
安检图像小目标违禁品特征提取模块构建与应用
2024-06-01 11:14:29刘天时周泽华郝敏杰
现代信息科技 2024年4期
关键词:计算机视觉
刘天时 周泽华 郝敏杰

收稿日期:2023-10-26
DOI:10.19850/j.cnki.2096-4706.2024.04.029
摘 要:针对物流包裹安检图像中小目标违禁品易漏检问题,通过在感受野模块的多分支并行网络上引入卷积注意力模块,构建一种适用于小目标违禁品检测的特征提取模块。在此基础上,将构建的特征提取模块融入YOLOv5模型的主干部分,使得模型在违禁品检测的过程中聚焦于图像的重要特征。为了充分发挥所构建模块对于小目标物体的特征提取能力,采用空间深度转换模块替代原模型中的下采样模块,使得YOLOv5模型在特征提取的过程中能够尽可能地保留小目标物体的特征信息,提高对小目标违禁品的检测效果。
关键词:安检图像;小目标违禁品;特征提取模块;计算机视觉;物流包裹
中图分类号:TP391.4;TP18 文献标识码:A 文章编号:2096-4706(2024)04-0136-06
Construction and Application of a Feature Extraction Module for Small Target Prohibited Items in Security Inspection Images
LIU Tianshi, ZHOU Zehua, HAO Minjie
(School of Computer Science, Xi'an Shiyou University, Xi'an 710065, China)
Abstract: Aiming at the problem that small target prohibited items in logistics package security inspection images is easy to miss detection, a feature extraction module suitable for small target prohibited items detection is constructed by introducing a convolutional attention module on the multi-branch parallel network of the receptive field module. On this basis, the constructed feature extraction module is integrated into the backbone of the YOLOv5 model, so that the model focuses on the important features of the image in the process of prohibited items detection. In order to fully utilize the feature extraction ability of the constructed module for small target objects, a spatial depth conversion module is used to replace the downsampling module in the original model, so that the YOLOv5 model can retain the feature information of small target objects as much as possible during the feature extraction process, and improve the detection effect for small target prohibited items.
Keywords: security inspection image; small target prohibited item; feature extraction module; computer vision; logistics package
0 引 言
近年来,随着线上购物的快速普及,物流包裹数目的激增给安全监管带来了巨大的挑战。包裹限制品检测作为物流行业及安防行业提供安全保障的重要環节,承担着防止限制品进入货运渠道的重要任务。因此,必须通过提高安检工作质量的方式排除安全隐患。目前,物流包裹的安检工作主要是由安检员对安检图像进行肉眼判别和检查,这种安检方式的可靠性很大程度上依赖于安检人员的工作经验和状态[1]。但长时间从事大量的、单一的人工视检工作很容易造成安检员视觉疲劳、注意力难以集中,导致错检、漏检等现象发生,带来安全隐患。与普通自然图像不同,安检图像的成像效果与物体自身的密度、成分以及成像时的空间位置等因素有关[2]。在安检图像中原本空间上交错的物品,外形轮廓会发生重叠,这就给人眼识别造成较大的干扰。由于违禁品种类较为庞杂,不同类别甚至同一类别违禁品之间的轮廓、尺度也存在明显差异,特别是对于电池、打火机等小目标违禁品来说目前的检测效果还不够理想,这就要求针对违禁品的目标检测方法应具备检测密集分布物品和小目标物品的能力。造成小目标物体检测效果不够理想的因素主要分为以下几个方面:1)小目标物体分辨率较低,可利用的特征信息少,相较于大目标物体而言,小目标物体的特征信息更难以提取[3]。2)小目标物体容易受到遮挡、聚集以及周围噪声的影响。3)针对一些大型的图像公共数据集,其中绝大部分都是正常尺度的物体,小目标物体占比较少,容易造成数据不均衡的问题[4]。针对上述问题,国内外学者做出了一系列研究和改进,并取得了一定进展。Lin等人构建了一种具有横向连接的、自顶向下的特征金字塔网络FPN,使得浅层特征和深层特征能进行更好的融合[5]。PANet在FPN的基础上添加了一条自底向上的路径,进一步增强了整个特征层次的定位能力[6]。Lim等人将小目标物体的特征与来自深层次的上下文特征进行融合,为小目标特征补充了上下文信息,使得网络模型对于小目标物体的检测精度有所提高[7]。杨慧剑等人采用空洞空间池化金字塔模块代替SPP模块,以减轻池化操作带来的影响[8]。高伟等人采用超分辨率生成网络,将检测效果较差的低分辨率图像重构为高分辨率图像,可以提升模型对于小目标物体的辨识能力[9]。
综上所述,目前提高小目标物体检测效果的主要方法是对模型的特征融合模块进行优化,使得图像的细节信息和语义信息能够相互融合。然而,由于小目标物体本身分辨率较低,且容易受到背景和噪声的影响,这些融合模块很难充分地获取到小目标物体的特征信息。为此,本文设计并构建了一种特征提取模块(Attention-Receptive Field Block, Att-RFB),将其融入YOLOv5模型的主干部分,以增强模型对于小目标物体特征信息的提取能力,提高小目标违禁品的检测精度。
1 Att-RFB特征提取模块构建
1.1 CBAM卷积注意力模块
在实际的安检图像中,违禁品可能只占图像中的一小部分,大部分是一些无效的冗余背景。因此,在特征提取的过程中需要特别关注图像中的主体部分。卷积注意力模块(Convolution Block Attention Module, CBAM)由通道注意力和空间注意力两个子模块级联构成[10],该模块可以对输入图像的语义特征和位置特征进行自适应调整,避免模型在训练的过程中提取到过多的无效特征。CBAM模块架构如图1所示。
图1 CBAM模块架构
1.2 RFB感受野模块
感受野模块(Receptive Field Block, RFB)是基于人类视觉系统中感受野机制提出的一种特征提取模块[11],它采用了一种多分支并联的结构,在不同的分支上采用不同大小的卷积核来捕获多尺度信息,在通道维度上将各个分支提取的结果进行拼接,以实现多尺度特征信息的融合。除此之外,RFB模块还引入了空洞卷积的思想,根据卷积核的大小插入相应扩张率的空洞,可以在不增加额外参数量的条件下扩大感受野,使得卷积模块能在更大的范围内捕获信息,提高网络模型的特征提取能力。RFB模块的结构如图2所示。
图2 RFB模块结构图
1.3 特征提取模块构建
相较于图像中的中、大目标物体,小目标物体普遍存在由于分辨率低而导致特征信息难以提取的问题。在日常的违禁品检测任务中,物品的摆放位置具有一定的随机性,经常会出现大目标物体遮挡小目标物体的现象,对小目标物体的特征信息表达造成较大干扰,影响小目标物体的检测效果。虽然RFB模块可以捕获到不同尺度的特征信息,但是增强重要特征以及抑制冗余特征的能力依然欠缺。因此,为了进一步提升RFB模块的特征提取能力,通过在RFB模块的多分支并行网络上引入CBAM模块,构建Att-RFB模块,如图3所示。
图3 Att-RFB模块结构图
首先,该模块使用1×1大小的卷积核对通道数进行调整,然后采用不同大小的卷积核对多尺度特征信息进行提取。通过引入空洞卷积在更大的感受野范围内提取全局特征。最后将每个分支提取到的特征信息输入到各自的CBAM模块中,进行通道维度和空间维度上的自适应调整。添加CBAM模块后的Att-RFB模块,不仅可以提取到图像中的細节特征和全局特征,还可以增强和抑制某些特征信息,使得网络模型更加聚焦图像中的主体部分,以提高对于小目标违禁品的定位能力。
2 Att-RFB特征提取模块应用
2.1 下采样模块改进
空间深度转换模块(Space-to-Depth Layer-Non-Strided Convolution Layer, SPD-Conv)由非跨步卷积模块和抽样模块构成[12],它采用逐帧抽样的方式,将维度为S×S×C的特征图转换为4个维度为S / 2×S / 2×C的特征子图,并沿通道维度进行拼接。该模块在实现下采样的同时,尽可能地保留了特征图中的信息,有效避免了跨步卷积带来的非对称采样的问题。因此,为了充分发挥Att-RFB模块的特征提取能力,提高模型对低分辨率小目标物体的检测效果,采用SPD-Conv模块替代YOLOv5模型中的下采样模块,SPD-Conv模块的抽样过程为:
其中:fx, y表示分割出来的特征子图;scale表示抽样尺度。
2.2 融入特征提取模块
YOLOv5模型的浅层网络感受野较小,无法很好地提取到全局的特征信息。为进一步增强模型对于小目标物体的分类以及定位能力,在模型主干中两处C3模块的输出位置添加Att-RFB模块。在增加少量参数的条件下扩大了浅层网络的感受野,使得模型在浅层网络上也能获取到图像中的全局特征。此外,浅层网络生成的特征图上保留着较为丰富的细节信息和位置信息,将Att-RFB模块融入浅层网络中可以提升网络模型对于重要特征信息的提取能力,抑制噪声和背景等冗余信息,融入Att-RFB模块的改进模型结构如图4所示。
使用SPD-Conv模块对原模型中的下采样模块进行改进后,网络的主干部分能充分保留输入图像的特征信息。同样,在网络的特征融合部分可以将经过多尺度融合后的特征信息更加完整地交付给检测模块。由于浅层网络包含较多的细节特征但是含有的语义特征少,深层网络含有较为丰富的语义特征但是缺乏位置、纹理等细节信息。因此,将Att-RFB模块融入模型中浅层网络的输出位置,可以更好地提取主干部分保留下来的特征信息,并将这些特征信息注入后面的特征融合部分。
3 数据集增强
实验采用津南算法挑战赛赛道二的物流包裹X光限制品数据集。该数据集包含铁壳打火机、黑钉打火机、刀具、电池电容以及剪刀5类物流包裹里常见的违禁品。为提高模型的鲁棒性和泛化性,对原数据集中的图像进行数据增强,使用水平翻转、竖直翻转、旋转3种方式来模拟真实安检场景中物品摆放位置随机、角度多变等容易对检测效果造成干扰的情况,增强后的数据集图像效果如图5所示。
(a)原图像 (b)水平翻转后的图像
(c)竖直翻转后的图像 (d)旋转后的图像
图5 增强后的数据集图像
对增强后的数据集进行可视化分析后由图6(a)可知,该数据集中黑钉打火机(Lighter2)和电池(Power)两类违禁品的数量较多,而其余种类违禁品的数量较少,具有严重的类别不均衡问题,这就可能造成不同类别的违禁品检测精度相差较大的情况。从图6(b)可以看出,该数据集中含有较多长宽占比仅为原图像0.1倍的小目标违禁品,因此类别严重不均以及含有较多的小目标违禁品会给检测带来一定的挑战。
4 实验结果分析
4.1 评价指标
本文选取的模型评价指标包括:参数量(Parameters)、计算量(Flops)、准确率(Precision)、召回率(Recall)、均值平均准确率(Map0.5)、每秒传输帧数(FPS)。
对于检测类别c而言,以召回率为横轴,精确率为纵轴,绘制坐标曲线,平均准确率AP为该曲线与坐标轴围成的面积,其计算式为:
(2)
Map0.5表示预测框与真实框的交并比为0.5时的均值平均准确率,n表示类别总数,其计算式为:
(3)
FPS表示单位时间内检测的图片数量,其计算式为:
(4)
其中:N(Frames)表示检测图片的数量;ElapsedTime表示检测花费的总时间。
(a)类别数量
(b)目标宽高占比分布
图6 数据集类别数量及目标宽高占比分布
4.2 消融实验结果分析
为了验证Att-RFB模块的有效性,以YOLOv5n模型为基线网络进行消融实验。其中打勾表示在基线网络上添加此模块,打叉表示未添加此模块。实验结果如表1所示。
表1 消融实验结果对比
SPD-Conv Att-RFB 准确率/ % 召回率/ % 计算量/ GB 检测
速度/ s 参数量/ M Map0.5 / %
× × 86.1 96 3.8 109.8 1.73 86.1
√ × 86.2 97 8.2 75.7 2.11 88.7
× √ 84.6 96 4.2 90.9 1.66 87.8
√ √ 87.5 96 8.9 69.4 2.26 89.2
由表1可得,在只将原模型中的下采样模块替换为SPD-Conv模块的情况下,模型的准确率和召回率有小幅提升,Map0.5在原模型的基础上提高了2.6%。单独将Att-RFB模块融入模型主干,在增加少量参数的条件下Map0.5提升了1.7%。將两个模块同时作用于模型,准确率提升了1.4%,Map0.5提升了3.1%,并且检测速度可以达到每秒69.4帧,能够满足日常违禁品检测任务中对于实时性的要求。通过以上消融实验可知,所构建的Att-RFB模块可以有效提升模型的检测精度,且与该改进模块之间的相容性较好。
4.3 对比实验结果分析
在保证初始参数一致的条件下对模型改进前后进行对比试验,实验结果如图7至图9所示。相较于原始模型,融入Att-RFB模块后的模型对于所有类别的违禁品检测精度均有提高。其中黑钉打火机和刀具(Knife)的检测精度提升最为明显,Map0.5分别提升了3.7%及2.1%。将融入Att-RFB模块的改进模型在数据集上进行验证可得,所有类别违禁品的检测精度得到进一步提升,黑钉打火机以及电池两类小目标违禁品的检测效果得到显著提升,Map0.5分别提升了6.4%以及3.1%。
图10中使用EigenCAM注意力可视化工具将数据集中部分图像的注意力区域以热力图的形式进行可视化展示,通过对比模型改进前后注意力区域的大小可知,改进后模型的注意力区域范围更大,且基本能够覆盖安检图像中的主体内容。
(a)原图 (b)原模型 (c)改进模型
图10 注意力区域可视化对比图
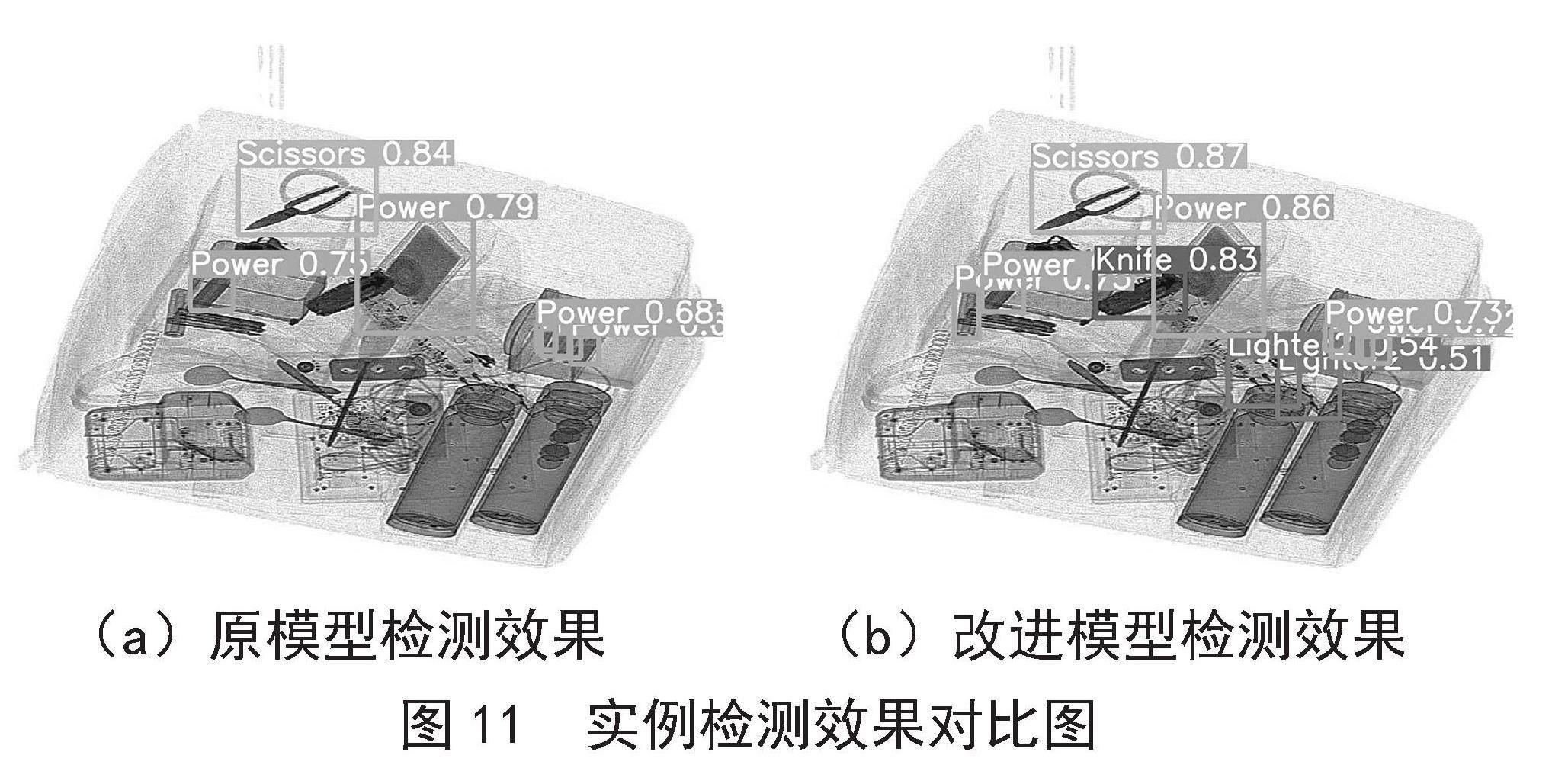
图11为含有违禁品的真实安检图像,该图像包含1个刀具、3个黑钉打火机、7个电池以及2把剪刀。使用原模型对安检图像进行实例检测,仅得到1把剪刀以及6个电池的信息,对融入Att-RFB模块的改进模型进行实例检测,可以检测出1个刀具、2个黑钉打火机、1个电池以及1把剪刀。将实例检测结果进行对比可知,Att-RFB模块能够有效提升模型对于打火机以及电池等小目标违禁品的检测精度,对于刀具等轮廓尺寸较为固定的违禁品也能有较好的检测效果。
(a)原模型检测效果 (b)改进模型检测效果
图11 实例检测效果对比图
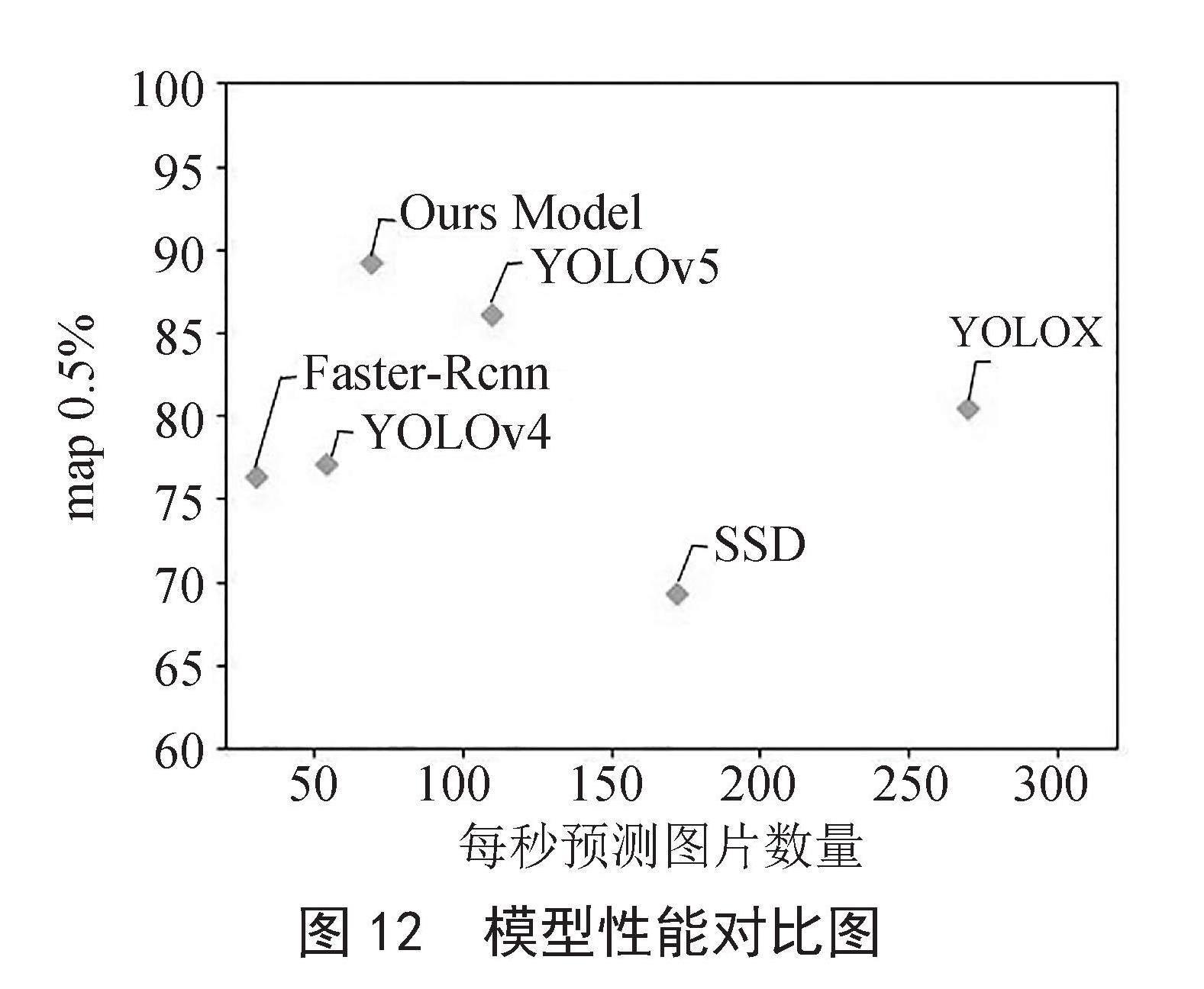
为了验证融入Att-RFB模块的改进模型性能,采用Map0.5以及FPS作为评价指标,将改进模型与其他目标检测模型进行对比,结果如图12所示。融入Att-RFB模块的改进模型相较于原模型Map0.5提高了3.1%,相较于更新的YOLOX模型Map0.5提高了8.7%,相较于Faster-RCNN两阶段目标检测模型Map0.5提高了13%。改进模型的检测精度具有一定的优越性,检测速度方面有所下降,但是仍能满足实时检测的任务需求。
图12 模型性能对比图
5 结 论
构建了一种特征提取模块Att-RFB。为了充分发挥Att-RFB模块对于小目标违禁品的特征提取能力,对YOLOv5模型的下采样模块进行了改进。通过消融实验可得,融入Att-RFB模块的改进模型,在检测的准确率以及检测精度上相较于原始模型有所提升。通过对比实验可以得出,融入Att-RFB模块的改进模型对于数据集中标注的所有类别违禁品的检测效果均有提升。其中,黑钉打火机和电池两类小目标违禁品的检测效果得到显著提升,Map0.5分别提升了6.4%、3.1%。所构建的Att-RFB模块可以显著提高模型对于小目标违禁品的检测精度。为了充分发挥Att-RFB模块对于小目标物体的检测能力,后期将针对不同检测场景对该模块进行改进,以增强该模块的泛化能力。
参考文献:
[1] 朱成,李柏岩,刘晓强,等.基于YOLO的违禁品检测深度卷积网络 [J].合肥工业大学学报:自然科学版,2021,44(9):1198-1203.
[2] 穆思奇,林进健,汪海泉,等.基于改进YOLOv4的X射线图像违禁品检测算法 [J].兵工学报,2021,42(12):2675-2683.
[3] 潘晓英,贾凝心,穆元震,等.小目标检测研究综述 [J].中国图象图形学报,2023,28(9):2587-2615.
[4] 张艳,张明路,吕晓玲,等.深度学习小目标检测算法研究综述 [J].计算机工程与应用,2022,58(15):1-17.
[5] LIN T Y,DOLLáR P,GIRSHICK R,et al. Feature Pyramid Networks for Object Detection [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu:IEEE,2017:936-944.
[6] LIU S,QI L,QIN H F,et al. Path Aggregation Network for Instance Segmentation [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:8759-8768.
[7] LIM J S,ASTRID M,YOON H J,et al. Small Object Detection using Context and Attention [C]//2021 International Conference on Artificial Intelligence in Information and Communication (ICAIIC).Jeju Island:IEEE,2021:181-186.
[8] 杨慧剑,孟亮.基于改进的YOLOv5的航拍图像中小目标检测算法 [J].计算机工程与科学,2023,45(6):1063-1070.
[9] 高伟,周宸,郭谋发.基于改进YOLOv4及SR-GAN的绝缘子缺陷辨识研究 [J].电机与控制学报,2021,25(11):93-104.
[10] WOO S,PARK J,LEE J Y,et al. CBAM: Convolutional Block Attention Module [C]//Proceedings of the European Conference on Computer Vision (ECCV).Munich:Springer,2018:3-19.
[11] LIU S T,HUANG D,WANG Y H. Receptive Field Block Net for Accurate and Fast Object Detection [C]//Proceedings of the European Conference on Computer Vision (ECCV).Munich:Springer,2018:409-419.
[12] SUNKARA R,LUO T. No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects [C]//Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Grenoble:Springer,2022:443-459.
作者簡介:刘天时(1960—),男,汉族,陕西渭南人,教授,工学博士,主要研究方向:计算机应用技术;周泽华(1999—),男,汉族,陕西西安人,硕士研究生在读,主要研究方向:智能计算与控制;郝敏杰(2000—),女,汉族,陕西汉中人,硕士研究生在读,主要研究方向:油气信息技术。
猜你喜欢
软件(2016年4期)2017-01-20 09:48:18
软件工程(2016年11期)2017-01-17 19:50:08
计算机应用(2016年12期)2017-01-13 20:26:21
中国新通信(2016年22期)2017-01-13 09:18:56
无线互联科技(2016年13期)2017-01-10 02:49:09
现代电子技术(2016年22期)2016-12-26 15:42:37
电子技术与软件工程(2016年19期)2016-12-19 19:21:36
中国科技纵横(2016年17期)2016-11-30 21:49:24
现代经济信息(2016年24期)2016-11-09 05:22:53
电脑知识与技术(2016年22期)2016-10-31 20:27:43
