
基于特征融合注意力机制的樱桃缺陷检测识别研究
2024-06-11 04:33:16代东南马睿刘起孙孟研马德新
山东农业科学 2024年3期
代东南 马睿 刘起 孙孟研 马德新

摘要:针对现有樱桃缺陷检测识别中存在的问题,为实现移动端智能化快速检测与精准识别,本研究提出了一种基于卷积神经网络对樱桃图像进行缺陷检测识别的轻量化模型,可为开发樱桃的移动端无损化智能检測系统奠定理论基础。首先,将采集到的完好樱桃、刺激生长樱桃、双胞胎樱桃和腐烂樱桃4类樱桃图像经预处理后按比例划分训练集、验证集和测试集。其次,基于迁移学习对比分析NASNet-Mobile、MohileNetV2、ResNet18、InceptionV3、VGG-16网络模型后,选择各方面性能表现良好的MobileNetV2为基线模型,通过微调构建I-MohileNetV2模型:然后在I-MohileNecV2基础上,嵌入坐标注意力(CA)模块,构建ICA-MohileNetV2模型,该模型平均准确率达到97.09%,相比于基线模型(90.02%)提高7.85%,比I-MobileNetV2模型(94.34%)提高2.91%。可见,ICA-MobileNetV2作为可部署移动端的轻量化模型,具有较高准确率和较少参数,适用于樱桃缺陷检测与多分类任务,为樱桃缺陷检测与品质分级研究提供了新思路。
关键词:樱桃;缺陷检测;卷积神经网络;坐标注意力机制
中图分类号:S126 文献标识号:A 文章编号:1001-4942(2024)03-0154-09
樱桃富含大量铁元素和多种维生素,并以富含维生素C闻名于世,具有美容养颜、排毒祛湿、补血等多种功效。世界上樱桃主要分布在美国、加拿大、智利等地,中国主要产地为山东、安徽、江苏等。樱桃在生长过程中,受遗传、环境压力、植物生长调节剂使用不当和病虫害侵袭等的影响,易形成刺激生长樱桃、双胞胎樱桃等畸形果。畸形果占比是樱桃品质分级的关键指标,NY/T2302-2013《农产品等级规格樱桃》规定:特级樱桃中不能有畸形果:一级樱桃中畸形果占比≤2%;二级樱桃中畸形果占比≤5%。由此可见,樱桃缺陷准确识别对于提高其整体质量评估、减少经济损失以及优化H动化采摘系统具有重要意义。目前,樱桃缺陷的检测识别主要依赖人工目视检测,这种方法既耗时费力,也不适合大批量检测,且会造成一定资源浪费。因此,开发一种准确、高效且无损检测樱桃缺陷的方法具有重要的实际应用价值。
深度学习(deep learning,DL)是一种表示学习方法,与传统的机器学习方法相比能更好地提取数据特征,目前在果实识别、病害检测等农业生产活动中应用较广泛。如Hossain等用深度学习方法搭建了水果识别框架:张永飞等提出了一种基于深度学习的关键点检测方法,能对樱桃的大小分级和有无果梗进行准确判别。基于深度学习的卷积神经网络(convolutional neuralnetworks,CNN)可通过自动提取并学习数据的多层表征来实现对复杂模式的模型构建,现已有AlexNet、VGG、GoogeNet、Inception、ResNet等卷积神经网络被提出,这为提高图像识别分类精度提供了新的技术支持。周辉礼利用CNN依据苹果表皮成熟度进行分级,准确率为82%:Nithya等利用基于深度CNN的计算机视觉系统对优质芒果进行分类,准确率达98%。但传统的CNN模型复杂度高,不易在移动设备上开发应用,如李天华等发现基于深度学习的视觉识别算法是采摘机器人的关键技术之一,但其在实际运用中难以兼顾实时性和精准性。因此,建立便于移动端搭载的高效CNN模型对于拓展其实际应用领域具有深远意义。
目前基于CNN对樱桃缺陷检测识别的研究相对较少,且大多研究中使用的网络模型参数量大,难以在移动端部署。刘洋等综合比较Mo-bileNetV1模型和InceptionV3模型后,发现Mo-bileNetV1模型部署在移动端性能更优。因此,本研究利用构建的4类樱桃数据集,以轻量化Mo-bileNetV2网络模型为基础,微调构建新的模块,并添加特征融合注意力机制,构建了ICA-Mobile-NetV2模型,获得了较高的樱桃缺陷检测准确率,且模型稳定性较好,适合移动端搭载,可为进一步开发樱桃缺陷在线识别系统提供技术支撑。
1 材料与方法
1.1 数据集构建
1.1.1 图像采集
供试樱桃品种为市面常见的甜樱桃主栽品种之一红灯樱桃。在5月下旬红灯樱桃成熟期,于青岛平度、青岛崂山、烟台福山樱桃产区采摘樱桃样品,然后在室内自然光照下采集樱桃图像,即:以A4白纸为背景,固定位置摆放樱桃,采用佳能EOS80D单反相机(1800万像素)进行拍摄。共采集1549幅图像,建立完好樱桃、刺激生长樱桃、双胞胎樱桃、腐烂樱桃4类数据集。各类樱桃示例见图1。随机对每类樱桃图像进行划分:70%作为训练集,20%作为验证集,10%作为测试集。各类数据集划分详情见表1。
1.1.2 图像预处理
由于采集的样本量较小,模型可能面临泛化能力不足的问题。为解决此问题,采用数据增强技术如随机旋转、水平翻转、垂直翻转、对比度调整和亮度调整等来扩充数据集。以刺激生长樱桃图像为例,经过数据增强处理后的效果如图2所示。
为了进一步解决数据集中不同类别图像数量占比不均的问题,采用数据平衡算法计算权重。设总类别数为C,类别i的样本数为ni,总样本数为N,那么,类别i的权重wi计算为:
wi=N/(C×ni)。
该算法将不同类别映射为不同权值,从而实现各数据集间的数据平衡,有助于提高深度学习模型在图像分类任务中的性能。
1.2 试验环境与参数设置
本试验基于TensorFlow平台,采用Keras深度学习框架。运行环境为Windows10专业版(64位)操作系统,处理器为Intel Core i5-7300HQ,内存8GB,显卡为NVIDIA GeForce CTX 1050,显存8CB。试验参数设置见表2。
1.3 模型性能评价指标
采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数(F1-Score)、混淆矩阵(Confusion Matrix)作为模型性能评价指标。其中,Accuracy为所有被正确识别的样本数占总样本数的比例:Precision是衡量模型正确预测能力的指标,为预测正确的样本数量占总体的比例:Recall表示在真实样本中被正确预测的样本数量占总样本的比例;F1-Score是结合Precision和Recall的综合指标,为Precision和Recall的调和平均数,取值范围是0-1,值越接近1表示输出结果越好。计算公式如下:
式中:TP表示实际为正也被预测为正的样本数量:FP表示实际为负但被预测为正的样本数量:FN表示实际为正但被预测为负的样本数量:TN表示实际为负也被预测为负的样本数量。
混淆矩阵又称可能性矩阵或错误矩阵,用于比较分类结果和实际测得值。作为可视化工具,可以把分类结果精度显示在一个混淆矩阵里。
1.4 模型构建
1.4.1 基线网络模型筛选
选择5种网络模型,包括MobileNetV2、NASNet-Mobile、VGG-16、In-ceptionV3、ResNet18,利用训练集数据进行模型训练。通过比较5种模型的识别效果(表3),Mo-bileNetV2模型具有较高的识别准确率,且模型参数量较小,易于后期在移动端设备部署。因此,本研究选用MobileNetV2作为基线网络模型。
1.4.2 MobileNetV2网络结构
MobileNetV2是2018年Sandler等提出的一款轻量型CNN模型。MobileNetV2采用深度可分离卷积代替普通卷积,可减少卷积核参数量,降低计算复杂度以加快运行速度,从而使模型轻量化,利于面向实际的移动端应用场景。MobileNetV2网络由卷积层、池化层以及系列瓶颈结构(Bottleneck)构成,见表4,其中Conv2d为普通的标准卷积操作,Avgpool表示全局平均池化。
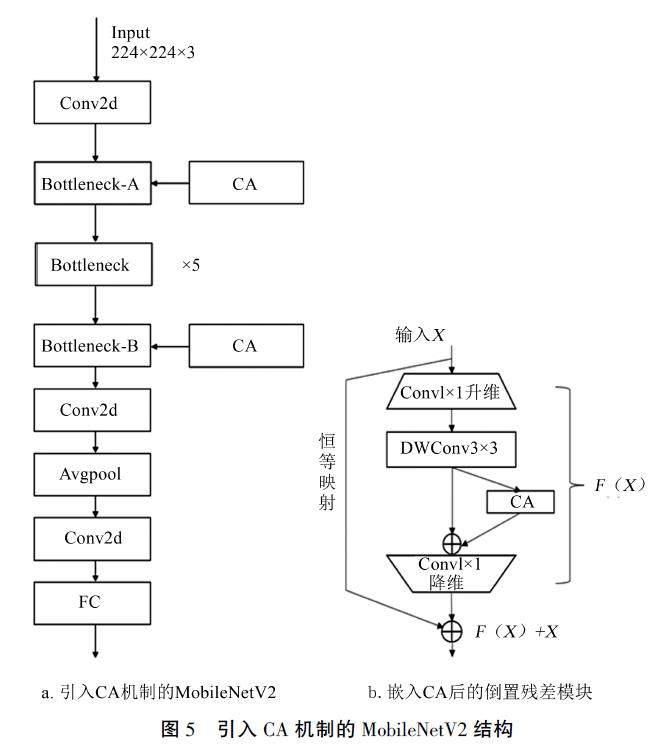
Bottleneck结构(图3)在MobileNetV2中起到降低参数量、减少计算复杂度并提高计算效率的作用,由三层组成:1×1的卷积层(扩展层)、3×3的深度可分离卷积层以及1×1的卷积层(投影层)。扩展层用于将输入特征图的通道数增加,即扩大其表示能力:紧接着的3x3深度卷积层通过分离通道间的卷积操作来减少计算量:投影层将扩展后的特征图压缩回原通道数,避免了过多的信息丢失。Bottleneck结构有效地实现了计算资源与模型性能之间的平衡,确保了模型在维持高效率的同时,也能够提供杰出的性能表现,使得MobileNetV2模型在资源受限的设备上仍具有较好的适用性。
1.4.3 基于预训练模型的迁移学习策略
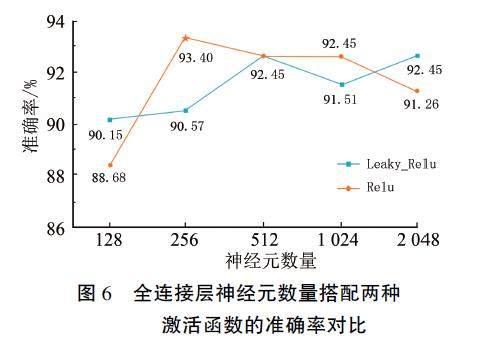
基于预训练模型的迁移学习策略是一种将现有预训练模型(例如在ImageNet上训练过的深度卷积神经网络)作为新任务的基础结构,并在此基础上进行修改和扩展的方法。该策略可以通过利用预训练模型中已经学到的通用特征提取能力,加速新任务的学习过程,并提高模型的性能。本研究使用MobileNetV2作为预训练模型,在此基础上构建新的全连接层,以帮助MobileNetV2模型更好地适应樱桃分类任务,捕捉到相关特征。考虑到全连接层不同的神经元个数搭配不同的激活函数对网络学习能力和泛化能力的影响,即较多的神经元数量可能会提高模型的表示能力和拟合能力,但同时也可能增加计算量和过拟合的风险,反之,较少的神经元数量会降低计算量和过拟合风险,但可能限制模型的表示能力,因此,本研究将128、256、512、1024、2048这5种不同数量的神经元,分别搭配Relu与Leaky-Relu两种激活函数,设计5种不同的模块进行逐一对比,并对4种学习率(0.1、0.01、0.001、0.0001)进行测试,选出性能表现优秀的一组参数搭配作为后续试验的默认参数设置。
1.4.4 特征融合注意力机制
注意力机制(atten-tion mechanism)是机器学习中的一种数据处理方法,广泛应用在自然语言处理、图像识别等各种类型的机器学习任务中,主要使网络能够更加关注于重要的局部信息。Hou等在2021年提出了一种为轻量级网络设计的注意力机制,称为坐标注意力(coordinate attention,CA),其结构如图4所示。CA通过在x和y两个方向上进行全局池化,将输入特征在垂直和水平方向上聚合为两个独立的方向感知特征图。与SE通道注意力不同,CA机制中每个注意力图都捕获了输入特征图沿着一个空间方向的长程依赖关系。CA机制通过将空间坐标信息与通道特征加权融合,既提高了模型特征表示能力,又能增强模型泛化能力,避免增加计算量的同时扩大感受野。
因CA灵活高效,可将其插入轻量级网络以提高网络精度。本研究将CA模块添加至Mobile-NetV2网络模块Bottleneck倒置残差结构的3×3深度可分离卷积与1×1卷积之间,以提高卷积层的注意力和感知力,进而提高模型的感知精度和分类性能,同時还能减少模型参数和加速模型训练过程。引入CA的MobileNetV2结构如图5所示。
2 结果与分析
2.1 迁移学习策略中相关参数的测试调整
2.1.1 全连接层神经元与激活函数的确定
从图6可见,当神经元个数为256、搭配Relu激活函数时,模型取得最高准确率93.40%,说明此时的模型非线性表达能力和学习能力较原始模型有显著增强。全连接层神经元数量继续增加,两种激活函数间的差别缩小,且准确率出现一定的下降,这可能是因为随着神经元个数的增加,模型复杂度提高,运算效率降低,产生过拟合趋势。因此,最终确定神经元个数为256,搭配Relu激活函数。
2.1.2 学习率的确定
学习率(learning rate,Lr)是训练模型时用于控制模型权重更新幅度的超参数。过低的学习率易导致收敛速度较慢,困在局部最小值附近:过高的学习率则易导致训练过程不稳定,甚至无法收敛。本研究在控制其他变量相同的条件下,对0.1、0.01、0.001、0.0001这4种学习率进行测试,结果(图7)显示,当将学习率设置为0.001时,训练过程较为平稳,模型稳定性增强,收敛速度快,准确率提高。
经过上述测试分析,最终确定学习率为0.001、全连接层神经元个数为256并搭配Relu激活函数的效果最好,由此组合成微调模块后的网络模型I-MobileNetV2。
2.2 注意力机制对模型性能影响分析
在I-MobileNetV2基础上,添加CA模块,组合成新的网络模型ICA-MobileNetV2。对I-Mo-bileNetV2、ICA-MobileNetV2與未调整的Mobile-NetV2模型的识别效果进行对比,结果(图8)显示,ICA-MobileNetV2准确率明显高于Mobile-NetV2和I-MobileNetV2模型,曲线振荡幅度变小,且损失值下降更快。表明改进后的ICA-Mo-bileNetV2模型性能提升,能快速平稳收敛,而且收敛后的损失值也明显低于改进前。
为进一步证实模型改进的有效性,本研究又进行了消融试验,即在参数不变的情况下,在I-MobileNetV2与MobileNetV2的同一位置分别添加SA(spatial attention)、SE(squeeze-and-excita-tion)和CBAM(convolutional block attention mod-ule)三种注意力模块,对比分析这些改进模型与本研究提出模型ICA-MobileNetV2在验证集上的准确率。由表5可以看出,本研究提出的ICA-MobileNetV2模型对樱桃缺陷识别的准确率最高,达到97.09%,明显高于其他模型1.08-7.04个百分点。
2.3 ICA-MobileNetV2模型的樱桃识别效果分析
利用测试集的樱桃图像数据对ICA-Mobile-NetV2模型的识别效果进行评价。结果(表6)显示,该模型对双胞胎樱桃的识别效果最好,准确率、精确度、召回率、F1分数均达到100%。基于F1分数,该模型对四类樱桃的识别效果排序为双胞胎樱桃>完好樱桃>腐烂樱桃>刺激生长樱桃。总体来看,ICA-MobileNetV2模型对四类樱桃的识别分类效果较好,各指标均值都达到97%。
图9是ICA-MobileNetV2测试结果的混淆矩阵。可见,预测值密集分布在对角线上,仅个别出现分类错误,这可能是因为部分刺激生长情况相对不明显的樱桃以及腐烂范围较小的樱桃与完好樱桃间相似度较高,特征提取过程中不易区分,从而导致识别错误。
3 结论
本研究通过对比分析VCG-16、ResNet18、NASNet-Mobile、MobileNetV2、InceptionV3模型的识别效果,选择参数量小且准确率较高的轻量级模型MobileNetV2作为基线网络模型。在此基础上,对迁移学习策略中的神经元数量、激活函数及学习率进行测试,构建了一个新的I-MobileNetV2模型,在预处理后的樱桃数据测试集上,达到了94.34%的识别准确率:进一步在I-MobileNetV2网络的残差结构中添加CA模块,构建了ICA-MobileNetV2模型。用验证集樱桃图像对ICA-MobileNetV2模型进行检验,识别准确率达到97.09%,可以实现对缺陷樱桃的高效识别与分类。
本研究基于特征融合注意力机制实现对缺陷樱桃的识别,不仅省时省力,可有效减轻人工分拣对樱桃果实的二次损伤,而且轻量化的网络结构也提高了其在可移动智能筛选设备中部署的可行性。后续将增加樱桃品种及缺陷样本种类,丰富数据集,同时继续优化模型,提高其识别速度和能力,以更好地投入到生产实践中。
基金项目:山东省自然科学基金项目(ZR2022MC152);山东省高等学校青创人才引育计划项目(202202027)
猜你喜欢
金桥(2022年2期)2022-03-02 05:43:04
人大建设(2018年5期)2018-08-16 07:09:08
喜剧世界(2017年13期)2017-07-24 15:43:42
中国高新技术企业(2016年34期)2017-02-10 16:40:20
计算机应用(2016年12期)2017-01-13 20:26:21
计算技术与自动化(2016年4期)2017-01-11 14:19:49
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
电脑知识与技术(2016年10期)2016-06-16 21:27:26
科技视界(2016年3期)2016-02-26 11:42:37
