
基于近邻传播聚类-K均值聚类的工业用户用电模式挖掘方法
2024-08-12 00:00:00宗一郑罡南钰
科技资讯 2024年12期

摘要:为了充分发挥用户负荷的可调节潜力,提出了一种基于近邻传播聚类-K均值聚类的工业用户用电模式挖掘方法。首先,比较K均值聚类和近邻穿传播聚类-K均值聚类的优缺点。在工业用户的选取上,选择最佳聚类数均为3的工业用户负荷数据作为被分析对象以便聚类,借助MATLAB工具对用户负荷数据进行聚类,得到了3组所需的聚类中心,再绘制成曲线以便观察和后续提取特征指标。
关键词:近邻传播聚类-K均 值聚类 工业用户 可调节潜力评估 评估指标体系 多准则决策法
中国分类号:
Mining MethodsfofrMining Industrial User the Electricity Consumption PatternModeofIndustrial Users Based on Adjacentffinity Propagation Clustering-K-mMeans Clustering
ZONG Yi ZHENG Gang NAN Yu
( Kaifeng Power Supply Company,State Grid Henan Electric Power Company Kaifeng Power Supply Company, Kaifeng, Henan Province,471000 China)
Abstract:This paper proposes aA method ofminingthe electricity consumption mode of miningindustrial users electricity consumption pattern based on nearest neighboraffinity propagation clustering-K-means clustering is proposed to give full play to the adjustable potential of user loads. Firstly, it comparesing the advantages and disadvantages of k-means clustering andaffinity propagation clustering-K-means clustering. In the selection of industrial users,it selects the industrial user load data with the best clustering number of33 are selected as the analysised object for clustering.,With the help of MATLABMvhavxz2+/DBdITNYzUCr/99hGpiIL9ZZ5UQZjPEYDk= tools, clustersthe user load datawith the help of theMATLAB tool, are clusteredand toobtains the three groups ofrequired cluster centers,which are then drawn into curves for observation and thesubsequent extraction of characteristic indicators.
KeyWords:AffinityNearest NeighborPpropagation Cclustering-K-means cClustering; Industrial users; Adjustable potential assessment; Evaluation index system; Multi-criteria decision-making method
数据挖掘是目前数据库领域和人工智能领域研究的重点方向,数据挖掘是从数据库的许多数据找出先前未知的、隐含的有潜在利益的信息的不平凡历程。发现的知识能运用在运筹控制、查询数据优化、信息检索分类等[1]。
Chen J [2]和WANG M [3]比较了各种聚类算法如K均值聚类、K-modes算法、模糊聚类算法和图论算法等的优缺点以及适用的场景。徐青山 等人[4]以模糊C均值聚类的方法(FCM)为基础,对每个用户的负荷数据进行聚类分析,并提出计算用户中断速率和中断特性的二次聚类模型。徐青山 等人[5]提出了结合Ward系统聚类法对重要用户的负荷数据进行聚类分析的改善模糊C均值法。孙毅 等人[6]以日负荷曲线为基础,利用模糊C均值聚类和模式识别原理,分类综合用户所属用电行业。任炳俐 等人[7]提出降低维度的关键性指标,采用传统的K-means聚类算法,聚类分析单一负荷,然后得出用户典型的日负荷曲线。
1K均值聚类及其特点
K均值聚类算法是Mac Queen提出的一种无监督聚类算法,其选择对象均为最小误差函数,从而可以将所有划分成给定的K个簇。
K均值聚类是一种硬聚类,隶属度很明确,只有0和1这两个值。需要事先确定最终聚类划分数目,除此之外还要正确选取加权模糊度参数,受主观影响较大,满足两个条件后才能获得较好的聚类效果,本文采用近邻传播聚类算法,该算法人为主观影响较小,无 须根据先验经验来确定聚类数目和中心且最终聚类效果相较而言较为稳定。
2基于近邻传播聚类-K均值的用电模式聚类
近邻传播聚类(简称AP)算法是2007年在Science杂志上提出的一种聚类算法。AP聚类算法在聚类的过程中涉及到了以下几种变化量。相似度矩阵S,该矩阵中的数值反映的数据序列中各个数据点之间的相似度,例如假设 存在数据集X={x_1,x_2,…,x_n },则数据x_i和数据x_j之间的相似度即为矩阵S中的元素s(i,j),计算方法如下:
s(i,j)=-||x_i-x_j ||^2 (i≠j) (1)
在数据更新过程中,还存在两个信息矩阵,即吸引信息矩阵和归属信息矩阵,分别用r和a表示。在更新结束之后如果确定数据j为数据i的聚类中心,那么两个信息矩阵的值以及j需要满足:
arg max┬j {a(i,j)+r(i,j)} (2)
AP聚类算法主要步骤如下:
步骤1:针对某一数据序列X={X_1,X_2,…X_n },根据式(1)构建相似度矩阵S,选用合适的参考值p。根据所需要的聚类数目将矩阵S中最大值/最小值/中值填入对角线中。
步骤2:吸引矩阵和归属矩阵的初始化,r=0,a=0,开始更新吸引信息矩阵r(i,j)和归属信息矩阵a(i,j)。r(i,j)更新计算方法如下。
r(i,j)=S(i,j)-max┬(j^'≠j) {a(i,j^' )+S(i,j^' ) } (3)
由于是第一次迭代,归属矩阵的值为零,因此定义r(i,j)的值为i,j之间的相似度S(i,j)与i和其他候选聚类中心(即,其 他不为j的数据点)之间的最大相似度之差。归属信息矩阵a(i,j)更新计算方法如下。
当i≠j时:
a(i,j)=min(0,r(j,j)+∑_(i^'∉{i,j}) max(0,r(i',j))) (4)
当i=j时:
a(j,j)=∑_(i^'≠j) max(0,r(i',j)) (5)
同时,当吸引信息矩阵和归属引入阻尼系数之后的更新公式如下:
r_(t+1) (i,j)=λr_t (i,j)+(1-λ)r_(t+1) (i,j) (6)
式 (6)中,r_(t+1) (i,j)和r_t (i,j)分别表示当前的吸引信息矩阵和前一次更新的吸引信息矩阵,两个不同迭代次数的矩阵用阻尼系数联系;
a_(t+1) (i,j)=λa_t (i,j)+(1-λ)a_(t+1) (i,j) (7)
式 (7)中,a_(t+1) (i,j)和a_t (i,j)分别表示当前的归属信息矩阵和前一次更新的归属信息矩阵,同样的,两个不同迭代次数的矩阵用阻尼系数联系。
步骤3:重复执行步骤2,按照步骤2中的顺序,先对吸引信息r(i,j)更新,利用已更新的r(i,j)对归属信息a(i,j)进行更新。综合考虑这两种在各个数据点之间传递的信息,遍历每一个数据点,判断其成为聚类中心的可能性。
AP聚类算法不需要事先确定最终聚类结果的类数目,并且不需要事先指定聚类中心,同时聚类结果比较稳定。
3 算例分析
3.1 用户负荷数据
为得到正常、中断、错时三种聚类数据,因此本文在数据集中选取1组最佳聚类数目均为3的不同行业的工业用户一年365天每天96点负荷数据来首先进行聚类分析。用户信息 行业类型为特种陶瓷制品制造。
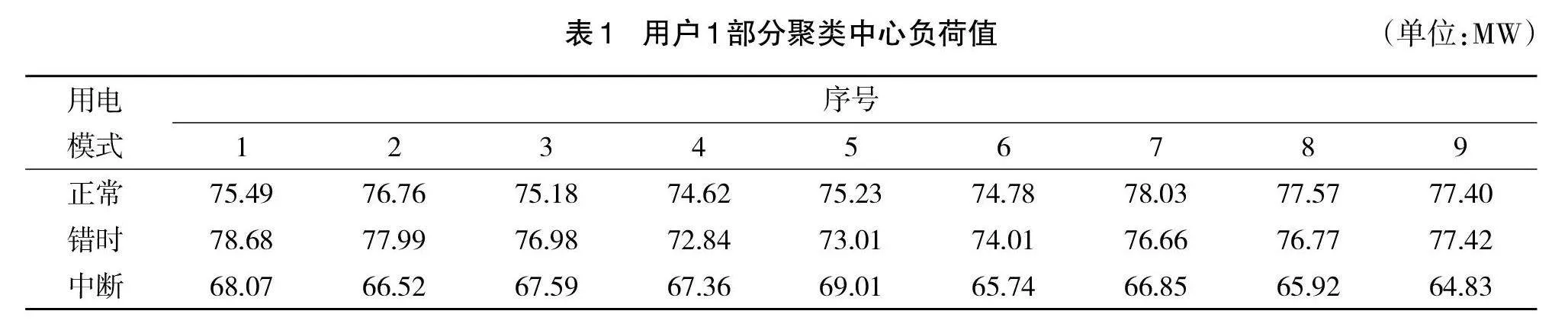
这个用户为筛选出来的最佳聚类数为3的用户,以MATLAB作为聚类工具来对工业用户数据进行聚类分析得到3组聚类中心数据,对这三组数据进行绘图以便观察。得到聚类中心C的部分数据如表1所示 。
3.2 仿真结果分析
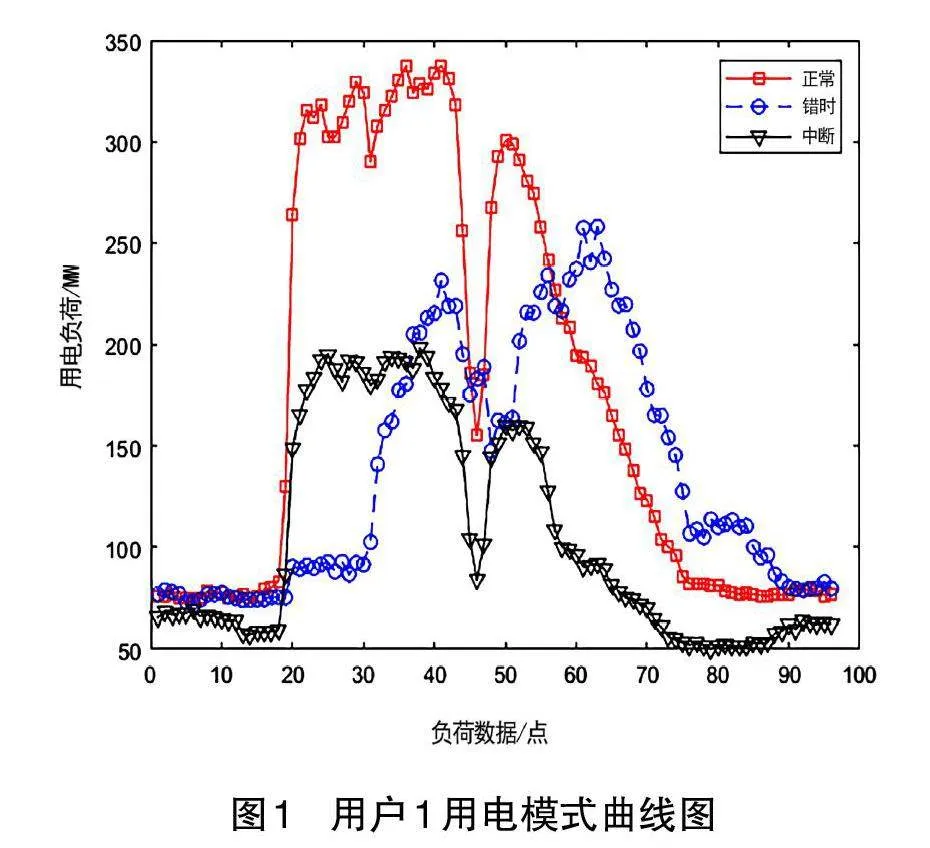
根据聚类得到的3组聚类中心,绘制出的正常、中断、错时功率曲线如图1所示:
如图1 所示,用户1的三种用电模式较为明显,其负荷曲线中正常工作模式曲线的高峰时段大约在第20 个至第60 个点范围内,且高峰时段和低峰时段的差值较大,曲线波动较大。用户1主要在高峰时段进行中断工作,在低峰时段也进行了少量的中断工作,说明用户关闭了部分生产设备和生活用电设备如空调、照明等,但一部分生产设备仍在正常运行。在进行错时工作时是将高峰时段的负荷转移至了第60个至第96 个点范围内。
5结论
本文将特种陶瓷制品制造工业用户负荷数据进行聚类分析。在工业用户的选取上,选择1组最佳聚类数均为3的工业用户负荷数据作为被分析对象以便聚类,以MATLAB作为聚类工具来对工业用户数据进行聚类得到了3组所需的聚类中心,再绘制成曲线以便观察和后续提取特征指标。通过对比3组用户的工作曲线中,还可以判断其具体的中断和错时时段和方式 。
参 考 文 献
杨佳兴.基于数据挖掘和聚类算法的通用航空航材分类方法研究[D].中国民用航空飞行学院, 2021.
CHEN J,ZHUX Z,LIU H W.A mutual neighbor-based clustering method and its medical applications[J].Computers in Biology and Medicine,150(2022) 106184.
WANG M, FU W, HE X, et al.A survey on large-scale machine learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2022,34(6): 2574–2594.
徐青山,吕亚娟,杨斌.工商业用户负荷中断速率及中断容量特性分析[J].电力需求侧管理,2019,21(3):21-25,1.
徐青山,吕亚娟,孙虹, 等.大用户多维度可中断特性精细化分析[J].电工技术学报,2020,35(S1):284-293.
孙毅,毛烨华,李泽坤, 等.面向电力大数据的用户负荷特性和可调节潜力综合聚类方法[J].中国电机工程学报,2021,41(18):6259-6271.
任炳俐,张振高,王学军, 等.基于用电采集数据的需求响应削峰潜力评估方法[J].电力建设,2016,37(11):64-70.
