
基于独立分类网络的开集识别研究
2024-06-17 13:41:57徐雪松付瑜彬于波
华东交通大学学报 2024年2期
徐雪松 付瑜彬 于波


摘要:【目的】为解决图像分类模型面对传统闭集训练方式出现的模型缺乏开集泛化性的问题,提出了一种分离式的独立分类网络结构。【方法】每个类别都包含独立的线性特征层,特征层中设计的神经元节点能够在有限的数据样本下更准确地捕获类别特征。同时,在模型训练时,文中引入了一类无需标注的负样本,使得模型在构建决策边界时不仅依赖于已知类别的特征差异,在不增加额外标注样本的情况下,增加模型决策边界的开集泛化性。【结果】结果表明:独立分类网络开集识别(ICOR)模型结构和开集自适应训练策略均能有效改善传统模型开放集识别(OSR)性能;随着开放度的增加,能表现出更好的鲁棒性,能更有效地降低模型的OSR风险。【结论】提出的独立分类网络并融合开集自适应训练的算法比现有开集识别算法具有更优的开集识别性能。
关键词:深度学习;开集识别;图像分类;迁移学习
中图分类号:TP391;U495 文献标志码:A
文章编号:1005-0523(2024)02-0079-08
Research on Open Set Recognition Based on Independent Classification Network
Xu Xuesong, Fu Yubin, Yu Bo
(School of Electrical & Automation Engineering, East China Jiaotong University, Nanchang 330013, China)
Abstract: 【Purpose】In order to solve the problem of image classification models lacking open set generalization due to traditional closed set training methods when facing open set recognition problems, we propose a separate independent classification network structure. 【Method】 Each category contains an independent linear feature layer. The neural nodes designed in the feature layer can capture the category features more accurately under limited data samples. At the same time, a class of negative samples without labeling is introduced in the model training, so that the model not only relies on the feature difference of the known categories when constructing the decision boundary, but also increases the open set generalization of the model decision boundary without adding additional labeled samples. 【Result】The results show that both the ICOR model structure and the open-set adaptive training strategy can effectively improve the OSR performance of traditional models; with the increase of openness, it can demonstrate better robustness; can more effectively reduce the OSR risk of the model. 【Conclusion】The proposed independent classification network combined with open-set adaptive training algorithm has better open-set recognition performance than existing open-set recognition algorithms.
Key words: deep learning; open set recognition; image classification; transfer learning
Citation format: XU X S,FU Y B,YU B. Research on open set recognition based on independent classification network[J]. Journal of East China Jiaotong University, 2024, 41(2): 79-86.
【研究意义】在实际应用中,由于无法准确预知样本的分布,预先设计好的分类器在面对未知类别样本时难以保持较高的分类准确性,这就是开放集识别问题(open set recognition,OSR)[1]。近年来许多学者针对这个问题提出不少方法,总的来说,分成生成式和判别式两种[2]。
【研究进展】判别式方法通过正则化收缩已知类在特征空间的决策边界,并在特征空间内给未知类分配区域,从而缓解模型的过度泛化,降低模型的OSR风险[3-5]。例如:Scheirer等[1]提出基于支持向量机的OSR算法,通过设计一个额外的超平面来区分已知和未知类别;Zhang等[3]采用极值理论对数据的尾部分布进行重新建模,提高了模型对尾部分布数据的处理能力;Bendale等[4]揭示了Softmax激活函数不适用于OSR任务,并提出了OpenMax算法作为深度学习领域OSR问题的第一个解决方案。
生成式方法通过约束已知类在特征空间的分布来缩小模型的决策边界,从而提高模型的OSR性能。例如:Neal等[6]提出使用生成对抗网络(generative adversarial networks,GAN)生成实例样本,并对生成样本进行概率估计来扩充已知类的分布,使分类器能够更加准确地区分已知类和未知类;Zhang等[7]采用自动编码器技术对输入样本进行重建,通过对比重建误差来评估输入样本;Xia等[8–10]通过在特征空间内对已知类的原型设计空间约束,限定未知类原型在特征空间的分布区域,以此来降低模型的OSR风险。
判别式方法依赖于对照组样本来确定各类别特征的分布,因此需要有足够数量的对照组样本,才能准确刻画每个类别的边缘特征。生成式方法通过生成方法学习每个类别自身的特征分布,同样需要足够丰富的自身样本才能训练出可靠的生成模型。但实际应用中,可能无法获得足够数量的标注样本。此时,由于自身样本特征稀疏,无论是判别式模型还是生成式模型的训练都面临较大困难。
【关键问题】卷积神经网络(convolutional neural network,CNN)和ViT(vision transformer)[11]被广泛应用于图像分类任务。本文以CNN和ViT模型结构为基础,对模型结构和训练策略进行了优化,提出了一种适用于OSR问题的模型结构--独立分类网络开集识别(independent classifiers for open-set recognition,ICOR)模型,以及一种新的模型训练策略--开集自适应训练。
【创新特色】本文的创新点主要体现在以下方面:提出了独立分类网络结构,该结构给未知类别提供了分类区域,过独立的线性层捕获更多类别特征,帮助模型学习更完备的特征;提出了一种开集自适应训练策略,在训练中增加了一类未标注的开集数据集作为所有已知类数据的负样本,通过额外对比已知类和负样本的特征差异来使模型学习更完备的已知类特征;本文的ICOR模型结构通过少量数据样本就可实现模型的训练,降低了在研究过程中模型对标注图像的依赖。
1 研究方案
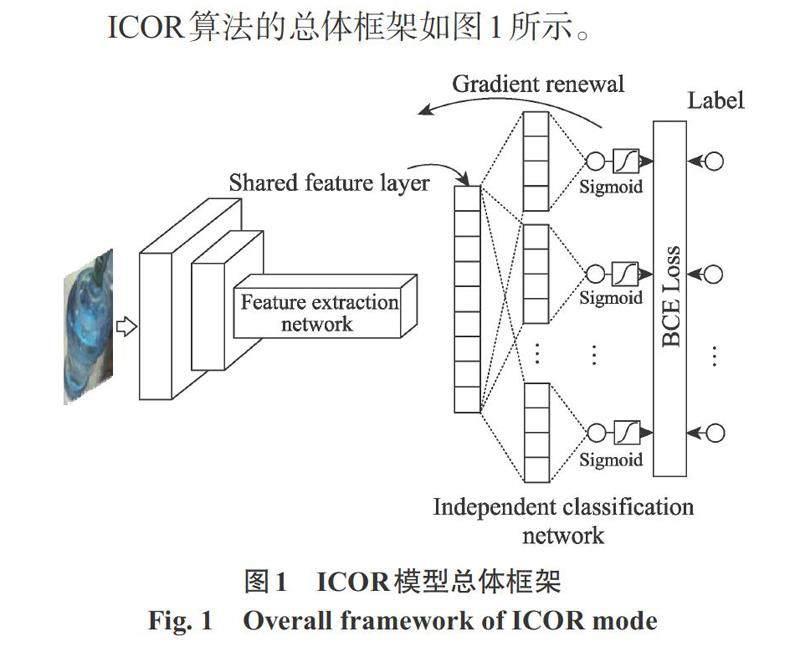
ICOR算法的总体框架如图1所示。
1.1 特征提取网络
实际应用中,数据样本的获取和标注往往是个难题。为此,本文在对ICOR模型的特征提取网络(feature extraction network)参数初始化时,采用了迁移学习的策略[12]。为了验证ICOR模型结构的普适性,在实验中,本文采用了3种具有代表性的特征提取网络:经典的ResNet50深度模型[13]、轻量化的MobileNet模型[14]和基于注意力机制模块的ViT模型[11]。
迁移学习策略的适用性受源任务与目标任务的相似度、数据分布差异的影响。因此,在进行参数迁移时,选择了与ICOR模型相同类型的图像分类模型,使用在ImageNet1K数据集(ResNet50、MobileNet)[13-14]和JFT-3B数据集[11](ViT)上预训练的模型参数初始化ICOR模型的特征提取网络。输入图像经过特征提取后的对应表达式为
[Vk=G(θG,Ik)] (1)
式中:[Ik]为输入图像;[θG]为特征提取网络[G(?)]的模型参数。对于输入图像[Ik],经过特征提取网络后得到共享特征向量[Vk](share feature layer)。其中,[G(?)]决定特征向量[Vk]的输出维度,[θG]决定特征向量[Vk]的特征属性。
1.2 独立分类网络
传统图像分类模型常使用Softmax交叉熵函数构建分类损失,这导致了两个问题:Softmax函数的归一化机制将整个特征空间划分给了已知类,没有给未知类别留有分类区域;Softmax容易导致模型过于关注目标类,降低了模型对非目标类的学习权重,容易导致模型陷入局部优化。
ICOR模型中,引入了图1所示的分离式独立分类网络结构(independent classification network)。每个独立分类网络结构包含了若干个独立神经元节点,与共享特征层之间使用全连接结构连接,激活函数采用GELU。同时,在输出端使用Sigmoid激活函数对分类器的输出进行独立归一化到0~1。第i个类别的预测概率可以表达为
[P(yi|Vk)=Sigmoid(Fi(φi|Vk))] (2)
式中:[Vk]为特征提取网络输出的特征向量,所有独立分类器共享该特征向量;[Fi(?)]为属于类别[yi]独立分类器;[φi]为该独立分类器的模型参数。独立分类网络将M分类转换成了M个单分类,每个独立网络只需要独立判断输入样本属于本类别的概率,这使得已知类别在特征空间内的分布形成闭合的区域,从而实现已知类和未知类在特征空间上的分离,给未知类别在特征空间内保留了分类区域。针对每一个独立分类器的预测输出,均使用二值交叉熵函数进行单独构建误差损失,计算式为
[L=-1Nk=1Ni=1Mlog(P(yi|xk)), tk=1-1Nk=1Ni=1Mlog(1-P(yi|xk)), tk=0] (3)
式中;[xk]为输入图像;N为迭代中的批次数量;M为已知类别的数量。训练中,对于单个独立分类器,只有当输入样本属于第i类时,才被视为该类别的正样本。因此,ICOR模型对正负样本的学习权重是相同的,通过增加模型对负样本特征的学习,可以促使模型缩小正样本类在特征空间内的决策边界。
1.3 开集自适应训练
在常规监督分类任务训练中,由于标签提供的信息有限,模型可能会拟合一些仅在闭集训练集下有利于分类的特征,这些特征可能并不具备开集泛化性。此外,在实际应用中,往往无法有效收集到足够的数据样本,这可能会导致模型过拟合,使得其特征学习偏向于局部优化。
本文提出了一种如图2所示的开集自适应训练策略。在模型训练时,额外添加了负样本图像。尽管负样本图像未进行细致的类别标注,但在模型训练中仍然可以提供额外的对比特征,使模型在构建已知类的决策边界时,不局限于已知类的特征差异,这些额外的特征差异信息可以从侧面反映已知类别的边缘特征分布。当模型用于构建决策边界的特征足够丰富时,模型在面对全新的开集数据时,紧凑的决策边界能赋予模型更好的鲁棒性。这种方式的优势在于,无需标注的数据样本十分易得,可以直接对大型数据集进行随机采样。
图2中,A和B表示的是训练集中闭集类对应的图像,实际问题可能还存在其他类,本文仅以A和B类为例进行描述说明。[?]表示未经过标注的未知类别的任意图像,其中[(A,B)??]。开集自适应训练的步骤包括。
步骤1 构建图1所示的ICOR模型,加载特征提取网络的预训练权重,在闭集条件下训练模型(Close training),直至模型收敛,保存模型。
步骤2 使用步骤1中保存的模型对未标注的负样本图像[?]进行预测(Open testing),并将预测值高于设定开集阈值的负样本图像保存。图2中A′表示图像[?]的预测值高于设定的开集阈值(Open threshold value),且对应的预测类别为A。
步骤3 将步骤2中保存的图像(A′和B′)与闭集图像进行混合,并用于模型的开集自适应训练(Open set adaptive training),直至模型收敛,并保存模型。其中,图像A′和B′对于任何一个独立分类网络的真实标签均设置为[0],表示不属于任何闭集已知类别。
步骤4 使用验证集图像对步骤3保存的模型进行验证(Open set verification),计算模型的开集和闭集精度。其中,开集验证集C中包含了已知类和未知类图像。
步骤5 重复步骤2到4,直到模型的开集和闭集精度达到预期要求后,开集自适应训练结束,保存最终模型。
在开集测试中,当输入样本的预测值小于设定的开集阈值时,被判定为开集类;反之,为闭集类。在步骤2中,尽管负样本图像可能被识别为已知类,但负样本图像仍然在特征空间内有其所属的分类区域,在步骤3中通过标签信息来不断的迭代学习,负样本图像能逐步地压缩已知类在特征空间内的区域,达到收缩已知类别决策边界的目的。
2 实验与分析
实验中,模型的学习率为0.001,学习动量为0.5,权重衰减率为0.000 05。实验平台服务器CPU为W-2133 CPU@3.60GHz,GPU为GeForce GTX 1080Ti,搭载Pytorch深度学习框架。
2.1 数据集介绍
正如1.3节所分析的,研究在少量样本条件下的OSR问题对解决实际工程应用问题具有极大的实际价值。为此,本文收集了两个小型的数据集。
2.1.1 小型数据集FDS
小型数据集(few data set,FDS)包含100类实际环境中的物品,每类物品从不同角度采集20张图像。数据集的部分展示如图3所示。
实验中,按照1:9来随机划分闭集和开集类别,每个类别按照1:3随机划分训练集和验证集。同时,为了便于ICOR模型的开集自适应训练,本文收集了一个不做类别标注的未知类数据集(unknown data set,UDS),一共包含5 000张图像,涵盖各类生活用品、服饰、地标等。其中,UDS数据集与FDS数据集之间在类别上不存在交集。
2.1.2 数据集Imagenet-Crop
图像背景信息可能会对模型训练造成影响,为增加实验的对比性,本文基于Imagenet1K数据集制作了比FDS数据更加复杂的Imagenet-Crop数据集。实验中,随机从Imagenet1K的1 000个类别中选取10个类别作为闭集类别用于模型的闭集训练,在剩余的990类中,划分400类作为开集类别用于模型开集测试,590类作为未知类别。
本文聚焦于研究模型的OSR性能,在实验中适当的增加了Imagenet-Crop数据集中闭集图像的数量,以保证模型的闭集精度。实验中,在闭集类别对应的训练集内随机抽取100张图像,按照2:8的比例划分训练集和测试集。
2.2 实验设计
为了评估ICOR模型和开集自适应训练策略的有效性。本文设计了在同等实验条件下关键参数的消融实验、模型开放度实验以及与现有OSR算法的对比实验。
2.3 消融实验
2.3.1 独立分类网络对模型开集性能的影响
AUROC常被用于评估模型的OSR性能[8-9],然而AUROC值只考虑到模型对已知类和未知类的分辨能力,并未考虑到模型对已知类的正确分类能力。本文采用“开集精度(open accuracy,OA)”来评估模型识别已知类和未知类的能力,并通过“闭集精度(close accuracy,CA)”来评估模型对闭集类别的正确分类能力,其定义为
[OA=i=1pOⅡ(yi* 式中:[PO]与[PC]分别为测试集中开集和闭集样本的总数;[yi*=argmax(y1*,y2*,…,yM*)],即对于输入样本[xi],[y*i]表示M个独立分类网络中对应预测输出的最大值;[Ⅱ]为指示函数,当逻辑为真,函数结果为1;[clsi]为输入样本[xi]的正确标签;[od]为开集拒判阈值。由于ICOR模型中每一个独立分类网络都通过Sigmoid函数激活输出,可以看作是逻辑回归的二分类,故设定开集拒判阈值为0.5。 为平衡模型性能和计算资源的消耗,本文通过多次实验的先验知识确定每个独立分类网络的神经元节点个数为共享特征层的十分之一。在FDS和Imagenet-Crop数据集上,训练次数为200次,采取解冻训练模式,即不对网络层进行冻结,训练所有模型的所有网络层。实验结果如表1所示。 表1中,1、4、7三组使用Softmax函数的模型在闭集条件下具有良好的识别精度,表明模型已经成功收敛。然而,这3组模型的最高OSR精度不超过0.474(1组)。此外,Sigmoid组模型对应的表1中的2、5、8组实验结果表明,在FDS数据集上,3组模型的OSR精度分别提高至0.824、0.707和0.826,这表明Sigmoid函数对模型的OSR性能有所提高。然而,在Imagenet-Crop数据集上,这些模型仍然表现出极高的OSR风险。例如,第8组的OSR精度仅为0.437,相对于第7组Softmax组的0.331仅有0.1的提升。 表1中的3、6、9组对比实验结果表明,在两个数据集下,ICOR模型均实现了最高的OSR精度。在Imagenet-Crop数据集上,最低的OSR精度也达到了0.792(9组),高于Sigmoid组最高的0.744(2组)。此外,通过比较Softmax和Sigmoid组的闭集精度可以发现,使用Sigmoid函数可以提高模型的OSR精度,但同时也可能降低模型的闭集识别精度。而本文提出的ICOR模型在同样的实验条件下,既保证了较高的闭集精度,同时对模型的OSR性能具有良好的改善效果。 2.3.2 开集自适应训练对模型开集性能的影响 为评估开集自适应训练策略对模型OSR性能的影响,本文在3组模型的Sigmoid和ICOR组的闭集训练基础上进行了开集自适应训练。训练中,在开集测试时,选择在闭集验证集中有95%以上样本被分类正确的预测置信度作为开集阈值。模型训练分两个阶段,首先进行100次的闭集训练,然后进行100次开集自适应训练。实验结果见表2。 表2中,K+表示模型经过开集自适应训练后的结果。2、6、10组的对比结果表明,经过开集自适应训练后,Sigmoid和ICOR组模型在两个数据集上的OSR精度均提升至0.9以上。因此,可以证明开集自适应训练能够有效提高模型的OSR性能。此外,在相同的特征提取网络下,ICOR模型相较于Sigmoid能更有效地提升模型的OSR性能。这也表明独立分类网络设计的有效性。 2.4 开放度测试实验 为了通过有限的未知类别估计模型在更加开放的环境中的OSR性能的鲁棒性,本文设计了开放度测试实验来进一步评估模型的开集性能。数据集的开放度(Openness)[1]是指在测试过程中出现未知类别的比例,其定义为 [Openness=1-2CTCE+CR] (5) 式中:[CT]为训练中的已知类别数;[CE]为验证集中的已知类别数;[CR]为验证集中已知类别和未知类别数之和。本文实验中,验证集包含了所有训练类别。根据式(5),FDS和Imagenet-Crop数据集对应的最大开放度分别为0.574和0.782。 F1值结合了准确率和召回率两个指标,常被用于评价二分类任务模型的综合性能,开集识别问题可以被视为一个简化的二分类任务,即模型是否准确识别已知类和未知类。模型在不同开放度条件下的F1分数的变化趋势如图4所示。 图4(a)和图4(b)展示了3组模型闭集条件下,在FDS和Imagenet-Crop数据集上进行开放度实验的结果。实验表明,随着数据集开放度的增加,模型在测试过程中需要处理更多未知类别,各组模型的综合F1分数逐渐降低,这与预期实验趋势一致。其中,Sigmoid组的折线图位于Softmax组上方,这表明使用Sigmoid比使用Softmax具有更优的开集识别性能,但随着开放度的增加,Sigmoid组的F1分数迅速下降,表明Sigmoid仅在低开放度条件下表现出良好的鲁棒性。相比之下,ICOR模型的折线位于最上方,并且随着开放度的增加,F1分数下降的速度要较为缓慢,表明相对于其他两组模型,ICOR模型具有更优的开集鲁棒性。 图4(c)和图4(d)展示了3组模型经过开集自适应训练后在FDS和Imagenet-Crop数据集上进行开放度实验的结果。在相同的开放度条件下,ICOR组的综合F1分数高于Sigmoid组。Sigmoid组的折线在开放度较小时呈水平状态,但在开放度大于50%和60%时,折线的斜率急剧降低,模型的F1分数急剧下降。这表明Sigmoid组在开集适应性训练后,在低开放度下能够保持较高的开集精度,但随着开放度的增加,仍然存在严重的开集识别风险。实验中,ICOR组的折线斜率始终保持着缓慢的下降趋势,模型表现出更优的鲁棒性。 2.5 算法对比实验 为验证ICOR算法对比其它OSR算法(AMPFL[8]、SLCPL[9]、ARPL[15]、GCPL[10])对现有模型OSR性能改善的优势,本文在FDS和Imagenet-Crop数据集上进行了对比实验。实验中,所有算法使用同一特征提取网络,并使用迁移自Imagenet1K数据集的预训练参数。实验中模型迭代次数均为200次,实验结果如表3所示。 表3中7到18组的实验结果表明,AMPFL、SLCPL、ARPL和GCPL等算法对模型的OSR性能改善有限。特别是在ResNet50特征提取网络框架下(第7、10、13和16组),尽管这些算法保持着较高的闭集精度,但存在极大的OSR风险,甚至高于传统的Softmax和Sigmoid(第1、4组)。此外,ICOR算法在未进行开集自适应训练时(第19、20、21组),实现了试验中最高的OSR精度;在进行开集自适应训练后,ICOR模型的OSR精度均在0.97以上,相比于现有OSR算法,ICOR(K+)在两个数据集上的表现(第22、23、24组)均有明显的优势。 同时,AMPFL、SLCPL、ARPL、GCPL等算法,随着特征提取网络的改变,模型的开集识别精度也会发生明显变化,这表明特征提取网络的类型对传统开集识别算法的开集识别精度具有很大影响,而本文算法随着特征提取网络的变化,开集识别精度保持稳定,表现出了更好的鲁棒性。 3 结论 本文针对传统模型存在的OSR问题,设计了ICOR模型和开集自适应训练策略,通过实验可以得出以下结论。 1) 通过消融实验证明,ICOR模型结构和开集自适应训练策略均能有效改善传统模型OSR性能。 2) 通过开放度实验证明,本文的ICOR模型及开集自适应训练策略随着开放度的增加,表现出更好的鲁棒性能。 3) 对比实验中其他现有OSR算法,ICOR模型和开集自适应训能更有效地降低模型的OSR风险。 参考文献 [1] SCHEIRER W J, ANDERSON D R R, SAPKOTA A, et al. Toward open set recognition[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence , 2013, 35(7): 1757-1772. [2] MAHDAVI A, CARVALHO M. A survey on open set recognition[C]//Laguna Hills: 2021 IEEE Fourth International Conference on Artificial Intelligence and Knowledge Engineering (AIKE), 2021. [3] ZHANG H, PATEL V M. Sparse representation-based open set recognition[J]. IEEE transactions on Pattern Analysis and Machine Intelligence, 2016, 39(8): 1690-1696. [4] BENDALE A, BOULT T E. Towards open set deep networks[C]//Las Vegas: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. [5] OZA P, PATEL V M. C2AE: Class conditioned auto-encoder for open-set recognition[C]//Long Beach: 2019 IEEE/ CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019. [6] NEAL L, OLSON M, FERN X, et al. Open set learning with counterfactual images[C]//Munich: Proceedings of the European Conference on Computer Vision(ECCV), 2018. [7] ZHANG Y, LEE K, LEE H. Augmenting supervised neural networks with unsupervised objectives for large-scale image classification[C]//New York: International Conference on Machine Learning (ICML), 2016. [8] XIA Z, WANG P, DONG G, et al. Adversarial motorial prototype framework for open set recognition[J]. Journal of LaTeX Class Files, 2015, 14(8): 1-14. [9] XIA Z, WANG P, DONG G, et al. Spatial location constraint prototype loss for open set recognition[J]. Computer Vision and Image Understanding, 2023, 229: 103651. [10] YANG H M, ZHANG X Y, YIN F, et al. Convolutional prototype network for open set recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 44(5): 2358-2370. [11] HAN K, WANG Y, CHEN H, et al. A survey on vision transformer[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 45(1): 87-110. [12] ZEILER M D, FERGUS R. Visualizing and understanding convolutional networks[C]//Zurich: European Conference on Computer Vision - ECCV 2014, 2014. [13] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]//Honolulu: 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2017. [14] GAVAI N R, JAKHADE Y A, TRIBHUVAN S A, et al. MobileNets for flower classification using TensorFlow[C]//Pune: 2017 International Conference on Big Data, IoT and Data Science (BID), 2017. [15] GENG C, HUANG S, CHEN S. Recent advances in open set recognition: A survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 43(10): 3614-3631. 第一作者:徐雪松(1970—),男,教授,博士,硕士生导师,研究方向为移动机器人视觉导航与控制、无人机控制、计算机视觉、模式识别。E-mail: cedarxu@163.com。 通信作者:付瑜彬(1996—),男,硕士研究生,研究方向为深度学习、开集识别。E-mail: 1668875496@qq.com。
猜你喜欢
知识管理论坛(2016年6期)2017-05-27 19:44:03
振动工程学报(2017年1期)2017-04-21 10:24:46
现代电子技术(2017年1期)2017-02-16 11:13:19
现代电子技术(2016年22期)2016-12-26 15:51:05
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
软件导刊(2016年9期)2016-11-07 22:19:22
软件工程(2016年8期)2016-10-25 15:47:34
商(2016年22期)2016-07-08 14:32:30
