
基于自然语言的油田勘探大数据检索系统
2024-07-02 09:48刘永军许攀王斌文李兴亮关中南
大众科学 2024年1期
刘永军 许攀 王斌文 李兴亮 关中南
摘 要: 近年来,人工智能和大数据处理技术在多个领域取得了良好效果,在油田勘探开发领域,各油田单位也进行了大量的探索,期望能够通过人工智能算法和大数据处理技术帮助科研人员解决工作中遇到的难题。通过分析自然语言处理的工作原理,结合油田勘探科研生产的实际需求,使用StanfordNLP机器学习工具训练了勘探大数据检索语言模型,开发了勘探大数据检索系统。对自然语言处理的相关概念进行了描述,介绍了分词样本和词性样本的训练过程,讲解了通过模型实现勘探大数据检索的算法实现过程,对勘探大数据检索系统的实际应用效果进行了展示。最后对人工智能在勘探开发领域的应用进行了讨论和展望,为人工智能在该领域的进一步应用打下基础。
关键词: 机器学习 自然语言处理 勘探大数据 人工智能 ChatGPT StanfordNLP
中图分类号: TP391.1文献标识码: A文章编号: 1679-3567(2024)01-0004-05
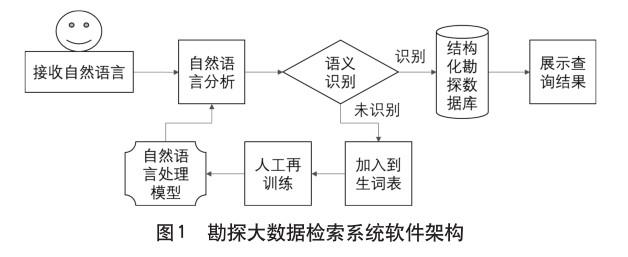
地质资料是地质工作成果的重要载体,是重要的信息资源。将分类语言主题语言(情报语言)与自然语言一体化检索应用于地质资料信息化检索系统,将有效的提高检全率、检准率,使检索操作也比较灵活、简便,这对地质资料信息化管理具有重要意义[1]。吐哈油田从2009年开始持续投入建设吐哈勘探开发技术数据库管理与应用平台,完成了物探、钻井、录井、测井、试油、分析化验等9类数据的数字化管理工作。为进一步提高数字资料的应用效率,吐哈油田期望通过为用户提供自然语言检索方式,使计算机能够更好地理解用户意图,更快更精准地向用户推送所需数据;同时通过自然语言检索,计算机能够挖掘到容易被忽略但对勘探研究非常重要的信息,协助研究人员在勘探研究过程中获得新的突破。整个软件架构如图1所示。
本文研究了自然语言处理算法的基本原理,并以此为理论基础,充分借鉴ChatGPT的算法思路,设计了一套勘探大数据检索系统软件架构,该构架包含样品收集、样本标注、模型训练、模型验证和模型应用五部分,数据处理人员通过不断地对模型进行训练、应用和再训练来完善模型,提高问题识别率和数据检索精度[2]。
在建设勘探大数据检索系统初期,根据勘探数据库自动生成了15 347条自然语言训练样本,采用斯坦福大学研发的开源机器学习工具包StanfordNLP[3]进行模型训练,生成了第一个自然语言分类模型;然后基于吐哈油田勘探生产数据库,使用Eclipse编程工具调用StanfordNLP实现了自然语言分析,开发了第一版勘探大数据检索系统,实现了自然语言的井筒文档和井筒数据问答功能,但问题识别率只有40%,回复正确率仅达到20%。随着系统的不断应用,通过不断收集问题样本,累计再训练了用户输入的10 450条自然语言,系统检索精度有了大幅提升,问题识别率达到70%,有效回复率达到50%。
本文第1节介绍了自然语言处理算法原理;第2节介绍了自然语言处理在勘探大数据库检索系统中的应用;第3节展示了勘探大数据检索系统的应用效果;最后对人工智能在油田勘探开发领域的前景进行了讨论和展望。
1 自然语言处理算法原理
自然语言处理简称NLP(Natural Language Process? ing)。NLP是计算机科学与人工智能领域中的一个重要研究方向,目的是通过预训练语言模型让计算机去理解并处理人类的自然语言,并正确完成自然语言所表述的任务[4]。NLP涉及计算机与人类语言之间的交互,特别是如何对计算机进行编程以处理和分析大量自然语言数据。NLP主要应用于文本挖掘、信息检索、句法语义分析、机器翻译、问答系统、对话系统。总的来看,自然语言的基本原理可以概括为词法分析、句法分析和语义分析。
1.1 词法分析
词法分析(tokenization)是自然语言处理的基本操作之一。分词的直译是词形化,顾名思义,就是把连续的文本分割成一个个独立的词元。目前分词算法的准确度可以达到95%。分词算法根据其核心思想主要分为两种:第一种是基于字典的分词,先把句子按照字典切分成词,再寻找词的最佳组合方式;第二种是基于字的分词,即由字构词,先把句子分成一个个字,再将字组合成词,寻找最优的切分策略,同时也可以转化成序列标注问题。在NLP中,最常用的神经网络为循环神经网络(RNN,Recurrent Neural Network),它在处理变长输入和序列输入问题中有着巨大的优势。目前对于序列标注任务,公认效果最好的模型是BiLSTM+ CRF[5]。结构如图2所示。

1.2 句法分析
句法分析是通过词语组合分析得到句法结构的过程,而实现该过程的工具或程序被称为句法分析器。目前较成熟的句法分析模型是基于概率的短语结构分析方法(Probabilistic Context Free Grammar,PCFG)。PCFG是一种生成式的方法,该算法基于句法树模型,它的短语结构文法可以表示为一个五元组(X,V,S,R,P),X是一个有限词汇的集合,其中的元素称为词汇或者终结符;V是一个有限标注的集合,称为非终结符集合;S称为文法的开始符号,并且包含于V;R是有序偶对(α,β)的集合,就是产生的规则集;P代表每个产生规则的统计概率。
1.3 语义分析
语义分析是指对语言表达进行深层次的理解和解释,以抽取其中包含的语义信息。在自然语音模型中,语义分析技术可以分为不同层次和任务,包括词法分析、句法分析、语义角色标注、命名实体识别等。近年来,基于神经网络的方法在自然语音模型中的语义分析中取得了显著的进展。例如:预训练的语言模型(Pre-trained Language Models)利用大规模无监督语料库进行训练,学习到丰富的语义表示。这些模型可以被用于各种下游任务,如命名实体识别、情感分析等,从而提高对语义的理解和表达能力。
另一个重要的发展是深度学习与知识图谱的结合。知识图谱是一个结构化的知识库,包含丰富的实体、关系和属性信息。将深度学习模型与知识图谱相结合,可以为自然语音模型提供更全面、准确的语义信息。通过利用知识图谱中的实体关系和属性,自然语音模型可以在语义分析过程中获得更多背景知识和上下文信息,从而提高对话的质量和准确度。
2 自然语言处理在勘探大数据库检索系统中的应用
目前油田的信息系统均采用输入或选择关键字段信息,通过在数据库中进行模糊查询的方式来检索数据,然后将数据以列表或文字的方式呈现给用户,用户再在列表中进行人工筛选,得到最终需要的结果。
本方案旨在为用户提供自然语言的输入界面,通过NLP分析语言的语义,使计算机了解用户的真实意图,然后检索数据库,将数据组织为用户想要的结果,推送到显示界面。如用户输入“测试1井1 340米的孔隙度”,则系统会从数据库查询测试1井在1 340 m处的样品孔隙度参数,然后直接展示给用户,省略了人工筛选环节,这将大幅提高用户检索数据的效率。
2.1 勘探大数据检索自然语言处理模型
为实现上文表述的应用场景,需要通过计算机完成从“自然语言”到“数据库语言”的转换,自然语言可以是一段话,也可以是一句话或一个词语。但本文中的自然语言有别于传统意义的自然语言,它是一种结合勘探专业的“专业自然语言”,如上文提到的“测试1井1 340米的孔隙度”,如果按照传统的自然语言,将会分解为“测试、1、井、1 340、米、的、孔隙度”,这将导致计算机无法完成该语言想要达到的目标,因此需要根据勘探专业特点对模型进行完全的重新训练,使算法能够将“测试1井”识别为一个井筒号,从而引导计算机从数据库中检索到测试1井的相关数据。
2.1.1 勘探专业词性分类
为使模型能够识别勘探专业词汇,同时保证计算机能够识别词法分析后形成的单词,并根据单词的含义生成用于查询数据库的SQL语句,按井号、井深、计量单位、报告名称、数据库字段、油田部门(如采油厂、送样单位、钻井公司等)等为类别对训练样本进行词性分类,同时建立数据字典,通过数据字典实现单词和数据库字段的关联,如表1所示。
2.1.2 准备和标注样本
为保证第一个自然语言检索模型具有足够的训练样本,笔者编写了样本生成脚本,使用勘探数据库中的井号等信息,自动生成了第一个标记好的训练样本共计15 347行,表2为部分生成的训练样本格式。

2.1.3 训练和测试模型
采用StanfordNLP作为语言模型的训练工具,针对15 347行训练样本进行了训练,并生成了第一个语言词性分析模型THKT.model.tagger、第一个语言分词模型THKT.ser.gz和第一个字典集THKT_Dict.ser.gz。随后使用StanfordNLP提供的测试工具对模型进行了测试,测试结果表明训练的模型能够满足应用。测试文本和测试结果如表3所示。
2.2 数据检索的算法实现
用户输入的查询语言经过分词和词性标记后,被处理成了计算机所期望的查询数据集、查询条件和查询结果三大类,分别对应数据库中的数据表、查询条件和查询结果。数据检索算法围绕这三部分内容,通过数据字典,将用户输入文字转换为数据库中的数据表、查询条件,然后形成查询语句。针对较为复杂的查询结果,如数据统计、交叉查询等查询结果,系统采用定制开发的方式实现。图3为数据检索的算法实现流程图。
3 勘探大数据检索系统的应用效果
随着勘探大数据检索系统(ChatTuha)的投入应用,该系统获得了广大油田用户的欢迎,在4个月内共接收23 128条自然语言,正确回复了16 349条数据,正确率达到70.6%,为用户提供了实实在在的帮助。同时也在油田范围内掀起了一股有关人工智能在油田各领域如何落地的讨论热潮。
自然语言处理技术在数据库检索中的应用打破了传统的数据检索方式,为用户提供了一种所想及所得的查询手段,大幅提高了数据库的应用效率。下一步,将持续对系统模型进行训练,对相应的相应算法进行扩展,努力将ChatTuha打造成一位具有高智商的工作秘书。图4为ChatTuha的使用界面。
4 讨论与展望
4.1 问题总结
自然语言处理在勘探大数据检索中的应用推动了油田勘探信息化建设中对人工智能研究的讨论,自然语言向机器语言的转换可通过训练样本、使用数据字典、基于机器学习的方法完成;由机器语言向数据库语言的转换可通过对词性进行标记,根据数据和需求的不同将自然语言处理成若干个可分类的条件组合,使用基于关键词匹配、基于相似度和基于分类器的方法实现。现有的基于自然语言的勘探大数据检索虽然取得了不少优秀的成果,也诞生了许多崭新的研究思路,但目前仍存在着一些不足和缺陷没有得到解决。

(1)勘探大数据训练样本等资源缺乏。目前勘探大数据检索的训练样本是根据现有数据库中的信息自动生成的,缺少接近人类实际检索语言的样本,因此样本的收集需要一个长期的过程。
(2)勘探大数据检索模型通用性差。勘探大数据检索模型是完全根据油田勘探专业的应用要求进行训练的,只能应用于油田勘探开发领域,用户只能使用专业性的语言进行提问,否则模型可能会无法识别用户语言。
(3)勘探大数据检索模型的精度有待进一步提高。近年来自然语言处理算法提升了对数据检索语言的识别精度,但提升的幅度有限。研究者还在不断尝试对算法进行完善,来进一步提高模型的精度和运行速度。
4.2 未来展望
根据当前的技术发展与研究现状,未来自然语言在勘探大数据应用方面的研究可以从如下方面开展。
(1)权威机构研究制定勘探大数据模型的训练规范与标准,标注和发布语料库资源供广大学者开展分析研究。
(2)跨专业多样性的训练。为提高分析模型的通用性,可集合钻井、测井、录井、试油、分析检测等不同专业的语言数据集进行联合训练,从而提高模型的通用性和鲁棒性。
(3)建立语料收集机制。可以国内各大油田内部信息平台为依托,设立语料收集窗口,从而增加样本规模,提高语言处理精度。
5 结语

本文旨在回顾自然语言处理在勘探大数据检索中的应用,以帮助新的研究者建立对这一领域的全面了解。首先,对自然语言处理作了简要介绍。其次,通过在实际开发勘探大数据检索平台后得出了自然语言处理在勘探大数据检索中的应用主要包括语句分词、词性识别和数据检索的算法实现。再次,通过展示勘探大数据检索系统的应用效果,得出该方法在勘探大数据应用中具有较高实用性的结论。最后,围绕这3个研究方向进行研究方法和研究进展的阐述。相信随着自然语言处理技术的不断发展,勘探大数据检索研究将有更加广阔的前景。
参考文献
[1]温雪茹,翟国平,李银罗.将情报语言与自然语言一体化检索应用于地质资料检索系统[C]//中国图书馆学会专业图书馆分会,敦煌研究院.中国图书馆学会专业图书馆分会2009年学术年会论文集.中国地质科学院水文地质环境地质研究所,2009:3.
[2]刘睿珩,叶霞,岳增营,等.面向自然语言处理任务的预训练模型综述[J].计算机应用,2021,41(5):1236-1246.
[3]本刊讯.斯坦福大学发布自然语言处理工具包StanfordNLP,支持中文等53种语言[J].数据分析与知识发现,2019,3(3):24.
[4]李小伟,舒辉,光焱,等.自然语言处理在简历分析中的应用研究综述[J].计算机科学,2022,49(S1):66-73.
[5]李铂钧,项秀才让,德吉卡卓,等.基于Bi-LSTM的藏文依存句法分析研究[J].计算机仿真,2023,40(7): 300-304.
猜你喜欢
化工管理(2022年14期)2022-12-02
中国交通信息化(2022年4期)2022-06-17
开放教育研究(2020年2期)2020-03-31
小学科学(学生版)(2019年11期)2019-12-09
装备学院学报(2017年3期)2017-07-21
装备学院学报(2017年2期)2017-06-05
能源(2016年1期)2016-12-01
现代语文(2016年21期)2016-05-25
计算机工程(2015年8期)2015-07-03
天然气与石油(2015年2期)2015-02-28
