好。
2.2 "实验结果
2.2.1 "对比实验
为验证RF⁃RFELMBagging算法的有效性,选取RFELM、SVM[13]、DT(Decision Tree)[14]、RF(Random Forest)[15]、AdaBoost[16]和DF[2]作为对比方法。RF⁃RFELMBagging算法中,设置K=50,L=20,筛选一半子分类器参与最终决策。RF和AdaBoost均使用1 000个子分类器,实验结果如表2所示。
从表2中可以看出,RF⁃RFELMBagging具有最高的F1分数,达到了71.7%,并且还有较低的标准差,这表明本文算法识别性能较好并且具有稳定性。DT、DF和AdaBoost方法表现良好,F1分数分别达到了68.5%、59.2%和67.5%,说明这三种方法对高排放源有一定的识别能力,但仍低于本文算法的F1分数。RFELM方法的F1分数仅为39%,观察R和P指标发现,尽管其R指标最高,但P指标是所有方法中最低的,可能是模型容易将正常排放源错误预测为高排放源。RF方法的表现较差,其R和P与RFELM相反,在所有方法中R指标最低,P指标最高,F1分数为51.2%,可能是模型容易将高排放源错误预测为正常排放源。SVM实验结果分类器并未倾向某一类别,但整体F1分数并不高。综上所述,RF⁃RFELMBagging方法在道路高排放源识别中取得了最好的识别结果。
2.2.2 "筛选比例δ对实验结果的影响
为了探究参与预测的子分类器数量对算法的影响,分别选取了筛选比例δ为[0.1,0.2,…,1]的RFELM进行预测,实验结果如图2所示。
从图2中可以看出,RF⁃RFELMBagging的F1分数随着筛选比例δ的增加呈现先上升后下降的趋势。上升的原因可能是参与预测的子分类器数量的增加,提高了模型的泛化能力。
为了解释下降的原因,统计了所有的RFELM子分类器验证分数,其分布情况如图3所示。从图3的分布结果可以看出,有相当一部分子分类器验证分数过低,当这部分子分类器参与预测时会导致模型性能下降。
2.2.3 "抗噪实验
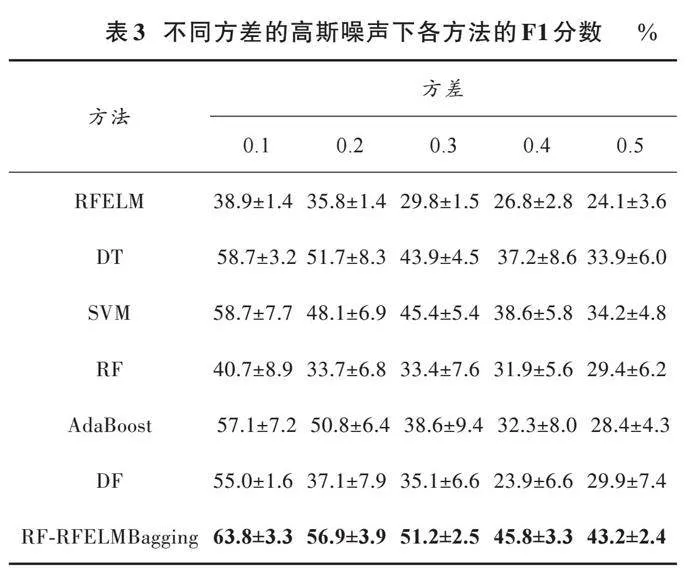
由于尾气遥测数据采集于机动车实际行驶环境,不可避免会存在噪声,因此模型的抗噪能力对移动污染源的识别具有重要意义。为了检验模型的抗噪声能力,向数据中引入不同程度的噪声数据来验证模型的稳定性。具体为在已经标准化的数据中引入均值为0,方差分别为[0.1,0.2,…,0.5]的随机高斯分布噪声进行实验,结果如表3所示。在噪声逐渐增强的过程中,与其他算法相比,RF⁃RFELMBagging算法模型性能下降较缓,在不同方差的情况下都具有最好的性能。这表明RF⁃RFELMBagging在噪声环境下,相比于其他对比算法有着更强的抗噪性。
2.2.4 "消融实验
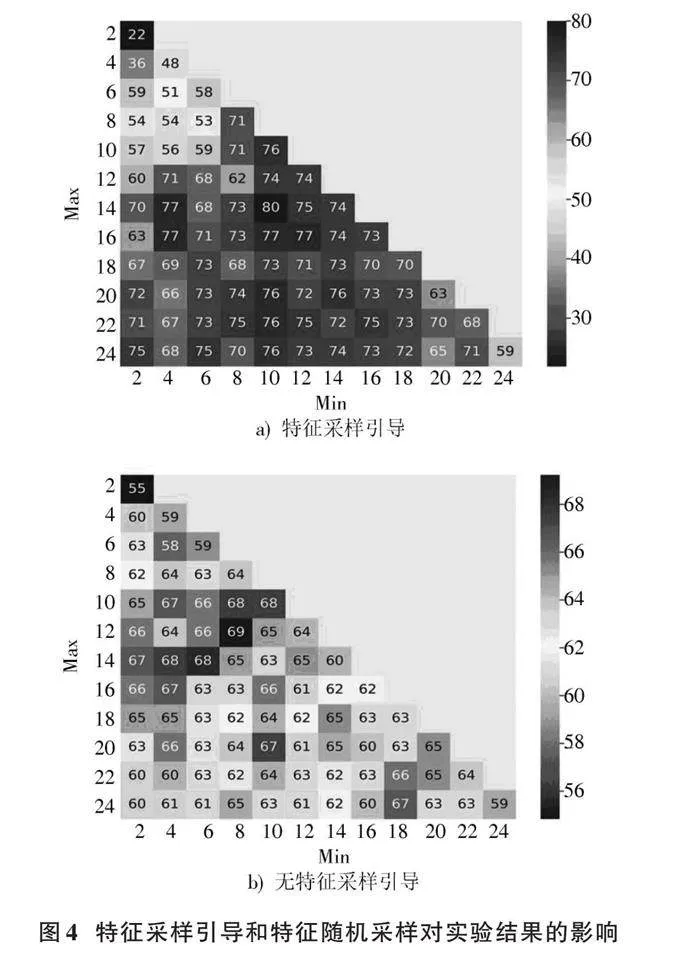
与单纯的Bagging算法相比,RF⁃RFELMBagging对使用的特征进行了随机采样,并对特征采样概率进行了引导。为了证明随机采样以及特征采样引导的作用,本文根据是否使用特征采样引导和特征随机采样,分别进行两组实验,实验结果如图4所示。其中图a)表示RF⁃RFELMBagging算法的特征采样数量Min和Max在2~24之间时的实验结果,在Min=10和Max=14时,F1分数最高达到80%。图b)展示了RF⁃RFELMBagging未使用特征采样引导策略的实验结果,此时特征的采样概率始终相同,当Min=8和Max=12时,未使用特征采样引导方法的F1分数最高为69%。
图4b)中,当Min和Max均为最大值时,此时算法退化为子分类器为RFELM的投票集成学习算法,F1分数仅为59%,远低于最高F1分数69%。这可能是因为全部特征中包含了部分对高排放源识别任务无关的特征,影响了重要特征的筛选与放大,而特征随机采样对提升道路高排放源识别精度是有效的。观察图a)与图b)可以看出,使用了特征采样引导的图a)总体要优于未使用的图b),且最高F1分数高出11%,这可能是因为特征采样引导使得特征采样更侧重于当前认为重要的特征,该特征作为训练数据的组成部分,将有效提高RFELM的识别精度。在图a)中,当Min和Max均为最大值时,F1分数仅为59%,远低于使用了特征随机采样和特征采样引导的80%,说明使用特征随机采样和特征采样引导对提升道路高排放识别是有效的。
2.2.5 "特征分析
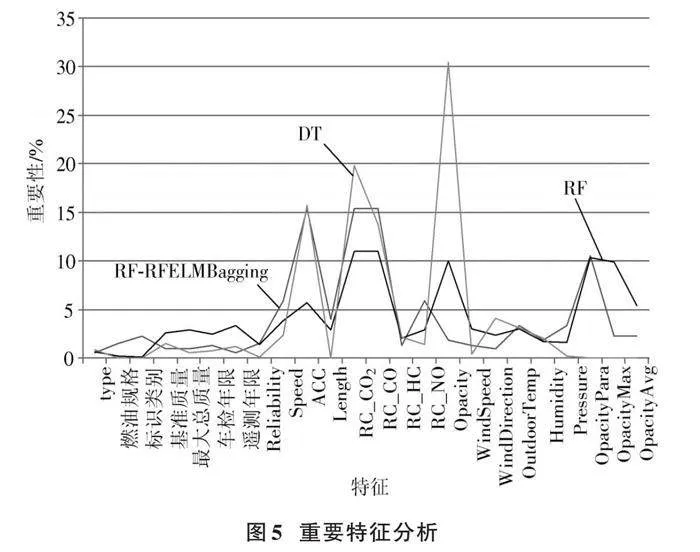
在RF⁃RFELMBagging算法中,记录了最后一组子分类器更新后的特征权重,在一定程度上可以体现这些特征在该次任务的重要性。RF和DT算法可以通过计算每个特征的基尼指数并归一化来衡量尾气遥测数据中各个特征的重要程度。本文将RF⁃RFELMBagging的特征权重进行归一化,表示各个特征的重要性,并与RF和DT计算的特征重要性进行对照分析,如图5所示。
由图5可知,在DT算法中特征之间的重要性差异比较明显,Opacity的重要性远高于其他特征,其次表现突出的是RC_CO2、ACC、RC_CO,而一些特征被认为完全不重要,如OpacityPara、OpacityMax、OpacityAvg等。在RF算法中,RC_CO2、RC_CO、Opacity同样有着比较突出的重要性,但OpacityPara和OpacityMax的特征重要性也很高,与DT的结果相悖。在RF⁃RFELMBagging中,ACC、RC_CO2、RC_CO的重要性与DT接近,与DT和RF不同的是,Opacity的特征重要性并不算突出。由此可见,RF⁃RFELMBagging与RF和DT类似,也可以评估单个特征的重要性。
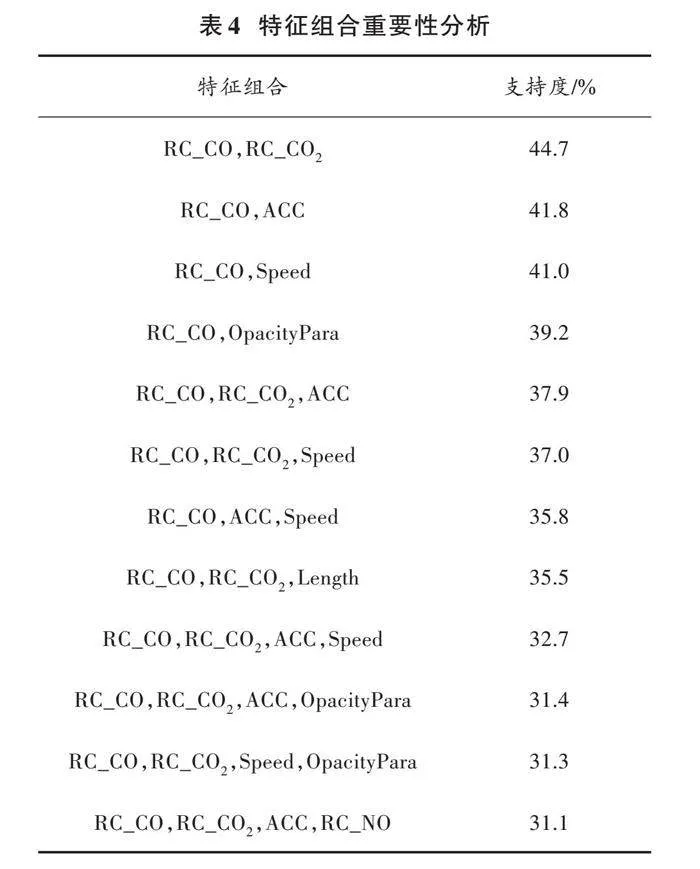
本文通过Apriori算法[17]发掘RF⁃RFELMBagging被选择分类器中出现的特征组合模式,特征组合的支持度表示特征组合出现的频率,如表4所示。
在两个特征的组合中,支持度排名前4的特征组合皆有RC_CO。其中(RC_CO2、RC_CO)的组合支持度为44.7%,为所有组合中的最高。这些结果表明RC_CO对于道路高排放源识别相当重要,且与RC_CO2搭配最佳。3个特征的组合出现频率最高的4个组合分别为(RC_CO2、RC_CO)与ACC、Speed和Length的组合,以及RC_CO、ACC和Speed的组合。4个特征的组合出现频率最高的4个分别为(RC_CO2、RC_CO、ACC)与Speed、OpacityPara和RC_NO的组合,以及(RC_CO、RC_CO2、Speed)和OpacityPara的组合。结合未展示的关联规则,发现被选择的分类器多数以(RC_CO2、RC_CO)与其他特征的组合模式。RF⁃RFELMBagging呈现以固定特征组合为核心,再与其他多种特征结合构建分类器的形式,这种形式的集成或许是其表现优良性能的原因。
3 "结 "论
机动车尾气遥测数据包含污染物浓度、车辆属性和气象环境等信息,然而无关的数据特征会影响道路高排放源的识别精度。为此,本文提出一种基于特征采样引导和集成RFELM的识别模型,可以在无先验知识的前提下,探究重要特征及其组合对实验结果的影响。实验结果表明,本文算法在提高道路高排放源的识别精度的同时,具有良好的抗噪能力。
注:本文通讯作者为李泽瑞。
参考文献
[1] LI W, LU C, DING Y. A systematic simulating assessment within reach greenhouse gas target by reducing PM2.5 concen⁃trations in China [J]. Polish journal of environmental studies, 2017, 26(2): 683⁃698.
[2] 许镇义,王仁军,张聪,等.基于深度特征聚类的高排放移动污染源自动识别[J].交通运输系统工程与信息,2021,21(6):298⁃309.
[3] 曾君,郭华芳,胡跃明.基于遥感监测的PKGV⁃ANN高排污车辆鉴别模型研究[C]//第二十七届中国控制会议论文集.北京:北京航空航天大学出版社,2008:1065⁃1069.
[4] GUO H F, ZENG J, HU Y M. Neural network modeling of vehicle gross emitter prediction based on remote sensing data [C]// 2006 IEEE International Conference on Networking, Sensing and Control. Ft. Lauderdale, FL: IEEE, 2006: 943⁃946.
[5] WANG R J, XIA X S, XU Z Y. Identification of high emission mobile sources based on self⁃supervised representation network [C]// Asian Simulation Conference. Singapore: Springer, 2022: 419⁃430.
[6] LI Z R, KANG Y, LÜ W J, et al. High⁃emitter identification model establishment using weighted extreme learning machine and active sampling [J]. Neurocomputing, 2021, 441: 79⁃91.
[7] KANG Y, LI Z R, LÜ W J, et al. High⁃emitting vehicle identification by on⁃road emission remote sensing with scarce positive labels [J]. Atmospheric environment, 2021, 244: 117877.
[8] 李丽敏,温宗周,宋玉琴.优化K均值聚类在冗余特征剔除中的应用研究[J].计算机与数字工程,2019,47(11):2836⁃2840.
[9] HUANG G B, ZHU Q Y, SIEW C K. Extreme learning machine: theory and applications [J]. Neurocomputing, 2006, 70(1/3): 489⁃501.
[10] LI G H, TANG Y Z, YANG H. A new hybrid prediction model of air quality index based on secondary decomposition and improved kernel extreme learning machine [J]. Chemosphere, 2022, 305: 135348.
[11] 王青宁,施均道,何旺容,等.基于BEMD和KELM的路面病害检测算法[J].现代电子技术,2023,46(9):110⁃114.
[12] RAHIMI A, RECHT B. Random features for large⁃scale ker⁃nel machines [C]// Proceedings of the 20th International Conference on Neural Information Processing Systems. Vancouver: ACM, 2007: 1177⁃1184.
[13] PLATT J. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods [J]. Advances in large margin classifiers, 1999, 10(3): 61⁃74.
[14] LOH W Y. Classification and regression trees [J]. Wiley inter⁃disciplinary reviews: data mining and knowledge discovery, 2011, 1(1): 14⁃23.
[15] BREIMAN L. Random forests [J]. Machine learning, 2001, 45: 5⁃32.
[16] HASTIE T, ROSSET S, ZHU J, et al. Multi⁃class adaboost [J]. Statistics and its interface, 2009, 2(3): 349⁃360.
[17] BORGELT C, KRUSE R. Induction of association rules: Aprio⁃ri implementation [C]// Compstat: Proceedings in Computational Statistics. Berlin: Physica⁃Verlag HD, 2002: 395⁃400.
猜你喜欢
当代陕西(2022年4期)2022-04-19 12:08:50
小猕猴学习画刊(2022年3期)2022-03-28 16:33:01
青年歌声(2020年12期)2020-12-23 06:30:00
电子制作(2019年11期)2019-07-04 00:34:40
电子测试(2018年13期)2018-09-26 03:30:00
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
现代工业经济和信息化(2016年6期)2016-05-17 05:36:13
读写算·高年级(2015年1期)2015-07-25 02:22:00
