
融合相似度负采样的远程监督命名实体识别方法
2024-08-15 00:00刘杨线岩团相艳黄于欣
计算机应用研究 2024年8期








摘 要:实体漏标是目前远程监督命名实体识别(distantly supervised named entity recognition,DS-NER)存在的一个难点问题。训练集中的漏标实体在模型训练中提供了不正确的监督信息,模型将在后续预测实体类型时更倾向于将该类实体预测为非实体,导致模型的实体识别和分类能力下降,同时影响了模型的泛化性能。针对这一问题,提出了融合实体特征相似度计算负采样命名实体识别方法。首先,通过对候选样本和标注实体样本进行相似度计算并打分;其次,以相似度得分作为依据对候选样本进行采样,采样出参与训练的样本。与随机负采样方法相比,该方法通过结合相似度计算,降低了采样到漏标实体的可能性,进而提高了训练数据的质量,从而提升了模型的性能。实验结果表明,该方法在 CoNLL03、Wiki、Twitter三个数据集上与其他模型相比,比基线模型平均取得了5%左右的F1值提升,证明了该方法能够有效缓解远程监督条件下实体漏标带来的命名实体识别模型性能下降的问题。
关键词:命名实体识别; 实体漏标; 远程监督; 负采样; 数据增强
中图分类号:TP391 文献标志码:A
文章编号:1001-3695(2024)08-011-2322-07
doi:10.19734/j.issn.1001-3695.2023.12.0577
Incorporating similarity negative sampling for distantly supervised NER
Liu Yang1,2, Xian Yantuan1,2, Xiang Yan1,2, Huang Yuxin1,2
(1.Faculty of Information Engineering & Automation, Kunming University of Science & Technology, Kunming 650500, China; 2.Yunnan Key Laboratory of Artificial Intelligence, Kunming 650500, China)
Abstract:The entity omission is a typical problem of distantly supervised named entity recognition. Entity omission in the training set provides incorrect supervision information during model training, model will be more inclined to predict this type of entity as a non-entity when subsequently predicting entity types, resulting in a decline in the model’s entity recognition and classification capabilities, and affects the generalization performance of the model. To deal with the problem, this paper proposed a incorporating similarity negative sampling for distantly supervised named entity recognition. Firstly, it calculated and scored the similarity between the candidate samples and the labeled entity samples. Secondly, it sampled the candidate samples based on the similarity score, and sampled the samples participating in the training. Compared with the random negative sampling method, this method reduced the possibility of sampling missing entities by combining similarity calculations, thereby improving the quality of training data and thus improving the performance of the model. Experimental results show that compared with other models on the three data sets of CoNLL03, Wiki, and Twitter, compared with the baseline model, the proposed model achieved an average F1 value improvement of about 5 percentage points. It is proved that this method can effectively alleviate the problem of performance degradation of the named entity recognition model caused by missing entities under distantly supervised conditions.
Key words:named entity recognition; entity omission; distantly supervised; negative sampling; data augmentation
0 引言
命名实体识别(named entity recognition,NER)主要是从文本中识别出特定类别的实体,例如人名、地名、组织机构名等,是自然语言处理(natural language processing,NLP)中的基础任务之一,能够服务于事件抽取[1]、实体链接[2]、关系抽取[3]、知识图谱等一系列下游任务。例如:在对话理解任务中,系统通过命名实体识别系统提取出相应的实体词,能够帮助系统更加准确地理解对话;在机器翻译任务中,正确的识别命名实体有助于保证翻译的准确性和一致性,提高机器翻译模型的整体性能,所以提升命名实体识别模型的性能是十分必要的。
早期的命名实体识别任务识别实体种类少,标注粒度较粗,且语种和领域单一,随着自然语言处理任务的不断发展和应用领域的不断拓展,为了保障下游任务的性能,就对命名实体识术提出了更高的要求。实体种类由早期的几类实体类型发展到十几类实体类型;标注粒度从早期的粗粒度标注进化到更细粒度的标注;从早期的大语种不断发展到使用人口较少的语种,并且根据不同具体的应用领域衍生出了针对领域的命名实体识别等。由于上述原因,命名实体识别使用人工标注训练数据成为了制约模型性能发展的一大瓶颈。由于语种与领域的不断拓展,利用人工方式来标注数据花费时间较长,成本较为高昂,难以满足当前条件下各类命名实体识别模型对训练数据的要求。一种解决手段是引入远程监督(distantly supervised,DS)[4]的策略,不同于传统命名实体识别方法采用人工标注数据来训练,远程监督的思路是利用外部知识库或领域词典对来自不同语种或者不同领域的训练数据进行大量的标注,这样可以使得模型获得所需的训练数据,从而缓解训练数据缺乏的问题。在拥有了训练数据后,命名实体识别模型的应用领域由此得到了极大扩展,下游任务性能也因此得到了提高。
不过基于远程监督方法的命名实体识别仍存在缺陷,这阻碍了远程监督方法的进一步使用,因为通过远程监督获取的标签,标注的实体大多有正确的标签,由于外部知识库或词典并不是完备集,其覆盖范围有限,不能保证完全覆盖数据集中包含的所有实体,从而导致数据集中有少量标注数据存在实体被漏标的情况。图1展示了一个远程标注示例,其中“OGR”指机构,“PER”指人名。第一行是初始文本,第二行是远程监督标注,第三行是正确标注。示例中,由于外部知识库或者词典不完备,机构实体“Manchester City”和“Arsenal”未被标注。
若有某个实体在训练集中被漏标,模型在训练时便会将其作为非实体学习,导致模型在后续预测实体类型时更倾向于将该实体预测为非实体,这将损害模型的性能。
在训练过程中引入负采样策略缓解漏标实体问题是当前的一种主流方法,能够在一定程度上避免采样到漏标实体作为负例参与训练。已有的采样方法在采样策略上进行了诸多探索,如随机采样、均匀采样[5]、加权采样[6]等,有效地提升了远程监督命名实体识别的效果。然而上述模型的采样方法在采样策略上大多带有一定的随机性,不可避免地导致采样出部分漏标实体参与训练,给模型带来了不正确的监督信号,从而导致命名实体识别模型性能下降。
针对上述提出的问题,本文提出了融合相似度负采样的远程监督命名实体识别方法。该方法主要贡献在于:
a)不同于之前方法的负采样策略带有随机性,本文提出了融合相似度计算的主动采样策略,能够尽可能地避免采样出未标注的实体参与训练,提高训练数据的质量,缓解实体漏标带来的模型性能下降问题。
b)采用了基于同义实体词替换的数据增强方法,有效地扩充了训练数据,同时提高了训练样本的丰富度,而且可以获得相对原始数据更多样性的语义特征。
c)本文方法在CoNLL03、Wiki、Twitter三个数据集上的结果与以往的基线模型相比,性能相比基线模型平均取得了5%左右的F1值提升。
1 相关工作
命名实体识别方法的发展经历了基于规则和手工模板的方法、基于统计机器学习方法和基于深度学习的方法三个阶段。
早期的命名实体识别方法主要采用基于规则和手工模板的方法,该方法主要通过相关领域专家对目标文本手工制定有效的规则识别命名实体。
基于统计机器学习的方法从给定的、有标签的训练数据出发,然后通过手动方式构造特征,根据特定模型对文本中的每个单词进行标签的标注,实现命名实体识别。方法有条件随机场(conditional random field,CRF)[7,8]、最大熵模型(maximum entropy,ME)[9]、支持向量机(support vector machine,SVM)[10]、隐马尔可夫模型(hidden Markov model,HMM)[11]等。
近年来,随着技术的发展和计算设备算力的不断提升,深度学习在计算机视觉、图像处理等方面取得了巨大的成功,而且在自然语言处理领域的应用也取得了很大的进步。命名实体识别方法的研究也从传统基于统计机器学习的方法转向基于深度学习的方法。长短期记忆网络(long short-yerm memory,LSTM)[12]被应用于处理命名实体识别问题,使用LSTM作为编码器,CRF作为解码器成为了NER任务中最基础的模型架构之一。Lample等人[13]在此基础上采用了双向长短期记忆网络(bi-directional long short-term memory,BiLSTM)作为编码器,提出了BiLSTM-CRF模型用于解决命名实体识别问题,BiLSTM网络结构有效利用输入的前向和后向特征信息,能同时关注到上下文的语义信息进行输出。Google在2018年提出基于Transformer的预训练语言模型(pre-trained language model,PLM)BERT(bidirectional encoder tepresentations from Transfor-mers)[14],在多项NLP任务中成功SOTA(state-of-the-art),掀起了NLP领域使用预训练语言模型的潮流,此后大多NER工作均在PLM的基础上进行微调。
基于跨度(Span)的命名实体识别方法是一种直观而有效的方式,基于Span的方法将句子视为实体跨度的集合,其中的元素就是句子所有可能的子序列,利用Span的语义信息对每一个Span进行验证,进而可以有效地识别实体。Fu等人[15]首先研究了基于Span的命名实体识别预测模型,并与传统序列标记框架进行了对比。游新冬等人[16]提出了一种基于跨度与拼接的中文命名实体抽取模型,在多个中文命名实体识别数据集上的实验证明了其有效性。
为了克服人工标注时间成本过长的缺陷,能以较快的速度构建数据集,远程监督方法被用于训练数据标注。但在实际应用中,外部知识库或词典并不是完备集,无法保证完整覆盖训练集中的所有实体,实体漏标情况不可避免。为了减轻漏标实体对模型的影响,Yang等人[17]将部分条件随机场 (partial conditional random fields,partial CRF)引入学习过程中,同时设计了一个选择器对样本进行过滤,在一定程度上减轻了远程监督所带来的漏标问题。Peng 等人[18]提出了一种基于正无标注(positive-unlabeled,PU)学习的命名实体识别方法,该方法可以利用未标注数据和实体词典进行模型的学习,且只需使用实体词典去标注部分实体,当词典的质量不佳时,该方法仍能很好地识别句子中的实体。但当高质量的训练数据稀缺时,上述方法仍会很大程度上受到未标注实体的影响,从而影响模型的性能。
漏标的实体(伪负样本)所占比例与真负样本相比占较少,因此负采样的优势在于能够提高采集到真负样本的概率。因而在实体漏标条件下训练模型过程中,负采样策略被广泛应用。杨一帆等人[19]在病历领域使用了负采样方法,有效缓解了医疗领域数据漏标造成的模型性能下降问题。Xu等人[20]利用Span标注方法,以负采样的方式代替了部分训练,缓解了远程监督数据集中样本带噪的问题。但是上述负采样策略均基于随机性采样,仍会采样出部分漏标实体参与训练,影响命名实体识别模型的性能。
数据增强(data augmentation)一般是基于现有数据生成更多的新数据,这样可以增加训练的数据量,提高模型的泛化能力;或者给数据增加噪声,提升模型的鲁棒性。计算机视觉(computer vision,CV)被广泛使用,在NLP任务中也被普遍应用。Yang等人[21]提出了一种名为FactMix的数据增强方法,通过利用训练集对训练样本进行词替换,利用PLM对非实体部分进行随机替换,能够提高模型的跨领域能力。Wei[22]等人提出一种简易的数据增强技术(easy data augmentation,EDA),通过同义词替换、随机插入、随机交换和随机删除实现数据增强效果,能够提高神经网络的分类性能。但上述数据增强方式大多是随机的,增强应尽可能YpIUO1m1a4xSnwsx87HXAQ==使扩增的数据句子在语义和结构上没有发生变化,而对应的实体之间类型应该相同。因此,本文的数据增强考虑采用基于同义实体词替换的数据增强方法。
2 融合相似度负采样的远程监督命名实体识别模型
2.1 问题定义
命名实体识别是将文本中的命名实体定位识别并分类为预定义实体类型(如人名、组织名、地名等)的过程。给定一个长度为n的句子X={x1,x2,…,xn},基于Span的方法是通过枚举出X所有可能的子序列,即跨度(Span),本文使用S表示所有可能的Span的集合,记为S={s1,1,s1,2,…,si,j,…,sn,n}。其中使用(i,j)来表示每个单独的Span,i表示每个Span在句子中的开始位置,j表示每个Span的结束位置,L为Span的最长取值,即0<j-i<L。对于所有枚举出的Span,模型会从预定义的标签空间预测相应的实体类型,预定义的标签空间中有v个实体类型,记为Y={y1,y2,…,yv}。
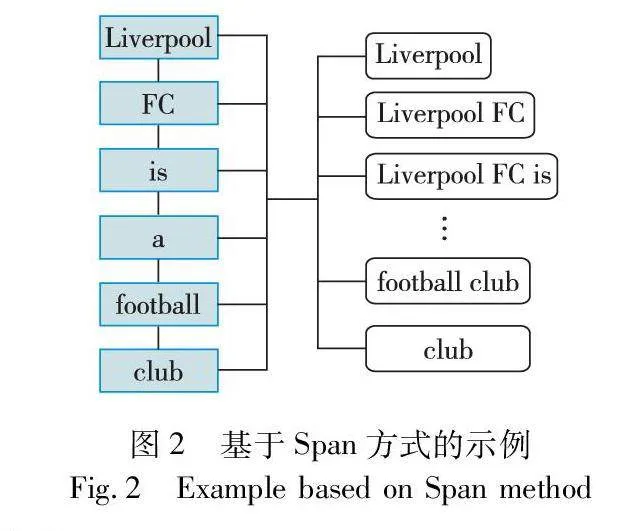
如图2所示,给定一个句子x=“Liverpool FC is a football club”,其对应标签为Y={(0,1,ORG)},其可能的所有跨度为
S={(0,0),(0,1),…,(1,1),(1,2),…,(5,5)}
对于其他非实体Span,则被标记为标签O。
2.2 模型架构
原有的负采样策略采样过程是基于随机采样方法获取负样本,不可避免地会采样到漏标实体作为负例进行训练,造成模型性能下降。因为漏标实体应与相同类型实体具有高相似度,与不同类型的其他实体具有低相似度。如果候选样本与不同实体类型都具有较高的相似度,则此样本很可能是一个负样本而不是漏标实体。所以本文提出了一种融合相似度计算远程监督命名实体识别方法,采用基于样本相似度计算的主动采样策略,尽可能避免采样到漏标实体参与训练,以此缓解实体漏标带来的模型性能下降问题。
本文模型的总体结构如图3所示,该模型主要包括编码器层、Span处理层、样本相似度计算及采样层、分类预测层。按批次输入的文本数据通过数据增强及编码层中的数据增强部分得到增强数据,而后将原始数据和增强数据通过编码部分进行编码;Span处理层将编码后的数据处理成跨度的向量表示,并将其送入样本相似度计算及采样层;通过计算候选样本与已标注样本之间的相似度并获取相似度得分,以相似度得分作为依据进行采样,而后把已标注样本和采样的样本通过分类层输出样本的预测值。针对已标注样本和采样出的样本分别计算损失,合并后即为总损失。
2.3 编码器层及Span处理层
本文使用预训练语言模型BERT作为编码器。开始阶段,为了得到句子中每个单词对应的上下文特征向量hi,需要利用BERT对句子进行编码。给定句子X={x1,x2,…,xn},将句子X输入BERT编码器后,对于其中的每一个单词xi,都会得到一个对应的上下文特征向量hi,如式(1)所示。
h1,h1,…,h1=BERTencoder(x1,x2,…,xn)(1)
Span的长度记为L,如式(2)所示。其中i表示Span的开始位置,j表示每个Span的结尾位置。
L=j-i+1(2)
对Span长度进行编码,记为l,是对Span的长度特征进行编码后的可训练嵌入。将可能的所有跨度集合记为S,对于S中的每个Span而言,si,j∈S,其中每个子元素可以表示为
si,j=[hi;hj;l](3)
其中:hi表示Span的开始部分;hj表示每个Span的结尾部分。有跨度集合S∈Euclid ExtraaBpB×N×r,其中B为批次中数据条数,N为批次数据中最长Span的长度,r为使用多层线性层进行降维后的维度。
2.4 相似度计算及采样层
本文通过实体的标签信息,将跨度分为标注样本和未标注样本,并且将未标注样本都视为潜在的负样本。以此为据,将处理得到的S划分为已标注样本向量表示集SL={sl1,sl2,…,slR}和候选样本向量表示集SU={su1,su2,…,suT},其中T>>R。未标注样本与标注样本的相似度计算公式如式(4)所示。
p=sim(su)=su·sl‖su‖‖sl‖(4)
对于su∈SU,都会与SL中的每一个样本计算相似度,记为pi;用上述计算出的相似度来计算未标注样本的相似度得分H,其计算过程如式(5)所示,其中R为批次中已标注样本的数量。
H(su)=-∑Ri=1pilog2pi(5)
而后以计算出的相似度得分为依据,对SU中的样本按从高到低进行排序,并按此得分为依据进行采样。为了尽可能地从候选样本中采样出负样本,也为了节省计算成本,采样数量由采样率控制,采样数量如式(6)所示,其中T为未标注样本的数量,r代表采样率。
K=(1-r)×T(6)
由此采样出的样本集合为Sselect={ssel1,ssel2,…,sselk},数量为K个。
2.5 分类预测层
对于SL和Sselect中的特征向量si,j,将其输入到多层感知机(multi-later perceptron,MLP)中来预测Span的标签类型,通过标签的权重和Span向量的内积来评分,评分函数如式(7)所示。
score(si,j,yv)=sTi,jwlabel(7)
其中:wlabel代表标签的权重;si,j代表Span的特征向量;v为可学习的实体类型种类。而后将每个实体Span得分输入到softmax函数中,选择得分最高的标签当作实体标签,如式(8)所示。
P(y|si)=softmax(W·score(si,j,yv)+b)(8)
其中:W和b分别为softmax层的权重和偏置。
本文模型的损失函数采用Zhang等人[23]提出的广义交叉熵损失函数(generalized cross entropy loss,GCE loss),如式(9)所示。
LGCE=∑ni=11-P(y|si,j)qq(9)
其中:n为样本数量;q为变换参数。
对于SL和Sselect来说,两个序列经过两次广义交叉熵损失函数分别得到LossL、Losssel,总损失为两者加和,如式(10)所示。
Lossall=LossL+Losssel(10)
3 实验结果与分析
3.1 实验数据集
本文使用了三个公共数据集进行实验,分别是CoNLL03、Wiki、Twitter,其中数据集的标签通过远程监督方式[24]获得。
a)CoNLL03数据集是来自路透社语料库的新闻通信文章,标注了人名(PER,persons)、地名(LOC,locations)、组织机构(ORG,organizations)、MISC(miscellaneous)四种实体,其中原始训练集数据为14 041条,测试集为3 250条,实验集为3 453条;b)Wiki数据集来自于维基百科的文章,标注了人名(PER,persons)、地名(LOC,locations)、组织机构(ORG,organizations)、MISC(miscellaneous)四种实体。其中原始训练集数据为1 142条,测试集为280条,实验集为274条;c)Twitter数据集来自于推特的推文,标注了地名(geoloc)、设施(facility)、电影(movie)、公司(company)等10种实体,其中原始训练集数据为2 393条,测试集为1 000条,测试集为3 473条。此外为了验证本文模型在中文命名实体识别上的能力,还在Ontonotes[25]中文数据集上开展了对比实验。
3.2 实验设置
实验使用的GPU为GeForce RTX 2080Ti。本文采用PyTorch实现提出的模型和算法实验。实验中采用反向传播算法进行参数优化。
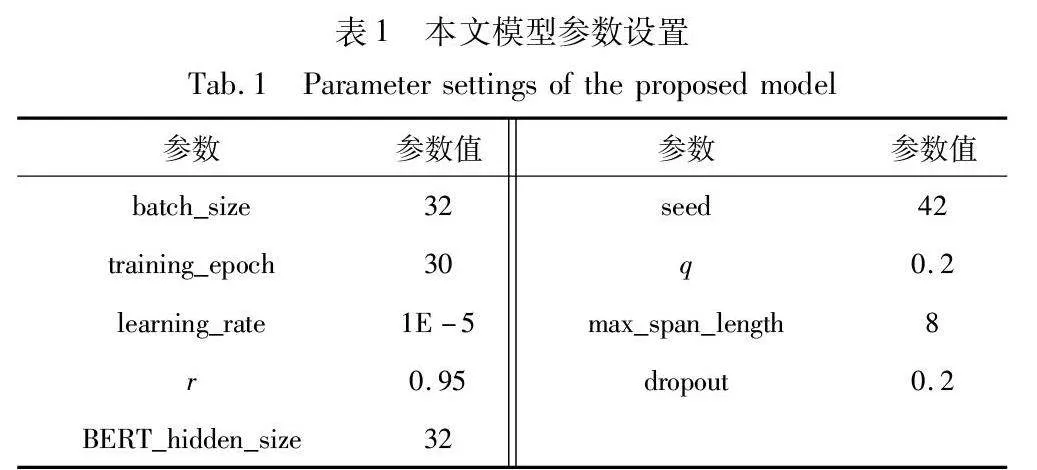
本文使用Adam优化器来训练模型,其学习率初始值为1E-5。广义交叉熵损失函数的变换参数q值设为0.2。Span最大长度设置为8。训练过程将BERT_BASE作为预训练语言模型,隐层数为768,注意力机制头数为12头。其他主要超参数具体设置如表1所示。
3.3 评价指标
本文将准确率P(precision)、召回率R(precision)、F1值(F1 score)作为实验的评价标准,如式(11)~(13)所示。
P=识别正确的实体数识别的实体数×100%(11)
R=识别正确的实体数样本的实体总数×100%(12)
F1=2PRP+R×100%(13)
3.4 模型实现细节
实体漏标会导致模型学习不正确的监督信号,导致模型对噪声数据产生拟合,从而导致模型性能变差。本文提出融合相似度计算的负采样算法来尽量避免噪声数据参与训练。具体而言,该算法首先通过基于同义词替换的数据增强方法扩充训练数据,例如句子“Shanghai is an East Asian city”中,“Shanghai”为LOC实体类型,在其对应的同义实体候选集中有其同义的单词“Tokyo”,进行替换后,生成新句子“Tokyo is an East Asian city”,依此类推,一个句子就可以变成两个句子或者多个句子,实现训练数据的扩充,从而达到数据增强的目的。
在同义实体词替换过程中,因为替换的实体词与被替换的词属于同一实体类型,所以替换后生成的句子仍然是合乎语法和语义的。而后依据实体的标签信息,将样本划分为标注样本和未标注样本,其中标注样本视为正样本,未标注样本视为负样本,通过计算正负样本之间的相似度并计算相似度得分,以此作为主动采样的依据。最后在相似度得分的基础上对负样本进行采样,采样出的训练数据参与训练。
算法1 融合相似度计算的负采样算法
输入:存在数据漏标情况的原始训练数据样本。
输出:采样出的参与训练的样本。
a)对输入数据进行预处理。
b)使用基于同义词替换的数据增强方法对训练数据进行扩充。
c)根据式(1)对训练数据进行编码得到数据的特征向量h。
d)根据式(3)对特征向量进行跨度编码得到跨度向量集S。
e)根据实体的标签信息,将跨度向量集划分为标注样本向量集SL和候选样本向量集Sselect。
f)根据式(4)计算候选样本与标注样本之间的样本相似度pi。
g)由步骤f)计算出的样本相似度,根据式(5)计算出样本的相似度得分H。
h)将步骤g)计算出的相似度得分按从高到低对候选样本进行排序,并根据式(6)来进行负采样,从而采样出参与训练的样本。
i)返回最后参与训练的样本集Sselect。
3.5 对比实验
为验证本文模型的有效性,采用以下方法作为基准模型,与本文模型进行比较:
a)BiLSTM-CRF[26]是传统的命名实体识别方法,使用通过远程监督获得标记数据进行训练。
b)AutoNER[24] 通过附加规则和字典对远程监督的数据集进行过滤,并为远程监督命名实体识别任务提出了一种新的标注方案。
c)LRNT[27] 将部分条件随机场用于采样非实体部分数据参与训练。
d)KB Matching使用基于知识库的方法,通过字符串匹配来检索实体。
e)Span-NS[5]在训练过程中采用了基于随机采样方法的采样策略。
f)Span-NS-V[6]在训练过程中均采用了基于加权抽样方法的采样策略。
g)BS-NER[17]利用Span标注方法,以负采样的方式代替了部分训练,缓解了远程监督数据集中样本带噪的问题。
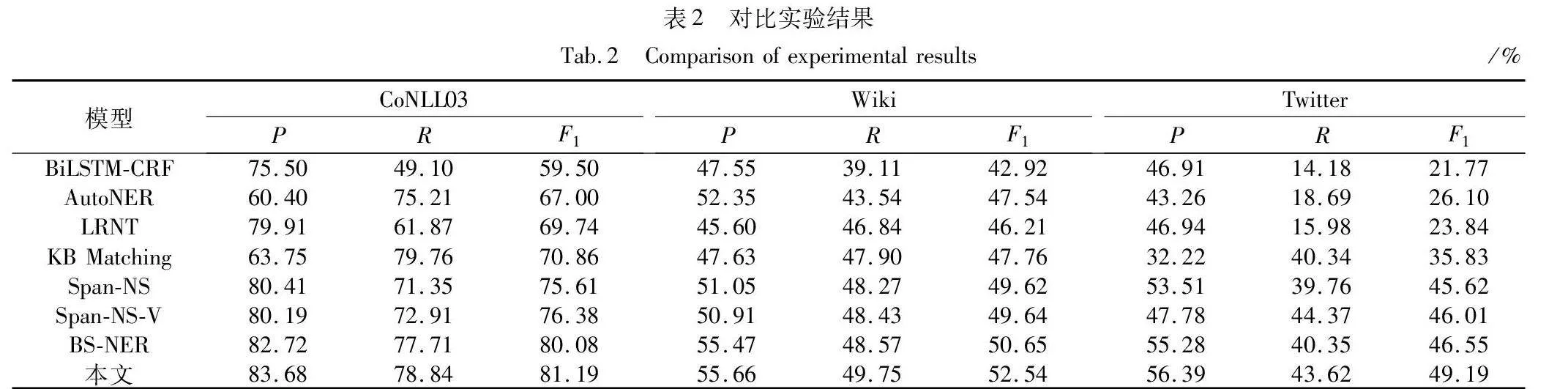
本文模型和其他基线模型在CoNLL03、Wiki、Twitter数据集上的实验结果如表2所示。
如表2所示,相比于其他的基线模型,本文模型的主要评价指标都有所提升,尤其是F1值的表现均为最优。本文模型在CoNLL03数据集上的表现都优于其他基线模型,其中R和F1值都高于其他模型,与BiLSTM-CRF等未采用负采样策略的模型相比,F1值分别提升了10.33~21.69百分点不等,这说明融合相似度计算的主动采样策略有利于缓解实体漏标问题,能够提高模型性能。
与Span-NS等负采样模型相比,本文模型的性能仍要好于先前的负采样模型。因为先前的负采样模型的采样策略大多带有一定的随机性,所以模型不可避免地会选择未标记的实体参与训练,从而在一定程度上对模型的性能造成影响。本文模型对比先前的采样模型,F1值提升了1.11~5.58百分点不等,这说明当训练数据中存在漏标实体时,在负采样的过程中引入融合相似度计算的主动采样策略,可以提高采样出的样本质量,尽可能地避免采样到漏标实体。
在Wiki数据集上,本文模型的表现也全面超过了其他基线模型。与Span-NS和Span-NS-V相比,F1值分别提升了2.92和2.90百分点。即使是和当前性能最优的模型相比,本文模型的性能仍要好于BS-NER,F1值提高1.89百分点。Wiki数据集数据量与其他两个数据集相比是偏少的,训练数据的缺少可能会给模型带来过拟合问题,本文模型与之前的模型相比,引入了基于同义词替换的数据增强方法,有效扩充了训练数据,同时可以获得相对原本数据更多样性的语义特征,并且能够提高模型的泛化能力;同时得益于负采样方法提升了R值,从而提升了整体的F1值,这也反映在了实验结果上。
本文模型在Twitter数据集上也取得了不错的效果,相比未采用负采样方法的F1值平均提高了22.31百分点。与近期的BS-NER相比,都同样取得了最优的结果,F1值提高了2.64百分点。与Span-NS-V相比,取得了最优F1值,在精确率和召回率上各有优势。
从图4可以更加直观地看出,本文模型在CoNLL03、Wiki和 Twitter三个数据集上的F1值都取得了较其他模型更优的结果。总体来看,本文模型在各类指标上优势明显,表明了融合相似度计算的主动采样策略的远程监督命名实体识别方法能够有效缓解实体漏标带来的模型性能下降问题,并且结合了同义实体词替换的数据增强方法,提高了数据来源的丰富性,从而提升了模型的泛化性能。
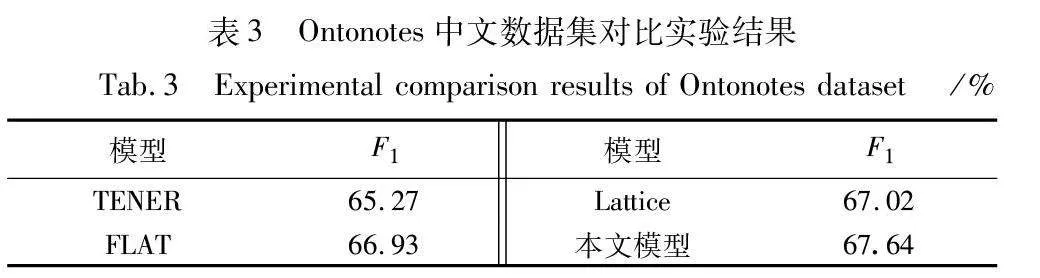
为了验证本文模型在中文命名实体识别中的应用能力,在Ontonotes数据集上开展对比实验,本文选择TENER[28]、FLAT[29]、Lattice[30]三个具有代表性的中文命名实体识别模型作为基线模型来进行对比。本文模型和其他基线模型在Ontonotes数据集上的实验结果如表3所示。
如表3所示,相比于其他三个基线模型,F1值分别提高了 2.37、0.71和0.62百分点。虽然本文模型是用于处理英文命名实体识别,但实验结果证明本文模型在中文命名实体识别上也能达到较好的效果。综上,由本文模型在中文命名实体识别数据集上的表现,可以证明本文模型在中文命名实体识别领域也有一定的竞争力。
3.6 消融实验
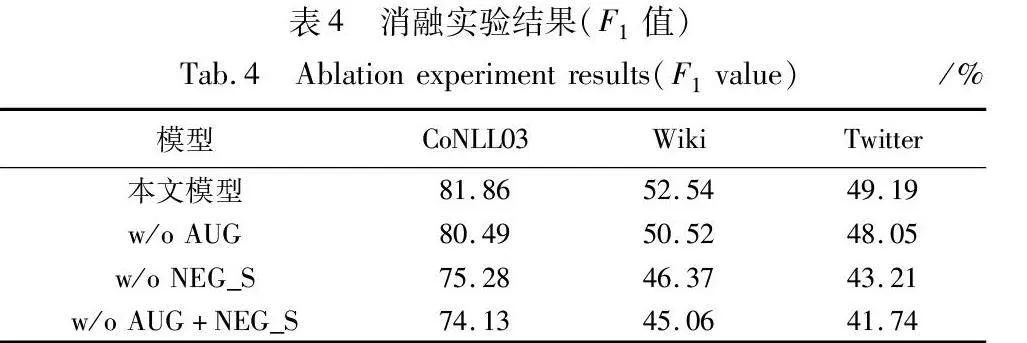
本节通过消融实验来验证模型模块的有效性。消融实验将在三个通过远程监督进行的标注数据集上进行,设置如下:a)不使用负采样策略与数据增强方法,只使用原始的框架训练模型(记为w/o AUG+NEG_S);b)仅使用数据增强方法训练模型,不采用负采样策略参与训练(记为w/o NEG_S);c)仅使用负采样方法训练模型,不采用数据增强方法参与训练(记为w/o AUG)。实验结果如表4所示。
从表中可以得出以下结论:
a)在三个数据集上,本文模型的F1值都是最佳的,说明模型中的每一个模块(包括负采样策略和数据增强方法)都是十分重要的。
b)在三种设置条件下,w/o AUG+NEG_S效果是最差的,分别比原模型降低了7.46、7.44、7.19百分点。这说明本文模型所提出的融合相似度计算的主动采样策略和同义实体词替换的数据增强方法能够十分有效地提升模型性能,其效果对模型皆具有正向作用。融合相似度计算的主动采样策略能够更加准确地避免从样本中采样出漏标实体作为样本来训练分类器,从而提高模型分类性能;数据增强模块可以有效扩充训练数据,增强模型泛化性。
c)为验证融合相似度计算的负采样策略对模型的提升能力,本文以w/o NEG_S同原始模型进行比较,实验结果相比较实验组F1值下降了5.98~6.58百分点不等。这说明当训练数据中存在漏标实体时,在采样负例训练模型的过程中引入相似度计算机制,可以进一步提升训练数据质量,从而提高模型的性能。这对模型性能的提升是非常有效的,其在模型中是不可或缺的一部分。
d)w/o AUG相较于原始模型,数据指标有一定程度的下降,证实了基于同义实体词替换的数据增强方法对模型是有正增益的。通过基于同义实体词替换的数据增强可以有效扩充训练数据,增加了样本来源的多样性,同时又可以获得相对原本数据更多样性的语义特征,提高了模型的泛化能力,对模型的增益效果也体现在了实验结果上。
3.7 采样率对比实验
在负采样阶段,采样的样本数量与质量都和采样率有关,这由式(5)可以看出,因此本文对不同的采样率进行对比实验,以探索采样率对实验结果的影响。
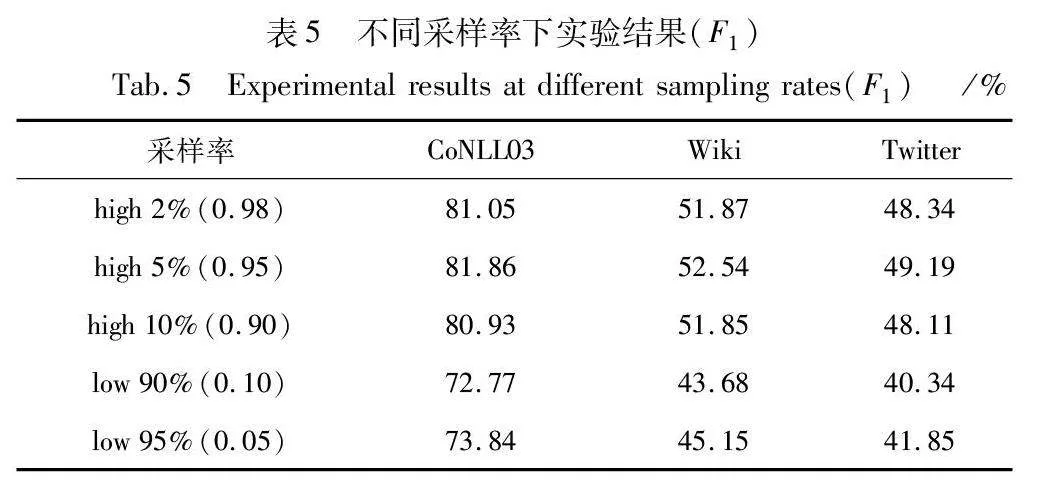
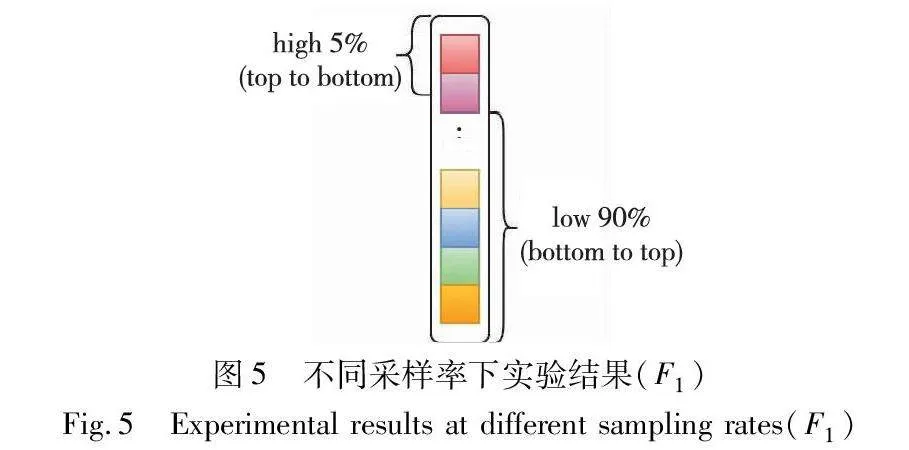
以三个数据集的F1值为例,表5列出了不同采样率下,三个数据集的实验结果。high代表采样时按样本相似度得分从高到低对样本进行采样,low代表采样时按样本相似度得分从低到高对样本进行采样,如图5所示。
从表5中发现,当采样出的样本为相似度得分靠前5%的样本时,F1值结果为最优,另两个相似度得分靠前的采样率下的模型表现略有下降。
相比之下,当采样到相似度得分较低的样本时,模型性能出现了明显的下降。说明从相似度得分较低的样本中采样出的样本中可能含有较多的漏标实体,这样的样本不利于模型学习样本分类,会给模型带来错误的监督信号,从而导致模型性能下降。
3.8 案例分析
本文使用“Japan began the defence of their Asian Cup title with a lucky 2-1 win against Syria in a Group C championship match on Friday.”作为例子进行示例分析,其中将未使用融合相似度计算的主动负采样方法的训练模型(without NS)作为本文模型的对比案例,Gold是标准标签。在表6中,展示了未使用负采样方法的模型和本文模型在远程监督条件下获取标签数据训练模型后作出的预测。未使用负采样方法的模型主要从远程监督中获取标签学习,在训练过程中由于漏标实体影响,将Asian识别为实体;而本文模型通过融合相似度计算的主动采样策略,避免了漏标实体带来的错误监督信号,而且通过数据增强和学习预训练语言模型中的知识成功识别出Asian Cup为MISC类型实体,由此进一步说明了本文模型的有效性。
4 结束语
本文提出了一种融合相似度负采样的远程监督命名实体识别方法。融合相似度计算的主动负采样策略尽可能地避免采样出漏标实体作为负例参与训练,提升了远程监督条件下命名实体识别模型的性能;同时,通过基于同义词替换的数据增强方法,增强了模型的泛化能力。实验结果表明,本文模型在三个常用的命名实体识别数据集均取得了优异的性能,有效地缓解了远程监督方法条件下实体漏标造成的模型性能下降问题。由于本文模型是针对实体漏标这一噪声进行研究的,对其他类型实体噪声的抗噪能力还有待进一步提高。在下一步的研究方向中,拟对数据中不完全标注带来的噪声进行进一步研究处理,以提高模型在此种噪声条件下的预测精度,进而增强模型的泛用能力。
参考文献:
[1]张虎, 张广军. 基于多粒度实体异构图的篇章级事件抽取方法[J]. 计算机科学, 2023, 50(5): 255-261. (Zhang Hu, Zhang Guangjun. Document-level event extraction based on multi-granularity entity heterogeneous graph[J]. Computer Science, 2023, 50(5): 255-261.)
[2]Gupta N, Singh S, Roth D. Entity linking via joint encoding of types, descriptions, and context[C]//Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2017: 2681-2690.
[3]王红, 史金钏, 张志伟. 基于注意力机制的LSTM的语义关系抽取[J]. 计算机应用研究, 2018, 35(5): 1417-1420,1440. (Wang Hong, Shi Jinchuan, Zhang Zhiwei. Text semantic relation extraction of LSTM based on attention mechanism[J]. Application Research of Computers, 2018,35(5): 1417-1420,1440.)
[4]Ji Guoliang, Liu Kang, He Shizhu, et al. Distant supervision for relation extraction with sentence-level attention and entity descriptions[C]//Proc of the 31st AAAI Conference on Artificial Intelligence, the 29th Innovative Applications of Artificial Intelligence Conference and the 7th Symposium on Educational Advances in Artificial Intelligence. Palo Alto,CA: AAAI Press, 2017: 3060-3066.
[5]Li Yangming, Liu Lemao, Shi Shuming. Empirical analysis of unlabeled entity problem in named entity recognition[EB/OL].(2021-03-18). https://arxiv.org/abs/2012.05426.
[6]Li Yangming, Liu Lemao, Shi Shuming. Rethinking negative sampling for handling missing entity annotations[EB/OL].(2022-02-25). https://arxiv.org/abs/2108.11607.
[7]Song Shengli, Zhang Nan, Huang Haitao. Named entity recognition based on conditional random fields[J]. Cluster Computing, 2017, 22(S3): 5195-5206.
[8]栗伟, 赵大哲, 李博, 等. CRF与规则相结合的医学病历实体识别[J]. 计算机应用研究, 2015,32(4): 1082-1086. (Li Wei, Zhao Dazhe, Li Bo, et al. Combining CRF and rule based medical named entity recognition[J]. Application Research of Compu-ters, 2015, 32(4): 1082-1086.)
[9]Ahmed I, Sathyaraj R. Named entity recognition by using maximum entropy[J]. International Journal of Database Theory & Application, 2015, 8:43-50.
[10]原旎, 卢克治, 袁玉虎, 等. 基于深度表示的中医病历症状表型命名实体抽取研究[J]. 世界科学技术-中医药现代化, 2018, 20(3): 355-362. (Yuan Ni, Lu Kezhi, Yuan Yuhu,et al. Depth representation-based named entity extraction for symptom phenotype of TCM medical record[J]. World Science and Technology—Modernization of Traditional Chinese Medicine and Materia Medica, 2018, 20(3): 355-362.)
[11]Patil N V, Patil A S, Pawar B V. HMM based named entity recognition for inflectional language[C]//Proc of International Conference on Computer, Communications and Electronics. Piscataway, NJ: IEEE Press, 2017: 565-572.
[12]王博冉, 林夏, 朱晓东,等. Lattice LSTM神经网络法中文医学文本命名实体识别模型研究[J]. 中国卫生信息管理杂志, 2019, 16(1): 84-88. (Wang Boran, Lin Xia, Zhu Xiaodong, et al. Chinese name language entity recognition(NER) using Lattice LSTM in medical language[J]. Chinese Journal of Health Informatics and Management, 2019,16(1): 84-88.)
[13]Lample G, Ballesteros M, Subramanian S, et al. Neural architectures for named entity recognition[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.Stroudsburg, PA: Association for Computational Linguistics, 2016: 260-270.
[14]Devlin J, Chang M W, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]//Proc of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2019:4171-4186.
[15]Fu Jinlan, Huang Xuanjing, Liu Pengfei. SpanNER: named entity recognition as span prediction[C]//Proc of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2021: 7183-7195.
[16]游新冬, 刘陌村, 韩君妹,等. EMSS: 一种基于Span匹配的中文实体抽取方法[J/OL]. 小型微型计算机系统. (2023-07-10). http://kns.cnki.net/kcms/detail/21.1106.TP.20230710.1020.003.html. (You Xindong, Liu Mocun, Han Junmei, et al. EMSS: a Chinese entity extraction method based on Span matching[J/OL].Journal of Chinese Computer Systems. (2023-07-10). http://kns.cnki.net/kcms/detail/21.1106.TP.20230710.1020.003.html.)
[17]Yang Yaosheng, Chen Wenliang, Li Zhenghua, et al. Distantly supervised NER with partial annotation learning and reinforcement lear-ning[C]//Proc of the 27th International Conference on Computational Linguistics. Stroudsburg, PA: Association for Computational LinguisticPeElexO9iLW9K2uUQQNYdNcQyXvqx2SqmcxswMohuRM=s, 2018: 2159-2169.
[18]Peng Minlong, Xing Xiaoyu, Zhang Qi, et al. Distantly supervised named entity recognition using positive-unlabeled learning[C]//Proc of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2019: 2409-2419.
[19]杨一帆, 施淼元, 缪庆亮,等. 基于远程监督的病历文本漏标问题研究[J]. 中文信息学报, 2022, 36(8): 73-80. (Yang Yifan, Shi Miaoyuan, Miao Qingliang, et al. Conquering unlabeled entity in medical record text under distant supervision framework[J]. Journal of Chinese Information Processing, 2022, 36(8): 73-80.)
[20]Xu Lu, Bing Lidong, Li Wei. Sampling better negatives for distantly supervised named entity recognition[C]//Proc of the 61st Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2023: 4874-4882.
[21]Yang Linyi, Yuan Lifan, Cui Leyang, et al. FactMix: using a few labeled in-domain examples to generalize to cross-domain named entity recognition[C]//Proc of the 29th International Conference on Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2022: 5360-5371.
[22]Wei J, Zou Kai. EDA: easy data augmentation techniques for boosting performance on text classification tasks[C]//Proc of Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2019: 6382-6388.
[23]Zhang Zhilu, Sabuncu M R. Generalized cross entropy loss for trai-ning deep neural networks with noisy labels[C]//Proc of the 32nd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2018: 8792-8802.
[24]Shang Jingbo, Liu Liyuan, Gu Xiaotao, et al. Learning named entity tagger using domain-specific dictionary[C]//Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2018: 2054-2064.
[25]Weischedel R, Palmer M, Marcus M, et al. OntoNotes release 4. 0. LDC2011T03[EB/OL].(2011-02-15). https://doi.org/10.35111/gfjf-7r50.
[26]Ma Xuezhe, Hovy E. End-to-end sequence labeling via bi-directional LSTM-CNNs-CRF[C] //Proc of the 54th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2016: 1064-1074.
[27]Cao Yixin, Hu Zikun, Chua T S, et al. Low-resource name tagging learned with weakly labeled data[C]//Proc of Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2019: 261-270.
[28]Yan Hang, Deng Bocao, Li Xiaonan, et al. TENER: adapting Transformer encoder for named entity recognition[EB/OL].(2019-12-10). https://arxiv.org/abs/1911.04474.
[29]Li Xiaonan, Yan Hang, Qiu Xipeng, et al. FLAT: Chinese NER using flat-lattice transformer[C]//Proc of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2020: 6836-6842.
[30]Zhang Yue, Yang Jie. Chinese NER using Lattice LSTM[C] //Proc of the 56th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2018: 1554-1564.
