
一种用于DBMS 模糊测试的自适应变异策略
2024-06-29 22:43:18问欣方勇贾鹏范希明
四川大学学报(自然科学版) 2024年3期
问欣 方勇 贾鹏 范希明
摘 要: 数据库管理系统(DBMS)被广泛应用于各个领域,并在其中发挥着不可替代的作用. 因此发现DBMS 中的bug,防止其被攻击者利用至关重要. 为了检测DBMS 中潜藏的bug,研究者提出了DBMS 模糊测试技术. 使用这项技术,研究者成功在DBMS 中发现了大量bug. 然而现有的DBMS 模糊测试技术依然存在一定的局限性. 现有的技术在对SQL 语句的抽象语法树(AST)进行变异时,没有根据不同节点和变异结果的重要性分配计算资源,而是采取了一种平均分配的策略,这降低了测试的效率. 为了解决这个问题,本文提出了一种使用基于语法信息的变异方法的自适应变异策略. 这种变异策略能够自动计算不同节点和变异结果的重要性,并根据重要性为更重要的操作分配更多的计算资源. 基于语法信息的变异方法可以将变异操作与变异结果直接关联,消除了变异操作和变异结果之间的偏差. 我们在一种新的DBMS 模糊测试工具Pinecone 中实现了这种变异策略,并使用Pinecone 对两款广泛使用的DBMS 进行测试. 实验证明,与Squirrel 相比,Pinecone 在MariaDB 和MySQL 中发现的路径数分别提升了4. 52% 和19. 4%,位图覆盖率分别提升了15% 和13. 8%,发现的Bug 数量提升了26. 7% 和75%,这证明了本文提出的方法可以有效提升模糊测试的效率.
关键词: DBMS 模糊测试; Squirrel; 语法信息; 自适应变异策略
中图分类号: TP391. 1 文献标志码: A DOI: 10. 19907/j. 0490-6756. 2024. 032006
1 引言
数据库管理系统(Database Management System,DBMS)是一种操纵和管理数据库的大型软件,被广泛应用于各种行业. 然而,像其他复杂系统一样,DBMS 内往往存在许多未被发现的bug. 这些bug 可能会被攻击者利用,从而造成严重的后果.
模糊测试是一种被广泛使用的自动化软件测试技术. 其基本过程是使用生成或变异的方法得到大量新测试用例,再将这些测试用例输入程序,找出能使程序出现异常的测试用例,最后通过这些测试用例找到程序中存在的bug. AFL[1]是最著名的模糊测试工具,其中使用的很多方法和设计理念被后人沿用,有许多先进的模糊测试工具是基于AFL 实现的,例如AFLGO[2]、AFLFast[3]、AFL++[4]等.
近年来,随着模糊测试技术的发展,模糊测试开始被用于DBMS 的测试. 最早的DBMS 模糊测试技术是黑盒的,其中代表性的工具是SQLsmith[5]. 使用SQLsmith,研究者们在多个DBMS中发现了100 多个bug[6]. 之后,出现了灰盒DBMS模糊测试技术. 最著名的开源灰盒工具是Squirrel[7],该工具基于AFL 实现,并在AFL 的基础上增加了基于抽象语法树(AST)的变异方法和语义引导的实例化方法,解决了AFL 难以产生语法正确且语义正确的SQL 语句的问题. 使用Squirrel,研究者在MariaDB、MySQL、SQLite 等著名DBMS 中发现了几十个bug. 之后,研究者们提出了越来越多的灰盒DBMS 模糊测试工具,包括RATEL[8]、SQLRight[9]、Griffin[10]、DynSQL[11]等.但是这些工具没有开源,因此Squirrel 仍是最著名的开源灰盒DBMS 模糊测试工具.
虽然Squirrel 取得了很好的效果,但仍然存在一些不可忽视的问题. 例如,变异策略问题. 近年来,研究者们提出了很多改善模糊测试效率的方法. 其中一项重要的研究是自适应变异策略[12-17].然而,人们对DBMS 模糊测试领域自适应变异策略的研究较少. Squirrel 在进行变异时,每种变异节点和变异操作被选择的机会是一样的. 然而,在AST 中,每种变异节点的重要性是不一样的,对于不同节点类型,不同变异结果的重要性也是不一样的. 因此,不同变异节点和变异结果带来的效果也是不同的. 如果选择了不重要的变异节点和变异结果,则会导致计算资源的浪费,从而降低模糊测试的效率. 本文提出了一种针对DBMS 模糊测试的自适应变异策略. 该策略会根据代码覆盖率信息自动判断不同变异节点和变异结果的重要性,使计算资源倾向于更重要的节点类型和变异结果,提升测试的效率.
2 背景
2. 1 Squirrel 简介
Squirrel 是一种DBMS 模糊测试工具,主要用于检测DBMS 中存在的内存bug. Squirrel 是基于AFL 实现的,修改了AFL 中的变异方法,使得在变异时能够确保SQL 语句语法正确. 同时,为了确保生成的SQL 语句是语义正确的,Squirrel 还添加了实例化模块,该模块会推断SQL 语句中数据库对象标识符之间的依赖关系,并基于依赖关系为标识符赋予正确的值.
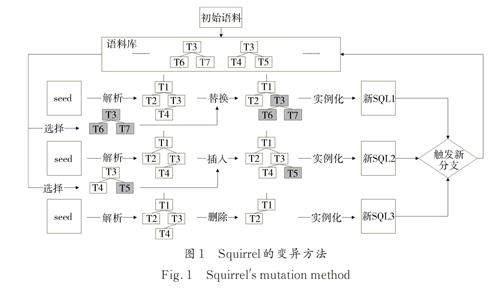
Squirrel 的变异方法首先会将SQL 语句解析为AST,之后对AST 中每个节点进行替换、插入和删除等3 种变异操作(图1). 其中,替换操作会根据变异节点子节点的类型从语料库中随机选择语料,替换变异节点的子树;插入操作会根据变异节点的类型从语料库中随机选择语料,将语料的子树插入变异节点的空白子树;删除操作会随机删除变异节点的子树. 最后,通过实例化就可以得到新的SQL 语句. 如果新语句使代码覆盖率增加,则将新语句的AST 加入语料库中.
2. 2 Squirrel 变异策略的局限性
Squirrel 使用了一种最基本的变异策略,即无差别的对待每种变异节点和变异操作. 这种变异策略假定了AST 中每种变异节点和变异操作的重要性是一样的. 但是,这种方法是存在明显缺陷的,因为不同种类节点的重要性是不同的.
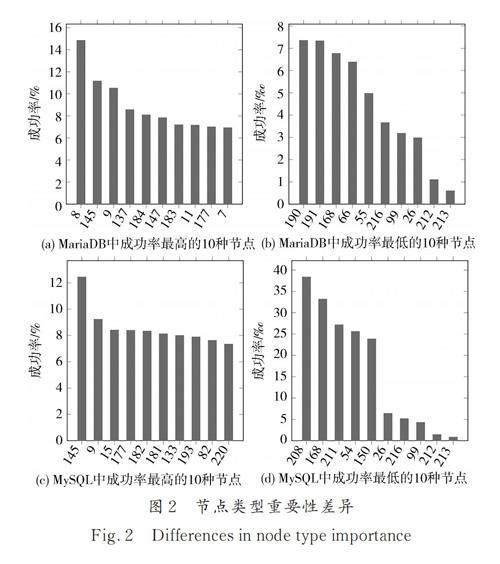
为证明以上观点,我们在MySQL 和Maria DB上进行了实验,来证明不同种类节点的重要性是不同的(如图2). 我们在MariaDB 和MySQL 中进行了12 h 测试,并记录了每种类型节点变异后触发新分支的概率. 图2a 和2b 展示了MariaDB 中成功率最高和最低的10 种节点. 其中,8 号类型节点在变异后,触发新分支的概率高达14. 85%,而213号节点在变异后触发新分支的概率仅有0. 6? .图2a 和2c 展示了MariaDB 和MySQL 中成功率最高的10 种节点,可以看出,在这两种DBMS 中,成功率最高的节点类型存在一定差异. 这说明在同一DBMS 中,不同类型节点在进行变异后,触发新分支的概率有很大差异. 在不同DBMS 中,不同类型节点触发新分支的概率也不一致.
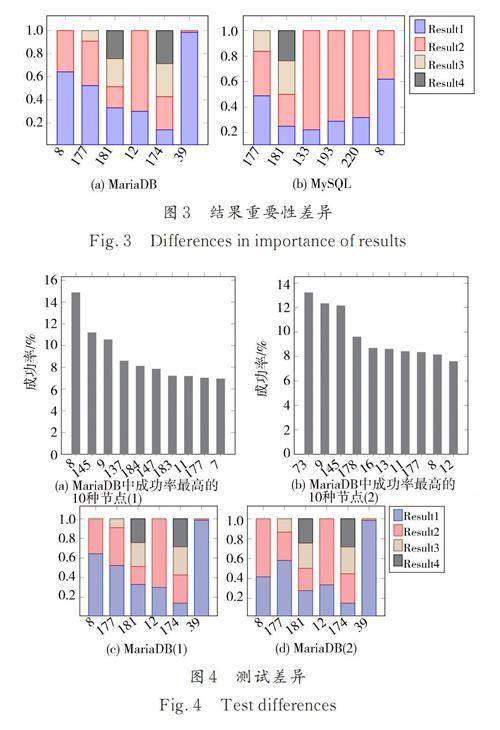
在同一类型节点中,不同变异结果的重要性也是不同的. 我们在MariaDB 和MySQL 中进行了12 h 测试,并记录了每种节点类型下不同变异结果触发新分支的概率(如图3). 我们选择了具有多种变异结果且成功率最高的6 种节点,展示同一种节点类型中不同变异结果重要性的差异. 这里的变异结果是指AST 中,该类型节点的合法结构. 有一些节点具有多种合法结构,这些结构的重要性是不同的. 在对这种节点进行变异时,某些结构更容易触发新分支. 图3 中resulti代表一种类型的节点中第i 种变异结果. 不同节点间的resulti 代表不同结果. 为了更直观的理解不同结果重要性的差异,我们对每种节点不同变异结果触发新分支的概率进行了归一化处理. 可以看出,对于一种类型的节点,不同变异结果的重要性是不一样的.例如,在39 号类型节点中,一共只有两种变异结果,变异结果1 触发新分支的概率要远高于结果2触发新分支的概率. 这说明结果1 的重要性高于结果2,在对39 号类型节点进行变异时,结果1 更容易触发新分支.
除此之外,即使在对同一数据库的不同测试中,变异节点和变异结果的重要性也是不同的. 如图4 所示,我们在MariaDB 中进行了两次12 h 测试. 可以看出,两次实验中,不同节点类型的重要性和每种节点不同结果的重要性存在一定差异.事实上,两次测试中,成功率最高的前30 个节点中有24 个是相同的,但是其排名和成功率存在一定差异. 对于同一类型的节点,每种结果的成功率也存在差异.
根据以上分析,我们可以得出结论,不同种类变异节点的重要性是不一样的. 对于同一种节点,不同变异结果的重要性也是不一样的. 在测试时,应当为更重要的节点和结果分配更多的计算资源. 而那些不重要的的节点和结果应当获得更少的计算资源. 然而,Squirrel 的变异策略无法实现这一点. 因此,需要一种更有效的变异策略.
3 方法概述
现有的变异策略无法根据变异节点和变异结果的重要性分配计算资源,这会导致测试效率降低. 为了解决这个问题,本文提出了一种使用基于语法信息的变异方法的自适应变异方法. 首先,本文提出了一种基于语义的变异方法. 这种变异方法兼容了Squirrel 使用3 种变异方法,同时能够在变异操作和变异结果之间建立直接的对应关系.之后,基于这种变异方法,本文提出了一种自适应变异策略. 这种策略能够在测试中动态调整每个节点和每种变异操作被选择的机会,为那些更重要的节点和操作分配更多的计算资源.
3. 1 基于语法信息的变异
在第2 节中,本文展示了不同的变异结果具有不同的重要性. 然而,Squirrel 使用的3 种变异操作与变异结果之间不存在对应关系. 在Squirrel 中,替换操作的变异结果由变异前的AST 结构决定;插入操作的变异结果由变异前的AST 结构和选择的语料决定;删除操作的变异结果是确定的,但是该操作很容易产生错误的变异结果. 由于Squirrel的变异操作与变异结果之间缺乏联系,因此即使调整这3 种变异操作被选择的机会,也不能有效地增加测试的效率.
为解决这个问题,本文提出一种基于语法信息的变异方法. 由于解析SQL 时需要使用SQL 的语法信息,因此语法信息与AST 之间存在一定的对应关系(如图5). SQL 是由上下文无关文法定义的语言,图5 左侧是其语法信息的一部分;右侧是这部分语法信息对应的AST. 可以看到,AST 中的节点对应了语法信息中的符号,一个节点的合法结构由语法信息中该非终结符的生成式决定.图5 中c_tab 非终结符一共有2 条生成式,那么c_tab 节点的合法结构也只有两种. 也就是说,若变异后AST 语法是正确的,那么只可能是这两种结果中的一个. 其他变异结果,如第3 种情况,由于不存在这种生成式,因此该结果是错误的. 因此,使用语法信息指导变异既可确保语法正确,又可在变异操作和变异结果之间建立直接的对应关系.
在开始测试前,会先从文件中提取语法信息,经过处理后用于指导变异. 具体处理方法如图6所示. 首先是从文件中提取语法信息. 这里的文件一般指bison 文件,由于bison 文件中除了语法信息外,还有其他代码,所以在处理时需要剔除多余代码. 获取到语法信息包括所有非终结符及其对应的生成式. 之后,对语法信息进行格式转换. 转换后的语法信息中,每条生成式具有特定格式. 这样做是为了统一生成式的格式,使得AST 中不同种类的节点具有同样的结构. 为了方便起见,这里使用了与Squirrel 中AST 一致的结构. 最后对语法信息中的终结符和非终结符进行编码,转换为数字形式.
算法1 描述了这种变异方法. 算法以选择进行变异的AST 节点和选择的生成式信息作为输入,输出新AST 的根节点. 第3 行的checkNode 函数会检查root 节点左右子节点的情况. 如果root节点左右子节点都存在,那么变异时有概率保留root 中原有的子节点. 第4~13 行对节点进行变异. 如果选择变异,则根据生成式信息中记录的节点类型,在corpos 中随机选择对应类型的节点索引. 之后对该节点对应的AST 进行深拷贝. 否则对root 的左右子树进行深拷贝. 第14 行是对当前节点的终结符部分进行修改,由于终结符以数字形式存在,因此可以直接赋值. Mutate 函数生成的新AST 是完整AST 中被修改的部分. 将这些新AST 连接到完整AST 的操作由其他函数完成,这部分与本文的方法无关,因此省略.
该方法完全取代了Squirrel 中使用的替换、插入和删除等3 种变异操作,并且在变异操作和变异结果之间建立直接的对应关系. 这样一来,就可以通过调整每种变异操作被选择的机会来调整每种变异结果出现的机会,从而为更重要的变异结果分配更多计算资源.
3. 2 自适应变异策略
经实验证明,不同节点类型和变异结果的重要性是不同的. 变异策略应根据不同节点类型和变异操作的重要程度,动态调整每种节点类型和变异操作被选择的机会,为更重要的节点类型和变异操作分配更多计算资源. 因此,本文提出了一种新的变异策略. 该变异策略将变异节点和变异操作的选择问题表示为一个多臂老虎机问题,假设有k 台老虎机,每台老虎机都对应一个奖励概率分布,其目标是在不知道奖励概率分布的情况下操作T 次老虎机后,能够取得累计最大奖励.
在本文提出的方法中,使用每种变异节点和变异操作被选择后成功触发新分支的次数和被选择的总次数的比值作为奖励. 因为在AST 中,不同种类节点出现的次数不同,有些类型的节点出现次数较多. 因此,以比值作为奖励更能反映不同变异节点和变异操作的重要性.
由于节点种类众多,而每种节点可能会有多种操作,同时考虑节点类型和变异操作会导致老虎机数量过多. DBMS 模糊测试的运行速度普遍较慢,过多的老虎机会导致在有限的时间内探索不足. 因此,本文分别考虑变异节点和变异操作的选择. 在求解多臂老虎机问题时,本文使用ε-贪心算法,这是一种在处理多臂老虎机问题时常用的算法. 这种算法在每次选择老虎机时,以ε 的概率随机选择老虎机,以1-ε 的概率选择期望奖励最大的老虎机. 其中,ε 会随时间逐步减少. 在使用时,本文对该算法进行了一定的修改,使其更适用于实际情况.
算法2 描述了本文的变异节点选择算法. 6~13 行的循环遍历AST. 对于AST 中每个节点,将其根据节点类型记录到topRewards 对象中. 该对象还维护一个列表,里面记录了AST 中奖励值最高的10 种节点类型,每次加入新节点时对该列表进行更新. 之后,在14~21 行,进入位置选择阶段. 对于AST 中每个节点,以ε 的概率选择当前节点进行. 在这里,算法使用1/T 作为ε 的值,T 为测试进行的时间(单位:h,向上取整). 以1-ε 的概率使用getRandomTopNode 方法从当前奖励最高的10 个节点类型中,随机选择一种节点类型,再随机选择一个该类型的节点进行变异. 将AST 子树连接到完整AST 的操作由其他函数完成.
选择了要进行变异的节点后,基于节点的上下文信息选择要进行的变异操作. 在这里,算法考虑了节点的上下文信息. 这是因为位于不同上下文环境下的节点可能代表不同的语义. 例如SELECT 语句单独存在时表示查询语句,但是在FROM 子句中表示子查询. 因此需要对每种上下文环境单独考虑. 另一个原因是每个节点可选的变异操作数量较少. 即使考虑了上下文信息,也不会出现探索不足的问题.
算法使用的上下文信息可以使用一个五元组(stmt,inSubquery,clause,pType,pInfo)描述. 其中,stmt 表示该节点所在的语句类型. 例如用于区分SELECT 语句和UPDATE 语句中的FROM 子句. inSubquery 用于标记该节点是否处于子查询中. clause 表示该节点处于什么子句中. 主要用来区分不同子句中的表达式. pType 表示该节点父节点的节点类型. pInfo 表示该节点父节点对应的生成式信息.
算法3 描述了本文的变异操作选择算法. 第3行使用getContext 函数获取root 节点的上下文信息. 在第4 行,根据该节点的类型和节点上下文信息获取该类型节点的生成式信息. 5~10 行的循环选择变异操作对root 进行变异. 变异的次数由使用的能量调度策略决定. 为了与Squirrel 对比,将N 设置为2. 每次变异有ε 的概率随机选择一条生成式信息进行变异,有1-ε 的概率选择奖励最高的生成式信息进行变异. 这里的ε 与变异节点选择部分的ε 相同.
4 实验及分析
本文基于Squirrel 实现了一个灰盒DBMS 模糊测试工具Pinecone,并与Squirrel 进行了对比.实验选取了MySQL 和MariaDB 作为目标,这两个DBMS 在现实世界中得到了广泛运用. 实验在一台使用了 Ubuntu 20. 04操作系统、Inte(l R) Xeon(R) CPU E3-1231 v3 @ 3. 40 GHz 3. 39 GHz 处理器和32 GB 内存的计算机上进行. 实验中,bitmap被设置为256 KB,并使用AFL 自带的afl-clangfast和afl-clang-fast++ 对MySQL 和MariaDB 进行插桩,插桩比例为5%. 实验中使用DBMS 的最新版本. 其中,MariaDB 的版本是11. 3. 0,MySQL的版本是8. 0. 34. 在实验中,每次同时进行两个测试,运行12 h,并重复3 次,结果取平均值.
4. 1 路径数和位图覆盖率对比
如图7 所示,在路径数和位图覆盖率方面,Pinecone 都取得了优势. 其中,在MariaDB 中,Pinecone 发现的路径数仅比Squirrel 多4. 52%. 但是在位图覆盖率方面,Pinecone 比Squirrel 高出15%. 在MySQL 中,Pinecone 发现的路径数比Squirrel 多19. 4%,位图覆盖率高出13. 8%. 实验结果说明,与Squirrel 相比,Pinecone 能够在相同时间内探索更多分支.
4. 2 发现bug 的数量
图8 展示了两种工具在测试中发现的bug 数量. 我们对发现的bug 进行了手动检查,以去除重复的bug. 我们同时使用了ASan[18]和GDB[19]去除重复bug. 对于会引发崩溃的bug,我们利用崩溃时的堆栈信息判断是否是重复bug. 对于没有引发崩溃,但是引发ASan 报错的bug,我们利用出现错误的代码行位置判断是否是重复bug. 实验结果显示,在MariaDB 中,Pinecone 发现的bug 数量比Squirrel 多26. 7%;在MySQL 中,Pinecone 发现的bug 数量比Squirrel 多75%. 这说明在发现bug 的能力方面,Pinecone 要优于Squirrel.
5 结论
本文使用实验统计数据证明了目前DBMS 模糊测试工具变异策略中存在的局限性,并且提出了一种自适应变异策略来解决这个问题. 这种变异策略能够自动计算不同变异节点和变异操作的重要性,并根据重要性调整不同变异节点和变异操作被选择的概率,从而为更重要的变异节点和变异操作分配更多计算资源. 本文在一种新的DBMS 模糊测试工具Pinecone 中实现了这种变异策略,并使用Pinecone 对MySQL 和MariaDB 这两款广泛使用的DBMS 进行测试. 实验表明,与当前先进的DBMS 模糊测试工具Squirrel 相比,Pinecone能够发现更多执行路径和程序bug. 这表明本文提出的自适应变异策略能够有效提升DBMS 模糊测试的效率.
参考文献:
[1] Zalewski. American fuzzy lop [EB/OL].[2023-12-
04]. https://github. com/google/AFL.
[2] B?hme M,Pham V T,Nguyen M D, et al. Directed
greybox fuzzing [C]//Proceedings of the 2017 ACM
SIGSAC Conference on Computer and Communications
Security. Dallas Texas USA: Association for
Computing Machinery, 2017:2329.
[3] B?hme M,Pham V T,Roychoudhury A. Coveragebased
greybox fuzzing as markov chain [C]//Proceedings
of the 2016 ACM SIGSAC Conference on
Computer and Communications Security. Vienna
Austria: Association for Computing Machinery,
2016:1032.
[4] Fioraldi A,Maier D,Ei?feldt H, et al. AFL++ :
Combining incremental steps of fuzzing research[ C]//
Proceedings of the 14th USENIX Workshop on Offensive
Technologies (WOOT20). Boston,MA:
USENIX Association, 2020.
[5] Seltenreich A,Tang B,Mullender S. SQLSmith[ EB/
OL].[2023-12-04]. https://github. com/anse1/sqlsmith.
[6] Seltenreich A,Tang B,Mullender S. SQLSmith bug
hunting [EB/OL]. [2023-12-04]. https://github.
com/anse1/sqlsmith/wiki#score-list.
[7] Zhong R,Chen Y,Hu H, et al. Squirrel:Testing database
management systems with language validity
and coverage feedback [C]//Proceedings of the 2020
ACM SIGSAC Conference on Computer and Com ‐
munications Security. Virtual Event USA:Association
for Computing Machinery, 2020: 955.
[8] Wang M,Wu Z,Xu X, et al. Industry practice of
coverage-guided enterprise-level DBMS fuzzing[ C]//
Proceedings of the 43rd International Conference on
Software Engineering:Software Engineering in Practice
(ICSE-SEIP). Virtual Event,Spain:IEEE Press,
2021: 328.
[9] Liang Y,Liu S,Hu H. Detecting logical bugs of
DBMS with coverage-based guidance [C]//Proceedings
of the 31st USENIX Security Symposium
(USENIX Security 22). Boston, MA:USENIX Association,
2022: 4309.
[10] Fu J,Liang J,Wu Z, et al. Griffin:Grammar-free
DBMS fuzzing[C]//Proceedings of the Conference
on Automated Software Engineering (ASE22).
MI, Rochester,USA:Association for Computing
Machinery, 2022: 1.
[11] Jiang Z M,Bai J J,Su Z. DynSQL:Stateful fuzzing
for database management systems with complex and
valid SQL query generation [C]//Proceedings of
USENIX Security Symposium( USENIX Security).
Anaheim, CA: USENIX Association, 2023: 4949.
[12] Lyu C, Ji S, Zhang C, et al. MOPT:Optimized mutation
scheduling for fuzzers [C]//Proceedings of the
28th USENIX Security Symposium( USENIX Security
19). Santa Clara,CA:USENIX Association,
2019: 1949.
[13] Karamcheti S,Mann G,Rosenberg D. Adaptive greybox
fuzz-testing with thompson sampling [C]//Proceedings
of the 11th ACM Workshop on Artificial Intelligence
and Security. Toronto, Canada:Association
for Computing Machinery, 2018: 37.
[14] Wang X,Hu C,Ma R, et al. CMFuzz:Contextaware
adaptive mutation for fuzzers [J]. Empirical
Software Engineering, 2021, 26: 1.
[15] Lemieux C, Sen K. Fairfuzz:A targeted mutation
strategy for increasing greybox fuzz testing coverage
[ C]//Proceedings of the 33rd ACM/IEEE International
Conference on Automated Software Engineering.
Montpellier, France:Association for Computing
Machinery, 2018: 475.
[16] Cha S K,Woo M,Brumley D. Program-adaptive mutational
fuzzing [C]//Proceedings of the 2015 IEEE
Symposium on Security and Privacy. San Jose,CA,
USA: IEEE, 2015: 725.
[17] Yue T,Tang Y,Yu B, et al. Learnafl:Greybox fuzzing
with knowledge enhancement [J]. IEEE Access,
2019, 7: 117029.
[18] Google. AddressSanitizer [EB/OL]. [2023-12-04].
https://github. com/google/sanitizers/wiki/Address‐
Sanitizer.
[19] Foundation F S. GDB:The GNU project debugger
[EB/OL]. [2023-12-04]. http://www. sourceware.
org/gdb/.
(责任编辑: 伍少梅)
