
基于深度学习的人体行为识别综述
2024-06-01 12:59:34吴婷刘瑞欣刘明甫刘海华
现代信息科技 2024年4期
吴婷 刘瑞欣 刘明甫 刘海华

收稿日期:2023-06-27
基金项目:国家自然科学基金项目资助项目(61773409)
DOI:10.19850/j.cnki.2096-4706.2024.04.011
摘 要:近年来,人体行为识别是计算机视觉领域的研究热点,在诸多领域有着广泛的应用,例如视频监控、人机交互等。随着深度学习的发展,卷积神经网络作为其领域中表现能力优越的人工神经网络之一,在动作识别领域中发挥着不可或缺的作用。文章基于深度学习总结基于2D CNN和基于3D CNN的动作识别方法,根据不同算法搭建的模型进行性能对比,同时对基准数据集进行归纳总结。最后探讨了未来人体动作识别的研究重难点。
关键词:动作识别;深度学习;卷积神经网络;图像分类
中图分类号:TP183;TP391.4 文献标识码:A 文章编号:2096-4706(2024)04-0050-06
Summary of Human Behavior Recognition Based on Deep Learning
WU Ting, LIU Ruixin, LIU Mingfu, LIU Haihua
(South-Central Minzu University, Wuhan 430074, China)
Abstract: In recent years, human behavior recognition is a research hotspot in the field of computer vision, and it has been widely used in many fields, such as video surveillance, human-computer interaction and so on. With the development of Deep Learning, as one of the artificial neural networks with superior performance capabilities in the field, Convolutional Neural Networks plays an indispensable role in the field of action recognition. Based on Deep Learning, this paper summarizes the action recognition methods based on 2D CNN and 3D CNN, compares the performance of models built according to different algorithms, and summarizes the benchmark data sets. Finally, the research key points and difficulties of human action recognition in the future are discussed.
Keywords: action recognition; Deep Learning; Convolution Neural Networks; image classification
0 引 言
人體行为识别是计算机视觉领域一大热题,随着深度学习的发展,视频中人体动作识别课题越发成熟,在监控系统[1,2]、人机交互[3]、智能看护[4]等日常生活中被广泛应用。
深度学习(Deep Learning)[5,6]是机器学习领域中一个新的研究方向,它逐渐成为计算机视觉领域的热门研究方法。卷积神经网络[7](Convolution Neural Networks, CNN)主要用于计算机视觉方面的应用,比如图像分类、视频识别[8]、医学图像分析等。由于背景的影响、光线变化以及动作相似性,使得模型识别性能下降。动作识别最重要的特征无关是外观特征和动作特征,最初卷积神经网络利用2D卷积核,主要由图像帧和光流图像作为输入,通过卷积层提取出视频当中的空间和动作特征进行学习,两者组合到一起初步实现动作识别的目的,后续学者针对融合策略以及动作的时空特征进行研究。
本文主要从数据集和动作识别的深度学习方法两大方面来介绍。首先介绍了几大类动作识别的公共数据集,从简单动作到交互动作,从小型数据集到大型数据库;其次分别介绍基于2D CNN和基于3D CNN的动作识别方法,根据不同算法之间的异同点将两者细分;最后提出未来动作识别所研究的难点及发展趋势。
1 公共数据集
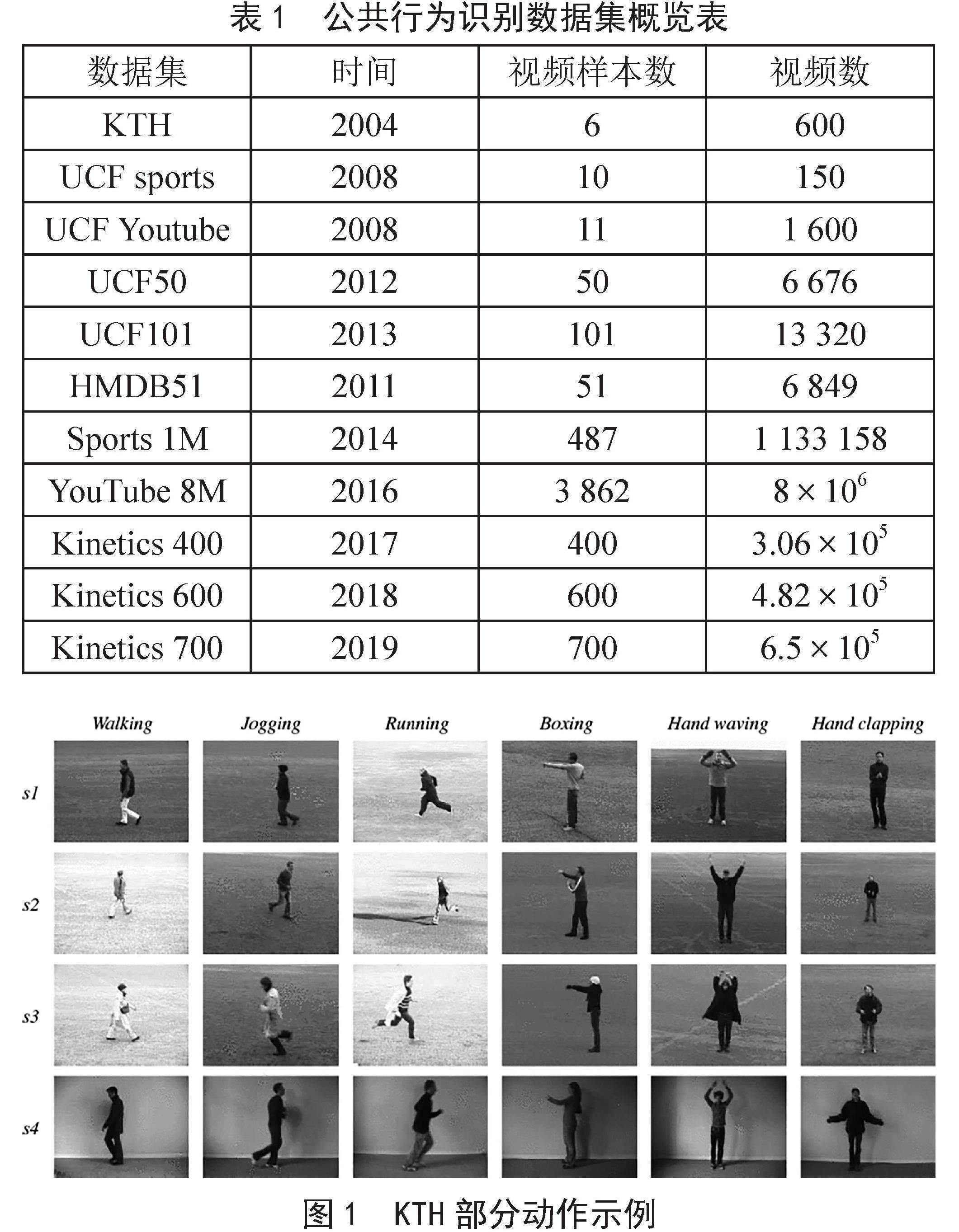
行为识别数据集是用于训练和测试不同算法对准确识别人类行为的数据集。目前国内外有多个公共人体行为数据库可供广大研究者学习,它们可以为评估各种不同人体行为识别算法提供一个共同的标准,便于验证相关算法的可行性。目前,公共行为识别数据库可以分为以下几种。表1列出了它们的大概信息。
1.1 KTH数据库
KTH [9]是最早的人体行为数据集,该人体行为数据库包括6种动作,由25个不同的人执行的,分别在四个场景下,一共有25×4×6 = 600段视频。视频中的背景相对单一和静止,拍摄过程中摄像头稳定。KTH数据库部分动作示例如图1所示。
表1 公共行为识别数据集概览表
数据集 时间 视频样本数 视频数
KTH 2004 6 600
UCF sports 2008 10 150
UCF Youtube 2008 11 1 600
UCF50 2012 50 6 676
UCF101 2013 101 13 320
HMDB51 2011 51 6 849
Sports 1M 2014 487 1 133 158
YouTube 8M 2016 3 862 8×106
Kinetics 400 2017 400 3.06×105
Kinetics 600 2018 600 4.82×105
Kinetics 700 2019 700 6.5×105
图1 KTH部分动作示例
1.2 UCF系列数据库
美国University of Central Florida(UCF)[10,11]自2007年以来发布的一系列数据库:分别是UCF Sports(2008)、UCF Youtube(2008)、UCF50和UCF101。其中UCF101包含101种动作类别共13 320个视频。该数据集有三个官方拆分方式,大多研究者报告第一个分割方式的分类准确率,或是三种分割方式的平均精度。由于该数据集包含很多低质量和不同光照的视频,所以极具挑战性。UCF Sports数据库部分动作示例如图2所示。
图2 UCF Sports部分动作示例
1.3 HMDB51数据库
HMDB51[12]数据集包含51种行为类别共6 849個视频。该数据集有三个与UCF101类似的官方拆分,并且以同样的方式进行评估。由于视频中包含的场景复杂、光照变化等因素,是目前最具挑战性的数据集之一。HMDB51数据库部分动作示例如图3所示。
图3 HMDB51部分动作示例
1.4 大型数据集
Sports 1M [13]的数据集是2014年Google公布的第一个大规模动作数据集,包含487种行为类别共1 133 158个视频;YouTube 8M [14]数据集是迄今位置规模最大的数据集,包含3 862个动作类共800万个视频;Kinetics系列数据集[15]最先是17年提出的Kinetics 400,包含400个人类行为类别,直至后续提出的Kinetics 600和Kinetics 700。此类数据集包含场景多,数据量庞大,极具挑战性。Sports 1M部分动作示例如图4所示。
图4 Sports 1M部分动作示例
2 基于2D卷积神经网络的行为识别
卷积神经网络(CNN)被广泛应用于静态领域的图像理解中,其遵循3层体系结构,分别是卷积层、池化层和全连接层。在人类行为识别中,视频被分为空间和时间信息。空间的视频帧代表着物体的外观信息,具体表征为RGB图像;时间信息指的是帧与帧之间的运动信息,具体表征为光流图像。最早是Simonyan等人[16]在2014年提出的双流CNN网络,其由两条分支组成,分别处理空间的RGB图像帧信息和时间维度的若干个图像帧之间的光流场信息。主干网络皆为CNN,最后进行softmax融合,如图5所示。
2.1 融合网络
在此之上,很多学者进行了一系列改进。Feichtenhofer等人[17]从融合策略上针对双流网络的后期融合,其从卷积层开始进行融合,讨论和融合、最大融合、串联融合、卷积融合、双线性融合五种空间融合方式和2D池化、3D池化、3D卷积+3D池化三种时间融合方式,如图6(a)所示。实验表明替代后期融合,早期融合受相对网络的约束,使模型在早期训练中能从两支网络互相学习、互相弥补,一定程度上弥补数据不足问题,效果比双流网络好。基于双流和时空融合,Feichtenhofer等人提出同时将残差网络和两个信息流的卷积神经网络结合,一是在双流网络中引入残差连接[18],通过发挥残差单元的跳跃连接的优点,允许两流之间时空交互,并在残差块之间添加时间流指向空间流,提出加法融合、乘性融合两种融合方式,实验最后对比时间流指向空间流、空间流指向时间流和两者相互指向的消融实验,表明第一种方式实验效果更好;二是在2017年[19]的基础上,后续提出在两条分支中添加采用中心初始化方式的时间滤波器1D卷积以捕获时间依赖关系,探讨其中心和平均两种初始化方式以及添加位置(每个残差单元跳跃连接后、每个残差块中和仅仅在每个残差单元的第二个残差块3×3卷积层后),如图6(b)所示。结果表明,采用残差网络的2D CNN结构在行为识别十分有效。
(a)双流融合网络
(b)时空残差融合网络
图6 Feichtenhofer等人的双流融合网络
Wang等人[20]提出一种时空金字塔网络(Spatiotemporal Pyramid Networks, STPN)来融合空间和时间特征,其结合 卷积神经网络和空间时间金字塔的结构,通过采样不同大小的视频片段来获得不同尺度的特征图。每个特征图由一个3D CNN进行提取,然后将不同尺度的特征图拼接在一起,形成多尺度的特征表示,随后将不同金字塔层中的特征进行融合,再将不同动作分类结果进行加权融合。该方法对各种融合策略进行统一建模,在多个动作数据集上进行实验展现其算法优越性。
2.2 其他网络
除了时空网络外,针对视频的输入形态,即网络输入不是视频帧,而是视频片段进行探讨。Wang等人[21]在双流网络的基础上加入分段和稀疏化采样的思想,提出具有四种输入模态的时域段网络(Temporal Segment Networks, TSN),如图7所示,对时间进行稀疏采样,即将视频分割成若干时间段,并将每个时间段视为独立的视频帧进行处理,但这样往往忽略了时空特征的交互,使得识别准确性下降。考虑到时间特征提取的困难,设计一些专门处理时间特征的网络,如对动作识别同样有效的长短时记忆(LSTM)。采用CNN+LSTM网络[22]进行时间动力学建模。在这些组合网络中,CNN用于提取帧特征,LSTM用于伴随时间的特征集成。
图7 Wang等人的TSN网络
基于双流网络的动作识别在过去几年取得了很大的进展。以上方法在时间流的输入上皆采用光流栈(Optical Flow Stacking),这需要耗费大量的时间和计算成本。为此,后续研究者直接在视频序列使用3D卷积神经网络进行动作识别,一方面不仅可以直接学习到视频当中的空间和时间特征,减少计算量;另一方面使用3D卷积神经网络可以学习到更加全面且准确的空间和时间信息,使得识别性能变得更好。
3 基于3D卷积神经网络的行为识别
在二维卷积神经网络中,2D特征图仅仅处理视频当中的空间信息,丢失了动作之间的关联性。而捕获视频的时间特征(长时间和短时间依赖关系)尤为重要。3D CNN将视频序列看作是一个三维图像序列,通过卷积神经网络对其进行处理以提取空间和时间特征,相对于双流网络,3D CNN不需要提前提取骨骼或其他先验特征,具有更强的适应性。
3.1 时空网络
对于连续性的图像,2D卷积核每次只抽取一帧图像,对这一帧进行单独的卷积操作,最后由每一帧的识别结果进行判断。3D卷积核的卷积操作会涉及前后连续性的几帧图像,因此3D卷积核能够提取空间领域上的图像信息,还能考虑连续帧之间的运动信息。Ji等人[23]首先开发一个三维CNN模型,它从相邻的输入帧提供多个通道,并对每个通道进行三维卷积。Tran等人[24]提出一种C3D网络架构,它使用多帧作为网络的输入,对视频数据进行了端到端的处理,包括时空特征提取和分類。C3D网络基于3D CNN通过在时间维度引入卷积和池化操作,使得网络对视频序列进行建模。Carreira等人提出一种双流膨胀三维CNN(I3D)[25],如图8所示,其将ImageNet预训练的2D CNN延伸到3D CNN中,结合两者优势,在基于二维的ResNet和Inception架构的基础上,使用3D卷积来捕捉时间信息。然而I3D网络具有一定的局限性,如需大量的标记数据和需要仔细调整参数。Tran等人[26]提出R(2+1)D模型,该模型使用一种新的卷积操作,称为时序分离卷积(Separable Spatiotemporal Convolution)来对时间信息进行建模,在多个数据集上取得了较好的效果。该网络与C3D类似,将2D空间卷积和1D时间卷积并联组合替代3D卷积,目的是减少模型中的参数数量,提高其效率。
3.2 融合网络
基于双流和3D CNN的卷积网络在视频识别任务中取得了良好的性能,因为两者可以同时捕获视频的空间和时间线索,但是皆有其局限性。例如,基于双流的结构无法学习到真正的时空特征,其采用两个流的单独分类分数的后期融合,而基于3D CNN的方法需要昂贵的内存需求和计算成本。为了避免两者缺点,Karpathy等人[27]在双流网络中提出晚融合、早融合和慢融合三种不同的融合方式,如图9所示,其一次可以连续输入多帧,能够获取视频中的时间信息,再通过一个CNN网络进行处理。在Feichtenhofer等人[19]提出时空乘性网络的基础之上,Zong等人[28]提出多流乘性残差网络(MSM-ResNets),在双流网络输入上增加运动显著图以捕获运动信息,然后时间流指向空间流进行一次乘性融合,运动显著流指向时间流再次进行乘性融合,最后三个分支经过softmax层进行后期融合以达到融合时空特征的效果。Gammulle等人[29]提出一种双流LSTM网络,主干网络是经过ImageNet预训练的VGG16网络,利用CNN提取空间特征,利用LSTM提取时间特征,结合两者形成一个深度融合框架,评估框架融合策略上的优劣势,其中双流的LSTM表现最好。
图9 Karpathy等人的双流融合网络
3.3 其他网络
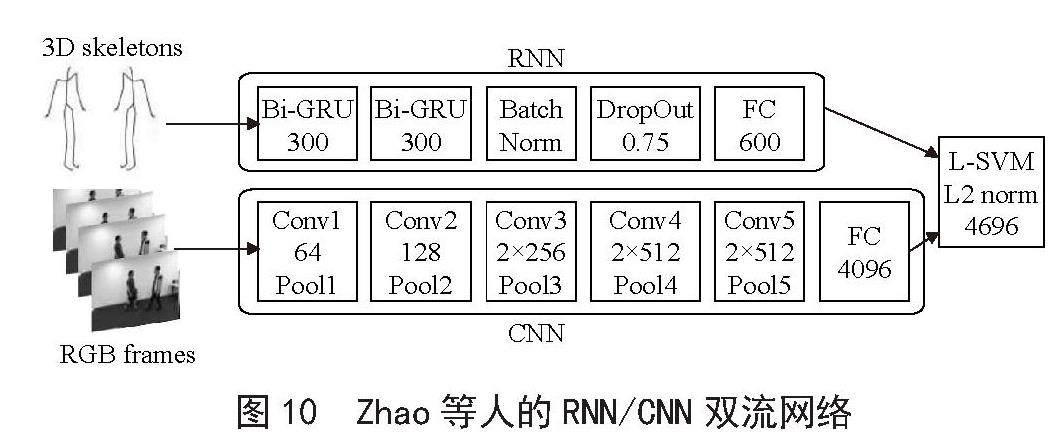
Donahue等人[30]提出一种结合CNN和LSTM的新型网络结构,即长期循环卷积网络(LRCN),通过CNN网络提取空间信息,LSTM网络提取视频中的时间长期依赖性,最后实现分类。该网络可以同时处理时序的视频输入和单帧图片输入,适用于大规模的视觉理解任务。Zhao等人[31]结合RNN和CNN的优势,提出基于门控循环单元的双流神经网络,空间分支采用3D CNN网络,时间分支采用RNN网络,门控循环单元层之后紧接着批量规范化和Dropout = 0.75。最后双流网络生成的特征通过一个线性SVM分类器进行动作分类。其中RNN网络使用双向GRU,输入为人体的骨架序列,在NTU RGB+D Dataset实现了很好的效果,如图10所示,表2列出了基于深度学习的行为识别不同算法下准确率对比。
图10 Zhao等人的RNN/CNN双流网络
总体而言,3D CNN在识别效果和效率上较2D CNN是很有竞争力的。但是,3D卷积神经网络模型参数量大,网络结构越深其模型参数越多,容易出现过拟合现象;且3D卷积核需要同时考虑时间和空间信息,需要消耗大量的计算资源和存储空间,因此训练需要很长时间以及很好的硬性资源条件。这些问题会限制基于3D CNN的动作识别方法在实际应用中的可行性和可扩展性。未来,如何通过减少模型参数来降低模型过拟合的风险以及提高网络的分类准确率是重要的研究方向。
4 结 论
视频动作识别已成为计算机视觉领域一个重要的研究方向,具有十分广泛的应用前景。本文系统地讲解人体行为识别领域的数据集和算法,基于深度学习是因为目前深度学习方法较于传统算法来说已成为主流趋势,并从简单模型向复杂模型演化,从最初的监督到弱监督及以后的无监督方法,都是未来发展的趋势。本文基于双流架构的基础,从融合策略上和针对输入模态上进行许多方面的改进。最后采用具有3D时空特性的卷积神经网络模型来进行识别,总结目前行为识别的经典算法,指出目前存在的难点问题。如何在减少模型参数数量的基础上提高模型识别的准确率成为未来一定的研究方向和发展趋势。
參考文献:
[1] AYERS D,SHAH M. Monitoring Human Behavior from Video Taken in an Office Environment [J].Image and Vision Computing,2001,19(12):833-846.
[2] 马海兵,白洁.人脸识别技术在智能视频监控系统中的应用 [J].现代电子技术,2007(20):125-128.
[3] 薛雨丽,毛峡,郭叶,等.人机交互中的人脸表情识别研究进展 [J].中国图象图形学报,2009(5):764-772.
[4] 吉江.幼儿/高龄视频看护系统建设需求分析 [J].A&S:安全&自动化,2011(9):94-96.
[5] SCHMIDHUBER J. Deep Learning in Neural Networks: An overview [J].Neural Networks,2015,61:85-117.
[6] KRIZHEVSKY A,SUTSKEVER I,HINTON,G E. ImageNet Classification with Deep Convolutional Neural Networks [C]//Twenty-sixth Annual Conference on Neural Information Processing Systems.Lake Tahoe:NIPS,2012:1-9.
[7] LECUN Y,BOTTOU L,BENGIO Y,et al. Gradient-based Learning Applied to Document Recognition [J].Proceedings of the IEEE,1998,86(11):2278-2324.
[8] KUMAWAT S,VERMA M,NAKASHIMA Y,et al. Depthwisespatio-temporal STFT Convolutional Neural Networks for Human Action Recognition [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2022,44(9):4839-4851.
[9] SCHULDT C,LAPTEV I,CAPUTO B. Recognizing Human Actions: A Local SVM Approach [C]//Proceedings of the 17th International Conference on Pattern Recognition(ICPR 2004).Cambridge:IEEE,2004,3:32-36.
[10] RODRIGUEZ M D,AHMED J,SHAH M. Action MACH a Spatio-temporal Maximum Average Correlation Height Filter for Action Recognition [C]//2008 IEEE Conference on Computer Vision and Pattern Recognition.Anchorage:IEEE,2008:1-8.
[11] SOOMRO K,ZAMIR A R. Action Recognition in Realistic Sports Videos [M]//Moeslund T B,Thomas G,Hilton A. Computer Vision in Sports.Berlin:Springer,2014:181–208.
[12] KUEHNE H,JHUANG H,GARROTE E,et al. HMDB: A Large Video Database for Human Motion Recognition [C]//2011 International Conference on Computer Vision (ICCV).Barcelona:IEEE,2011:2556-2563.
[13] KARPATHY A,TODERICI G,SHETTY S,et al. Large-scale Video Classification with Convolutional Neural Networks [C]//2014 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Columbus:IEEE,2014:1725-1732.
[14] ABU-EL-HAIJA S,KOTHARI N,LEE J,et al. YouTube-8M: A Large-Scale Video Classification Benchmark [J/OL].arXiv:1609.08675 [cs.CV].(2016-09-27).https://arxiv.org/abs/1609.08675.
[15] KAY W,CARREIRA J,SIMONYAN K,et al. The Kinetics Human Action Video Dataset [J/OL].arXiv:1705.06950 [cs.CV].(2017-05-19).https://arxiv.org/abs/1705.06950v1.
[16] SIMONYAN K,ZISSERMAN A. Two-stream convolutional networks for Action Recognition in Videos [C]//NIPS'14: Proceedings of the 27th International Conference on Neural Information Processing Systems.Cambridge:MIT Press,2014,1(4):568-576.
[17] FEICHTENHOFER C,PINZ A,ZISSERMAN A. Convolutional Two-Stream Network Fusion for Video Action Recognition [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:1933-1941.
[18] FEICHTENHOFER C,PINZ A,WILDES R P. Spatiotemporal Residual Networks for Video Action Recognition [C]//29th Conference on Neural Information Processing Systems(NIPS 2016).Barcelona:NIPS,2016:3468-3476.
[19] FEICHTENHOFER C,PINZ A,WILDES R P. Spatiotemporal Multiplier Networks for Video Action Recognition [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu:IEEE,2017:7445-7454.
[20] WANG Y B,LONG M S,WANG J M,et al. Spatiotemporal Pyramid Network for Video Action Recognition [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu:IEEE,2017:2097-2106.
[21] WANG L M,XIONG Y J,WANG Z,et al. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition [J/OL].arXiv:1608.00859 [cs.CV].(2016-08-02).https://arxiv.org/abs/1608.00859.
[22] STAUDEMEYER R C,MORRIS E R. Understanding LSTM--A Tutorial into Long Short-Term Memory Recurrent Neural Networks [J/OL].arXiv:1909.09586 [cs.NE].(2019-09-12).https://arxiv.org/abs/1909.09586.
[23] JI S W,XU W,YANG M,et al. 3D Convolutional Neural Networks for Human Action Recognition [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(1):221-231.
[24] TRAN D,BOURDEV L,FERGUS R,et al. Learning Spatiotemporal Features with 3D Convolutional Networks [C]//2015 IEEE International Conference on Computer Vision (ICCV).Santiago:IEEE,2015:4489-4497.
[25] CARREIRA J,ZISSERMAN A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu:IEEE,2017:4724-4733.
[26] TRAN D,WANG H,TORRESANI L,et al. A Closer Look at Spatiotemporal Convolutions for Action Recognition [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:6450-6459.
[27] KARPATHY A,TODERICI G,SHETTY S,et al. Large-Scale Video Classification with Convolutional Neural Networks [C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:1725-1732.
[28] ZONG M,WANG R L,CHEN X B,et al. Motion Saliency Based Multi-stream Multiplier ResNets for Action Recognition [J].Image and Vision Computing,2021,107:104108.
[29] GAMMULLE H,DENMAN S,SRIDHARAN S,et al. Two Stream LSTM: A Deep Fusion Framework for Human Action Recognition [C]//2017 IEEE Winter Conference on Applications of Computer Vision(WACV).Santa Rosa:IEEE,2017:177-186.
[30] DONAHUE J,HENDRICKS L A,GUADARRAMA S,et al. Long-Term Recurrent Convolutional Networks for Visual Recognition and Description [C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Boston:IEEE,2015:2625-2634.
[31] ZHAO R,ALI H,SMAGT P V D. Two-stream RNN/CNN for Action Recognition in 3D videos [C]//2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).Vancouver:IEEE,2017:4260-4267.
作者簡介:吴婷(1998—),女,汉族,广西北海人,硕士研究生在读,研究方向:视觉认知计算与医学图像处理;通讯作者:刘海华(1966—),男,汉族,湖北孝感人,教授,博士,研究方向:视觉认知计算与医学图像处理。
猜你喜欢
现代电子技术(2017年1期)2017-02-16 11:13:19
计算机应用(2016年12期)2017-01-13 20:26:21
现代电子技术(2016年22期)2016-12-26 15:51:05
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
软件导刊(2016年9期)2016-11-07 22:19:22
软件工程(2016年8期)2016-10-25 15:47:34
商(2016年22期)2016-07-08 14:32:30
电脑知识与技术(2016年10期)2016-06-16 21:27:26
