
基于数据挖掘的校园运动研究
2024-06-01 22:43:17周义陈婕孟翔汪小芸张豹
现代信息科技 2024年4期
周义 陈婕 孟翔 汪小芸 张豹

收稿日期:2023-06-27
基金项目:贵州省2022年省级大学生创新创业训练计划项目(S202214440127)
DOI:10.19850/j.cnki.2096-4706.2024.04.009
摘 要:体质测试作为反馈大学生体质健康水平的根本途径,为高校开展学生健康干预工作提供了数据支撑,但如何对体测数据进行科学分析及合理使用也变得尤为重要。文章通过数据挖掘技术研究大学生体测数据,分别采用决策树、朴素贝叶斯、贝叶斯神经网络对体测数据进行预测,结果显示,贝叶斯神经网络的预测准确率最高。利用CART决策树对体测数据进行分类,由此可得到最优决策树,由最优决策树分析影响大学生体质水平的重要因素,进一步探讨体测成绩对大学生身体素质的影响和作用,从而提高大学生参与校园运动的热情和兴趣。
关键词:数据挖掘;决策树;朴素贝叶斯;贝叶斯神经网络;校园运动
中图分类号:TP391 文献标识码:A 文章编号:2096-4706(2024)04-0041-05
Research on Campus Sports Based on Data Mining
ZHOU Yi, CHEN Jie, MENG Xiang, WANG Xiaoyun, ZHANG Bao
(Science College, Guizhou Institute of Technology, Guiyang 550003, China)
Abstract: Physical fitness testing, as the fundamental way to provide feedback on the physical health level of college students, provides data support for universities to carry out student health intervention work. However, it has become particularly important to scientifically analyze and reasonably use physical fitness data. This paper uses data mining techniques to study the physical measurement data of college students, and uses decision trees, naive Bayes, and Bayesian neural networks to predict the physical measurement data. The results show that Bayesian neural networks have the highest prediction accuracy. By using the CART decision tree to classify physical testing data, the optimal decision tree can be obtained. It analyzes the important factors that affect the physical fitness level of college students through the optimal decision tree, further explore the impact and role of physical testing scores on the physical fitness of college students, and thereby enhance their enthusiasm and interest in participating in campus sports.
Keywords: data mining; Decision Tree; naive Bayes; Bayesian Neural Networks; campus sports
0 引 言
隨着数据挖掘技术的更新迭代,使用数据挖掘工具对高校学生的体测数据进行挖掘和处理已成为一种新的发展趋势。在我国,对此展开了多方面的研究,比如利用Clementine 12.0数据挖掘软件分析高校学生体测中各项指标之间的关联规则[1],从而对各个指标的影响因素做出判断。本文运用Jupyter Lab数据挖掘软件对大学生体测数据进行分类分析。由于高校学生体测数据的数量较为庞大,而数据挖掘工具在此方面的应用也并未成熟,尤其是缺乏高效的数据挖掘算法,基于此,本文拟对大学生体测数据进行特征分析,并运用决策树算法、朴素贝叶斯算法以及贝叶斯神经网络算法,有效降低数据计算量,提升预测准确度,并将这些算法应用到对大学生体测数据的挖掘分析之中,从多维角度实现对大学生身心状况的测试和评价。这有助于引导大学生转变“重文轻体”的思想观念,提高大学生身体素质,促进学生德智体美劳全面发展[2]。
1 基于分类算法的数据挖掘
数据挖掘是一个从纷乱庞杂到协调有序的有效信息提取过程,是充分挖掘数据价值的过程[3],也是统计分析的延伸和扩展,涉及多种技术和方法,如神经网络、决策树、模糊算法、关联规则法等。随着数据挖掘技术在诸多领域的广泛应用,数据挖掘理论逐渐形成,并以数据挖掘过程规范和数据挖掘技术为核心内容。数据挖掘的应用涵盖商业、医疗、金融、教育、政府等多个领域,可以应用于市场营销分析、疾病预测和诊断、信用评估和风险管理、教育评估和决策支持、政府决策和公共服务等方面。数据挖掘的持续发展,不仅为我们提供了更多富有价值的信息,也为我们提供了更多的机会。
1.1 CART决策树
CART决策树是一种可以从复杂、不规则数据中找出最优数据的分类模型,其形式主要是建立一个二分枝模型,从而对复杂的数据进行最优决策分类,并通过分类实现数据预测。该算法的分类主要是通过计算Gini系数选取属性集中的某个属性,将当前待分类的样本集分为两个子样本集,并循环往复此步骤,直至当前待分类的样本集被判定为叶节点或达到停止分类的条件[4-6]。
CART决策树选取的分裂属性为基尼系数,假设类的总数为J,P表示特征,Pj表示第j个特征在样本总数中所占的比例,则基尼系数的计算式为:
(1)
样本集合M的基尼系数为:
(2)
其中,| M |表示集合M总样本数,| Cj |表示集合M中属性为j的样本子集数,基尼系数Gini(M)表示集合M的不确定性。
1.2 朴素贝叶斯
朴素贝叶斯的目标是通过训练数据集学习联合概率分布P(X,Y),并由贝叶斯定理将联合概率转化为先验概率分布和条件概率分布之积[7]。给定数据集T = {(x1, y1), (x2, y2), …, (xn, yn)},其中N表示样本总数,xi = (xi(1), xi(2), …, xi(n))T是一个n维向量,yi ∈ {c1, c2, …, ck},k表示标签类别数。首先计算先验概率:
(3)
再给出条件概率:
(4)
由式(2)可以看出,条件概率有指数级的参数数目,直接计算的工作量巨大,而贝叶斯关于条件概率提出一个条件独立的假设,即:
(5)
对于给定数据x = (x(1), x(2), …, x(M))T,联立(1)(3)可得:
(6)
在分类时,朴素贝叶斯通过学习到的模型将后验概率最大的类作为x的类输出[8],最终的分类函数为:
(7)
1.3 贝叶斯神经网络
随着深度学习的不断发展,神经网络因其强大的非线性拟合能力而备受关注。其中,贝叶斯神经网络是一种将贝叶斯理论和神经网络融合在一起进行数据挖掘的方法。它的优点在于将不确定性考虑在内使模型更加可靠。具体来说,贝叶斯神经网络是在贝叶斯原理的基础上引入了神经网络的权值,在权值的后验概率下进一步优化目标函数,并利用权值的最大后验概率来计算神经网络的权值,进而构建一种新型的贝叶斯神经网络建模。这个模型在处理小数据集、避免过拟合和提高模型泛化能力方面具有优势。一个神经网络模型可以视为一个条件分布模型P( y | x, w),其中y表示标签数据,x表示输入数据,w表示神经网络的权值,D表示数据集,将输入数据转换为高斯分布以获得更高可能性的参数。
(8)
通过最大似然估计(MLE)方法最大化后验概率获得参数点估计:
(9)
在最大似然估计中,将w取不同值概率视为相等,即并不对w做出先验估计。如果为w引入先验估计,就变成最大后验估计(MAP)[9]:
(10)
按照已知的先验分布,基于贝叶斯原理对神经网络的不确定因素进行分析,得到网络结构的后验概率,使得后验概率最大的网络参数是最优的。
2 数据处理
2.1 数据的相关性分析
由于男、女生的体测项目和成绩评判标准有所不同,需按性别将数据集分成两组。在进行具体的分析之前,需要对分类得到的数据集进行数据的相关性分析,检测数据集中体测项目与最终成绩之间的关系。本文使用皮尔逊相关系数来检验不同特征之间的相关性,假设有两个变量X、Y,两个变量之间的皮尔逊相关系数计算式为:
(11)
其中,cov表示变量之间的协方差,σ表示标准差,E表示期望。相关系数的符号“+”“-”分别表示正相关、负相关,值的大小代表了两个变量之间影响关系的强弱程度。
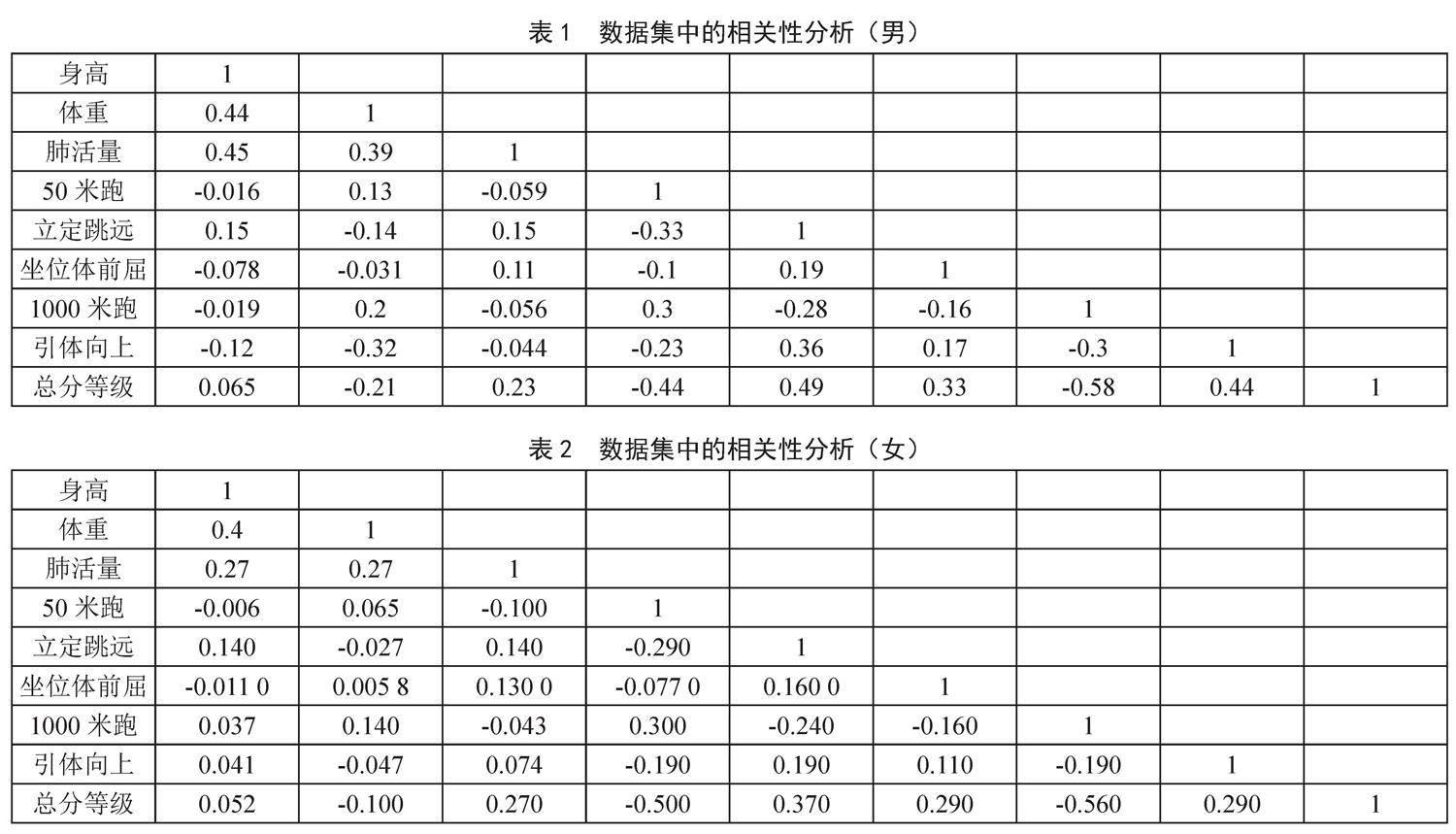
从表1男性相关性分析中可以看出,各个项目之间的相关性不是太强,有益于神经网络训练。此外,图中最后一列,即总分等级与各测试项目之间的相关系数中,1 000米测试与总分等级的相关性最大,表明1 000米测试对总分等级的影响因子最大,而立定跳远、引体向上和50米测试对总分等级的影响也较大。
从表2女性相关性分析中可以看出,50米测试和800米测试之间存在较强的相关性,而其余各个项目之间的相关性并不是太强。此外,图中最后一列,即总分等级与各测试项目之间的相关系数中,800米测试和50米测试的成绩与总分等级的相关性很大,表明对于女生来说,短、长跑测试对总分等级的影响因子最大。
2.2 数据的归一化处理
归一化是将数据的绝对数值转化为相对数值的一种线性尺度变换过程。通常,神经网络的隐层采用Sigmoid转换函数,为提高训练速度和灵敏性以及有效避开Sigmoid函数的饱和区,一般要求输入数据的值在0~1之间[10]。为确保所构建的模型具备一定的外推功能,需要将预处理数据的值控制在0.2~0.8之间。基于此,本文采用标准差方法對样本数据进行归一化处理,即:
(12)
其中,μ表示向量x的均值,σ表示向量x的标准差,使原始体测数据在0~1之间变化。
3 模型预测结果分析及比较
3.1 归一化数据与原始数据对比
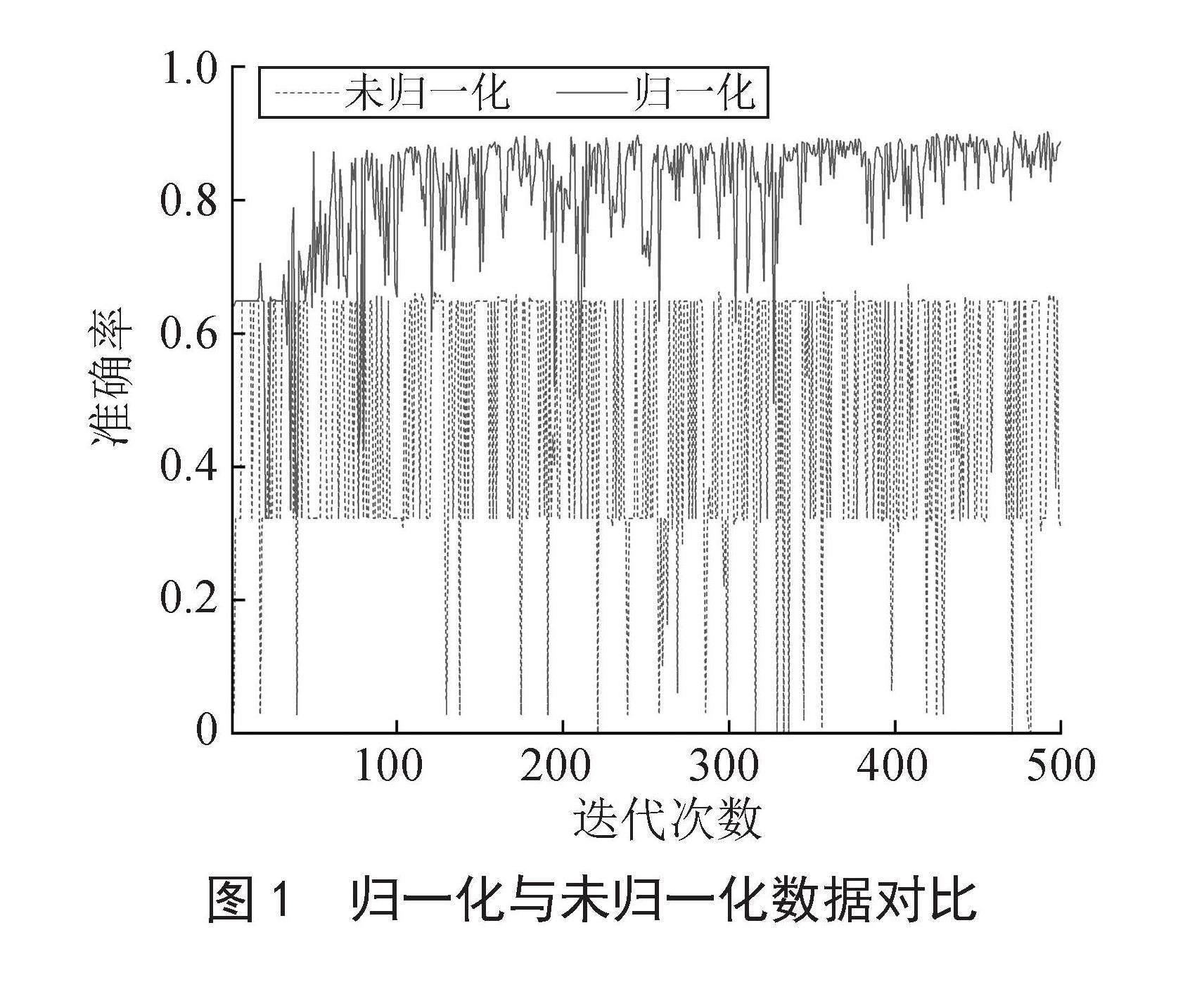
贝叶斯神经网络输入归一化是对神经网络输入数据进行处理的方法。样本数据归一化处理后,模型在训练集上的准确率经过500次迭代后,收敛至90%左右,而未经归一化处理的原始数据,经过500次迭代后仍未收敛。因此,在求解精度上,归一化处理后的数据经过模型计算优于未归一化的数据[11],模型测试结果表明,输入向量各分量经归一化处理后,预测效果优于转化前的数据,如图1所示。
图1 归一化与未归一化数据对比
3.2 CART决策树结果分析
文中使用JupyterLab实现CART决策树的编程,将大学生体测原始数据导入处理,获得男、女生最优决策树,结果如图2、图3所示。
从图2来看,在男生体测数据的训练集中有7 748
个数据,划分为4个类别,数量分别为2 483、5、
5 043、213,对应的标签分别是不及格、优秀、及格、良好,其中及格的数量最多。此外,Gini系数表示样本的不确定性,Gini的值越大,表明样本集合的不确定性越大[12]。而决策树会把Gini系数下降最快的特征作为根节点,所以选择1 000米测试作为第一个根节点,表明1 000米测试是影响男生体测成绩的第一要素,而立定跳远和引体向上也是影响男生体测成绩的重要因素。
从图3来看,在女生体测数据的训练集中有2 195
个数据,划分为4个类别,数量分别为312、1、
1 747、135,对应的标签分别是不及格、优秀、及格、良好,其中及格的数量最多。而决策树会把Gini系数下降最快的特征作为根节点,所以选择800米测试作为第一个根节点,表明800米测试是影响女生体测成绩的第一要素,而50米测试也是影响女生体测成绩的重要因素。
3.3 决策树、朴素贝叶斯与贝叶斯神经网络比较
在本实验中,选用决策树、朴素贝叶斯和贝叶斯神经网络三种分类器进行对比。选择数据集中80%的样本作为训练样本集,剩下20%的样本用作测试样本集,将选区的训练集数据作为输出,带入贝叶斯神经网络中,用训练好的网络对测试集数据进行分类,并分析分类效果。最后,将相同的训练集数据和测试集数据分别带入决策树和高斯朴素贝叶斯进行性能对比,实验结果如表3和表4所示。
从结果可以看出,取同样的数据和特征,在预测男、女生的体测成绩中,贝叶斯神经网络的准确率达到93%以上,比决策树和朴素贝叶斯的准确率都高;从精确率上看,贝叶斯神经网络的预测结果也高于决策树和朴素贝叶斯。说明贝叶斯神经网络在分类准确率和精确率两个方面均优于决策树和朴素贝叶斯。
贝叶斯神经网络适用于具有复杂输入输出关系的数据挖掘,且预测时不需要建立精确的数学模型。通过对实验数据的归一化处理,显著提高了网络模型的求解效率,同时,该模型能够通过分析大样本数据来确定影响学生体测成绩的关键因素,并对这些因素之间的相关性进行定量分析,具有较好的泛化能力。与决策树相比,贝叶斯神经网络不仅具备优良的非线性性能,还具备贝叶斯后验概率的真实性。
表3 不同算法对于男生体测成绩预测结果的对比
算法 指标
准确率 精确率 召回率
决策树 0.868 4 ± 0.007 2 81.32 83.13
朴素贝叶斯 0.889 0 ± 0.004 7 88.82 80.29
贝叶斯神经网络 0.934 5 ± 0.004 3 88.91 81.45
表4 不同算法对于女生体测成绩预测结果的对比
算法 指标
准确率 精确率 召回率
决策树 0.883 4 78.43 78.43
朴素贝叶斯 0.908 9 86.04 82.55
贝叶斯神经网络 0.938 1 90.41 85.46
4 通过数据挖掘进行体质分析
模型预测结果表明,该高校学生体测成绩良好及优秀率不足2.85%。从整体上来看,该高校学生的体质健康水平有待进一步提高。
结合男生相关性分析和最优决策树,1 000米测试对男生成绩影响最大,而引体向上和立定跳远次之。1 000米作为男生体能、耐力和爆发力的测试,主要检验男生的心肺功能、下肢力量以及肌肉发展水平是否达到正常水准。结合相关性和Gini系数来看,Gini系数低的因素相关性也较差,说明在日常训练中男生应根据自身的不足,补足短板,进行专项的体能和耐力训练,全面提升自己的体质健康水平。
在女生的体测项目中,起决定性作用的是800米和50米测试,表明一部分女生在有氧、无氧耐力上与标准水平还有一定的差距,而这类女生可以考虑适当增加身体锻炼的频次以及提升锻炼的效果,比如加强日常跑步训练,进行跳绳等有氧锻炼。如果女生能够在这两个项目中取得优异成绩,那么女生体测的及格率将会大大提高。
5 结 论
学生的体质健康水平一直以来都是高校重点关注的一项指标,而体测数据不仅是学生体质健康水平的一种直观反映,更是高校学子身体机能的综合体现。本文通过数据挖掘技术探索体测成绩与高校学生身体素质的关系,利用决策树、朴素贝叶斯、贝叶斯神经网络进行了相应处理,再利用CART决策树得到最优分类模型,提取出当前学生的体测成绩并进行了分析,进而有效干预高校学生身体素质的发展,为进一步采取相应措施提供可循依据。
参考文献:
[1] 张雪琴,江帆,席本玉.基于数据挖掘的学生体质健康测试平台设计及应用研究 [J].電子设计工程,2022,30(13):87-90+95.
[2] 赵东健.教学型职业院校体育实践课思政进课堂的实现途径研究 [J].青少年体育,2022(6):34-35+42.
[3] 朱晓飞.移动Wi-Fi网络环境下学生上网行为数据分析及应用 [D]. 新乡:河南师范大学,2020.
[4] 于淼,陈颖,丁康,等.基于CART决策树模型的北京市春季气传花粉浓度与植被空间结构关系研究 [J].北京林业大学学报,2023,45(1):121-131.
[5] 张艳可,王金亮,苏怀,等.基于CART决策树的双尺度流域单元地貌分类研究——以北回归线(云南段)地区为例 [J].地理与地理信息科学,2021,37(2):84-92.
[6] 张睎伟,王磊,汪西原.基于CART决策树的沙地信息提取方法研究 [J].干旱区地理,2019,42(5):1133-1140.
[7] 王子涵,杨秀芝,段现银,等.基于贝叶斯神经网络的机床热误差建模 [J].制造技术与机床,2022(1):141-145.
[8] 贡保才让,色差甲,慈祯嘉措,等.基于Naive Bayes的藏文人名性别自动识别 [J].青海师范大学学报:自然科学版,2017,33(4):11-15.
[9] 向新明.面向贝叶斯神经网络的概率计算电路设计 [D].成都:电子科技大学,2021.
[10] 叶子健,刘士文,景冰璇,等.基于神经网络和支持向量机的体测分析模型 [J].科学技术创新,2021(34):55-57.
[11] 马湧,孙彦广.贝叶斯神经网络在蒸气管网预测中的应用 [J].中国冶金,2014,24(6):53-57.
[12] 张居营.大话Python机器学习 [M].北京:中国水利水电出版社,2019.
作者简介:周义(2000—),男,汉族,贵州毕节人,本科在读,研究方向:数据挖掘;通讯作者:张豹(1988—),男,汉族,安徽阜阳人,讲师,硕士研究生,研究方向:数据安全。
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
成都信息工程大学学报(2018年6期)2018-03-21 05:45:58
电力与能源(2017年6期)2017-05-14 06:19:37
中国中医药信息杂志(2016年7期)2016-12-01 06:07:55
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
电测与仪表(2016年2期)2016-04-12 00:24:40
信息通信技术(2015年6期)2015-12-26 01:16:46
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
