
基于特征融合的加密Tor 流量检测方法
2024-06-29 02:43:46李常亮王俊峰方智阳孙贺
四川大学学报(自然科学版) 2024年3期
李常亮 王俊峰 方智阳 孙贺


摘 要: 匿名网络是目前保护个人隐私的常用工具,结合混淆网桥组件后具备极强的隐私保护能力;信息对抗中的持续博弈使得在匿名网络中运用加密代理成为数据安全敏感用户实现隐私保护的主要手段. 匿名网络和加密代理双重保护让流量检测面临以下两个方面的挑战和问题:(1) 代理汇聚:经过加密代理之后的流量呈现单流特性,导致基于完整数据流的流量检测方法失效;(2) 特征模糊:数据包混淆机制使得数据流特征稀疏化,导致基于低阶统计特征的方法效果减弱. 本文提出了一种名为SETTDM 的流量检测方法来应对上述两种挑战. 具体而言,针对代理汇聚问题,采用基于滑动窗口的方式拆分数据子流,使得SETTDM 方法能应用于因代理产生的聚合数据流并尽可能地保留了原始数据流的特征空间;针对特征模糊问题,提出基于特征融合的特征提取方法:多角度的统计时序特征结合ResNet 提取的加密空间特征. 在实验中采集了真实的二次加密Tor 流量、加密背景流量和未加密背景流量,并融合公开加密流量数据集ISCXVPN2016 组成实验数据集;经测试,SETTDM 方法可以达到99. 78% 的精确率,相比对比方法有着2. 30%~9. 29% 的提升.
关键词: 加密流量; 匿名网络流量; 隐私保护; 特征融合
中图分类号: TP393. 3 文献标志码: A DOI: 10. 19907/j. 0490-6756. 2024. 032001
1 引言
随着网络技术的蓬勃发展,互联网承载了日常生活中的大量信息传输[1]. 对隐私敏感的用户倾向于使用隐私增强的技术来隐蔽自己的在线活动轨迹. 匿名网络[2]是目前最受欢迎的隐私增强技术[3],一方面提供针对用户的隐私保护方案,保护服务使用者的网络行为隐私;另一方面提供针对隐藏服务的隐私保护方案,帮助隐匿隐藏服务提供方的出站流量,使得隐藏服务难以被追踪溯源.后者常被一些不法分子用于非法活动,对网络空间安全造成了极大的危害[4],站在监控匿名网络中非法行为的角度,对匿名网络及其扩展组件的流量进行检测都具有重要意义.
匿名网络是基于互联网之上建立的隐蔽网络,旨在为网络用户提供了全方位的隐私保障. 第二代洋葱网络简称Tor[5],是目前应用最广泛的匿名网络,其融合了多级中继路由、节点加密以及动态引入节点等设计思想,同时具备对服务使用者和服务提供者的隐私保护能力. 随着信息对抗中的持续博弈,Tor 项目组也在为抵御新型流量检测方法研发新的技术,混淆网桥就是其中一种策略.混淆是指采用更难以被检测到的流量混淆技术来给匿名网络流量加壳,网桥则是指将采用了新的混淆技术的节点作为匿名网络引入节点,以取代原来的普通入口节点. Obfs4[6]是Obfs 网桥迭代更新到第四代的版本,其引入了椭圆加密算法对流量载荷进行加密;使用数据包随机填充方式伪装普通流量以抵御基于数据包长度的流量检测;在握手阶段采用基于Ntor[7]的握手机制以防范中间人攻击. 综合来说,Obfs4 采用了多种流量混淆思路,为用户提供了匿名性和安全性保障.
加密代理和匿名网络有着相似的思想,都是通过中继节点来实现用户与目标网络服务之间的数据传输. 不过,他们的部署方式和使用场景略有不同. 加密代理通常是由用户自行部署的私人节点,用于加密数据并转发到目标节点,主要用于绕过网络封锁、保护个人隐私等目的. 而匿名网络则是由社区共同维护的公共节点组成,主要用于隐藏用户的真实身份、保护用户隐私等目的. 因此,匿名网络的节点数量通常要比加密代理多得多,节点的流量吞吐量也更大,同时也更容易被监管设备加入黑名单. 使用常见匿名网络直接访问Google 或YouTube 通常会被禁止访问. 但是,可以通过在匿名网络出口节点之后部署个人加密代理来解决这个问题. 这样Google 或YouTube 就不会因为判定出匿名网络的公用出口节点发送大量数据包而终止我们的网络请求. 同时,使用加密代理也可以保护我们的隐私.
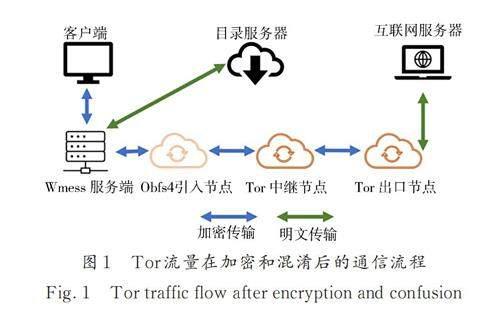
对于匿名网络流量和加密代理的融合场景,本文选择引入Obfs4 混淆网桥后的Tor 网络和由Google 开源的Vmess 加密代理协议来进行介绍:Tor 流量在本地由Tor 浏览器生成,经本地Obfs4网桥混淆加壳后转发至本地加密代理,由本地加密代理加壳后转发至远程加密代理服务器,经远程加密代理服务器解密后与Tor 入口节点(Obfs4服务节点)进行通信建立连接,由此接入Tor 网络. 整体流程图如图 1.
面对同时隐藏在匿名网络混淆增强技术和加密代理下的网络流量,流量检测需要克服以下难点:(1) 代理汇聚:经过加密代理之后的流量呈现单流特性,基于完整数据流的流量检测方法失效;(2) 特征模糊:数据包混淆机制使得数据流特征稀疏化,导致基于低阶统计特征的方法效果减弱.
在流量检测领域,现有技术方案有以下3 种:(1) 基于端口的检测方案[8];(2) 基于深度包特征的检测方案[9-12];(3) 基于机器学习方法的检测方案[13]. 基于端口的检测方案使用IANA[14]分配的固有端口号来检测流量中的特定协议. 基于深度包检测的方案则采用提取流量有效载荷中的特定应用程序签名的方式来检测特定协议. 基于端口的检测方法快速高效,仅需要应用协议的端口信息就能实现流量检测,但随着隐私增强技术的不断发展,动态端口技术和加密代理的出现,使得基于端口和基于深度包检测的方案逐渐失效. 基于机器学习的检测方案通常包含数据预处理、特征提取以及分类检测等多个步骤,通过合理的手动筛选流量特征和机器学习模型自动筛选特征可以极大地提高检测精度,但现实场景中大量的网络流量需要处理,使得机器学习模型必须考虑实时性和准确性之间的平衡.
针对前文所述难点,结合目前常用的流量检测方案,本文提出一种名为SETTDM(SecondaryEncrypted Tor Traffic Detection Method)的基于特征融合的二次加密Tor 流量检测方法. 该方法针对代理汇聚问题采用基于滑动窗口的方法从聚合混合多条数据的数据流中切割出子流,解决经加密代理转发后流量由多流转化为单流使得完整数据流分析失效的问题并最大限度保留了原始数据流的特征空间;而后针对特征模糊问题从多角度特征入手,先提取数据包低阶时序特征,再使用ResNet[15]自动提取数据包级别和数据流级别协同的加密空间特征,充分挖掘流量表征信息;最后将提取出的两种特征融合后使用DNN 网络完成加密代理下匿名网络流量的检测. 在实验环境采集时长为三周的数据流量融合ISCXVPN2016[16]中加密流量的数据集中进行测试,SETTDM 方法达到了99. 78% 的精确率,99. 86% 的F1-Score.
2 相关工作
匿名网络技术在不断迭代,我们将匿名网络流量检测研究依据检测源的不同划分为基于Tor自身缺陷的检测方案和基于Tor 及其相关组件通信原理的检测方案.
在基于Tor 自身缺陷的检测方案中,由于Tor本身的一些技术性漏洞,通过对Tor 网络部分外露节点IP 探测和基于统计特征的检测方式,就能达到较好的效果. Ghafir 等[17]使用爬虫定期爬取Tor入口节点IP,对网络流量使用基于IP 比对和基于黑名单过滤的方式进行Tor 流量检测,实现了对Tor 流量的高效检测. 何高峰等[18]通过分析Tor 通信机制,提出了基于报文长度的检测方案和基于TLS[19]握手指纹特征的检测方案,在CAIDA 数据集上表明,两种检测方案都能成功检测Tor 网络流量. 但随着混淆网桥等进一步增加流量隐蔽性组件的加入,流量特征难以提取,加密方式也不仅仅是TLS,上述两种基于Tor 自身显著缺陷的方法对现代Tor 网络流量都失去检测效果.
基于Tor 及其关联组件通信原理的相关研究主要是在加入混淆网桥组件的场景下,使用机器学习方法对Tor 流量进行检测. Obfs4 是使用最广泛的混淆网桥,因此本文主要讨论和Obfs4 相关的检测方案. 本文基于特征选择的不同又将目前针对Tor 网络流量分类的机器学习研究分为两种:(1) 基于完整数据流的检测方案;(2) 基于数据流中部分关键信息的检测方案.
在基于完整数据流的检测方法中,He 等[20]和Liang 等[21]均采用了一种基于随机性测试的方法,利用数据包中的数据熵值和字节分布特征判断数据加密. He 等[20]将初筛判定加密的流量进行Obfs4 握手部分数据包重组,并根据其返回的确认包时序特征与其他流量进行细粒度的区分;然后提取16 种统计特征完成最后分类,并在其实验室环境采集的数据集下达到了99% 的精确率. Wu等[22]在骨干网络中采集了大量背景流量,将Obfs4流量融合到一起形成实验数据集;对骨干网络的流量进行采样,并使用嵌套计数的布隆过滤器记录采样数据包的信息,通过特征值计算获取采样流量的特征;针对Obfs4 流量,手动提取了14 种统计特征,并利用随机森林[23]对每个特征进行了重要性计算;在Obfs4 流量仅占0. 15% 的数据集里进行验证,F1-Score 达到了90%. 基于完整数据流的检测方法的不足之处是由于代理汇聚问题的存在,难以将原始多条数据流从混淆数据流中区分开来,并由于代理汇聚进一步放大了特征模糊问题,导致此类方法的效果急剧减弱;此外,由于采用完整数据流进行检测所带来的特征提取和模型预测时间开销巨大使得此类方法实时性难以保证.
在基于部分数据包检测的方法里,Wang 等[24]在分析Obfs4 流量过程中通过计算关键访问信号得到了Obfs4 流量中具有区分度的TCP 包启动下标和窗口大小,将该窗口内的数据包用来提取表征该条流量的统计特征,在实验环境自行构造的数据集下可以达到90% 以上的准确率和召回率.此方法在特征提取上较为高效,能保证较高的实时性;但是关键信号的计算对原始数据包有着较高的依赖,如果少量的原始关键数据包丢失或未能捕获到则整条异常数据流都不能被正确检测出. Xu 等[25]采用了滑动窗口的机制来应对海量的数据包,在使用5 元组分割数据流后,继续使用滑动窗口将整流划分为子流;在子流上手工提取时间差和数据包长度等12 个特征输入随机森林和XGBoost[26]进行检测,在实验环境下,能以99% 的准确率和召回率检测出隐藏在Meek[27]、FTE[28]和Obfs4 下的Tor 流量. 但此方法的不足之处在于仅使用了低阶统计特征,而对流量双重加密后的潜在空间特征未能利用,存在进步的空间. 不论是基于关键TCP 序列还是使用滑动窗口的方式,都有效减少了检测时间. 相对而言,使用关键TCP 序列的方法,流量针对性较强,迁移能力较弱;而采用滑动窗口切分子流的方式具备更好的可复用性.
3 方法介绍
对于待测网络流量,本文采用基于五元组和滑动窗口来进行两阶段的数据流切分. 对于切分后的每条数据流,分别提取低阶统计特征和加密空间特征. 将上述两种特征融合叠加,使用DNN网络完成分类. 总体架构如图 2.
3. 1 数据流预处理
首先将原始输入流量依据五元组规则进行切分得到初始数据流,接着使用滑动窗口将初始混合数据流切分为多条子流,便于后续特征提取. 使用五元组划分数据流是为了将不同时刻属于不同流的数据包划分开来,虽然加密代理的引入会引发多流汇聚成单一流的现象,但在不同时间段内的流量由于加密代理的动态端口机制会表现出多条流的特性,因此使用五元组初步划分不同时间段的流是很有必要的. 而使用滑动窗口机制,则是为了应对在一个时间段内由加密代理导致的多流汇聚成单一流,无法对单条混合流量进行检测的问题. 通过调整滑动窗口的窗口大小和步长参数,可以保证在切分后的子流中存在能表征流量的特征.
猜你喜欢
软件导刊(2017年7期)2017-09-05 06:27:00
无线互联科技(2017年12期)2017-07-18 17:40:58
科技资讯(2017年11期)2017-06-09 18:28:13
电子技术与软件工程(2017年5期)2017-04-23 23:37:37
现代电子技术(2017年7期)2017-04-14 19:20:42
软件导刊(2016年11期)2016-12-22 22:00:22
软件导刊(2016年11期)2016-12-22 21:38:16
现代情报(2016年11期)2016-12-21 23:37:36
电子技术与软件工程(2016年20期)2016-12-21 11:21:44
企业导报(2016年20期)2016-11-05 18:53:13
