
面向小目标检测的轻量化改进CenterNet算法
2024-07-31 00:00:00张伟丰
湖北汽车工业学院学报 2024年2期
关键词:目标检测








摘 "要:为提高传统目标检测算法的实时性,并解决小目标检测效果不佳及漏检率高的问题,提出了改进CenterNet算法。首先将特征提取网络由ResNet50改为SqueezeNet,卷积计算的部分用深度可分离卷积代替;接着使用双阈值改进NMS算法替代单阈值-非极大值抑制算法,通过DIoU计算损失函数。结果表明:改进算法在安全帽和口罩检测数据集的检测精度分别为91.3%和85.5%,与CenterNet算法相比,性能分别提升了2.35%和3.76%,同时具有更快的检测速度。
关键词:目标检测;SqueezeNet;深度可分离卷积;CenterNet
中图分类号:TP391.41 " " " " " " " " " " " " 文献标识码:A 文章编号:1008-5483(2024)02-0057-07
Lightweight Improved CenterNet Algorithm for Small Target Detection
Zhang Weifeng
(School of Economics amp; Management, Hubei University of Automotive Technology, Shiyan 442002, China)
Abstract: In order to improve the real-time performance of the traditional target detection algorithm and solve the problems of poor effect and high miss rate in small target detection, an improved CenterNet algorithm was proposed. Firstly, the feature extraction network was changed from ResNet50 to SqueezeNet. The convolution calculation parts in the network were replaced by depthwise separable convolution. Then, the double-threshold improved non-maximum suppression (NMS) algorithm was used to replace the single-threshold NMS algorithm, and the loss function was calculated through DIoU. The experimental results show that the detection accuracy of the improved algorithm in helmet detection and mask detection datasets is 91.3% and 85.5%. Compared with the original CenterNet algorithm, the performance is improved by 2.35% and 3.76%, respectively, and the detection speed is faster.
Key words: target detection; SqueezeNet; depthwise separable convolution; CenterNet
目前主流的目标检测算法为以FasterRCNN为代表的双阶段检测算法和以YOLO系列为代表的单阶段检测算法,这些算法均是基于anchor的算法,需要产生大量的anchor,并且需要人工设定大量的超参数,如尺寸、数量等,参数设置不合理往往导致检测性能下降,另外大量的anchor区域为负样本区域,造成正负样本不平衡,影响模型训练效果,导致模型的复杂度较高。为避免这些缺点,不需要anchor的全新检测思路出现。2018年Law等提出了CornerNet,以目标边界的左上角点和右下角点为关键点来预测边界框;2019年Zhou等提出了CenterNet[1],直接以目标的中心点作为关键点进行分类和边界回归。2种算法不必在检测过程中产生大量先验框,检测速度相应提高,但仍有较大计算量,无法满足高实时性检测的要求,因此需要设计更加轻便灵活的网络。在特征提取网络的轻量化设计方面,目前也取得了比较多的成果。一些典型方法如SqueezeNet[2]、ShuffleNet[3]、MobileNet[4]、ThunderNet[5]等轻量化神经网络,通过设计更加高效的网络单元,在不损失网络性能的条件下,减少网络的参数量,提升网络运行速度;另外一些研究提出了模型的压缩方法,如剪枝、量化、知识蒸馏等;还有一些研究则着重于高效的网络结构设计,如ESPNet[6]执行新的空间金字塔模块以提高计算效率,ICNet[7]使用多尺度图像作为输入和级联网络来提升准确率,BiSeNet[8]引入空间路径和语义路径以减少计算量。文中在CenterNet基础上进行网络轻量化改造,并进行优化:1)特征提取网络采用SqueezeNet,并进行改进以贴合网络检测层,将传统卷积替换为深度可分离卷积;2)在检测框的非极大抑制方面,使用双阈值改进NMS(GDT-NMS)算法替代单阈值NMS算法,减少目标漏检和误检问题,提升小目标检测性能;3)使用GIoU替换IoU计算目标间的相似度,使目标定位更准确。
1 网络结构设计
1.1 主干特征提取网络
CenterNet用到的主干特征网络有多种,常用的有VGG、ResNet等,这些网络虽然能提取到较好的特征,但参数量太大,网络训练和推理需要耗费大量计算资源。应用于移动设备的目标检测算法需要解决网络效率问题,即采用轻量的特征提取网络。近年来提出的轻量级网络主要有MobileNet系列、ShuffleNet系列、GhostNet、SqueezeNet等[11],文中采用SqueezeNet作为特征提取网络,轻量化设计策略描述如下:1)使用1×1卷积层替代3×3卷积层;2)减少3×3卷积层的输入特征图通道数;3)推迟神经网络下采样的时机。
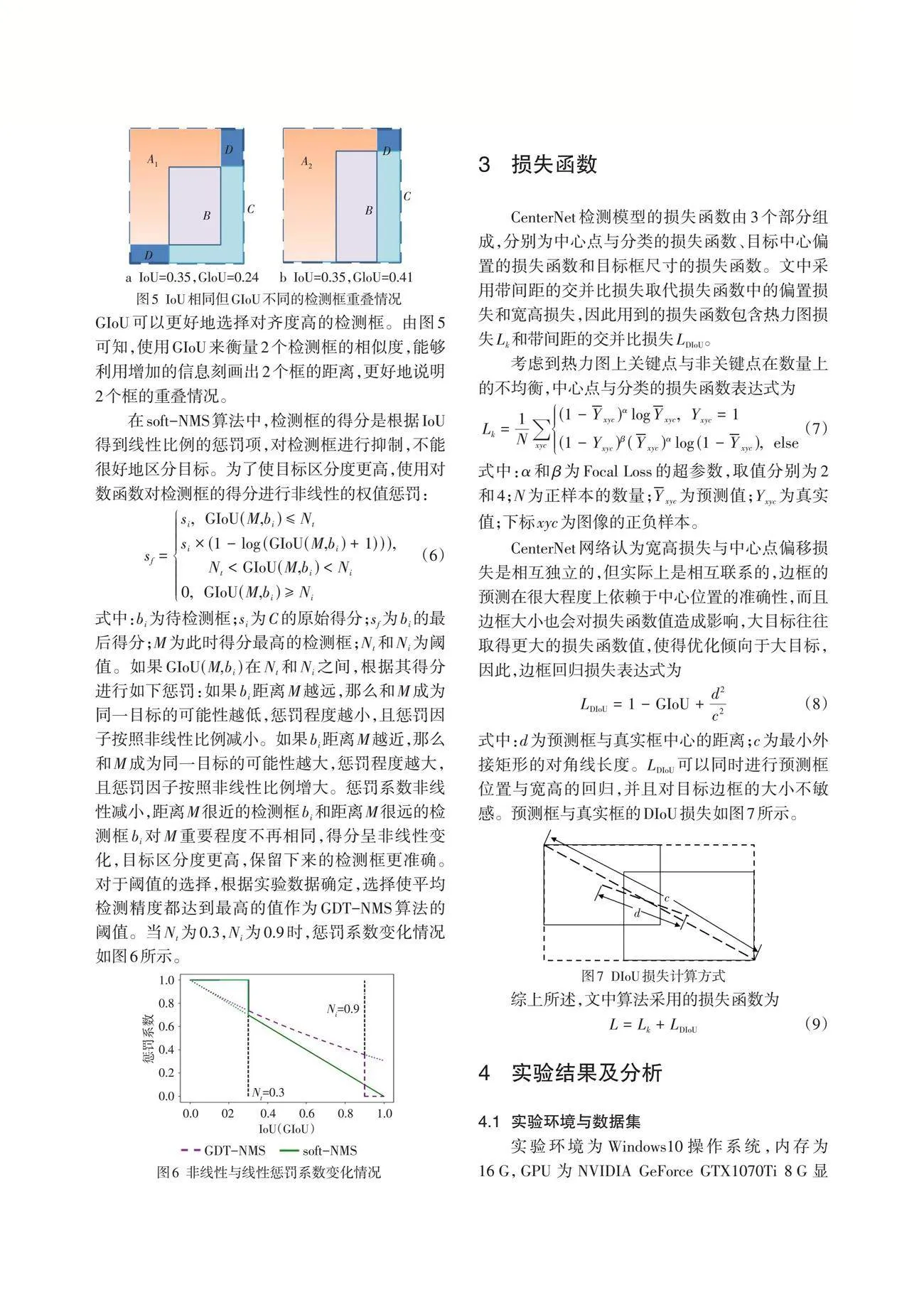
SqueezeNet的核心是fire模块,包含squeeze和expand,squeeze用来减少expand的输入特征图通道数,组成部分主要为1×1卷积层,expand部分包含1×1卷积层和3×3卷积层。fire模块共有3个超参数,分别为squeeze中卷积的通道数[s1×1]、expand中1×1卷积的通道数[e1×1]、expand中3×3卷积的通道数[e3×3],满足
[s1×1lt;e1×1+e3×3] (1)
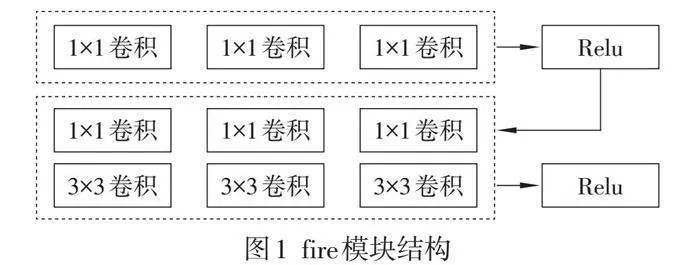
相当于在2个3×3卷积中间加入了瓶颈层。Fire模块结构如图1所示。文中网络结构是在SqueezeNet基础上加入短连接后形成的结构。增加短连接可以提高网络的性能,有效防止梯度消失,提升网络训练的稳定性,而且增加简单短连接的效果比增加复杂短连接的效果更好。简单短连接的Squeeze Net结构如图2所示,包括1个卷积层、8个fire模块和1个卷积层。
1.2 网络改进与检测网络构建
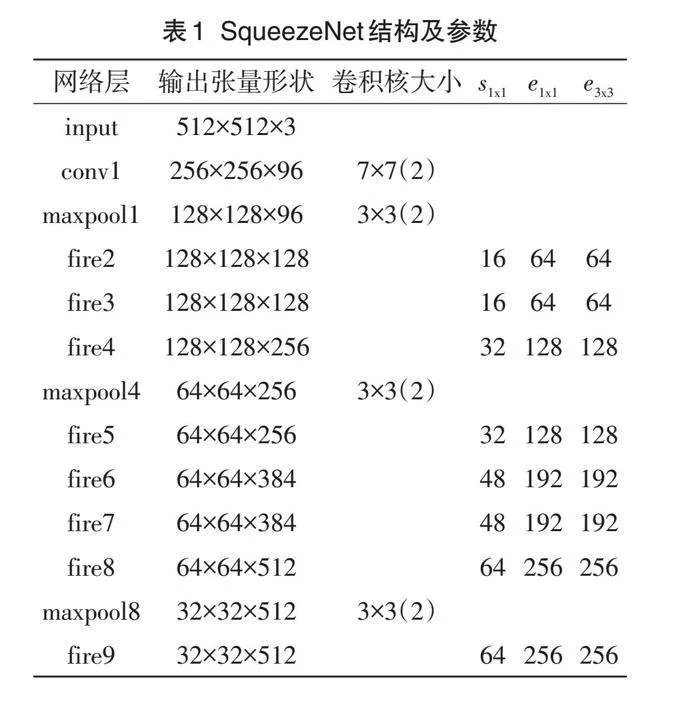
在简单短连接的SqueezeNet基础上,去掉fire9之后的模块,当输入图片是512×512×3时,最后网络输出的shape为32×32×512。网络结构及参数设置如表1所示。接着在后面加上3×3的深度可分离卷积,调整通道数至256,利用2次反卷积进行上采样,得到更高分辨率的输出。2个反卷积的输出通道数分别设置为128和64,最终获得1个128×128×64的有效特征层。这个特征层相当于将整个图片划分成128×128个区域,每个区域存在1个特征点,如果某个物体的中心落在这个区域,那么就由这个特征点来确定。最后利用这个特征层进行3个卷积:
1)热力图预测 卷积通道数为num_classes,输出shape为(128,128,num_classes),代表每个热力点是否有物体存在,以及物体的种类。
2)中心点预测 卷积通道数为2,输出shape为(128,128,2),代表每个物体中心距离热力点偏移的情况。
3)宽高预测 卷积通道数为2,输出shape为(128,128,2),代表每个物体宽高的预测情况。
检测网络的整体框架如图3所示。
在传统卷积中,设输入通道数为[ci],输出通道数为[co],卷积核尺寸为[k],则参数量为[cik2co]。深度可分离卷积中,首先进行逐通道的卷积(DW卷积),此时通道数为1,然后再用1×1的卷积(PW卷积),将上述经过卷积之后的所有特征图的通道串联起来。深度可分离卷积参数量为
[k×k×1×ci+1×1×ci×co=cik2+cico] (2)
传统卷积和深度可分离卷积参数量比值为
[cik2+cicocik2co=1co+1k2] (3)
由此可见,将模型中传统卷积用深度可分离卷积代替,参数量大幅度减小。
2 双阈值改进的非极大值抑制算法
目标的重复检测或漏检会直接影响算法最终的检测准确率。在算法的后处理阶段,使用GDTNMS算法来抑制多余的检测框。首先在计算检测框的得分时,使用GIoU代替传统的IoU计算目标间的相似度:
[D=C-A⋃B, " GIoU=IoU-DC] (4)
式中:A和B为2个检测框;C为A、B的最小外接矩形;D为矩形C中不含A和B并集的部分。[GIoU]计算方式如图4所示,即
[IoU=A⋂BA⋃BGIoU=A⋂BA⋃B-C-(A⋃B)C] (5)
利用GIoU计算检测框的相似度有如下优点:1)当使用IoU计算时,只能反映2个目标的重合程度,不能描述其距离。通过引入1个外接矩形C,2个框之间的距离通过A、B、C共同确定,即使A、B不发生重叠,GIoU也能反映出2个框的远近。2)IoU不能反映2个检测框的重叠形式。当2个检测框在许多不同方向上有重叠,并且IoU相同或相近时,仅使用IoU衡量2个检测框的相似度,无法保证保留下来的检测框更接近真实位置。GIoU通过引入C和D的信息可更好地反映出检测框的对齐程度,2个目标的对齐程度越接近,目标的相似度越高,因此能够保证保留下来的检测框定位更加准确。
如图5所示,2组重叠方式不同的检测框,A1和A2为候选目标,矩形框B为该目标的真实位置,当无法使用IoU判断哪个检测框更接近真实位置时,GIoU可以更好地选择对齐度高的检测框。由图5可知,使用GIoU来衡量2个检测框的相似度,能够利用增加的信息刻画出2个框的距离,更好地说明2个框的重叠情况。
在soft-NMS算法中,检测框的得分是根据IoU得到线性比例的惩罚项,对检测框进行抑制,不能很好地区分目标。为了使目标区分度更高,使用对数函数对检测框的得分进行非线性的权值惩罚:
[sf=si, " GIoU(M,bi)≤Ntsi×(1-log(GIoU(M,bi)+1))), " " " "Ntlt;GIoU(M,bi)lt;Ni0, " GIoU(M,bi)≥Ni] (6)
式中:[bi]为待检测框;[si]为C的原始得分;[sf]为[bi]的最后得分;[M]为此时得分最高的检测框;[Nt]和[Ni]为阈值。如果[GIoU(M,bi)]在[Nt]和[Ni]之间,根据其得分进行如下惩罚:如果[bi]距离[M]越远,那么和[M]成为同一目标的可能性越低,惩罚程度越小,且惩罚因子按照非线性比例减小。如果[bi]距离[M]越近,那么和[M]成为同一目标的可能性越大,惩罚程度越大,且惩罚因子按照非线性比例增大。惩罚系数非线性减小,距离[M]很近的检测框[bi]和距离[M]很远的检测框[bi]对[M]重要程度不再相同,得分呈非线性变化,目标区分度更高,保留下来的检测框更准确。对于阈值的选择,根据实验数据确定,选择使平均检测精度都达到最高的值作为GDT-NMS算法的阈值。当[Nt]为0.3,[Ni]为0.9时,惩罚系数变化情况如图6所示。
3 损失函数
CenterNet检测模型的损失函数由3个部分组成,分别为中心点与分类的损失函数、目标中心偏置的损失函数和目标框尺寸的损失函数。文中采用带间距的交并比损失取代损失函数中的偏置损失和宽高损失,因此用到的损失函数包含热力图损失[Lk]和带间距的交并比损失[LDIoU]。
考虑到热力图上关键点与非关键点在数量上的不均衡,中心点与分类的损失函数表达式为
[Lk=1Nxyc(1-Yxyc)αlogYxyc, " Yxyc=1(1-Yxyc)β(Yxyc)αlog(1-Yxyc), " else] (7)
式中:α和β为Focal Loss的超参数,取值分别为2和4;[N]为正样本的数量;[Yxyc]为预测值;[Yxyc]为真实值;下标[xyc]为图像的正负样本。
CenterNet网络认为宽高损失与中心点偏移损失是相互独立的,但实际上是相互联系的,边框的预测在很大程度上依赖于中心位置的准确性,而且边框大小也会对损失函数值造成影响,大目标往往取得更大的损失函数值,使得优化倾向于大目标,因此,边框回归损失表达式为
[LDIoU=1-GIoU+d2c2] (8)
式中:[d]为预测框与真实框中心的距离;[c]为最小外接矩形的对角线长度。[LDIoU]可以同时进行预测框位置与宽高的回归,并且对目标边框的大小不敏感。预测框与真实框的DIoU损失如图7所示。
综上所述,文中算法采用的损失函数为
[L=Lk+LDIoU] (9)
4 实验结果及分析
4.1 实验环境与数据集
实验环境为Windows10操作系统,内存为16 G,GPU为NVIDIA GeForce GTX1070Ti 8 G显存,python版本3.6.8,深度学习框架为tensorflow 2.3.0,通过CUDA10.2进行网络训练的加速。实验数据集来自于网络,为公开的口罩数据集和安全帽检测数据集,与VOC数据集格式一致,每条数据都是图片与其相对应的xml文件。口罩数据集只有2个类别“have_mask”和“no_mask”,对应的图片数量分别为514张和651张,共计1 165张图片。安全帽检测数据集共有7 581张图像,同样有2个类别,“hat”表示佩戴安全帽,“person”表示普通未佩戴的行人头部区域。按照8∶2划分训练集和验证集,首先进行数据预处理,遍历每张图片并且从xml文件中读取检测框的坐标数据和分类数据,按照文件路径、检测框坐标、类别格式写入文本文件中,网络训练时,根据路径读取图片以及标签,生成训练数据集。由于数据集样本数不足,为提高训练网络的性能,在训练过程中使用数据增强处理,对原始图片随机进行裁剪、颜色变换、镜像翻转等数据增强的操作。
网络训练的参数设置如下:Batch size为8,Epoch为100或80,初始学习率为0.0001,通过模拟余弦退火策略来调整网络的学习率。
4.2 评价指标
选择平均精度均值(mAP)和检测速度对算法进行评估,引入F1-score指标。F1-score是对精度和召回率的调和平均,表达式为
[F1=2prp+r, " p=TPTP+FP, " r=TPTP+FN] (10)
式中:[p]为精确率;[r]为召回率;TP为真正例;FP为假正例;TN为真负例;FN为假负例。文中数据集只包含2类样本,以口罩数据集为例,mAP为
[mAP=2-1APhave_mask+APno_mask] (11)
4.3 对比实验
由于在算法后处理中采用了GDT-NMS算法,阈值的选择对算法的检测精度有直接影响,需要根据实验选择最佳的阈值组合。由于[Ni大于Nt],因此[Ni]取0.2~1,[Nt]取0.1~0.9,步长为0.1,对不同阈值组合分别进行实验。首先在训练数据集上完成网络训练,然后在测试数据集计算出mAP。mAP随[Ni]和[Nt]的变化情况如图8所示,[Ni]和[Nt]对算法的检测精度有明显影响,这是由于阈值过大或过小会造成目标漏检或者误检,导致mAP偏低。口罩检测数据集[Ni]取0.6、[Nt]取0.3和安全帽检测数据集,[Ni]取0.8、[Nt]取0.4时,算法检测精度最好。
为验证改进算法(SN-CenterNet)的有效性及可靠性,在PASCAL VOC 2007数据集上进行实验。将实验结果与当前主流的目标检测算法进行性能对比,如表2所示,可以看出,SN-CenterNet算法在mAP相当或稍微下降的前提下,模型体积减小,检测速度提升,适用于需要实时计算的应用场景。
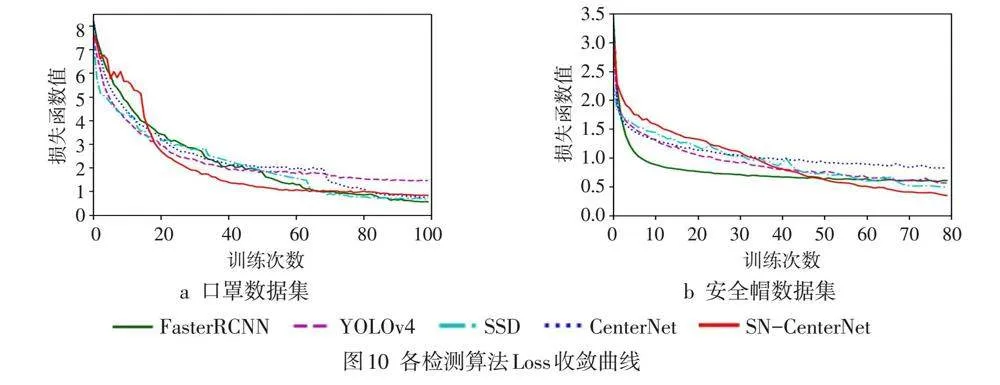
选择CenterNet、Faster RCNN、YOLOv4、SSD算法与SN-CenterNet算法在口罩数据集和安全帽数据集上进行训练和测试,得到PR和损失函数变化曲线,见图9~10。从图9看出,SN-CenterNet算法检测性能基本上超过其他方法或者与之相当,在计算量大大减小的情况下,在这些数据集中仍保持良好的泛化能力和检测能力,达到了预先设计的目标。从图10可看出,SN-CenterNet算法在进行数据集的训练时表现得更加稳定,损失函数呈现稳定下降,并有继续收敛的趋势,表明对网络的训练更加有效,同时由于网络参数轻量化,训练速度更快。
不同算法对比实验结果如表3所示,可以看出,SN-CenterNet算法参数量仅为其他算法的1/10左右,因此推理速度快。由于进行了多处优化和改进,SN-CenterNet算法检测精度与其他算法相比并未大幅下降,比CenterNet算法有所提升,平均精度达到了91.3%和85.5%,检测速度大幅提高,在2个数据集上FPS均超过了80,能满足实时性的要求。
4.4 消融实验
为验证各种改进算法的有效性,对SqueezeNet、深度可分离卷积、GDT-NMS算法和GIoU目标相似度计算进行了消融实验,设计了8种不同的组合方式,实验结果如表4所示。A组为CenterNet,B组将主干网络替换为了SqueezeNet,可以看出,B组mAP有一定下降,但FPS有较大提高,与预期结果符合。C、D、E组是在CenterNet基础上分别增加了深度可分离卷积、GDT-NMS算法和GIoU目标相似度计算,mAP有一定程度的提高,FPS有一定提高或基本保持不变。F、G、H组采用了SqueezeNet作为主干网络,并且分别应用了上述改进方法,FPS均有较大提高,同时MAP保持不变或略有提升,和B组相比,MAP显著提升,证明了SN-CenterNet算法的有效性。
4.5 图片检测效果
不同算法与其他算法在口罩和安全帽数据集上的部分检测结果如图11~12所示,可以看出,SN-CenterNet算法能有效进行小目标检测,并且对检测框的定位更加准确,对目标区有更高的置信度,误检和漏检率较低。
5 结论
在目标检测算法的实时应用领域,网络轻量化是主要解决方案,性能良好的轻量化目标检测算法需要更优的网络设计。文中在CenterNet基础上进行了一系列改进,不需要产生anchor,在速度和精度上能实现较好的平衡。使用SqueezeNet代替原有主干网络,虽然特征提取能力有所降低,但算法整体更加轻便;使用深度可分离卷积代替传统卷积,在保证特征提取能力的同时,参数量进一步减小,很大程度减少了运算量,加快了模型推理速度;在算法后处理阶段,使用双阈值改进NMS算法,使目标定位更加准确,减少了误检和漏检的概率,实验证实了算法的检测效果良好,运行速度有较大提高,可满足实时检测的要求。
参考文献:
[1] "黄跃珍,王乃洲,梁添才,等. 基于改进CenterNet的车辆识别方法[J]. 华南理工大学学报(自然科学版),2021,49(7):94-102.
[2] "Iandola F N,Han S,Moskewicz M W,et al. SqueezeNet:AlexNet-level Accuracy with 50x fewer Parameters and lt;0.5MB Model Size[EB/OL]. 2016:arXiv:1602.07360. http://arxiv.org/abs/1602.07360
[3] "Zhang X Y,Zhou X Y,Lin M X,et al. ShuffleNet:an Extremely Efficient Convolutional Neural Network for Mobile Devices[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE,2018:6848-6856.
[4] "Howard A G,Zhu M L,Chen B,et al. MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Applications[EB/OL]. 2017:arXiv:1704.04861. http://arxiv.org/abs/1704.04861.pdf
[5] "Zheng Qin,Zeming Li,Zhaoning Zhang,etc. ThunderNet:Towards Real-time Generic Object Detection. Computer Vision and Pattern Recognition (cs.CV). 28 Mar 2019,251–258.
[6] "Mehta S,Rastegari M,Caspi A,et al. ESPNet:Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation[C]//European Conference on Computer Vision. Cham:Springer,2018:561-580.
[7] "Zhao H S,Qi X J,Shen X Y,et al. ICNet for Real-time Semantic Segmentation on High-resolution Images[EB/OL]. 2017:arXiv:1704.08545. http://arxiv.org/abs/1704.08545
[8] "Yu C Q,Wang J B,Peng C,et al. BiSeNet:Bilateral Segmentation Network for Real-time Semantic Segmentation[C]//European Conference on Computer Vision. Cham:Springer,2018:334-349.
[9] "Paszke A,Chaurasia A,Kim S,et al. ENet:a Deep Neural Network Architecture for Real-time Semantic Segmentation[EB/OL]. 2016:arXiv:1606.02147. http://arxiv.org/abs/1606.02147
[10] "董艺威,于津. 基于SqueezeNet的轻量化卷积神经网络SlimNet[J]. 计算机应用与软件,2018,35(11):226-232.
[11] "胡玲艳,周婷,许巍,等. 面向番茄病害识别的改进型SqueezeNet轻量级模型[J]. 郑州大学学报(理学版),2022,54(4):71-77.
[12] "李成豪,张静,胡莉,等. 基于多尺度感受野融合的小目标检测算法[J]. 计算机工程与应用,2022,58(12):177-182.
[13] "王文光,李强,林茂松,等. 基于改进SSD的高效目标检测方法[J]. 计算机工程与应用,2019,55(13):28-35.
[14] "Lin T Y,Dollár P,Girshick R,et al. Feature Pyramid Networks for Object Detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE,2017:936-944.
[15] "Lin T Y,Goyal P,Girshick R,et al. Focal Loss for Dense Object Detection[C]//2017 IEEE International Conference on Computer Vision (ICCV). IEEE,2017:2999-3007.
[16] "Bochkovskiy A,Wang C Y,Liao H Y M. YOLOv4:Optimal Speed and Accuracy of Object Detection[EB/OL]. 2020:arXiv:2004.10934. http://arxiv.org/abs/2004.10934
[17] "Zhang P P,Liu W,Lu H C,et al. Salient Object Detection by Lossless Feature Reflection[C]//Proceedings of the 27th International Joint Conference on Artificial Intelligence. ACM,2018:1149-1155.
[18] "王建军,魏江,梅少辉,等. 面向遥感图像小目标检测的改进YOLOv3算法[J]. 计算机工程与应用,2021,57(20):133-141.
[19] "王继霄,李阳,王家宝,等. 基于SqueezeNet的轻量级图像融合方法[J]. 计算机应用,2020,40(3):837-841.
猜你喜欢
科技创新与应用(2016年36期)2017-02-21 18:48:01
软件(2016年4期)2017-01-20 09:38:03
科教导刊·电子版(2016年28期)2017-01-10 22:25:23
科学与财富(2016年28期)2016-10-14 23:45:18
无线互联科技(2016年7期)2016-05-30 13:57:06
电脑知识与技术(2016年5期)2016-04-14 13:48:16
科技视界(2016年4期)2016-02-22 13:09:19
哈尔滨理工大学学报(2015年5期)2016-01-19 18:06:12
湖南大学学报·自然科学版(2015年10期)2015-11-30 18:52:07
现代电子技术(2015年20期)2015-10-26 22:48:16
