
基于申威SIMD指令的H.264编码优化
2024-09-14 00:00:00黄朴刘世巍张昊王聪
现代电子技术 2024年6期


摘 "要: 国产化申威处理器出现较晚,其在多媒体领域中的性能还不突出,同时通用处理器中的单指令流多数据流(SIMD)因能有效提升并行处理能力而受到处理器厂商的青睐。为提高国产化自主平台申威架构的多媒体处理能力,结合申威架构Core3B体系的SIMD指令系统,提出一种基于申威架构的SIMD指令集H.264编码优化方法。结合申威处理器的并行结构特点,利用申威适配的Perf、Top指令等系统性能分析工具,采集两种主流视频分辨率下与编码性能强相关的高频热点函数,详细分析其程序并行化可行性,采用手工嵌入申威SIMD和访存扩展等汇编指令进行细粒度优化。实验结果表明,该方法在申威架构下的H.264平均编码性能提升了约30%。相应工作成果已推送到申威社区,增强了基于申威处理器的国产计算机在桌面多媒体应用领域的工作体验。
关键词: 单指令流多数据流; H.264标准; 申威处理器; 热点函数; 程序并行化; 细粒度
中图分类号: TN911⁃34; TP3 " " " " " " " " " " " 文献标识码: A " " " " " " " " " " 文章编号: 1004⁃373X(2024)06⁃0049⁃06
H.264 encoding optimization based on SW SIMD instruction
HUANG Pu, LIU Shiwei, ZHANG Hao, WANG Cong
(CETC Suntai Information Technology Co., Ltd., Wuxi 214000, China)
Abstract: Domestic Shenwei processors emerged relatively late, and their performance in the multimedia field is not yet outstanding. At the same time, single instruction multiple data (SIMD) in general⁃purpose processors are favored by processor manufacturers for effectively improving parallel processing capabilities. In order to improve the multimedia processing capability of the domestic independent platform Shenwei architecture, a SIMD instruction set H.264 encoding optimization method based on the Shenwei architecture is proposed by combining with the SIMD instruction system of the Core3B system of the Shenwei architecture. Based on the parallel structure characteristics of the Shenwei processor, high⁃frequency hotspot functions strongly related to encoding performance under two mainstream video resolutions are collected by means of system performance analysis tools such as Perf and Top instructions adapted by Shenwei. The experimental results show that this method can improve the average encoding performance of H.264 under the Shenwei architecture by about 30%, and the corresponding work results have been pushed to the Shenwei community, enhancing the work experience of domestic computers based on Shenwei processors in the field of desktop multimedia applications.
Keywords: SIMD; H.264 standard; Shenwei processor; hotspot function; program parallelization; fine grained
0 "引 "言
单指令流多数据流(Single Instruction Multiple Data, SIMD)是计算机处理器中的一种指令集架构,主要用于执行并行计算[1]。为提升CPU的图形图像数据处理能力,SIMD架构被广泛应用于各种类型的计算机处理器中,包括常见的桌面和移动设备处理器[2⁃3]。
申威是我国自主设计、具有完全自主知识产权的64位字长Load/Store型RISC架构多核处理器[4]。经过多年发展,申威形成了Core3B核心处理器指令系统,包括基本指令系统和SIMD扩展指令系统。所有指令均采用定长的32位格式,支持32位单精度和64位双精度浮点运算,支持256位单指令流多数据流(SIMD)的短向量运算,通过指令集适配优化,可以大幅度提升系统性能。
尽管H.265已发布多年,但H.264仍是目前市场应用最广泛的视频编解码标准[5]。对该编解码算法的结构并行性研究,主要集中在X86和ARM平台上[6⁃7],而在国产化CPU平台上的相关研究还不多见[2],大部分为针对解码器或滤波模块的优化工作。文献[8]介绍了基于开源编码器汇编优化帧内预测的率失真代价计算过程。文献[9]设计了一种基于4×4基本块复用的18路预测模式并行的高吞吐量全流水线硬件架构。文献[10]完成了视差估计算法的并行映射。文献[11]设计了一种新的帧内率失真优化预测模式的并行流水线硬件架构。
本文针对申威威焱831平台特点,基于Core3B SIMD指令优化了H.264视频编码器的处理效率,工作成果已推送到申威开源社区,为加快国产申威计算机的图形化应用发挥了积极作用。
1 "申威SIMD技术
目前,程序向量化通常由两种途径来实现:其一是利用编译器自身的功能实现程序的自动向量化,即编译器经过对程序的依赖分析、对齐分析等自动把标量代码转变成相应的向量化指令,从而实现程序的并行计算;其二是手工向量化,开发人员利用SIMD程序接口或使用内嵌汇编的方法,通过SIMD扩展的体系结构和指令集,对串行程序重新进行向量化程序的编写,在一定程度上省去编译器进行向量化分析查找后端指令等工作,并且对性能提升有明显效果。本次研究主要基于威焱831处理器,使用手工嵌入式汇编的方式将普通程序替换为申威SIMD指令来提升多媒体程序性能。
1.1 "申威SIMD概述
申威处理器提供了200多条指令来实现 SIMD的功能,支持浮点双256位SIMD流水线和整数单256位SIMD流水线。
1.2 "数据类型、寄存器与指令扩展
C3B核心扩展指令系统设置有32个256位向量寄存器,与浮点寄存器文件共用地址,其低64位即是浮点寄存器;向量寄存器与浮点寄存器在硬件实现上不同,但是在汇编代码中的表示格式是相同的。此外所有寄存器均以字符$开头,所以在汇编代码中向量寄存器和浮点寄存器均以$f0~$f31表示。
C3B核心支持短向量数据类型,包括长度为8的字整数向量(8×32位)、长度为4的单精度浮点向量(4×32位)与双精度浮点向量(4×64位),还有限支持长度为32的字节整数向量(32×8位)、长度为16的半字整数向量(16×16位)、长度为4的长字整数向量(4×64位)以及256位的8倍字整数数据。
C3B的扩展指令系统较为全面,在多媒体优化中经常用到的指令包括加法减法指令、可重构逻辑运算指令、位移指令、条件判断选择指令以及装入和存储指令等。
1.3 "向量化限制
理论上来说,对于完全SIMD向量化的程序,32×8 的向量运算性能可以达到标量的8倍,64×4的向量运算性能可以达到标量的4倍。但是,程序向量化通常存在以下限制,因此很难做到完全SIMD向量化。
首先是硬件限制:向量化受限于硬件的限制。在 SIMD扩展中,向量化访存操作必须是地址连续的,且要求32字节对界。因此,虽然有些循环是可向量化的,但具体针对威焱831体系结构,需要进行程序变换后才能向量化。
1) 循环结构的限制:循环必须是只有一个入口和一个出口时才能被向量化。
2) 更有效的使用Cache:高效地使用各级Cache对于性能的提高是极为重要的,一级Cache中访问数据的速度比主存储器中访问数据快数十倍。为了更好地使用Cache,程序需要尽量使用同一个Cache行的所有数据而不是各不同Cache行的部分数据,而且程序最好能在数据被替换出Cache以前尽量多地重用这些数据。当然,为了从SIMD部件中获得性能的提升,也要求程序最好访问连续的内存区域,这一点来讲,Cache与SIMD 部件对程序的要求是一样的。
3) 对界问题:大部分情况下,申威架构下使用扩展存储与装入指令进行变量映射的时候,需要保证标准类型变量为32字节对界。若进行了不对界访存,程序运行时,系统需要不断处理该访存引起的异常,这将极大拖慢程序与系统的运行速度。数据Cache中跨32字节的不对界访存如图1所示。
上述三个问题的处理,1)关系到能否实施向量化,2)、3)则是向量化后能否发挥预期性能的关键。
2 "FFmpeg的H.264编码优化
2.1 "H.264视频编码标准
H.264(AVC)视频编码标准作为目前应用最广的标准意义非凡,其既能带来较高的压缩率,又能保证编码质量,在安防、直播等视频领域都有很广泛的应用。
从编码途径上分类,视频编码可分为硬件编码和软件编码。硬件编码依靠专门的解码芯片,编码效率高;软件编码则可以支持不同的视频编解码标准,系统兼容性好,当然软件编码对CPU的性能要求也较高。目前基于H.264标准的媒体应用最广泛,因此从实用性角度看,优化H.264的软件编码效率,性价比最高。
2.2 "H.264编码器优化实现
FFmpeg是一套完善的开源的音视频处理软件框架[12],编译时可集成x264库。在申威处理器上,其H.264编码流程由通用分支基于高级语言实现,虽然具有格式兼容性好和算法升级灵活的优势,但单纯依靠CPU性能,编码效率较低。
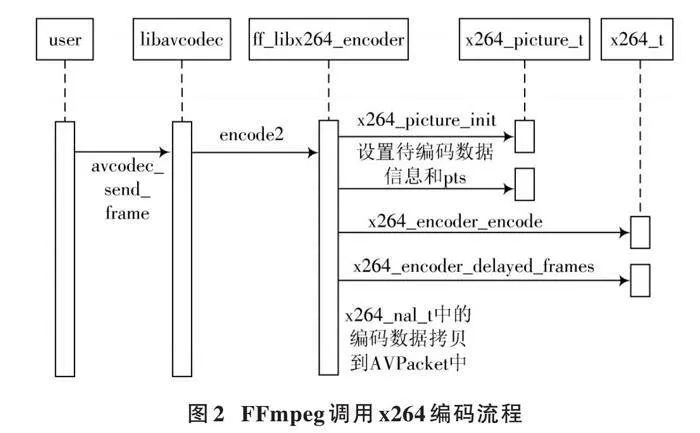
FFmpeg调用x264的流程如图2所示。图中,用户传入命令参数后,解析指令、进行查找编码器等操作,由avcodec_open2打开编码器接口进入编解码器部分,随后初始化x264编码器并进行相关配置;其次是编码阶段,由avcodec_alloc_frame()函数为编码帧分配内存,av_read_frame()函数从码流中读取帧数据,判断帧类型后调用avcodec_encode_video()函数编码;最后是收尾阶段,释放数据内存、编码器和关闭输入文件。
2.2.1 "性能瓶颈分析
x264的编码运算主要集中在x264_encoder_encode()函数,可细分成: 帧间和帧内预测、变换与量化、滤波、熵编码四部分。H.264码流的基本单位是NALU(码流单元),分为多种类型,比如:图像数据分片(Slice)、增强信息(SEI)、序列参数集(SPS)、图像参数集(PPS)。一个Slice分片通常由多个宏块(MB)组成,宏块是编码运算处理的基本单位。
1) 帧间和帧内预测:帧间预测指利用视频时间域相关性,使用邻近已编码图像像素预测当前图像的像素,以达到有效去除视频时间域冗余的目的。由于视频序列通常包括较强的时间域相关性,因此预测残差值接近于0。将残差信号作为后续模块的输入进行变换、量化、扫描及熵编码,可实现对视频信号的高效压缩,核心函数是x264_mb_analyse_inter_*()。
帧内预测则是利用图像内空间域相关性,使用已编码像素预测图像邻近像素,以达到有效去除图像空间域冗余的目的,其核心函数是x264_mb_analyse_intra()。
2) 变换与量化:变换编码将图像时域信号变换成频域信号,在频域中图像信号能量大部分集中在低频区域,相对时域信号,码率有较大的下降。H.264对图像或预测残差采用4×4整数离散余弦(DCT)变换技术。
量化过程就是根据图像的动态范围大小确定量化参数,既保留图像必要的细节,又可以减少码流。在图像编码中,变换编码和量化从原理上讲是两个独立的过程;但在H.264中,将两个过程中的乘法合二为一,并进一步采用整数运算,减少编解码的运算量,提高图像压缩的实时性,这些措施对峰值信噪比(PSNR)的影响很小,一般低于0.02 dB,可不计。
宏块编码函数x264_macroblock_encode是完成变换与量化的主要函数。
3) 滤波:H.264视频编码标准中,在编解码器反变换量化后,图像会出现方块效应,尽管H.264采用较小的4×4变换尺寸,可以降低这种不连续现象,但仍需要一个去方块滤波器,以最大程度提高编码性能。在x264中,x264_slice_write()函数中调用x264_fdec_filter_row()的源代码,x264_fdec_filter_row()对应着x264中的滤波模块。
4) 熵编码:熵编码函数x264_macroblock_write_cabac()或x264_macroblock_write_cavlc()读取码流数据,进行CABAC或CAVLC熵编码。
在申威平台上,通过性能分析发现,编码过程绝大多数CPU性能消耗在帧内预测、运动补偿、DCT变换、滤波等过程运算上。另外,在视频输出方面,大量的数据拷贝操作同样消耗了不少的CPU时间。
表1统计了CPU占比的热点函数,并删掉了其中不满足向量化限制性条件的内容。
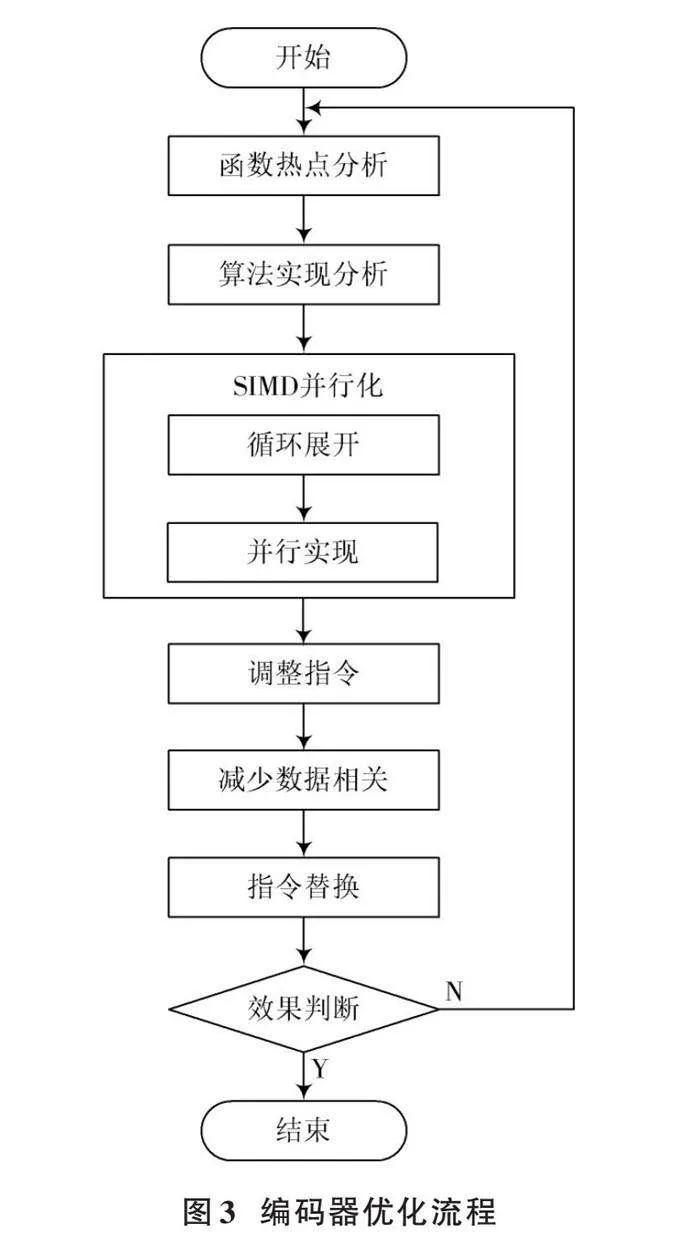
针对上述分析,在申威平台上进行编码器优化的流程如图3所示。首先,使用性能分析工具perf记录编码全程的高频热点函数;其次,逐项分析热点函数,在满足向量化限制条件的基础上研究并行化方法;然后采用SIMD指令以嵌入式汇编手段重构热点函数,包括循环展开、数据分组打包、并行运算等步骤;最后结合申威流水线特点,考虑指令延迟及循环间隔等因素,进一步调整指令流,减少因数据相关而引入的不必要延迟,使用更高效的指令进行替换。如果性能结果不满意,则继续查找新的优化点,重复上述过程。
2.2.2 "优化实现
1) SIMD优化。利用微处理器的并行部件,SIMD技术通过一条指令对一组数据进行相同的操作,从而完成之前需要多条指令才能完成的处理任务。以方块滤波函数x264_pixel_sad_16×16为例,其通用分支代码实现和采用SIMD扩展指令将内层循环进行并行优化后的代码如下:
//C代码节选
for( int y = 0; y lt; ly; y++ )
{
for( int x = 0; x lt; lx; x++ )
{
i_sum+=abs(pix1[x]⁃pix2[x]);
}}
//并行化改造
for(int y = 0; y lt; ly; y++) {
for(int i = 0,x = 0;i lt; idx ; i++,x+=8){
_asm_ _volatile_(
\"VLDD $f2,0(%0)\n\t\"
\"VLDD $f3,0(%1)\n\t\"
\"VSUBW $f3,$f2,$f4\n\t\"
\"VSUBW $f2,$f3,$f5\n\t\"
\"VSELLTW $f4,$f5,$f4,$f6\n\t\"
\"VSTD $f6,0(%2)\n\t\"
:
:\"r\"(amp;v_pix1[x]),\"r\"(amp;v_pix2[x]),\"r\"(amp;v_result)
:);}}
其中v_pix1、v_pix2为源代码中像素数据pix1及pix2转换并进行对齐操作的向量数组。使用VLDD指令加载到向量寄存器$f2、$f3后,使用VSUBW指令进行v_pix1-v_pix2、vpix2-v_pix1减法操作。将二者的差值分别存储到$f4、$f5,通过指令VSELLTW判断$f4向量中每个元素的值,如果小于0则选取$f5中相应元素的值;否则,将$f4相应元素的值存储至$f6。最终使用VSTD指令将结果$f6储存至对齐数组v_result中,该数组的各元素之和即为源代码中的i_sum。内层循环一次可操作8个数据,整体来看循环次数减少为原来的[18],有效提升了性能。
又如子函数x264_clip_pixel()被2的整数倍次调用,改造时需先展开再进行并行化改造,同时其运算完全由位运算、加减法及条件判断组成,是比较理想的可改写函数。其代码如下:
//简化C代码
for( int y = 0; y lt; i_h; y++, dst += i_dst, src += i_src)
for( int x = 0; x lt; i_w; x++ )
dst[x] = x264_clip_pixel(x);
// x264_clip_pixel()
x264_clip_pixel(x){
return ((xamp;~A)?(⁃x)gt;gt;31amp;A;x;
}
其中x = src[x]*A + B;
for( y = 0; y lt; i_height; y++, dst += i_dst_stride, src += i_src_stride ){
for( x = 0; x lt; j; x++ ){
for( i = 0; i lt; 8; i++){
tmp_res[i] = src[i+off] * scale;}
_asm_ _volatile_(
\"VLDD $f10,0(%0)\n\t\"
\"VLDD $f11,0(%1)\n\t\"
\"VADDW $f10,$f11,$f12\n\t\"
\"VSTD $f12,0(%2)\n\t\"
:
:\"r\"(amp;tmp_res),\"r\"(amp;tmp_offset),\"r\"(amp;tmp_dst)
:);
_asm_ _volatile_(
\"VLDD $f10,0(%0)\n\t\" " " " " " " " " " " " " " " " " " "//tmp_dst
\"VLDD $f11,0(%1)\n\t\" " " " " " " " " " " " " " " "//PIXEL_MAX
\"VLDD $f12,0(%2)\n\t\" " " " " " " " " " " " " " " " "//tmp_const0
\"VADDW $f11,1,$f13\n\t\" " " " " " " " " " " " " " "//tmp_max+1
\"VSUBW $f12,$f13,$f13\n\t\" " //⁃(tmp_max+1)=~PIXEL_MAX
\"VLOG08 $f12,$f10,$f13,$f14\n\t\" " //tmp_dstamp;~PIXEL_MAX
\"VSUBW $f12,$f10,$f15\n\t\" " " " " " " " " " " " " " "//⁃tmp_dst
\"VSRAW $f15,31,$f15\n\t\" " " " " " " " " " " " " " " //gt;gt;31算术
\"VLOG08 $f12,$f15,$f11,$f15\n\t\" " " " " " " " " " " " " " " "//amp;
\"VSELEQW $f14,$f10,$f15,$f16\n\t\" " " " " " " " " " " " " " "//?
\"VSTD $f16,0(%3)\n\t\" " " " " " " " " " " " " " " " " " " " " " " //
:
:\"r\"(amp;tmp_dst),\"r\"(amp;tmp_max),\"r\"(amp;tmp_const0),\"r\" (amp;tmp_
return)
:);
首先改造最内层数据变量x,由于缺少乘法指令,因此src[x]*A保留,将其8次循环的值赋给对齐向量数组tmp_res;然后B值赋给向量tmp_offset,通过指令VADDW相加存储到tmp_dst,即完成变量x的向量化;其次改造x264_clip_pixel(x):x向量值tmp_dst加载到$f10,常量A对齐转换为tmp_max后加载$f11,0对齐转换为tmp_const0加载到$f12;由于缺少向量取反指令, tmp_max首先加1存储至$f13,随后通过VSUBW进行tmp_const0⁃tmp_max间接实现取反操作;最后通过可重构指令VLOG08实现tmp_dstamp;~PIXEL_MAX的逻辑与操作,其中数据8通过与操作的真值表求出,剩余部分可查看注释释义。
2) 对界问题的处理。申威架构中,一般情况下可采用两种方式来处理对界问题:一是采用SIMD整理指令对数组b进行拼接;二是使用不对界访存接口直接处理。理论上,方法2比方法1性能要好。但实际使用中,不对界仿存指令依旧会带来不可接受的巨大开销。因此申请许多新内存空间,并利用_attribute_((aligned(n)))强制对界,配合内存拷贝优化方式来初始化能有效提升性能。
3) 内存拷贝优化。帧拷贝大量使用memcpy()函数。该部分通过SW平台下优化的mem库直接链接使用。
上述三种优化手段里面,SIMD向量优化主要集中在运动补偿和去块滤波方面,效果明显;而帧拷贝优化属于通用优化方法,在编码的各个阶段都可以获益,尤其是在编码后的视频输出阶段。
3 "实 "验
3.1 "实验平台
实验的硬件平台采用威焱831台式计算机。威焱831为64位字长的国产高性能8核通用处理器,该处理器集成了8个64位RISC结构的申威处理器核心,采用Core3B核心指令系统,主频2.5 GHz,配置16 GB DDR3内存,搭载UOS 20操作系统,采用Linux 4.19⁃sw内核。视频编码器x264版本为0.164.x,测试视频片段为h264格式视频文件通过FFmpeg软件解码出来的YUV文件,包括1 080P、4K两种主流分辨率。
3.2 "实验数据
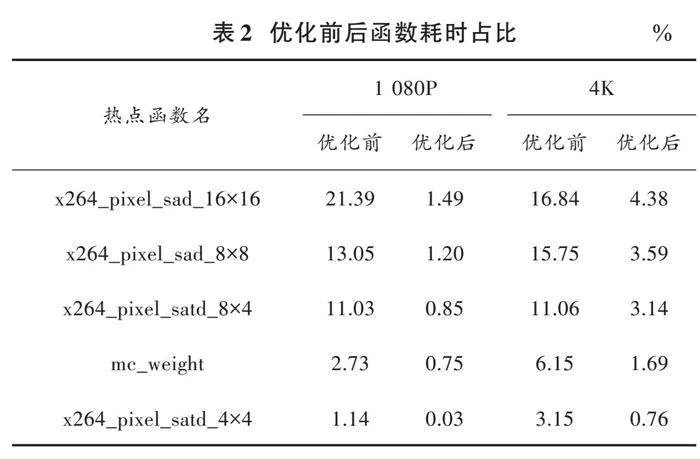
表2统计了上述主要耗时函数在两种分辨率的YUV文件编码H.264格式视频过程中的CPU耗时占比,以10亿个CPU周期(G Cycles)为单位。从表2可以看出,经过SIMD向量化优化后,去块效应滤波模块和运动补偿模块计算效率明显改善,结合表1可发现性能改善主要集中在去块效应滤波模块。SIMD向量化充分利用了各种系统资源和程序的计算并行性特征,编码过程中的计算效率明显提升。在保证了帧率和图像质量的前提下,各主要热点函数经过SIMD优化后,在整个编码过程中的耗时占比大幅下降。其中,在1 080P分辨率下耗时均下降到2%以下,相对于4K分辨率的编码情景,改善效果感性上更为显著。
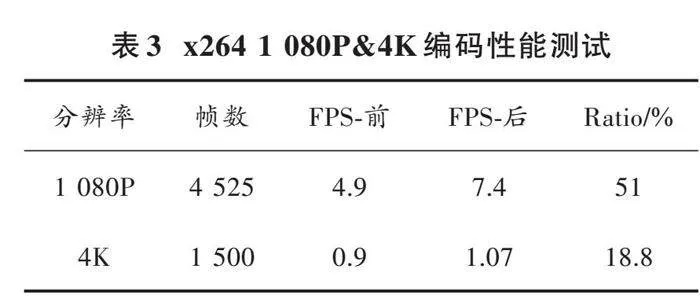
表3统计了优化前后两种分辨率视频的整体编码性能,主要以编码时的FPS作为性能比较基准单位。
从表3可以看出:与表2占比耗时提升推测相对应,1 080P分辨率的编码性能效果提升更为显著,整体编码性能由4.9提升到7.4,平均提升幅度达到50%以上;4K分辨率提升效果则达到近20%,不过CPU占用率基本达到饱和。
4 "结 "语
本文对申威处理器上使用FFmpeg编码H.264标准视频的性能瓶颈进行了较详细的分析,针对其中比较耗时的操作,提出了在申威架构下适用SIMD进行优化的具体方法。各项数据表明,在保证图像视频质量下,编码器在主流分辨率下的性能提升了15%以上,平均性能提升了30%以上。这种基于申威SIMD技术的优化方法充分利用了总线、数据通道资源,并且没有改变处理算法的基本结构,在基于软件编码的国产处理器多媒体领域中有着广泛应用。
参考文献
[1] 刘浩浩.面向SIMD超长向量加速部件的向量化方法研究[D].郑州:中原工学院,2022.
[2] 阳飞.基于龙芯2K1000B的H.264视频解码系统软件适配与优化[D].南京:东南大学,2020.
[3] 裴航.基于申威421处理器的视频解码SIMD优化技术研究[D].郑州:中原工学院,2021.
[4] 张振东,王彤,刘鹏.面向申威众核处理器的规则处理优化技术[J/OL].计算机研究与发展:1⁃19[2023⁃09⁃13]. http://kns.cnki.net/kcms/detail/11.1777.TP.20230720.0940.004.html.
[5] 冯德邦.支持超高清的H.264熵解码器的设计与验证[D].哈尔滨:哈尔滨工业大学,2022.
[6] 谷一鑫.面向ARM架构的图像高性能计算库研究与移植优化[D].西安:西安电子科技大学,2022.
[7] 马浩.基于Tilera多核处理器的HEVC解码主要模块并行处理方案设计与实现[D].南京:南京邮电大学,2021.
[8] 佘成龙.“魂芯”DSP H.265帧内预测实现及预测模式并行化设计[D].合肥:合肥工业大学,2019.
[9] 熊启金,丁永强,林志坚.高效视频编码帧内预测算法优化与硬件架构设计[J].无线电通信技术,2023,49(5):953⁃959.
[10] 蒋林,冯茹.基于视频阵列处理器的3D⁃HEVC视差估计算法并行设计与实现[J].计算机应用与软件,2023,40(7):260⁃265.
[11] 林志坚,丁永强,杨秀芝,等.HEVC帧内率失真优化预测模式的并行流水线硬件设计[J].华南理工大学学报(自然科学版),2023,51(5):95⁃103.
[12] FFmpeg documentation. FFmpeg source code [EB/OL]. [2022⁃04⁃30]. http://www.ffmpeg.org/download.html#get⁃sources/.
[13] 屠要峰,陈河堆.面向GoldenX软硬协同优化的异构加速列式存储引擎研究[J].计算机学报,2022(1):207⁃223.
猜你喜欢
科普童话·神秘大侦探(2023年1期)2023-05-30 12:48:10
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09 06:12:12
汉字汉语研究(2020年2期)2020-08-13 07:52:48
电子制作(2019年22期)2020-01-14 03:16:24
测控技术(2018年5期)2018-12-09 09:04:26
疯狂英语·新读写(2018年3期)2018-11-29 22:37:11
电子测试(2018年18期)2018-11-14 02:30:34
电子设计工程(2015年12期)2015-02-27 12:06:20
汽车零部件(2014年1期)2014-09-21 11:41:11
小青蛙报(2014年1期)2014-03-21 21:29:39
