
单源域泛化中一种基于域增强和特征对齐的元学习方案
2024-08-15 00:00孙灿胡志刚郑浩
计算机应用研究 2024年8期









摘 要:基于元学习的单源域泛化(single domain generalization,SDG)已成为解决领域偏移问题的有效技术之一。然而,源域和增强域的语义信息不一致以及域不变特征和域相关特征难以分离,使SDG模型难以实现良好的泛化性能。针对上述问题,提出了一种单源域泛化中基于域增强和特征对齐的元学习方案(meta-learning based on domain enhancement and feature alignment,MetaDefa)。利用背景替换和视觉损害技术为每一张图像生成多样且有效的增强图像,保证了源域和增强域之间的语义信息一致性;多通道特征对齐模块通过关注源域和增强域特征空间之间的相似目标区域和抑制非目标区域的特征表示充分挖掘图像信息,进而有效地提取充足的可迁移性知识。通过实验评估,MetaDefa在office-Caltech-10、office31和PACS数据集上分别取得了88.87%、73.06%和57.06%的精确度。结果表明,MetaDefa方法成功实现了源图像和增强图像之间的语义一致性和对域不变特征的充分提取,从而显著提升了单源域泛化模型的泛化性能。
关键词:单源域泛化; 元学习; 域增强; 特征对齐
中图分类号:TP391.41 文献标志码:A
文章编号:1001-3695(2024)08-020-2392-06
doi:10.19734/j.issn.1001-3695.2023.11.0585
Meta-learning based on domain enhancement and feature alignment for single domain generalization
Sun Can, Hu Zhigang, Zheng Hao
(School of Computer Science & Engineering, Central South University, Changsha 410083, China)
Abstract:The single domain generalization(SDG) based on meta-learning has emerged as an effective technique for solving the domain-shift problem. However, the inconsistent semantic information between source and augmented domains and difficult separation of domain-invariant features from domain-related features make SDG model hard to achieve great generalization. To address the above problems, this paper proposed a novel meta-learning method based on domain enhancement and feature alignment(MetaDefa) to improve the model generalization performance. This method utilized background replacement and visual damage techniques to generate diverse and effective augmented images for each image, ensuring the consistency of semantic information between the source domain and the enhanced domains. The multi-channel feature alignment module fully mines image information by focusing on similar target regions between the source and enhanced domains feature spaces and suppressing feature representations of non-target areas, thereby effectively extracting sufficient transferable knowledge. Through experimental evaluation, MetaDefa achieved 88.87%, 73.06% and 57.06% accuracy on office-Caltech-10, office31 and PACS datasets, respectively. The results show that the MetaDefa method successfully achieves semantic consistency between the source and augmented images and adequate extraction of domain-invariant features, which significantly improves the generalization performance of single domain generalization models.
Key words:single domain generalization; meta-learning; domain enhancement; feature alignment
0 引言
被大量标签数据所驱动的深度神经网络在各种计算机视觉任务中取得了显著的进展[1, 2]。然而,当源域和目标域之间的数据分布存在明显差异时,源域上已训练好的模型在目标域上的性能会显著下降[3],这便是领域偏移问题。事实上,由于不能收集到输入图像每一种可能的变化(如光照、背景和天气等),领域偏移问题在现实场景中普遍存在。
单源域泛化是解决领域偏移问题的有效方法之一。SDG方法通过在单一源域中训练模型以学习可迁移性知识,并将这些知识应用于未知的多个目标域,从而提升模型的泛化性能[4]。在单源域泛化中,域增强技术是一种常见的方法。该方法在模型训练过程中通过合成多个增强域,提升了源域数据的复杂性和多样性[5~9]。差异多样的源域能够使模型有效地区分特定于域和语义的信息,消除模型预测与输入图像之间的虚假相关性。文献[5]通过将输入图像与另一个图像以一定的比例混合,生成了新的训练样本。文献[8]通过改变对象的位置、形状、纹理等信息以及向图像中添加不同类型的噪声随机生成增强域。这些方法扩充了训练数据,减少了模型过拟合的风险,但却破坏了输入图像的语义信息。另外一些研究者基于源域数据的特征表示来研究SDG,力求减小源域和增强域特征空间之间的表示差异,使模型更关注域不变特征[10~12]。Shu等人[10]引入了额外的熵正则化,通过最小化不同训练域数据分布之间的Kullback-Leibler散度推动模型学习域不变特征。Segu等人[11]使用依赖于域的批处理归一化层将图像样本映射到一个潜在空间以收集源域的统计信息,并利用领域特定属性来学习域潜在空间。Hou等人[12]设计了一个领域解耦与组合模块,通过傅里叶变换将源域特征解耦为域相关特征和域不变特征,同时引入了反向传导机制不断识别和更新域不变参数。上述方法尝试从特征空间中学习域不变特征,但当源域和目标域的数据分布存在显著差异时,该方法难以确保模型在未知目标域上的泛化效果。
uwRsXO40S2uQzL0B272dPyRPBmA0FL3VWqZg6Z0n4W8=为使模型更好地表征特征,提高对未知场景的适应性,近年来元学习单源域泛化备受关注[13~16]。在元学习单源域泛化方法中,源域数据被划分为虚拟训练域和虚拟测试域,两者组合构成虚拟任务。模型在虚拟任务中持续地学习和识别域不变特征,以期在面对未知的复杂目标域时能够实现出色的泛化效果。文献[13]在元学习过程中利用对抗性训练来创建虚构但具有挑战性的增强域,并使用Wasserstein自动编码器来放松最坏情况约束。文献[15]设计了一个特征评价网络,该网络评价特征提取器所生成特征的质量,并构建了一个可学习的辅助损失,为特征提取器提供额外的反馈。然而,上述方法在特征提取过程中主要侧重于简单地对齐域不变特征,存在着域相关特征抑制不足的问题。
针对上述问题,本文提出了一种单源域泛化中基于域增强和特征对齐的元学习方案。首先,引入了基于背景替换和视觉损害技术的域增强模块,通过考虑增强域的有效性和多样性,生成的增强域在保证语义信息一致性的同时也能更好地模拟目标域中的不同数据分布。其次,设计了多通道特征对齐模块,旨在减小源域和增强域特征空间中目标类别区域之间的距离,并压缩非目标类别区域,以提高模型对域不变特征的关注以及对域相关特征的抑制。
本文的主要贡献如下:
a)提出了域增强模块,通过在元学习训练过程中使用背景替换和视觉损害技术生成了多样且有效的增强域。该模块旨在模拟未知目标域数据分布时,不破坏源域的语义信息。
b)设计了一个多通道特征对齐模块,通过约束模型在相同输入图像的不同视图中识别一致且通用的视觉线索,并在未知目标域中重新利用这些线索,以期模型更关注域目标类别特征,并抑制非目标类别特征表达。
c)三个基准数据集上进行的大量实验显示了MetaDefa卓越的综合性能。
1 方法
在单源域泛化的元学习中,存在着单一源域S和多个目标域T。源域S和目标域T包含相同的任务,即具有相同的标签空间与输入特征空间,但两者的数据分布不同。源域S将被划分为虚拟训练域Strain和虚拟测试域Stest。引入函数f:Sx→y,用于将S中的输入图像x映射到类标签的热向量y,其中模型参数需要被学习。在每次迭代中,首先进入元训练阶段。模型开始在Strain上进行训练,计算损失和梯度,并更新参数=→i。随后,执行元测试阶段。在这个阶段中,使用更新后的参数i在Stest上训练模型以计算损失Euclid Math OneLAp(fi),然后计算并保存梯度。最后,重复整个过程n次,所有存储的梯度被累积并用于更新初始参数。
图1展示了MetaDefa的域增强和多通道特征对齐模块。其中,f表示参数为的模型骨干。wik表示完全连接层(fully connected layer,FC)中第k个特征图对应于类别i的权重。MetaDefa的算法细节如算法1所示。
算法1 单源域泛化中一种基于域增强和特征对齐的元学习方案
输入:源域S;超参数β;学习率lr;模型参数φ;跳跃点k;超参数λ1、λ2。
输出:训练好的模型参数。
1 extract data from source domain S for building task pool with N size, which contain Strain,Stest
2 randomly initialize
3 for epoch to epochs do
4 sample n tasks Ti from task pool
5 for all Ti do
6 if i≤k
7Euclid Math OneLAp=Euclid Math OneLApCE+λ1Euclid Math OneLApCAM
8 else
9Euclid Math OneLAp=Euclid Math OneLApCE+λ1(Euclid Math OneLApCAM+Euclid Math OneLAporiminor+Euclid Math OneLApaugminor)-λ2Euclid Math OneLApstyle
10 end if
11 //元训练阶段
12 carry out background substitution on Strain //保持有效性
13 carry out visual corruption on Strain //保持多样性
14 output Strainand Saugtrain
15 use Strainand Saugtrainto compute the loss:Euclid Math OneLApTi(fi)
16 compute the adapted parameters with gradient descent:
i=- lr*Euclid Math OneLApTi(fi)
17 //元测试阶段
18 carry out background substitution on Stest
19 carry out visual corruption on Stest
20 output Stestand Saugtest
21 use Stestand Saugtestdataset to compute the loss:Euclid Math OneLApTi(fi)
22 compute the gradient: iEuclid Math OneLApTi(fi)
23 end for
24 //真正参数更新
25 update =-β*∑n1Euclid Math OneLApTi(fi)/n
26 end for
1.1 域增强模块
为确保Strain与虚拟增强训练域Saugtrain,Stest与虚拟增强测试域Saugtest之间的语义信息一致性,考虑多样性和有效性,域增强模块通过背景替换和视觉损害技术生成最优的增强域。
1.1.1 背景替换
大量的研究表明,优先考虑图像的多样性而忽略有效性的数据增强方法会导致模型性能下降[17]。本文利用背景替换技术确保图像的有效性。在替换过程中,首先利用实例掩码注释来获得图像的对象区域并保持其位置不变。然后,从Strain中选择不同类的另一张图像,从该图像中随机裁剪一个补丁。最后,使用该补丁替换源图像背景,生成有效的增强图像。执行背景替换之后,图像的多样性得以增加,且不引入更多噪声,保证了增强图像的有效性。
1.1.2 视觉损害
引入视觉损害导致的图像多样性可以提升模型在处理未知的多个目标域时的泛化能力[18,19]。对图像施加视觉损害不仅会创建不同样式的增强域,还会引入大量与任务无关的视觉变化,这有助于模型在训练过程中忽略虚假模式。为进一步扩大增强域的多样性,即扩大Strain与Saugtrain、Stest与Saugtest之间的数据分布差异,使模型对于输入图像的变化、扭曲和噪声具有更好的鲁棒性。本文利用视觉损害技术来更好地模拟目标域的数据分布,并设计了一个最小阈值,只有随机损害概率高于阈值的视觉损害才会被执行。基本的视觉损害包括自动对比度、颜色、清晰度、傅里叶变换、ImageNet-C[19]等。
1.2 多通道特征对齐模块
Strain与Saugtrain、Stest和Saugtest之间的可迁移性知识会显著地影响模型的泛化性。在多通道特征对齐模块中,模型将关注域不变特征与抑制域相关特征,以提取充足的可迁移性知识。由于对Strain与Stest执行相同的特征对齐操作,故下文使用Strain表示虚拟域、Saugtrain表示增强虚拟域。
1.2.1 关注域不变特征
当模型聚焦于Strain和Saugtrain特征空间中对预测最有贡献的空间区域时,模型能够捕捉与域无关的普遍特征和模式,而不仅仅关注于特定的风格样式,这将显著提高模型的泛化性。类激活图(class activation maps,CAM)能够可视化给定特征图中对输出贡献最大的空间区域,为模型预测提供视觉解释[20]。与CAM-loss[21]不同,本文通过最小化Strain与Saugtrain的CAM之间的距离,旨在约束模型在相同输入图像的不同视图中找到一致且通用的视觉线索。模型将在未知的多个目标域中重用这些线索,以提高对域不变特征的捕捉能力。
形式上,模型最后一层的卷积层将输出一定数量的特征图,其中fk(x,y)代表第k个特征图在空间位置(x,y)处的激活值。对第k个特征图的高度H和宽度W执行全局平均池化:Fk=1H×W∑x,yfk(x,y)。对于给定的类别i,执行softmax操作以得到类别分数zi=∑kwikFk,其中wik表示在完全连接层FC中第k个特征图对应于类别i的权重。将Fk和zi合并得到:
zi=1H×W∑x,yfk(x,y)
=1H×W∑x,y∑kwikfk(x,y)
(1)
定义CAMi为类别i的类激活图,其中每一个空间元素为
CAMi(x,y)=∑kwikfk(x,y)(2)
其中:CAMi(x,y)表示空间位置(x,y)处的激活值对图像属于类别i的可能性。为使模型在Strain和Saugtrain的CAM中找寻一致且通用的视觉线索,使用Jensen-Shannon散度构建Euclid Math OneLApCAM损失:
Euclid Math OneLApCAM(MCAM,MaugCAM,i)=DJS(MCAM‖MaugCAM)(3)
其中:MCAM为给定类别i的虚拟域Strain的CAM;MaugCAM为增强虚拟域Saugtrain的CAM。
1.2.2 抑制域相关特征
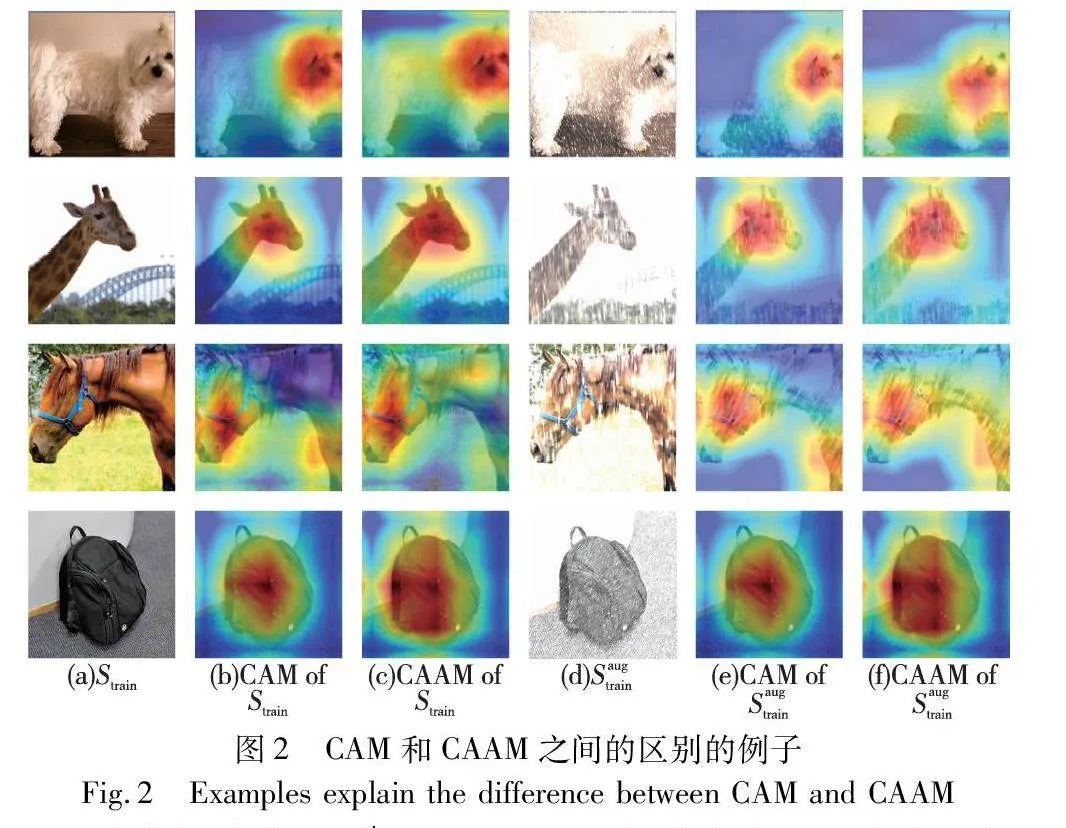
如图2所示,(a)表示虚拟域Strain,(b)(c)分别表示Strain的CAM和CAAM。同样,(d)表示增强虚拟域Saugtrain,(e)(f)表示Saugtrain的CAM和CAAM。通过对比图2(a)与(b),(d)与(e),由于目标类别和非目标类别的CAM在某些区域中可能重叠,仅考虑CAM,模型在非目标类别和图像类别数据之间的复杂关系方面存在局限。与CAM相比,图2(c)(f)所示的类别不可知激活图(class agnostic activation maps,CAAM)展现出更显著的激活区域和更丰富的特征,其中每个空间元素表示为CAAM(x,y)=∑kfk(x,y)。不幸的是,CAAM中包含的冗余特征可能导致非目标类别的置信度得分超过目标类别的置信度得分,从而引起难以接受的误分类。为抑制非目标类别(域相关)特征的表达,鼓励图像的CAAM与目标类别的CAM密切对齐。Euclid Math OneLAporiminor损失、Euclid Math OneLApaugminor损失被定义为
Euclid Math OneLAporiminor(MCAAM,MCAM,i)=1H×W
∑x,y‖MCAAM-MCAM‖(4)
Euclid Math OneLApaugminor(MCAAM,MaugCAM,i)=1H×W∑
x,y‖MaugCAAM-MaugCAM‖(5)
其中:MCAAM、MaugCAAM分别为Strain和Saugtrain的CAAM;MCAM、MaugCAM为Strain和Saugtrain的CAM;Euclid Math OneLAporiminor和Euclid Math OneLApaugminor代表着Strain与Saugtrain中的次要区域。相比于文献[21],为进一步提高模型对非目标类别(风格样式)的感知和抑制,虚拟域Strain和增强虚拟域Saugtrain之间的次要区域应尽可能不同,构建了Euclid Math OneLApstyle损失:
Euclid Math OneLApstyle(Euclid Math OneLAporiminor,Euclid Math OneLApaugminor,i)=Euclid Math OneLAporiminor-Euclid Math OneLApaugminor(6)
根据式(3)~(6),考虑到Euclid Math OneLApCAM、Euclid Math OneLAporiminor和Euclid Math OneLApaugminor都与特征之间的相关性有关,而Euclid Math OneLApstyle为两个数值之差,通过引入超参数λ1、λ2,最终的目标函数定义为
Euclid Math OneLAp=Euclid Math OneLApCE+λ1(Euclid Math OneLApCAM+Euclid Math OneLAporiminor+Euclid Math OneLApaugminor)-λ2Euclid Math OneLApstyle(7)
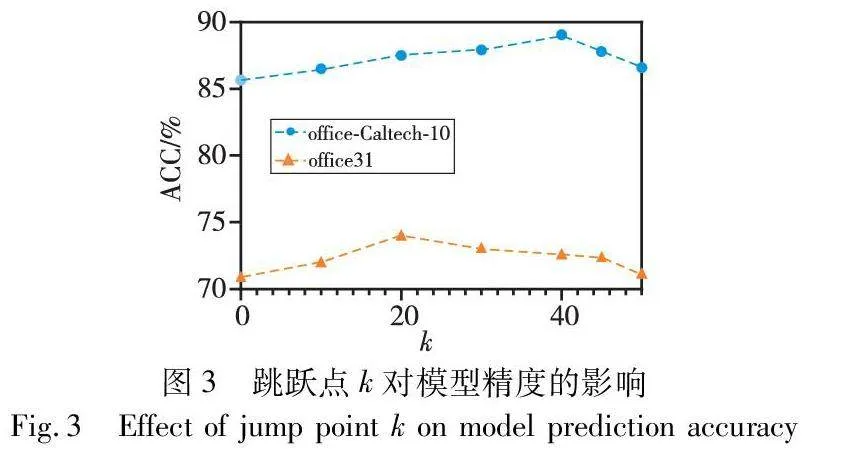
确定何时引入Euclid Math OneLAporiminor、Euclid Math OneLApaugminor和Euclid Math OneLApstyle损失成为了一个需要解决的问题。直观地说,模型在训练的早期阶段获得的CAM过于离散,难以有效引导CAAM靠近CAM。而在训练后期,CAM获得了显著的目标类别特征,具备足够的能力引导CAAM。此次选择经过精心设计,形成了一个简明而有效的跳跃过程。具体而言,在每一轮训练的前k个任务中选择不应用Euclid Math OneLAporiminor、Euclid Math OneLApaugminor和Euclid Math OneLApstyle损失,而在第k个任务之后引入这些损失。本文采用ResNet-18模型,在office-Caltech-10和office31数据集上进行了图像分类实验,以研究跳跃点k与模型精度之间的关系。每轮任务的数量设定为50,实验结果如图3所示。
在office-Caltech-10上的实验结果表明,随着k值的增加,模型精度逐渐提高,直至在k=40时到达最高值,之后开始下降。第一次训练时(k=0),由于前期模型学习到的CAM过于简单和离散,未能有效引导CAAM,甚至导致CAM向CAAM靠拢。随着k值的增加,模型学到的目标类别特征越加清晰和显著,CAM能够更有效地引导CAAM靠拢。然而,当k值过大时,考虑CAAM的时间过晚,模型对于非目标类别特征的学习较差。因此整体精度曲线呈现出先上升,达到最高值后再下降的趋势。在office31上模型精度与跳跃点k值的相关性与office-Caltech-10总体趋势一致。不同之处在于,在office31数据集上,达到最高点的k值为20。这表明所提出的MetaDefa方案在关注目标类别特征表达的基础上,还广泛抑制了非目标类别特征的表达。由此导致在面对数据量更多,域差异更大的数据集时,模型在训练前期学到的CAM会更加详细和聚集,这也意味着只需要较少的任务模型就能够学习到足够的可迁移性知识,从而有效地引导CAAM靠拢CAM。
2 实验
2.1 数据集和实验设置
为了评估MetaDefa在元学习单源域泛化中的可行性和有效性,本文进行了广泛的实验分析,选取了三个具有挑战性的基准数据集:office-Caltech-10(office10)[22]、office31[23]和PACS[24]。office-Caltech-10数据集包含分布在四个域的2 533张图像,这些域包括C(Caltech)、A(Amazon)、W(Webcam)、D(DSLR)。而office31包含来自三个域(A,W,D)的4 110张图像,涵盖31个类别。与只有10个类别的office-Caltech-10相比,office31的类别更多,域之间的分布差异也更大,因而更具挑战性。PACS数据集包含来自4个不同领域的9 991张图像,涵盖7个类别。这些领域分别是photo(照片)、art(艺术绘画)、cartoon(卡通)和sketch(素描)。相比其他数据集,PACS所包含的四个域之间存在较大的风格差异,故被认为是一个更具挑战性的数据集。
在所有的设置中,本文将RGB图像的大小统一调整为224×224。office-Caltech-10和office31数据集选择域DSLR作为源域,PACS选择photo为源域。模型使用在ImageNet上预训练的ResNet-18模型,并使用SGD优化器,设置学习率、批次大小和训1EqXmV2yiul7vzrGAmi0uA==练批次分别为4×10-3、32和30。所有实验均重复五次,最终结果取平均值。“AVG”列表示方法在多个目标域上的平均性能。
2.2 基线和比较方法
为了评估MetaDefa的有效性,从域增强和特征对齐两方面进行了比较,包括:a)基线,只使用交叉熵损失而不使用任何域增强的元学习;b)CutOut[6]和RandAugment(RandAug) [8]使用先进域增强技术,而其他模块设置与MetaDefa一致;c)L2D[25],基于语义一致性来对齐领域不变特征;d)ACVC[18],基于类激活图但不抑制非目标类别特征表达;e)CAM-loss[21],仅约束CAAM靠拢CAM。
2.3 在office-Caltech-10、office31和PACS上的比较
如表1所示(表中黑体数据为最优值,下同),MetaDefa在offiv2lUxr8fCDEmeNqYoOqKrg==ce-Caltech-10的三个目标域上均取到了最优的泛化效果,模型精度分别为88.44%、80.21%和97.97%。通过考虑增强的有效性,MetaDefa相比于仅关注多样性的CutOut和RandAugment分别提高了2.62%和2.8%的性能,这验证了所提出域增强模块的有效性。此外,MetaDefa在特征对齐过程中抑制了非目标类别特征表达,模型获得了更多的可迁移性知识,使得MetaDefa的性能比L2D、ACVC和CAM-loss分别提高了2.54%、1.66%和1.43%。
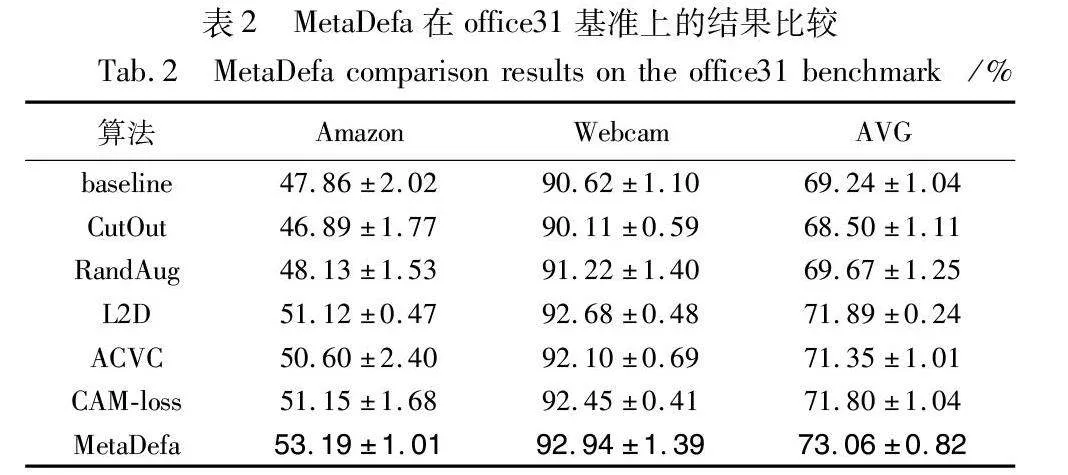
如表2所示,MetaDefa相比于对比方法在office31数据集上获得了更优的泛化性能,仅使用简单的域增强方法如CutOut和Rangdug,模型的泛化性能提升有限,分别为-0.74%和0.43%。而MetaDefa方法实现了显著的3.82%精度提升,这凸显了考虑增强有效性的重要性和所提出域增强模块的有效性。在与源域DSLR有较大差异的Amazon域上,MetaDefa相较于性能排名第二的CAM-loss方法提升了2.04%,这表明抑制非目标类别特征的表达能大幅度地提升模型的泛化性能。通过缩小图像的次要区域,相比在office-Caltech-10上只提升了2.76%的精度,MetaDefa 在类别更多且域差异更显著的office31数据集上表现得更为优越,模型精度提升了3.82%。结合图4(a)(b)可知,MetaDefa在office-Caltech-10和office31数据集上都展现出了通用性和先进性。
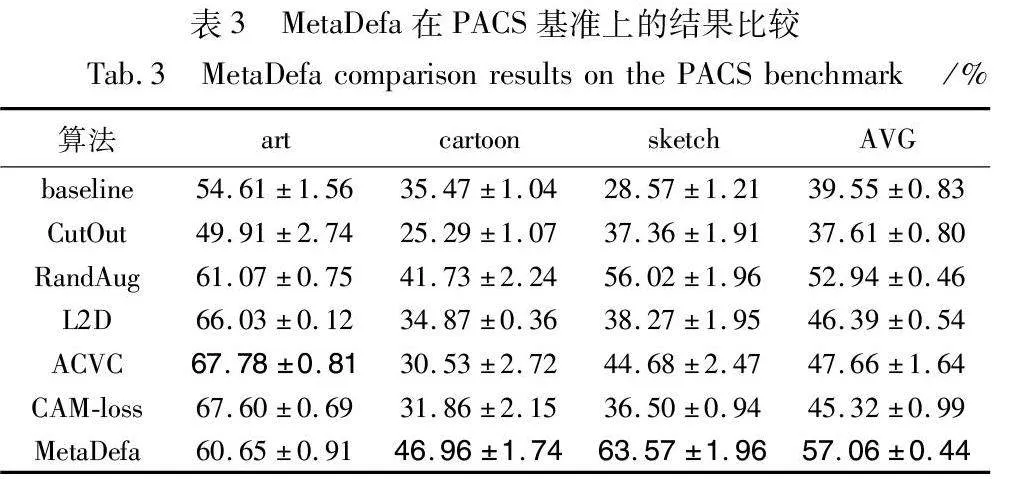
根据表3所示,MetaDefa在PACS数据集上获得了最佳的泛化性能,达到了57.06%。与office-Caltech-10和office31相比,PACS上的基线精度较低。这表明仅使用CE损失在数据量更多且域差异更大的PACS数据集上难以学到泛化性能良好的模型。在域差异较大的cartoon和sketch目标域上,MetaDefa方法显示出了显著的性能提升,相比于性能排名第二的RandAug方法分别提升了5.23%和7.55%。这验证了所提出的域增强模块不仅确保了语义信息一致性,还生成了更符合未知目标域数据分布的样本。而在域差异较小的art域上,MetaDefa方法相比基线也提升了6.04%,但弱于ACVC等方法。这表明MetaDefa为防止模型过拟合,主要关注于与源域差异较大的目标域。
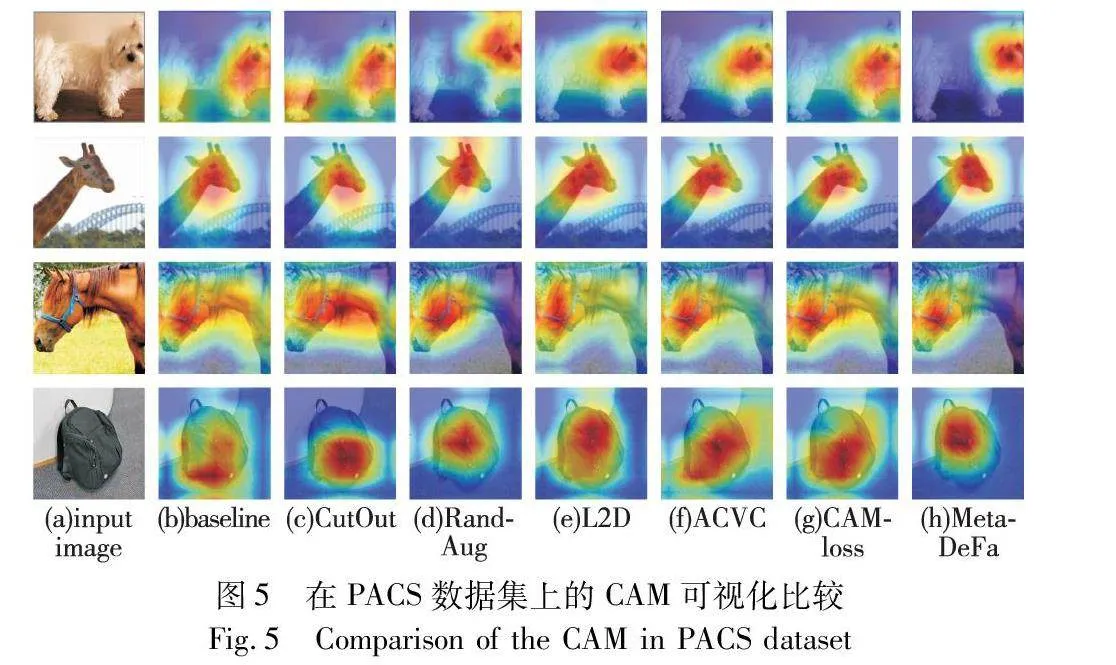
为定性分析MetaDefa在PACS数据集上的性能表现,本文可视化展示了各方法在PACS数据集上的CAM,如图5所示。从图5中可以看出,经典的CutOut方法会混合图像区域,这破坏了图像的语义信息,导致了更大的激活区域,使得模型的关注焦点偏离了对象目标区域。ACVC和L2D等方法成功找到了目标区域,但存在着非目标类别特征表达,而RandAug方法也存在抑制非目标类别不显著的问题。相比之下,MetaDefa方法不仅准确识别到了目标类别区域,还广泛抑制了非目标类别特征的表达。
3 消融实验
在MetaDefa中,基于多通道特征对齐构建的不同损失项Euclid Math OneLApCAM、Euclid Math OneLAporiminor、Euclid Math OneLApaugminor、Euclid Math OneLApstyle对于模型精度有着至关重要的影响。因此,本文在三个基准数据集上进行了充分的消融实验以评估这些损失项的有效性和适用性。同时,通过实验结果观察和验证了超参数λ1和λ2对元学习过程中模型训练的影响。
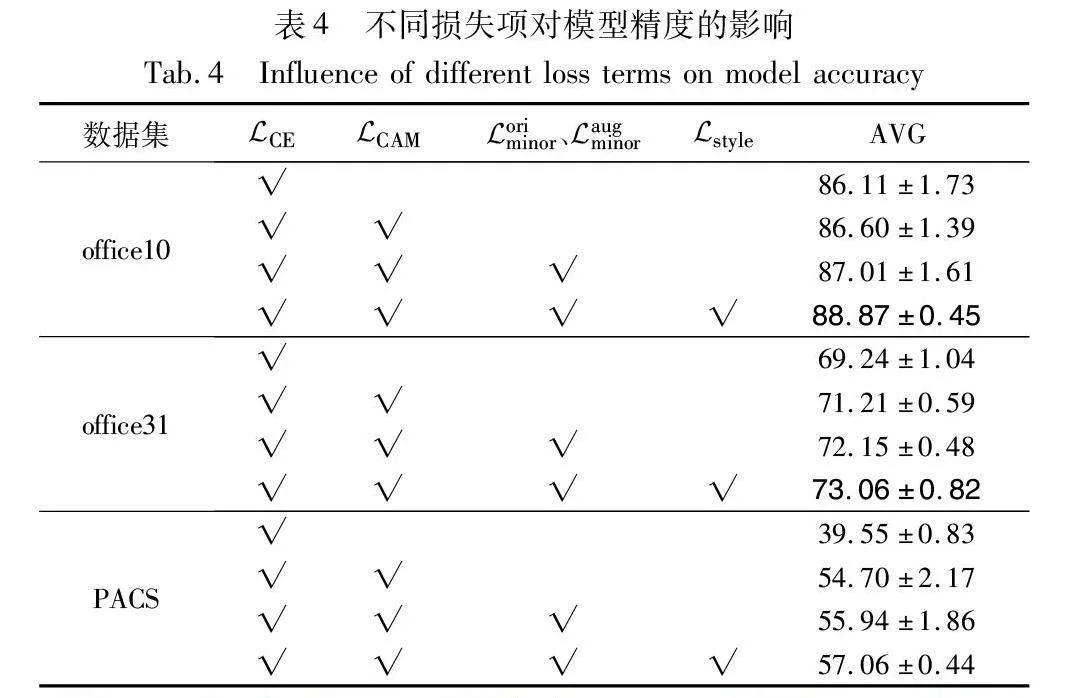
3.1 不同损失项对模型精度的影响
如表4所示,设计的损失项在交叉熵损失的基础上都显著提高了模型的预测精度。在office-Caltech-10上,选择在Euclid Math OneLApCAM、Euclid Math OneLAporiminor、Euclid Math OneLApaugminor基础上加入Euclid Math OneLApstyle损失,模型精度提升了1.86%。这体现了提高模型对非目标类别敏感度的优越性。在office31上测试时,仅加入Euclid Math OneLApCAM时,准确度略微提高了1.97%,而在同时加入Euclid Math OneLApCAM、Euclid Math OneLAporiminor、Euclid Math OneLApaugminor时,精度却提升了2.91%,这表明简单地让模型关注图像的主要目标类别特征对于模型的泛化性提升有限。而当引入CAAM后,通过约束CAAM靠拢CAM并抑制更广泛的非目标区域(例如背景),模型精度有了显著的提升。图6可视化展示了在PACS数据集上不同损失项的CAM。对比图6(a)与(b)可知,Euclid Math OneLApCAM使模型的关注焦点从错误的激活区域主要集中于目标类别区域。对比图6(b)与(c),在Euclid Math OneLApCAM基础上加入Euclid Math OneLAporiminor和Euclid Math OneLApaugminor,错误的激活区域进一步减少。而对比图6(a)与(d),设计的损失项使模型更加集中表达目标类别特征,并广泛抑制了非目标类别特征。
3.2 超参数对模型精度的影响
超参数λ1代表着Euclid Math OneLApCAM、Euclid Math OneLAporiminor、Euclid Math OneLApaugminor的权重,而λ2代表Euclid Math OneLApstyle的权重。为更好地提高模型的泛化性,本文进行了大量的消融实验以研究λ1、λ2对模型精度的影响。首先,固定λ2为0.5,然后设置λ1的取值为{0.005,0.01,0.06,0.1,0.2},以评估模型在office-Caltech-10和office31上的性能表现。如图7(a)所示,可以看出当λ1=0.06时,模型都取得了最好的精度。关于λ2的影响描述在图7(b)中,设置λ2的取值为{0.1,0.2,0.5,1.0},并且固定λ1=0.06。可以看出,λ2在这两个数据集上的最好取值并不相同。在office-Caltech-10上,当λ2=0.5时模型性能最佳。而在office31时,λ2的最佳取值为0.2。这是因为与office-Caltech-10相比,office31域之间的分布差异较大,即图像的风格样式差异较大,导致Euclid Math OneLApstyle取值也较大。因此,较小的权重能够有效地抑制非目标类别特征的表达。
4 结束语
为解决元学习单源域泛化中源域和增强域语义信息不一致以及域不变特征和域相关特征难以分离的难题,本文提出了一种基于域增强和特征对齐的元学习方案。其核心思想是利用背景替换和视觉损害技术构建多样且有效的增强域,并约束模型关注于图像的主要目标类别特征和驱使类不可知激活图靠拢类激活图,使模型更倾向于表达目标类别特征并抑制非目标类别特征。实验结果表明,MetaDefa方法在三个基准数据集上实现了良好的泛化性能。改进后的网络模型实现了对特征空间良好的分离,但引入的损失项较多,如何度量各损失之间的相关性并没有被详细讨论。因此在未来的工作中,将进一步研究如何为构建的损失项自适应分配权重,以更好地解决元学习单源域泛化问题。
参考文献:
[1]潘雪玲, 李国和, 郑艺峰. 面向深度网络的小样本学习综述 [J]. 计算机应用研究, 2023, 40(10): 2881-2888,2895. (Pan Xueling, Li Guohe, Zheng Yifeng. Survey on few-shot learning for deep network[J]. Application Research of Computers, 2023, 40(10): 2881-2888,2895.)
[2]杨朋波, 桑基韬, 张彪, 等. 面向图像分类的深度模型可解释性研究综述[J]. 软件学报, 2023, 34(1): 230-254. (Yang Pengbo, Sang Jitao, Zhang Biao, et al. Survey on interpretability of deep models for image classification[J]. Journal of Software, 2023, 34(1): 230-254.)
[3]Wang Mei, Deng Weihong. Deep visual domain adaptation: a survey[J]. Neurocomputing, 2018, 312: 135-153.
[4]Wang Jindong, Lan Cuiling, Liu Chang, et al. Generalizing to unseen domains: a survey on domain generalization[J]. IEEE Trans on Knowledge and Data Engineering, 2023, 35(8): 8052-8072.
[5]Zhang Hongyi, Cisse M, Dauphin Y N, et al. mixup: beyond empirical risk minimization[EB/OL]. (2017). https://arxiv.org/abs/1710.09412.
[6]DeVries T, Taylor G W. Improved regularization of convolutional neural networks with cutout[EB/OL]. (2017-08-15). https://arxiv.org/abs/1708.04552.
[7]Yun S, Han D, Oh S J, et al. Cutmix: regularization strategy to train strong classifiers with localizable features[C]//Proc of IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2019: 6023-6032.
[8]Cubuk E D, Zoph B, Shlens J, et al. RandAugment: practical automated data augmentation with a reduced search space[C]//Proc of IEEE International Conference on Computer Vision and Pattern Re-cognition Workshops. Piscataway, NJ: IEEE Press, 2020: 702-703.
[9]邢艳, 魏接达, 汪若飞, 等. MaskMix: 用于变化检测的掩码混合数据增强方法[J]. 计算机应用研究, 2023, 40(12): 3834-3840,3847. (Xing Yan, Wei Jieda, Wang Ruofei, et al. MaskMix: mask mixing augmentation method for change detection[J]. Application Research of Computers, 2023, 40(12): 3834-3840,3847.)
[10]Shu Yang, Cao Zhangjie, Wang Chenyu, et al. Open domain gene-ralization with domain-augmented meta-learning[C]//Proc of IEEE International Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2021: 9624-9633.
[11]Segu M, Tonioni A, Tombari F. Batch normalization embeddings for deep domain generalization[J]. Pattern Recognition, 2023, 135: 109115.
[12]Hou Feng,Zhang Yao,Liu Yang,et al. Learning how to learn domain-invariant parameters for domain generalization[C]//Proc of IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway, NJ: IEEE Press, 2023: 1-5.
[13]Qiao Fengchun, Zhao Long, Peng Xi. Learning to learn single domain generalization[C]//Proc of IEEE International Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2020: 12556-12565.
[14]Balaji Y, Sankaranarayanan S, Chellappa R. MetaReg: towards domain generalization using meta-regularization[J]. Advances in Neural Information Processing Systems, 2018, 31: 998-1008.
[15]Li Yiying, Yang Yongxin, Zhou Wei, et al. Feature-critic networks for heterogeneous domain generalization[C]//Proc of the 36th International Conference on Machine Learning.[S.l.]: PMLR, 2019: 3915-3924.
[16]Zhao Yuyang, Zhong Zhun, Yang Fengxiang, et al. Learning to ge-neralize unseen domains via memory-based multi-source meta-learning for person re-identification[C]//Proc of IEEE International Confe-rence on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2021: 6277-6286.
[17]Deng Weijian, Zheng Liang. Are labels always necessary for classifier accuracy evaluation?[C]//Proc of IEEE International Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2021: 15069-15078.
[18]Cugu I, Mancini M, Chen Y, et al. Attention consistency on visual corruptions for single-source domain generalization[C]//Proc of IEEE International Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 4165-4174.
[19]Hendrycks D, Dietterich T. Benchmarking neural network robustness to common corruptions and perturbations[EB/OL].(2019). https://arxiv. org/abs/1903.12261.
[20]Zhou Bolei, Khosla A, Lapedriza A, et al. Learning deep features for discriminative localization[C]//Proc of IEEE International Confe-rence on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2016: 2921-2929.
[21]Wang Chaofei, Xiao Jiayu, Han Yizeng, et al. Towards learning spatially discriminative feature representations[C]//Proc of IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2021: 1326-1335.
[22]Gong Boqing, Shi Yuan, Sha Fei, et al. Geodesic flow kernel for unsupervised domain adaptation[C]//Proc of IEEE International Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2012: 2066-2073.
[23]Saenko K, Kulis B, Fritz M, et al. Adapting visual category models to new domains[C]//Proc of the 11th European Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2010: 213-226.
[24]Li Da, Yang Yongxin, Song Y Z, et al. Deeper, broader and artier domain generalization[C]//Proc of IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2017: 5542-5550.
[25]Wang Zijian, Luo Yadan, Qiu Ruihong, et al. Learning to diversify for single domain generalization[C]//Proc of IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2021: 834-843.
