
基于模型质量评分的联邦学习聚合算法优化
2024-08-15 00:00吴小红陆浩楠顾永跟陶杰
计算机应用研究 2024年8期










摘 要:在联邦学习环境中,客户端数据的质量是决定模型性能的关键因素。传统的评估方法依赖于在中心节点的验证集上衡量客户端模型的损失,从而对数据质量进行评估。在缺乏有效验证集的情况下,数据质量的评估是困难的。为了解决上述问题,提出了一种根据同伴信息进行模型质量评分的方法。通过对客户端上传的模型参数进行裁剪处理,基于正确评分规则的相关理论设计模型质量评分机制,并在此基础上优化聚合算法,降低低质量客户端对全局模型的影响。在MNIST、Fashion-MNIST和CIFAR-10等数据集上的实验表明,提出的评分机制无须复杂的算法,且能有效辨别搭便车、噪声、错误标签三类低质量数据客户端,提高联邦学习性能的鲁棒性。
关键词:联邦学习; 模型质量; 参数裁剪; 同伴信息; 聚合算法
中图分类号:TP391 文献标志码:A
文章编号:1001-3695(2024)08-025-2427-07
doi:10.19734/j.issn.1001-3695.2023.11.0586
Optimization of federated learning aggregation algorithm based onmodel quality scoring
Wu Xiaohong1,2, Lu Haonan1, Gu Yonggen1,2, Tao Jie1,2
(1.School of Information Engineering, Huzhou University, Huzhou Zhejiang 313000, China; 2.Zhejiang Province Key Laboratory of Smart Management & Application of Modern Agricultural Resources, Huzhou Zhejiang 313000, China)
Abstract:In federated learning environments, it is crucial to assess the quality of client data, especially when a validation set is not available. Traditional evaluation methods rely on measuring the loss of client models on the validation set of a central node to assess data quality. To address these issues, this paper proposed a method for scoring model quality based on peer information. This method involved tailoring the model parameters uploaded by the client and designing a model quality scoring mechanism based on the theories of correct scoring rules. It developed an optimized aggregation algorithm, leveraging the scores of clients to mitigate the impacts of low-quality local models on the global model. Experiments conducted on datasets like MNIST, Fashion-MNIST, and CIFAR-10 demonstrate that the proposed scoring mechanism is straightforward and effective in identifying three types of low-quality data clients: free-riding clients, overly privacy-protective clients, and mislabeled clients. The proposed method enhances the robustness of federated learning performance.
Key words:federated learning; model quality; parameter interception; peer information; aggregation algorithm
0 引言
近年来,移动应用的快速演进显著改善了人们在沟通、购物、出行及生活各方面的模式。为了强化这些移动应用的个性化功能,机器学习技术得到了广泛应用。一种常见的做法就是将用户数据汇集并上传至集中式服务器,由其训练成机器学习模型来预测,比如产品推荐。但是机器学习技术的发展仍然面临风险与挑战,数据安全问题亟待解决,用户的个人隐私容易受到侵犯,在不同的行业和部门中,存在数据访问和共享的限制,这导致了数据孤岛的形成[1,2]。
为解决上述问题,谷歌提出了联邦学习技术[3]。与传统的机器学习将所有客户端的数据收集之后再进行机器学习模型训练不同,联邦学习引入了一种隐私保护的策略,该策略主要是通过在本地设备上存储数据和训练模型,从而避免了客户端本地数据的暴露。在客户端本地完成模型训练产生模型更新后将此更新传输给中心服务器进行模型聚合,此过程迭代多次可得到优化的全局模型。由于这种方式下中心服务器并没有对数据进行直接访问,有效地保护了用户数据隐私。
区别于传统分布式学习,联邦学习由客户端自主选择是否和中心服务器进行合作学习,因此联邦学习的最终模型性能易受低质量客户端的影响,比较常见的低质量客户端有以下三种情况:
a)搭便车。这部分客户端在不参与训练的情况下发送随机模型进行搭便车来获得其他客户端训练出来的全局模型[4]。
b)过度隐私保护。这类客户端在上传参数或者梯度时客户端会对参数和梯度加入较大的噪声以减少本地数据隐私暴露的风险,但这种方式会对最终聚合全局模型的精度造成影响[5]。
c)具有错误标签数据。这类客户端在现实中可能是由于各种原因导致标签出现错误,显然利用错误标签训练的局部模型聚合后将会降低联邦学习全局模型精度[6]。
因此,在联邦学习中,评估参与训练客户端的数据质量或模型质量,识别低质量客户端,是联邦学习性能优化的关键。已有的一些基础联邦学习算法如FedAvg、FedSGD未考虑数据质量对模型性能的影响,一些算法如FedProx[7]、SCAFFOLD[8]针对数据非独立同分布的特征对基础算法进行了改进,但是不能解决上述低质量客户端的影响。
虽然已有不少的学者针对联邦学习参与者的贡献和质量评估进行了研究,然而在缺乏有效数据验证集的场景中,联邦学习的客户端质量评估依然是一个难题。为优化联邦学习性能,本文基于正确评分规则的相关理论,提出了一种无验证数据的客户端模型质量评估算法,仅利用客户端上传的模型对参与联邦学习的客户端的模型质量进行评分,并在此基础上优化联邦学习聚合算法。本文的主要贡献如下:
a)设计了一种根据同伴模型评分的客户端模型评分机制,使服务器能够识别联邦学习环境中的低质量本地模型。该机制通过互评的方法使得每个客户端的模型都受到其他客户模型的评估,这一过程有助于识别那些因搭便车行为、过度隐私保护或数据标签不准确等问题而导致模型质量低下的客户端。
b)基于设计的模型评估机制,进一步提出了一种鲁棒的联邦学习聚合算法。该算法根据模型得分为每个客户端分配聚合权重,降低低质量客户端对全局模型的影响,使质量较高的本地模型在全局模型中具有更加显著的影响力。
c)通过实验验证了本文算法的性能。实验选择三个标准数据集——MNIST、Fashion-MNIST以及CIFAR-10,采用了多层感知器(MLP)和卷积神经网络(CNN)机器学习模型进行实验。实验结果显示,本文算法在识别低质量数据的客户端方面具有显著的效果,并且在时间复杂性和多个具体性能指标上优于现有方法。
1 相关工作
1.1 联邦学习
联邦学习是一个分布式机器学习框架,其中包含一个中心服务器和若干持有隐私数据的客户端,假定客户端集合被表示为Nc={1,2,…,N},每个客户端i都有一个私有隐私数据集Di,i∈Nc。在每一轮全局迭代t中,中心服务器会随机选择k个客户端参与模型训练,这些客户端用集合{1,2,…,k}表示。
在第t轮迭代的起始阶段,参与训练的客户端i从中心服务器上下载初始的全局模型,利用本地的数据集Di训练得到本地模型wti,该过程可通过各种机器学习算法实现。所有客户端的训练是并行执行的,客户端与客户端之间并不存在直接的数据交换。
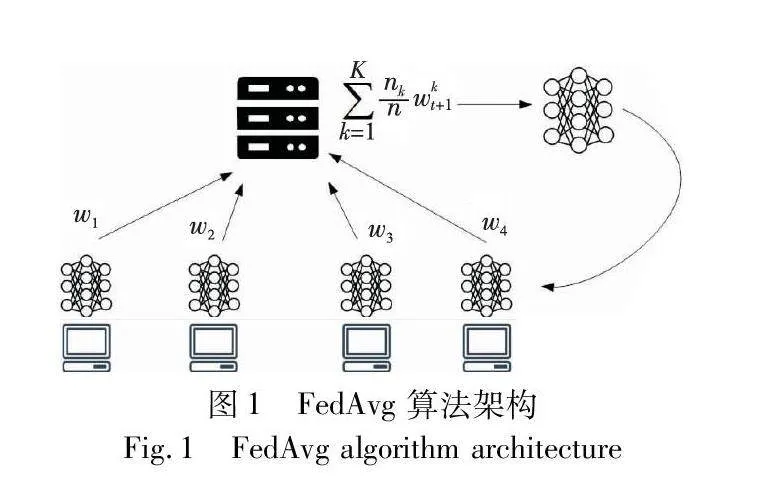
训练完成后,中心服务器从参与当前训练的客户端收集本地模型,然后通过特定的聚合算法——如图1所示的联邦平均算法(federated averaging,FedAvg)生成全局模型wt,其中nk是第k个客户端的数据量,n是所有客户端的数据量,利用两者的比值作为聚合的权重。中心服务器在得到全局模型参数wt之后,将其下发给各个下一轮参与训练的客户端,客户端便可以根据新的全局模型参数wt和本地的数据集Di进入下一轮迭代,从而进一步提升模型性能。在整个过程中,中心服务器并未接触到任何客户端的原始数据,只需要处理模型参数,从而在联邦学习过程中确保了数据隐私的安全。
整个联邦学习训练过程包含四个步骤:
a)任务初始化:中心服务器从总的客户端集合Nc中选取k个客户端参与,确定训练任务,并将当前全局模型传送给参与训练的客户端。
b)本地模型训练:客户端从中心服务器下载全局模型wt-1(其中t表示当前的训练迭代轮次)。客户端利用本地数据集Di训练得到本地模型wti。训练的目标是通过最小化损失函数L(wti)找到最佳的本地模型并将其上传至服务器。
wti=arg minwL(w;Di)(1)
c)全局模型聚合:中心服务器将参与训练的客户端上传的本地模型wti利用聚合算法聚合。更新全局模型wt。
wt=∑iai·wti(2)
d)完成T轮训练后,停止训练过程并生成最终的全局模型wT。
1.2 联邦学习低质量客户端评估方法
在联邦学习领域,针对凸损失函数和平滑非凸损失函数的模型训练,文献[9]引入了平均中值算法和维度剪枝平均算法。这些算法有效地防止了中央服务器在模型更新过程中受到质量较低数据客户端的不利影响。然而,Yin等人[10]指出,在处理多数非平滑和非凸损失函数时,依赖于维度中值或剪枝均值的算法可能导致模型收敛至非全局最优解,如鞍点或局部最小值。为应对此问题,提出了拜占庭扰动梯度算法,专注于在非凸情形下寻找近似局部最优解。但这类方法的一个明显不足之处在于,它们要求评估每次学习迭代中所有计算节点上报的局部梯度,这在处理大规模数据学习任务时可能因计算复杂度过高而显得不切实际。
在联邦学习中,处理低质量客户端参与训练的问题时,部分方法依赖于测试数据集来评估模型质量。具体来说,Shapley值[11~13]在联邦学习中广泛被用来量化用户的贡献,通过在每轮迭代训练中评估不同客户端抽样顺序对全局模型精度的边际影响来实现。同时,Li等人[14,15]提出的检测机制和Cao等人[16]的FLTrust算法也依赖于测试数据集来区分模型质量。Li等人的方法通过结合测试数据和自动编码器来识别恶意模型更新,而Cao等人的FLTrust算法则依赖于一个由服务器收集的小型但未受污染的“信任数据集”以增强系统对恶意客户端的抵御能力。由于联邦学习的数据集大部分属于Non-IID(non-independent and identically distributed,非独立同分布)的状态,且数据分布本质上是未知的,所以难以找到任何一个数据集能够完整模拟真实世界中的未知数据分布。此外,从客户端获取适用的测试数据集可能会违反联邦学习中的隐私保护原则。因此需要一种无须测试数据集的方法来进行客户端模型质量评估。
区别于上述依赖测试数据集的方法,Lyu等人[17]引入了一种评估联邦学习中客户端的创新方法,该方法采用了同行评估机制,并结合了参数之间的随机相关性概念[18,19]。这种方法通过分析服务器端收集的客户端模型更新,并基于这些更新参数之间的随机相关性来评估客户端的贡献度。每个客户端根据这些相关性得到一个唯一的评分,进而在模型聚合过程中根据这一评分赋予不同权重。此举旨在降低那些提供低质量更新的客户端在联邦学习中的影响。这一机制为联邦学习提供了一种新的参与者评估方法,它不依赖于验证数据的可用性,从而克服了先前方法的某些局限性。虽然在计算复杂性上相对较高,然而该方法为联邦学习中客户端模型评估引入了一种基于同行信息的创新方法。
受前述研究成果的启发,本文提出了一种新的联邦学习聚合算法。该算法使得在有低质量客户端参与的情况下联邦学习模型依然具有较高的准确性,同时不依赖于验证数据集进行模型验证和调整。该方法旨在面对数据和参与者极其多样化的环境时,增强联邦学习系统在现实世界数据场景中的应用性和鲁棒性。
2 问题描述
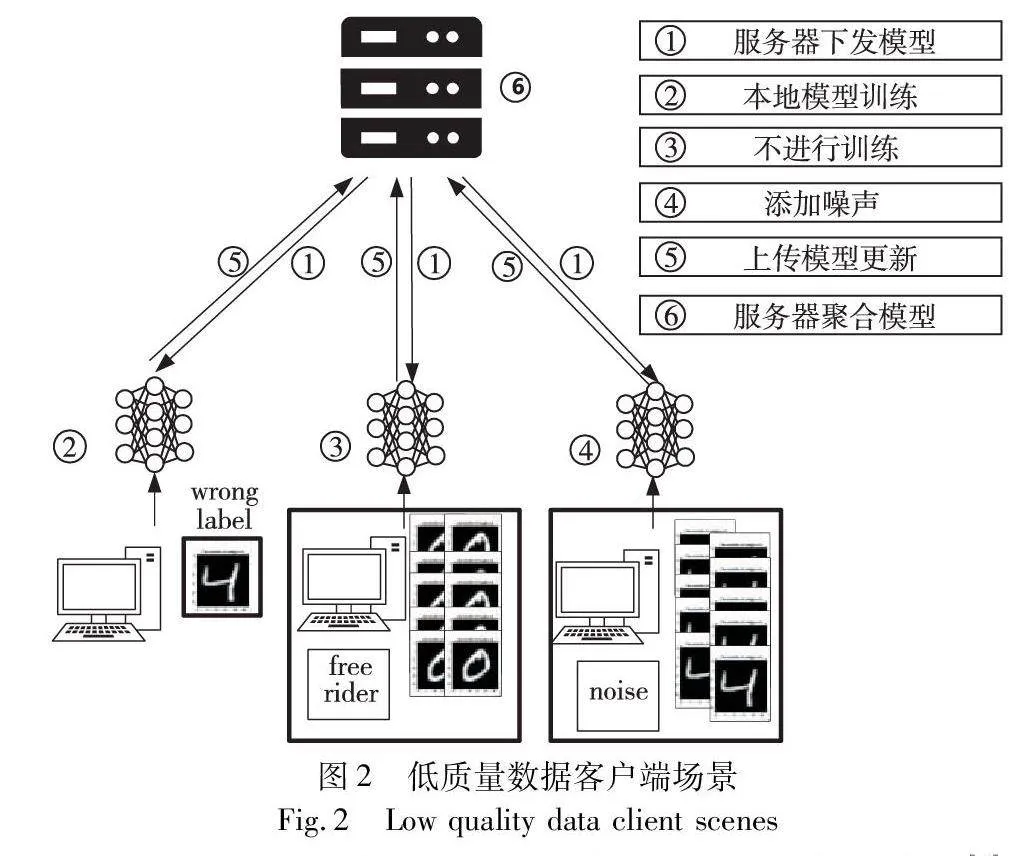
首先探讨联邦学习环境中三种典型的低质量数据客户端的具体策略,场景如图2所示,包括搭便车者、过度隐私保护者(过分添加噪声的客户端)以及提供错误标签的客户端。
a)搭便车客户端。这类客户端会生成随机模型参数[4],目的是为了减少本地训练的计算成本,从而在不贡献有效学习资源的情况下从联邦学习系统中受益。目前,搭便车策略主要有以下两种形式:
(a)参数扰动策略。在该策略中,客户端直接采用从服务器接收的全局模型,对其引入轻微的随机扰动,然后将其上传回服务器。令wt-1表示上一轮从服务器调度的全局模型。这一类客户端每一轮上传的模型参数为
wti=wt-1+δ1(3)
其中:δ1~Euclid Math OneNAp(0,σ21),意味着wt中的每个参数都添加了随机高斯噪声。
(b)随机参数策略。在这种策略下,客户端不依赖于从服务器接收的任何预先训练的模型信息。相反,它采取了一种自主的方法,即直接生成并上传随机化的模型参数。这一类客户端每一轮上传的模型参数为
wti~Euclid Math OneNAp(0,σ21)(4)
b)过度隐私保护客户端。尽管客户端只是上传模型参数,数据的隐私泄露风险仍然存在[20~22]。为了抵御潜在的逆向工程攻击,这可能导致客户端在上传的模型参数中引入了过多的噪声。虽然这样做能够提高数据的安全性,但过度的噪声添加也可能损害全局模型的性能和准确性。这一类客户端每一轮上传的模型参数为
ti=wti+δ2(5)
其中:δ2~Euclid Math OneNAp(0,σ22)。
c)错误标签的客户端。对于窜改数据标签的低质量客户端,如文献[23]所述,其目的在于通过修改本地训练数据的标签来影响聚合后的全局模型,从而使模型偏向于他们所期望的方向。这种行为不仅威胁到模型的准确性,还可能严重破坏联邦学习环境的整体效率。这些客户端通过对本地数据的标签施加扰动,有意识地导致全局模型学习到错误的模式。设yi代表原始标签的一个数据点。那么添加扰动的标签i为
i=yi+Δ(6)
其中:Δ是错误标签的客户端引入的故意偏差。例如,如果yi=5且Δ=2,则i=7。
本文使用CNN模型分别对上述三类客户端的加入进行了联邦学习训练实验。图3展示了搭便车客户端对联邦学习在全局聚合后模型精度的潜在影响。这些搭便车客户端的模型参数wti~Euclid Math OneNAp(0,σ21),即方差为σ1=0.01的高斯分布。如图3所示,仅有25%的搭便车客户端可显著降低整体性能。
图4是过度隐私保护行为对全局聚合后模型精度的影响。这里,每个客户端i的模型参数更新ti=wti+Euclid Math OneNAp(0,σ22),当σ2=0.1时,性能略有下降,但是当σ2增至0.2或更高时,性能急剧下降。
在联邦学习环境中存在错误标签客户端的情形时,如图5所示,当这些客户端在MNIST数据集中将部分标签窜改为错误标签时,对模型精度有显著影响。当错误标签客户端的比例达到25%时,联邦学习在该数据集上的精度便开始逐渐下滑。随着错误标签的客户端数量的进一步增加,联邦学习的性能急速下降。
上述实验结果明确指出了对一种能有效检测这些低质量客户端的评价方法的迫切需求。在联邦学习的众多应用场景中,客户端持有的数据往往具有非独立同分布的特点。在此背景下,尽管某个客户端可能只持有部分标签的数据,其上传的模型在中心服务器的全局聚合中仍有其独特的贡献。在无有效验证数据集的场景下,有必要提出一种新颖的评价方法,这种方法能够在缺少有效验证数据集的前提下,对客户端上传的本地模型进行有效评估。借助这种评估机制,可以给上述的三种低质量数据的客户端上传的模型参数评定更低的分数,从而在中心服务器的全局聚合过程中减小其权重。通过这一策略,期望能够提高整体模型的准确性,并促进模型更快地收敛,提高联邦学习性能的鲁棒性。
3 基于评分机制的FL聚合算法
3.1 模型参数的截取处理
在没有验证数据集的联邦学习中,本文将模型参数的训练过程模拟为对某些事件的预测过程,并借鉴了预测问题中的评分规则,用于评估概率预测的准确性,要求预测值必须落在[0,1]。由于联邦学习中的模型参数被限制在这个范围,本文在评分前将每个客户端的模型参数进行了裁剪处理,确保它们位于[0,1]的有效区间。
首先,对客户端i的模型wi进行分层的参数裁剪,第k层的参数裁剪如下:
i,k=wi,kmax(1,‖w1,k,w2,k,…,wn,k‖2)(7)
每个客户端的模型的各个层参数被拼接成一个矩阵,式(7)中的二范数就是这个矩阵的二范数。应用数值缩放比例为
pi=pi-mpMp-mp(8)
其中:mp和Mp分别表示所有客户端模型第p个参数的最小值和最大值;pi表示裁剪归一化后的模型参数,每个参数都在[0,1]。值得注意的是,在模型聚合过程中不调整客户端模型的参数。上述裁剪和归一化操作仅在模型评估阶段使用。
3.2 二次评分规则
正确的评分规则(proper scoring rule) 用于激励专家诚实地报告他们的概率信念[24,25]。只有当评分规则能够激励预测者提供准确且真实的预测时,才被视为正确。在这样的背景下,正确的评分规则是指当预测者在其预测与真实概率或后验分布的均值相匹配时,预期得分达到最大化的评分规则。
假设真实状态θ∈[0,1],服从一个未知的分布。参与者可以私下观察信号,产生真实状态的后验分布G。根据文献[23]中的工作,关注的是能够引导出后验均值的评分规则,即该评分规则要求参与者报告其后验的均值,并根据参与者的报告以及实际发生的状态来对其进行评分。设μG为后验分布G的均值,r∈[0,1]为代理的报告值。
定义1 如果对于任何后验分布G以及报告r,满足
Eθ~G[S(μG,θ)]≥Eθ~G[S(r,θ)](9)
则称评分规则S(r,θ)对于引出均值是正确的。
根据文献[24],式(10)中的二次评分规则被证明对于导出均值是正确的。
S(r,θ)=1-(θ-r)2(10)
本文将客户端模型参数训练和上传映射到上述场景。令Nc={1,2,…,N}为参与客户端集合,wji是客户端i对参数j的训练值。对于普通的客户端,假设对于第t轮训练,其参数值服从相同的分布,其均值为μt,但对于任一参与者,具体分布参数是未知的。
令r=wji表示客户端i对训练结果的报告,θ表示真实状态。由于真实状态应与被评价客户端自身的预测值无关,选择θj-i作为真实状态。θj-i是除客户端i外所有参与客户对参数j报告的平均值,可视为真实状态(真实状态通过其他客户的报告得出),即
θj-i=∑k∈Nc,k≠iwjkN-1(11)
由于普通客户端训练的参数服从均值为μt的一个分布,则θj-i同样服从均值为μt的一个分布。
二次评分规则改为如式(12)所示。
S(wji,θj-i)=1-(θj-i-wji)2(12)
对于前述的低质量客户端,由于没有采用真实数据集进行训练或添加了过度噪声,显然其模型参数值wji不再服从均值为μt的分布,其报告值易较大地偏离θj-i,所以得分降低。当存在的低质量客户端数量占比较小时,评分规则可以区分普通客户端和低质量客户端。
如果模型参数被限制在[0,1],则式(12)中展示的二次评分规则的上界为1。设P表示模型参数集合,那么客户端模型wi的评分公式可以表示为
si=∑i∈P1-(θj-wji)|P|(13)
设P表示模型参数集合,那么客户端模型wi的评分公式可以表示如下:
命题1 若模型参数被限制在区间[0,1]内,式(13)中客户端模型的二次评分规则上界为1。
证明 模型参数被限制在区间[0,1]内,则式(12)中表示的二次评分规则的上界为1,式(13)对|P|个参数求解分数的平均值,因此模型得分是有界的,在区间[0,1]内。
在全局模型的每次聚合之前,都应用此评分规则来评估参与某轮联邦学习的客户端的质量。θ-i的使用提供了相对评估,客户端的分数与其同行的表现相对应。这种评分机制为评价单个客户端模型在联邦学习框架中的贡献提供了一个稳健的指标。
3.3 改进的联邦学习聚合算法
本节提出一种基于二次评分的联邦学习聚合算法,称为 FedQuaScore聚合算法。FedQuaScore的主要目标是防范使用低质量数据的客户。算法1是模型参数的裁剪和评分。算法2是联邦的聚合算法FedQuaScore,在联邦学习过程中根据客户评分进行聚合。
算法1 客户端模型裁剪与评分(scoring(W,ξ))
输入:客户端模型集合W=(w1,w2,…,wN)。
输出:评分向量score=(s1,s2,…,sN)。
a)for i=1 to N do
b) for each k; // 对模型中的每一层k进行分层处理
c) i,k←wi,kmax(1,‖w1,k,w2,k,…,wn,k‖2);
d) end for
e) for each p∈P do;
f) pmin←minj∈Ncwpj;
g) pmax←maxj∈Ncwpj;
h) pi←pi-pminpmax-pmin;
i) end for
j)end for
k)score=(0,0,…,0);
l)for i=1 to N do
m) si←∑j∈P1-(θj-i-ji)2|P|;
n)end for
在算法1中,步骤b)~d)实现了参数裁剪操作,把选中层的参数拼接成一个矩阵,利用这个矩阵的二范数对客户端i的模型wi进行分层的参数裁剪,确保参数保持在适当的范围内,进一步增强联邦学习的鲁棒性。在实验中范数裁剪方法参见参考文献[27]。e)~i)的计算使每一个参数分布在[0,1]。l)~n) 应用二次评分规则得到了模型的评分,得到上界为1的分数。评分机制起着至关重要的作用,其目标是有效评估每个客户模型的质量。
命题2 模型裁剪与评分算法时间复杂度为O(|P|N2),其中|P|为参数个数,N为客户端个数。
证明 算法1中,步骤b)~d)是模型参数的裁剪,假设第k层的参数个数为xk,通过二范数的计算公式可知,时间复杂度为O(∑k∈K|xk|N),其中∑k∈K|xk|=|P|,所以对每个客户端每个参数都裁剪量化的时间复杂度为 O(|P|N2)。对参数的归一化部分,即步骤a)~i),由于f)和g)求最大最小值的复杂度为O(N),对每个客户端每个参数求取则是O(|P|N2)。所以算法1的复杂度为O(|P|N2)。
在考虑到模型复杂性带来的挑战时,如果对客户端上传的模型的全部参数进行处理,会导致算法的运行时间过长。根据文献[26]的研究,采用对模型最后一层参数进行余弦相似性计算的方法显示出最佳效果。这一成效主要源于模型最后一层与输出结果的密切相关性,这一层参数在最大程度上揭示了不同模型间的显著差异。基于此发现,本文沿用文献[26]的策略,选取模型最后一层的参数作为评分计算的依据。此方法不仅保障了评估的准确性和效率,同时有效地解决了由于参数维度过高所带来的计算挑战。
算法2中,服务器端为明显区分聚合权重之间的差异,选择了指数加权法。如算法2第e)~h)行所示,客户端i的聚合权重为
ai=exp(αsi)∑Kj=1exp(αsj)(14)
其中:参数α主要用于调整放大倍数的分数。由于提出的评分策略可以有效地反映模型的质量,即使α的值不是特别大,算法2仍然可以达到显著的效果实验评估。
算法2 基于评价分数的联邦学习聚合算法FedQuaScore
输入:初始全局模型w0;全局训练轮数T;数据集D;批大小b;学习率η;客户总数K;选定客户的比例c。
输出:训练完成后的全局模型wT。
服务器端:
a)for t=1 to T do
b) 随机选择K个客户端;
c) 接收客户端模型W=(w1,w2,…,wN);
d) score=scoring(W,ξ);
e) for i=1 to K do
f) ai←exp(αsi)∑Kj=1exp(αsj);
g) end for
h) wt←∑Ki=1aiwti;
i)end for
j)return wT;
客户端(第t轮):
k)接收全局模型wt-1;
l)在本地数据集上基于全局模型训练得到本地模型
m)将训练好的本地模型wti发送回服务器
4 实验验证
4.1 实验设置
在实验设计中,采用谷歌推出的联邦学习框架,实验选择的数据集包括MNIST、Fashion-MNIST(FMNIST)和CIFAR-10三个数据集。比较的基准方法为文献[3]中的FedAvg方法和文献[15]提出的Fed-PCA方法,比较的指标是低质量客户端的平均权重和全局模型准确性。
a)MNIST。手写数字图像数据库,被广泛用于训练多种图像处理系统。它由60 000个训练样本和10 000个测试样本组成,每个样本均为28×28像素的灰度图像,并涵盖10个类别。
b)Fashion-MNIST。此数据集含有60 000个训练样本和10 000个测试样本。每个样本均为28×28像素的灰度图像,代表10种不同的服饰和鞋类。
c)CIFAR-10。是一个十分类的标准图像分类数据集,包括60 000个32×32像素的彩色图像样本,分为50 000个训练样本和10 000个测试样本。它涵盖的类别包括飞机、汽车、鸟、猫等。
在机器学习模型方面,选择了多层感知器(MLP)和卷积神经网络(CNN)两个经典模型。具体来说,在存在搭便车的客户端和过度噪声保护客户端的实验中,对MNIST数据集的训练过程采用了卷积神经网络架构。这个网络包含两层5×5的卷积层,每个卷积层后跟着一个ReLU激活函数和2×2的最大池化层。在对FMNIST数据集的训练过程中,采用了一种多层感知器(MLP)模型。这个模型的设计包含一个输入层,该层具有784个神经元,紧接着是一个含有64个神经元的隐藏层,最后还有一个具有10个神经元的输出层。
对于标签不正确的低质量数据客户端的实验中,本文使用之前提到的MLP模型训练MNIST模型。对CIFAR-10数据集的训练过程中,采用了卷积神经网络架构。包含两个主要的卷积阶段,每个阶段包括两个3×3卷积层,随后是批量归一化、ReLU激活函数和2×2最大池化层。在关于错误标签客户端的实验中设置Δ=5来调整这类客户端在训练时的标签。
所有的实验均在二类Non-IID下进行。具体实施过程为:本文将MNIST、Fashion-MNIST、CIFAR-10的训练数据按标签顺序排列,划分为200个数据块,每块含300条数据,各客户端将从中不重复地随机选取两个数据块作为其本地数据集。在所有实验中,α的值为5。
在搭便车客户端的配置中,这些客户端在本地训练阶段并未实际运用本地计算资源。他们所提交的模型参数更新均符合wti~Euclid Math OneNAp(0,σ21),其中σ1设置为0.01。实验对搭便车客户端的不同比例下的性能进行了评估,并与Fed-PCA策略进行了对比。在有过度隐私保护的客户端参与的实验设定中,假设有25%的客户端向他们的模型参数中加入了噪声,每个上传的模型参数均满足pi=wpi+Euclid Math OneNAp(0,σ22)的分布。本文旨在探索不同噪声级别对模型的影响。在处理恶意客户端的实验设计中,本文尝试了不同比例的客户端数据标签被窜改的场景。具体地,本文研究了错误标签客户端数量占训练客户端总数的10%、20%、30%和40%的情境。
4.2 实验结果
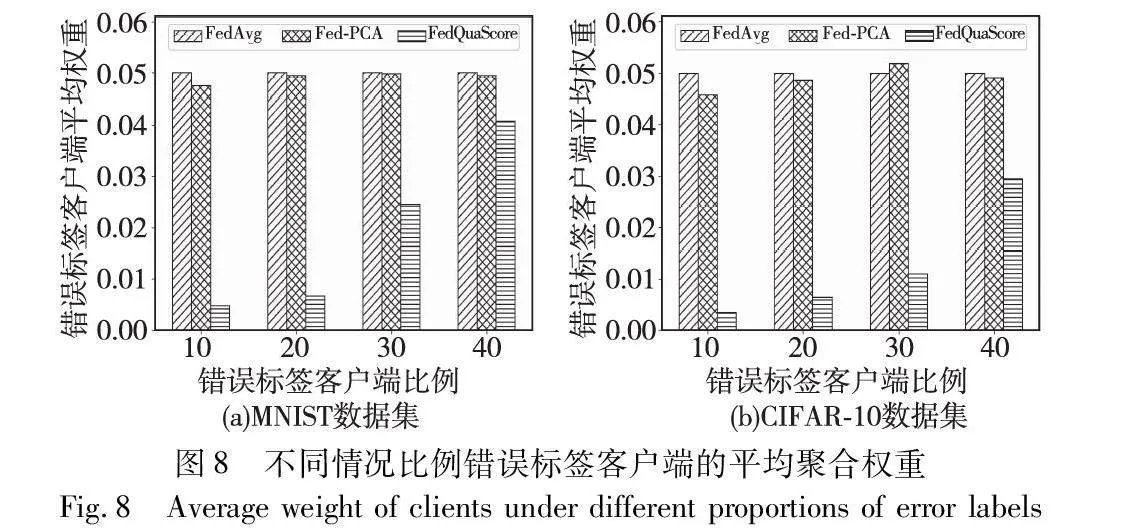
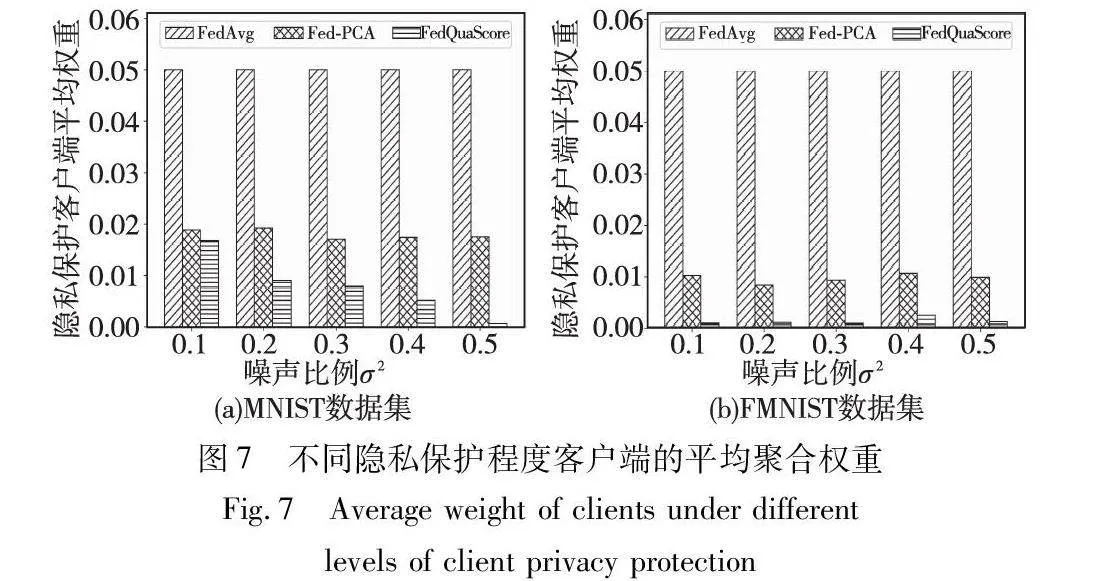
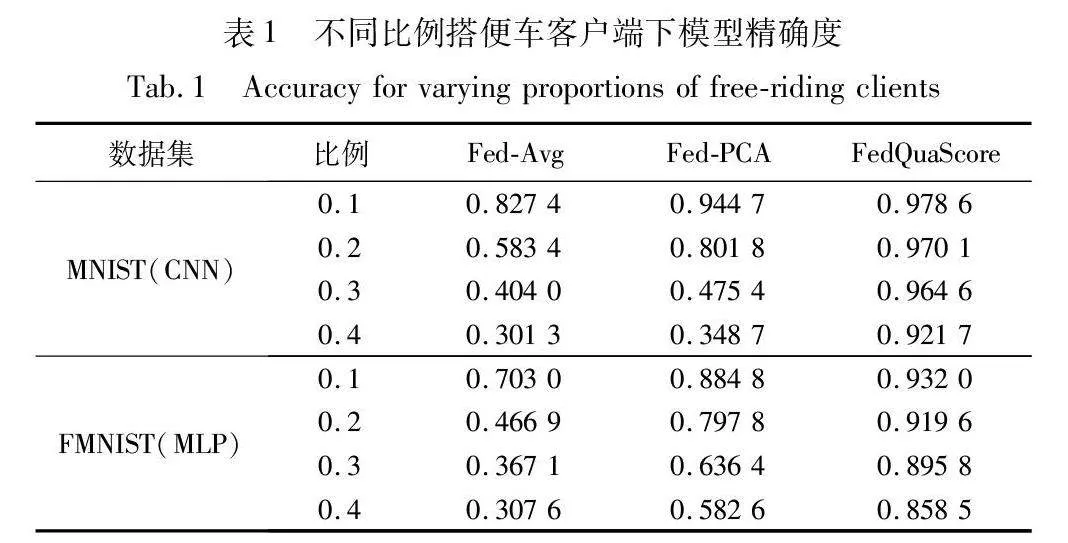
首先在MNIST和Fashion-MNIST两个数据集上比较不同搭便车客户端比例的场景下的算法性能,如表1和图6所示。图6~8纵坐标均为客户端聚合时的平均权重。
从图6(a)(b)中可以观察到,FedAvg算法为每个客户端分配了基准权重0.05。在搭便车客户的比例不超过20%的情况下,Fed-PCA算法在降低搭便车客户端聚合权重方面表现出了值得肯定的效果,然而,随着搭便车客户比例的增加,其性能呈现出显著下降的趋势。与此相对比,本文的FedQuaScore算法在所有的测试设置中均能通过为这些搭便车的客户端分配极小的聚合权重,从而保持优异的性能表现。
如表1所示,本文比较了FedQuaScore、FedAvg和Fed-PCA三种算法在全局模型精度上的表现。结果显示,FedQuaScore在模型精确度方面领先于其他两种算法,即便在搭便车客户比例不断上升的情况下也能维持这一优势。
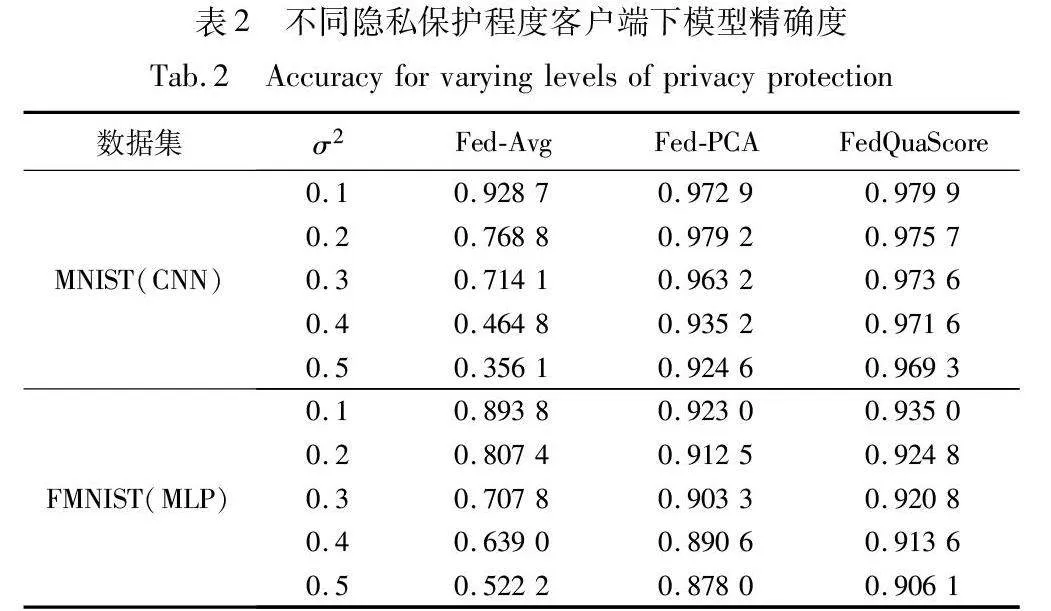
其次,实验比较了过度噪声客户端参与下算法的性能。通过图7(a)(b)可以看出,不同隐私保护程度客户端在联邦学习聚合中的平均权重。当添加噪声方差为σ2=0.1时,Fed-PCA显示出其优越性。然而,随着添加噪声的提高,Fed-PCA并没有进一步降低此类客户端在联邦学习中的总权重。FedQua-Score方法在面对不同隐私保护级别的客户时表现出稳健性;隐私保护级别越高,为此类客户分配的权重就越低。如表2所示,即使隐私保护不断增强,FedQuaScore在模型准确性方面仍领先于FedAvg和Fed-PCA。
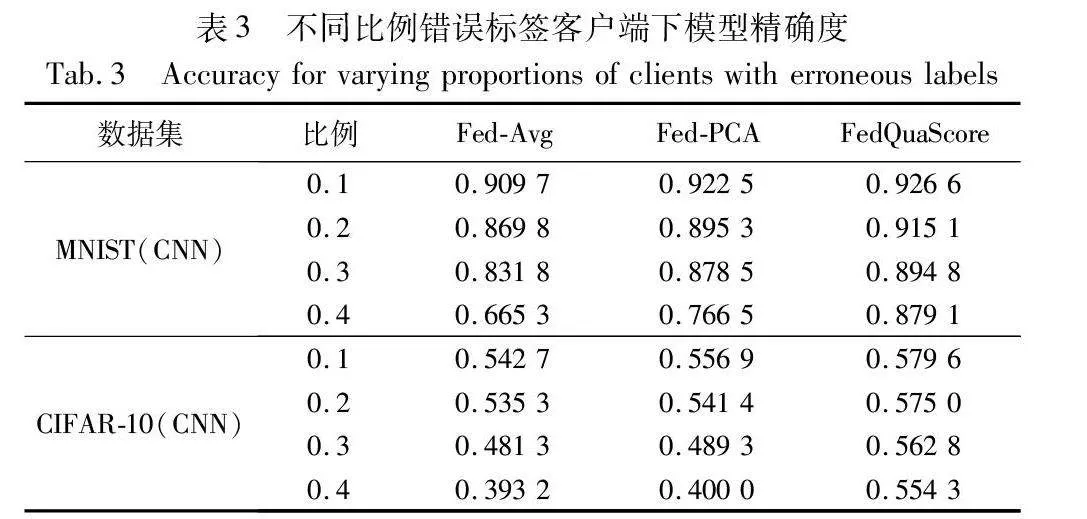
第三,评估联邦学习聚合过程中错误标签客户端参与下算法的性能。图8(a)(b)展示了在MNIST和CIFAR-10数据集上,不同比例的错误标签客户端对聚合模型平均权重的影响。特别是,当存在20%的错误标签客户端时,FedQuaScore算法开始展现其在削减不良影响上的有效性。与此相比,其他算法对错误标签的敏感度较低,这可能导致模型性能的降低。特别是,Fed-PCA算法未能显著调整错误标签客户端的权重分配,在某些情况下甚至向这些客户端分配了更高的权重。这些发现强调了FedQuaScore在处理数据质量不一的客户端时的鲁棒性和有效性。如表3所示,在错误标签客户端的比例增加的情形下,FedQuaScore在模型准确性方面相较于FedAvg和Fed-PCA算法仍展现出领先优势。
图9(a)(b)展示了携带错误标签客户端在比例为0.3和0.4时对联邦学习模型收敛性的显著影响。从图中可以看出,当使用传统的FedAvg算法时,模型的收敛过程表现出显著的波动性,其学习轨迹出现了不稳定的波动。这种波动性可能会对模型的最终稳定性及其在处理未知数据时的泛化能力产生负面影响。与此相反,通过采用本文提出的学习过程中动态调整聚合权重的方法,可以明显观察到更加稳定和平滑的收敛轨迹。
5 结束语
本文提出了一种名为FedQuaScore的创新联邦学习聚合算法,优化客户端模型参数的评估过程。FedQuaScore的核心在于为每一参与客户端分配一个合理的评分,以确保得分较高的客户端在全局模型聚合中享有较大权重。此策略的目的是最小化低质量数据客户端对于全局模型准确性的负面影响。
通过在客户端中加入不同比例的搭便车客户端、过度隐私保护客户端以及带有错误标签的客户端等,并与现有方法进行对比,实验结果验证了FedQuaScore在各种测试场景下的高性能与稳健性。目前该方法还存在一定的局限性。首先,FedQuaScore 的核心机制是基于模型参数的均值来评估和整合不同客户端的数据。然而,如果低质量客户端的模型参数所占比例较大时,该方法的有效性降低;其次,目前没有考虑具体攻击手段的防御,如通过客户端局部模型窜改以诱发模型误识别的攻击策略。下一步将针对上述存在的2a03cfece84fd2e3eac853056cdb7e4f问题持续改进算法,提高算法的有效性。
参考文献:
[1]Zhang Chen, Xie Yu, Bai Hang, et al. A survey on federated lear-ning[J]. Knowledge-Based Systems, 2021, 216: 106775.
[2]Zhou Jun, Fang Guoying, Wu Nan. Survey on security and privacy-preserving in federated learning[J]. Journal of Xihua University:Natural Science Edition, 2020, 39(4): 9-17.
[3]McMahan B, Moore E, Ramage D, et al. Communication-efficient learning of deep networks from decentralized data[C]//Proc of the 20th International Conference on Artificial Intelligence and Statistics. 2017: 1273-1282.
[4]Lin Jierui, Du Min, Liu Jian. Free-riders in federated learning: attacks and defenses[EB/OL]. (2019). https://arxiv.org/abs/1911.12560.
[5]Bonawitz K, Ivanov V, Kreuter B, et al. Practical secure aggregation for privacy-preserving machine learning[C]// Proc of ACM SIGSAC Conference on Computer and Communications Security.New York:ACM Press, 2017: 1175-1191.
[6]Fang Minghong, Cao Xiaoyu, Jia Jinyuan, et al. Local model poiso-ning attacks to{Byzantine-Robust}federated learning[C]// Proc of the 29th USENIX Security Symposium. 2020: 1605-1622.
[7]Li Tian, Sahu A K, Zaheer M, et al. Federated optimization in hete-rogeneous networks[J]. Proceedings of Machine Learning and Systems, 2020,2: 429-450.
[8]Karimireddy S P, Kale S, Mohri M, et al. SCAFFOLD: stochastic controlled averaging for federated learning[C]//Proc of the 37th International Conference on Machine Learning. 2020: 5132-5143.
[9]Ghosh A, Hong J, Yin Dong, et al. Robust federated learning in a heterogeneous environment[EB/OL]. (2019). https://arxiv.org/abs/1906. 06629.
[10]Yin Dong, Chen Yudong, Kannan R, et al. Defending against saddle point attack in Byzantine-robust distributed learning[C]//Proc of International Conference on Machine Learning. 2019: 7074-7084.
[11]Liu Yuan, Ai Zhengpeng, Sun Shuai, et al. Fedcoin: a peer-to-peer payment system for federated learning[M]//Federated Learning: Privacy and Incentive. Cham: Springer International Publishing, 2020: 125-138.
[12]Jia Ruoxi, Dao D, Wang Boxin, et al. Towards efficient data valuation based on the Shapley value[C]//Proc of the 22nd International Conference on Artificial Intelligence and Statistics. 2019: 1167-1176.
[13]Wang Guan, Dang Xiaoqian, Zhou Ziye. Measure contribution of participants in federated learning[C]//Proc of IEEE International Conference on Big Data. Piscataway,NJ:IEEE Press, 2019: 2597-2604.
[14]Li Suyi, Cheng Yong, Wang Wei, et al. Learning to detect malicious clients for robust federated learning[EB/OL]. (2020). https://arxiv.org/abs/2002.00211.
[15]Li Suyi, Cheng Yong, Liu Yang, et al. Abnormal client behavior detection in federated learning[EB/OL]. (2019). https://arxiv.org/abs/1910. 09933.
[16]Cao Xiaoyu, Fang Minghong, Liu Jia, et al. FLTrust: Byzantine-robust federated learning via trust bootstrapping[EB/OL]. (2020). https://arxiv.org/abs/2012.13995.
[17]Lyu Hongtao, Zheng Zhenzhe, Luo Tie, et al. Data-free evaluation of user contributions in federated learning[C]//Proc of the 19th International Symposium on Modeling and Optimization in Mobile, Ad hoc, and Wireless Networks. Piscataway,NJ:IEEE Press, 2021: 1-8.
[18]Shnayder V, Agarwal A, Frongillo R, et al. Informed truthfulness in multi-task peer prediction[C]//Proc of ACM Conference on Econo-mics and Computation. New York:ACM Press,2016: 179-196.
[19]Miller N, Resnick P, Zeckhauser R. Eliciting informative feedback: the peer-prediction method[J]. Management Science, 2005, 51(9): 1359-1373.
[20]孙爽, 李晓会, 刘妍,等. 不同场景的联邦学习安全与隐私保护研究综述[J]. 计算机应用研究, 2021, 38(12): 3527-3534. (Sun Shuang, Li Xiaohui, Liu Yan, et al. Survey on security and privacy protection in different scenarios of federated learning[J]. Application Research of Computers, 2021, 38(12): 3527-3534.)
[21]熊世强, 何道敬, 王振东,等. 联邦学习及其安全与隐私保护研究综述[J]. 计算机工程,2024,50(5):1-15. (Xiong Shiqiang, He Daojing, Wang Zhendong, et al. Review of federated learning and its security and privacy protection[J]. Computer Engineering,2024,50(5):1-15.)
[22]Abadi M, Chu A, Goodfellow I, et al. Deep learning with differential privacy[C]//Proc of ACM SIGSAC Conference on Computer and Communications Security.New York:ACM Press, 2016: 308-318.
[23]张世文, 陈双, 梁伟,等. 联邦学习中的攻击手段与防御机制研究综述[J]. 计算机工程与应用,2024,66(5):1-16. (Zhang Shiwen, Chen Shuang, Liang Wei, et al. Survey on attack methods and defense mechanisms in federated learning[J]. Computer Engineering and Applications,2024,66(5):1-16.)
[24]Oesterheld C, Treutlein J, Cooper E, et al. Incentivizing honest performative predictions with proper scoring rules[C]//Proc of the 39th Conference on Uncertainty in Artificial Intelligence.[S.l.]:JMLR.org,2023:1564-1574.
[25]Li Yingkai, Hartline J D, Shan Liren, et al. Optimization of scoring rules[C]//Proc of the 23rd ACM Conference on Economics and Computation.New York:ACM Press,2022:988-989.
[26]Fung C, Yoon C J M, Beschastnikh I. The limitations of federated lear-ning in sybil settings[C]//Proc of the 23rd International Symposium on Research in Attacks, Intrusions and Defenses. 2020: 301-316.
[27]Pascanu R, Mikolov T, Bengio Y. On the difficulty of training recurrent neural networks[C]//Proc of International Conference on Machine Learning. 2013: 1310-1318.
[28]王永康, 翟弟华, 夏元清. 联邦学习中抵抗大量后门客户端的鲁棒聚合算法[J]. 计算机学报, 2023, 46(6): 1302-1314. (Wang Yongkang, Zhai Dihua, Xia Yuanqing. A robust aggregated algorithm against a large group backdoor clients in federated learning system[J]. Chinese Journal of Computers, 2023, 46(6): 1302-1314.)
