
融合用户数据的高校图书馆书目系统设计
2024-07-09 00:00:00王一博张鹏翼
图书馆建设 2024年1期
关键词:高校图书馆
[摘 要] 融合图书馆用户数据、Web图书数据的新型高校图书馆书目系统分为数据准备和数据清洗、数据规范和数据集成、数据分析和结果呈现三个模块;用户数据源来自北京大学图书馆数据资源服务中心的用户及其行为数据和馆藏资源及其使用数据,Web数据源包括豆瓣读书数据、当当图书数据、京东图书数据以及中国知网引文数据;数据处理方法包括数据清洗、数据规范和数据集成;系统实现的三个关键技术为融合用户数据及内容的图书推荐方法、豆瓣读书笔记的摘要和关键词生成方法以及情感分析方法。该书目系统聚焦于解决书目信息单一的问题,通过集成和分析图书馆用户数据和Web图书数据,丰富书目信息的内容,为下一代图书馆书目系统的设计与实现提供了参考。
[关键词] 高校图书馆 图书馆书目系统 用户数据 网络数据 图书推荐
[中图分类号] G258.6;G250.7 [文献标志码] A [ DOI ] 10.19764 / j.cnki.tsgjs.20221737
[本文引用格式] 王一博,张鹏翼.融合用户数据的高校图书馆书目系统设计[J].图书馆建设,2024(1):121-130,145.
Designing a University Library Bibliographic System Integrating User Data
Wang Yibo, Zhang Pengyi
[Abstract] The new university library bibliography system integrating library user data and e-commerce book purchase platform data is divided into three modules: data preparation and data cleansing, data specification and data integration, data analysis and result presentation. User data sources come from the user and their behavior data, as well as the collection resources and their usage data from the Data Resource Service Center of Peking University Library. Web data sources include Douban Reading Data, Dangdang Book Data, JD.com Book Data, and CNKI Citation Database. Data processing methods include data cleansing, data specification and data integration. The three key technologies implemented in the system are book recommendation methods that integrate user data and content, abstract and keyword generation methods for Douban reading notes, and sentiment analysis methods. This bibliographic system focuses on solving the problem of single bibliographic information. By integrating and analyzing library user data and web book data, it enriches the content of bibliographic information and provides a reference for the design and implementation of the next generation library bibliographic system.
[Keywords] University library; Library bibliographic system; User data; Web data; Book recommendation
0 引 言
随着大数据、人工智能等技术的迅猛发展,各行各业都发生着深刻的变革。图书馆拥有丰富的馆藏资源与数据库商提供的海量信息资源,如何为用户提供更优质的服务是图书馆管理和图书馆学研究共同关注的重要问题之一。
图书馆集成管理系统既包含开放给图书馆用户进行资源检索的OPAC系统,也包含对图书馆的各项业务进行管理的业务管理系统。用户最频繁使用和直接交互的是其中的书目系统,书目系统的设计在很大程度上决定了图书馆是否可以满足用户对于图书馆获取书目资源和服务的基本需求,是用户从多维度评价图书馆发展水平的重要指标之一。目前,图书馆集成管理系统的提供商大都集中在英语国家,如美国、英国、加拿大、澳大利亚、新西兰等国家的 120 多家厂商提供图书馆自动化系统产品[1]。其中,商业自动化系统有 Innovative Interfaces 公司的Millennium、Exlibris公司的Aleph 500和 Voyager系统、SirsiDynix 公司的 Symphony 系统等,开源自动化系统有 Folio、Evergreen、Koha 系统等。
尽管集成管理系统中的书目系统提供了基本的书目元数据检索功能,但现有图书馆书目系统大多未综合利用各类用户数据,未能在图书描述数据和用户使用数据之间建立有效的关联。本文旨在研究如何融合图书馆内部用户数据和Web用户数据,以更好地收集和丰富图书元数据,多维度反映图书的内容和特征,对高校图书馆书目系统的改进提出一些建议。
本文设计的系统架构分为3个主要模块:数据准备和数据清洗、数据规范与数据集成、数据分析与结果呈现。系统设计所用的技术涉及到Web数据采集、数据集成和数据挖掘,自然语言处理相关技术如中文分词、词频统计等,数据库查询语言SQL,计算机系统设计等。
1 国内外相关研究与实践
1.1 图书馆书目系统发展历程和功能
图书馆的发展经历了从以藏书为中心到突出开放借阅,再到以人为本,注重人的需求、可接近性、开放性、生态环境和资源融合的几个阶段[2]。图书馆书目系统作为用户获取图书馆馆藏的重要渠道,其发展历程也可以大致反映上述图书馆发展的阶段。其中,第一阶段(20世纪50年代至70年代)是图书馆系统发展的萌芽阶段[3]。随着计算机的出现,纸质的卡片目录逐渐被机读目录所替代,图书馆系统开始出现。第二阶段(20世纪80年代到21世纪初)是图书馆系统的蓬勃发展阶段[3]。这一时期图书馆的发展理念从以馆藏资源为中心逐渐向以用户为中心转变。图书编目不再成为系统中唯一重要的模块,采编、流通、期刊管理、用户管理等模块也都陆续集成在系统中,图书馆的业务流程也得到了一定程度的优化。第三阶段(2010年左右至今)是图书馆系统发展的成熟阶段[3]。商业化图书馆服务平台(Library Service Platform,简称LSP)作为第三阶段图书馆系统进入公众视野,受到越来越多的关注[4]。一些图书馆开始积极研发基于FOLIO(The Future of Libraries is Open)的微服务架构的图书馆书目系统,这从一个侧面说明了图书馆系统由统一的集成书目系统向个性化开发定制的方向转变。
图书馆学研究十分注重对图书馆书目系统发展历程和作用的分析和反思。例如,胡振宁[5]回顾并梳理了深圳大学图书馆系统30年的发展历程。张志东等[6]运用了文献调研法和访谈法,对云南大学1988—2018年的图书馆系统建设历程进行了梳理。霍建梅等[1]对国外较为成熟的图书馆系统市场格局进行了分析,指出了商业化系统和开源系统各自的优劣势、面临的挑战和未来的发展趋势。
一些学者通过分析大量用户搜索书目系统的数据,从中发现了一些特征和规律。早在1993年,Millsap等[7]就发现在加州大学MELVYL图书馆系统中,30.2%的用户只搜索了1次,62.2%的用户进行的是标题检索。Schultheiss等[8]研究了德国图书馆搜索系统超过420万次的搜索会话,发现用户更倾向于使用简短的搜索语句,约有38%至57%的用户在检索前预先知道需要检索的内容,而且基本都只浏览检索结果的首页。
尽管图书馆书目系统经过几十年的发展已经取得了很大的进步和成就,但不可否认的是,现有书目系统仍存在不足,直接影响了图书馆服务效能,并制约了年轻图书馆用户群体的发展壮大。与网络搜索引擎对检索结果的优化带给用户的体验相比,图书馆书目系统的检索体验老旧而冗余;与此同时,不少用户宁愿花钱在图书电商网站(如当当、京东等)购买新的纸质或电子图书,也不愿在图书馆书目系统费力进行检索;与豆瓣、知乎等相关图书爱好者建立的知识交流社区相比,现有图书馆书目系统也缺乏与用户进行相关交流的平台。Moscoso等将OPAC系统的错误分为4类:与OPAC系统连接操作相关的错误消息,与OPAC搜索数据条目相关的错误消息,与结果页面访问相关的错误消息,与结果导航任务相关的错误消息[9]。Trivedi等[10]对印度不同大学图书馆的239名研究对象开展了问卷调查,结果表明OPAC系统在清晰地展现图书馆资源和可用资源、在线搜索馆藏速度等方面尚有提升的空间。
1.2 书目数据与用户数据融合相关研究
图书馆内部用户数据是指广大用户与图书馆交互不断积累的各类大数据,如用户进出馆数据、借还书数据、预约数据等。已有研究尝试利用内部数据源对书目系统的用户服务进行扩充。其中,何娟[11]使用了某院校图书馆2017 年全年的用户借还书数据,从书目数据和用户数据两个维度构建了个人用户画像,利用向量空间模型计算用户之间的相似度,使用K-means聚类法对用户聚类形成群体用户画像,为图书个性化推荐奠定了基础。胡云飞[12]对某高校图书馆的用户基本信息、馆藏基本信息、用户行为信息进行了清洗和汇总,构建了读者行为库,并针对某一维度或多个维度组合后的用户群体,利用自身提出的基于马氏距离的二分 K-means 算法进行聚类,最后设计和实现了一个高校图书馆用户画像系统。
与图书馆对用户体验不够重视相比,图书电子商务网站(如京东、当当等)通过收集和分析用户信息、建立不同群体用户画像做精准营销。Web用户数据是指用户在多种知识社区、电子商务平台以及微博等社交媒体平台上的行为记录,如对图书的购置、评价和其他与之相关的原创内容生成行为。例如,中国知网引文数据库中的图书被引频次,豆瓣读书社区中的图书评论数据,以及京东和当当等电子商务平台上图书的销售与用户评价数据等。在用户行为建模中,已有大量研究提出了各种模型的构建方法,如基于图书内容和借阅记录的推荐模型,用户书评的情感分析和摘要提取方法等。国内外的学者们对此进行了很多相关研究,Hu等[13]提出一种基于Word2Vec和TF-IDF融合的特征提取方法建立用户画像,并通过分析一段时间内用户的搜索日志,推断出用户的基本信息。Wang等[14]将用户兴趣分为固定类别的兴趣和动态事件的兴趣,并通过建立动态模型捕捉用户的兴趣变化。Sharma等[15]为用户查询提供个性化结果,将查询结果与用户资料中的关键词匹配,证明了方法的有效性。陈杨等[16]提出基于网络数据采集建立的少儿图书用户画像模型,该模型包含对用户基本属性、认知兴趣、认知心理的角色定位,对用户的图书偏好和图书浏览及购买历史的阅读需求,以及对用户消费行为、忠诚度及满意度的行为属性,可以实现用户信息的标签化,进而实现图书圈层精准营销目的。陈旭松[17]考虑到用户动态兴趣的因素,将用户一段时期内购买的物品按照时间排序,刻画出用户的长短期兴趣,以提升推荐精度。
有很多学者对图书馆书目系统的改进提出了新的设计思路。Nahotko[18]分析研究了55所波兰大学图书馆网站的内容及其分面导航的OPAC,提出应该增加MARC字段的搜索并提供“一框搜索”,而且可以在得到初步检索结果的基础上叠加一组类别过滤器。林珍梅[19]将大数据时代的Hadoop技术与图书馆阅读书目智慧推荐相结合,集成了多个不同来源的数据,将整个系统设计分为网页前端、数据存储、分析推荐3部分,并采用调查问卷等性能评估方法对系统的推荐效果开展了评估。曹意[20]引用人工智能技术训练书目数据集,利用迭代函数通过多次迭代获得最优推荐集合,结合硬件设计和软件设计完成图书馆书目推荐系统设计。唐乐等[21]通过采集、分析、处理西南交通大学图书馆OPAC日志数据的结构,设计了一个日志管理系统,该系统可以自动采集并分析用户日志,识别用户检索行为,完成图书推荐并将结果返回给用户。
无论学者是应用各类数据挖掘方法对图书馆各类流通数据分析挖掘方面的研究,还是对用户在电商平台上购买、评论商品等行为的用户画像构建,都为更好地改进图书馆书目系统,进而更好地为用户服务提供新的思路和方法。
2.3 用户检索与书目系统研究
信息行为研究发现,用户在检索过程中无法精准描述自身信息需求,Belkin[22]将这种状态称为“知识非常态”(Anomalous State of Knowledge,简称ASK)模型。因此,需要深入到信息需求表达的背后,了解其信息查找行为的根源,即其欲利用信息解决的问题[23]。在信息检索领域,在系统设计中融入ASK模型,可以更有效匹配信息资源和用户需求[24]。有研究通过“隐式相关性反馈”,基于用户的点击、浏览等行为,作为反映信息资源与用户需求相关性的隐式指标来更好地预测用户的检索意图[25]。
用户在使用书目数据进行检索的过程中,也存在检索式表达和真实需求之间的差异。目前,高校图书馆书目系统大多存在的问题包括:提供的检索入口与用户真实需求相关性差异大、检索结果未包含电子资源、书目信息过于简单、缺少用户互动的知识社区等。例如,美国哈佛大学图书馆员Single[26]在研究16项图书馆门户可用性测试成果的基础上总结出图书馆门户存在的6大问题,包括专业术语的使用、用户对搜索工具不理解、用户对资源实体的误用、外部链接的低效、全文获取的障碍性及用户对页签系统的忽视。与之类似,北京大学图书馆采用的是1998年由SirsiDynix公司推出的Unicorn系统(已升级为Symphony系统)。该系统在国内多所高校图书馆(如兰州大学图书馆、河南大学图书馆等)已有广泛应用,系统普遍面临以下三类问题:首先,用户输入关键词与检索结果之间的关联性不高,达不到用户的心理预期;其次,书目信息展现过于简略;最后,系统缺乏用户交互性的知识社区环境,限制了师生之间的知识传播。
因此,构建融合用户数据的高校图书馆书目系统可以在一定程度上利用用户的借阅、购买、评论等行为数据进行更精准的推荐服务,如同义词、相关检索词的联想和推荐等,并可以通过用户在使用系统中的反馈进一步完善系统,形成用户和系统之间的交互。
2 系统设计和主要模块
本文在参照国内外部分图书馆书目系统和电子商务系统的基础上,设计了一个融合内外部用户数据的高校图书馆书目系统。信息系统开发的规范流程主要分为4个步骤:需求分析、系统分析、系统设计、原型实现。本文遵循了一般信息系统开发的流程,重点介绍系统分析、系统设计和原型实现。
系统的总体设计分为三个主要模块:数据准备和数据清洗、数据规范和数据集成、数据分析和结果呈现。本研究系统的总体架构如图1所示。
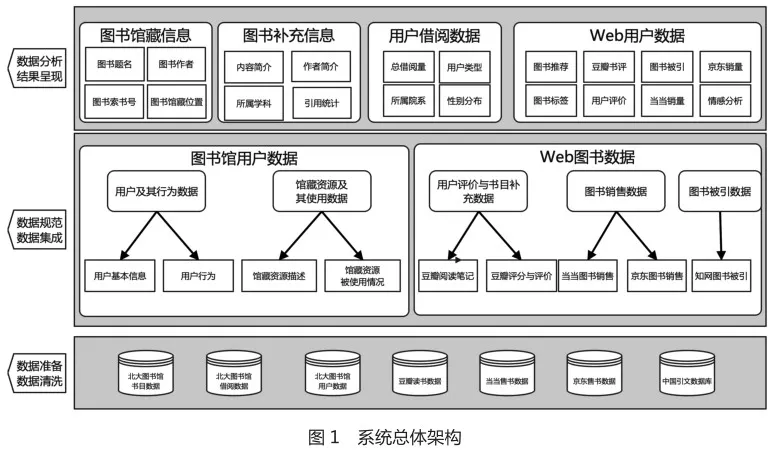
模块一为数据准备和数据清洗。为深入挖掘用户在图书馆、互联网知识社区、电子商务购书平台上的行为模式,本文的数据以北京大学图书馆的各类数据为例,并引入Web图书数据。不同数据的抽取方式存在很大差异,如北京大学图书馆的数据都是结构化地存储在数据库中,因此只需要编写SQL语句就可以从数据库中抽取出数据;而京东等电商售书平台的评论数据分散在不同网页中,需要程序爬取后编写相关的正则表达式,去掉无关的网页标签。
模块二为数据规范和数据集成。图书馆用户数据可分为用户及其行为数据和馆藏资源及其使用数据两大类:用户及其行为数据包含用户基本信息和用户行为,馆藏资源及其使用数据包含馆藏资源描述和馆藏资源被使用情况。图书馆内部用户数据一般为结构化数据,其搜集方法通常是:根据特定需求,通过SQL语句从数据库中查询和导出。Web图书数据又可分为用户评价和书目补充数据、图书销售数据以及图书被引数据三大类:用户评价和书目补充数据包含豆瓣阅读笔记、豆瓣评分与评价,图书销售数据包含当当图书销售和京东图书销售数据,图书被引数据包含知网图书被引数据。由于每一类数据源的元数据格式、数据处理规则不同,数据清洗后的数据并不能直接用于数据分析,需要对数据进行分类,并进行人工审核和二次规范。数据规范完成后,再将各类规范后的数据存放在数据库表中,以备后续分析和使用,本文使用PostgreSQL关系型数据库存储数据。
模块三为数据分析和结果呈现。本模块在对数据库中的数据进行分析与挖掘的基础上,构建用户端的展示系统,将最终分析结果呈现给用户。该系统展示的内容包括四类:图书馆藏信息、图书补充信息、用户借阅数据和Web用户数据。尤其是用户借阅数据和Web用户数据,可作为传统书目系统数据的有效补充。例如,系统会根据用户的检索行为对用户给予一定量的显式反馈,如“查看更多馆藏”“相似用户推荐”等,数据管理员也可以通过浏览借阅日志分析发掘用户的潜在需求。本系统后端采用Python下的网页端框架Django,前端采用Vue.js用户界面的渐进式框架,结合Element桌面端组件库共同搭建。

UML(Unified Modeling Language,统一建模语言)用例图描述系统外部的执行者与系统的用例之间的某种联系,能够较为确切和详细地描述用户的功能需求[27]。本系统主要包括三类用户:广大读者、数据管理员和系统管理员。对于读者,可以查询自己的个人信息,进行图书检索、社群发现,对系统进行相关性反馈。数据管理员在日常工作中主要负责数据的管理与分析以及数据可视化展示,数据的管理与分析包括用户借阅数据、Web用户数据和图书馆藏数据三个部分,每部分数据都需要进行查询及添加、更新及删除等;数据可视化展示包括对用户借阅数据、Web用户数据和图书馆藏数据的可视化展示。系统管理员主要负责整个系统的运转和维护,如系统界面和功能维护、后台用户增删、用户权限设定和系统日志维护等。用户和用例的关系以及用例间关系如图2所示。
3 数据源和数据处理方法
3.1 图书馆用户数据源
北京大学图书馆内部组织结构调整后成立了国内第一家高校图书馆数据中心——数据资源服务中心。该中心将所有数据分为:用户及其行为数据、馆藏资源及其使用数据、服务业务数据、财务数据、馆员数据、科研类数据、基础数据、长期保存数据8大类,进一步划分为94小类数据。本文选择的内部数据源主要来自于用户及其行为数据和馆藏资源及其使用数据两大类。
用户行为数据包含两部分:一是描绘用户基本信息的数据,主要包含的数据项有用户借阅证号、姓名、性别、身份、院系、学部、权限授予和到期时间等;二是描绘用户在图书馆内产生的进馆、借阅、预约、室内阅览等行为的数据,以借阅数据为例,包含的数据项有借阅时间、借阅工作站编号、借阅馆别、所借书条码号、借阅用户借阅证号等。
馆藏资源及其使用数据也包含两部分:一是描绘图书馆馆藏资源的数据,主要包含的数据项有机器可读目录MARC、图书题名、作者、出版地、出版商、出版年、语种、分类号、索书号等;二是描绘馆藏资源被使用情况的数据,主要包含的数据项有图书编目时间、上架时间、外借时间、上一次借阅时间、当前借阅状态等。
3.2 Web图书数据源
本文所选的Web数据源较为丰富,具体包括:豆瓣读书数据、当当图书数据、京东图书数据以及中国知网引文数据库,以获得书目基本信息之外的用户评价与书目补充数据、图书销售数据和被引数据。
用户评价与书目补充数据:既包括用户在阅读某本图书后留下的图书摘要和评论,撰写的阅读笔记、读后感、相关图书推荐等内容,也包括反映用户真实感受的情感值。豆瓣网是一个知识社区网站,用户可以通过注册的方式选择自己感兴趣的社区(包括豆瓣读书、电影、音乐等),在所选社区中与其他用户交流心得。以豆瓣读书社区为例,每位用户可以为感兴趣的图书打分、撰写评论、撰写读书笔记等,其他用户可以查看该图书总得分、评价人数、评价星级,从而对该书形成一个总体印象。据不完全统计,豆瓣读书每个月有800万的访问用户数和上亿的用户访问量[28]。
图书销售数据:截至2022年,我国各类电商图书零售码洋规模占比为84.7%,实体店图书零售码洋规模占比为15.3%[29]。叠加疫情影响,线下销售乏力的趋势仍在持续。京东、当当为线上图书销量排行榜中前两名的平台。
图书被引数据:中国知网引文数据库是依据中国知网收录数据库的文后参考文献和文献注释为信息对象建立的具有特殊检索功能的文献数据库[30],所提供的文献资源引用数据包括期刊论文、博硕士学位论文、图书、专利等。本文是以书目为研究对象,因而重点关注图书被引这一数据指标。
Web用户数据一般为半结构化或非结构化的数据,其搜集方法主要是通过编写程序自动抓取,或者使用商业数据采集工具(如八爪鱼等)进行数据的抓取。本文通过python编写的爬虫和八爪鱼工具相结合,采集了用户评价与书目补充数据、图书销售数据和图书被引数据。
3.3 数据处理方法
本文所用的数据处理方法包括:数据清洗、数据规范和数据集成。数据清洗所用的程序语言为Python编程语言,具体包括Numpy、Pandas等常用的数据清洗模块;数据规范是指对每一大类数据,根据其元数据格式和数据处理规则不同,选择合适的数据规范方法;数据集成是将规范的各类数据集成到同一个数据库的不同数据表中。其他的数据处理方法还包括中文分词、英文词干提取等。
4 系统实现的关键技术
4.1 融合用户数据及内容的图书推荐方法
在图书推荐方面,本文采用了结合图书内容、内部数据源和Web数据源的综合推荐算法,主要由以下三个步骤组成:首先,对当当购书平台、京东购书平台、豆瓣读书平台的图书推荐列表,以及北京大学图书馆图书借阅的共现图书列表取并集,得到候选图书列表;其次,依据内部数据源和Web数据源中的数据及图书的摘要内容,对候选图书列表中的每一本候选图书进行打分;最后,根据所有图书得分,按照分值高低进行排序,选择分值最高的前n本图书作为最终的推荐图书列表。

4.2 摘要生成和关键词提取方法
除图书基本信息外,用户评价及摘要数据是用户在阅读书目内容的基础上,撰写的个人主观感受,可以独立于图书著者的内容简介,对这类内容的分析有助于加深其他用户对该书的理解。
文本摘要是大至一本书、小至一段文字内容的提炼和概括。随着自然语言处理技术的不断发展,生成式摘要和抽取式摘要均成为自动摘要生成的主要方式[31]。自动生成文本摘要的主要方法有:统计分析方法、主题模型方法、图模型方法和机器学习方法等[32],这些方法已在实践中有广泛的应用,如生成新闻摘要、学术报告摘要、法律文本摘要等。
与内容概括式的摘要不同,用户在阅读平台如豆瓣读书等分享的内容多种多样,既包括对书内容的概括、喜欢的章节摘抄,也包括读后的感悟和思索。因此,对豆瓣读书笔记的分析和挖掘,能够补充传统书目数据中内容概括式摘要的不足,从提炼和分享用户的阅读体会出发,贯彻“用户中心”的理念。本文采用了TextRank算法对每本书的豆瓣评论文本进行摘要生成与关键词提取。其中,TextRank算法是一种基于图的排序算法,主要用于文本的无监督排序,其基本思想来源谷歌的PageRank算法。该算法通过构建文本中的关键词或句子之间的共现关系网络,评估每个关键词或句子的重要性,进而提取重要的关键词或生成文本摘要。
4.3 情感分析方法
Web用户评价及读书笔记一般表达了撰写者的情感色彩和情感倾向性,如喜、怒、哀、乐、赞同、反对、中立等,其他用户可以通过浏览这些内容了解撰写者对于图书的主观感受,分析不同用户的文本内容能够得出用户对于图书的情感值。
文本情感分析又称意见挖掘[33],主要研究如何从文本中发现或挖掘人们对于某种事物、产品或服务所表达出的情感、意见或情绪[34]。情感分析包括情感信息的抽取、情感信息的分类以及情感信息的检索与归纳[35],可以在篇章级、句子级和方面级三种粒度展开[36]。
用户的书目选择和阅读过程,既受到图书主题和信息需求主题的相关性影响,也受到图书所传达的情绪和情感倾向的影响。用户阅读图书特别是休闲阅读的主要目的之一就包括寻求情感支持和情绪共鸣等。分析用户分享的笔记文本的情感倾向,可以帮助其他用户更好地判断图书所反映的情感特征是否符合其需求。本文在去除停用词、中文分词的基础上,对每本书所有用户的评价及读书笔记调用SnowNLP①进行情感分析,计算情感值得分。
5 原型系统展示
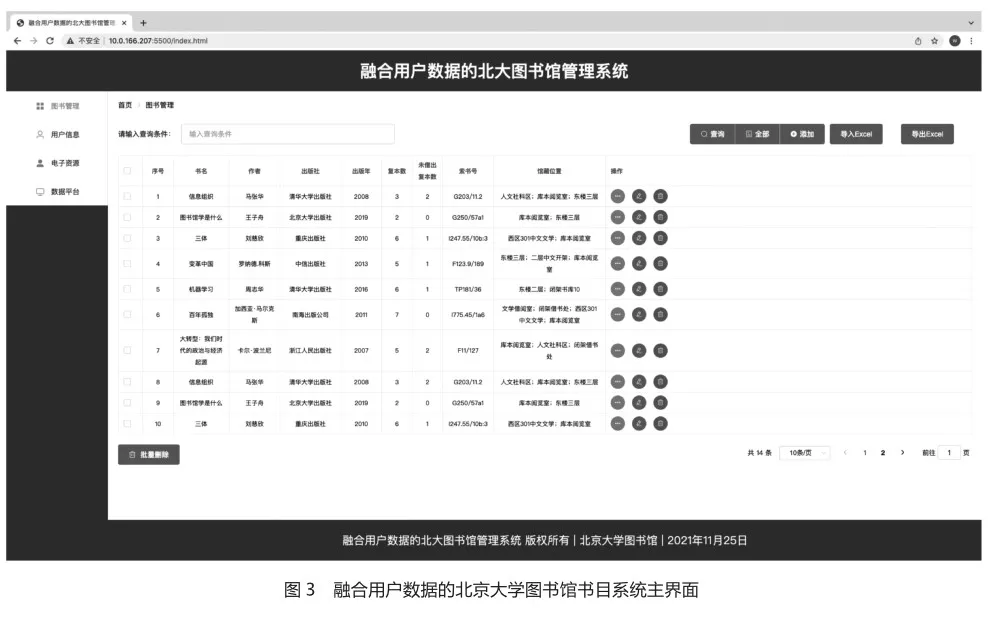
本文设计了一个“融合用户数据的北京大学图书馆书目系统”,如图3所示。
在图3中,系统的主界面简要展示了第一页共计10本书的基本信息,书目信息下方可选择每页显示的数据数量和翻页页码。每本书的具体信息包括:书名、作者、出版社、出版年、复本数、未借出复本数、索书号、馆藏位置。点击一本书后面的绿色“查看”按钮,将会打开该书的详情界面,用户可查看本书更为详细的信息,管理员可进行常规的增删查改等操作,亦可完成批量导入导出等操作。

以一本书的详情页面为例,进入这本书的详情界面,首先可以看到图书的题名和封面图片,如图4所示。
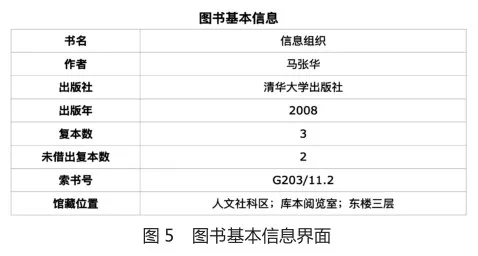
“图书基本信息” 模块与图3所展示的系统主界面的内容基本一致,包括书名、作者、出版社、出版年、复本数、未借出复本数、索书号和馆藏位置(见图5)。
“图书补充信息”模块包含这本书的内容简介、作者简介、所属学科和引用统计。其中,内容简介、作者简介来自Web数据源当当图书平台,所属学科为教育部一级学科,引用统计为中国知网引文数据库中的图书被引次数(见图6)。

“用户借阅数据” 模块反映了这本书在北京大学图书馆的借阅情况,具体包括:近五年总借阅量、 近五年本科生借阅量、近五年硕士研究生借阅量、近五年博士研究生借阅量、近五年教工借阅量、 近五年男性借阅量、 近五年女性借阅量、近五年借阅最多的学院和近五年借阅最多的学部。上述数据通过书目、借阅、用户数据库的SQL查询得到,查询结果如图7所示。

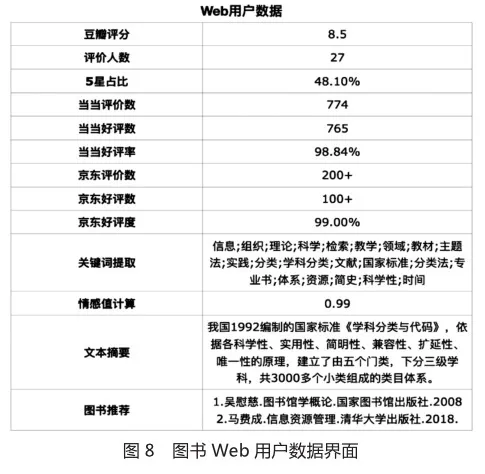
“Web用户数据” 模块反映了这本书在豆瓣、当当、京东的评价和销售情况,还包括对这些平台的用户评论、读书笔记挖掘分析的结果。具体包括:豆瓣评分、评价人数、 5星占比、当当评价数、当当好评数、当当好评率、京东评价数、京东好评数、京东好评度、关键词提取、情感值计算、文本摘要和图书推荐(见图8)。
6 结论与展望
信息技术的快速发展带来了新的发展机遇。传统的图书馆书目系统受到搜索引擎技术、电商平台等的冲击和挑战,用户不再单纯依赖书目系统进行信息获取和图书借阅。这都为高校图书馆提升用户获取图书的满意度、更好履行信息提供者和用户服务职能提出了更高的挑战。
智慧图书馆是未来的发展方向,其体现之一就是要求图书馆系统能够随用户需求的不断提升而成长,不断优化图书馆的服务[4]。高校图书馆用户在使用图书馆平台时,不仅需要馆藏资源查询、数据库检索等大多数图书馆平台所具备的基本功能,还需要图书推荐、用户社群等更为丰富的交互、交流功能,这都要求图书馆相关学者和技术人员在充分考虑用户需求的基础上,不断完善现有高校图书馆书目系统的功能。
本文旨在研究如何融合图书馆内部用户数据和Web用户数据,为高校图书馆书目系统的改进提出设计方案,并实际搭建了原型系统,主要研究内容如下:
(1)设计了一个融合用户数据的高校图书馆书目系统的框架。系统的设计分为三个主要模块:数据准备和数据清洗、数据规范和数据集成、数据分析和结果呈现。
(2)阐述了图书馆用户数据源和Web图书数据源包含的内容,以及数据处理方法,奠定了系统的基础数据支撑。
(3)提出了系统实现的三个关键技术:融合用户数据及内容的图书推荐方法、豆瓣读书笔记的摘要和关键词生成方法以及情感分析方法。
(4)设计了一个融合用户数据的北京大学图书馆书目系统,对系统的界面和各个功能模块进行了展示。
图书馆书目系统是用户与图书馆交互最多的系统之一,其易用性从很大程度上决定了是否可以满足用户最基本的需求。本研究主要聚焦于解决图书馆书目系统书目信息单一的问题,通过集成和分析图书馆用户数据和Web图书数据,丰富了书目信息的内容,为下一代图书馆书目系统的设计与实现提供了参考。
本文也存在一些研究不足:首先,本文仅选择一所高校的图书馆数据作为内部数据源,可能无法揭示各个图书馆用户的总体特征,更无法反映我国各个地域(东部地区、中部地区、西部地区)之间用户使用资源的差异。其次,本文图书推荐所用算法涉及权重的确定,不同专家间可能会存在一定程度的差异,该主观因素会影响最终的推荐结果,可能不一定满足用户的实际需要。第三,系统未考虑相似用户兴趣的知识社群构建。第四,未对系统进行可用性评估。这些不足将会在今后的研究中不断改进完善。
随着新一代图书馆系统的开放性不断增强,图书馆开源社区的技术水平不断发展,相信在不远的未来,高校图书馆书目系统将可以为用户提供更好的个性化精准服务。
参考文献:
[1] 霍建梅, 李书宁. 国外图书馆自动化系统市场发展状况研究[J].大学图书馆学报, 2012, 30 (4): 66-71.
[2] 吴建中. 走向第三代图书馆[J]. 图书馆杂志,2016,35(6): 4-9.
[3] 何珂.Folio框架下图书馆管理系统设计研究 [D]. 济南:山东师范大学, 2021.
[4] 王文清, 陈凌, 关涛. 融合发展的CALIS新一代图书馆服务平台[J]. 数字图书馆论坛, 2020 (1): 2-10.
[5] 胡振宁. 上下求索 与时俱进——深圳大学图书馆计算机管理集成系统(Sulcmis)发展历程回顾(1985-2015)[J].图书馆论坛, 2017,37(6):36-44.
[6] 张志东,黄体杨,徐国英.云南大学图书馆自动化管理系统发展历程(1988-2018)[J].图书馆论坛,2019,39(9):12-18.
[7] MILLSAP L,FERL T E.Search patterns of remote usersan analysis of OPAC transaction logs[J]. Information technology and libraries,1993,12(3):321-343.
[8] SCHULTHEISS S,LINHART A,BEHNERT C,et al. Known-item searches and search tactics in library search systems:results from four transaction log analysis studies[J/OL].[2022-04-15].https:// www.sciencedirect.com/science/article/abs/pii/ S0099133320301051.
[9] MOSCOSO P,GARCIA ORTIZ F M.Error and information messages in online public access catalogues[J].Revista espanola de documentacion cientifica,2008,31(1):52-65.
[10] TRIVEDI D,BHATT A,TRIVEDI M,et al.Assessment of e-service quality performance of university libraries[J]. Digital library perspectives,2021,37(4): 384-400.
[11] 何娟. 基于用户个人及群体画像相结合的图书个性化推荐应用研究[J].情报理论与实践,2019,42(1):129-133,160.
[12] 胡云飞. 基于读者行为分析和多视角聚类算法的高校图书馆用户画像研究[D].杭州:浙江工业大学,2019.
[13] HU J,JIN F,ZHANG G,et al.A user profile modeling method based on word2vec [C]// Proceedings of the IEEE International Conference on Software Quality,Reliability and Security (Companion Volume). Prague:IEEE,2017.
[14] WANG J,LI Z W,YAO J Y,et al.Adaptive user profile model and collaborative filtering for personalized news[M]//ZHOU X F, LI J Z,SHEN H,et al. Frontiers of WWW research and development-Apweb 2006.Harbin:8th Asia-Pacific Web Conference,2006:474-485.
[15] SHARMA S,RANA V.Web search personalization using semantic similarity measure[C]//Proceedings of the 2nd International Conference on Recent Innovations in Computing (ICRIC),Jammu:Springer International Publishing,2020.
[16] 陈杨,罗晓光.少儿图书用户画像模型构建及精准营销分析——以分众传播理论为视角[J].中国出版,2019,(11): 50-53.
[17] 陈旭松.基于用户行为序列建模的推荐算法研究[D].北京:中国科学技术大学,2021.
[18] NAHOTKO M.Knowledge organization affordances in a faceted Online Public Access Catalog(Opac)[J]. Cataloging classification quarterly,2022,60(1):86-111.
[19] 林珍梅.基于Hadoop的高校图书馆阅读书目智慧推荐系统设计[J].图书馆学研究,2020(23):91-101.
[20] 曹意.基于人工智能技术的图书馆书目协同推荐系统[J].现代电子技术,2020, 43 (15):168-170,174.
[21] 唐乐,李向前.基于用户日志的OPAC推荐系统设计与实现[J].数字图书馆论坛, 2019(1): 30-36.
[22] BELKIN N J.Anomalous states of knowledge as a basis for information retrieval[J].Canadian journal of information and library science,1980(5):133-143.
[23] 马费成,宋恩梅.信息管理学基础[M].武汉:武汉大学出版社,2011:310-311.
[24] 乔欢.信息行为学[M].北京:北京师范大学出版社,2010: 168-169.
[25] KELLY D,TEEVAN J.Implicit feedback for inferring user preference:a bibliography[C]//Proceedings of the Acm Sigir Forum.New York:ACM,2003.
[26] 陈剑晖.美国图书馆门户研究的启示与思考[J].图书馆学研究,2015(3):89-92,101.
[27] 姚路,李靖,曾斌,等.管理信息系统[M].北京:国防工业出版社,2021:338-340.
[28] 2020年十大阅读APP排行榜 古今中外文学 国外名著阅读软件[EB/OL].[2022-04-15].https://www.phb123. com/shenghuo/shuji/40525.html.
[29] 2022年图书零售市场年度报告[EB/OL].[2023-09-02]. https://www.sohu.com/a/625857552_121124778.
[30] CNKI中国引文数据库[EB/OL].[2022-04-15].http:// www.scaa.xhu.edu.cn/2c/1f/c2575a76831/page.htm.
[31] GAMBHIR M,GUPTA V.Recent automatic text summarization techniques:a survey[J].Artificial intelligence review,2017,47(1):1-66.
[32] 汪旭祥,韩斌,高瑞,等.基于改进TextRank的文本摘要自动提取[J].计算机应用与软件,2021,38(6):155-160.
[33] 周建,刘炎宝,刘佳佳.情感分析研究的知识结构及热点前沿探析[J].情报学报,2020,39(1):111-124.
[34] MESSAOUDI C,GUESSOUM Z,BEN ROMDHANE L. Opinion mining in online social media:a survey[J].Social network analysis and mining,2022,12(1):25.
[35] 赵妍妍,秦兵,刘挺.文本情感分析[J].软件学报,2010, 21(8):1834-1848.
[36] 谭翠萍.文本细粒度情感分析研究综述[J].大学图书馆学报,2022,40(4):85-99,119.
[作者简介]
王一博 1992年,北京大学信息管理系博士生,北京大学图书馆馆员,研究方向为用户研究、数据分析等。E-mail:wangyibo46@pku.edu.cn。
张鹏翼 1981年,北京大学信息管理系长聘副教授,研究方向为用户研究、信息组织等,本文通讯作者。E-mail:pengyi@pku.edu.cn。
①SnowNLP是一个python的类库,可以应用于中文文本数据的情感训练和预测。
猜你喜欢
现代经济信息(2016年19期)2016-10-20 16:13:56
出版广角(2016年15期)2016-10-18 00:19:57
科技视界(2016年21期)2016-10-17 19:32:37
科技视界(2016年21期)2016-10-17 19:25:20
商(2016年27期)2016-10-17 06:39:10
商(2016年27期)2016-10-17 06:38:27
商(2016年27期)2016-10-17 06:30:59
科学与财富(2016年28期)2016-10-14 23:43:29
科学与财富(2016年28期)2016-10-14 00:28:44
科技视界(2016年20期)2016-09-29 13:17:57
