
基于双向Transformer的降水临近预报模型
2024-08-15 00:00潘龙吴锡
计算机应用研究 2024年8期










摘 要:精准的降水临近预报对日常生活至关重要,但现行预报模型的准确度有待进一步提升。为此,提出一种新的预报模型BTPN。该模型引入双向Transformer,从时空序列的正逆方向提取特征,捕获关键信息,减少时空特征丢失;使用卷积Transformer模块结合卷积的局部编码和Transformer的全局编码特性,强化时空信息提取和关联性,缓解时空长时序信息丢失问题;结合细节提取模块,有助于减少局部细节的损失,并缓解高值区域消散问题。在HKO-7数据集上的评估显示,BTPN模型在MAE、SSIM及CSI指标上超越了其他先进模型,并在大面积降水和台风极端天气情境中显示出优异的预测能力。实验表明BTPN模型具备更高的预报精确性,具备较好的应用前景。
关键词:降水临近预报; 时空序列; 双向Transformer; 卷积
中图分类号:TP183;P457.6 文献标志码:A
文章编号:1001-3695(2024)08-029-2455-06
doi:10.19734/j.issn.1001-3695.2023.12.0613
Bidirectional Transformer-based precipitation nowcasting model
Pan Long, Wu Xi
(School of Computer Science, Chengdu University of Information Technology, Chengdu 610225, China)
Abstract:Accurate precipitation nowcasting is crucial for daily life, but the current forecasting models need further improvement in terms of accuracy. This paper proposed an innovative forecasting model called BTPN to address this issue. The model introduced bidirectional Transformer to extract features from both the forward and backward directions of spatiotemporal sequences, capturing key information and reducing spatiotemporal feature loss. It combined the convolutional Transformer block with the local encoding of convolution and the global encoding of Transformer to enhance spatiotemporal information extraction and correlation, alleviating the problem of long-term spatiotemporal information loss. The model also incorporated a detail extraction module to reduce the loss of local details and mitigate the issue of dissipation in high-value areas. Evaluation on the HKO-7 dataset shows that the BTPN model surpasses other advanced models in terms of MAE, SSIM, and CSI metrics, demonstrating excellent predictive capability in large-scale precipitation and extreme weather scenarios. The experiments demonstrate that the BTPN model possesses higher forecasting accuracy and promising applications.
Key words:precipitation nowcasting; spatiotemporal sequences; bidirectional Transformer; convolution
0 引言
天气预报在当代社会扮演着不可或缺的角色,对多个关键性行业提供了支撑,包括农业、航海和灾害响应等,并对日常生活及生产活动产生深远影响[1,2]。然而,实现高精度、宽范围、高解析度的实时降水预报依然是个突出挑战。在这些挑战中,尤其是短期降水预测,在气象学中占有特殊地位。这一任务的核心在于使用历史的气象数据来预测未来零至一小时的降水变化,以便有效预测并应对潜在的强对流天气事件,并确保实时气象预报的准确性。
数值天气预报(NWP)[3]是当今天气预测领域的主要技术手段。这种方法本质上是数据驱动型的,需综合考量一系列大气物理属性,包括但不限于风速、气压和温度等关键气象参数,并依托这些变量构建模型框架。NWP模型在操作过程中需对高度复杂的数学方程组进行求解,因此对计算资源的需求极其巨大,随之而来的是显著的计算成本。此外,鉴于其对大量输入数据的依赖性,该技术在处理短时间尺度预报的预测准确率尚有待提高[4]。
因现代社会对快速且准确的短期天气预报的迫切需求,数值天气预报(NWP)技术表现出了其局限性[5,6]。目前,在短期临近预报的实践中,外推法成为了主要选择。
传统的外推方法包括单质心法、互相关法和光流法[7,8]。单质心法通过识别和跟踪对流单体,提供基于单体合并和分裂的运动和演变信息,但当对流回波发生融合和分裂时预报精度会迅速下降[9]。互相关方法通过计算两个临近时刻的雷达回波之间的空间优化相关系数来建立拟合关系,有效跟踪层状云和降雨系统,但对于回波变化迅速的强对流系统,其跟踪精度明显降低[7]。当前应用较多的光流法,如ROVER(雷达回波的实时光流变分方法)[10],通过计算雷达回波图像序列中的光流场来代替雷达回波运动矢量场,进而实现临近投射,但计算过程中存在累积误差问题。
传统气象预报方法常借助最新的几幅雷达回波图像来预测未来回波的位置,无视了雷达回波中对流系统的非线性动态。这种做法就导致了对历史雷达数据的应用不充分和预测时间跨度的限制[11]两个主要局限性。
随着人工智能技术,尤其是深度学习的飞速进步,这些技术已在目标检测、图像分割、自然语言处理等多个领域得到成功应用。在气象学领域,特别是关键的降水临近预报研究领域,研究人员已经开始探索人工智能的潜力,并取得了突破性的成果[1,12,13]。
Shi等人[14]提出的卷积长短时记忆网络(ConvLSTM)在气象预报领域标志着一项重大的技术突破。与标准的全连接LSTM相比,ConvLSTM借助卷积操作有效地挖掘了空间特征,大幅提升了降水临近预报的准确性,优于传统的全连接LSTM及光流技术。继此创新之后,Shi等人[15]进一步开发了TrajGRU模型,该模型整合了时间卷积网络对时空属性的高度敏感性以及光流技术模拟云运动的能力,进一步增强了对云自然运动的模拟,从而提升了预报性能。
在此之后,Wang等人[16]开发了PredRNN模型,该模型的核心创新在于融入了时空长短时记忆网络(spatio-temporal LSTM),通过这种设计,模型可以有效地捕捉时间序列数据中的空间和时间依赖性,显著提高了对复杂天气系统动态预测的准确性。进一步地,Wang等人[17]提出了PredRNN++,利用Causal LSTM进一步提升了信息流和梯度传播的效率,同时引入了创新的梯度高速公路机制,有效提升了深度时空网络在训练阶段面临的稳定性。最终,Wang等人[18]推出了PredRNNv2,该模型不仅在PredRNN++的基础上进行了扩展,而且通过整合具备记忆解耦功能的时空记忆流,结合使用反向传播计划抽样训练与记忆解耦损失,极大地强化了模型对时间和空间多维长期依赖的捕获能力,为临近降水预报技术带来了革新性的进展。
Guen等人[19]提出的PhyDNet模型,巧妙地融合了物理学原理与前沿深度学习技术。该架构通过集成新颖的物理循环单元(PhyCell),这一单元受到数据同化技术的启发,在隐空间中施加偏微分方程(PDE)的约束以进行预测,不仅提高了模型在预测任务中的准确性和可解释性,还确保了其预测过程遵循物理定律。
在降水临近预报的研究领域,卷积神经网络(CNN)已经成为一个不可或缺的工具。CNN凭借其卓越的图像特征提取能力,通过将这些特征有效映射到标签图像上,已广泛应用于多种预测任务中。在这一系列的网络架构中,U-Net[20]作为一个经典的全卷积网络结构,因其广阔的适用性而受到科研界的高度重视[21]。例如,Han等人[22]提出的基于U-Net的降水预测模型,在预测性能上优于传统的外推方法。此外,文献[13]推出的SmaAt-UNet模型运用了深度可分离卷积[23]和卷积块注意力模块(CBAM)[24],在大幅减少参数量(仅为原始U-Net的四分之一)的同时,仍保持了接近原始U-Net的精确预测能力。Gao等人[21]提出的SimVP模型在视频预测任务中取得了卓越的成果,这一成就不仅凸显了全卷积网络在比拼RNN网络时展现出的潜力,也在时空序列预测方面实现了更优表现。继续在这一方向深入探索,Han等人[5]将SimVP模型成功迁移到短临预报的任务中,并展现了同样优异的性能。
由于降水本身具有高度非线性、随机性和复杂性,其时间变化较快、空间分布不均匀,同时还具有短期突发性和不可预见性等特点,降水临近预报精度还有较大提升空间。在降水临近预报领域,循环神经网络(RNN)模型,如PredRNN系列,在传递长时间序列信息的能力上表现出色。然而,它们在捕捉和分析空间特征方面存在局限。此外,RNN模型逐步预测的特性也限制了训练和推理效率,并且具有高计算成本[22]。相比之下,卷积神经网络(CNN)模型在空间特征提取方面具有强大的优势,计算量小且结构简单。然而,当处理时间序列数据时,CNN模型面临信息流失的问题,尤其在进行长时间序列预测时更为严重[22,25]。CNN和RNN模型都无法获取全局变化信息,这对于降水临近预报是一个瓶颈,因为局部降水受到全局降水变化的影响,而局部感受野无法准确理解和把握全局变化。在当前模型中,对于降水预报中更关心的高强降水区域的预测,仍存在高值区域易消散的情况,整体预报准确性仍有待提升[5,7]。
针对以上问题,本文提出了一种基于双向Transformer的降水临近预报模型(BTPN)。模型的主体架构采用了SimVP模型,利用空间特征和时空特征分离处理的方式,缓解一定的时空信息流失问题[21]。为了获取全局状态信息,本文设计了一种双向Transformer(bi-directional Transformer,BiT)。与传统的Transformer相比,BiT可以同时从时空序列的顺序和逆序中高效地提取特征,从而有效捕捉那些在顺向信息流中易被忽略的关键细节,并且保留更多特征信息,减轻了时空信息流失问题。与以BERT语言模型[26] 为代表的使用掩码机制(masked language model,MLM)实现深度双向Transformer不同,本文双向Transformer在注意力阶段通过双向的Q和K对时空特征进行加权,这种方法更加简单易行且适用于时空序列问题。BiT具备了Transformer[27,28] 的核心优势,即全局注意力机制,可以在整个序列范围内捕获相关信息,从而提升了模型处理长期依赖关系信息的能力,其优秀的注意力机制也能很好地关注高值区域的变化。与卷积提供的局部特征编码相结合,BiT的全局编码能力使本文设计的CT-block能够轻量高效地提取时空信息,同时其残差结构缓解了模型深层特征的损失。在模型的编码器和解码器阶段,本文引入了D-block结构,这种基于残差[29]的设计思路有效地减少了在维度转换过程中低维细节特征的丢失,缓解了高值区域消散问题。在公认的HKO-7数据集[15] 上进行的一系列对比实验中,实验结果充分证明了BTPN模型在降水临近预报任务上的卓越表现,相比其他模型展现了更高的预测准确率。
1 BTPN模型
降水临近预报任务本质是时空序列预测问题,需要同时考虑时间维度和空间维度。为了进一步提升降水临近预报准确性,设计了BTPN模型,如图1所示。该模型由encoder、translator和decoder三种结构组成,encoder用于提取历史帧的空间特征,translator用于学习时空演化与传递,decoder用于集成和预测未来帧的空间特征。这种空间特征和时空特征融合分离的结构使得CNN模型也能具备更高的时空特征传递性能[21]。
a)encoder。在编码器设计中,采取了创新的堆叠策略,将CGS与D-block模块相结合。编码器由Ns个CGS(Conv-GroupNorm-SiLU)和D-block的复合结构组成。在处理编码器输入数据时,本文将输入数据的形状从(B,T,C,H,W)改组合为(B×T,C,H,W),即将批次维度B和时间维度T合并,该策略使得模型能更集中于提取空间特征。在这一过程中,每组的CGS-D-block-CGS结构中,CGS和D-block采用步长为1的卷积,保证特征提取的精细化,而每组结构末尾的CGS则采用步长为2的卷积操作,以实现下采样。在传统模型中,过度依赖CGS模块的堆叠往往会导致空间细节信息的大量损失,而通过在CGS堆叠中穿插D-block模块的策略,既强化了深层特征的提取,同时也有效减轻了浅层细节信息的丢失,从而实现了优化模型对空间特征把控的能力,加强了对高值区域预报的准确性。
b)translator。设计采用了Nt个卷积Transformer模块(CT-block)来学习和处理时空域特征,有效缓解了CNN模型存在的时空长时序信息丢失的问题,还实现了对全局和局部信息的综合利用。输入特征的形状由(B,T,C,H,W)转换为(B,T×C,H,W),合并了时间维度T和通道维度C,使其能够同时处理时空特征的动态变化。CT-block结构内嵌了双向Transformer(BiT)机制,它的工作过程开始于一个1×1大小的卷积层,用于扩充特征的通道数。接着,采用残差连接结构[29]进行特征学习,其中首先通过一个3×3的卷积层来捕捉局部时空特征,然后使用1×1的逐点卷积(pointwise convolution)对特征通道进行线性组合并将其映射至一个更高维的空间,以此来增强特征的表达能力。BiT用于全局时空信息的学习,它允许模型捕捉和整合跨越整个输入的长范围依赖信息。最后,输入特征和BiT的输出通过一个3×3的卷积层进行合并和融合,这样不仅利用了BiT提供的全局信息,还保留了局部特征的细节,能够学习局部降水和全局降水之间的相互影响关系。
c)BiT。如图2所示,常规双向Transformer主要应用于自然语言处理(NLP)领域,以BERT语言模型[26]为代表,主要使用掩码操作实现上下文双向理解,本文的双向Transformer(BiT)是通过设计的双向多头自注意力(BMA)机制来实现双向操作,增强对动态时空数据序列的正向和逆向处理能力,具备更优的时空信息提取能力,缓解了时空信息流失的问题,其双向的注意力也可以更好地5U/3pKoaOc0uqSiFdgxaaw==捕获高值区域的变化,更适用于时空序列问题。该机制对捕获复杂的动态场景中变化迅速的特征至关重要。通过在已有的查询(Q)和键(K)向量的基础上增添它们的反向对应(和),BMA使得模型能够从数据的两个方向同步地提取关键特征,使用逆序的和从逆序特征中揪出容易遗漏的重要信息,进而增强了模型使用顺序的Q和K进行特征筛选的能力。BiT通过双向多头自我注意力单元和多层感知机(MLP)块的串联搭建而成,这些模块的协同工作用于合成和精炼时空特征,以及施行高阶非线性特征转换。每个注意力和MLP模块前采用层归一化(LN),以规范化输入,这样的预处理对提升模型的训练稳定性和加速收敛进程格外有益。BiT模型设计中缺少对空间位置的内在偏置,影响了空间特征的感知能力。汲取MobileViT[30]中数据空间重新排列的方法,强化了BiT对空间特征的感知。通过unfold操作,将标准输入维度(B,D,H,W)重新排列为(B,N,P,D),其中P=wh表示一个图像patch中的像素数,N=(HW)/P代表图像中patch的总数。在实验中,本文选择了(2,2)大小的patch。随后,fold操作使得变换后的数据能够轻松地恢复为其原始维度(B,D,H,W)。BiT操作流程如下:
z′i=BMSA(LN(zi-1))+zi-1 i=1,…,L(1)
zi=MLP(LN(z′i))+z′i i=1,…,L(2)
双向多头自注意力依赖于缩放的点积注意,对顺序查询Q、顺序键K、逆序查询、逆序键和值V进行操作:
attention(Q,K,,,V)=softmax(QKT+Tdk)V(3)
headi=attention(QWQi,KWKi,Wi,Wi,VWVi)(4)
MultiHead(Q,K,,,V)=concati(headi)WO(5)
其中:dk是关键维度;Wi和WO为权重矩阵。值得注意的是,在计算逆序控制和时需要先对特征在通道维度进行逆序操作,当完成T运算后在通道维度再次进行逆序操作,即还原为顺序结构,如图2所示,其中符号即代表通道逆序操作。
d)decoder。解码器采用Ns层TCGS+D-block+CGS复合结构的叠加策略来逐渐构建对未来帧的预测。在这个过程中,转置卷积操作扮演了上采样的角色,旨在将深层的特征空间有效恢复至与原始输入匹配的分辨率,此操作的采样步长设为2。而D-block和CGS层则通过步长为1的卷积过程细致地处理特征信息,以确保输出的细节质量。通过decoder模块的跳跃连接,可以利用浅层历史输入数据来恢复预报结果中的浅层细节。整个解码器的架构设计与编码器(encoder)形成了一种对称关系。
2 实验
2.1 HKO-7数据集
HKO-7数据集依托于香港天文台,2017年由Shi等人[15]正式提出,之后被气象预报领域研究广泛应用,推动了降水预报领域的发展。HKO-7数据集是2009—2015年的香港区域雷达回波数据。雷达CAPPI反射率图像的分辨率为480×480像素,高度为2 km,覆盖以香港为中心的512 km×512 km区域。数据是逐6 min的,因此每天有240帧数据。数雷达反射率因子可以通过pixel= 255×dBZ+1070+0.5」线性变换为像素值,并将转换后的像素值裁剪为0~255。利用Z-R关系可以将雷达反射率值转换为降雨强度值(mm/h):dBZ=10blog a+10blog R,其中R为降雨率水平,a=58.53,b=1.56。
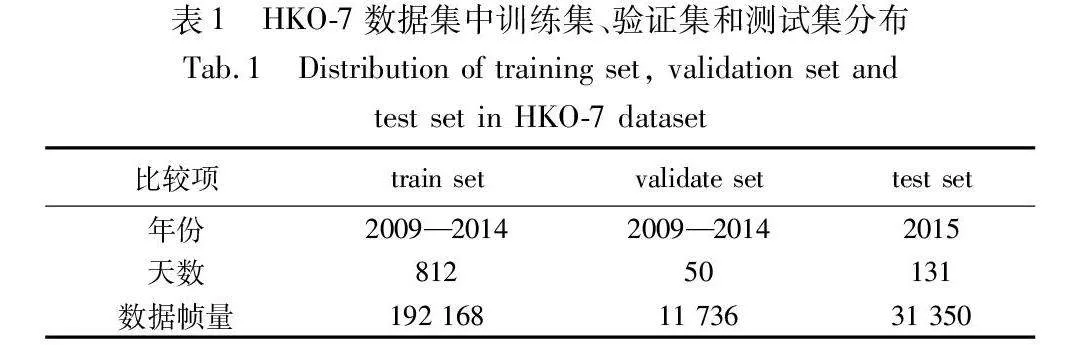
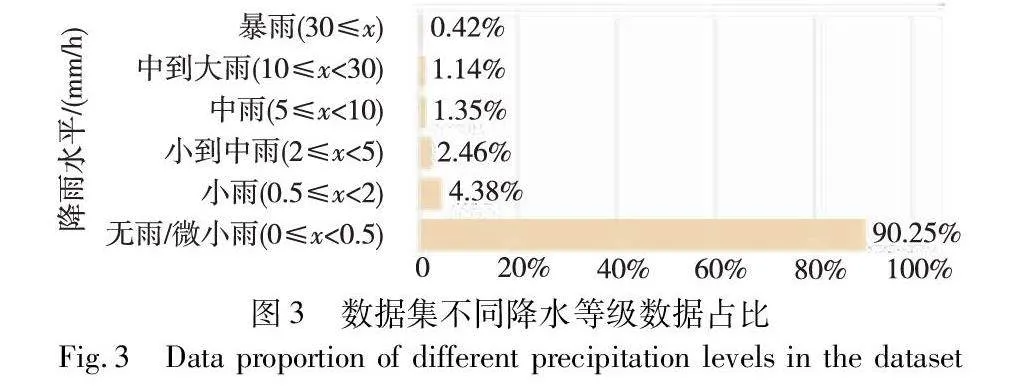
如图3所示,由于降雨事件很少发生,所以根据雨量信息选择下雨天来形成最终的数据集,如表1所示,该数据集有812天用于训练,50天用于验证,131天用于测试。本文对HKO-7数据进行了降采样,由480×480处理为112×112大小。
2.2 实验设置
如图3所示,HKO-7数据集存在数据分布不均衡的情况,Shi等人[15]提出损失函数B-MSE和B-MAE用于解决该问题。B-MSE和B-MAE分别是在常规MSE和MAE的基础上通过不同降水强度进行加权而改进的损失函数,可以提高强降水临近预报的精度。损失函数如下[15]:
loss=1N∑Nn=1∑224i=1∑224j=1ωn,i,j(xn,i,j-n,i,j)2+
1N∑Nn=1∑224i=1∑224j=1ωn,i,j|xn,i,j-n,i,j|
ω(x)=1 x<222≤x<555≤x<101010≤x<3030x≥30(6)
其中:N代表数据帧;xn,i,j代表第n帧的(i,j)位置的数值;ωn,i,j代表第n帧的(i,j)位置的权重,通过权重函数ω(x)获取。
数据预处理方式使用最大最小归一化,其公式如下:
Y=X-minmax-min(7)
其中:min为0;max为255;X为输入数据;Y为归一化后数据。
BTPN模型设置encoder和decoder模块的Ns为2;其中GroupNorm的group数量为2。translator模块的Nt设置为3,其中GroupNorm的group数量为8。BiT模块的双向自注意力设置为4头。
其他对比模型的和官方开源代码参数一致。在本文中所有模型的基础训练设置保持一致,本文使用Adam优化器[31],学习率设置为10-4,进行100 000次采样训练,batch_size设置为2,输入历史1 h数据(10帧)预测未来1 h(10帧)变化。本文使用RTX 2080显卡进行训练,12 GB显存,CPU为Intel CoreTM i7-7700K CPU,4.20 GHz,PyTorch版本为1.10.1。
2.3 实验指标
为了全面评估不同模型的性能,本文使用了MAE(平均绝对误差)、CSI(临界成功指数)和SSIM(结构相似性)三种评价指标。
a)MAE。平均绝对误差主要是可以对数值精度误差进行评估,有效地揭示了预测值和真实值在数值上的差异。MAE越小表示越接近真实值,其公式如下:
MAE=∑ni=1xi-yin(8)
其中:xi表示预测值;yi表示真实值;n表示像素数量。
b)CSI。临界成功指数同时考虑了预报中的命中、漏报和误报,能够评定不同降水等级下的准确性,是降水临近预报中常用的评价指标,其公式如下:
CSI=TPTP+FN+FP(9)
其中:TP(预测=1,真值=1)是真阳性;FN(预测=0,真值=1)是假阳性;FP(预测=1,真值=0)是假阴性。
c)SSIM。结构相似性是评定两幅图像之间的空间相似程度的指标,同时考虑图片亮度、对比与结构信息,在图像质量的衡量上更能符合人眼对图像质量的判断,其公式如下:
SSIM(x,y)=(2μxμy+c1)(2σxy+c2)(μ2x+μ2y+c1)(σ2x+σ2y+c2)(10)
对于输入图像x和y,μx和μy分别代表x和y的均值,σx和σy分别代表x和y的方差,σxy代表x和y的协方差,c1=(k1L)2和c2=(k2L)2是两个常量,k1=0.01,k2=0.03,L代表像素范围值。SSIM数值为[-1,1],越接近于1表示两幅图像越相似。
2.4 实验结果与分析
不同模型在测试集上的MAE、SSIM和CSI指标如表2所示,其中CSI指标选取了2、5、10和30 mm/h四种降水阈值,以评估模型对于从小雨到暴雨不同降水强度的预报准确度。从表2可以看出,BTPN模型在所有指标上均超越了其他模型,与较优的PredRNN-v2模型相比,MAE和SSIM分别提升了2.06%和3.11%,在2、5、10和30 mm/h阈值下的CSI指标分别提升了0.44%、1%、2.51%和7.11%。由此可以看出,BTPN模型整体上具有较高的预报精度,特别是在关注度更高的高降水量区域表现出更为显著的精度提升,这对于短临预报具有重要的意义。
平均指标并不能完全反映不同模型在不同时间维度上的预报准确度,因此本文绘制了各模型在不同预报时刻的精度趋势图,如图4所示。从图中可以直观地看出,BTPN模型在不同预报时刻同样保持着超越其他模型的精度,并维持了较低的误差累积,体现了BTPN模型在降水临近预报上的有效性和优秀性能。
为客观评估不同模型的性能,本文挑选了两种代表性的降水情景进行了详细分析:a)普遍的大面积降水事件;b)强度更为严峻的台风天气。大面积降水事件包括了一系列不同的降水强度,能够全面测试各模型在常见降水气候下的预报准确性。在极端气象事件如台风的预报中,准确性尤为关键。由于台风导致的降水变化具有较高的不可预测性,这对于预报模型来说是一个显著的挑战,极端天气预报的准确性能够有效地验证模型的综合性能表现。
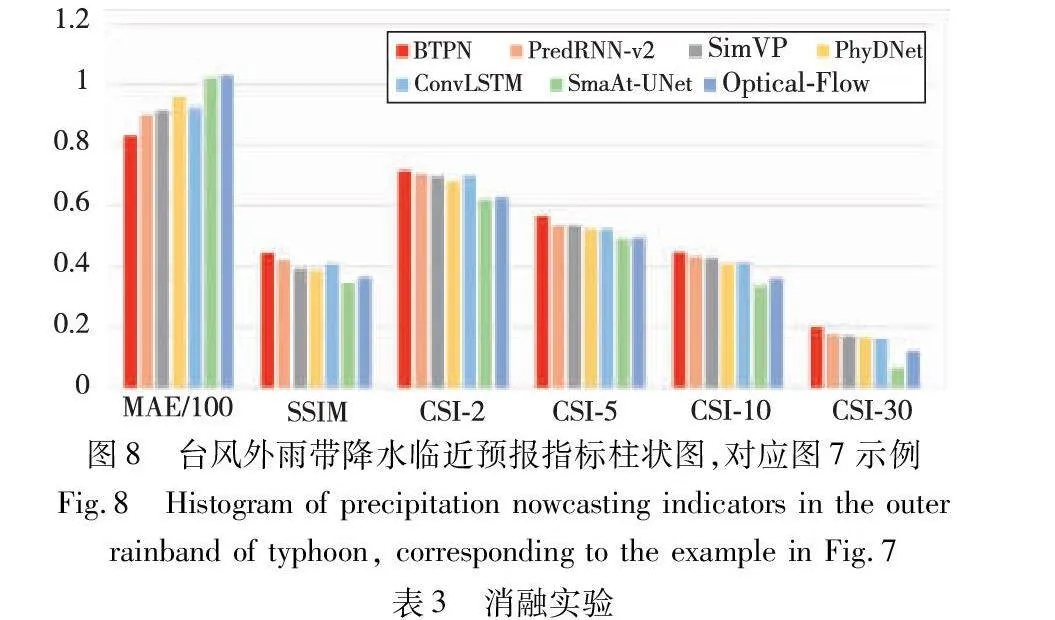
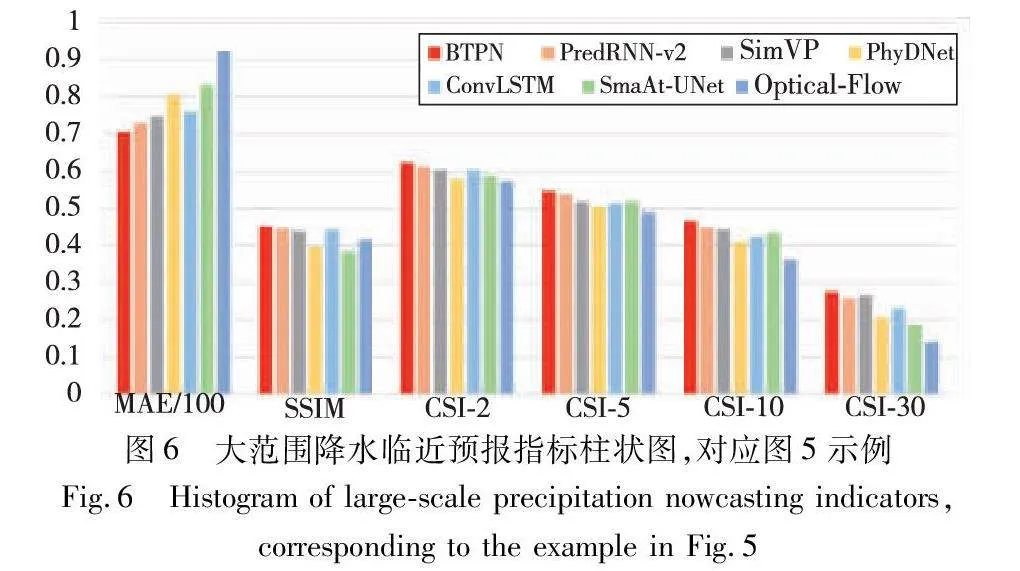
图5中矩形框标识的部分清晰地揭示了BTPN模型预报结果与实际观测的吻合程度较高。相比之下,其他模型在预测高降水率区域时显现了明显的消散现象,光流法无法预测雨区的生消变换,未能精确捕捉到实际的降水区域。图6展示的性能指标柱状图进一步印证了BTPN模型在大范围降水事件预报上的卓越准确性。
在台风条件下,BTPN模型继续展现出其优异的预测精度。图7中的矩形框清楚地表明,BTPN模型能较为确切地预测低值和高值区域的分布,展现了其优秀的时空信息传递和提取能力,而其他模型在这方面表现则不佳,产生了较多的误报问题,光流法更是出现了严重的形变现象。对图6、8中的指标图进行比较可见,在台风引起的降水中,各模型的临近降水预报准确度普遍低于普通降水事件的预报准确度,这反映出台风对降水预报准确性所造成的负面影响显著,增加了降水落区预测的不确定性。然而,即便如此,BTPN模型在各项指标上依旧保持了一定的优势,并显示出较高的稳健性。
2.5 消融实验
消融实验是评价和解析模型各构成部分作用的重要实验方法。该方法通过删减或修改模型的特定部分,研究这些变动如何影响模型的整体表现。
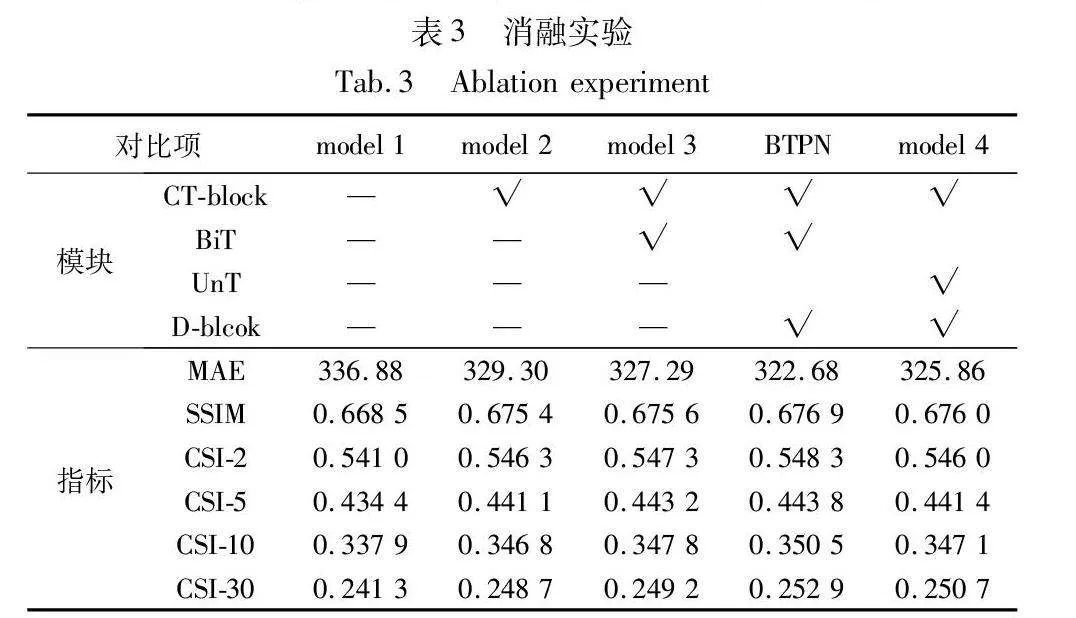
如表3所示,本文对BTPN模型进行了一系列消融实验,主要针对模型中的CT-block、BiT和D-block三个关键模块。消融实验的初始条件是基础的SimVP模型,即model 1。在model 1的基础上,将inception模块替换为内含常规Transformer的CT-block构建出model 2。实验结果表明,该变动带来了模型性能的整体提升,由此证明了CT-block的有效性。接下来,model 3是在model 2的基础上,通过采用BiT替代CT-block中的Transformer结构,模型性能再次得到提高,这验证了双向Transformer在时空序列特征提取方面的有效性。BTPN模型是在model 3的基础上加入了D-block细节模块,减少了编解码过程中可能出现的特征丢失,从而实现了性能的进一步提升。model 4是在BTPN基础上,使用单向Transformer(UnT)替换双向Transformer(BiT),UnT也就是对BiT中的逆序和使用常规顺序特征,发现精度下降,尤其是高值区域,说明单纯地增加和并未带来性能提升,因此逆序操作是有效的,模型可以从逆序特征中学习到更多的信息。
消融实验的结果清楚地表明,本文为降水临近预报专门设计的三个模块不仅具有实际效能,而且在提升模型整体性能方面发挥了关键作用。
3 结束语
本文提出了一种创新的降水临近预报模型BTPN,设计的双向Transformer结构有效地捕捉了数据在时间和空间上的关联性。与此同时,结合 CT-block,融合Transformer全局信息和卷积局部特征的优势。此外,使用D-block增强编解码过程中的特征抽取能力,并缓解细节信息的损失,从而实现了更高的预报准确度。
在HKO-7数据集上的实验结果验证了BTPN模型在降水临近预报领域的先进性。实验结果直观地展示了BTPN模型在时空信息的传递和提取方面优于其他模型,进一步提升了对降水高值区域的预报准确性。无论是在定量指标上还是定性指标上,BTPN模型都展现出较优的性能,证明了模型设计的有效性。这为降水预报问题提供了一种新的思路,对未来的研究有着一定的启示作用。未来,本文将探究多源数据融合的预报方法,通过结合温度场、风场等对降水预测有着密切关联的因子,以期进一步提高预报的精度。
参考文献:
[1]Gao Zhihan, Shi Xingjian, Wang Hao, et al. Deep learning and the weather forecasting problem: precipitation nowcasting[M]//Camps-Valls G, Tuia D, Zhu X X, et al. Deep Learning for the Earth Sciences: A Comprehensive Approach to Remote Sensing, Climate Science, and Geosciences.[S.l.]: Wiley, 2021: 218-239.
[2]罗健文, 邹茂扬, 杨昊, 等. 面向降雨预报的雷达回波预测序列外推方法[J]. 计算机应用研究, 2024, 41(4): 1138-1142. (Luo Jianwen, Zou Maoyang, Yang Hao, et al. Research on extrapolation of radar echo prediction sequence for rainfall prediction[J]. Application Research of Computers, 2024, 41(4): 1138-1142.)
[3]Bauer P, Thorpe A, Brunet G. The quiet revolution of numerical weather prediction[J]. Nature, 2015, 525(7567): 47-55.
[4]Ayzel G, Scheffer T, Heistermann M. RainNet v1.0: a convolutional neural network for radar-based precipitation nowcasting[J]. Geoscientific Model Development, 2020, 13(6): 2631-2644.
[5]Han D, Choo M, Im J, et al. Precipitation nowcasting using ground radar data and simpler yet better video prediction deep learning[J]. GIScience & Remote Sensing, 2023, 60(1): 2203363.
[6]Ko J, Lee K, Hwang H, et al. Effective training strategies for deep-learning-based precipitation nowcasting and estimation[J]. Compu-ters & Geosciences, 2022, 161: 105072.
[7]孔德璇. 基于深度学习的贵州地区分钟级临近降水预报研究[D]. 南京: 南京信息工程大学, 2023. (Kong Dexuan. Research on minute-level near-term precipitation forecast in Guizhou based on deep learning[D]. Nanjing: Nanjing University of Information Science & Technology, 2023.)
[8]吴晓锋, 唐晓文, 王元, 等. 基于单多普勒雷达的光流法改进技术[J]. 气象科学, 2020,40(4): 497-504. (Wu Xiaofeng, Tang Xiaowen, Wang Yuan, et al. Improved optical flow method based on single-Doppler radar[J]. Meteorological Science, 2020, 40(4): 497-504.)
[9]Johnson J, Mackeen P L, Witt A, et al. The storm cell identification and tracking algorithm: an enhanced WSR-88D algorithm[J]. Weather and Forecasting, 1998, 13(2): 263-276.
[10]Woo W C, Wong W K. Operational application of optical flow techniques to rainfall nowcasting[J]. Atmosphere, 2017, 8(3): 48.
[11]Gultepe I, Sharman R, Williams P D, et al. A review of high impact weather for aviation meteorology[J]. Pure and Applied Geophy-sics, 2019, 176: 1869-1921.
[12]徐成鹏, 曹勇, 张恒德, 等. U-Net模型在京津冀临近降水预报中的应用和检验评估[J]. 气象科学, 2022, 42(6): 781-792. (Xu Chengpeng, Cao Yong, Zhang Hengde, et al. Application and evaluation of U-Net model in near-term precipitation forecast in Beijing-Tianjin-Hebei region[J]. Meteorological Science, 2022, 42(6): 781-792.)
[13]Trebing K, Staczyk T, Mehrkanoon S. SmaAt-UNet: precipitation nowcasting using a small attention-UNet architecture[J]. Pattern Recognition Letters, 2021, 145: 178-186.
[14]Shi Xingjian, Chen Zhourong, Wang Hao, et al. Convolutional LSTM network: a machine learning approach for precipitation nowcasting[C]//Proc of the 28th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2015: 802-810.
[15]Shi Xingjian, Gao Zhihan, Lausen L, et al. Deep learning for precipitation nowcasting: a benchmark and a new model[C]//Proc of the 31st Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 5622-5632.
[16]Wang Yunbo, Long Mingsheng, Wang Jianmin, et al. PredRNN: recurrent neural networks for predictive learning using spatiotemporal LSTMs[C]//Proc of the 31st Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017, 879-888.
[17]Wang Yunbo, Gao Zhifeng, Long Mingsheng, et al. PredRNN++: towards a resolution of the deep-in-time dilemma in spatiotemporal predictive learning[C]//Proc of the 35th International Conference on Machine Learning.[S.l.]: PMLR, 2018: 5123-5132.
[18]Wang Yunbo, Wu Haixu, Zhang Jianjin, et al. PredRNN: a recurrent neural network for spatiotemporal predictive learning[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2023, 45(2): 2208-2225.
[19]Guen V L, Thome N. Disentangling physical dynamics from unknown factors for unsupervised video prediction[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2020: 11474-11484.
[20]Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation[M]//Navab N, Hornegger J, Wells W, et al. Medical Image Computing and Computer-Assisted Intervention. Berlin: Springer, 2015: 234-241.
[21]Gao Zhangyang, Tan Cheng, Wu Lirong, et al. SimVP: simpler yet better video prediction[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 3160-3170.
[22]Han Lei, Liang He, Chen Haonan, et al. Convective precipitation nowcasting using U-Net model[J]. IEEE Trans on Geoscience and Remote Sensing, 2022, 60: 1-8.
[23]Chollet F. Xception: deep learning with depthwise separable convolutions[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2017: 1800-1807.
[24]Woo S, Park J, Lee J Y, et al. CBAM: convolutional block attention module[C]//Proc of European Conference on Computer Vision. Berlin: Springer, 2018: 3-19.
[25]Reichstein M, Camps-Valls G, Stevens B, et al. Deep learning and process understanding for data-driven earth system science[J]. Nature, 2019, 566(7743): 195-204.
[26]Devlin J, Chang M W, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[EB/OL]. (2019-05-24). https://arxiv.org/abs/1810.04805.
[27]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[EB/OL]. (2023-08-02). https://arxiv.org/abs/1706.03762.
[28]Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[EB/OL]. (2021-06-03). https://arxiv.org/abs/2010.11929.
[29]He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep residual learning for image recognition[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2016: 770-778.
[30]Mehta S, Rastegari M. MobileViT: light-weight, general-purpose, and mobile-friendly vision Transformer[EB/OL]. (2021-10-05). https://arxiv.org/abs/2110.02178.
[31]Kingma D P, Ba J. Adam: a method for stochastic optimization[EB/OL]. (2017-01-30). https://arxiv.org/abs/1412.6980.
