
基于深度学习的实时视频通话人像抠图方法
2024-07-10 10:19:45李曈
无线互联科技 2024年11期
关键词:深度学习
李曈


摘要: 文章提出基于深度学习的实时视频通话人像抠图方法,充分利用了多维监控空间进行抠图特征多维识别,从而更加准确地提取人像边缘和背景特征,进一步优化抠图效果。研究通过生成人像三分图,建立适用于实时视频通话的人像抠图模型,为人像编辑提供了更高质量的抠图工具。实验结果显示,这一方法不仅在抠图效果上表现出较高的连接度,而且具有较好的应用潜力,可以有效提升人像抠图的精准性和实时性,对视频通话等场景具有积极意义。
关键词:深度学习;视频通话;人像抠图;抠图方法
中图分类号:G642 文献标志码:A
0 引言
随着互联网技术的发展,视频通话已成为人们日常沟通的重要方式。然而,视频通话中的背景往往会影响通话体验,尤其是当背景杂乱或与主题无关时。为了解决这一问题,人像抠图技术应运而生[1]。该技术能够将视频通话中的人像从背景中分离出来,从而使用户可以将人像置于任何所需的背景之上。然而,现有的抠图技术往往存在处理速度慢、效果不佳等问题,无法满足实时视频通话的需求[2]。
针对现有技术的不足,本文提出了一种基于深度学习的实时视频通话人像抠图方法,通过实验验证了所提出方法的有效性和实时性。
1 基于深度学习的实时视频通话人像抠图方法设计
1.1 抠图特征多维识别
创建多维监控空间,首先使用扫描设备进行初始面部扫描。接下来,通过复制面部图像并进行分析,系统会比较面部特征[3]。利用人脸姿态估计技术,可以调整面部方向,从而扩大识别范围并提高面部图像识别的准确性。计算识别时标准人脸比例的公式为:
H=(1-θ)2∑χy+χθy+2(1)
在公式(1)中,θ表示瞳孔双眼之间的距离,H表示标准人脸尺度值,y反映识别次数,χ反映瞳孔中心到鼻子末端的距离。表示识别率[4]。标准人脸尺度值是用于对特征进行标准识别的值,根据实际的识别需求和标准校准,对人脸的单个位置进行二次提取,收集获得的数据以供进一步使用。
1.2 基于深度学习生成人像三分图
本文的目标是根据人脸的大小,调整人像三分图中未知区域的比例,使得抠图方法更加灵活,能够适应不同的人脸尺寸和比例,提高了算法的普适性和通用性[5]。将深度学习技术应用于生成人像三分图中,能够提高在实际应用场景中视频抠图对图像影响的准确性。
为了实现这一目标,采用人脸检测的方法来确定图像中的人脸位置,获取左右瞳孔、鼻型和左右嘴角等关键部位的转向单元[6]。双眼瞳孔之间的距离是一个重要的参考值,它反映了面部识别中使用的面部大小。然而,如果面部位置发生显著变化,面部的宽度和高度也会随之改变。当脸部左右旋转的角度发生变化时,双眼之间的距离也会相应改变。抬头和低头也会影响面部的高度。为了获得相对稳定的参考值,使用方程(2)来表示。
S=max(P,N)(2)
在公式(2)中,S表示标度值,N是瞳孔中心到鼻子末端可移动的最大距离,P是瞳孔双眼之间可移动的距离。
通常,用于训练的人像三分图是在α的标记图像的基础上绘制的。在α的图像中创建人像三分图,经过腐蚀和膨胀操作,从图像α中去除每个像素,得到3个点的图像。控制双边肖像上未知区域的占比具体方程如式(3)所示。
Ti=128|Dk(Ai)-HEk(Ai)|>th
Ai其他(3)
在公式(3)中,Ai表示原始像素值,Dk表示稀释算子,Ek表示腐蚀算子,k表示函数核,th表示人像三分图中未知区域的比例阈值。像素Ti有3个可能的值:0,127和254,分别表示背景、未知区域和地面。在阿尔法图像中,像素Ai的值只有0和254。其中,0表示背景,254表示地面。通过这个公式,可以精确地控制人脸图像的分割,从而提高图像处理的准确性和稳定性。
通过调整人脸比值S,可以实现对腐蚀和扩展核大小、未知区域的专一率以及训练和移除三角形等操作的精确控制,从而优化人脸图像的分割过程,提高分割结果的准确性和质量。
使用上述方法进行面部标准化,将面部标准化为128像素×128像素。基于双眼间的距离,使用相似的变换矩阵绘制128张标准化的面部图像。与上述方法相同,使用比例缩放、平移和裁剪变换公式将肖像转换为标准1024像素×1024像素,使用面部特征点作为参考点。变换矩阵如下:
τ=a0b
0ac(4)
a=48/S;b=γx-162;c=γy-255;(γx,γy)为原图像中鼻尖关键点的坐标。
为了获得更精细的人像三分图,采用了基于深度学习的方法,对第三时刻表生产网络进行训练。输入数据是来自RGB的3个特征图像。该网络具有多个通道,能够提供前景、背景和未知区域的3个分割结果。特别地,采用了Resnet101结构进行训练,该结构能够产生3个部分的时间表。损失函数由交叉熵损失函数定义。在训练过程中,使用了基于深度学习的18618个训练视频通话中的3个分割图像。此外,还使用了方程(4)来裁剪成1026×513预训练图像。最后一层被修改为3个输出类别。使用553个图像数据进行训练,该方法能够改进该层的学习指标,降低整个网络的学习指标,从而更好地协调整个网络。
在三分图生成网络模型前向推断过程中,根据方程(4),将彩色图像转换为1026×1026分辨率。模型结果为1026×1026的分割图T。当将图像I与分割图T连接时,原始的3个Q生成通道是RGB图像数据,第四通道则是4个T通道分割图像中的图像Q。为了将图像Q缩小到320×320分辨率,从而生成人像三分图。此外,必须在整个过程中记录图像的转换参数,以便最终能够重新建立原始分辨率的图像。
1.3 构建实时视频通话人像抠图模型
基于之前获取的三分图像,利用图像信号处理开发了一个智能人脸抠图模型。首先,利用公共密钥矩阵和三角形处理程序来获得处理信号的简化过程,构建了相应的显示密钥公式。其次,利用原始自然图像来校准更深层次的信息和视觉有效性信息,对多级切割位置进行过度分割。通过集成形态学稀释和侵蚀算法,可以测量分割单元的值,从而获得所需的切割图像。利用彩色纹理图、热特性图以及储量表示方法,通过完成初始阈值的处理来获得地面目标阈值的精确结果,从而获取精细的前景目标抠图结果。
使用生成的人像三分图,构建了透明度遮罩矩阵,即将人像和背景分离的掩模矩阵。为人像区域赋予一个透明度值,通常为1(完全不透明),表示该部分保留在最终图像中。为背景区域赋予另一个透明度值,一般为0(完全透明),表示该部分在最终图像中被完全去除。边界区域则根据具体需求赋予中间的透明度值,用来实现人像和背景之间的自然过渡效果。将生成的透明度遮罩矩阵与原始图像进行融合,根据遮罩矩阵中不同区域的透明度值,将人像和背景合成为一幅新的图像。这样就可以实现透明度遮罩效果,使得人像被准确地提取并与背景合成,达到更加自然、逼真的视觉效果。实时视频通话人像抠图模型的计算公式如下:
Eq=τ010110010
→En=τ00…0001…1001…1000…00(5)
在公式(5)中,Eq和En表示图像采集和处理的膨胀过程。
2 实验论证
本研究的主要目标是分析和评估基于深度学习的实时视频通话人像抠图方法在实际应用中的效果。为了实现这一目标,采用了比较分析的方法,建立了3个测试组,张远等[3]的基于不同场景下三分图扩展的图像抠图算法(传统方法1)、刘相良等[6]的基于多级表征线索注意模型的轻量化抠图方法(传统方法2)以及本文提出的基于深度学习的实时视频通话人像抠图方法。在实验过程中,根据实际需求和标准的变动,对最终的试验结果进行了对比验证。
2.1 实验准备
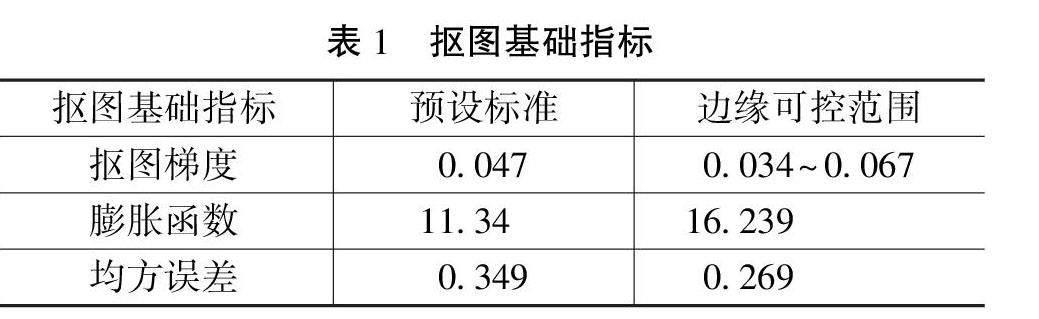
利用综合显示技术分析和构建智能人脸测试环境。选择100条人脸识别图像视频作为主要测试对象,其中训练组40条,测试组60条。使用PyTorch处理核心视频,然后获取适当的数据和信息,将其集成到面部视频中。主要的抠图指标如表1所示。
根据表1,确定了抠图的基本指标设定。此外,使用替换技术创建了多维回收空间,开发了动态严格训练集,确定了字符像素值为205,将其他像素值设为 0。使用获得的人像三分图视频来膨胀完成基本的抠图环境设置。
在预先构建的测试环境中,使用深度学习技术测试了实时视频通话人像抠图方法。为了测试结果准确,创建了6个抠图任务,从选定的100个人脸视频中选择了60个进行抠图处理。基于深度学习技术生成三分图,对整个视频进行方位统计和处理,使用模型和转换模块校准面部识别特征,创建适当的识别键坐标,最终转换阿尔法视频。通过调整视频阿尔法的综合指标和参数,通过在面部的相应位置进行抠图,得出了抠图数据集的平均分辨率标准。经过初步处理后,将其设置在指示器位置,测算抠图后新图像的连接度,最终得到实验结果并进行记录。在上述设置的基础上,比较和分析实验结果,实验结果如图1所示。
2.2 对比实验
从图1中可以看出,本文方法的图像连接度超过了最低控制标准0.014%,均高于传统方法1和传统方法2,这表明该方法具有较好的抠图效果,连接度较高,更具应用价值。
3 结语
随着科技的不断发展,人们对视频通话的需求越来越高,对通话体验的要求也越来越严格。因此,人像抠图技术作为提升视频通话体验的关键技术,其研究具有重要的意义。本文所提出的基于深度学习的实时视频通话人像抠图方法,旨在解决传统抠图技术存在的问题,满足实时视频通话的需求。实验结果表明,该方法在保证抠图效果的同时,具有较好的实时性,为提升视频通话体验提供了有力支持。
参考文献
[1]赵子荣,司亚超.基于U2Net的自动抠图技术研究[J].河北建筑工程学院学报,2023(3):202-206.
[2]李国贞,潘红改.Photoshop软件中的抠图方法和图像合成应用[J].漯河职业技术学院学报,2023(5):24-28.
[3]张远,黄磊.基于不同场景下三分图扩展的图像抠图算法[J].智能计算机与应用,2023(7):128-133.
[4]李晓颖,李思琪,洪雪梅,等.采用精确抠图的单条自然图像背景虚化合成方法[J].华侨大学学报(自然科学版),2023(3):391-397.
[5]杨天成,杨建红,陈伟鑫.图像抠图与copy-paste结合的数据增强方法[J].华侨大学学报(自然科学版),2023(2):243-249.
[6]刘相良,张林丛,朱宏博,等.基于多级表征线索注意模型的轻量化抠图方法[J].控制与决策,2024(1):87-94.
(编辑 王永超)
Real-time video ting method based on deep learning
LI Tong
(School of Computer Science and Engineering, Northeastern University, Shenyang 110819, China)
Abstract: The article proposes a real-time video call portrait cutout method based on deep learning, which fully utilizes the multidimensional monitoring space for multidimensional recognition of cutout features, thereby achieving more accurate extraction of portrait edges and background features, and further optimizing the cutout effect. A portrait cutout model suitable for real-time video calls was established by generating a portrait tripartite graph, providing a higher quality cutout tool for portrait editing. The experimental results show that this method not only exhibits high connectivity in the cutout effect, but also has good application potential, which can effectively improve the accuracy and real-time performance of portrait cutout, and has positive significance for scenarios such as video calls.
Key words: deep learning; video call; portrait matting; matting method
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27 19:23:52
中国远程教育(2016年11期)2016-12-27 18:07:31
现代商贸工业(2016年25期)2016-12-26 09:58:02
江苏教育·中学教学版(2016年11期)2016-12-21 11:45:08
江苏教育·中学教学版(2016年11期)2016-12-21 11:36:29
现代情报(2016年10期)2016-12-15 11:50:53
考试周刊(2016年94期)2016-12-12 12:15:04
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
