
一种基于数据融合的新的入侵检测框架
2015-09-14 09:34苏健
物联网技术 2015年8期
苏健


摘 要:根据数据融合理论,提出了一种基于二级数据融合的入侵检测的理论框架。该方法在一级融合充分利用了多源检测信息;进行二级融合的各检测方法则利用各自特点弥补单一方法的缺陷,故可在保持较低误警率的情况下,提高检测率,同时能够发现未知类型的攻击。在该理论框架下建立一种实现模型,可将一种新的基于聚类(非监督学习)分析方法应用于此。在仿真实验中,通过通用的KDD99数据集的测试结果表明,其总体检测率得到了明显的提高。文中也对系统的实时性进行了分析和总结。
关键词:网络安全;入侵检测;数据融合;聚类
中图分类号:TP393.08 文献标识码:A 文章编号:2095-1302(2015)08-00-03
0 引 言
近年来,互联网迅猛发展,随之而来的是网络入侵事件的数量也成倍增长;信息安全领域面临严峻的挑战,而入侵检测技术作为主要的动态防御手段已经成为当前刻不容缓的重要课题。入侵检测是对计算机系统攻击行为的检测。入侵检测系统(Intrusion Detection System)能实时监控系统的活动、及时发现攻击行为并采取相应的措施以避免攻击的发生或尽量减少攻击造成的危害。
传统的入侵分析技术分为滥用检测(Misuse Detection)和异常检测(Anomaly Detection)两大类。目前已经发展出的入侵分析技术已有数十种,而任何一种单一的入侵分析技术都存在一定的不足。例如,基于规则匹配的滥用检测方法不能有效检测已知攻击的变种或为止攻击;基于系统调用的异常检测方法不能适应用户反复无常的更改其工作习惯;基于神经网络的入侵检测方法要求训练数据集纯净,可移植性差。本文提出的新的入侵检测框架能充分利用多源检测信息,进行融合的各检测方法利用各自特点弥补单一方法的缺陷,在保持较低的误警率的情况下,提高检测率,同时能够发现未知类型的攻击。
1 基于数据融合的入侵检测
1.1 理论模型
数据融合技术在军事领域已得到广泛的应用,其定义为:把来自多传感器和信息源的数据和信息加以联合(Association)、相关(Correlation),合并为一种表示形式,以获得目标精确的位置/状态估计、身份识别,以及对战场态势和威胁的综合评估。
把网络数据看作来自多传感器的多源信息并引入数据融合的分析模型,能有效的发现、分析数据之间的内在联系,并为系统管理员提供有效的风险评估。在1999年,Tim Bass提出了将数据融合应用于入侵检测的理论模型[1],图1所示是Tim Bass的基于数据融合的入侵检测模型图。
在图1所示模型中,态势数据可通过网络传感器的初步观测基元、标识符、次数和描述获得。原始数据需要校准过滤,参照图1中的层次0。第1层的对象提取在时间(或空间)上相关联,其数据标以公制的权重。观测数据可以根据入侵检测基元关联、配对、分类。对象通过配位的行为、依赖、共同的源点、共同的协议、共同的目标、相关的攻击率或其他高层次的属性被检测出,形成一个基于对象的聚集的集合。对象在这样的对象基上的上下文中排列、关联、置位后,态势提取就可以提供态势知识和识别。
在该模型的启发下,本文提出了一种基于二级数据融合的入侵检测的框架。第一级对通过多源检测信息进行融合,提取出有效特征,实现数据融合的目标标定;第二级融合对同一目标用不同的检测方法进行分析,并使用决策器对各分析结果进行决策融合,得出最终决策并形成反馈控制自适应的调整IDS自身,图2所示是基于二级数据融合的入侵检测框架。
在本模型中,一级融合从主机传感器、网络传感器、网关传感器采集数据,进行对象提取。二级融合中使用的分析引擎也分为滥用和异常两大类。前一大类具有检测率高但不能发现未知类型的攻击的特点;后一大类则特点各有不同,如基于时序异常的IDS可以发现系统底层的异常,而基于用户行为异常的IDS 对用户的习惯敏感。通过决策融合可以利用各检测引擎的优点,弥补其他的不足。而决策形成的反馈控制可以对某些分析引擎进行微调,从而使整体具有自适应性。在决策融合中可以采用的决策方法有:决策表、能量函数、D-S证据理论。
1.2 实现模型
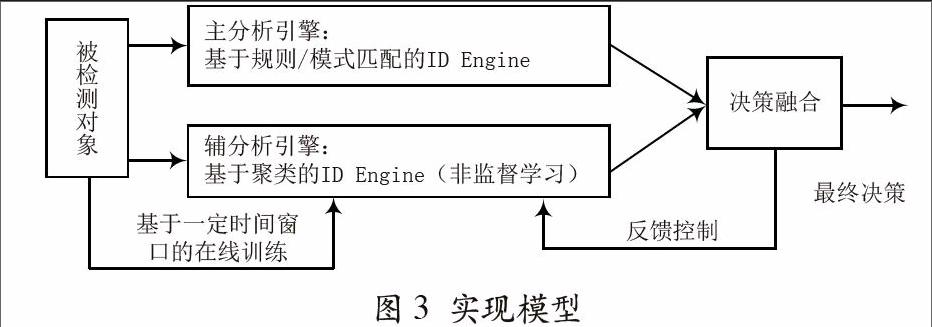
在现有的试验条件下,不可能将理论模型中所有的分析引擎都加以使用。目前入侵检测系统中最大的问题就是不能在较低的误警率下获得较高的检测率。产生这样问题的根本原因是入侵检测系统根据单一的检测手段得到的信息不完善,根据这些信息不易得出正确的结论。着眼于这一点,本文从两大类入侵分析引擎中各选取一种具有代表性的进行融合:基于规则/模式匹配的Intrusion Detection Engine和基于聚类 (非监督学习)的Intrusion Detection Engine。基于规则/模式匹配的滥用检测方法已经发展的比较成熟,市场上的商用IDS多基于此。它是对数据包作基本的协议解码后结合数据包数据区的内容匹配来检测攻击,其特点是对已知类型的攻击检测率相当高,但具有不能发现未知类型的攻击、不易配置更新的不足。基于聚类(非监督学习)的检测方法属于异常检测,它是通过在数据中发现不同类别的数据集合来区分异常用户类,进而推断入侵事件发生,检测异常入侵行为。该方法具有在较低误警率下发现未知类型攻击的能力,但是其检测率不高。在文献[2]中给出了一种基于非监督学习的实现方法,但其性能不能满足要求,本文采用另外一种非监督学习的聚类方法,取得了不错的效果。
实际的实现模型如图3所示,该模型由于检测率高、误警率几乎为零,故将基于规则/模式匹配的IDE作为主分析引擎。基于聚类(非监督学习)的IDE作为辅助分析引擎,弥补主分析引擎不能发现未知攻击类型的不足。由于在特征空间中反映出的入侵数据流的分布变化不定,辅分析引擎采用基于一定时间窗口的在线训练加以拟合。决策融合现简单的采用基于检测率、误警率二维因素的决策表,表1所列是其二维的决策表。
当最终决策表明当前数据流中的入侵数据所占的比例大于2%时形成反馈控制:关闭辅分析引擎,通知管理员,只使用主分析引擎检测。当入侵数据所占的比例小于2%时继续同步工作。
1.3 基于聚类(非监督学习)的入侵分析方法
将模式识别中的聚类技术引入入侵检测属于异常检测的方法。与有监督学习相比,非监督学习的识别率要低一些,但具有发现未知相似类型的能力。该方法提出了一种能处理不带标识且含异常数据样本的训练集数据的入侵检测方法。对网络连接数据作归一化处理后,在特征空间中按照一定规则形成类质心,并通过计算样本数据与各类质心的最小距离来对各样本数据进行类划分,同时根据各类中的样本数据动态调整类质心。由于网络数据一般服从这样的前提假设:正常行为的数据量及其类别数将远远大于各种攻击行为的数据量及其类别。一般可以以训练结果中各个类划分的样本数来评判该类是否异常。完成样本数据的类划分后,根据异常比例来确定异常数据类别并用于网络连接数据的实时检测。结果表明,该方法有效地以较低的系统误警率从网络连接数据中检测出新的入侵行为,更降低了对训练数据集的要求。
文献[2]中详述了该方法的一种具体实现,其核心聚类算法是最邻近算法。其性能在误警率平均2.63%的情况下,检测率在18.75%到56.25%之间波动。为了将这一方法应用于我们的框架中,必须进一步提高检测率。在此方法中,核心聚类算法采用最大最小距离算法[3],同时加入一些其他的技术如非线性的归一化预处理、非数值型特征的有效编码等。最终,在相同的误警率下,检测率提高至31.625%到81.7%之间。并且,将此方法应用于入侵检测框架时,可以利用上面提及的反馈控制调整最大最小距离算法的聚类参数,进一步提高分类的准确性,从而提高检测率。
2 仿真试验
在试验中,我们采用通用的KDDCup99[4]专用数据集进行测试。该数据集来源于从一个模拟的局域网上采集来的9个星期的网络连接数据。每条数据有41个特征,包括36个数字型特征,5个字符型特征。数据集种共包含4大类22种攻击。本入侵检测系统配置如下:主分析引擎可匹配识别8种攻击;辅分析引擎的一次训练集包含10种攻击,其中2种为主分析引擎不可识别的攻击。被检测集含有10~12种攻击。经过5组测试,其平均性能如表2所列。
由此可见,基于融合的检测在较低的误警率下可以识别一定的未知类型攻击,从而明显提高了检测率。其平均检测时间在0.011~0.019秒之间,基本可以接受。与传统的方法相比,以上结果充分说明了该方法的可行性与实用性。
同时经过进一步分析,还可以看出,虽然基于聚类(非监督学习)的入侵检测方法有助于提高基于规则/模式匹配的入侵检测方法的检测率,但后者对降低前者的误警率没有丝毫帮助,这也是我们下一步要研究的课题之一。
此外,入侵检测系统的一个非常重要的特性就是对实时性的要求很高。系统的精度再高,事后分析的延迟超过一定的限度对用户来说也是无用的。因此,本文对训练的实时性和检测的实时性也进行了相关的分析。
(1)训练的实时性。我们分别对样本容量为1 000,2000,5 000的训练集做了整体性测试,其结果如图4所示。
可以看出,样本容量为1 000时训练耗时为2分40秒,而增加到2 000时已经需要16分钟。训练时间是随着样本容量的增加而呈指数级增长的。就算以最低的样本容量训练也远不能达到实时的要求。进一步分析发现大部分时间都用来进行距离矩阵的运算了,实际核心算法的单次迭代花费小于2秒。从程序的编写角度还可以提升20 %以上的速度,例如:距离在首次使用时计算;数据库的查询速度可以提升;数值预处理以后不需要开方运算。另外,由以上分析可以想到,在“实时采集,实时训练,实时检测”的系统中,训练样本的采集不要批量而是一条条的采集,采集到一条就立刻计算相关的距离值,即将集中计算距离矩阵的时间分散开。这样总体的训练时间可以降到5秒钟以下,达到接近实时训练的要求。
(2)检测的实时性。检测时间主要受规则集大小和聚类方法最终生成的分类器数目的多少影响。当前条件下一条样本的平均检测时间一般为0.015~0.019秒,这是可以接受的。
3 结 语
本文提出了一种基于数据融合的入侵检测框架,其核心思想是充分利用多源检测信息,通过融合与反馈的方法有机的结合各种分析引擎。并且一种新的基于聚类(非监督学习)的检测方法应用于本框架,经试验证明了其有效性。
在下一步的工作中,还需要进一步完善整个框架,提高其性能和实用性,具体方法包括:
(1)提高基于聚类的检测方法在线学习的稳定性;
(2)引入其它类型的分析引擎进行融合;
(3)在相同条件下比较分析各种融合方法的结果;
(4)提高反馈控制的精确性。
参考文献
[1] Bass,T.,Intrusion Detection Systems and Multisensor Data Fusion:Creating Cyberspace Situational Awareness, Communications of the ACM[J] , April 2000,43(4):223.
[2] Leonid Portnoy, Intrusion detection with unlabeled data using clustering [J]. ACM Workshop on Data Mining Applied to Security, 2001:105.
[3] Jinzong Li, Pattern Recognition Guide [M], China Higher Education Press, Beijing China,1994:313.
[4] Lippmann, R.P. and J. Haines, Analysis and Results of the 1999 DARPA Off-LineIntrusion Detection Evaluation, [A]. Recent Advances in Intrusion Detection, Third International Workshop, RAID 2000 Toulouse, France, October 2000 Proceedings, H.Debar, L. Me, and S.F. Wu, Editors. 2000, Springer Verlag. p. 162-182.
[5] M.C.Fairhurst, A.F.R.Rahman, Enhancing consensus in multiple expert decision fusion, IEE Proc-Vis.ImageSignalProcess [J]. February 2000, 147(1):167
[6] Lee.W, R.Nimbalkar,K.Yee,etc.A Data Miming Mining and CIDF Based Approach for Detecting Novel and Distributed Intrusions. [J]. Proceedings of The Third International Workshop on Recent Advances in Intrusion Detection. Lecture Notes in Computer Science No.1907, Toulouse, France, October 2000:291.
猜你喜欢
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
电子设计工程(2015年6期)2015-02-27
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
