
面向食品安全法规的知识图谱构建
2024-06-03 15:50:16张馨月王宁张瑶瑶
现代信息科技 2024年6期
张馨月 王宁 张瑶瑶
收稿日期:2023-08-18
基金项目:太原科技大学教学改革创新项目(XJ2021004)
DOI:10.19850/j.cnki.2096-4706.2024.06.023
摘 要:我国建立了完备的食品安全法规体系,其具有海量和零散性的特点,难以检索分析。以食品安全法规文本数据为依托,通过自顶向下和自下而上的方式进行食品安全法规知识图谱的构造研究。首先,获取多源异构的食品安全法律法规和问答数据语料,对用户的需求进行分析。其次,定义食品安全知识图谱的本体层及其属性,使用基于规则的方法对知识进行抽取,针对规则性不强的知识,使用基于机器学习的命名实体识别方法完成领域命名实体识别。最后,实现食品安全法规知识图谱的构建。
关键词:食品安全法规;知识图谱;自然语言处理;机器学习;命名实体识别;BERT模型
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2024)06-0103-07
Construction of Knowledge Graph for Food Safety Regulations
ZHANG Xinyue, WANG Ning, ZHANG Yaoyao
(College of Computer Science and Technology, Taiyuan University of Science and Technology, Taiyuan 030024, China)
Abstract: China has established a complete food safety regulatory system, which is characterized by massive and fragmented nature and difficult to retrieve and analyze. Therefore, we conduct research on the construction of a Knowledge Graph of food safety regulations through a top-down and bottom-up approach based on the textual data of food safety regulations. First, we obtain multi-source heterogeneous food safety laws and regulations and Q&A data corpus, and analyzes user needs. Then, we define the ontology layer and attributes of the food safety Knowledge Graph. We extract the knowledge by using a rule-based method, and complete the domain named entity recognition by using Machine Learning-based methods for the knowledge with weak regularity. Finally, we realize the construction of Knowledge Graph for the food safety regulations.
Keywords: food safety regulation; Knowledge Graph; natural language processing; Machine Learning; named entity recognition; BERT model
0 引 言
“民以食为天,食以安为先”。食品安全是健康中国的重要内容,也是“五大公共安全”的重要内容之一[1]。2017年7月8日,国务院印发了《新一代人工智能发展规划》,其中提到促进人工智能在法律文件阅读与分析中的应用[2]。因此,使用人工智能技术来完成对食品安全法律法规的阅读与分析,是实现“舌尖上的安全”必不可少的環节之一。构建基于食品安全法律法规的知识图谱,不仅能够解决知识查询问题,还可以将食品安全法律法规中涉及的重点实体和层次等内容通过知识图谱中的边进行连接,这样就打破了法律法规的相对独立性,可以对法律法规的重要知识进行关联查询。
目前,知识图谱在司法领域的应用取得了一些进展。Li等人提出了事务的法律规定预测任务,并使用知识图谱中的文本理解和图推理的方式来完成任务[3]。Filtz等人构造了奥地利法律知识图谱,提出了LKG本体论。通过链接到地理名称和开放街道地图等外部空间知识库,对各种欧盟成员国的现有法律举措进行深度分析[4]。曾兰兰等人基于刑事裁判文书数据构建了刑事法律知识图谱[5]。
《规划》指出,要强化利用人工智能等计算机技术实现对食品安全的有效保护,在综合考量食品分类、预警水平、食品安全风险和评估等内容的基础上建立了人工智能食品安全预警系统[6]。但是我国针对食品安全法规知识图谱的构建和研究仍然处于起步状态,亟待我们进一步深入研究。
1 图谱概述
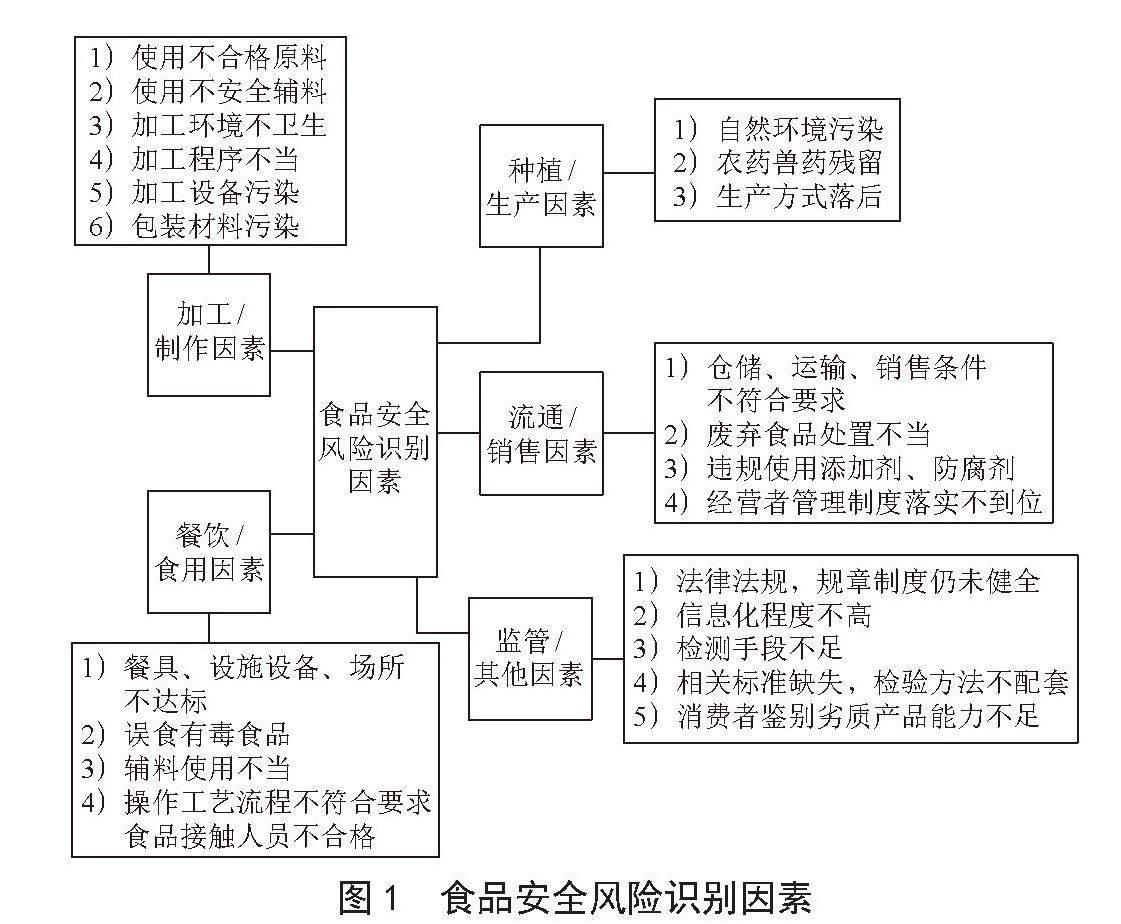
对用户需求的正确认知直接关系到所构建知识图谱质量的高低。本文将业内公认规模较大、可信度较高的“12348中国法网”等网站作为数据源,爬取主题为“食品”的法律咨询问答8 000余条,并进行了咨询用户画像和咨询问答分类分析,从而得到不同类别用户的具体需求。将如图1所示的风险识别因素作为领域实体进行存储,将因素的层次结构作为知识图谱模型构建的参考,并将它们补充进食品安全领域词典中。
图1 食品安全风险识别因素
与食品安全风险因素存在的各个阶段相对应,咨询用户的角色基本上可以分为四类,即生产者、销售者、网络食品第三方交易平台和消费者。他们所关心的问题具有相似性,可分为三类,即赔偿问题、行政处罚和刑事责任。经过整理分析,在用户进行搜索或提问之后,公共法律服务网站反馈给用户的搜索结果或回答包括两个方面的内容,一是违法犯罪行为或受到侵害行为所涉及的法规,包括具体的章节条例;二是相关的执法部门或可以求助的部门能够提供的具体帮助。其他详细的解答内容都是从这两个方面延伸出來的。
因此,本文旨在建立法律法规之间的联系,破除法律法规之间的独立性,以法律法规为核心对知识进行重载利用。食品安全法规知识图谱作为领域知识图谱,主要强调知识的体系结构和深层次的领域知识,因此采用自顶向下和自底向上相结合的方式进行构建。本文结合食品安全相关行政法规、司法解释以及地方政府规章文本数据的逻辑特点,对知识图谱进行设计。数据来源为全国人大常委会、国务院、国家质量监督检验检疫总局、国家食品药品监督管理总局、中央编办、地方食品药品监督管理局等网站公开发布的有关食品安全的一般法律、条例、决定、办法等共计3 474篇(截至2023年4月)。在构建食品安全法规知识图谱时,首先定义食品安全法律政策体系,并根据该体系形成本体概念。我国的食品安全政策体系包含法律、法规、部门规章、规范性文件等,形成了国家、部门、行业与地方逐层约束的食品安全法规体系,具有“二元制”和“多层次”的特点。在《中华人民共和国食品安全法》和《中华人民共和国农产品质量安全法》的指导下,全国人民代表大会及其常务委员会制定了法律,涵盖立法、执法、法律监督、刑罚和行政处罚等各个方面。在食品安全法律法规体系的纵向关系上,法律、法规、部门规章、规范性文件和安全标准之间需要相互协调,彼此衔接,下一层的立法不能和上一层的立法相互抵触,也就是遵守“法制统一”的原则。
2 知识图谱模式层设计与构造
2.1 总结和分析食品安全法规领域本体
首先,构建知识图谱模式层,定义本体概念及属性:
1)法规。是食品安全法规知识图谱中的核心概念。使用法规名称、主席令号、发布时间、施行时间、立法主体、法规目录、施行范围、效力等级、涉及执法部门、规定过程、规定责任部门、参考文件、制定依据、法规条文等属性对法规进行描述。
2)相关部门。每篇法规都会涉及立法主体、执行某些条款、触犯某些条款所牵涉的执法部门、责任部门。
3)品类领域。在不同类型的法律法规中,所要针对和规范的生产品类、角色品类可能类似,也可能不同,因此其实体内容非常广泛,生产品类如养殖业、捕捞业等,角色品类如药品生产企业、药品经营企业等,它们在法规中都属于被定义和被规范的内容。
4)规定过程。由于食品安全法规覆盖了从种植养殖、生产、加工经营、检测到流通消费的全过程,所以将规定过程定义为知识图谱中的一个本体,通过将本体实例化来描述规范过程。
5)规定对象。覆盖了大部分食品类别,是参照了GB 2760-2014国家标准中的附录E食品分类系统所定义的本体,与规定过程相对应。若某一法规约束了某一食品类别下的食品,则可以将该食品作为这一食品类别下其他食品的参考。
2.2 定义本体之间的关系
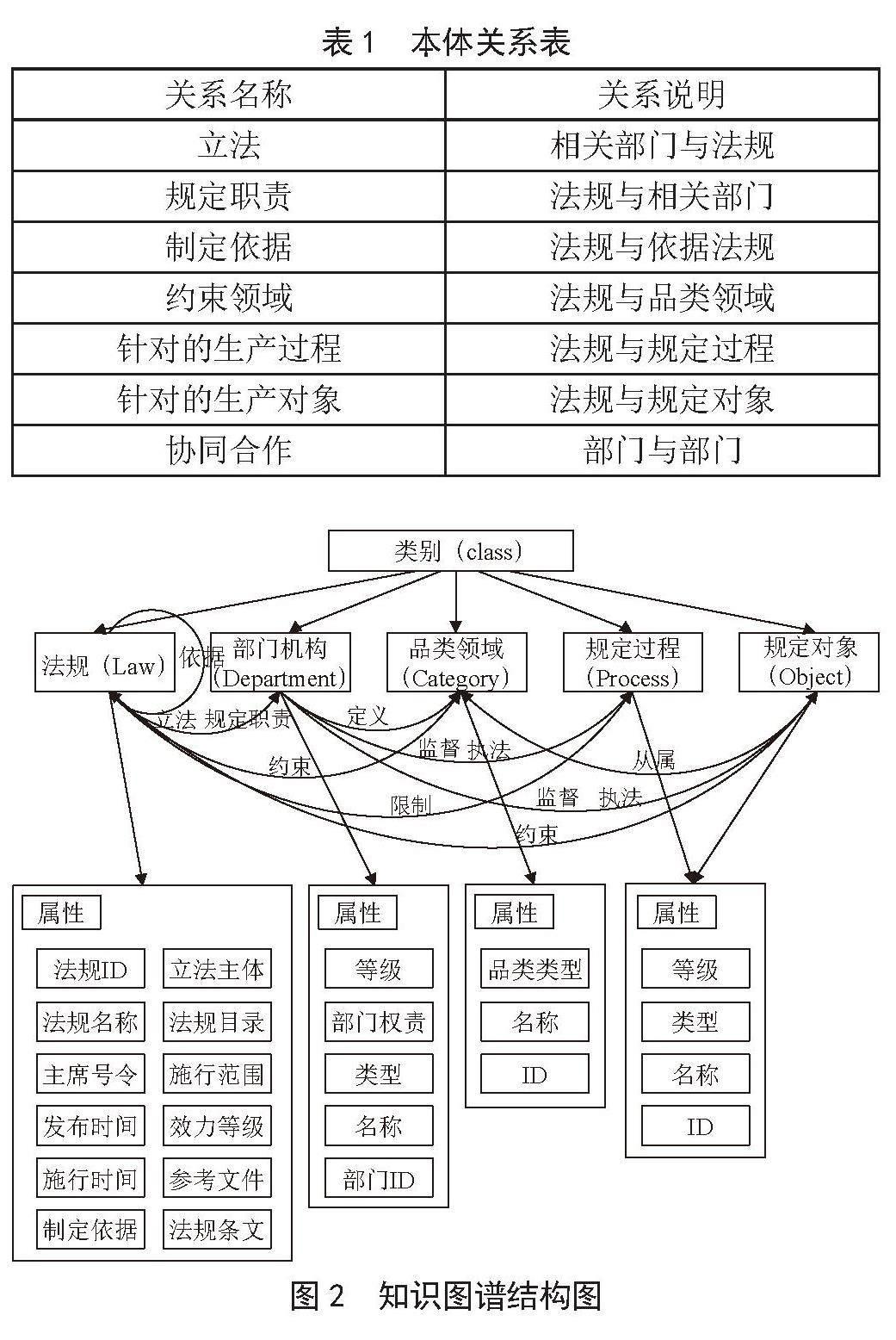
在关系方面,从当前法规的独立性出发,以法规为核心,将法规与相关部门、品类领域、规定过程、规定对象的关系进行知识图谱的语义关系定义,如表1所示。食品安全法规知识图谱的结构如图2所示。通过命名实体识别方法和基于规则的实体、实体属性和实体关系抽取方法,能够将本体实例化,并存入数据库中,构造知识图谱。
表1 本体关系表
关系名称 关系说明
立法 相关部门与法规
规定职责 法规与相关部门
制定依据 法规与依据法规
约束领域 法规与品类领域
针对的生产过程 法规与规定过程
针对的生产对象 法规与规定对象
协同合作 部门与部门
图2 知识图谱结构图
3 知识抽取
3.1 主题词提取
通过提取食品安全法律法规的所有章节名实体来概括该法规的文本内容。为了进一步补充法规内容特征,对每篇法规进行内容提取,获得特征项。食品安全法律法规的原始数据中包含有大量的领域特征词汇,如果将这些特征词汇作为特征项,会给后续处理工作带来很多不必要的麻烦。因此,使用TF-IDF函数从特征词汇中提取出主题词来表示食品安全法律法规的主要特征,能够概括法规的文本内容。
我国的法律法规文本与新闻报道等文本存在着很大的区别。它们的书写格式、段落结构、遣词造句都必须要符合一定的规范。因此,一些实体、实体属性都可以通过基于规则的方法进行抽取,并且能够取得较好的抽取效果。特殊用语描述内容的附近会有明显的提示词,可以用来提取扩充实体。
3.2 基于BERT-BiLSTM-CRF的命名实体识别
BiLSTM-CRF模型是将双向长短期记忆网络(BiLSTM)和条件随机场(CRF)有机结合的命名实体识别模型[7]。命名实体识别问题实际上是一个序列标注问题。本文使用BIO标注集对数据字符进行标注。BiLSTM模型是由一个正向LSTM和一个反向LSTM组合而成的,对输入的字符序列进行两个方向的计算,能够用到两侧的上下文信息。Softmax输出的概率相对独立,输出值之间不存在依赖关系,在每一步选出一个概率最大的值,输出其对应标签,会生成不符合语义逻辑的标签序列。CRF层将输出层面的关联性进行分离,进行标签预测时将上下文关联情况考虑在内。此外,在求解维特比时,CRF使用动态规划算法来求解概率最大的路径,可以防止结果中出现非法序列,比如“B-OBJ”后面跟着“I-DEP”。
假设字符序列输入的是X = (x1,x2,x3,…,xn),获取到输入序列后,进行分布式表示,经过BiLSTM层的学习之后,输出概率矩阵Pn×m,其中m表示标签的类别个数。对于想要输出的标签序列y = (y1,y2,y3,…,yn),定义最优路径得分,如式(1)所示:
(1)
最优路径求解如式(2)所示:
(2)
其中,Pi, j表示xi被标记为第j个标签的概率大小,Ai, j表示概率转移矩阵中第i个标签被转移到第j个标签的概率。由此可知,CRF建模输出标签二元组,并且使用动态规划的算法求出得分最高的路径y?作为最优路径。如图3所示为BiLSTM-CRF模型的网络结构。
训练BiLSTM网络结构需要将预处理后的食品安全法律法规汉字语料输入到待训练的神经网络模型中,但是神经网络模型不能接收汉字,汉字字符串的长度也互不相同。因此本文采用BERT模型进行字符向量的编码,解决了Word2Vec歧义词效果不佳的问题[8]。BERT模型能够通过在所有层上下语境的基础上实现联合调整的方式来预训练深层双向表征。只要额外增加一个输出层,即可对预训练的BERT表征进行微调,使它更加适合新任务和新模型。组成BETR的核心模块是12层或24层的双向Transformer,其最为关键的部分是Attention机制。相对于RNN,双向编码器Transformer更加高效,能够捕捉到更长距离的依赖。相对于LSTM,Transformer能够并行训练,达到更快的训练速度。
在BERT模型后接入BiLSTM-CRF网络结构,使用BiLSTM获得每个实体类型标签的得分,并通过CRF借助维特比算法挑选出概率最大的标签类型。BERT-BiLSTM-CRF的网络模型如图4所示。
图4 BERT-BiLSTM-CRF模型结构示意图
其中,Ei表示序列中第i个位置的输入。由图4可以看出,BERT-BiLSTM-CRF模型通过将BERT模型的输出作为特征表示加入BiLSTM模型中。因为需要海量数据和强大的计算能力来支持模型的训练,本文使用了针对中文语料的Bert-Base-Chinese版本。
3.3 命名实体识别实验分析
利用YEDDA文本标注工具,参照BIO标准对数据集进行类型标注。对改进后的CRF模型、BiLSTM-CRF模型和BERT-BiLSTM-CRF模型在有效食品安全相关行政法规、司法解释以及地方政府规章文本数据中命名实体的识别效果上进行了比较,实验中采用的评价指标是机器学习中常用的评价機制准确率、召回率和F1值。
其中准确率的求解如式(3)所示:
(3)
其中,P表示命名实体识别实验的准确率,Q表示结果中被正确识别的词语数,R表示结果中所有的实体数。召回率的求解如式(4)所示:
(4)
其中,R表示命名实体识别实验的召回率,Q表示结果中被正确识别的词语数,T表示文本中所有应当被识别的实体数。F1值的求解如式(5)所示:
(5)
3.3.1 CRF模型实验
实验中使用食品安全法律法规文本涉及的词汇和词性作为词的特征输入,借助CRF++0.58工具包实现对食品安全法律法规文本的命名实体识别。CRF模型训练需要特征模板,以便通过训练集提取特征函数。如图5所示为特征模板的部分截图。
图5 定制CRF特征模板
其中,U表示模板类型是Unigram Feature,每行中的% x[m, n]表示生成一个CRF中的点函数。
3.3.2 BiLSTM-CRF模型实验
针对该模型使用不同参数值进行了多组实验,根据实验机器具体环境修改Batch size参数为20,根据模型训练效果修改Dropout为0.5,修改Learning rate为0.001。
3.3.3 BERT-BiLSTM-CRF模型实验
在BERT-BiLSTM-CRF网络模型实验中,使用到的训练数据如上文所述。由于数据和实验配置所限,选择Bert-Base-Chinese版本进行实验,并选用模型中的默认参数。其中sequence length设置为128,以减少因句长过短导致的命名实体漏检。
为了测试添加了特征的CRF模型、BiLSTM-CRF模型、BERT-BiLSTM-CRF模型在食品安全法律法规数据集上的效果,文章将这些模型应用在命名实体识别任务中,设置了对比实验来验证模型的有效性,如图6所示。
图6 实验结果对比图
在食品安全法律法规数据集中,CRF模型取得了比BiLSTM-CRF模型更为优越的效果,验证了对数据进行预处理时根据数据特点对特征模板进行定制的实效性。BERT-BiLSTM-CRF模型取得了最好的效果,相对于BiLSTM-CRF模型,前者的领域命名实体准确率提高了0.22%,领域命名实体召回率提高了3.94%,F值提高了1.91%,说明它捕捉到了更长距离的依赖和上下文信息,能够显著改良食品安全法律法规领域的命名实体识别。
使用BERT-BiLSTM-CRF模型识别并抽取出法规施行时间、地点、部门机构、规范对象、约束食品类别等实体,作为对食品安全法规知识图谱的实体扩充。将结果与《GB 2760—2014食品添加剂使用标准》《T/CFLP 0022—2019食品冷库温度监测规程》等领域的标准和规范进行对照,保证识别结果的有效性和科学性。抽取后有效的食品安全法规实体数据量如表2所示。
表2 识别实体统计表
实体类型 制定施行时间 地点名称 部门机构 规范对象 约束食品类别
实体个数 2 570 1 020 417 976 406
3.4 知识抽取评价
知识抽取是知识图谱构建过程中的关键步骤,知识抽取的效率和准确性决定了所构建知识图谱的质量,因此评价食品安全知识图谱和基于食品安全知识图谱的分析系统,需要对知识抽取的有效性进行验证。根据食品安全政策体系,将法规分为六类,并从每类法规中随机抽取法规文本段进行抽取评估,比较模型抽取的效果。如表3所示,抽取准确率较高,但在发生前缀、后缀省略和术语位置更换用词等情况时,会出现抽取识别失败的问题。
4 知识图谱的存储
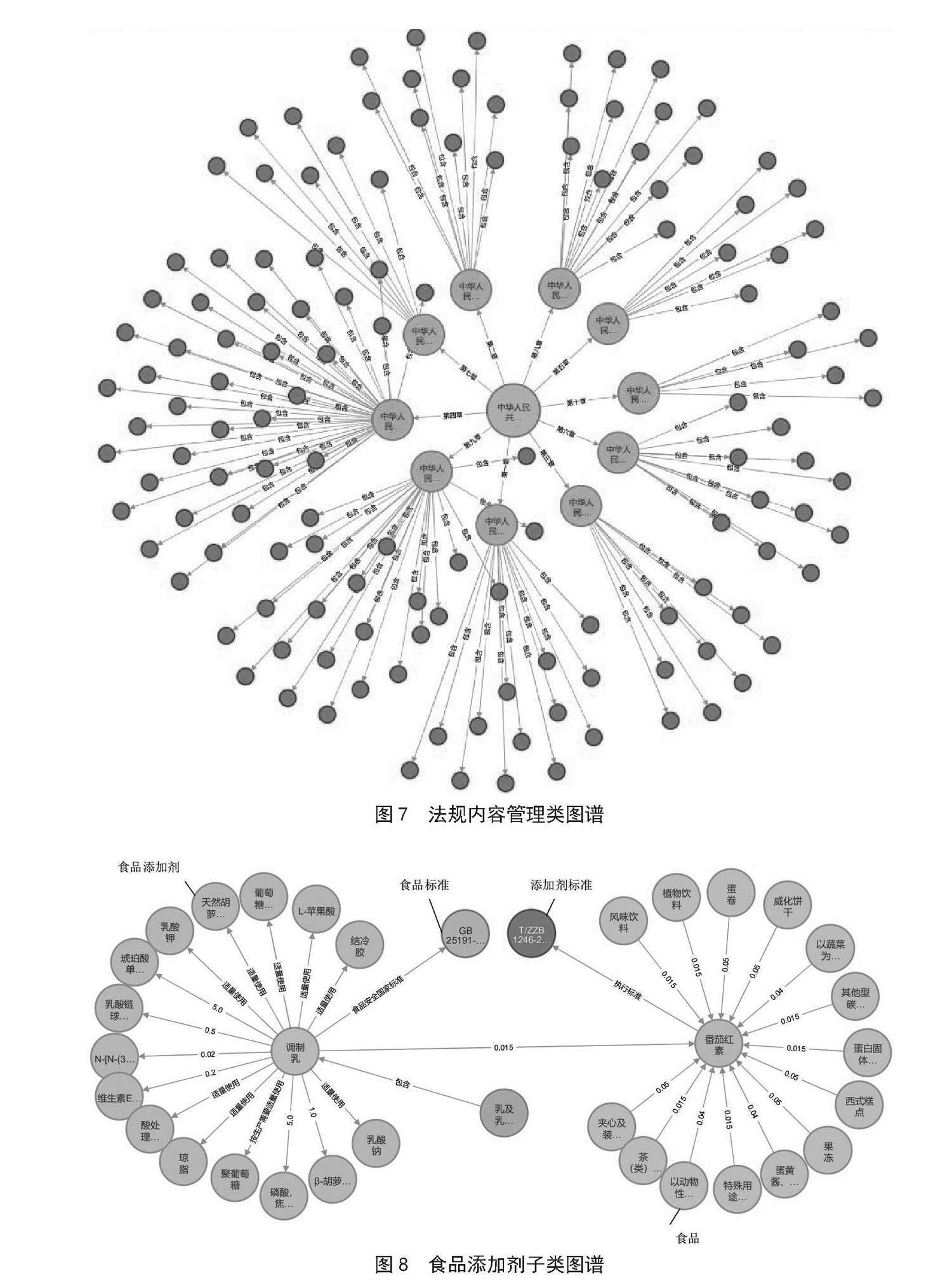
根据知识图谱中知识的类别,对实体、实体属性和实体关系进行存储。本文中采用Protégé工具[9]进行了本体的创建和存储。对于实体和实体之间的关系,如国家层面的政策法规与国家级的食品安全监管部门建立的联系,规范某个食品类别的法规与生产企业、食品对象建立的联系等,需要用三元组的形式进行存储,使用Neo4j数据库进行有效表示,构建食品安全法规知识图谱。例如,为了满足用户对《食品安全法》具体章节条目内容的需求,本文将法规章节、法规条目作为实体内容与法规名称实体建立包含关系,组成实体关系三元组数据,并将其导入Neo4j数据库[10]中,形成法规内容管理类图谱,如图7所示。
表3 知识抽取对比表
基本法律 《中华人民共和国畜牧法》已由中华人民共和国第十届全国人民代表大会常务委员会第十九次会议于……自2006年7月1日起施行 《中华人民共和国畜牧法》->法规名称
全国人民代表大会常务委员会->部门机构
2006年7月1日->施行时间
行政法规 其他食品生产经营者应当在依法取得相应的食品生产许可、食品流通许可、餐饮服务许可后,办理工商登记 食品生产经营者->规范对象
食品生产经许可->规范对象
食品流通许可->规范对象
餐饮服务许可->规范对象
工商登记->规范对象
部门规章 生产企业必须在巴氏杀菌乳和超高温灭菌乳包装主要展示面上紧邻产品名称的位置 生产企业->规范对象
巴氏杀菌乳->约束视频类别-乳及乳制品
灭菌乳->约束食品类别-乳及乳制品
当用户查询有关某种食品添加剂的问题时,结合食品名称,通过知识图谱挖掘到相关规章对于该添加剂功能、最大使用量和使用标准的约束。构建<约束食品名称>-<最大使用量>-<食品添加剂>三元组,将所得到的三元组数据存储到Neo4j数据库中。如图8所示为食品添加剂子类图谱。
5 结 论
通过爬虫技术获取了多源异构的食品安全法律法规等相关语料和法律咨询网站的问答数据语料。根据问答数据语料对用户的需求进行分析,總结出用户的知识盲点和搜索重点,以此确定研究方法和研究内容。在处理食品安全法律法规文本时,根据法律法规文本用词比较规范的特点,使用基于规则的方法对部分实体、实体属性和实体关系进行抽取。对于规则不明显的非结构化法律法规文本语料,采用命名实体识别的方法完成领域命名实体识别。将抽取出的实体、实体属性和实体关系存入图数据库,构建食品安全法规知识图谱。
参考文献:
[1] 蔡娇丽.国民收入、健康不平等与健康产业发展 [D].武汉:武汉理工大学,2019.
[2] 张子洞.浅谈人工智能产业的创新与发展——统筹推进现代化经济体系建设 [J].新丝路:上旬,2021(1):1-3.
[3] LI L Q,BI Z,YE H B,et al. Text-guided Legal Knowledge Graph Reasoning [C]//Knowledge Graph and Semantic Computing: Knowledge Graph Empowers New Infrastructure Construction. Singapore:Springer,2021:27-39.
[4] FILTZ E,KIRRANE S,POLLERES A. The Linked Legal Data Landscape: Linking Legal Data across Different Countries [J].Artificial Intelligence and Law,2021,29(4):485-539.
[5] 曾兰兰.刑事法律知识图谱构建技术研究 [D]. 贵阳:贵州大学,2023.
[6] 徐博.当前我国智慧法院建设问题研究 [D].武汉:华中师范大学,2019.
[7] DANG N C,MORENO-GARC?A MN,PRIETAF D L. Sentiment Analysis Based on Deep Learning: A Comparative Study [J/OL].arXiv:2006.03541v1 [cs.CL].(2020-06-05).https://arxiv.org/abs/2006.03541.
[8] MU X F,WANG W,XU A P. Incorporating Token-level Dictionary Feature into Neural Model for Named Entity Recognition [J].Neurocomputing,2020,375:43-50.
[9] MUSEN M A. The Protégé Project: a Look Back and a Look Forward [J].AI Matters,2015,1(4):4-12.
[10] FERNANDES D,BERNARDINO J. Graph Databases Comparison: AllegroGraph, ArangoDB, InfiniteGraph, Neo4J, and OrientDB [C]//Proceedings of the 7th International Conference on Data Science, Technology and Applications DATA. Porto:Scitepress Digital Library,2018:373-380.
作者简介:张馨月(1995—),女,汉族,山西太原人,助教,硕士研究生,研究方向:知识图谱。
猜你喜欢
计算机应用(2016年12期)2017-01-13 01:24:36
科技创新与应用(2016年31期)2016-12-03 03:33:48
新教育时代·教师版(2016年33期)2016-12-02 22:26:31
智富时代(2016年12期)2016-12-01 16:28:41
时代金融(2016年27期)2016-11-25 17:51:36
中国远程教育(2016年9期)2016-11-19 12:21:26
科教导刊(2016年26期)2016-11-15 20:19:33
中国教育信息化·基础教育(2016年9期)2016-10-18 02:29:50
科学与财富(2016年28期)2016-10-14 21:19:17
电脑知识与技术(2016年10期)2016-06-16 21:16:32
