
NetExtractor:基于网络轨迹的未知协议逆向方法
2024-06-29 02:43:46王崇宇朱宇坤牛伟纳宁延硕江雅洁张岩峰
四川大学学报(自然科学版) 2024年3期
王崇宇 朱宇坤 牛伟纳 宁延硕 江雅洁 张岩峰


摘 要: 网络协议逆向工程是许多安全领域面临的重要挑战. 当前主流方法是对网络轨迹间的字符和令牌进行比对切分,但现有工作在推导时受限于二进制协议字段取值差异高、状态复杂等特性,存在格式过度切分和多状态字段标注精度低等问题. 基于此,本文提出NetExtractor工具,集成格式提取优化方法和状态标注优化方法. 在格式提取阶段,提取网络轨迹时空特性进行粗聚类,而后进行多序列比对,利用统计特性进行优化合并,进一步提高格式提取的精准度. 在状态标注阶段,引入编辑距离衡量字段间差异,结合随机森林和统计特性对候选状态字段进行约束,提升多状态字段标注精度. 为验证该方法的有效性,本文使用NetExtractor工具对僵尸网络zeroaccess 协议的格式和状态机进行自动化逆向,并在8 个常用协议上开展评估实验验证方法效率,实验表明与领域最领先研究工作相比,NetExtractor 可提升协议格式和协议状态识别准确度,对网络安全分析具有较大意义.
关键词: 协议逆向; 网络轨迹; 协议格式; 状态标注
中图分类号: TP311 文献标志码: A DOI: 10. 19907/j. 0490-6756. 2024. 033005
1 引言
出于经济战略利益、个人隐私保护等多种需求,当前多个行业领域的部分网络协议设计趋于复杂化、私有化和专用化,并且不公开协议规范的实现细节. 此类对于非相关人员而言的“未知”协议(私有协议),本身可能存在安全问题,为网络增加了更多脆弱面. 在实网环境中,多数监测手段无法对未知协议交互过程进行有效监控和分析,而协议漏洞挖掘、资产探测、行为审计、军事数据链分析和通信协议安全等网络安全活动中也存在获取网络协议规范的需求. 对未知网络协议进行基于逆向的识别分析是安全领域需解决的重点问题. 虽然现有wireshark、pyshark 和scapy 等解析工具较为成熟,但此类工具在分析协议过程中依照协议设计规范,仍无法处理私有协议. 而对私有协议的逆向可以帮助发现协议中的问题和缺陷,改进协议的设计和实现,提高网络服务的可用性和灵活性,推动网络技术的发展和创新,从而为网络活动的发展和价值提供支持和保障. 因此在不依赖于协议规范信息等先验条件下,对协议的网络轨迹、系统指令进行采集和分析,获取协议格式、协议语义和协议状态机的“协议逆向”对网络安全具有重大意义.
当前协议逆向研究已有较多成果,但现有研究在分析格式时,对协议中的部分字段会产生过度切分的问题,即一个连续序列被判定为多个相邻序列,对Fuzz 等下游研究产生较大影响,如当缺少高精度的协议格式边界,Fuzz 低价值变异用例数量将指数级增长. 同时对包含多状态字段的协议逆向时,现有研究方法只能识别最核心的状态字段,对于状态描述字段的其他字段难以判定,导致标注后的状态组合不能和协议功能一一映射,影响状态机构建的正确性和完备性,根据错误状态生成的状态机,Fuzz 分析时将无法覆盖到可能存在异常的分支.
基于对现有研究在逆向“ 非密态二进制变长应用层未知协议”时,格式提取过程存在的“ 协议字段过度切分”及“包含多状态字段的协议状态标注精度低”等两个问题的分析. 本文发现非密态协议的字段与流量时空特性存在关联关系,同时过度切分字段间在包含信息量上存在近似关系. 针对多状态字段的协议,状态字段呈现低变异性,状态字段对于报文具有强约束关系,且状态字段常出现于协议中靠前的功能段.
因此,本文提出了一种基于网络轨迹的二进制未知协议逆向方法,该方法针对非密态二进制协议原始数据进行分析,不需引入指定先验,可以逆向协议格式、进行状态标注,可以同时用于二进制文本协议. 方法结合流量时空特征、序列信息熵、序列信息熵变化率和互信息关系对格式提取环节进行优化,同时利用协议功能段和数据段信息熵差异确定协议头部位置,基于状态字段特性筛选候选状态字段,使用编辑距离和权重标记来表述候选状态字段间差异,结合互信息和协议设计共性进一步确定状态字段. 方法整体结合流量时空特性、统计特性和设计约束共性等信息,构建了从格式判定、状态字段判定到状态机构建的一套基于网络轨迹的未知协议逆向方案,使用工控和互联网领域8 个具有代表性的协议,进行了实验分析,并与Netzob[1]、VDV(Variance of the Distributionof Variances)[ 2]、Netplier[3]方法进行效果比对,验证方案正确性和优势,使用zeroaccess 协议进行验证.
本文中准确获取协议格式和状态字段的方法可以辅助下游研究深入解析协议各种字段含义、规范和用法,对协议的功能和行为进一步分析利用具有重要意义,可以广泛应用于协议漏洞挖掘、协议一致性测试、深度包解析、协议重用、僵尸网络检测等领域.
本文主要贡献如下:(1) 为解决协议格式推断中部分字段过度切分的问题,本文对现有的多序列比对方法进行了改进. 使用层次聚类和信息熵等方法对相关序列进行预聚类和过度切分判定,以提取更精确的协议格式,实验结果表明该方法可显著减少过度和错误切分位;(2) 为解决状态机构建中多字段同时约束协议功能导致状态标注精度低的问题,本文设计了状态标注优化方法,该方法结合编辑距离、权重选取、信息熵和互信息等因素,提高了状态标注精度和鲁棒性,进而优化推断结果;(3) 本文实现了内置上述两种方法的未知协议逆向工具NetExtractor,能够在复杂环境下对工控、互联网等领域内的网络协议进行逆向分析,进行格式边界提取、协议状态标注,实现从二进制流量输入到协议格式获取、协议深层信息提取的自动化处理. 同时使用该工具自动化逆向分析了恶意软件内置的用于构建僵尸网络的zeroaccess协议.
2 相关工作
协议逆向方法根据其接收的输入数据类型主要分为两类:第一类方法是基于指令执行轨迹的逆向方法. 该方法主要使用符号执行、污点分析等技术对程序进行逆向分析,以获取表述协议的规范. 然而,基于指令的方法在非受控环境中的实用性较低,同时对于需要获取服务器端二进制文件的情况也存在困难,此外,在出现二进制混淆和封装场景时,该方法也无法进行分析;因此,第二类方法基于网络轨迹的逆向方法[4-34]应运而生, 且在近 3 年逐渐成为研究热点,该类方法核心根据流量数据取值的变化和关联性对报文格式和状态进行分析. 在非受控和半受控的场景下,该方法具有较高的实用性. 但是,在处理加密传输和复杂编码的流量时,如HTTP2. 0、嵌套 TLS 的应用层协议,该方法的效果略有欠缺.
在基于网络轨迹的逆向相关方法中,Mcafee公司发表的PI 项目是协议逆向分析的先驱,他首次引入了生物信息学领域的渐进多序列比对思路. 通过局部多序列比对推断序列间相似度,该研究可以判定常量域或变量域的字段. 然而该方法在二进制协议格式提取精度上略有欠缺, 同时无法获取语义信息. 后续 RolePlayer[35]、 Discoverer[36]、Netzob 和Netplier 等方法的分析在一定程度上会基于 PI 的思想. 其中 Discoverer 首次利用空格和非字母等定界符区分字段位置,在递归聚类后比较子类属性和语义,对相似度高的共性字段进行合并,但由于二进制类协议无法直接使用文本类协议的标识符进行划分,因此在分析二进制类型协议效果较差. Netzob 为逆向领域首次出现的工程化开源工具, 其在格式提取、状态机构建方面进行了进一步优化,但对不同协议类型,泛化能力较差,推断格式边界推断精度仍有待提高. 在状态标注方面,VDV 方法首次基于字段在流内和流间的方差特性,对方差低的字段判定为状态字段,但对多状态字段处理时,仅能识别一个状态字段,且极受相近分布的非状态字段影响. Netplier作为领域最领先研究,对格式提取和状态标注同时进行了处理,其底层基于渐进多序列比对,设定协议约束后,结合概率推导推断协议关键字, 根据关键字取值的联合分布推断消息类型. 但研究底层代码逻辑较僵化、处理时引入了强先验,在分析变长二进制协议时,格式过度切分情况较多、去除先验后多状态字段标注精度仍有待提升. 此外,近期BLEEM[37]将流量侧协议分析与Fuzz 进行了更充分的结合,改进后Fuzz 效果突出,但此研究更侧重于Fuzz 方式的优化,在逆向协议方面并未进行大幅度改进.
3 基于网络轨迹的未知协议逆向方法
本节介绍结合流量时空特性的协议逆向方法,包括协议格式提取和状态字段提取过程.
3. 1 方法概述
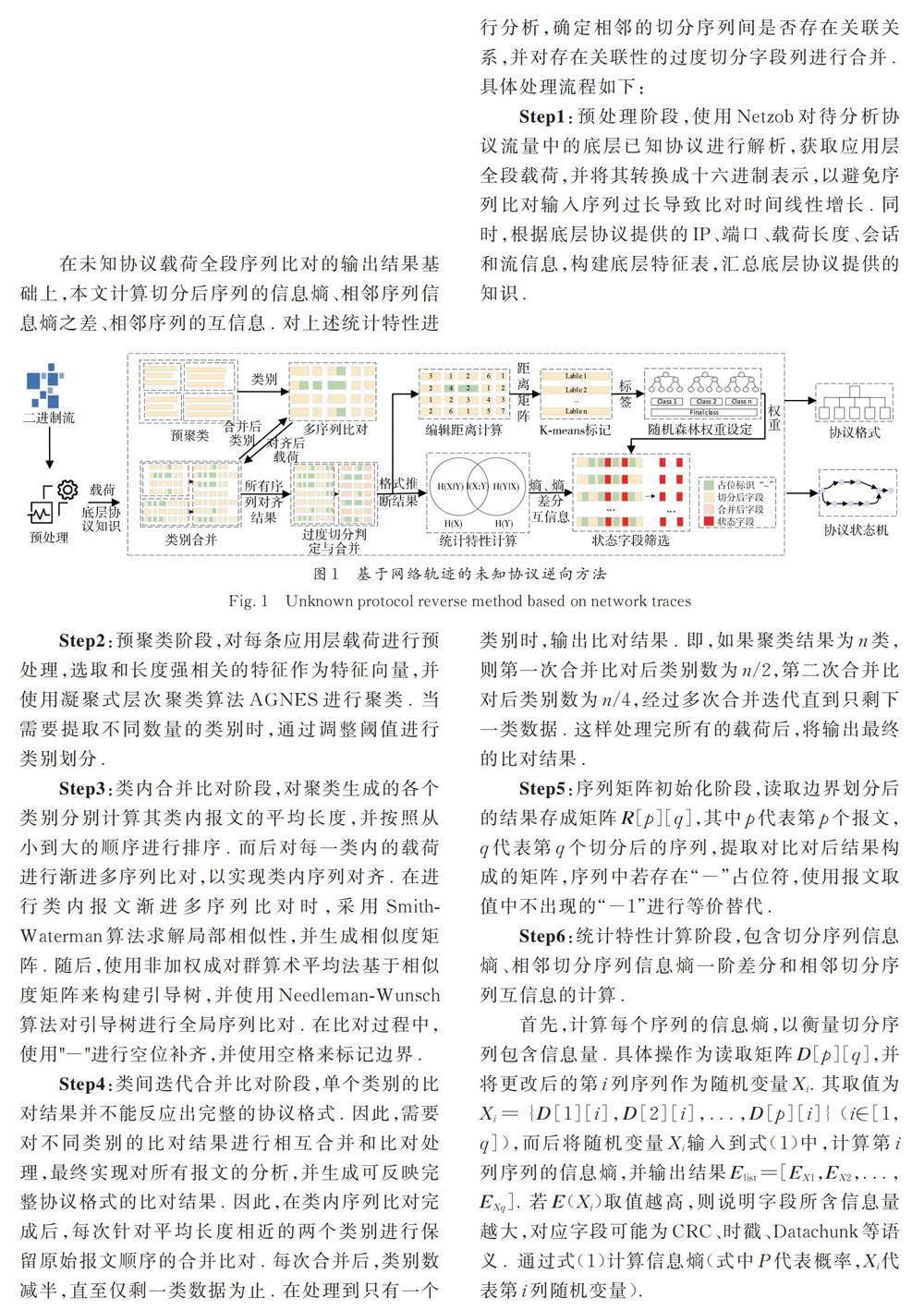
本文结合流量时空特性进行协议逆向,对IP等承载应用层协议的底层基础协议进行解析,结合端口过滤未知协议报文,提取应用层载荷,并将底层协议解析过程中获取的IP、端口、会话和载荷长度等信息抽取成底层特征知识,进而辅助应用层未知协议判定. 之后基于层次聚类方法进行粗粒度预聚类,根据长度差异对应用层载荷进行迭代多序列比对对齐报文格式字段,结合字段的信息熵和互信息取值,对存在关联的相邻字段进行合并. 根据状态字段特性进行初步筛选,对候选字段根据编辑距离进行粗粒度划分和随机森林权重标记,结合候选字段间的熵值特性进行状态字段筛选. 核心思路如图1 所示.
3. 2 格式提取优化方法
为解决过度切分问题,本节基于报文长度和功能间的约束关系对报文长度相近的报文进行粗粒度聚类. 聚类后对每一类内的报文进行渐进多序列比对,以实现序列对齐. 随后按照类内报文平均长度对类别进行排序,依次对第n 类和第n+1类进行合并,并按照报文在原始文件中的顺序将其合并成一个新的类别. 对于不同的分类重复以上操作,直到所有类别合并对齐成为一类,从而避免了每次选取最短两类进行比对时产生的偏差叠加.
