
3D场景渲染技术
2024-08-15 00:00韩开徐娟
计算机应用研究 2024年8期









摘 要:神经辐射场(NeRF)是一种面向三维隐式空间建模的深度学习模型,在表示和渲染三维场景领域具有重要价值。然而由于神经辐射场算法训练过程复杂、需要大量的计算资源和时间等,其可用性和实用性受到一定限制,如何针对神经辐射场的痛点问题进行优化是当前计算机视觉等领域研究的热点之一。此研究旨在对神经辐射场的优化和应用进行全面综述。首先,在深入解析神经辐射场基本原理的基础上,从渲染质量、计算复杂度、位姿等方面对现阶段神经辐射场的优化情况进行概述;其次,列举神经辐射场应用状况,为未来更高效和实用的算法优化设计提供参考;最后,总结神经辐射场的优势与局限性,并提出未来可能的发展方向,以期发挥神经辐射场在三维渲染、场景合成等方面的巨大潜力。
关键词:神经辐射场; 神经渲染; 三维场景; 深度学习
中图分类号:TP399 文献标志码:A
文章编号:1001-3695(2024)08-002-2252-09
doi:10.19734/j.issn.1001-3695.2023.11.0551
Comprehensive review of 3D scene rendering technique-neural radiance fields
Han Kai, Xu Juan
(School of Information Science, Beijing Language University, Beijing 100083, China)
Abstract:NeRF is a deep learning model aimed at modeling three-dimensional implicit spaces, and it holds significant value in the representation and rendering of 3D scenes. However, due to the complex training process, substantial computational resources, and time requirements, the usability and practicality of the NeRF algorithm are somewhat limited. Addressing the pain points of NeRF optimization has become a hot topic in the field of computer vision. This paper aimed to provide a comprehensive review of the optimization and application of NeRF. Firstly, it delved into the basic principles of NeRF and outlined the current optimization status from the perspectives of rendering quality, computational complexity, and pose. Secondly, it enumerated the application scenarios of NeRF to provide references for future, more efficient and practical algorithmic optimizations. Finally, it summarized the strengths and limitations of NeRF and proposed potential future directions tailored to harness the tremendous potential of NeRF in 3D rendering, scene synthesis, and beyond.
Key words:neural radiance fields(NeRF); neural rendering; 3D scene; deep learning
0 引言
近年来,虚拟现实(virtual reality,VR)和增强现实(augmented reality,AR)等技术引发了虚实结合的浪潮,人们对于在线教育、远程办公和数字文娱等需求逐渐增加,使VR/AR行业呈现出快速增长的态势。特别是2021年元宇宙(Metaverse)[1]概念引爆全球,构建高质量的虚拟镜像世界需要大量的数据、算力和算法的支持。然而,目前VR/AR资源较少,构建方式往往采用人工或三维重建的方式,较为复杂。其中三维重建通过对拍摄的多张照片进行分析匹配,构建相应的三维模型[2],传统三维重建的关键技术主要包括激光扫描法、结构光法、Kinect技术和单目视觉等,按照是否主动向场景中发射光源分为主动式和被动式[3]。主动式通过传感器主动向物体照射光源,依靠解析返回的信号来获得物体的三维信息;被动式不使用任何其他能量,依靠多视图几何原理基于视差进行计算。
随着深度学习技术的迅猛发展,研究者开始探索利用神经网络来解决三维场景重建和图像合成的问题。为了摆脱传统体积渲染的束缚,神经辐射场应运而生。神经辐射场是一种新兴的机器学习方法,最早出现在2020年ECCV会议上,由Mildenhall等人[4]提出。自该文发表以来,神经辐射场引起了计算机科学与技术领域的广泛关注,特别是在计算机视觉领域掀起了研究热潮,对计算机图形学、虚拟现实和增强现实等领域均产生了积极影响,是一项具有极大研究潜力的技术[5,6]。在Google Scholar上搜索2020年1月至2023年11月神经辐射场有关论文达1万余篇,引用量已超6 000次,ICCV、ECCV等学术会议中都收录了大量关于神经辐射场的高质量论文。可见,神经辐射场已然成为国内外图形图像领域学术研究重要关注的内容。
然而,在技术应用过程中,神经辐射场训练一次需要100 k~300 k次迭代,完成一个三维场景需要构建大量的物体,采用当前的训练模式无法有效运用在下游产业中。同时,神经辐射场大量的神经网络运算导致其渲染速度缓慢,种种因素制约了神经辐射场在实际场景中的应用。为使神经辐射场能够更好地发挥其价值,学界开始了对神经辐射场技术的优化研究,这些研究成果对更好地发挥神经辐射场具有重要借鉴意义。鉴于此,本文将从全面介绍神经辐射场方法的基本原理出发,针对神经辐射场优化技术进行分析,并从实际应用情况进行概述,旨在对当前神经辐射场的发展情况进行总结,从而探索其在渲染技术和相关领域中的潜力和未来可能的研究方向,为后续进一步优化研究提供有益参考。
1 神经辐射场的基本原理
神经辐射场是一种高质量场景重建技术,它能够表示场景的三维结构,从而实现新视角的视图合成[4]。神经辐射场的主要任务是在已知视图的视角下生成未知视角的图像,基本形式是将三维场景表示为神经网络近似的辐射场,并从二维图像中重建出逼真高质量的三维场景,本质上也是一种基于深度学习的机器学习方法。下文将从神经辐射场基本架构、渲染和训练这三个主要方面展开,深入阐释神经辐射场方法的基本原理。
1.1 神经辐射场的基本架构
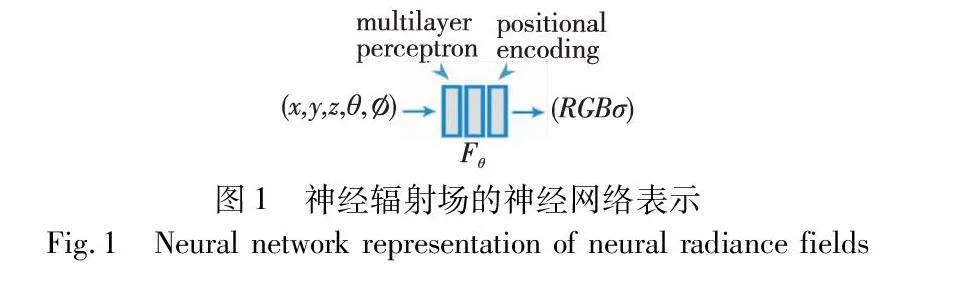
神经辐射场引入了辐射场的概念,指在空间中每个点上的颜色和辐射强度的分布,这里每个点的辐射信息可以表示为一个连续的函数,以此获取这个辐射场包含在任意空间点处的颜色、密度等属性信息。在实际训练中,使用基于神经网络的隐式表示方法来表示场景的辐射场,这是因为相较于显式表示方法,隐式表示方法无须显式存储场景的几何形状和材质,能进行无限的分辨率渲染,并且使用神经网络可以从训练数据中学习场景的复杂性和多样性。神经辐射场的基本架构主要包括位置编码和多层感知机。
1.1.1 位置编码
在传统的MLP网络中,由于其局限性,较难有效学习和表示颜色、纹理和光照等高频数据的细节。但场景中的颜色纹理信息通常具有高频成分,如果直接使用MLP网络对场景进行学习,可能会导致习得的纹理表面变得相当模糊。
为了解决这一问题,神经辐射场引入了位置编码(positional encoding)[7]的概念。位置编码函数采用与Transformer 中类似正余弦周期函数的形式,在不同频域上对位置进行编码,允许MLP网络同时学习场景中的高低频信息,以提高对细节的捕捉能力。位置编码主要用于提升MLP网络对场景中高频信息的捕捉能力,类似于傅里叶变换,利用高频函数将低维空间的数据输入映射到高维空间,以增加网络对高频数据的敏感性[8]。神经辐射场能够采用位置编码将输入的空间位置(x,y,z)和观察方向(θ,)映射到高维空间,实现高频信息的有效拟合,提高生成图像的清晰度。
1.1.2 多层感知机
神经辐射场通常使用多层感知机(multilayer perceptron,MLP)来学习一个三维场景颜色、密度等物理属性,MLP是一个由多个全连接的隐藏层组成的深度神经网络,可以作为通用函数近似器表示表面或体积属性[4]。其中每个隐藏层中的神经元与前一层中的所有神经元相互连接,通过非线性变换将输入映射到输出,再通过输出层的神经元输出对应的属性。
神经辐射场使用Fθ(x,d)→(c,σ)两个独立的MLP来分别表示场景中每个点的辐射颜色和密度。具体操作步骤如下:首先,将输入数据x(即x,y,z)传入第一个MLP网络,经过一系列的非线性变换和激活函数后,得到对应的中间特征和σ(即对应点的密度);接着,将中间特征和d(即观察视角)再次输入到另一个全连接层中,并预测场景中的颜色c,由此得到对应点的颜色和密度值。
如图1所示,神经网络的输入是连续的5D坐标,包括空间点坐标(x,y,z)和观察方向(θ,),共计五个变量[4],经过位置编码和多层感知机的处理,输出对应点的颜色(r,g,b)和体积密度。整个过程需要在场景中进行大量空间点的采样并进行预测,使神经辐射场从不同视角合成出逼真的连续视角图像,实现对场景的渲染任务。可以通过限制颜色的预测,保持多视图之间的一致性,使得神经辐射场能够根据不同视角下的光照效果生成不同的图像。结合MLP的能力,神经辐射场能够模拟逼真的场景,并有效提升生成图像的画面质量。它可以通过捕捉复杂的非线性关系,有效进行建模,从而实现后续高质量的图像渲染效果。
1.2 图像渲染
在渲染阶段,神经辐射场使用了体积渲染方法[9],通过光线和场景点的采样预测颜色和密度,并将其累积到最终的合成图像中。体积渲染是一种将三维场景转换为二维图像的技术,具体到神经辐射场中来说,当给定不同视角的相机姿态后,可以计算出特定像素坐标的颜色。
具体实现步骤为:通过对采样点或途经点(即相机光心发出的一条射线经过要计算颜色的像素坐标,并穿过场景中的各个点)的颜色值累加,可以得到该像素的最终颜色。在这个过程中,通过渲染方程对每个途经点进行递归计算,能够获取途经点到相机位置的颜色值,具体体现在渲染方程中
(γ)=∫tftnT(t)σ(r(t))c(r(t),d)dt(1)
其中:c表示颜色;σ表示密度;r表示相机发出射线上的距离;d表示相机射线上的方向;t则表示在相机射线上采样点到相机光心的距离;dt表示光线在每一步积分的微分距离。这里一条射线上的点是连续的,因此射线的颜色可以由积分得到。T(t)是射线从tn到t这一段路径上的光线累积透明度,可以理解为这条射线从tn到t没有击中任何粒子的概率。在方程中,累积的体积密度σ越大,T(t)的值越小,有效降低了遮挡对该位置颜色的影响。
考虑到一条射线上大部分区域都是空区域或被遮挡的区域,对最终颜色的贡献值较小,神经辐射场中采用了一种优化策略分层体素渲染[4],通过对不同区域分别进行粗采样和细采样的方式来减少计算开销。在粗采样阶段,神经辐射场使用较为稀疏的采样点,在起点和终点之间均匀采样Nc个点。这些粗采样的点用于计算体素的密度和颜色值。对于得到的粗采样点,神经辐射场通过归一化权重进行分段常数概率密度函数的构建,并使用逆变换方法对粗采样的点进行二次采样,以此得出更多的细采样点。通过将这些细采样点与原有的粗采样点一起采样,减小估算积分式的计算开销,加快训练速度。
1.3 神经辐射场的训练
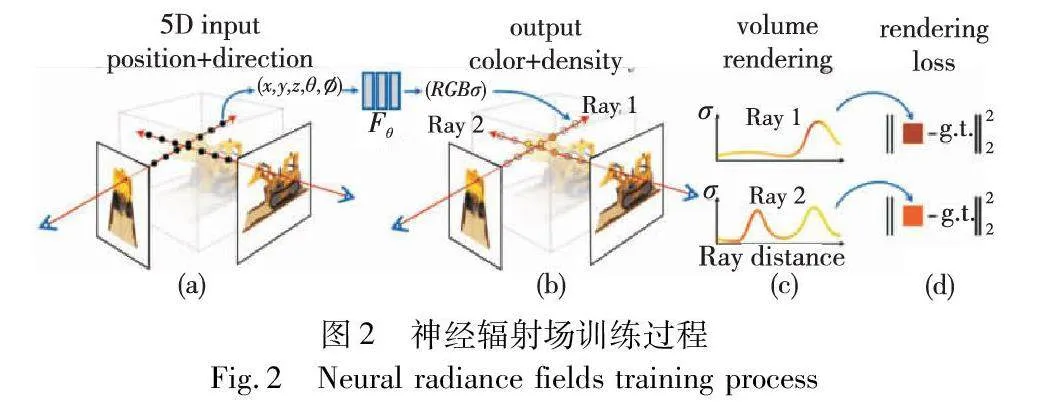
总的来说,神经辐射场的训练过程包括数据准备、射线采样、场景表示预测、渲染图像生成和损失函数计算几个步骤,如图2所示。
收集准备用于训练的场景数据是训练的基础,数据包括多个角度下拍摄的图像以及相机姿态信息。一些常见的神经辐射场数据集通常会涵盖不同类型的场景,包括LLFF、360_v2和Objectron[10]等。其次,需要完成对多视角图像的射线采样,这里的一条射线对应最终图片的一个像素,找到射线与场景的若干个交点,这些采样点将作为MLP的输入完成后续的训练。想要确定射线,离不开对相机位姿的确认,可以利用SFM(structure from motion)方法[11]进行相机位姿的生成。
接着,将每个采样点的3D坐标和观察位置输入到神经网络中,通过一系列非线性变换和激活函数,产生该位置的密度值和颜色值。利用体积渲染技术,沿着光线路径对密度和颜色值进行插值[12]和融合,以计算出每个像素的颜色值。
因为体积渲染函数是可微的,可以通过计算渲染生成的图像与真实图像之间的差异,使用损失函数进行比较,从而对神经辐射场的场景表示进行迭代优化。这里的损失函数可以用于衡量生成图像和真实图像中每个像素RGB值之间的差异。通过整个训练过程,使得神经辐射场可以在之前未见过的视角下生成逼真的图像。
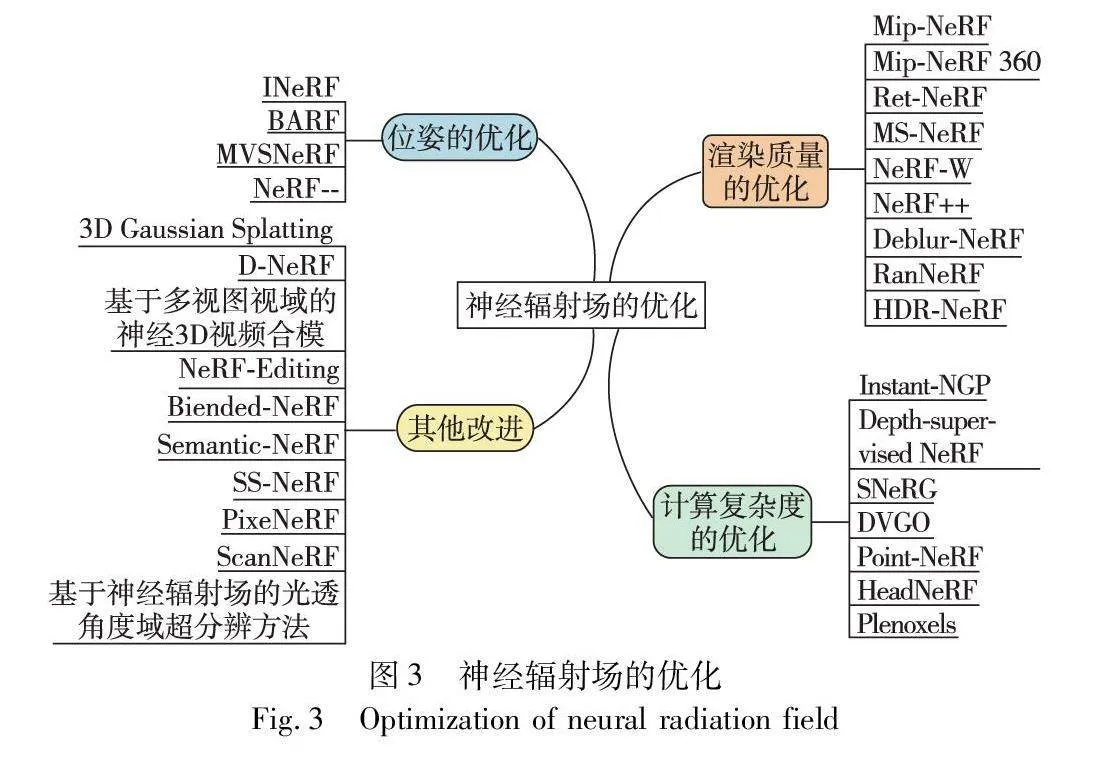
2 神经辐射场的优化
神经辐射场能较好地和现有的图像内容理解方法兼容,能够不受网格限制更好地处理场景细节和纹理,并且可以在不同视角下生成高质量的图像。但同时,神经辐射场的训练和渲染往往需要大量的计算资源和时间,使得研究者需要从渲染质量、计算复杂度、位姿优化等多个方面不断尝试优化和改进神经辐射场算法。为了更加透彻地了解作为神经隐式表征突出代表的神经辐射场技术的应用潜力,如图3,本章围绕现阶段神经辐射场的优化,从渲染质量、渲染速度、位姿、可编辑场景等优化方法出发,对相关研究成果进行系统梳理和总结。
2.1 关于渲染质量的优化
渲染质量是评判神经辐射场技术好坏的重要指标,影响着后续的研究工作。研究者们大多将精力集中于优化和提升生成的三维空间的渲染质量上。以下模型皆致力于提升合成视图的渲染图像质量。
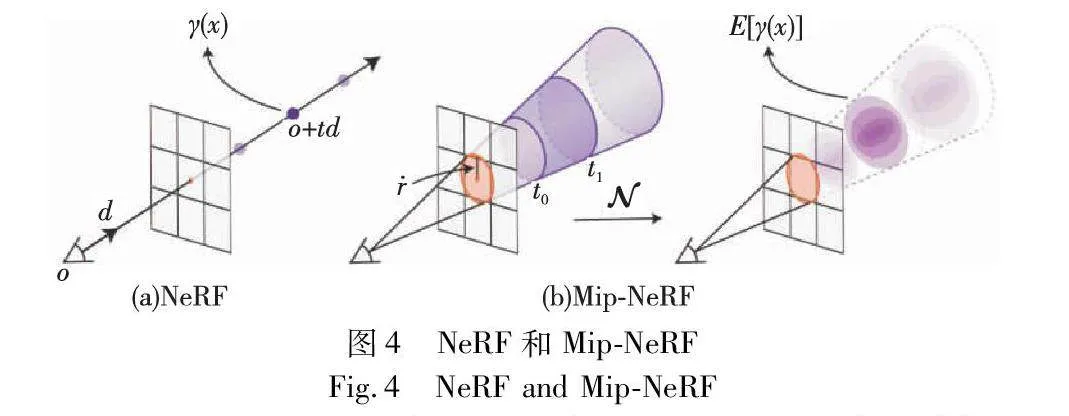
Mip-NeRF[13]是一种减少图像锯齿神经辐射场的多尺度表示方法,如图4所示,相较于传统神经辐射场的表示方法,它提出利用锥追踪(cone tracing)[14]来完成光线追踪,改善了神经辐射场投出光线产生混叠的问题,显著提高了神经辐射场呈现精细细节的能力。不同于传统的光线追踪,该方法通过有效地渲染圆锥体,构建了每个圆锥体覆盖体积的综合位置编码,从而降低了混叠出现,显著提高了神经辐射场呈现细节精细度的能力。
Mip-NeRF在渲染场景时能够展现更加清晰、平滑的图像效果,并减少了图像锯齿现象,使得渲染结果更加逼真。同时,Mip-NeRF在性能方面也有所提升,相较于传统神经辐射场,其渲染速度提高了约7%的同时,还能将模型的大小减半,节约了存储空间。但Mip-NeRF存在一定的缺点,它的效果实现需要准确标定相机位姿,只有当收集图片质量高且相机姿态准确时,它才能呈现良好的效果,否则容易因为拍摄过程中出现的运动模糊等噪声受到影响,后续的工作在一定程度上对此问题进行了优化。
针对应用于无界场景表现不佳的问题,Barron等人[15]提出一种无边界抗锯齿神经辐射场Mip-NeRF 360,它是Mip-NeRF的扩展,使用非线性场景参数化、在线蒸馏和基于失真的正则化器来克服无界场景问题。与Mip-NeRF相比,它减少了57%的均方误差。
Ref-NeRF[16]建立在Mip-NeRF的基础上,用反射亮度取代了神经辐射场中参数化视相关的出射亮度,并采用一组空间变化场景属性构造函数,提出了一种新的关于视相关辐射值的参数化和结构化方式,对法向量提出新的正则化。这些操作能让MLP在上面更好地插值,主要解决了合成中的高光和反光问题。
为解决神经辐射场在多尺度的视图合成任务中产生模糊和锯齿的问题,范腾等人[17]提出了多尺度神经辐射场(MS-NeRF)方法,该方法通过在多尺度视图合成任务过程中引入不同尺度场景下稀疏的视图特征和视点特征作为先验信息,并利用浅层的残差块网络对深层网络进行监督,从而提高了合成视图的视觉效果。
NeRF-W[18]是一种神经辐射场的扩展,通过放宽严格一致性的假设来处理实际场景中的复杂性和多样性。其主要技术点包括采用自监督学习方法来学习如何将非结构化网络照片集转换为3D场景表示,通过比较渲染图像与实际图像之间的差异来学习场景的外观和结构。这种方法允许在渲染图像中出现一些不一致性,但需要在可接受的范围内。NeRF-W能够更好地处理实际场景中的复杂性和多样性,从而提高了3D场景重构的精度和质量。
NeRF++方法[19]引入了自适应采样策略和分层网络结构,使用球体分离场景,为未绑定场景生成新的视图,它主要训练了两个独立的神经辐射场模型,一个用于球体内部,一个用于球体外部,使用这种训练方法将原始的神经辐射场扩展,实现了远景渲染质量的提高。对渲染质量优化方法的总结及对比如表1所示。
上述各项提升NeRF渲染质量的优化技术都对渲染质量有一定的提升,且各有其优势和不足。在神经辐射场基础上,目前Mip-NeRF对于后续的进一步研究最具影响力,它提出了锥形追踪,减少了锯齿伪影,Ref-NeRF实现效果同样十分优秀。除此之外,Deblur-NeRF[20]使用了一个新颖的可变形稀疏核模块,实现了模糊输入恢复清晰的效果,使神经辐射场对模糊输入具有鲁棒性。具体应用到图像处理方向,RawNeRF[21]和HDR-NeRF[22]同样展现了创新的一面。然而,究其本质,神经辐射场离不开对渲染高清视图的需求,当前研究尽管在一定程度上提高了渲染质量,但在实际应用的过程中仍可能面临成本过高等现实问题,除了注重渲染质量的提升以外,还应平衡成本与效益的关系,以真正实现NeRF的落地应用。
2.2 关于计算复杂度的优化
原始版神经辐射场需要100张左右的图片进行训练,随着计算复杂度的改进,现有模型只需要几张图像几秒钟就可以进行高质量重建。Instant-NGP[23]模型极大地提高了神经辐射场模型的训练速度,如图5所示,原先一个场景训练需要几个小时,Instant-NGP只要几秒钟就可以完成。不同于神经辐射场的MLP,Instant-NGP用体素网格进行哈希编码,这种新的位置编码极大地提高了训练和推理速度。
Depth-Supervised NeRF[24]在原有损失函数的基础上提出了创新,充分利用了现有的深度监督学习方法,并巧妙地利用了运动恢复结构(structure from motion,SFM)将稀疏3D点作为额外的深度监督信号。通过引入这个损失函数,DS-NeRF能够把光线的深度分布与给定的3D关键点相匹配,并且还考虑了深度的不确定性。这种方法在训练过程中仅使用较少的视图就能生成更加优质的图像,并且训练速度提高了2~3倍。此外,DS-NeRF的优势还在于它能够支持多种深度监督形式,如扫描深度传感器和RGBD重建输出。
SNeRG[25]则是一种加速渲染的方法。Hedman等人通过预计算和存储稀疏神经辐射网格来对神经辐射场进行实时渲染,将MLP模型转换成一个稀疏网格模型进行训练,实现30 fps以上的典型神经辐射场场景。但其对含反射和透明场景进行建模时较为困难,需要对每个表面的视图依赖性完成单独建模,这对于城市规模的渲染,将会出现成本过高的情况。
DVGO[26]提出了对网格进行训练加速的方法,采用将场景进行显示体素表达的方法,将神经辐射场的训练时间缩减到半小时以内。Sun等人采用了两个先验算法,通过混合体素阶段跳过了大量无关点的采样,相比于传统神经辐射场,它直接使用三线性插值得出空间点的信息,无须通过MLP,由此实现了加速训练。DVGO测试中得到的结果通常比NeRF好,特别是在一些具有复杂几何的场景上,但对无界场景没有给出处理方法。对以上计算复杂度优化方法的总结及对比如表2所示。
除此之外,Point-NeRF[27]、HeadNeRF[28]和Plenoxels[29]等模型都在高效建模与渲染方面展现出优秀的能力。Point-NeRF用3D点云和神经特征来模拟辐射场进行优化,训练时间大大缩短;HeadNeRF则是将神经辐射场集成到人头的参数表示中,可以实时渲染高保真头部图像,同时通过设计新的损耗项,将一帧的渲染时间从5 s减少到25 ms;Plenoxels通过梯度方法和正则化对校准图像进行优化,是一种全体素用于逼真视图合成的系统,优化速度比神经辐射场快两个数量级。
神经辐射场技术涉及复杂的计算问题,需要高度优化技术来提高计算效率。以上研究从训练和渲染阶段入手,致力于优化神经辐射场的计算复杂度,以提高计算速度和准确性。这些研究取得了一定的进步,但仍然存在一些不足。例如,当使用几张简单的图像进行重建时,如何更好地把控渲染后三维模型的精细度是一项重要的挑战。由此可见,未来在应用神经辐射场进行场景重建时,需要同时考虑渲染质量的提升和计算复杂度的降低,以获得最佳的效果。
2.3 关于位姿的优化
传统神经辐射场的训练建立在已有相机位姿的基础上,通常受到不对准相机位姿训练样本的影响,且在实际应用中存在相机位姿未知的情况,因此,位姿优化的NeRF具有一定的研究价值。部分研究采用NeRF-based SLAM(simultaneously localization and mapping)等方法来优化位姿,并不断尝试与深度学习融合,如下几个关于位姿的优化模型和方法值得关注。
iNeRF[30]是一种用于姿态估计的反向神经辐射场框架,通过固定网络模型优化相机位姿。它可以在没有3D网格模型或深度感应的情况下,仅使用RGB图像作为输入来估计具有复杂几何形状的场景和物体的姿态。通过反转从单一视图推断出的NeRF模型,对RGB图像进行类别级别的物体姿态估计,包括训练期间未见的物体实例。它的优点是可以应用于真实世界的场景和物体,并且可以通过预测更多图像的相机姿态来改善模型。iNeRF可以通过估计新图像的相机姿态,并将这些图像用作NeRF的额外训练数据,从而改善NeRF在复杂真实世界场景(如LLFF数据集)中的性能。
BARF[31]同时优化网络模型和相机位姿,是一种用于训练NeRF的新方法,如图6所示,可以在不准确甚至未知的相机姿势下进行训练。Lin等人[31]发现从粗到细地注册相机帧对NeRF同样适用。BARF可以有效地优化神经场景表征,并解决大型相机姿势的错位问题,为视觉定位系统和未知相机姿势的场景表示提供了新的可能性。
MVSNeRF[32]本质上是一种结合了多视角立体匹配(MVS)和神经辐射场(NeRF)技术的方法。其主要技术点在于利用平面扫描3D成本体积进行几何感知场景理解,通过将附近输入视图的2D图像特征扭曲到参考视图的扫描平面上,在输入参考视图处构建成本体积。该方法进一步微调提速特征和MLP解码器,能够高效地重建复杂的三维场景,并提升泛化能力,使得重建的辐射场可以适用于不同的视角和光照条件。
NeRF--[33]专注于前向场景的新视图合成。与传统神经辐射场方法不同,NeRF--简化了训练过程,摈弃了对已知或预先相机参数的需求。为了实现这一改进,NeRF--提出了三项关键贡献:首先,它将相机参数视为可学习的参数,与神经辐射场模型一同进行联合优化,通过光度重建实现了相机参数的联合优化;其次,为了评估相机参数和新视图渲染质量,引入了一个新的数据集,名为BLEFF(blender forward-facing dataset);最后证明在大多数场景下,联合优化流程能够恢复准确的相机参数。NeRF--技术为新视图合成提供了一种高效、灵活的解决方案,并为相机参数的学习和优化带来了新的视角和进展。
传统神经辐射场的训练依赖于每张图片的相机位姿和内参,因此对于这一阶段的优化也尤为重要。上文列举的各类位姿优化方法较好地解决了相机姿势估计误差问题,总结及对比如表3所示。
2.4 其他优化
学者们除了对神经辐射场在渲染质量、计算复杂度和相机位姿上的改进展开大量研究外,还面向高分辨率实时渲染、动态场景、可编辑NeRF、语义表示、无约束等其他方面的优化问题作出了探讨。针对神经辐射场技术瓶颈的优化,促使更多的研究者发现神经辐射场的可能性,加入优化的队伍,不断促进着视图合成领域的发展。
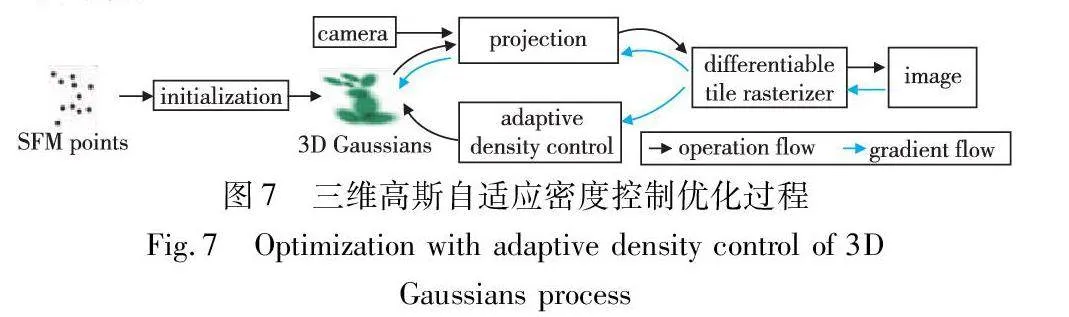
对于无边界和1080p分辨率下无法实现实时渲染的问题,文献[34]提出用3D高斯函数表示场景,这是一种类似于神经辐射场的技术,可以实现在1080p分辨率下的高质量实时渲染。如图7所示,首先,在相机校准过程中生成稀疏点,使用3D高斯函数表示场景,既保留了辐射场的特性,又可以避免在空白区域内不必要的计算;其次,对3D高斯函数进行交错优化/密度控制,特别是通过优化各向异性协方差,以实现对场景的准确表示;最后,开发了一种GPU友好的快速可视性感知渲染算法,该算法支持各向异性飞溅,在加速训练的同时支持实时渲染。
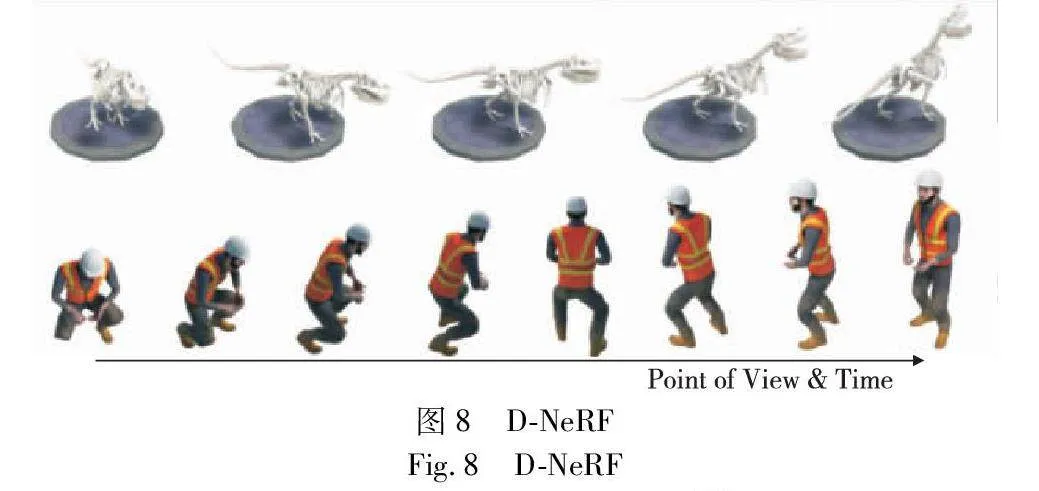
针对神经辐射场只能重建静态场景的技术瓶颈,不少研究致力于将其扩展到动态领域。Pumarola等人[35]提出的D-NeRF可以用于对动态场景的建模和渲染,在单相机围绕场景旋转一周的情况下,重建物体的刚性和非刚性运动,将神经辐射场扩展到动态领域。图8描述了动态场景数据集的构建和训练D-NeRF模型的过程,与静态场景的神经辐射场不同,动态场景中的物体和相机位置可能随时间变化,D-NeRF将时间作为额外输入实现对动态场景的建模,捕捉物体的运动和场景随时间产生的变化,从而控制物体的移动。
基于多视图视频的神经3D视频合成[36]采用时间条件神经辐射场,通过一组紧凑的代码表示场景动态信息。这种方法可以有效地将10台摄像机记录的18 s 30帧/s的多视图视频进行建模,并且模型大小仅为28 MB,实现了高效的动态场景合成与建模。
除高分辨率实时渲染、动态建模外,还存在其他基于神经辐射场劣势的改良。针对神经辐射场无法在场景中执行用户控制的形状变形的情况,NeRF-Editing[37]通过建立显式网格表示和目标场景的隐式神经表示之间的对应关系,使得用户可以对场景的隐式表示进行可控的形状变形,并合成编辑后的场景新视图。这种方法为编辑场景提供了更加直观和灵活的方式,允许用户以交互方式修改场景的外观和形状。近期提出的Blended-NeRF[38]提供了一种全面的框架,能够在场景中进行局部编辑。通过引入预训练模型和3D RoI框以及独特的融合技术和视觉增强方法,显著提高了编辑的效率和质量。
基于神经渲染的无监督连续语义自适应Semantic-NeRF[39]模型首次提出将语义信息加入NeRF,实现了仅依靠少量特定语义标签就能获取准确的语义标注和理解。通过融合分割模型的预测来训练每个场景的Semantic-NeRF模型网络,然后使用视图一致呈现的语义标签作为伪标签来适应模型,如图9所示。由于该模型体积较小,可以储存在长期记忆中,随后可用于从任意角度呈现数据,对正确的语义输出有着重要影响。
SS-NeRF[40]提供了一种新的场景理解方法,能够从新颖的视点渲染逼真的RGB图像,而且还能够渲染各种精确的场景属性。有助于在统一的框架下解决各种场景理解任务,包括语义分割、表面法线估计、重塑、关键点检测和边缘检测。
针对神经辐射场需要大量输入视图的问题,PixelNeRF[41]可以根据一个或少数几个输入图像预测连续的神经场景表示。传统的神经辐射场构建方法涉及对每个场景进行独立的优化,需要大量校准的视图和计算时间。为了解决这些问题,PixelNeRF提出了一个全卷积的架构,将神经辐射场与图像输入进行条件化。这使得网络能够跨多个场景进行训练,学习场景的先验知识,从少数几个视图中以前向传播的方式执行新视图合成。
针对将真实物体转移到虚拟世界的目标,ScanNeRF[42]通过比对三个先进神经辐射场优化技术,提出了一个基准思想来评估神经辐射场和神经渲染框架,并设计了一个可以实现短时间收集对象数千张图像的流程,用于快速扫描真实物体,为促进神经辐射场框架的研究起到了促进作用。
近年来,国内研究者在神经辐射场领域进行了其他方面的优化探索。苗源等人[43]从光场数据采集的角度出发,提出了基于神经辐射场的光场角度域超分辨方法。该方法能够准确表达具有复杂不利条件的光场场景,有效解决了场景高频纹理信息较难拟合的问题,为后续开展光场计算成像研究提供参考。
表4对比了以上优化方法的创新、结果及应用场景。神经辐射场的优化研究涵盖了渲染速度、渲染质量、动态建模、语义分割等各个方面,从传统神经辐射场各个阶段出发,研究者们结合实际,能够发掘出不同的优化方式,从而改进神经辐射场。这些优化工作使得神经辐射场在实际应用中更具有吸引力,为图像渲染和场景重建等领域的发展带来了新的可能性。但往往研究者仅针对某一个方面进行优化,或者融合某两部分完成优化,因其训练成本过高,大部分研究者在入手阶段就“望而却步”,不利于深入实践。因此对神经辐射场各个阶段的前后交融研究十分必要,开源数据集和实际应用使用的技术整理可以帮助未来研究者在某一阶段优化的基础上继续完善,不断发掘神经辐射场的可能性。
3 神经辐射场的应用
每一项新技术的出现,都需要将其应用到实际生活中,以促进便利和改善现有技术的不足。近年来,深度学习技术的快速发展为各个领域带来了革命性的变化,神经辐射场作为其中的一种先进方法,在场景合成和渲染方面展示出巨大潜力。它能够为用户带来沉浸式视觉效果,增强个性化定制,进一步降低人工成本。它的创新思想和技术为许多实际应用领域带来了前所未有的机会,了解神经辐射场应用场景从而探寻未来发展的可能性是十分必要的。本章以神经辐射场实际应用为重点,阐述神经辐射场在计算机视觉、计算机图形学和增强现实等领域的具体应用案例,并介绍了一些相关的研究进展内容。
3.1 自动驾驶
随着科技的不断进步,自动驾驶已经成为社会炙手可热的话题之一。然而,要大规模推广自动驾驶无人车,在前期的开发阶段需要进行多次测试和设置。神经辐射场作为一种高度逼真的场景渲染方法,在场景感知、决策支持等方面发挥着重要作用,在自动驾驶领域具有广泛的应用前景。基于神经辐射场的衍生版本Block-NeRF[44],利用自动驾驶的传感器收集附近街区的环境数据,并合成大规模的逼真3D场景。这种视图合成技术可以实现虚拟和现实场景的实时融合,为自动驾驶系统提供精确的视觉效果。CityNeRF[45]首次尝试将神经辐射场带到城市级规模,捕捉了城市环境的复杂细节和空间变化,为在不同细节级别上的视图渲染提供了强大的解决方案。
如图10所示,除了基本的视图合成,神经辐射场还可以通过改变环境照明条件,模拟一些复杂的路况,包括天气和时间的变化、环境照明变化等情况,帮助自动驾驶提供一个很好的模拟数据,提升导航的稳定性,从而进一步提升模拟驾驶场景的仿真度。
利用神经辐射场技术,自动驾驶系统可以实现对周围环境的实时三维重建,为自动驾驶的定位和导航提供重要的支持。通过不断更新的场景重建模型,系统能够准确定位车辆在场景中的位置,为后续的路径规划和选择提供精确的参考。这种三维重建能力对于自动驾驶的定位和导航非常关键,有助于提高自动驾驶系统的定位准确性。
神经辐射场技术能够协助自动驾驶系统实现对周围障碍物的三维检测和跟踪。通过将实时摄像头图像输入到已训练好的模型中,系统可以获取障碍物的准确三维位置和形状信息,这为自动驾驶系统提供了关键的感知能力,使其能够更好地规避障碍物,确保行驶的安全性和稳定性。
3.2 图像处理
神经辐射场作为一种隐式表示方法,在图像处理方面展现出了很大的发展前景。与传统的图像处理方法依赖于人工设计的提取器不同,神经辐射场采用了一种全新的思路,即从隐式神经表示或神经场的角度来处理图像。例如,RawNeRF[21]能够处理高动态范围(high dynamic range imaging,HDR)图像视图的合成,能够处理具有复杂光照和明暗变化的HDR图像,使得还原夜景照片成为可能。它使用原始线性图像作为训练数据,并在线性颜色空间中进行渲染。这使得RawNeRF能够处理不同曝光和色调映射曲线,从而提供更大的灵活性。它在神经辐射场渲染之后处理,而不是直接使用后处理的图像作为训练数据。然而,与RawNeRF中的原始线性图像相反,HDR-NeRF[22]通过使用可变曝光时间的低动态范围训练图像来接近HDR视图合成,在HDR重建上获得了较高的视觉评估分数。
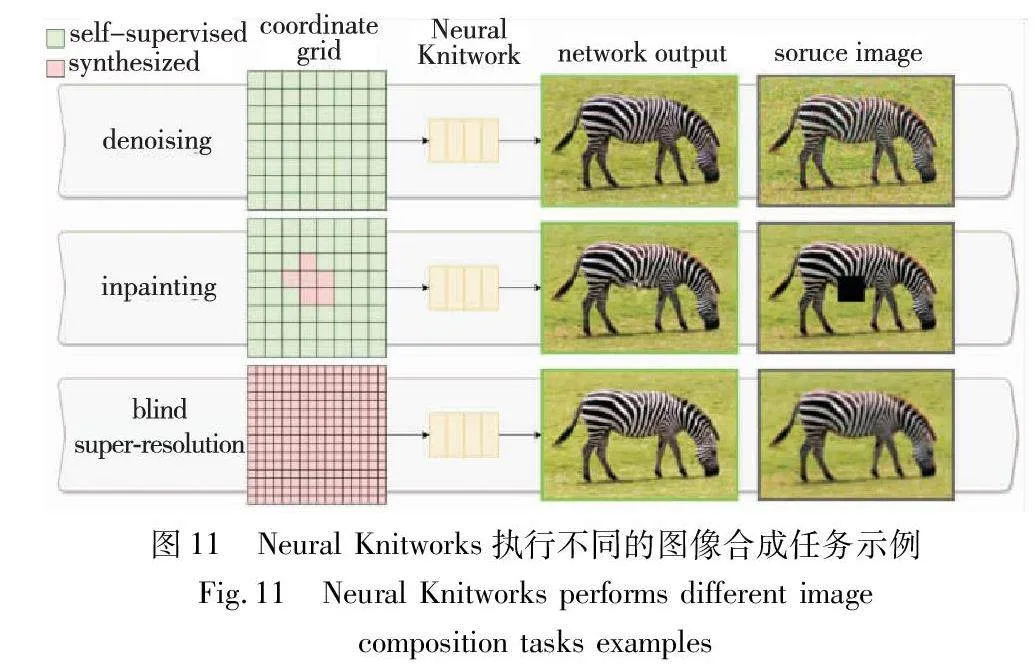
如图11所示,Neural Knitworks[46]在单个样本上训练的模型可以在非常低的内存要求下执行许多不同的图像合成任务。它是一种用于自然图像神经隐式表示学习的体系结构,通过对抗的方式优化图像补丁的分布,能够捕捉图像的特征和结构,并通过增强补丁预测之间的一致性,确保生成的图像在多个任务中都能保持稳定和准确,以此来实现图像合成。
综上,神经辐射场在图像处理方面展现出了在高动态范围图像视图合成、去噪和图像修复等方面的能力,这些技术的发展将为图像处理领域带来更多创新和进步。
3.3 数字化人体
数字人是一种虚拟人体形象技术,其目标是运用数字技术创造出与人类形象类似的虚拟人物形象。数字人常运用于教育、电子商务和媒体娱乐等领域,可以充当虚拟助教、虚拟客服或是虚拟主播,近年来十分火爆。但传统的数字人制作非常复杂,不仅需要昂贵的设备还需要完成3D建模、材质纹理处理、骨骼绑定和动作步骤等流程,并且需要大量专业人士的协作,这极大地限制了数字人技术的应用范围。神经辐射场为通过少量训练数据实现高质量数字人建模与渲染带来可能,它能够简化数字人的制作难度,为创造写实、还原的数字人形象提供了强大的算法支持;虚拟主播数字人也有望在电商经济日益火爆的背景下,助力减少人力成本,为直播带来不一样的体验;为影视制作、动画游戏开发等领域提供更广阔的空间。
在数字化人体中,神经辐射场的主要应用之一是人体姿态估计和重建。通过收集多个视角的图像或视频,神经辐射场可以对人体进行3D重建,从而获得人体的准确姿态和形状信息。这对于虚拟人物形象的创建非常重要,可以为虚拟角色赋予逼真的动作和姿态,增强用户的沉浸感[47]。除了完成基本人体结构的制作,数字人实现仿真性的一个重要因素在于人脸面部表情变化。人脸重建要求神经辐射场模型在面部表情变化下具有鲁棒性,而面部表情变化可能表现为拓扑变化。模型通常将变形场参数化为附加的MLP,潜在地受到潜在代码的制约,允许从基线人脸控制变形,能够实现人脸的位姿、表情编辑,在动画制作和游戏制作领域有着很好的发展前景[48]。
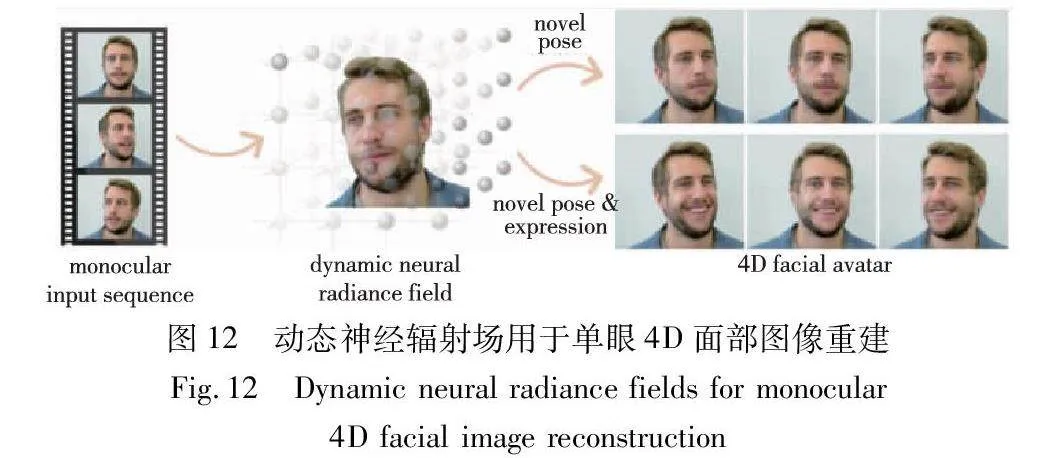
此外,神经辐射场在人脸面部表情重建和编辑方面也开始有了新发展。如图12所示,通过给定一个人的单目肖像视频序列,无须专门的捕获设置,就可以重建一个代表4D面部化身的动态神经辐射场,从而合成新的头部姿势以及面部表情的变化[49]。神经辐射场的高质量渲染能力为数字化人体中的虚拟影像生成提供了新思路。通过神经辐射场的神经场表示,可以生成逼真的虚拟人体影像,用于电影特效、虚拟演员和虚拟角色的制作等方面。神经辐射场通过算法生成对应的数字人,为数字人建模和渲染带来了全新的技术方案。目前,神经辐射场在数字化人体方面的相关算法研究大多只是针对单个身体部位如肢体或面部进行的[47~49],未来有望在数字人的智能化与拟人化方面实现突破。
3.4 其他应用
神经辐射场除在以上三个方面的应用,在虚拟现实和增强现实领域也展现出巨大的价值,无论是重建真实世界的场景还是创造元宇宙的数字地图,都可以运用在游戏、教育等各行各业,为用户提供更真实的体验。通过利用神经辐射场技术,开发者可以创建逼真的虚拟世界,让用户能够沉浸在更真实、详细的环境中。这样的体验可以让用户感觉身临其境,增加乐趣并提高使用者的沉浸感。
同时,神经辐射场在医疗领域具有广泛的应用前景,可以作为医疗教学辅助和实操训练的重要工具,可以用于重建和可视化医学图像,如CT扫描和MRI核磁共振成像。在成像中,传感器探测的数据需要经过离散采样并重建成体数据或者切片供人类观看。Truong等人[50]提出一种在稀疏采样下进行神经场重建的框架,通过神经辐射场生成的逼真渲染结果,可以帮助医生更好地理解患者的解剖结构、诊断疾病,并进行手术规划。相较于传统依赖于模型的解剖学教学,神经辐射场可以通过对患者影像数据进行处理和重建,生成高度逼真的三维解剖模型,帮助医学生在虚拟环境中进行解剖学习和实践,提高其对人体结构和器官的理解,提供更生动、立体的学习体验。
除此之外,神经辐射场还有其他一些潜在的应用。例如,神经辐射场可以用于模拟和训练机器人,通过对真实环境的建模和渲染,帮助其学习和训练各种技能和行为模式,提高机器人面对复杂环境任务的高度智能和适应能力。综上,神经辐射场具有广泛的应用潜力。未来,随着神经辐射场技术的不断优化和发展,相信它将在各个领域发挥更大的价值,为产业新发展带来更多机遇和可能。
4 结束语
4.1 神经辐射场的优势与局限性
神经辐射场作为一种新兴的计算机视觉技术,具有巨大的优势。如前所述,它能够有效地对复杂的场景进行重建,在一定程度上减轻传统建模的压力。同时,它能够从有限数量的输入样本中学习预测出近似3D场景的辐射场和密度场,对场景中的物体进行精确捕捉和识别,为各种应用提供了有力支持。它也能够适应不同场景的外在条件,例如光照等,通过神经网络从现有观测中学习渲染,实现高质量三维场景的生成,这些优势使得神经辐射场成为一种强大而有效的技术。但是,没有一项技术是完美无缺的。高计算成本、高计算复杂度限制了神经辐射场在实际应用和交互式场景中的使用,对单一方面的优化不足以实现广泛的推广应用。同时,神经渲染的一个主要局限体现在它无法处理结构数据,如网格、点云等,它采用的是隐式场景表示方法,构建的虚拟现实内容是体积数据,无法进行物理碰撞等检测,因此无法直接迁移到现有的渲染引擎中进行交互,这意味着神经辐射场生成的内容可能无法与其他常见的三维模型和场景进行无缝集成和交互。这些限制使得神经辐射场在实际应用中受到一定的制约。然而,随着技术的不断发展和改进,相信这些问题未来都能解决,神经辐射场也有望成为一种更加强大和灵活的工具,为元宇宙、虚拟现实和增强现实等领域带来更多创新和可能性[51]。
4.2 未来可能的研究方向
神经辐射场的提出引起了学术界的热烈反响,研究者们对于神经辐射场的研究热情高涨,促使神经辐射场取得了快速发展。然而,尽管神经辐射场是一个关键性的突破,但要实现完美的效果仍需要一定的时间,现阶段出色的研究成果尚未落地,神经辐射场的优化还可以从以下三个方面考虑:
a)渲染质量和渲染成本并行优化。为了实现更全面、精细的场景重建,需要进一步探索神经辐射场在质量和成本并行的优化方式。当前对这方面的研究大多是分步进行的,质量高、成本低的处理仍然是一个挑战,因此需要开发更有效的方法来解决这一问题,在提高渲染质量的同时,降低训练成本。
b)探索神经辐射场的多模态表示能力。当前基于神经辐射场的优化工作,大部分还是由视图作为输入,对于多模态数据的处理研究较少,因此有必要探索其他模态如文字、音频和视频等的结合。同时可以探索与生成式人工智能的结合,训练扩散模型,完成一些生成方面的任务。训练具有语义理解能力和语义视图综合能力的神经辐射场,判断其应用落地的可能,也许会产生令人惊艳的效果。同时还需开发更有效的方法来整合不同类型的数据,以提高场景感知和理解的能力。
c)与实际应用紧密结合。神经辐射场技术可以尝试与显式场景表示相结合,以投入实际应用场景为目标进行研究,在与实际应用结合的过程中,催生新的优化方式,不断迭代促成神经辐射场的发展。
总而言之,神经辐射场技术的出现令人振奋,通过辩证的眼光审视这一新技术,本文既看到了其发展前景,也意识到了现有技术的不足之处。在未来的工作中,神经辐射场将在现有工作基础上,重点在更高质量更快速度的渲染、虚拟现实和应用落地等方面的进一步研究。相信通过持续的研究和创新,神经辐射场技术将真正实现在各个领域的全面落地和应用。
参考文献:
[1]Lee L H, Braud T, Zhou Pengyuan, et al. All one needs to know about metaverse: a complete survey on technological singularity, virtual ecosystem, and research agenda[EB/OL]. (2021-11-03). https://arxiv.org/abs/2110.05352.
[2]Ebrahimnezhad H, Ghassemian H. Robust motion from space curves and 3D reconstruction from multiviews using perpendicular double stereo rigs[J]. Image and Vision Computing, 2008, 26(10): 1397-1420.
[3]江静, 张雪松. 基于计算机视觉的深度估计方法[J]. 光电技术应用, 2011,26(1): 51-55. (Jiang Jing, Zhang Xuesong. Depth estimation methods based on computer vision[J]. Electro-Optic Technology Application, 2011,26(1): 51-55.)
[4]Mildenhall B, Srinivasan P P, Tancik M, et al. NeRF: representing scenes as neural radiance fields for view synthesis[J]. Communications of the ACM, 2021, 65(1): 99-106.
[5]Gao K, Gao Yina, He Hongjie, et al. NeRF: neural radiance field in 3D vision, a comprehensive review[EB/OL]. (2023-11-30). https://arxiv.org/abs/2210.00379.
[6]Tewari A, Thies J, Mildenhall B, et al. Advances in neural rendering[J]. Computer Graphics Forum, 2022, 41(2): 703-735.
[7]Tancik M, Srinivasan P, Mildenhall B, et al. Fourier features let networks learn high frequency functions in low dimensional domains[J]. Advances in Neural Information Processing Systems, 2020, 33: 7537-7547.
[8]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017:6000-6010.
[9]Kajiya J T, Von Herzen B P. Ray tracing volume densities[J]. ACM SIGGRAPH Computer Graphics, 1984, 18(3): 165-174.
[10]Ahmadyan A, Zhang Liangkai, Ablavatski A, et al. Objectron: a large scale dataset of object-centric videos in the wild with pose annotations[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2021: 7818-7827.
[11]Schonberger J L, Frahm J M. Structure-from-motion revisited[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2016: 4104-4113.
[12]钟宝江, 陆志芳, 季家欢. 图像插值技术综述[J]. 数据采集与处理, 2016, 31(6): 1083-1096. (Zhong Baojiang, Lu Zhifang, Ji Jiahuan. Review on image interpolation techniques[J]. Journal of Data Acquisition and Processing, 2016, 31(6): 1083-1096.)
[13]Barron J T, Mildenhall B, Tancik M, et al. Mip-NeRF: a multiscale representation for anti-aliasing neural radiance fields[C]//Proc of IEEE/CVF International Conference on Computer Vision. Pisca-taway, NJ: IEEE Press, 2021: 5835-5844.
[14]桂梅书, 侯进, 谭光鸿, 等. 基于体素锥追踪的全局光照算法[J]. 光学学报, 2019, 39(6): 292-301. (Gui Meishu, Hou Jin, Tan Guanghong, et al. Global illumination algorithm based on voxel cone tracing[J]. Acta Optica Sinica, 2019, 39(6): 292-301.)
[15]Barron J T, Mildenhall B, Verbin D, et al. Mip-NeRF 360: unbounded anti-aliased neural radiance fields[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 5460-5469.
[16]Verbin D, Hedman P, Mildenhall B, et al. Ref-NeRF: structured view-dependent appearance for neural radiance fields[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 5481-5490.
[17]范腾, 杨浩, 尹稳,等. 基于神经辐射场的多尺度视图合成研究[J]. 图学学报, 2023,44(6):1140-1148. (Fan Teng, Yang Hao, Yin Wen, et al. Multi-scale view synthesis based on neural radiance field[J]. Journal of Graphics, 2023,44(6):1140-1148.)
[18]Martin-Brualla R, Radwan N, Sajjadi M S M, et al. NeRF in the wild: neural radiance fields for unconstrained photo collections[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Re-cognition. Piscataway, NJ: IEEE Press, 2021: 7206-7215.
[19]Zhang Kai, Riegler G, Snavely N, et al. NeRF++: analyzing and improving neural radiance fields[EB/OL]. (2020-10-21). https://arxiv.org/abs/2010.07492.
[20]Ma Li, Li Xiaoyu, Liao Jing, et al. Deblur-NeRF: neural radiance fields from blurry images[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 12851-12860.
[21]Mildenhall B, Hedman P, Martin-Brualla R, et al. NeRF in the dark: high dynamic range view synthesis from noisy raw images[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Re-cognition. Piscataway, NJ: IEEE Press, 2022: 16169-16178.
[22]Huang Xin, Zhang Qi, Feng Ying, et al. HDR- NeRF: high dynamic range neural radiance fields[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 18377-18387.
[23]Müller T, Evans A, Schied C, et al. Instant neural graphics primitives with a multiresolution hash encoding[J]. ACM Trans on Graphics, 2022, 41(4): 1-15.
[24]Deng Kangle, Liu A, Zhu Junyan, et al. Depth-supervised NeRF: fewer views and faster training for free[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 12872-12881.
[25]Hedman P, Srinivasan P P, Mildenhall B, et al. Baking neural radiance fields for real-time view synthesis[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2021: 5855-5864.
[26]Sun Cheng, Sun Min, Chen H T. Direct voxel grid optimization: super-fast convergence for radiance fields reconstruction[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 5459-5469.
[27]Xu Qiangeng, Xu Zexiang, Philip J, et al. Point- NeRF: point-based neural radiance fields[C]//Proc of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 5428-5438.
[28]Hong Yang, Peng Bo, Xiao Haiyao, et al. HeadNeRF: a real-time NeRF-based parametric head model[C]//Proc of IEEE/CVF Confe-rence on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 20342-20352.
[29]Fridovich-Keil S, Yu A, Tancik M, et al. Plenoxels: radiance fields without neural networks[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 5491-5500.
[30]Lin Yenchen, Florence P, Barron J T, et al. iNeRF: inverting neural radiance fields for pose estimation[C]//Proc of IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, NJ: IEEE Press, 2021: 1323-1330.
[31]Lin C H, Ma W C, Torralba A, et al. BARF: bundle-adjusting neural radiance fields[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2021: 5721-5731.
[32]Chen Anpei, Xu Zexiang, Zhao Fuqiang, et al. MvsNeRF: fast generalizable radiance field reconstruction from multi-view stereo[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2021: 14104-14113.
[33]Wang Zirui, Wu Shangzhe, Xie Weidi, et al. NeRF--: neural radiance fields without known camera parameters[EB/OL]. (2022-04-06). https://arxiv.org/abs/2102.07064.
[34]Kerbl B, Kopanas G, Leimkühler T, et al. 3D Gaussian splatting for real-time radiance field rendering[J]. ACM Trans on Graphics, 2023, 42(4): 1-14.
[35]Pumarola A, Corona E, Pons-Moll G, et al. D-NeRF: neural radiance fields for dynamic scenes[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2021: 10313-10322.
[36]Li Tianye, Slavcheva M, Zollhoefer M, et al. Neural 3D video synthesis from multi-view video[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 5511-5521.
[37]Yuan Yujie, Sun Yangtian, Lai Yukun, et al. NeRF-editing: geometry editing of neural radiance fields[C]//Proc of IEEE/CVF Confe-rence on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 18332-18343.
[38]Gordon O, Avrahami O, Lischinski D. Blended-NeRF: zero-shot object generation and blending in existing neural radiance fields[EB/OL]. (2023-09-07). https://arxiv.org/abs/2306.12760.
[39]Liu Zhizheng, Milano F, Frey J, et al. Unsupervised continual semantic adaptation through neural rendering[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2023: 3031-3040.
[40]Zhang Mingtong, Zheng Shuhong, Bao Zhipeng, et al. Beyond RGB: scene-property synthesis with neural radiance fields[C]//Proc of IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway, NJ: IEEE Press, 2023: 795-805.
[41]Yu A, Ye V, Tancik M, et al. PixelNeRF: neural radiance fields from one or few images[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2021: 4576-4585.
[42]De Luigi L, Bolognini D, Domeniconi F, et al. ScanNeRF: a scalable benchmark for neural radiance fields[C]//Proc of IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway, NJ: IEEE Press, 2023: 816-825.
[43]苗源, 刘畅, 邱钧. 基于神经辐射场的光场角度域超分辨[J]. 光学学报, 2023, 43(14): 93-102. (Miao Yuan, Liu Chang, Qiu Jun. Neural radiance field-based light field super-resolution in angular domain[J]. Acta Optica Sinica, 2023, 43(14): 93-102.)
[44]Tancik M, Casser V, Yan Xinchen, et al. Block-NeRF: scalable large scene neural view synthesis[C]//Proc of IEEE/CVF Confe-rence on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 8238-8248.
[45]Xiangli Yuanbo, Xu Linning, Pan Xingang, et al. CityNeRF: building NeRF at city scale[EB/OL]. (2021). https://api. semanticscholar. org/CorpusID: 245117494.
[46]Czerkawski M, Cardona J, Atkinson R, et al. Neural Knitworks: patched neural implicit representation networks[J]. Pattern Recognition, 2024,151:110378.
[47]Chen Jianchuan, Yi Wentao, Ma Liqian, et al. GM-NeRF: learning generalizable model-based neural radiance fields from multi-view images[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2023: 20648-20658.
[48]Zheng Mingwu, Zhang Haiyu, Yang Hongyu, et al. NeuFace: realistic 3D neural face rendering from multi-view images[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2023: 16868-16877.
[49]Gafni G, Thies J, Zollhofer M, et al. Dynamic neural radiance fields for monocular 4D facial avatar reconstruction[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Pisca-taway, NJ: IEEE Press, 2021: 8645-8654.
[50]Truong P, Rakotosaona M J, Manhardt F, et al. Sparf: neural radiance fields from sparse and noisy poses[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2023: 4190-4200.
[51]马瑞祾, 徐娟. 国际中文教育元宇宙: 理论意蕴、双轮驱动与发展进路[J]. 云南师范大学学报: 对外汉语教学与研究版, 2023, 21(4): 16-25. (Ma RuiLing, Xu Juan. The metaverse of international Chinese language education: theoretical implications, two-wheel drive and development strategies[J]. Journal of Yunnan Normal University: Teaching & Studying Chinese as a Foreign Language Edition, 2023, 21(4): 16-25.)
