
基于对齐原型网络的小样本异常流量分类
2024-06-29 22:43林同灿葛文翰王俊峰
四川大学学报(自然科学版) 2024年3期
关键词:入侵检测
林同灿 葛文翰 王俊峰


摘 要: 异常流量分类是应对网络攻击,制定网络防御的前提. 网络流量数据量大导致分析成本高,新型异常流量标记样本数量少导致分类难度大,小样本学习能有效应对这些问题. 但目前小样本学习的方法仍然面对着复杂的模型或计算过程带来的效率低下、训练和测试样本分布偏差导致的监督崩溃问题. 本文提出了一种基于对齐的原型网络,包含内部对齐和外部对齐模块. 该方法首先基于原型网络在元学习框架下生成类别原型,其内部对齐模块通过支持集的预测损失来矫正原型在样本分布空间中的偏差,外部对齐模块通过对比原型和查询集中样本之间的相似性,将原型嵌入进查询集的分布空间,生成动态矫正后的类别原型,从而增强了原型在不同分布下的动态适应能力. 基于对齐的原型网络在没有添加额外的参数和网络结构的情况下改进了模型的训练过程,保持快速检测的同时提升了分类性能. 在CIC-FSIDS-2017 和CSE-FS-IDS-2018 数据集上的实验结果表明,本文方法的F1 值为98%,相比于其他模型提高了3. 37% ~ 4. 85%,运行时间降低了89. 12%~93. 14%. 此外,该方法具有更强的鲁棒性,在更多的异常类别和更少的支持样本的情况下仍然能保持较好的性能.
关键词: 异常流量; 入侵检测; 小样本学习
中图分类号: TP183 文献标志码: A DOI: 10. 19907/j. 0490-6756. 2024. 030001
1 引言
全球网络攻击数量不断增加,2022 年的网络攻击次数在高水平的情况下进一步增加了38%[1].随着CHATGPT 等人工智能技术的快速进步[2],黑客可以以更快、更自动化的方式产生新的、更复杂的攻击方法,开展攻击活动,导致新的异常网络流量的出现,加剧了本已具有挑战性的网络安全形势.
机器学习和深度学习方法已被广泛应用于提高异常流量检测和分类的自动化和智能化. 然而,其性能表现依赖于大量的训练样本,导致训练成本高. 在如今网络攻击进化快的时代背景下,异常流量的类型不断增多,但是能采集到的新型异常流量的标记样本数量又很少,当训练样本不足时,模型性能会显著降低[3]. 因此,如何实现有效、高效的小样本异常流量分类是重要问题.
为了解决这一问题,研究人员开始关注小样本学习[4]的方法,期望利用少量的标记数据来学习异常的模式特征,从而在减少训练成本的同时,也提升对新型异常流量的检测能力. 基于MAML 网络的小样本异常流量检测方法[5]在元训练和元测试的范式下,通过学习任务之间的通用表征,使得模型能够满足增量检测的要求,这个框架已被广泛应用,但该模型学习的通用表征,不能满足复杂的流量环境的特征捕捉. 对流量特征的捕捉尚不充分. 基于孪生网络(Siamese Network)的检测方法[6- 8]在元学习的框架下,灵活支持多种特征提取器以在新的嵌入空间对流量进行表示,然后再通过样本间的距离度量判断异常流量的类别,但是其模型复杂、运行成本高,不适用于高效实时的检测系统. 基于原型网络(Prototype Network)的检测方法[9- 11],不再逐对比较样本,而是先获得一个异常流量的类别原型表征,再把待测样本与类别原型进行比较从而实现分类. 原型网络加快了操作速度,改进了对异常流量的抽象表示,但对原型生成有更高的要求,生成的类别原型的质量是关键影响因素.
因此,现有的小样本异常流量分类仍然存在不足,主要包括:(1) 监督崩溃:网络在训练的时候会自动地挖掘各类别典型的分布特征,而忽视了特征和背景之间的关联,丢失了与其他类别相似性判断的信息. 对于网络流量而言,传输环境、报文格式,数据包上下文关系都存在着明显的相似性,但是这些信息也蕴含着不同攻击模式的特征,背景信息也就显得更加重要. 当样本数量很少的情况下,背景信息的偏差比较大,加剧了监督崩溃的现象[12].(2) 操作效率:模型需要在特征提取和运行效率之间取得平衡,深度学习叠加模块以及孪生网络多次对比的方式会导致模型参数增多、复杂性提高、运行时间加长,不能满足系统快速检测的要求.
本文提出了一种基于对齐的原型网络(AlignedPrototype Network,APN)来应对这些问题. 本模型选择以原形网络[13]为框架,充分利用其模型简单有效的优势,以满足运行效率的需要. 为了进一步解决监督崩溃的问题,APN 引入了两个无参数模块:内部对齐(Internal Alignment,IA)和外部对齐(External Alignment,EA). APN 通过加强对于已知的少量样本的利用,考虑未知的测试样本的特征分布,生成更加动态、精准的类别原型,使得模型能够持续调整新型异常流量的特征抽取和类别原型刻画. 具体而言,原形网络对同一类的样本进行聚合,生成类别原型;内部对齐模块校正原始原型,并通过测量支持样本与类原型之间的距离预测损失来获得自加权原型. 外部对齐模块则通过测试样本的特征分布,定位类别原型的相关特征,再通过预测的概率分布矩阵对相关特征进行加权,从而实现测试样本和类别原型的特征对齐,获得根据环境动态矫正而来的类别原型. 两种对齐方式都以损失函数的形式添加进网络中,在不增加网络参数的前提下,生成更具分辨性的类别原型表征. 本文重构了两个真实的流量数据集CIC-IDS-2017 和CSE-IDS-2018 来评估APN 在小样本场景中的性能表现. 实验结果表明,模型的运行时间及内存开销更小、分类性能更强,在多个任务场景下的鲁棒性更强.
2 相关工作
2. 1 异常流量分类
异常流量通常是由网络攻击产生的. 识别异常流量的类型有助于网络防御和响应. 基于机器学习和深度学习的方法已经得到应用,并取得了良好的效果[14]. 基于机器学习的方法可以自动处理网络流特征,并且易于部署. 其中,支持向量机和决策树方法是最主流的,其他常用的方法包括ANN、GA、K-NN、Na?ve Bayesian 等. 支持向量机方法使用非线性核将数据映射到高维空间,然后使用超平面将流量分类为不同的类. SVM-L[15]结合了LDA 成对公式的思想,通过优化模型来调整分类器的超参数,实验验证将基于统计规律和自然语言处理技术处理的特征输入到SVM-L 中,可以获得更高的精度. Hosseini 等[16]将SVM 和GA算法相结合,设计了用于特征选择的MGA-SVM模块,降低了计算复杂度,提高了检测速度,以满足大流量分析的需要. 决策树是一种树结构模型,将流量的特征属性作为节点,检测决策作为边缘节点,其分支反映了决策过程,有助于解释模型的决策路径和特征的影响. Ahmim 等[17]提出了一种分层入侵检测系统,该系统采用了3 个基于树的分类器. 该系统为每个分类器选择不同的特征,在每个级别执行分类任务,以实现对流量的粗略到精细分类,从而解决泛化能力有限的问题. K-NN 作为一种聚类方法,能够提供基于实例的解释,通过分析距离度量方法和最近邻居,有助于了解模型对类别和样本的理解,但是对异常点十分敏感. 朴素贝叶斯是一种基于贝叶斯定理的概率分类器,为异常流量分类提供了良好的基线. Khamaiseh等[18]将K-NN 和Naive Bayes 分类器用于SDN 中的网络流量检测,并证明了这两种方法都能够在SDN 的网络环境中检测异常流量. 张瑜等[19]则设计了AFSA 算法来自动适应特征的选择来提升检测的效果. 机器学习的成功取决于特征或规则的有效设计. 然而,识别每个独特环境或任务的最佳细粒度流量特征可能具有挑战性,特别是在小样本异常流量场景中存在显著噪声干扰的情况下.
深度学习的算法主要包括以下核心骨干网络CNN、RNN、LSTM、注意力机制和GAN 等,广泛应用于异常流量分类任务[20, 21]. 这些算法在NSLKDD、KDD CUP99、CIC-IDS2017 等数据集[22]上进行了验证,并取得了较好的成绩. PBCNN[23]设计了一种分层的字节CNN,从原始流量包和网络流中提取特征,并通过全连接层对其进行分类,在CIC-IDS-2017 和CSE-CIC-IDS2018 数据集上取得了显著的结果. Elsherif [24]评估了RNN、LSTM、BRNN 和BLSTM 在NSL-KDD 上的性能,证明RNN 和LSTM 可以从历史序列中捕获流量特征,而BRNN 和BLSTM 具有双向建模的特性,从而提高了召回率. 注意力机制具有更强的处理复杂输入关系和序列关系的能力,引领了GPT、BERT等强大模型的发展. ET-BERT[25]利用BERT 强大的学习能力,在相关数据集上训练模型来理解网络流量的上下文信息,然后实现加密流量的分类,实现了良好的性能. 生成对抗性网络(GenerativeAdversarial Network,GAN)可以通过生成样本和判别样本的竞争过程来提高生成样本的水平.Ding 等人[26]设计了一个TACGAN 来生成更多的攻击型数据,并引入了信息损失来提高生成样本和真实样本之间的一致性,解决了数据样本不平衡的问题. 深度学习方法可以自动提取特征,网络模块可以被设计用来表达和抽取不同的流量特征,本文的方法也基于深度学习对流量进行表征.但深度学习模型的性能取决于数据的丰富性. 当样本量不足时,模型容易过拟合,导致模型性能急剧下降.
2. 2 小样本学习及异常流量的应用
机器学习和深度学习无法应对样本数量不足的情况,部分研究工作开始着眼于小样本环境下对于异常流量的检测和分类.
小样本学习代表了一种新的机器学习范式,它利用先验知识从有限数量的例子中有效地学习新的通用表示[4]. 目前,基于元学习的小样本学习在计算机视觉和自然语言处理领域得到了广泛的应用,并取得了巨大的成功. 流行的网络包括MAML[27]、原型网络[13]、孪生网络[28]、匹配网络[29]、关系网络[30]等.
MAML 是基于任务粒度的小样本学习,Feng等人[5]结合了MAML 算法,设计了一个用于小样本异常流量检测的框架. 该方法利用了33 个基于机器学习特征选择的固定特征和LSTM 挖掘的时间特征,然后通过DNN 对其进行分类. 在元学习训练过程中,通过多个N-way K-shot 分类任务获得预训练的DNN 模型参数,然后在测试阶段,基于新的类样本调整模型参数,以获得适合类的分类模型. 这种方法的主要缺点是使用了固定的特征,这限制了模型的能力. 其次,MAML 算法需要在测试过程中不断更新模型参数,效率相对较低.
孪生网络是简单、有效的网络模型之一,FCNet[7]就是一种基于孪生网络的小样本网络入侵检测框架,该方法首先排列组合所有的网络流类别,构造了多个的二分类任务. 每个任务都将网络流量转换为图像数据,然后输入到FC-Net 中,以计算每对样本之间的相似性,从而进行分类,实现了95% 的平均准确率. Wang 等人[8]采用孪生胶囊网络的方式进行样本相似度的比较,利用改进的胶囊网络模块来捕捉特征之间的动态关系,提升检测能力,同时改进了采样方法,以解决数据不平衡的问题. 这些方法基于孪生网络,具有良好的可扩展性和简单的架构,在多个问题上都取得了良好的效果. 然而,训练过程需要重复的成对比较步骤,效率低,运行速度慢.
原型网络在多个领域也取得了不错的表现,Yu 等人[9]在NSL-KDD 和UNSWNB15 数据集上验证了原型网络流量分类的效果,并表明在各种分类场景下,与传统的机器学习和深度学习方法相比,原型网络可以实现优越的性能. Wang 等人[10]从数据和特征贡献的角度出发,结合原型网络的特征生成和欠采样特性,提出了一种新的检测方法. Guo 等人[11]提出GP-Net 中对流的全局信息和流有效载荷的字节位置关系进行了建模,提高了原型网络在加密流检测中的检测性能. 本文选择原型网络作为基础框架,进一步拓展其训练方式和骨干网络的设计,来解决支持集和查询集之间的差异,防止监督崩溃和操作效率低下的问题.
3 研究方法
3. 1 小样本异常流量分类框架
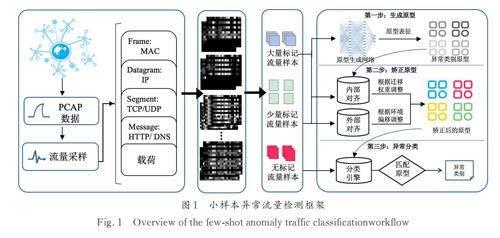
基于APN 网络的小样本异常流量分类框架如图1 所示,包含4 个核心流程:流量收集、流量表示、任务组建和异常分类.
流量收集阶段可以网络流量监控软件来执行,通过收集原始流量文件(如PCAP 格式)以最大限度地保留原始信息. 流量表示阶段通过对网络流量解析、裁剪获得统一的流量尺寸,然后转化成2D 灰度图像. 根据标记样本数量的情况,异常流量可以分为有大量标记样本的类别、仅有少量标记样本的类别. 任务组建阶段基于小样本N-wayK-shot 的分类任务设置,抽取样本组建分类任务用于模型训练. 在异常分类阶段,每个任务会利用已标记的样本来挖掘异常流量的类别原型,然后将未标记的样本与生成的原型进行比较,从而实现分类.
具体地,异常流量分类模块输入流量的表示X ∈ [ 0,256]n*W*H, 输出分类结果 Y ∈ [ 1,…,C ]n.其中,W 和H 是处理图像的宽度和长度,C 是异常类别的数量. 在元学习的训练方式中,一个分类任务被看作一个样本,在一个分类任务中,包含了支持集和查询集两种样本集合. 在APN 中,模型会先将支持集的样本使用原型网络生成异常流量原型,以捕获该类异常流量的特征空间. 初始原型在内部对齐模块(IA)和外部对齐模块(EA)中得到进一步校正,其中内部对齐通过为支持集样本分配权重来克服支持集的密度偏差,外部对齐通过转移到查询集的特征空间来适应动态环境中的特征分布. 最后,将真实环境中的测试流量与对齐的原型进行匹配,并通过距离测量和相似性评估获得流量的异常类别.
3. 2 网络流量表示
网络流量定义为一段时间内的五元组< 源IP、目的地IP、源端口、目的地端口、协议>. 鉴于小样本学习在图像领域取得的巨大成功,网络流被表征为捕捉特定内容信息的图像. 为了确保捕获的信息是有效的,该过程遵循以下原则:(1) 保持生成图像的时空结构的稳定性,调节其大小,并为神经网络处理提供更合适的输入数据源;(2) 保持网络流量信息的真实性,并通过关注头部信息来提取具有代表性的信息. 在网络通信中,客户端的初始数据包通常传达更多关于其通信目的和行为信息的含义,而后续数据包主要传输特定数据,信息量较小. 类似地,对于每个数据包,数据包的元数据和前一部分的负载信息更能描述数据包的总体含义. 具体步骤如下:
(1) 流量抽取:根据五元组格式从流量的原始记录(如PCAP 格式)中解析包并提取、组装成流量X.
(2) 流量采样:对提取的流量进行采样. 由于网络流的有效载荷长度不一致,获得的图像大小也不一致,这对模型不友好. 虽然我们可以通过补0 的方式来保证图像大小的一致性,但是补充过多的0 会造成表征数据的稀疏,影响模型收敛. 基于统计分析,确定网络流的前M 个包进行保留,截断M 之后的数据包. 特别地,为了保持流量包的时空连续性,我们将N 取平方. 对每个包的前N 2 个字节进行保留,截断N 2 之后的字节内容.
(3) 流量表示:采用灰度图像来压平通道,减少通道之间先验关系的影响,最大限度地保留原始输入信息的时空结构. 具体操作包括:首先对网络流进行重新排列,生成大小为W 和H 的像素矩阵,满足W*H ≥ M*N 2. 像素的每个点对应字节的值,字节的值为0~255,因此像素矩阵在视觉上是灰度图像. 线性排列用于组织像素,当达到图像的宽度时,像素继续排列在下一行. 如果所有像素都排列完成,而图像空间仍然有剩余,则用0 填充图像.
3. 3 基于对齐的原型网络(APN)
APN 的结构如图2 所示,分为元学习的特征表示、原型生成与对齐两部分. 原型生成和对齐可以进一步分为以下模块:紫色线表示的内部对齐(IA)和绿色线表示的的外部对齐(EA). 在模型训练过程中,每个样本是N-Way K-Shot Q-Query 的一个分类任务,命名为Episode. 其中,N 表示类的数量,K 表示每个类中包括的支持集样本的数量,Q 表示每个类包括的查询集样本的数目. 每个事件中的训练和测试数据集被命名为支持集( Xs ,Ys) 和查询集( Xq ,Yq). 对于每次训练,APN随机组装事件,然后让模型执行分类任务,通过损失来指导模型更新. 对于标签较少的新类,APN 类似地构建分类任务,并提供有限的样本作为支持集,并且模型可以基于先前学习的任务先验知识来抽取和比较特征以执行分类任务,从而预测查询样本的类.
猜你喜欢
现代电子技术(2016年24期)2017-01-19
现代商贸工业(2016年28期)2016-12-27
电子技术与软件工程(2016年22期)2016-12-26
电脑知识与技术(2016年21期)2016-10-18
科教导刊·电子版(2016年18期)2016-07-18
科教导刊·电子版(2016年18期)2016-07-18
电脑知识与技术(2016年12期)2016-06-14
科技视界(2016年9期)2016-04-26
物联网技术(2015年8期)2015-09-14
