
基于八叉树的地震数据分布式存储方法研究
2024-06-01 05:59:06景妍彭成
电脑知识与技术 2024年10期
景妍 彭成
摘要:针对现有地震数据存取效率不足的问题,在参考谷歌文件系统设计理念并吸收其关键分布式处理技术的基础上,利用三维空间下八叉树结构与编码的快速空间定位机制,实现对三维大数据体的结构分块存储。这一方法减少了单机存储空间开销,并通过备份降低了数据丢失的风险。同时,采用八叉树结构的分块存储,对于相近区域的属性计算和三维渲染在文件访问速度上具有优势。
关键词:分布式;八叉树;地震数据;子块切分;哈希编码
中图分类号:P311.5, TP311.1 文献标识码:A
文章编号:1009-3044(2024)10-0081-03
0 引言
如果能夠充分利用最新的信息科学技术方便地调取上游板块基础资料,例如地震数据,并无缝地融合于油气资源评价参数获取与勘探部署决策过程中,对实现油气高效勘探具有重要的现实意义[1]。考虑到以SEGY格式存储的三维地震数据,一个文件就可以达到几百GB甚至TB级别,在业内不断应用计算机存储新技术的情况下,设计、调整并形成了一系列网络文件存储技术与部署方案[2]。例如,以直连式存储、网络附加存储、存储区域网为代表的网络存储技术,配套高性能计算集群来提高单位时间内执行的任务数,体现出大吞吐量、低延迟数据读取的特点[3-4]。由于采用的是直接存储整个大数据文件的方式,面向集群的大文件存取存在对存储和执行环境要求高、网络互联设备昂贵、地理上连接距离有限、需要配备专业人员维护、访问速度瓶颈等问题[5-6]。特别是,单个大文件I/O节点不仅因大量数据交换而变得很慢,还存在单点故障、容易造成集群瘫痪等实际问题[7]。
随着地震采集及电子扫描技术的发展,获取地震资料的量级快速增长。尽管用来处理数据的计算机性能在不断提高,但数据规模爆炸式的增长仍然超越了内存的发展速度[8]。从存储、加载到显示,需要重新审视现有的主流文件存储格式,并配套研发相适应的渲染、大数据挖掘等一系列支持大数据体的核心技术[9]。随着三维地震数据采集、油气田开发等系列新技术带来的快速数据更新,大数据背景下三维数据体的高效存储与处理分析变得越来越复杂[10]。在参考谷歌文件系统设计理念和消化其关键分布式处理技术的基础上,本方法利用三维空间下八叉树结构与编码的快速空间定位机制,实现对三维大数据体的结构分块存储。
1 分布式存储节点及八叉树切分参数配置
地震数据八叉树分布式存储是指对地震数据通过八叉树结构进行切分,切分成多个子块文件后传输到不同存储节点中进行存储,实现分布式存储。分布式存储的结构包括本地、服务器、存储节点三个类型的对象,其中本地存放了待切分的源地震数据,服务器中存放切分和存储节点的参数配置,以及各个子块的编码及存储位置信息,存储节点中存放切分生成的子块以及索引文件。
分布式存储节点的配置包括服务器的地址以及存储节点的地址配置。在进行八叉树切分时,服务器及存储节点会运行数据存取服务程序,其可以实现不同计算机之间的数据发送和接收功能,此服务程序基于RCF的开源代码实现。在配置服务器地址时,输入服务器的网络地址和网络端口号进行连接,服务器会返回当前已经存在的分布式地震数据对象列表,用户新建一个分布式地震数据名表示切分后的地震数据对象,然后输入各个存储节点的网络地址和网络端口号,之后的地震切块会发送到这些存储节点中。
八叉树切分参数的配置是基于八叉树结构。源地震数据可以看作一个三维的数据立方体,长宽高分别对应主测线、联络线和深度。用户配置时会指定小立方体的长宽高方向上的数据量,通过小立方体的长宽高和源地震数据的长宽高比较,得到源地震数据在三个方向上与小立方体三个方向上长度的比值,取比值最大的一个方向并计算满足大于此比值的最小的2 的次幂,这个次幂数即为八叉树切分的层级数。
索引文件中会记录源地震数据三个方向上的数据量以及八叉树的切分方式。通过这两个参数可以推导出地震数据和八叉树子块在空间位置上的对应关系,通过对应关系可以从空间位置得到子块的编号,也可以通过子块编号得到其对应的空间范围。对于源地震数据三个方向上与2的次幂不整除的情况,在计算生成某个子块时,这个子块所在的空间位置可能没有对应的地震数据或者只有一部分地震数据,那么不生成此子块或者只生成有数据部分的子块即可。
2 切块编码及存储节点的分配
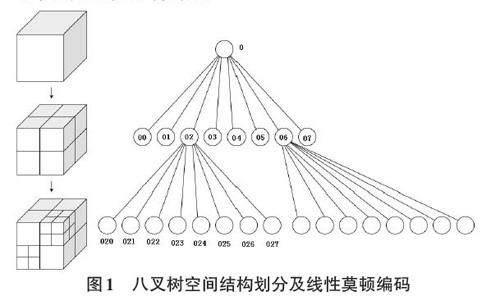
八叉树空间结构的三维空间编码通常采用线性莫顿编码,如图1所示,每一位八进制数位可以看成3 位二进制数,由所在节点的空间位置编码而来(其中,n 表示子体数据块所处的空间结构位置):Morton =[(x0,y0,z0),(x1,y1,z1),...,(xn-1,yn-1,zn-1)]。切分时的每个子块都会有其对应的莫顿码,从莫顿码也可以反推出子块对应的空间范围。
八叉树节点体现了空间坐标信息,同时易于实现自然数的映射,即某一体数据块的具体文件存储位置。莫顿码按照大小排序得到子块的自然数编码(Tile ID) ,进而映射到不同体数据块文件存储位置。读取子块数据时,当给出三维空间数据获取范围时,通过计算八叉树中所在的空间位置得到莫顿码,进而以Tile ID为索引定位数据在文件中的存储位置;同样,给出数据存储位置,也可以计算 Tile ID,得到它在体数据或八叉树中的空间位置。Tile ID从零开始,对应最终层级中莫顿码最小的子块,依次类推。
为了使分布式存储节点在存储多个不同地震数据体子块时,文件名称不相重复,需要对地震数据体的子块命名独有的文件名,本文采用生成随机64位无符号整型数来表示子块的哈希编码(UUID) ,每个子块文件命名为“XXX(UUID).afs”。
子块有莫顿码、Tile ID、UUID三种码,与子块一一对应,从莫顿码和子块长宽高范围也可以推导出其所在的空间位置,从而实现编码和位置信息的关联。
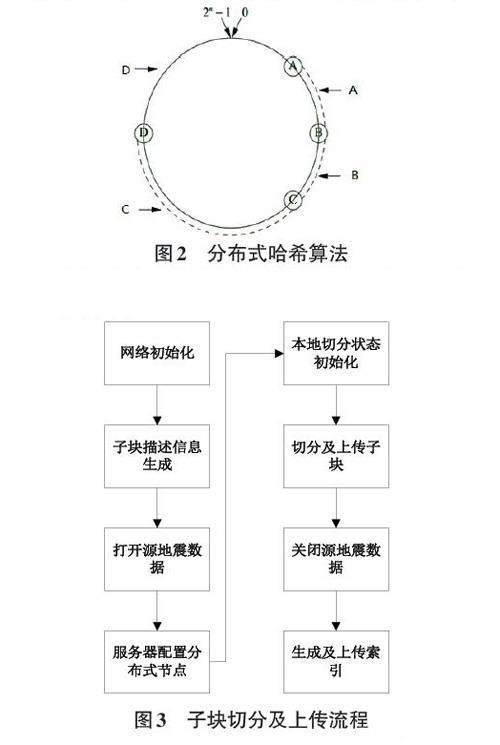
在分配存储节点时,要确定一个子块需要传输到哪些存储节点中,采用的是一致性哈希算法,如图2所示,整数0到2^64-1构成一个圆环,每个存储节点生成一个随机64位无符号整型数据表示存储节点的哈希值,根据哈希值在圆环中所处的位置,将存储节点放在相应位置上,如图中ABCD四个节点。每个子块也有一个UUID,根据UUID落在圆环中的位置,例如在AB之间那么这个子块就分配给A,在BC之间就分配给B,在CD之间就分配给C,在DA之间就分配给D。对于多副本的情况,只需在圆环上顺时针往后面找相应数量的存储节点进行分配,例如有两个副本,那么一个子块分配给A,则再顺时针往下找到B,最后子块会传输到A和B两个存储节点实现多副本。
本地将存储节点配置和子块切分参数配置传给服务器,服务器端完成每个子块生成UUID以及计算其对应的存储节点的工作,并将分布式地震数据名、子块与UUID的对应列表、子块与存储节点的对应列表保存。
3 切分地震数据生成子块
切分地震数据生成子块的流程如图3所示:
1) 初始化网络环境,启动RCF中用来连接服务端的接口,分别启动连接服务器的接口以及连接存储节点的接口。
2) 本地根据子块切分参数配置生成各个子块的莫顿编码和总的子块个数。
3) 打开源地震数据文件,准备读取数据。
4) 将存储节点配置和子块切分参数配置传给服务器,服务器端完成每个子块生成UUID以及计算其对应的存储节点的工作,并将每个子块的文件名返回给本地。
5) 初始化当前切分状态信息,包括切分时的当前子块,带宽,数据传输量,上传的最长最短用时等。
6) 切分源地震数据体生成子块,具体生成一个子块的步骤为:首先根据当前子块的Tile ID得到其莫顿编码,再通过莫顿编码转换为具体的空间范围,对于三维地震数据体,空间范围即主测线、联络线、深度三个方向上的范围,然后循环遍历主测线和联络线,一对主测线号和联络线号确定的平面上的位置称作CDP点,这个CDP点对应一个地震道,按照深度方向的范围从源地震文件中读取这个地震道,然后将数据写入到子块中。
源地震数据的组织方式是按照地震道来排列的,每个地震道的长度相同,在地震道道头中有其主测线号和联络线号,本地首先读取所有地震道头,建立CDP点位置与对应地震道在文件中位置的对应关系(gridpos_filepos) ,有些地震数据里面地震道并不是按照主测线和联络线顺序排列的,可能顺序是乱的。所以在从源地震数据读取地震道时,需要利用grid?pos_filepos来找到其正确的位置。
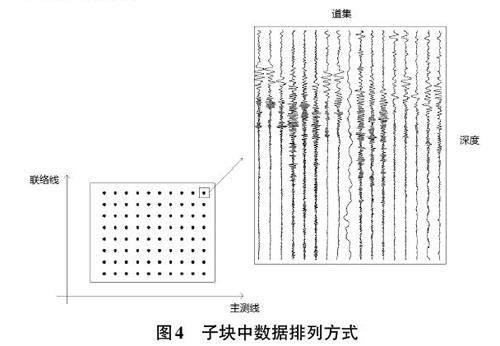
对于叠前地震数据,每个CDP点对应一组地震道而不是一条地震道,此时需要读取一组地震道在子块深度范围内的数据,也是利用gridpos_filepos,此时这个对应关系是一对多的,将所有相同CDP点号的地震道数据读出,然后顺序地写入子块中。gridpos_filepos 会在后续步骤写入索引文件传到存储节点。子块的数据排列方式如图4所示,平面上两个方向分别为切分后的主测线和联络线部分,每个CDP点号对应一个道集,为相同CDP号的一组地震道在子块深度区间范围内的数据。
4 传输子块及索引到存储节点
对于生成的子块文件,传输到对应的存储节点中。首先向服务器发送子块的Tile ID,服务器通过自身存储的子块与存储节点的对应列表,将需要上传的存储节点返回给本地,本地通过与存储节点的数据传输接口,将子块上传到存储节点中。在前面配置参数的步骤中,配置存储节点时需要配置文件存放的具体路径,表示子块在存储节点计算机中存放的位置。存储节点根据当前切分地震数据体的分布式文件名称,对其名称进行MD5哈希得到一个无符号整型数字,在文件存放路径下建立名为此数字的子文件夹,所有当前切分地震数据体的子块都存放在這个子文件夹中,之后子块获取也是根据MD5哈希找到正确的目录去加载。
索引文件内容包括源地震数据主测线和联络线组成的测网形状信息,八叉树参数(层数、子块等方向的大小),子块数量,各子块文件名,gridpos_filepos,源地震数据体深度范围及测网范围。最后,将索引传输到每个存储节点中。
5 加载并使用分布式地震数据
用户指定要加载的分布式地震数据名称,选择后从存储节点中下载索引文件并加载到本地,完成分布式文件的加载。在使用分布式地震数据时,例如想查看某一条主测线的地震道剖面,则根据剖面的主测线号、联络线号、深度范围以及八叉树切分参数,得到对应的子块编号。然后将下载子块的编号发送给服务器端,服务器端根据子块与存储节点的对应关系以及子块编号与子块文件名对应关系,找到子块对应的存储节点及文件路径返回给本地,本地再从相应的存储节点下载子块。子块下载完成后,从子块中对应的位置读取地震数据并形成地震剖面。
一个具体的地震剖面查询流程如图5所示。
1) 通过输入的主测线号或者联络线号,生成一组CDP点位置及起止时间。
2) 对于每一个CDP点位置以及起止时间,首先从缓存中查询,如果缓存中有,则直接返回数据,如果没有,则将CDP点位置转换为在数据立方体长宽平面上的偏移量,将起止时间转换为数据立方体在高方向上的偏移量。
3) 根据偏移量,得到具体的空间坐标范围。
4) 根据空间坐标范围及八叉树切分配置,得到对应的一组莫顿编码。
5) 对于每个莫顿编码,获取对应的Tile ID。
6) 根据Tile ID,在缓存中查询,如果缓存中有,则直接返回数据,如果没有则获取对应的UUID及子块文件名。
7) 如果本地有对应的子块文件,则读取数据并返回,如果没有则向服务器询问子块所在存储节点,服务器根据子块与存储节点的对应列表返回子块所在存储节点,本地再向存储节点下载子块,存储节点根据当前地震数据体的分布式文件名称及子块文件名,找到对应的存储路径,将文件传回本地。
6 结论
本文设计了一种地震数据八叉树分布式存储方法,通过分布式哈希方法对地震子块分配,支持叠前地震数据的子块切分存储,同时提供冗余存储降低数据丢失风险。基于八叉树的分布式存储减少了单机存储空间开销,并且对于相近区域的属性计算和三维渲染在文件访问速度上具有优势。
参考文献:
[1] 陈通,韩雪君,马延路.时序数据库在海量地震波形数据分布式存储与处理中的应用初探[J].中国地震,2022,38(4):799-809.
[2] 庞锐,许自龙,朱海伟,等.面向地震数据交互分析场景的高效分布式缓存框架[J].石油物探,2022,61(6):1090-1098,1114.
[3] 李彩华,滕云田,周健超,等.分布式地震数据采集器的高精度时间同步系统研制[J].地震学报,2022,44(6):1111-1120.
[4] 吴峥,王方建,董翔,等.地震观测数据融合存储技术研究[J]. 地震地磁观测与研究,2023,44(1):115-119.
[5] 周勃,刘万伟.基于HDF5的地震解释成果数据存储技术研究[J].信息系统工程,2022(5):132-135,140.
[6] 朱少华,魏绪云,胡旭辉.从模拟时期到数字时代地震业务数据档案存储研究[J].山东档案,2023(2):79-80.
[7] 杨河山,张世明,曹小朋,等.基于Hadoop分布式文件系统的地震勘探大数据样本采集及存储优化[J].油气地质与采收率,2022,29(1):121-127.
[8] 蒋治刚.StorNext并行存储技术在辽河油田地震资料处理中的应用[J].信息系统工程,2021(9):35-37.
[9] 吕作勇,黄文辉,康英,等.海量多源异构地震监测数据存储和共享服务系统[J].华南地震,2021,41(2):13-18.
[10] 赵辉.地震监测数据的Hadoop存储解决方案[J].华南地震,2020,40(3):70-75.
【通联编辑:梁书】
猜你喜欢
电脑知识与技术(2024年12期)2024-06-16 05:03:12
智能计算机与应用(2022年10期)2022-11-05 07:45:44
枣庄学院学报(2022年5期)2022-09-21 09:35:22
现代计算机(2021年36期)2021-03-14 00:50:40
天津音乐学院学报(2020年1期)2020-06-11 12:39:28
计算机应用(2018年12期)2019-01-07 12:16:36
中国盐业(2018年21期)2018-03-05 08:06:22
知音海外版(上半月)(2018年2期)2018-02-09 18:49:49
机械设计与制造工程(2013年4期)2013-09-12 03:23:04
科技传播(2012年2期)2012-06-13 10:03:26
