
基于变分信息瓶颈多任务算法的多领域文本分类
2024-06-29 22:43马儀邵玉斌杜庆治龙华马迪南
四川大学学报(自然科学版) 2024年3期
马儀 邵玉斌 杜庆治 龙华 马迪南


摘要: 多领域文本分类存在领域差异和词汇差异,导致分类的准确性和泛化性低,传统方法无法取得很好的效果. 针对上述问题,本文提出基于变分信息瓶颈多任务算法的多领域文本分类方法,将任务建模为从综合特征中提取任务专属特征的分层学习表示问题. 首先基于信息瓶颈原理,将综合特征和任务专属特征之间存在的冗余信息建模为均值为零,方差为对角矩阵的加性噪声,通过重参数化方法让噪声参与模型训练;其次通过信息瓶颈的变分边界构建模型损失函数以限制模型的信息流动,从而将带有加性噪声的综合特征解耦为任务专属特征;最后通过解码器中的分类器处理任务专属特征得到文本分类结果. 实验表明,该模型在FDU-MTL 多领域文本分类数据集上的平均分类准确率达到92. 17%,较多个对比模型有明显提升,且该模型具有更好的可解释性.
关键词: 信息瓶颈; 多任务模型; 多领域; 变分边界; 可解释性
中图分类号: TP393 文献标志码: A DOI: 10. 19907/j. 0490-6756. 2024. 032004
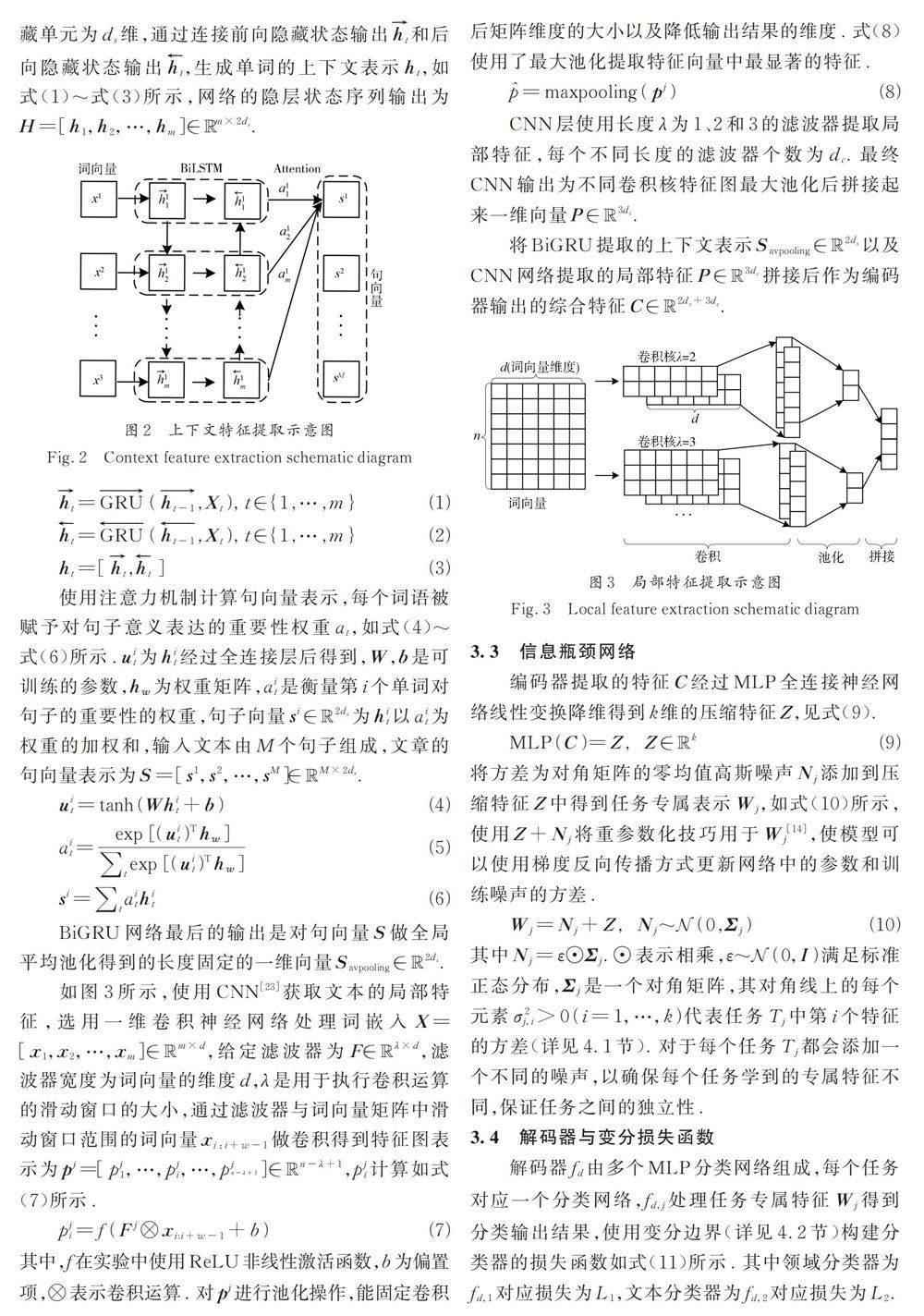
1 引言
多领域文本分类训练数据的多样性一定程度上能缓解标签资源不足问题[1-3],更贴近现实场景. 但它存在两个主要问题:首先,由于数据的稀疏性,导致部分领域标签资源缺乏或没有标签,严重影响模型泛化[4,5];其次,不同领域的文本数据存在领域差异和词汇差异,包括语言表达方式、领域专有的术语和词汇、文本主题等[1,4-6]. 如多领域情感分类中,许多词有多种定义,两个句子中相同的单词可以表达不同的含义,即使是只有一个定义的单词,也可以根据上下文表达不同的情感. 如,“容易”或“预期”可以在婴儿产品评论中传递积极情绪,而在电影或书评中传达的是负面情绪.这些问题导致多领域文本分类的准确性和泛化性难以提升.
目前构建多领域文本分类模型时,域适应[7]、对抗性学习[3,5,8]、共享私有范式[3,9]和熵最小化技术[10]是优化模型的主要方向. 域适应将数据分为源域和目标域,利用源域丰富的训练数据学到的特征对另一个资源较低的目标领域进行分类,然而域适应的方法难以训练一个或多个域的有效分类器,并且有些域没有标记数据,难以提升模型泛化性. 对抗性学习通过减少领域之间的数据分布差异进行特征对齐,并学习领域不变特征来提高模型的泛化性.但域间文本数据分布差异很大,目前的方法不能保证域完全对齐[3,5,8],导致预测时模型不能区分不同的领域,难以提升预测准确性. 共享私有范式包含共享特征提取器和领域特征提取器,然后通过两类特征提取器的结合来提升模型的准确性. 其中,共享特征提取器构建共享的潜在空间来学习领域不变特征,领域特征提取器提取领域特定特征. 但现有方法不能很好地平衡两类特征提取器的权重[3,9].共享特征提取器过于侧重域间的相似性,忽略域间的差异性;而领域特定特征提取器则过度关注单一领域,忽略通用特征,导致模型将不同类别的样本错误地匹配在一起,影响模型整体性能. 熵最小化技术用于正则化多领域文本分类模型,降低模型对未标记数据预测的不确定性. 但未加约束的熵最小化技术使模型在未标记数据上的表现过于自信,错误地确定某些样本的标签,将未标记数据中相似但不同的样本归为同一类别,导致模型的准确性下降[10].
本文提出了一种基于变分信息瓶颈多任务算法的多领域文本分类方法(Variational InformationBottleneck and Multi-Task Multi-Domain Text ClassificationMethod,VIBM)来缓解上面的问题.VIBM 通过构建多任务网络的同时实现领域分类和文本分类任务. VIBM 为编码器、信息瓶颈和包含多个任务分类器的解码器的分层结构. 基于信息瓶颈降低输入数据的复杂性,同时保留任务所需的最重要信息的思想,将问题重构为:从编码器提取的综合特征中获取输入到解码器的任务专属特征的分层学习表示问题,将综合特征与任务专属特征之间的冗余信息视为加性噪声. 噪声的构建与信息瓶颈的优化目标有关,通过理论推导提高了模型的解释性. 具体来说,首先使用BiGRU 和CNN 构建编码器来提取文本的全局和局部特征,融合全局和局部特征得到综合特征;其次信息瓶颈网络对综合特征进行压缩,以降低数据复杂度,压缩后的综合特征添加一个均值为零、协方差矩阵为对角矩阵的高斯噪声进行重参数化,得到不同任务的专属特征,使噪声的方差可以参与训练;最后将任务的专属特征传入解码器中得到最终的分类结果,将信息瓶颈的优化目标的变分边界表示扩展到多任务网络中得到变分损失函数,利用变分损失函数更新网络参数和训练噪声来解开综合特征的纠缠,获得最佳的专属特征. 该模型不需要任务之间具有相关性[11],VIBM 的编码器的设计能提取出更丰富的特征,多任务网络的结构能更好地利用域间数据的差异性和相似性,提高数据的利用效率,利用信息瓶颈网络得到任务专属特征避免共享私有范式下的特征权衡问题,并且通过最小化信息瓶颈约束下的变分损失提高了模型泛化到未标记数据领域的能力[12].实验结果表明,该方法能够有效提升多领域文本分类任务的准确性和泛化性,且更具有可解释性.
2 相关工作
2. 1 信息瓶颈
信息瓶颈原理是信息论率失真理论的拓展,其基本思想是仅保留对于任务最重要的信息,并最大限度地压缩输入数据的复杂性,以实现学习的最有效性[13-15]. Alemi 等[16]提出了一种信息瓶颈的变分近似,应用在深度学习模型中提高其泛化性和鲁棒性. 自然语言处理中变分信息瓶颈用来实现快速非线性压缩词嵌入,让标签序列在相同的标签粒度级别上被更准确地解析[17]. West 等人[18]引入信息瓶颈层,使模型能够压缩输入的原始句子信息的同时又能够保留与句子中最重要的信息相关的部分来实现无监督文本摘要. Mahabadi 等人[19]使用变分信息瓶颈来对大规模语言模型的微调,改进低资源场景大规模语言学习模型的效果,在文本分类等任务上取得较好的效果. Chen 等人[20]提出变分词掩码方法使用信息瓶颈对词嵌入进行约束,自动学习任务专属的重要词,提高了文本分类模型的可解释性.
