
地质资料数据挖掘系统研究与实现
2024-08-12 00:00:00郝珊彭薇
科技资讯 2024年12期
摘要:国内的地质资料管理多存在保管分散、协同性差、“信息孤岛”问题,很难实现其信息共享,而且难以从海量地质资料中及时获取有用的信息。数据挖掘等新兴技术应用于地质资料管理中,有助于提高地质资料服务水平。然而,目前地质资料数据挖掘多基于目录元数据库,难以发现地质资料全文间的相关性。为此,采用文本聚类分析方法提高推荐资料间的相关性,并从资料文本中提取指定关键信息,以此提高地质资料的利用效率。
关键词:地质资料 数据挖掘 聚类分析 信息提取
Research and Implementation of the Data Mining System of Geological Data Mining System
HAO ShanPENG Wei
(Geological Survey Institute of Hunan Provinciale, Changsha,Hunan Province, 414000 China)
Abstract:The management of geological data in China often faces the problems such asof scattered storage, poor collaboration, and "information islandssilos", making it difficult to achieve information sharing and obtain useful information from massive geological data in time. The application of emerging technologies such as data mining to geological data management is helpful to improve the service level of geological data, but thecurrent data mining of at present,geological data mining is mostly based on catalog metadatabases, and itmaking it is difficult to find the correlation betweenamong the full text of geological data. Therefore, the text clustering analysis method is used to improve the correlation betweenamong the recommended data, and the specified key information is extracted from the data text, so as to improve the utilization efficiency of geological data.
KeyWords:Geological data;Data mining;Cluster analysis;Information extraction
地质资料是地学工作的重要载体,同时也是反映国家地质环境的重要数据。经过几十年的地学研究及勘探工作,国内已经积累了海量的地质资料成果。地质资料主要以PDF文件的形式保存,随着其数量的不断增长,如何快速而又有效地从海量地质资料中获取需要领域或专题的信息,成为地学工作者的重要研究课题。
传统的地质资料管理方式是用信息检索技术为用户提供查询服务,将用户的查询条件和地质资料数据库的目录元数据进行匹配,这样返回的结果只是目录元数据符合用户要求的资料条目,无法判断地质资料整体的相关性,所以可能会给用户推荐无关内容。
数据挖掘技术是一种从海量数据中获取隐含信息的知识发现技术,将其应用到地质资料领域,可以有效促进地质资料的利用及共享,使地质资料具有更高的经济价值。
1 数据挖掘技术
数据挖掘任务中,最常见的两种算法是分类分析和聚类分析[1],其中,分类分析的任务是从已有数据中得到给定数据的描述,产出物是一个称为分类器的分类模型,利用此分类模型可以对未来数据进行分类;聚类分析会将原本不存在类别描述的数据或样本划分成不同的类别,每一类别中的数据具有一定的关联性或相似性,不同类别中的数据或样本则极不相似。
不论哪种数据挖掘任务,其首要目标都是从海量数据中找到数据间的关联规则,分析不同地质资料间的关联关系,这一过程称为关联分析。关联分析后可能会得到多条关联规则,这些规则并不是都有意义的,没有意义的关联规则需要丢弃。一般使用支持度及置信度两个指标对关联规则进行评价,支持度表示事件组合出现的概率,置信度表示某种事件在另外事件已经出现的情况下出现的概率,支持度和置信度需要结合使用,这两个指标都具有较高的关联规则才是有效的关联规则。
地质资料数据挖掘任务是从海量地质资料中找到相同主题、领域的地质资料,并根据其相关性进行个性化推荐,因此可以看出,这一过程是一个聚类分析的过程。由于地质资料多数是文本信息,这就需要对其进行文本聚类分析。
2 地质资料聚类分析
地质资料聚类分析实际上是一个文本聚类分析问题,这一过程需要根据不同地质资料间的相似性把所有文本划分为不同的子集合,不同的子集合表示不同的类别,并且同一子集合中的文本具有较大的相似性,不同子集合间的文本相似性尽量小。文本聚类分析的关键步骤包括[2]:“地质资料预处理、建立文本模型、特征选择以及聚类处理”。其中,地质资料预处理会去掉无效、错误的文本,并对地质资料中的文本进行分词处理;建立文本模型过程中,将表示文本特征项的词频信息表示为特征向量;特征选择在不影响模型精度的情况下从特征向量中选择主要的特征,降低文本模型的计算复杂度;文本聚类会选择合适的聚类算法对文本向量进行聚类操作。
文本预处理一般包括去除冗余噪声数据、提取文本信息、分词等,由于地质资料数据在录入过程中已经经过严格的审查处理,几乎具有完全可用及有效性,一般无须考虑去除噪声数据操作。然而,地质资料数据通常是以PDF文件的形式存在,这种文件类型中含有很多用于显示控制的格式信息,它们只是起到显示控制的作用,而和地质资料内容没有任何关系,所以地质资料预处理时会去掉这些格式信息。去除格式信息后的地质资料文本接下来会进行分词处理,还有一些虽然出现频率很高,但对地质资料主题没有任何帮助的指示代词、连接词等,这些称为“停用词”的无效词汇也需要去除。
文本表示模型的典型方式是向量模型,也就是用文本的特征项表示向量空间的维度属性,有几个特征项就构成几维向量空间。中文文本特征项的表示方式包括字、词语、短语等,使用单个的字表示文本特征项时会导致地质资料中的文本都是相互独立的,忽略了文本重要信息的同时,会失去其表达的主题特征;由于前面预处理过程中已经对地质资料文本进行了分词操作,因此本文选择使用地质资料文本中的词语来表示文本特征项。
一篇地质资料文本组成的文本特征项可能多达数百个,特征向量维度对应也有数百维,这样的特征向量在进行聚类分析时复杂度较高。另外,聚类算法多采用距离度量来分析不同特征向量的相似性,距离度量方式一般都假定特征向量每个维度的重要性都是相同的,然而对于地质资料而言,地质相关词汇的重要性明显比其他领域词汇高。基于上述考虑,本文在进行特征选择时使用一种改进的TF-IDF方法。传统TF-IDF方法认为如果某文档中一个词语出现的次数越多(即TF值越大),则这个词汇在此文档中越重要。本文对TF-IDF方法的改进方法是:预先设置一个地质词汇表,当计算出词汇的TF-IDF权重后检查词汇是否在地质词汇表中,如果在表中则将其权重设置为原来的2倍,以提高地质相关词汇的重要性。
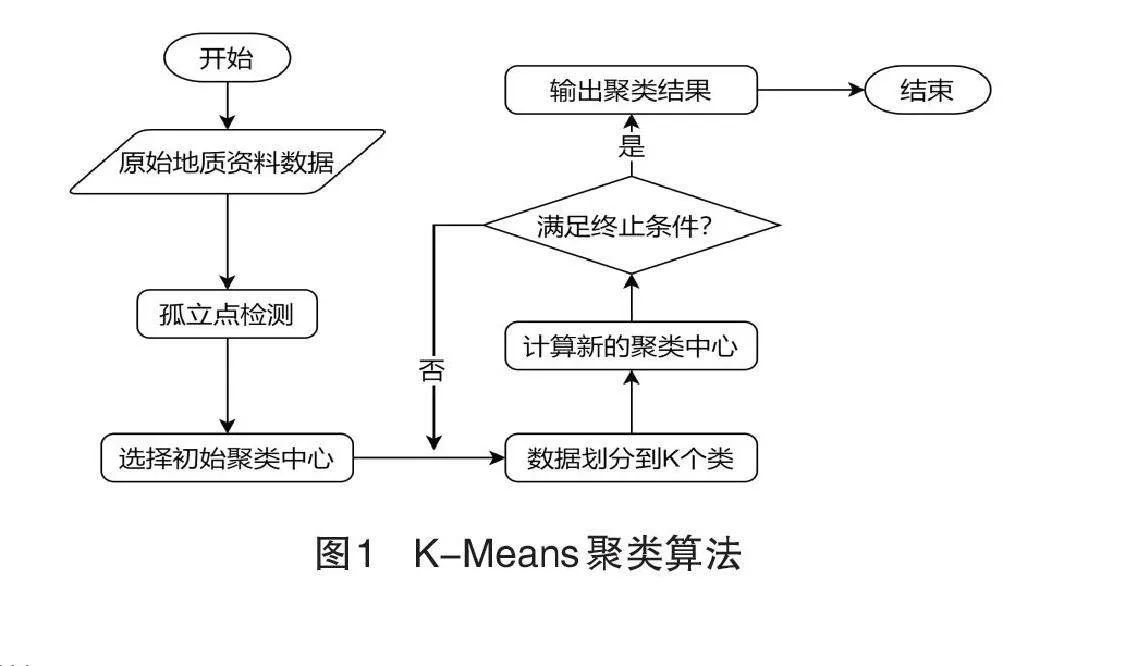
K-Means聚类算法比较简单而且执行效率高,因此本文选择K-Means聚类算法对地质资料进行文本聚类分析。基本的K-Means聚类算法对孤立点比较敏感,如果初始聚类中心选择了两个或以上的孤立点就会导致初步的聚类划分产生较大误差,所以聚类之前需要先检测孤立点,检测出的孤立点可以直接丢弃也可以就近分配到最近的聚类结果。优化的K-Means聚类算法流程如图1所示。
3 地质资料的信息提取
各种地质资料服务平台中仅靠资料的简单描述信息难以正确地理解地质资料的整体内容,因此描述地质资料信息的目录元数据就至关重要。需要注意的是目前多数目录元数据是人工录入方式产生的,这不仅存在效率问题而且可能产生人为录入错误。为了提高目录元数据的准确性,以此提升地质资料数据挖掘的精度,本文自动完成地质资料的关键信息提取。
地质资料服务方提供的最基本地质资料服务是资料的目录检索,检索对象是地质资料的目录元数据库。在分析目录元数据库结构以及地质资料的著录格式后,可以发现元数据一般都位于地质资料的固定位置,并且格式一般是统一的,这为目录元数据的自动信息提取提供了可能。分析地质资料的著录格式后可以将地质资料目录元数据的信息提取步骤总结如下[3]。(1)确认目录元数据提取规则。按照地质资料著录格式,分析地质资料各元数据及其位置信息、对应关系,并确定所有元数据间的提取规则。(2)按照提取规则编程实现,并将主要信息展现给用户。(3)用户反馈没有问题后则把提取的信息保存到目录元数据库,如果反馈有问题则修正提取算法。(4)重复上述过程,直到所有元数据提取完成。需要注意的是,这种方式只能提取不在地质资料正文中的目录元数据,对于经纬度信息、矿产资源等出现在正文内的元数据描述信息不适用。
提取地质资料正文中的信息,可以使用GATE框架。GATE框架在自然语言处理领域尤其是文本处理方面有广泛的应用,它的一大优势在于可以处理任意数量规模的文本数据,因此非常适合处理地质资料。GATE框架中的元素被有效地分为不同的组件,主要包括语言资源组件、处理资源组件、可视化资源组件、重置组件、分词组件等[4]。语言资源组件是指和地质资料数据相关的组件,如词典、语料库、文本资源等,处理资源组件指的是GATE框架中程序算法实现的组件,如解析器、N元组模型,可视化资源组件可以将GATE框架的处理结果展现给前端用户。GATE框架中还有一个专门用于提取文本中的英文信息的组件ANNIE,对于一些涉及英文内容的地质资料非常有用。地质资料输入GATE框架后会被转换为GATE的内部格式,以此为GATE框架提供统一的文件表示模型,然后重置组件会去除地质资料中已经存在的标注信息。接下来GATE框架的分词组件将文本切分为最简单的token,相关联的token被组织为词表,词表通过索引文件访问。
4 地质资料数据挖掘系统实现
本文设计的地质资料数据挖掘系统主要分为两大子系统:系统管理子系统以及服务子系统。系统管理子系统采用B/S模式,采用响应式页面设计方案,能够实现地质资料管理部门间的信息共享及业务协同。服务子系统前后端分离实现,主要提供地质资料服务目录、地质资料发布管理、地质资料数据服务等功能,服务子系统的主要模块包括文本聚类模块、信息提取模块。
地质资料服务目录功能实现地质资料的原始文件、实物信息等的综合查询服务,支持用户根据传统地质资料的各元数据、资料分类、资料年代以及全文关键词等进行检索;对于可公开的地质资料还提供电子文档在线服务。地质资料发布模块提供图文发布、结构化资料发布等方式,两种方式都支持批量发布、批量检索。
地质资料数据服务功能可以支撑地质资料的全生命周期,主要服务包括:汇交在线办理、汇交监管、委托管理、政务服务以及全流程关联服务等,此系统应用后地质资料从采集、汇交,到受理、验收以及公示等都可以全流程管理。当在矿产勘查及开采领域应用时,系统可以汇总勘查领域的地质资料数据集,全面而又整体地反映区域内的地质资料分布、特征等信息,从而提供基础信息支撑。当应用到油气地质资料领域时,油气地质资料数据集可以再次细分,把不同区块形成油气成果、原始及实物地质资料分别形成专题数据库,为油气矿业权的出让、管理提供数据服务。
5 结语
本文对地质资料数据挖掘系统进行研究,首先简要介绍数据挖掘技术,然后采用文本聚类分析方法提高推荐资料间的相关性,并从地质资料中提取关键信息,不仅可以从目录元数据中获取信息,还可以综合反映地质资料的全文主旨,以此提高地质资料的利用效率。
参考文献
[1] 张蕾,易锦俊,王楠,等.省级实物地质资料管理与服务现状研究[J].地质论评. 2024(3):807-811.
[2] 喻孟良.数字化转型背景下地质资料信息化管理探究[J].信息与电脑(理论版). 2024,36(2):221-223.
[3] 刘炳菊.地质资料档案史料的挖掘与利用[J].上海国土资源.2022,43(1):93-96,102.
[4] 朱小龙.地质文本中油气藏特征提取及成藏知识图谱构建研究[D].北京:中国地质大学,2021.
[5]蔡金铸.安徽省庐江县岳山银铅锌矿地质特征及成矿预测[J].西部探矿工程. 2023,35(11):132-135,139.
