
基于视觉的相机位姿估计方法综述
2024-08-15 00:00王静王一博郭铖郭苹叶星邢淑军
计算机应用研究 2024年8期




摘 要:相机位姿估计是通过估计相机的位置坐标和环绕三个坐标轴的角度偏转,来描述其相对于给定场景的方向和位置,是自动驾驶、机器人技术等任务的重要组成部分。为帮助研究人员在相机位姿估计领域的研究,对相机位姿估计的研究现状和最新进展进行梳理。首先介绍了相机位姿估计的基本原理、评价指标和相关数据集;然后从场景关系搭建和相机姿态解算两个关键技术出发,对两阶段模型结构方法和单通道模型结构方法进行阐述总结,分别从核心算法和利用的场景信息不同上进行分类归纳分析,并对室内室外公开数据集上的表现作对比;最后阐述了该领域当前面对的挑战和未来的发展趋势。
关键词:相机位姿估计; 深度学习; 场景关系搭建; 姿态解算
中图分类号:TP391 文献标志码:A
文章编号:1001-3695(2024)08-001-2241-11
doi:10.19734/j.issn.1001-3695.2023.11.0552
Overview of vision-based camera pose estimation methods
Wang Jing, Wang Yibo, Guo Cheng, Guo Ping, Ye Xing, Xing Shujun
(College of Communication & Information Technology, Xi’an University of Science & Technology, Xi’an 710054, China)
Abstract:Camera pose estimation plays a crucial role in tasks such as autonomous driving and robotics, elucidating the direction and position of the camera in relation to a given scene through the estimation of its positional coordinates and angular deviations around the three coordinate axes. To facilitate the understanding of researchers in the realm of camera pose estimation, this paper comprehensively reviewed the current research status and latest progress in this field will. Firstly,it introduced the fundamental principles, evaluation indicators, and pertinent datasets associated with camera pose estimation. Subsequently, the review elaborated and summarized the two-stage model structure method and single-channel model structure method from the two key technologies of scene relationship construction and camera pose calculation. It conducted classification and analysis based on the diverse core algorithms and scene information employed, with performance comparisons drawn from indoor and outdoor public datasets. Lastly, it expounded the current challenges in the field and future development trends.
Key words:camera pose estimation; deep learning; scene relationship construction; pose calculation
0 引言
相机位姿估计是计算机视觉中的一个基本问题,同时也是移动机器人、SLAM[1]、增强现实(AR)[2,3]、自动驾驶[4,5]的核心技术之一,准确估计相机的位姿对于上述领域的应用至关重要。相机位姿估计也被称为相机定位,具体来讲就是通过图像或视频来确定相机在世界坐标系下的位置和朝向。在过去的几十年中,相机位姿估计已经得到了广泛的研究和应用,而随着深度学习的发展,越来越多的方法开始将其应用于相机位姿估计中。
回顾相机位姿估计的发展,从一开始的几何方法到图像检索方法,再到近几年发展迅速的深度学习方法,估计的相机姿态在准确性和鲁棒性上有了很大的提升。几何方法通过对从查询图像中提取出的关键点进行描述得到特征,进而与3D点云模型进行匹配[6],得到查询图像和场景之间的关系[7,8],通过三角测量或PnP(perspective-n-point)[9]等方法进行解算,求得相机位姿。该方法实现简单,但易受噪声影响、场景变换导致鲁棒性较差,且计算量大。基于图像检索法[10]主要是选择最佳的匹配图像,在图像数据库中检索与查询图像相似的最近邻图像[11],利用该近邻图像的三维模型信息,计算出相机的位姿。但在实际情况中,检索过程中往往不能得到相似度极高的近邻图,这会大大影响位姿估计的精度[12],且随着场景尺寸的增大,图像数据库的占用量会随之上升,这对模型实现实时性是一个相当大的挑战。随着深度学习在计算机视觉领域取得的成功,受此启发,2015年,Kendall等人[13]提出了PoseNet,该模型是第一个从输入查询图像直接输出位姿的模型,由于其估计相机位姿的过程不依赖交叉帧或关键点,令其相较于传统基于结构的方法有着很多优势,如推理时间短、内存占用少、人工成本低等,但该方法初期对场景信息的利用不充分,性能相较于传统方法并没有实现超越,后续众多研究人员对其进行研究,目前结合深度学习的方法成为了研究趋势。
本文根据模型结构上的差异将相机位姿估计的方法进行分类,在顶层分类为两阶段模型结构方法和单通道模型结构方法。在这两个类别上,根据基于结构的混合方法中核心算法不同,以及基于深度学习的场景信息利用上的不同,进行更为具体的分类。其中基于深度学习的方法将关系搭建和位姿解算设计进一个整体的模型里,只需输入查询图像就能得到相机位姿。基于结构的混合方法中,查询图像与场景之间的关系搭建和位姿解算是两个分开的阶段。相较于陈宗海等人[14]的横向分类方法以及Shavit等人[15]的端到端和混合位姿分类方法,本文在不同的类别上更能关注到算法核心点,不再局限于2D-3D之间的映射[16~21],对于场景信息的利用上划分更为细致。本文将对主流的相机位姿估计方法进行综述,并介绍最新基于深度学习的相机位姿估计方法,为相关领域的研究人员提供帮助。最后,总结当前研究的局限和挑战,并得出未来的发展方向。
1 基础知识
1.1 相机位姿估计
相机采集图像的本质是将3D空间中的点映射为成像平面,使用相机中的光感传感器记录亮度信息,获取像素点,形成照片。相机成像模型为成像过程提供数学理论支持,其过程如图1所示,整个过程包括相机坐标系、世界坐标系、图像坐标系和像素坐标系间的转换。相机成像过程中构成相似三角形,通过相似三角形建立等比关系:
Zcf=Xcx=Ycy(1)
其中:f为相机焦距;(Xc,Yc,Zc)是相机坐标系下的坐标;(x,y)是图像坐标系下的坐标。投影后的坐标为
x=fXcZc(2)
y=fYcZc(3)
在相机位姿的表示上,目前有欧氏变换、欧拉角、四元数等表示方式。欧氏变换中使用旋转矩阵来表示相机位姿过于冗余,而使用欧拉角来表示位姿时因其奇异性容易出现锁死状态,四元数表示方法改善了前两种表示方法的缺点,表示不冗余,并且不会因奇异导致锁死,其表示公式为
p=p0+p1i+p2j+p3k(4)
其中:i,j,k为虚部,具有以下约束:
i2=j2=k2=1ij=k,ji=-kjk=i,kj=-iki=j,ik=-j(5)
若相机绕着单位向量m旋转了Φ度,则其旋转向量表示为
R=1-2p22-2p232p1p2-2p0p32p1p3+2p0p22p1p2+2p0p31-2p21-2p232p2p3-2p0p12p1p3-2p0p22p2p3+2p0p11-2p21-2p22(6)
可将式(6)简化为
R= b11b12b13b21b22b23b31b32b33(7)
此时旋转矩阵与四元数转换关系为
p0=tr(R)+12(8)
p1=b23-b324p0(9)
p2=b31-b134p0(10)
p3=b12-b214p0(11)
四元数表示的相机位姿为
R=[x,y,z,p0,p1,p2,p3]T(12)
1.2 评价指标
评价指标是用来度量和比较不同算法或模型性能的标准。能够量化不同方面的性能,帮助研究人员直观地了解算法或模型的表现,为后续算法的优化和改进提供指导。
在测量评估相机位姿估计模型性能的过程中,需要将估计方法所计算的位姿与地面真实姿态进行比较,所得到的误差越小,说明估计的结果与地面真实姿态越接近。地面真实姿态通过使用运动结构(SfM)[22]工具或者由扫描设备(如Microsoft Kinect)直接提取三维场景中的坐标。
1.2.1 平移和旋转误差
大部分的数据集提供地面真实姿态的6Dof信息。在使用估计的姿态来测量偏差时,若输入为单个图像,误差度量为绝对姿态误差(APE),包含了绝对平移误差和绝对旋转误差。绝对平移误差为估计的平移分量和地面真实平移分量x之间的欧几里德距离:
tape=‖x-‖2(13)
绝对旋转误差,以度为单位,可以计算得到对准地面实况和估计取向所需最小旋转角度。
rape=α=2 arccosq180π(14)
若输入为序列图像,误差度量为相对姿态误差(RPE),包含了相对水平误差和相对旋转误差,与APE相同,使用四元数表示法,RPE主要度量视觉里程计相对运动姿态。
1.2.2 采样阈值误差
部分模型采用间接方法测量定位性能,如采样阈值误差百分比,即就是通过将估计的相机位姿与真实的相机位姿进行比较,计算误差(例如欧几里德距离或角度差),并将其与给定的固定阈值进行比较。如果误差超过了固定阈值,就会被计入固定阈值错误的数量中。固定阈值包括高精度(0.25 m,2°)、中等精度(0.5 m,5°)以及粗精度(5 m,10°)。使用百分比突出显示总体的准确性,百分比越高,性能越好。
1.3 数据集介绍
数据集是研究和实践中不可或缺的元素,在衡量和验证模型算法、系统的性能等方面起着关键作用。数据集能够更好地反映算法和模型适应的场景,从而使得算法和模型在更广泛的情境下得以验证和改进。
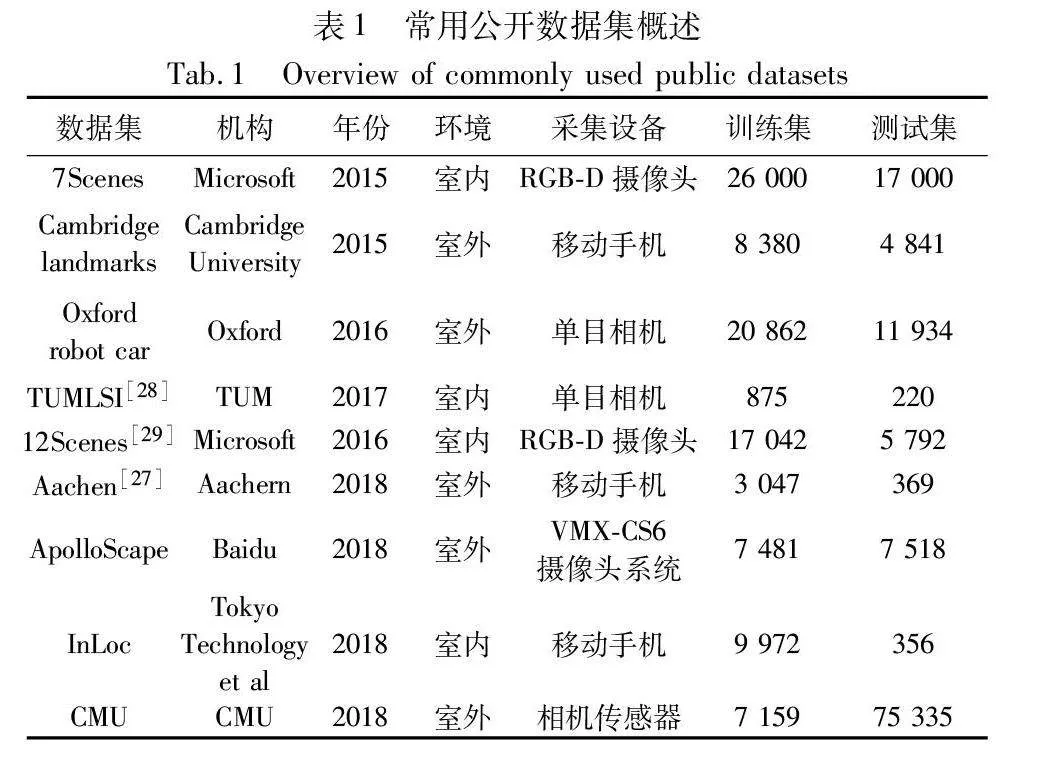
公开的数据集能够验证模型在当前研究现状中所处的水平,相机位姿估计的数据集按场景分为室内数据集和室外数据集两种。表1总结了相机位姿估计常用的数据集信息,室内代表公开数据集有7Scenes[23]等,室外代表公开数据集有Cambridge landmarks[13]和Oxford robot car[24]等。本节对使用广泛的数据集进行了介绍,阐述了其数据集结构和内容,并指明了所介绍数据集应用的视觉任务。
7Scenes是相机位姿估计和场景重建的室内公开数据集,由剑桥大学研究人员创建,包含了chess、fire、heads、office、pumpkin、redkitchen、stairs七个不同的场景。该数据集特点为使用相机匀速拍摄成连续的序列图像,数据集提供场景的RGB图像、深度图以及相机真值,图像中包含了很多挑战性元素,如重复性纹理、低纹理以及光照变化等情况。该数据集更加接近现实复杂的室内情况,对相机位姿估计任务有很大的挑战性,7Scenes是目前使用最为广泛的室内数据集。
Cambridge landmarks是室外场景的数据集,使用智能手机拍摄剑桥大学周围五个不同场景的图像(K.College、Old Hospital、Shop Faade、St M.Church、Great Court),每个场景包含了超百帧的图像数据,且场景的距离跨度较大。该数据集也提供了相机真值,同时划分好了训练集和测试集,数据集图像中包含了大量干扰信息,有行人、车辆、光照变化、天气变化以及物体快速变化导致的运动模糊,对模型性能有很大的挑战。该数据集目前是相机位姿估计领域中使用最为广泛的室外数据集。
ApolloScape数据集[25]是由百度Apollo团队制作的室外场景数据集,该数据集除了提供场景RGB信息外,还涵盖了其他的场景信息。首先,该数据集包含了高质量的激光雷达数据,提供了精准的三维点云信息,更真实地还原了复杂的户外场景;其次,该数据集还提供了丰富的像素级标注,使研究者能够进行对语义理解和场景分析相关算法的研究。目前,该数据集依旧在不断地更新发展,为视觉领域技术的研究提供有力的支持。
InLoc数据集[26]是Tokyo Technology等单位为大规模室内定位而设计的。数据集由一个RGB-D图像数据库组成,并通过移动手机拍摄的一组单独的RGB查询图像进行增强,以使其更适合于室内定位。由于大的视点变化、移动的家具、遮挡、照明变换和过道等因素存在,使得待定位的查询图像和数据库图像之间存在显著的外观变化。同时该数据集提供了相机真值以帮助研究人员更好地使用。
CMU数据集[27]是卡内基梅隆大学使用相机传感器制作的室外数据集。此数据集包含了季节变化和天气变化,并且采集城市内和郊区两处场景数据,不仅在时间上跨度较大,场景的距离跨度也很大。数据集整体提供了17个序列场景,并为每个场景建立了3D模型,同时数据集提供了查询图像的6DoF真值姿态,以帮助研究人员进行算法的验证和实现。
2 两阶段模型结构方法
两阶段的模型匹配方法在估计相机位姿时包含场景关系搭建和相机位姿解算两个工作阶段。场景关系搭建阶段的目的是建立查询图像与场景模型之间的匹配关系。相机位姿解算阶段对搭建的场景关系进行约束解算,以恢复相机位姿,经典的做法是应用几何约束下的PnP来计算位姿,并用RANSAC算法[30~33]来剔除离群值。
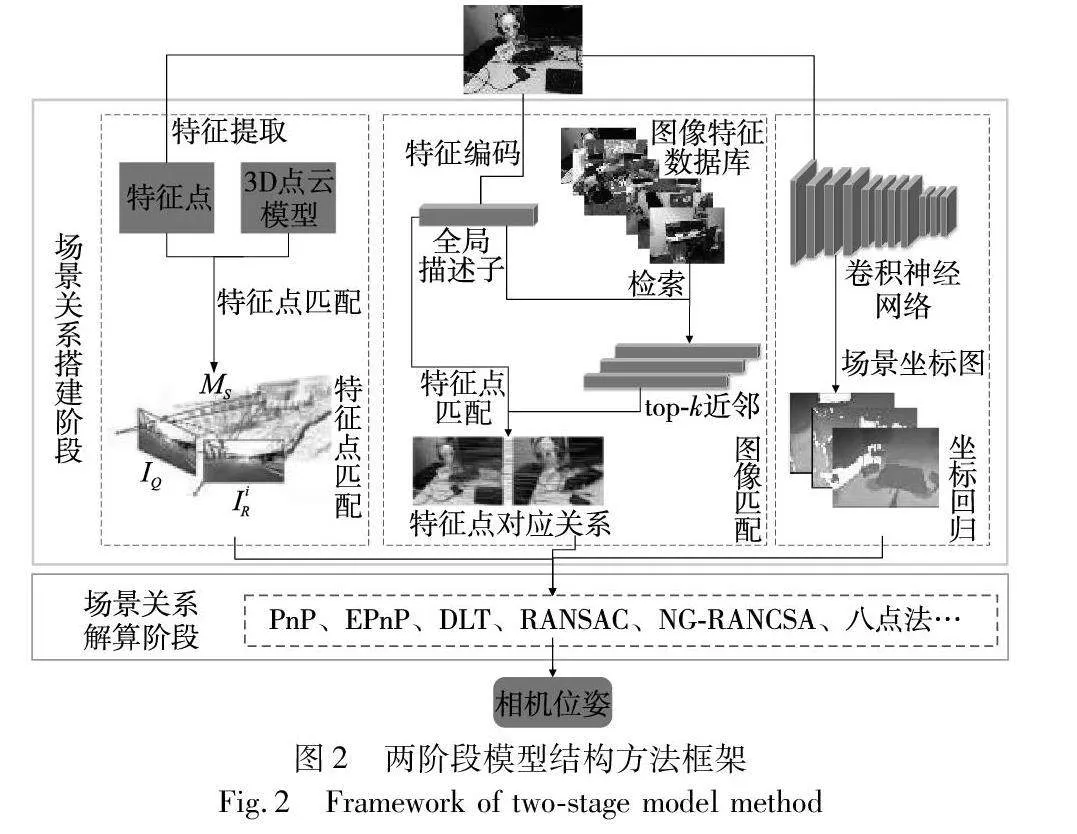
两阶段模型结构能够清晰地了解到模型在当前时刻的作用,整体结构如图2所示。场景关系搭建阶段根据搭建方法不同,分为三种方法。特征点匹配方法主要是从查询图像中提取特征点,然后与三维场景进行特征匹配,因此需要重建三维点云模型以缩小特征匹配空间。采用SFM(structure from motion)技术对三维场景进行重建,重建的点云模型存储了场景图像中的特征向量和关键点,且能够保存场景中的几何信息。由于三维点云模型对几何信息表达冗余,所以在解算过程中有更多的几何约束信息去剔除离群值,提高精度。基于图像检索的方法是二维到二维之间进行特征映射,该方法在搭建匹配关系时需要建立图像匹配数据库[34],其匹配关系搭建流程为,首先对查询图像的特征进行编码,获得全局描述子,其次在图像匹配数据库里检索最近邻图片,进行特征点匹配,得到场景关系。坐标回归方法是直接估计三维场景的坐标,通过训练神经网络,可以从输入查询图像直接得到三维场景的坐标,因此无须重建三维点云模型和建立图像数据库。
2.1 特征点匹配+解算
二维到三维的特征匹配算法对场景中的遮挡、光照变化有较好的鲁棒性,且在相机与场景之间距离较远时,依旧可以提供较高的位姿精度,但需要场景中具有足够的3D点和2D特征点进行匹配,对数据需求较高。目前,对于特征点匹配方法的改进主要集中在特征点的提取和匹配上,提取查询图像中的特征点主要由关键点检测器来完成,而将所有特征提取非常耗时,特征点的匹配方法是否高效会直接影响解算后位姿的精度,因此很多模型将工作的重点放在了场景关系搭建阶段,目的是为了提高效率和精度,部分研究人员将模型的改进重心放在了匹配方法上。
Sattler等人[35]探索了一种正交策略,将3D点量化为一种细分词汇表[36]来隐式执行特征匹配,通过一种简单的投票策略来找到局部唯一2D-3D点分配,该方法只需存储单词标签,因此内存占用大大降低,从而加快了特征匹配速度。加速2D-3D匹配过程中会因为量化操作导致匹配损失,尤其是泛化到大场景中,相似或重复纹理的特征点总会影响位姿的精度。为此,Liu等人[37]提出了一种新的全局排序算法,利用了查询图像以及3D点之间展示的全局上下文信息,这样做不仅考虑了每个2D-3D匹配之间的视觉相似性,还兼顾了匹配对之间的全局兼容性。
除了在场景关系搭建阶段改进2D-3D匹配方法外,有效地提取局部健壮特征点不仅能够提升匹配效率,同时能够提升精度。特征点的提取依赖于关键点检测器,而手工制作的关键点检测器(SIFT[38]、SUSAN[39]等)对于实时性来说并不理想,为了加快检测器的效率。DeTone等人[40]提出了一个可以在完整大小的图像上运行的完全卷积模型,能够训练出多视角几何问题的关键点检测器,在关键点检测上引入了一种多尺度、多单应用(homographic adaptation)的方法,用来提升关键点检测的重复性。Tian等人[41]将二阶相似性(SOS)[42,43]应用到局部描述符中,提出二阶相似性正则化(SOSR),并将其纳入训练中,学习描述符包含局部补丁到运动结构的多种任务信息,实验表明,描述符匹配鲁棒性得到显著提升。Wang等人[44]提出了一个弱监督框架,无须像素级地面实况,仅从图像之间的相对位姿学习特征点描述符,性能优于之前的完全监督描述符。
大部分特征点描述在关键点检测器检测完成后进行提取,为获取更为健壮的关键点,部分研究人员将关键点检测的阶段向后推迟。Dusmanu等人[45]提出了一个可实现双任务的卷积神经网络D2Net,将关键点检测推迟到特征点描述之后,所获得的关键点更为稳健。Luo等人[46]基于文献[45]提出ASLFeat,提高了局部特征的提取能力,获得了更强的几何不变性。具有同样的顺序思想,Tian等人[47]在2020年提出D2D的描述符模型,先描述再检测关键点位置,该模型无须任何额外的训练,通过相对或绝对的局部深度特征图在空间和深度维度上去定义关键点。
2.2 图像检索+解算
特征点匹配方法泛化到大场景下,精度和鲁棒性会受到很大的影响,且大场景下建立3D点云模型需要采集大量的图像,尤其在大场景户外环境下,会受到多种因素影响,例如光线变化、天气变化、遮挡、动态物体等。目前,利用图像检索的场景关系搭建方法来求解大场景下相机位姿,相较于特征点匹配有很大的优势,该方法对于室外大场景的变化有较好的应对表现。基于图像检索的方法无须建立3D点云模型,而是建立图像匹配数据库,通过对场景中每个图像提取特征点,并将其存储于数据库。在位姿估计时,在数据库中对查询图像进行检索,得到最相似的图像,建立场景关系并进行解算。在进行检索的过程中,通过对局部特征进行编码来得到用于图像检索的全局描述子。传统局部特征的图像编码方法有词包(BoW)[48]、局部聚集描述符向量(VLAD)[49]等,后续在检索过程中应用CNN来进行聚合局部特征。
Revaud等人[50]提出一种通过列表排序损失直接优化全局mAP的方法,以改善由于追求最小化本质损失上界而导致平均准确率无法达到最优的问题;针对大量高分辨率图像会超出GPU内存的问题,引入新的优化方案,可以处理任意图像分辨率和网络深度的训练批量。Teichmann等人[51]针对检索基准中缺乏边界框数据集,提出了新的基于Google地表边界框数据集,目的是利用索引图像区域来提高检索准确性。同时,为将检测的区域信息组合成改进的整体图像,引入了新的区域聚合选择匹配核(R-ASMK),在不增加维度的前提下,显著提升了图像检索的准确性。
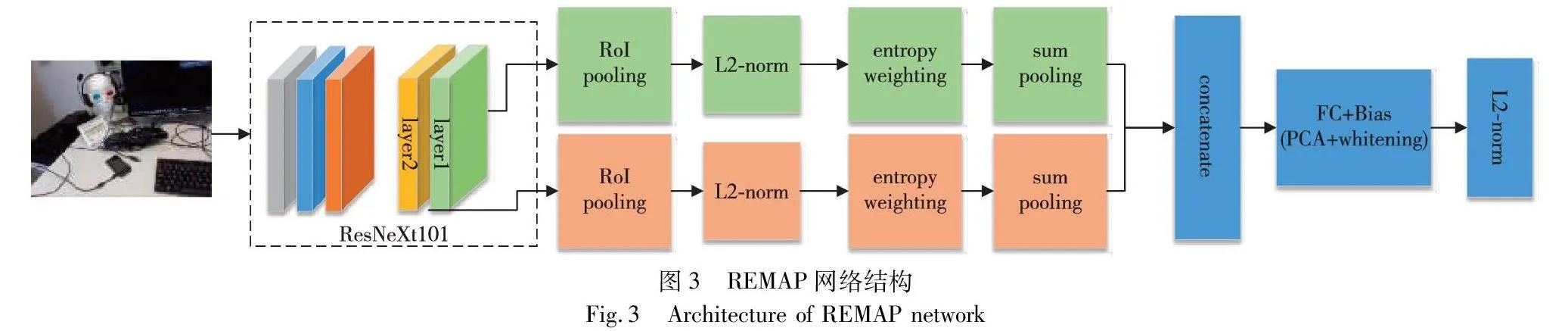
全局描述符在检索中起到主要作用,健壮的全局描述符可以检索出相似的最近邻图像,相似的最近邻图像是模型性能精度的保障。Husain等人[52]提出了新的基于CNN的全局描述符REMAP,其结构如图3所示。REMAP清晰地学习到不同语义级别的视觉区分性特征,在检索语义有用的区域和层时,通过使用Kullback-Leibler(KL)散度测量每个区域和层的信息增益,目的是能够关注全局上下文信息,获得更为健壮的全局特征描述符。
相较于其他方法,图像检索的场景关系搭建方法在模型泛化性上有一定的优越性,因为该方法对3D场景没有很高的要求。为进一步提高模型在变化场景中的泛化性,Sarlin等人[53]于2019年提出了HF-Net,在模型结构上进行了创新性的变化,使用由粗到细的分层结构,同时对局部特征和全局描述符进行预测,这种分层的结构方法节省了大量运行时间,因此,提高实时性的同时又保证了泛化性。2020年,Zhou等人[54]提出新的图像检索框架,首先检索出与查询图像相同的场景图像集合,计算其与查询图像的本质矩阵,利用检索图像的基本矩阵得到查询图像位姿,该框架不依赖场景三维模型,在新场景中有很好的泛化性。
2.3 坐标回归+解算
基于特征点匹配或者基于图像检索等方式搭建场景关系,依赖于图像中的特征点,特征点的健壮性会直接影响估计位姿的精度。坐标回归的方法不再依赖于图像中的特征点,直接通过查询图像对3D场景的坐标进行回归,无须建立3D点云模型或庞大的图像检索库,在无须特征点检测和匹配的情况下就可以获得二维到三维之间的对应关系,通过PnP和RANSAC算法进行相机位姿的解算,使其对场景中的不利因素和变化有很好的鲁棒性。
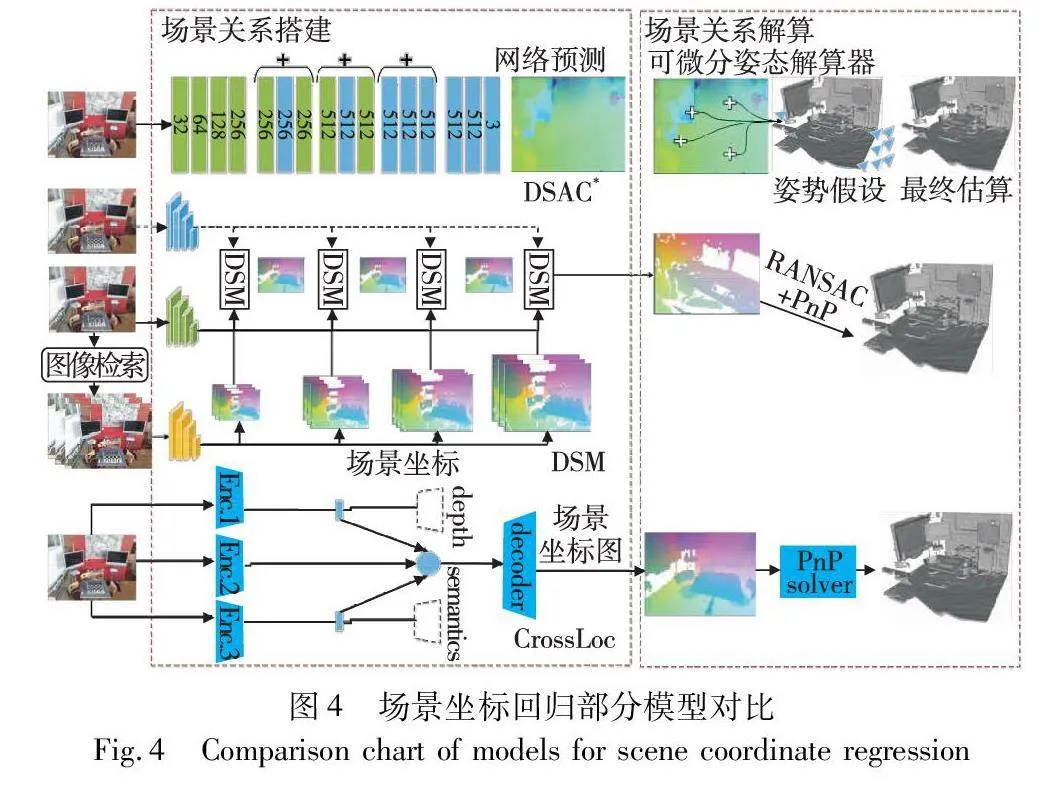
2017年,Brachmann等人[55]提出了DSAC,将场景关系搭建和相机位姿解算过程结合起来,通过训练神经网络,预测查询图像像素和3D场景坐标点之间的对应关系,接着进行RANSAC,得到模型假设集合,通过评分函数对模型假设集合打分,得到最优模型,最终实现可微分的RANSAC。为提高DSAC训练时间和泛化能力,Brachmann等人[56]在文献[55]的基础上提出了DSAC++,先前预测场景坐标会学习整个位姿估计的流程,而DSAC++证实学习单个组件就可以密集回归场景坐标,大大减少了训练时间,使用了新的熵控制软内点计数的假设评分方法,大大提升了泛化能力,且DSAC++能够自动发现场景几何。
将多视角几何约束添加进场景坐标网络中是一种新的提升模型各种能力的手段。2020年,Cai等人[57]将时间序列图像的多视角几何约束用于对场景的坐标预测,不同视角下场景点的变形误差信息能够提高网络回归到正确的场景坐标的能力,实验表明,多视角的网络更容易收敛。Li等人[58]通过将回归场景坐标的网络进行分层,由一系列的输出层组成,每个输出层都受前一输出层的约束,最后一个输出层输出预测的3D坐标,这种由粗到精的方式令该分层网络实现了更精准的3D场景坐标预测。同年,Zhou等人[59]提出KFNet,将场景坐标回归的问题拓展到时域上,通过将卡尔曼滤波结合进回归网络中,解决了时间序列图像上像素级的状态推断,该方法在时域位姿估计中有较高的精度。
扩展到时域可以提升估计位姿的精度,但如何处理大场景依旧是个难题。2021年,Tang等人[60]提出了新的预测场景坐标方法,场景不可知的相机定位使用密集的场景匹配块(DSM),结构如图4所示。DSM模块接受查询图像的特征图以及部分特征图对应的场景坐标,再利用DSM模块接受的信息以一种由粗到细的方式预测场景坐标。DSM在查询图像和场景之间构建成本体素,匹配每个查询图像像素的场景通过成本量,使得网络在有限的容量内处理大规模场景,该方法同样可以扩展到时域上。
如何通过最少的信息挖掘场景中的几何信息,以帮助估计位姿的精度,并且减少训练时间,为实时性的应用作出铺垫。2022年,Brachmann等人[61]提出DSAC*,结构如图4所示,总结了文献[55,56]并进行了扩展。在训练DSAC*网络时,可以是RGB或RGB-D,也可以将3D模型加入训练,以减少信息的利用,改进网络结构减小内存占用,简化训练过程,提高训练效率,改进后的网络可在训练时自动发现场景中的三维几何信息,有助于提高估计位姿精度。场景中的其他信息可以提升估计位姿的精度,因此添加场景其他信息以提高大场景环境下的定位精度,也是一种方法。2022年,Yan等人[62]提出了CrossLoc,该网络结构如图4所示。其是一种自我监督进行多模态位姿估计的学习方法,通过使用几何信息和场景结构信息(如语义)来进行场景坐标的预测,为得到大尺寸数据集的多模态合成数据集,提出TOPO-DataGen方法。实验表明,在空中场景环境定位时,该方法使用多模态合成数据集进行辅助达到了最先进的基线。为提高模型鲁棒性和精度,王静等人[63]通过引入深度过参化卷积来取代网络骨架中传统的卷积层,并在网络学习过程中增加细粒度信息,以解决空间信息丢失问题,提高信息利用率。当前使用场景坐标方法来搭建场景关系已经取得了很好的精度,但是模型在回归3D场景坐标时计算密集,较为耗时,很难推广到实时推理的环境中。2022年,Bui等人[64]提出了一种简单的场景坐标回归算法,使用多层感知网络映射场景坐标,为减小模型尺寸,场景坐标由稀疏描述符得到,而非RGB图像像素数据。
3 单通道模型结构方法
不同于两阶段的场景关系搭建和相机位姿解算的位姿估计流程,单通道模型结构方法将两个工作融合进一个神经网络中,通过场景数据集去训练优化一个神经网络,最终直接输出估计的相机位姿。整个过程并不存储场景中任何几何关系,也无须搭建3D点云模型或图像数据匹配库。神经网络能够提取数据集图像中的特征,并将其向高维空间映射,最后通过线性映射层(如全连接FC层)得到位姿估计。整个过程通过数据集给出的相机位姿真值构造损失函数对训练过程进行监督,使网络实现对场景信息的学习。
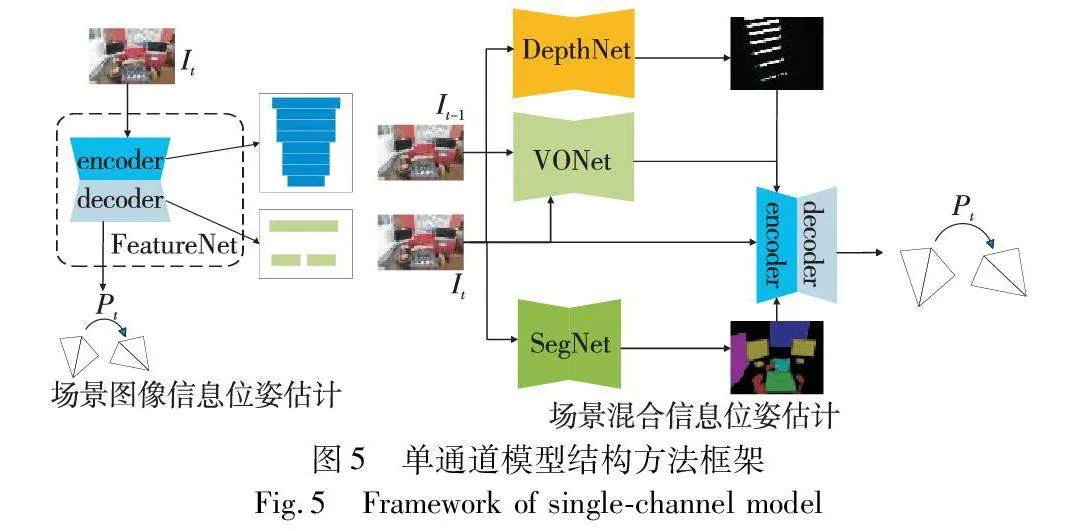
单通道模型结构方法是由一个整体神经网络去估计位姿的,该神经网络分为学习特征的编码器和对位姿回归的解码器,整体结构如图5所示。编码器的输出是一个经过学习的表示,其中包含了输入图像里的重要信息,解码器对信息进行特定的映射操作,逐步生成最终的位姿输出。在训练神经网络时,对学习过程中场景信息的使用上,有单一场景图像信息和混合场景信息的使用,因此将其分为场景图像信息位姿估计和场景混合信息位姿估计。
在场景图像信息位姿估计中,神经网络使用场景的RGB图像进行网络训练,编码器从输入图像中学习特征,解码器回归相机位姿。从当前的研究现状可知,在神经网络的编码器中添加技术模块和网络单元,可使神经网络在学习图像特征时能够聚焦到局部特征和重要特征,并且能够降低网络计算复杂度,进而提高网络的效率和性能。编码器学习到特征会将其输入进解码器中,解码器会将学习到的特征进行映射转换为最终的输出,解码器的具体设计取决于视觉任务的性质,一般估计的相机位姿会以6DoF表示,使用全连接FC层进行特征映射。
在场景混合信息位姿估计中,神经网络的训练不再局限于场景的RGB图像,场景中的其他信息会和RGB图像共同训练网络,例如场景运动信息、场景结构信息等。在神经网络的编码器中,不仅要考虑高效提取图像特征,更多地是如何应对多种信息特征的融合或是信息之间的互补。场景混合信息位姿估计在神经网络的编码器中同样会有技术模块的应用,在获取场景中的其他信息时,会有相关算法应用于神经网络中。解码器的设计和场景图像信息位姿估计一致,通过FC层进行线性映射。
3.1 场景图像信息位姿估计
通过将单个图像作为输入,直接去回归相机6DoF,其输出包括相机的平移分量和旋转矩阵,仅对单个图像进行提取高维特征,最终由线性映射层表示出6维向量。2015年,Kendall等人[13]提出了PoseNet。PoseNet是第一个通过训练卷积神经网络从单个RGB图像中回归相机位姿的网络模型,使用固定的损失函数作为对相机位姿估计的监督,公式如下:
l=‖-x‖2+β‖-q‖q‖‖2(15)
即在网络训练过程中使用固定的超参数β去计算水平和角度误差的加权和,与特征匹配的方法不同,PoseNet不依赖于手工设计特征,推理速度快、占用内存小,表现出的鲁棒性受到了很多研究人员的关注。PoseNet是第一个只通过神经网络就可以估计到相机位姿的网络,为了继续提高其精度和鲁棒性,众多研究人员对其进行了改进,目的是能够通过单个图像就获得高精度的相机位姿。
为应对多个数据集中更换训练场景需重新训练的问题。Naseer等人[65]根据PoseNet提出了一个分类网络的新网络SVSPoseNet。SVSPoseNet更换了网络骨架,将GoogLeNet替换为VGG16[66],额外的两个FC层进行6DoF水平和角度预测,在数据集的多个场景中使用相同参数,不再根据不同的训练集进行超参数优化,减少了网络训练时间,该算法在室外大场景环境下取得了较好的位姿精度。为增强网络的鲁棒性,以应对在不同光照条件或运动模糊等不断变换场景中精度下降的问题,2017年Melekhov等人[67]提出了一种具有沙漏形状的网络Hourglass PoseNet,该网络整体由编码器、解码器和回归器组成,通过向解码器引入上卷积层以恢复查询图像的细粒度信息,并补充深度卷积网络,其中编码器和解码器使用了修改后的ResNet34[68],相较于PoseNet,增强扩展了原始架构。
在网络训练中,固定的损失函数需要进行手动调节超参数,这样做会导致大量的人工成本,网络模型性能对于超参数β很敏感,且在场景变化过程中,最佳性能的超参数β极难寻找。针对该问题,2017年Kendall等人[69]提出了可学习的损失函数。可学习损失函数的超参数可以跟随网络模型的训练过程不断进行变化,自动学习最佳权重,新的损失函数使用同方差不确定性[70]来进行表示,能够专注于任务本身的不确定性,以概率的方式来联合收割不同任务的损失。该可学习损失函数可添加进多种模块或功能进行约束,以得到几何约束。2019年,Bui等人[71]提出了新的网络框架,加入判别器网络和对抗学习,这样可以在估计位姿时将姿势进行细化,网络在可学习损失函数加持下性能得到很大提升。目前利用CNN方法已经表现出针对场景变化的可靠性了,但场景中动态环境依旧是导致模型性能不高和不稳定的因素。2019年,Huang等人[72]提出新的框架去解决动态问题,引入了预先引导的dropout模块和一个自注意模块。dropout模块回归时可输出多个假设,对动态环境中动态对象的不确定性进行量化,从而提高鲁棒性,自注意模块能够让网络忽略前景对象的干扰,专注于背景中的关键地标,以提升网络估计精度。在利用单图像进行估计位姿时,会有较多离群值,通过添加几何约束能够改善此问题,研究人员通过实验发现,注意力机制对于提高估计精度、减小离群值也有很大的作用。2020年,Wang等人[73]提出一种自注意力引导的神经网络AtLoc,能够在训练过程中专注于几何上更为健壮有用的特征。AtLoc使用可学习的损失函数,在网络骨架上使用ResNet34作为编码器网络,使得模型在输入仅为单图像时,也能够学习到更为鲁棒的对象特征。
当前网络模型的性能体现主要由数据集进行评估,数据集中不同场景分开进行训练和评估,不同场景之间做迁移会导致精度严重下降,这对模型的泛化是一个很大的挑战。Chidlovskii等人[74]提出了APANet,通过添加对抗学习来表示模型的迁移,同时修改分类领域的自适应技术,并将其加进位姿估计网络中,验证场景不变的图像表示。为进一步提升模型的泛化能力,2021年,Sarlin等人[75]提出PixLoc,通过输入查询图像和场景3维模型,即可输出得到图像对应相机位姿。PixLoc将相机位姿问题转换为度量学习,端到端地学习了像素到位姿的数据先验,算法着重于表征学习,让网络很好地理解几何原则并鲁棒地应对场景变化,固定LM优化算法的参数可以使数据和优化器解耦,达到与场景结构无关适用于任何场景的效果,从而提升泛化能力。2022年,Chen等人[76]提出DFNet,引入一种比之前光度匹配更具健壮性的直接匹配方法,并与绝对姿态回归结合,弥补真实图像和合成图像之间的特征级领域差距,在曝光自适应的新视图合成(NVS)的支持下,成功解决了室外环境中现有光度基准方法无法处理的光度畸变问题。该文还介绍了一种数据生成策略,通过对训练数据轨迹进行扩充,使其对未知数据有了更好的泛化性。场景图像信息位姿估计模型对比如图6所示。
3.2 场景混合信息位姿估计
以往的方法在估计位姿时,网络模型仅根据场景图像进行训练和估计位姿,主要依赖输入的图像信息,但场景中所包含的信息并不单只有图像中的特征,还有几何信息(如视觉里程计[77~79])和结构信息(如语义信息[80,81])等,仅使用图像特征并不能充分利用场景中的信息。因此,很多研究人员在估计位姿网络中添加了场景其他信息,目的是通过辅助任务约束[82~84]以减小位姿误差,提高精度和鲁棒性。
2018年,Valada等人[85]提出了VLocNet,在位姿估计网络中添加了几何信息-视觉里程计作为辅助信息,以两张序列图像作为输入,通过暹罗网络对视觉里程计进行回归,使用可学习的损失函数进行约束,并和全局损失函数进行整合,以达到对整体网络进行约束,实验表明,位姿精度有了很大的提升。同年,该作者团队在文献[85]的基础上提出VLocNet++[86],在估计相机位姿网络中添加了场景结构信息,即场景的语义信息,提出自监督扭曲技术以学习一致的语义信息,对于各个任务之间的依赖性提出了自适应融合层,以进行彼此之间的调节,新的可学习损失函数将估计位姿、视觉里程计、语义结合在一起进行网络约束。实验结果表明,VlocNet++在感知变化、重复结构和无纹理变化的场景中,表现出了很好的性能和鲁棒性。在估计位姿的网络中添加视觉里程计信息是提升精度的重要手段,且视觉里程计信息是场景中重要的几何信息,但目前视觉里程计信息在预测时仍存在轨迹漂移现象。2019年,Lin等人[87]提出了DGRNet,该网络可实现对视觉里程计进行精准预测,并能够和位姿估计网络进行融合。该方法在估计视觉里程计网络和相机位姿网络中均使用了LSTM单元,能够挖掘长距离图像之间的关系,并存储过去几帧预测的相机位姿数据,以减少视觉里程计轨迹漂移和提高位姿的估计精度,并使用CTC loss+MSE对整个网络模型进行训练。
2020年,Tian等人[88]在估计相机位姿时引入了三维场景几何感知约束,进一步融合了3D场景几何信息,通过利用深度图将约束公式化为光度差和SSIM。相比之下,3D场景几何约束是像素级的,可以在估计位姿时利用更多的信息,包括相机运动、三维结构和光度信息,在预测精度和收敛性能上都有明显的提高。2021年,Chen等人[89]提出了语义信息增强的全局检索方法,使用语义修复网络(SI-GAN)将场景中动态语义图像转换为完整的静态对象,并使用SME将修复后的静态语义图像分割嵌入,生成语义检索的归一化向量。SI-GAN能够减轻场景元素前后遮挡所造成的边缘信息弱化问题。最后将语义检索和RGB图像相结合,该方法在场景复杂、光照变化强的环境中有很好的性能表现。
3.3 深度学习模型对比分析
本节汇总了场景图像信息位姿估计和场景混合信息位姿估计中的部分模型,对比了模型的网络骨架(编码器+解码器)、损失函数类型、损失函数等,如表2所示。
对于神经网络模型,网络骨架的选择对特征的提取能力影响很大,深层网络相较于浅层网络表现更为出色。同时损失函数对于模型训练的约束是相当重要的,设计合理的损失函数也是提高精度的重要手段。很多研究人员根据模型应用的场景特性和表现出的缺点,为模型添加技术模块和网络单元,不仅能够解决网络相关问题,还能提升整体模型的鲁棒性或泛化能力。
4 性能对比分析
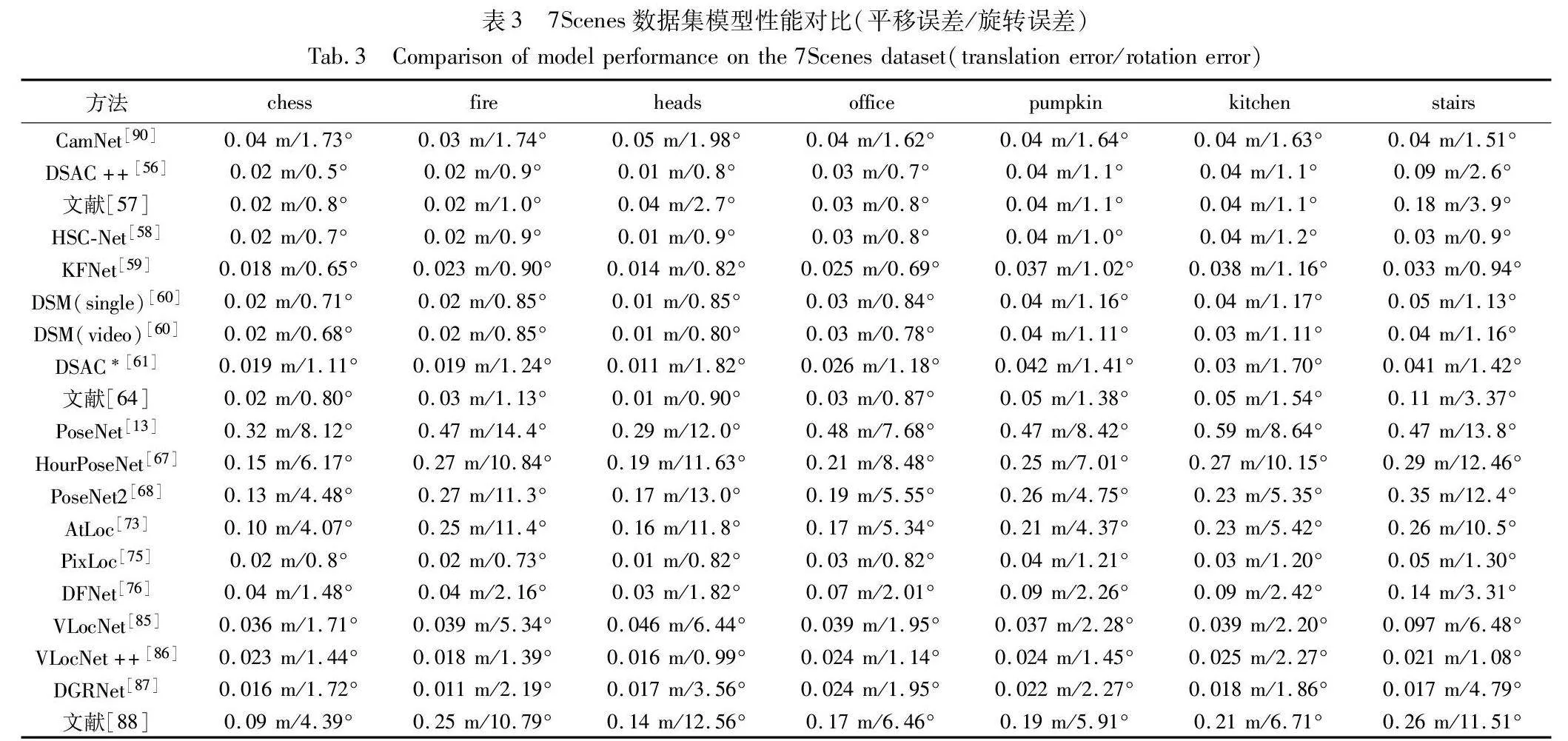
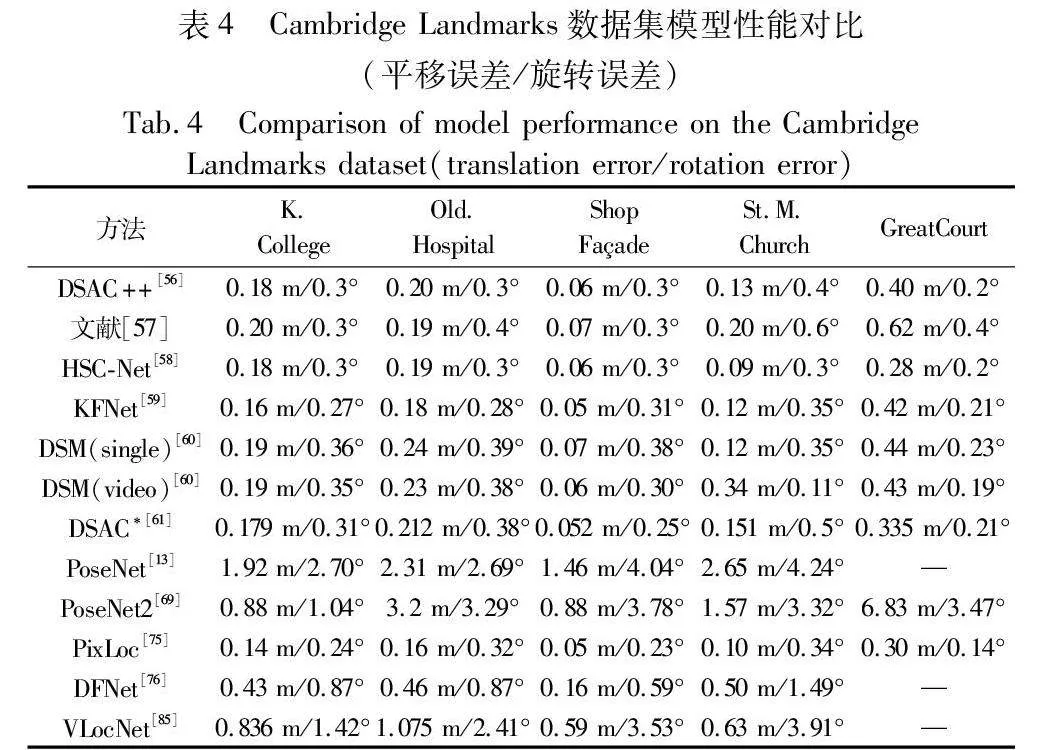
前两章总结性描述了近几年的代表性方法,对两阶段模型结构方法和单通道模型结构方法进行分析。依赖2D点和3D模型匹配的方法在相机位姿估计中已经应用得很成熟了。为应对复杂场景和重复纹理的环境,深度学习成为了当前解决该问题的热点方法。为了能够比较上述方法,总结了它们在公开数据集7Scenes和Cambridge Landmarks上的性能表现数据,其中数据表示为相机位置的水平误差(m)和相机姿态的角度误差(°),如表3和4所示。
4.1 模型解算方法对比
两阶段模型结构方法通过对特征点的匹配关系或3D场景中像素坐标进行解算,以确定相机在世界坐标系中的位置和方向。两阶段方法在位姿解算的方法使用上层出不穷,目前使用频率较多的方法有2D匹配对极几何中的矩阵方法(本质矩阵和单应矩阵)以及3D-2D匹配求解的PnP等,这些解算方法在求解位姿时搭配相关算法以提升精度,例如BA调整、RANSAC等方法。对极几何的矩阵方法中,本质矩阵对于强几何约束和视角小的相机位姿估计有很强的适用性,这两种情况一般会发生于静态场景中,静态场景能够通过三角化获取到精确的三维结构,因此该方法对于稳定精确的几何关系有较为出色的可解释性,但在动态场景或场景运动信息丰富的情况下,该解算方法并不适用,且该方法对场景中的噪声和物体遮挡相当敏感。单应矩阵解算相机位姿需要大量匹配的特征点,这对于模型效率和实时性来说并不友好,但单应矩阵在解算平面场景的相机位姿时表现出色,同样该方法易受噪声和异常值的影响,目前使用一些鲁棒方法去改善此情况,例如使用RANSAC剔除匹配中的离群值和异常值来提高解算相机位姿精度。
利用坐标回归算法去估计相机位姿,通常使用PnP方法去解算位姿。PnP在已知一张3D特征点的情况下,只需3个点就可以解算相机位姿。因此,PnP方法简单且直接,特别适用于少量特征点的情况,并对噪声和遮挡相对鲁棒。PnP求解还有直接线性变换DTL方法,通过已知的空间坐标和归一化坐标直接求解相机的位姿。目前,还可以把PnP构建成一个重投影误差的非线性最小二乘问题,利用BA调整,将相机位姿和3D点位置看作优化变量进行优化,这样能够对全局进行优化,综合考虑到多个视角和特征点,非线性的方法使PnP可以处理大规模场景和大量特征点。
单通道模型结构方法在解算相机位姿时,并不使用具体的解算算法,主要利用神经网络中的解码器进行估计。解算相机位姿的解码器结构较为简单,通常利用全连接FC层进行位姿映射,FC层中的神经元与前一层的所有神经元相连接,将上一层网络的特征数据作为其输入,以进行整合分类,最终直接输出相机位姿。利用FC层解算出的相机位姿精度主要受神经网络学习能力的影响,因此,如何提高神经网络学习到更为鲁棒的场景特征,才是提升相机位姿精度的主要途径。
两阶段模型结构方法在解算上依赖于场景匹配的特征点,对于纹理丰富、有明显特征的场景效果较好,单通道方法通过大规模数据学习更复杂的图像表示,在解算一些缺乏明显特征的场景也具有较强的适应性。目前,两种模型结构中所使用的解算方法在多种场景中仍具有很大的应用需求。
4.2 模型性能分析对比
从表3、4可以得出,坐标回归加解算的DSAC*精度是最好的。通过分类方法之间的对比,场景关系搭建阶段使用的3D坐标回归的方法,在精度上优于其他方法,并且在进行估计相机位姿时,使用场景中其他信息,会进一步提升精度。DSAC++和DSAC*在估计位姿过程中会自动发现场景中的几何信息,并利用该几何信息提升位姿精度。使用场景中的其他信息是提升精度的常用做法,同时也是一种发展趋势。单通道模型结构方法中,在网络训练过程中融合场景其他信息,精度都有较大的提升。VLocNet和DGRNet在网络中融合视觉里程计信息,让场景里元素前后变化在网络中能够更好地表达。VLocNet++在融合视觉里程计的基础上加入了丰富的语义信息,在元素前后变化的轨迹上注意到轮廓边缘结构,以提升场景在模型中的信息利用率,其估计位姿的精度与DSAC*性能相当。KFNet和DSM通过将回归3D场景坐标的问题引入到时域里,估计的位姿在角度误差上降低了很多,角度误差达到SOAT。
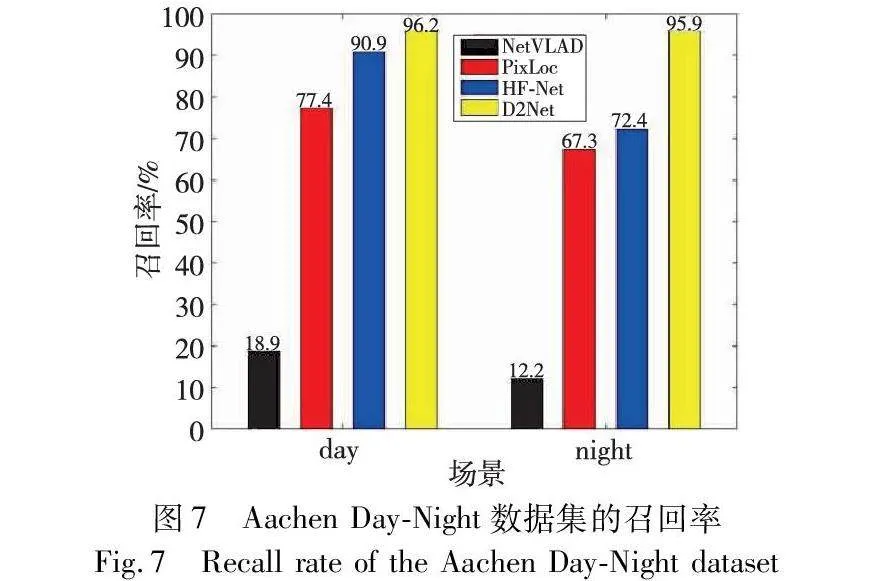
场景坐标回归方法在室内有很好的表现,但在大场景户外环境中表现不佳,尽管CrossLoc在泛化性上有了很大的改进,但大量的计算令其牺牲了实时性。模型良好的泛化性能够应对未知和不断变化的场景。在场景关系搭建阶段,基于图像检索的方法展现了较为突出的泛化能力,由于不建立3D场景模型,图像检索的方法能较好地实现迁移学习,被查询的图像数据库是庞大的,其预训练的模型可以在特定任务的小规模数据上进行微调,以应对新的场景。表现较好的方法如HF-Net,在召回率上有很好的表现(见图7),该方法同时对局部特征和全局描述符进行预测,实现了高精度定位,由粗到细的分层结构节省了运行时间,在大场景上有良好的实时性表现。其中由粗到细的分层结构方法通过逐渐减小搜索空间,让场景在模型中表达出更为精细的信息,不仅结合了全局和局部信息,还防止大规模场景在变化过程中信息混淆和丢失的问题。使用该分层结构的方法还有CamNet、HSC-Net等模型,在7Scenes和Cambridge Landmarks数据集上表现良好。分层结构的优点不仅满足较好的位姿精度,而且很容易推广到大规模户外场景中。
单通道模型的性能表现能力受网络骨架和损失函数影响较大,网络骨架的选择和设计会直接影响整体模型的特征提取能力、表示能力以及运算效率。当前较多模型会选择ResNet系列作为模型的网络骨架,像Hourglass PoseNet、AtLoc、APANet等模型在编码器结构上使用了ResNet系列,在加深网络层数以提高特征提取能力的同时,ResNet能够缓解梯度消失问题和提高网络收敛速度。损失函数直接反映出模型估计位姿与相机真值之间的差异,是模型优化的目标函数。传统的损失函数需要微调超参数β,费时费力。PoseNet2提出了一种新的令超参数拥有学习能力的损失函数,不再进行手动调节,PoseNet2在新的损失函数里加入几何约束,其表现出的性能相较于PoseNet有一定的提升。VLocNet和VLocNet++同样使用该可学习损失函数,在损失函数里加入了场景几何约束和结构约束进行监督,模型均表现出较好的结果。
5 结束语
1)挑战
通过对现有方法的研究和分析,相机进行位姿估计时,已不再局限于场景的RGB图像数据,融合场景的其他信息成为了主流,目的都是在提高场景信息利用率的同时提高精度。在满足鲁棒性的前提下,泛化性也是一个重要的模型性能,因此近几年很多研究人员在泛化性上努力着。当前相机位姿估计仍存在很多挑战:
a)视觉特征匹配。准确的相机位姿估计需要进行准确的特征匹配,但在复杂场景、低纹理区域或遮挡情况下,特征匹配可能变得困难。
b)鲁棒性。相机位姿估计需要在不同的环境条件下保持鲁棒性,包括光照变化、动态物体和噪声等因素的干扰。
c)尺度歧义。单个图像无法提供绝对尺度信息,因此需要结合其他传感器或利用先验知识来解决尺度歧义问题。
d)实时性。许多应用场景需要实时的相机位姿估计,因此需要在保持准确性的同时,保持较低的计算时间。
2)展望
a)深度学习方法。深度学习模型在计算机视觉领域取得了巨大成功,将深度学习引入相机位姿估计任务可以进一步提高性能和鲁棒性。未来深度学习模型能够更好地处理复杂、动态的场景,包括城市环境、人群密集区域等。这将为实际应用提供更多的可能性,尤其是在复杂环境中需要准确估计相机位姿的场景下。
b)多传感器融合。结合多个传感器(如惯性测量单元、GPS、激光雷达、视觉等)的数据,不同传感器对环境的感知方式各异,综合利用这些信息可以获得更全面的环境感知,仅单目相机传感器的RGB图像数据并不能包含场景太多的信息,多传感器获取场景数据进行融合能够降低某一传感器对系统性能的影响,提高系统的鲁棒性。同时,通过融合多源信息,可以更好地抑制传感器噪声和误差,提高位姿估计的稳定性,并解决尺度歧义问题。目前多传感器数据融合需要克服数据异构特性的挑战,因此该领域的主要工作集中在融合方法上,在前融合阶段和后融合阶段有很多研究。前融合阶段对于多种传感器数据融合方法众多,对于不同信息处理方法各异,例如语义信息和点云数据的拼接操作,或是RGB图像和激光点云进行特征图分层融合,同样也有设置参数权重对特征值按比例融合,控制不同传感器数据的贡献率。后融合有匈牙利匹配和卡尔曼滤波等方法,此处融合在获得传感器的输出后,就可以在观测层面进行融合,例如使用卡尔曼滤波对相机和雷达获取数据进行融合。当前使用多种传感器信息去提高相机位姿估计精度是重要的一种技术途径。
c)语义信息融合。语义信息是通过RGB图像获取的,包含了场景中物体元素的边缘信息,同时也蕴涵了物体元素之间的相对关系、布局结构,能够为模型估计相机位姿提供更多的几何约束,因此语义信息的引入为相机位姿估计的准确性、鲁棒性和应用范围提供了更多可能性。然而,这也带来了挑战,包括如何有效融合语义信息、处理复杂场景、解决不平衡类别和实时性等方面的问题。未来的研究将集中在解决这些挑战,并进一步推动相机位姿估计技术的发展。
d)自适应方法。开发自适应的相机位姿估计方法,可以根据场景和任务的特点,自动调整算法参数和策略,能够提高模型鲁棒性、实现多模态融合、优化实时性和效率,引入在线学习和迁移学习,以及环境感知和交互性,增强模型的性能和泛化能力。
e)增强现实和虚拟现实。相机位姿估计在增强现实和虚拟现实应用中具有重要作用,例如导航、教育、医疗、文化、手势识别以及场景还原等。未来将聚焦于提高位姿估计的精度和实时性,以提供更逼真和流畅的增强现实和虚拟现实体验。
参考文献:
[1]Durrantwhyte H, Bailey T. Simultaneous localization and mapping[J]. IEEE Robotics & Automation Magazine, 2006,13(2): 99-110.
[2]Middelberg S, Sattler T, Untzelmann O, et al. Scalable 6-DoF loca-lization on mobile devices[C]//Proc of European Conference on Computer Vision. Cham:Springer,2014:268-283.
[3]Ventura J, Arth C, Reitmayr G, et al. Global localization from monocular slam on a mobile phone[J]. IEEE Trans on Visualization and Computer Graphics, 2014, 20(4): 531-539.
[4]Kim K, Kim C, Jang C, et al. Deep learning-based dynamic object classification using LiDAR point cloud augmented by layer-based accumulation for intelligent vehicles[J]. Expert Systems with Applications, 2021,167: 113861.
[5]Zermas D, Izzat I, Papanikolopoulos N. Fast segmentation of 3D point clouds: a paradigm on LiDAR data for autonomous vehicle app-lications[C]//Proc of IEEE International Conference on Robotics and Automation. Piscataway, NJ: IEEE Press, 2017: 5067-5073.
[6]Yu Tan, Meng Jingjing, Yuan Junson. Multiview harmonized bilinear network for 3D object recognition[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2018:186-194.
[7]Siddharth C, Narayanan P. Visibility probability structure from SfM datasets and applications[C]//Proc of European Conference on Computer Vision. Berlin:Springer, 2012: 130-143.
[8]Irschara A, Zach C, Frahm J M, et al. From structure-from-motion point clouds to fast location recognition[C]//Proc of IEEE Computer Society Conference.Piscataway, NJ: IEEE Press,2009:2599-2606.
[9]Gao Xiaoshan, Hou Xiaorong, Tang Jingliang, et al. Complete solution classification for the perspective-three-point problem[J]. IEEE Trans on Pattern Analysis & Machine Intelligence, 2003, 25(8): 930-943.
[10]Radenovic F, Tolias G, Chum O. CNN image retrieval learns from BoW: unsupervised fine-tuning with hard examples[C]//Proc of European Conference on Computer Vision.Cham:Springer,2016:3-20.
[11]Qiang Hao, Rui Cai, Zhi Weili, et al. 3D visual phrases for landmark recognition[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press, 2012: 214-223.
[12]王静, 金玉楚, 郭苹, 等. 基于深度学习的相机位姿估计方法综述[J]. 计算机工程与应用, 2023, 59(7): 1-14. (Wang Jing, Jin Yuchu, Guo Ping, et al. Survey of camera pose estimation methods based on deep learning[J]. Computer Engineering and Applications, 2023, 59(7): 1-14.)
[13]Kendall A, Grimes M, Cipolla R. PoseNet: a convolutional network for real-time 6-DoF camera relocalization[C]//Proc of IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE Press, 2015: 2938-2946.
[14]陈宗海, 裴浩渊, 王纪凯, 等. 基于单目相机的视觉重定位方法综述[J]. 机器人, 2021, 43(3): 373-384. (Chen Zonghai, Pei Haoyuan, Wang Jikai, et al. Survey of monocular camera based visual relocalization[J]. Robot, 2021, 43(3): 373-384.)
[15]Shavit Y, Ferens R. Introduction to camera pose estimation with deep learning[EB/OL]. (2019-07-08). https://arxiv.org/abs/1907.05272.
[16]Wu Zhirong, Song Shuran, Khosla A, et al. 3D ShapeNets: a deep representation for volumetric shapes[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2015: 1912-1920.
[17]Kalogerakis E, Averkiou M, Maji S, et al. 3D shape segmentation with projective convolutional networks[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2017: 3779-3788.
[18]Riegler G, Osman U A, Geiger A. OctNet: learning deep 3D representations at high resolutions[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2017: 3577-3586.
[19]Klokov R, Lempitsky V. Escape from cells: deep Kd-networks for the recognition of 3D point cloud models[C]//Proc of IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2017: 863-872.
[20]Su Hang, Maji S, Kalogerakis E, et al. Multiview convolutional neural networks for 3D shape recognition[C]//Proc of IEEE Internatio-nal Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2015: 945-953.
[21]Ma Chao, Guo Yulan, Yang Jungang, et al. Learning multiview representation with LSTM for 3D shape recognition and retrieval[J]. IEEE Trans on Multimedia, 2018, 21(5): 1169-1182.
[22]Hartley R, Zisserman A. Multiple view geometry in computer vision[M]. Cambridge: Cambridge University Press, 2003.
[23]Glocker B, Izadi S, Shotton J, et al. Realtime RGB-D camera relocalization[C]//Proc of IEEE International Symposium on Mixed and Augmented Reality. Piscataway,NJ:IEEE Press, 2013: 173-179.
[24]Maddern W, Pascoe G, Linegar C, et al. 1 year, 1000 km: the Oxford RobotCar dataset[J]. International Journal of Robotics Research, 2017,36(1): 3-15.
[25]Huang Xinyu, Wang Peng, Cheng Xinjing, et al. The ApolloScape open dataset for autonomous driving and its application[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2019, 42(10): 2702-2719.
[26]Taira H, Okutomi M, Sattler T, et al. InLoc: indoor visual localization with dense matching and view synthesis[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2018: 7199-7209.
[27]Sattler T, Maddern W, Toft C, et al. Benchmarking 6DoF outdoor visual localization in changing conditions[C]//Proc of IEEE Confe-rence on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2018: 8601-8610.
[28]Walch F, Hazirbas C, Leal-Taixe L, et al. Image-based localization using LSTMs for structured feature correlation[C]//Proc of IEEE International Conference on Computer Vision. Piscataway,NJ:IEEE Press, 2017: 627-637.
[29]Valentin J, Dai A, Niener M, et al. Learning to navigate the energy landscape[C]//Proc of the 4th International Conference on 3D Vision. Piscataway,NJ:IEEE Press, 2016: 323-332.
[30]Cordts M, Omran M, Ramos S, et al. The cityscapes dataset for semantic urban scene understanding[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2016: 6-8.
[31]Fischler M A, Bolles R C. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography[J].Communications of the ACM, 1981,24(6):381-395.
[32]Dániel B, Noskova J, Matas J. MAGSAC: marginalizing sample consensus[C]//Proc of Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2019: 10197-10205.
[33]Lebeda K, Matas J, Chum O. Fixing the locally optimized RANSAC[C]//Proc of British Machine Vision Conference. 2012.
[34]Philbin J, Chum O, Isard M, et al. Lost in quantization:improving particular object retrieval in large scale image databases[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2008: 1-8.
[35]Sattler T, Havlena M, Radenovic F, et al. Hyperpoints and fine vocabularies for large scale location recognition[C]//Proc of IEEE International Conference on Computer Vision. Piscataway,NJ:IEEE Press, 2015: 2102-2110.
[36]Mikulik A, Perdoch M, Ondrˇej C, et al. Learning vocabularies over a fine quantization[J]. International Journal of Computer Vision, 2013, 103(1): 163-175.
[37]Liu Liu, Li Hongdong, Dai Yuchao. Efficient global 2D-3D matching for camera localization in a larges-cale 3D map[C]//Proc of IEEE International Conference on Computer Vision. Piscataway,NJ:IEEE Press, 2017: 2372-2381.
[38]Lowe D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60: 91-110.
[39]Bay H, Ess A, Tuytelaars T, et al. Speededup robust features (SURF)[J]. Computer Vision and Image Understanding, 2008, 110(3): 346-359.
[40]DeTone D, Malisiewicz T, Rabinovich A. SuperPoint: self-supervised interest point detection and description[C]//Proc of IEEE Confe-rence on Computer Vision and Pattern Recognition Workshops. Piscataway,NJ:IEEE Press, 2018: 224-236.
[41]Tian Yurun, Yu Xin, Fan Bin, et al. SoSNet: second order similarity regularization for local descryiptor learning[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2019: 11008-11017.
[42]Cho M, Lee J, Lee K M. Reweighted random walks for graph matching[C]//Proc of the 11th European Conference on Computer Vision. Berlin:Springer, 2010: 492-505.
[43]Cho M, Lee K M. Progressive graph matching: making a move of graphs via probabilistic voting[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2012: 398-405.
[44]Wang Qianqian, Zhou Xiaowei, Hariharan B, et al. Learning feature descriptors using camera pose supervision[C]//Proc of European Conference on Computer Vision.Berlin: Springer, 2020: 757-774.
[45]Dusmanu M, Rocco I, Pajdla T, et al. D2-Net: a trainable CNN for joint description and detection of local features[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2019: 8092-8101.
[46]Luo Zixin, Zhou Lei, Bai Xuyang, et al. ASLFeat: learning local features of accurate shape and localization[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2020: 6589-6598.
[47]Tian Yuren, Balntas V, Ng T, et al. D2D: keypoint extraction with describe to detect approach[C]//Proc of the 15th Asian Conference on Computer Vision.Berlin:Springer, 2020:223-240.
[48]Kesorn K, Poslad S. An enhanced bag of visual word vector space model to represent visual content in athletics images[J]. IEEE Trans on Multimedia, 2011, 14(1): 211-222.
[49]Amato G, Bolettieri P, Falchi F, et al. Large scale image retrieval using vector of locally aggregated descriptors[C]//Proc of Similarity Search and Applications: 6th International Conference. 2013: 245-256.
[50]Revaud J, Almazán J, Rezende R S, et al. Learning with average precision: training image retrieval with a listwise loss[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway,NJ:IEEE Press, 2019: 5107-5116.
[51]Teichmann M, Araujo A, Zhu Menglong, et al. Detect-to-retrieve: efficient regional aggregation for image search[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2019: 5109-5118.
[52]Husain S S, Bober M. REMAP: multi-layer entropy-guided pooling of dense CNN features for image retrieval[J]. IEEE Trans on Image Processing, 2019, 28(10): 5201-5213.
[53]Sarlin P E, Cadena C, Siegwart R, et al. From coarse to fine: robust hierarchical localization at large scale[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2019: 12708-12717.
[54]Zhou Qunjie, Sattler T, Pollefeys M, et al. To learn or not to learn: visual localization from essential matrices[C]//Proc of IEEE International Conference on Robotics and Automation. Piscataway,NJ:IEEE Press, 2022: 3319-3326.
[55]Brachmann E, Krull A, Nowozin S. et al. DSAC-differentiable RANSAC for camera localization[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2017: 6684-6692.
[56]Brachmann E, Rother C. Learning less is more-6D camera localization via 3D surface regression[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2018: 4654-4662.
[57]Cai Ming, Zhan Huangying, Weerasejera W S, et al. Camera relocali-zation by exploiting multi view constraints for scene coordinates regression[C]//Proc of IEEE/CVF International Conference on Computer Vision Workshops. Piscataway,NJ:IEEE Press, 2019: 3769-3777.
[58]Li Xiaotian, Wang Shuzhe, Zao Yi, et al. Hierarchical scene coordinate classification and regression for visual localization[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2020: 11983-11992.
[59]Zhou Lei, Luo Zixin, Shen Tianwei, et al. KFNet: Learning temporal camera relocalization using Kalman filtering[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2020: 4919-4928.
[60]Tang Shitao, Tang Chengzhou, Huang Rui, et al. Learning camera localization via dense scene matching[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2021: 1831-1841.
[61]Brachmann E, Rother C. Visual camera relocalization from RGB and RGB-D images using DSAC[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2022, 44(9): 5847-5865.
[62]Yan Qi, Zheng Jianhao, Reding S, et al. CrossLoc: scalable aerial localization assisted by multi-modal synthetic data[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2022: 17358-17368.
[63]王静, 胡少毅, 郭苹, 等. 改进场景坐标回归网络的室内相机重定位方法[J]. 计算机工程与应用, 2023, 59(15): 160-168. (Wang Jing, Hu Shaoyi, Guo Ping. et al. Indoor camera relocation method based on improved scene coordinate regression network[J]. Computer Engineering and Applications, 2023, 59(15): 160-168.)
[64]Bui T B, Tran D T, Lee J H. Fast and light weight scene regressor for camera relocalization[EB/OL]. (2022).https://arxiv.org/abs/2212. 01830.
[65]Naseer T, Burgard W. Deep regression for monocular camera-based 6-DoF global localization in outdoor environments[C]//Proc of IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway,NJ:IEEE Press, 2017: 1525-1530.
[66]Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[EB/OL]. (2014). https://arxiv.org/abs/1409. 1556.
[67]Melekhov I, Ylioinas J, Kannala J, et al. Image-based localization using hourglass networks[C]//Proc of IEEE International Conference on Computer Vision Workshops. Piscataway,NJ:IEEE Press, 2017: 879-886.
[68]He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep residual learning for image recognition[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2016: 770-778.
[69]Kendall A, Cipolla R. Geometric loss functions for camera pose regression with deep learning[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2017: 5974-5983.
[70]Kendall A, Cipolla R. Modelling uncertainty in deep learning for camera relocalization[C]//Proc of IEEE International Conference on Robotics and Automation. Piscataway,NJ:IEEE Press, 2016: 4762-4769.
[71]Bui M, Baur C, Navab N, et al. Adversarial networks for camera pose regression and refinement[C]//Proc of IEEE/CVF International Conference on Computer Vision Workshops. Piscataway,NJ:IEEE Press, 2019: 3778-3787.
[72]Huang Zhaoyang, Xu Yan, Shi Jianping, et al. Prior guided dropout for robust visual localization in dynamic environments[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway,NJ:IEEE Press, 2019: 2791-2800.
[73]Wang Bing, Chen Changhao, Lu C X, et al. AtLoc: attention guided camera localization[C]//Proc of AAAI Conference on Artificial Intelligence. Palo Alto, CA:AAAI Press, 2020: 10393-10401.
[74]Chidlovskii B, Sadek A. Adversarial transfer of pose estimation regression[C]//Proc of European Conference on Computer Vision. Berlin:Springer-Varlag,2020: 646-661.
[75]Sarlin P E, Unagar A, Larsson M, et al. Back to the feature: lear-ning robust camera localization from pixels to pose[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2021: 3247-3257.
[76]Chen Shuai, Li Xinghui, Wang Zirui, et al. DFNet: enhance absolute pose regression with direct feature matching[C]//Proc of European Conference on Computer Vision. Cham: Springer, 2022: 1-17.
[77]Melekhov I, Ylioinas J, Kannala J, et al. Relative camera pose estimation using convolutional neural networks[C]//Proc the 18th International Conference on of Advanced Concepts for Intelligent Vision Systems. Cham:Springer, 2017: 675-687.
[78]Brahmbhatt S, Gu J, Kim K, et al. Geometry-aware learning of maps for camera localization[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2018: 2616-2625.
[79]Balntas V, Li Shuda, Prisacariu V. RelocNet: continuous metric learning relocalisation using neural nets[C]//Proc of European Conference on Computer Vision.Cham:Springer, 2018: 751-767.
[80]Rader N, Bausano M, Richards J E. On the nature of the visual-cliff-avoidance response in human infants[J]. Child Development, 1980,51(1): 61-68.
[81]Toft C, Olsson C, Kahl F. Long-term 3D localization and pose from semantic labellings[C]//Proc of IEEE International Conference on Computer Vision Workshops. Piscataway,NJ:IEEE Press, 2017: 650-659.
[82]Bilen H, Vedaldi A. Universal representation: the missing link between faces, text, planktons, and cat breeds[EB/OL]. (2017). https://arxiv.org/abs/1701. 07275.
[83]Yu Bo, Lane I. Multi-task deep learning for image understanding[C]//Proc of the 6th International Conference of Soft Computing and Pattern Recognition. Piscataway,NJ:IEEE Press, 2014: 37-42.
[84]Rahmatizadeh R, Abolghasemi P, Blni L, et al. Vision-based multi-task manipulation for inexpensive robots using end-to-end lear-ning from demonstration[C]//Proc of IEEE International Conference on Robotics and Automation. Piscataway,NJ:IEEE Press, 2018: 3758-3765.
[85]Valada A, Radwan N, Burgard W. Deep auxiliary learning for visual localization and odometry[C]//Proc of IEEE International Confe-rence on Robotics and Automation. Piscataway,NJ:IEEE Press, 2018: 6939-6946.
[86]Radwan N, Valada A, Burgard W. VlocNet+: deep multitask lear-ning for semantic visual localization and odometry[J]. IEEE Robo-tics and Automation Letters, 2018, 3(4): 4407-4414.
[87]Lin Yimin, Liu Zhaoxiong, Huang Jianfeng, et al. Deep global-relative networks for end-to-end 6-DoF visual localization and odometry[EB/OL]. (2018). https://arxiv.org/abs/1812.07869.
[88]Tian Mi, Nie Qiong, Shen Hao. 3D scene geometry-aware constraint for camera localization with deep learning[C]//Proc of IEEE International Conference on Robotics and Automation. Piscataway,NJ:IEEE Press, 2020: 4211-4217.
[89]Chen Hongrui, Xiong Yuan, Wang Jingru, et al. Long term visual localization with semantic enhanced global retrieval[C]//Proc of the 17th International Conference on Mobility, Sensing and Networking. Piscataway,NJ:IEEE Press, 2021: 319-326.
[90]Ding Mingyu, Wang Zhe, Sun Jiankai, et al. CamNet: coarse-to-fine retrieval for camera relocalization[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway,NJ:IEEE Press, 2019: 2871-2880.
