
基于变分自编码器的近似聚合查询优化方法
2024-05-25 01:02黄龙森房俊周云亮郭志城
浙江大学学报(工学版) 2024年5期
黄龙森,房俊,周云亮,郭志城
(1.北方工业大学 信息学院,北京 100144;2.北方工业大学 大规模流数据集成与分析技术北京市重点实验室,北京 100144)
近年来,大数据的快速增长和广泛应用对查询处理提出了巨大挑战.在大规模数据集上执行聚合查询是数据分析和决策制定的常见任务.近似查询处理方法(approximate query processing,AQP)[1-2]通过使用抽样、概率估计、统计技术等近似技术,可以快速地计算查询的近似答案且提供一定的精度保证[3-4].
偏态数据分布是指在数据集中存在不平衡的数据分布情况,其中某些属性的取值频率远高于其他属性.该分布可能源于数据收集过程、自然数据特征或者是特定应用领域的限制等因素.采用近似查询处理方法,往往无法有效处理这种偏态数据分布,导致查询结果的准确度下降.分层抽样方法被认为是解决偏态数据分布的有效方法.传统做法通常是依据概率进行抽样,但一次或几次抽样的随机性无法保证所抽样本的分布与原始偏态数据的分布相一致.采用多次迭代的抽样方法可以减轻这一问题,但会带来显著的时间和空间成本.
机器学习驱动的AQP 算法主要关注于使用生成模型表达原数据集的概率密度分布,利用所得的概率密度函数,近似估计查询结果.生成模型具有学习数据分布的潜在变量并快速生成符合该分布数据的特点[5-7],在音频、图像和文字等领域中广泛应用.近年来,生成模型也在近似查询处理方法中用于生成符合原始数据分布的小样本数据[8-9],但如果直接将生成模型应用于偏态数据的学习生成,效果不理想.
本文提出结合分层分组抽样和变分自编码器生成模型的近似聚合查询新方法(group variational auto-encoder,GVAE),通过数据预处理、分层分组、模型优化等手段,训练优化的变分自编码器模型.生成模型后设置采样比例,输入随机噪声到模型中,快速生成小批量样本并执行聚合查询.实验表明,与基准方法相比,对偏态分布数据的近似聚合查询有更小的查询相对误差.
1 相关工作
近似查询处理这一领域的研究历程总体上可以分为以下2 个阶段.1)Olken 等[10]首次提出并实现了在关系型数据库上使用采样技术.此后,在随机采样的基础上,分层抽样和各种离线构建数据概要的方法被广泛研究.在分布式系统被提出后,研究者们关注于如何在分布式场景下离线或在线采样.2)在深度学习技术推动的 AI 浪潮下,研究者逐渐意识到机器学习模型对数据的强大拟合能力,基于生成模型的AQP 算法在这种背景下被提出.现行的AQP 算法主要包含在线算法、离线算法与机器学习算法3 种[11-12].在线 AQP 算法的主要目的是在查询执行期间设计合理的采样策略,基于在线采样计算OLAP 的近似查询结果,并为该近似查询结果设计误差估计算法[13-14].
基于离线算法的近似查询处理方法主要通过分析历史查询日志和原数据集,对数据总体进行采样或计算其关键统计信息,利用这些信息近似回答在线查询[15-18].
基于机器学习的近似查询处理算法分为以下2 类:1)使用神经网络直接学习原始数据分布到生成数据分布的映射;2)利用生成模型学习原始数据分布的潜在特征,根据潜在特征对随机变量的分布变换,生成与原始数据分布相似的数据样本.变分自编码器(variational auto-encoder,VAE)[19]和生成对抗网络[20](generative adversarial network,GAN)是生成模型中经典的2 类模型.VAE 模型学习数据的低维潜在特征(均值和方差),快速拟合数据分布并生成具有较高相似度的数据,提供用于聚合查询的数据样本.
Thirumuruganathan 等[21]提出使用变分自编码器模型(VAE-AQP)对原始数据分布进行建模,生成高效、交互式的总体估计.VAE-AQP 存在处理偏态数据时相对误差不够精确的问题,难以拟合期望的数据分布,影响查询准确率.
GAN 通过判别网络和生成网络相互对抗和学习的方法,降低生成样本和原始数据之间的聚合查询误差.Zhang 等[22]介绍了基于条件生成模型的近似查询处理方法,提出使用基于Wasserstein的条件生成对抗网络(conditional -Wasserstein generative adversarial network,CWGAN)来有效地处理Group-by 查询,在节省计算资源的同时保持较高的结果精度.GAN 在训练过程中没有明确的指标确定模型达到纳什均衡,容易出现模型坍塌的问题.
2 基础定义
2.1 聚合查询
讨论如下所示的查询语句:
其中,T为数据集,T={X1,X2,···,Xn}.每个属性 Xi都可以用作查询中的条件和 COND中的属性,也可以用作分组聚合的属性.WHERE 和 G ROUP BY子句都是可选的,G是分组查询中的指定分组列名.COND可以是多个条件同时判断,每个条件都可以是 Xiop CONST形式的任何关系表达式,其中Xi是一个属性,op∈{=,<,>,≤,≥},CONST是指判断条件的具体数值.AGGR是在AQP 相关研究中广泛 研究的COUNT、AVG、SUM 聚合函数.
2.2 偏态系数
偏态(skewness)是指对数据分布对称性的测度[23].偏态分布(skewness distribution)指频数分布的高峰位于一侧,尾部向另一侧延伸的分布.它分为正偏态和负偏态,正偏态和负偏态由偏态系数来决定,若偏态系数大于0,则该分布为正偏态,反之为负偏态,如图1 所示.

图1 左偏分布、右偏分布与正态分布的比较Fig.1 Comparison of left-skewed and right-skewed distribution with normal distribution
一般可以用偏态系数(coefficient of skewness,SK)刻画偏态程度,计算方法如下所示:
式中:Xi为第 i个数据点,X为样本均值,S为样本标准差,n为数据的样本大小.|SK|∈(0,0.5)为轻度偏态分布,|SK|∈(0.5,1.0)为中度偏态分布,|SK|∈(1.0,+∞)为高度偏态分布.
2.3 聚合查询误差
聚合查询误差由相对误差(relative error difference)来计算,记为 Rq.设聚合查询语句 q 的查询结果真值为 θ,AQP 查询估计值为 θ˜,则相对误差的计算如下:
设通过分组聚合查询语句 q给出一个组 G,G={g1,g2,···,gn}为分组结果的不同组别.其中,AQP 聚合查询结果组别可能不包含在 G中.设真实数据的组别为 {g1,g2,···,gn},gi∈G,对应组的真实数据查询结果集合为 θ={θ1,θ2,···,θn},AQP查询估计值当m>r时有真实数据不存在的组别,不具有统计价值,因此不作考虑.缺失的分组项设置为100%.计算平均相对误差如下所示:
2.4 不同偏态系数聚合查询的相对误差
以PM2.5 数据集①http://archive.ics.uci.edu/ml/datasets/Beijing+PM2.5+Data.为例,给出2010~2014 年的气象环境数据,部分数据如表1 所示.表中,ρB为PM2.5 的质量浓度,CBWD 为风向,IWS 为累计风速.

表1 PM2.5 数据集的示例Tab.1 Example of PM2.5 dataset
利用CWGAN 和VAE-AQP 学习原数据分布生成的模型,对不同 Field 字段分组聚合查询,相对误差如表2 所示.

表2 不同模型下不同数据偏态系数的相对误差Tab.2 Relative errors of bias coefficients for different data under different models
3 GVAE 方法
该GVAE 方法的处理过程如图2 所示,主要包括数据预处理、模型训练、数据生成、聚合查询4 个步骤.
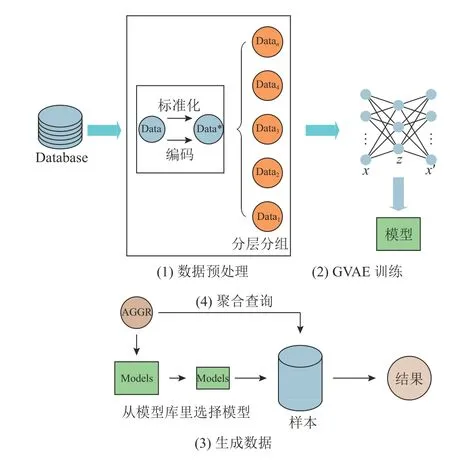
图2 GVAE 方法的流程图Fig.2 Flowchart of GVAE method
数据预处理是将数据集数据转换为可以被神经网络学习的数据,共分为数据编码、数据标准化和数据分层分组3 部分.其中数据编码将类别少的数据转换为数值,便于GVAE 模型计算.数据标准化可以在保留数据分布特征的前提下消除不同数据之间的量纲差异,便于神经网络梯度迅速下降,快速收敛.
数据分层分组是为了学习不同列的偏态分布并生成小样本数据,其中分组是为了使变分自编码器学习和生成小批量数据,而分层的目的是使每一组的数据分布都与原偏态数据的分布相似.
GVAE 模型训练是将已经预处理好的数据输入到神经网络中学习,得到模型库后,根据不同的聚合查询语句从模型库中选取模型,根据一定的样本比例生成数据,对样本执行聚合查询.3.2~3.4 节将进一步描述上述内容.
3.1 数据预处理
对数据进行预处理,包括数据的编码、标准化和分层分组3 部分,如图2 的数据预处理部分所示.
3.1.1 数据编码 机器学习中常用的编码为二进制编码和独热编码(one-hot encoding),例如将数值 [1,2,3,4]编码为 [0001,0010,0100,1000],可以看出编码位数和数值种类数成正比.机器学习过程中每一批的数据维度需要增加,加大了学习训练时间的开销.
本文使用的是标签编码(label encoder)[24].标签编码是根据字符串形式的特征值在特征序列中的位置,为其指定一个数字标签.针对有不同数据类型的数据,需要对其格式进行转换.对每一列数据统计分类和类型个数.分别对每一类标号,将真实值替换为标号值.
需要转换为编码的数据类型为类别和数值2 类.如表1 所示,字段 CBWD的数据类型为类别类型,为了适应神经网络学习,必须对数据进行编码.其中字段CBWD共有4种取值:[SE,NE,SW,CV],编码后为 [1,2,3,4];字段 Year共5 种取值:2010~2014,因其数值大且类别少,3.1.2 节中的标准化过程计算更复杂,需要将其编码,减小计算难度.
3.1.2 数据标准化 在机器学习算法中,数据标准化和归一化是2 种常见的特征缩放(feature scaling)方法.其中归一化指的是将数据的每一列的值缩放至0~1.0.对于偏态分布数据,在缩放过程中会导致分布特征消失,因此不选择使用归一化.
通过数据标准化,可以缩小数据的取值范围,不会丢失原始数据分布的特征,也可以将数据转换为近似的标准高斯分布,便于GVAE 模型学习数据分布.标准化过程如下所示:
式中:X为多维的数据向量,Xij为X 中第i 行第j 列数据;µj为数据第j 列的均值,σj为数据第j 列的标准差.通过将数据向量减去均值向量,再除以标准差向量,可以实现多维数据的标准化处理.计算每一列数据的均值和方差,将数据标准化,理论上数据是多少维,均值和方差也是相同的维度.将均值和方差向量保存,用于生成数据后的逆标准化.
3.1.3 分层分组 分层分组算法如算法1 所示,为了便于GVAE 一次性拟合每一组的分布,参考经典VAE 学习图片数据的方法,将数据展开为一维向量,加速GVAE 学习的速度,拟合更准确.
根据算法1,对表1 所示的数据集进行训练.设置每一组样本的数据规模为1 000,记为基数.将4 000 条数据对应分为4 组,聚合查询语句如式(1)所示,保持GVAE 模型网络结构和采样比例不变,统计平均训练时间和查询准确率,如表3所示.表中,Ng为每一组的数量,Tavg为训练时间,Acc为近似查询准确率.当数据规模为10 000~100 000 时,以1 000 为基数分组,兼顾了训练时间和查询准确率,若数据规模更大,则可以考虑根据数据量设置更大的基数.
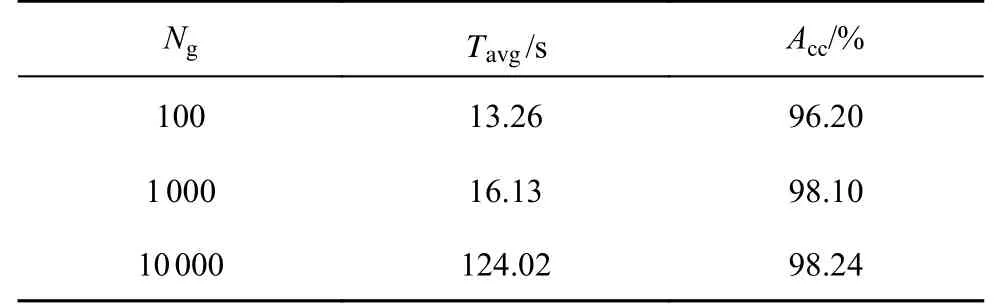
表3 分组基数的比较Tab.3 Comparison of subgroup bases
不同分组方法对学习效率的影响,比较区间分组和分层分组方法,数据集分为样本大小相同的若干组.任意重复选取2 组数据,计算总体数据和单列数据(CBWD)的均值(mean)、方差(Std)和KL 散度(KL)平均值,2 种分组方法的比较结果如表4 所示.

表4 区间分组样本分布的比较Tab.4 Comparison of sample distribution for interval grouping
分层分组算法是在对数据分组之前先对数据分层,根据不同的聚合查询语句 Aggr的数据类别数量,计算每个类别占总数据的比例,根据每层的比例对数据分组.若 G有多个字段,则执行多次分层抽样,使得分组后的数据分布与多个字段的原数据分布相似.根据离散数据和连续数据的分组方式不同,离线数据可以以直接分层的方法实现;连续数据考虑先聚类为几个层级,再进行分层抽样.对于连续数据,会产生更多误差,若不考虑时间开销,则可以考虑将数据排序后等距分组,以高时间复杂度的代价换取低误差.
分层分组算法带来了更多的时间和空间开销.假设总体大小为 N,分为 n 个层级,每个层级的大小分别为 N1,N2,···,Nn.指定每组样本大小为M,假设每个层级的抽样比例为 p1,p2,···,pn,满足 M=N1p1+N2p2+...+Nnpn.将一列数据分为 n个层级的时间复杂度为 O(N),空间复杂度为 O(n),存储层级信息.从数据中反复抽样 m组,m=N/M,每一层抽样时间的复杂度为 O(Nipi),因此抽样需要 O(m(N1p1+N2p2+...+Nnpn))=O(mM)=O(N)的时间复杂度,存储分组数据也需要 O(N)的存储开销.时间复杂度为 O(2N)=O(N),空间复杂度为O(N)+O(n)=O(N).
每一组数据是从原始数据依据聚合查询语句的字段分层随机抽样得到,字段不同,分组分层抽样的方式不同,分组数据也不同.不同的查询字段对应不同的模型.有相同G 的查询字段可以使用对应查询字段的查询语句训练得到的模型.
3.2 GVAE 模型训练
针对本文关注的问题,GVAE 与经典VAE 模型相比,主要在神经网络结构和损失函数2 个方面进行了改进.
3.2.1 神经网络模型 变分自编码器是一类生成模型,它可以学习复杂的数据分布并生成样本.VAE 的训练效率高,具有可解释的潜在空间.
生层模型中的潜在变量是捕获用于生成建模的数据特征的中间数据表示.设 X是希望建模的数据,z是潜在变量,P(X)为由属性 A1,···,Am组成的潜在关系的概率分布,P(z)为潜在变量的概率分布,则 P(X|z)是 给定潜在变量的生成数据的分布.
将式(5)代入式(6),式(6)也被称为变分目标(variational objective),此时可以将 P(X|z)和 Q(z|X)相关联,即用 Q(z|X)来替代 P(z|X),推断出 P(X|z).式(6)的第1 项为重构损失,第2 项为KL 散度.
神经网络结构如图3 所示,编码器将输入数据 X映射到潜在空间,解码器将潜在向量 z 映射回原始数据空间,通过学习数据的潜在特征 µ 和 σ并生成新数据样本 X′.GVAE 模型的编码器和解码器分别为3 个全连接层,深度为3 时可以兼顾学习效率和查询准确率.
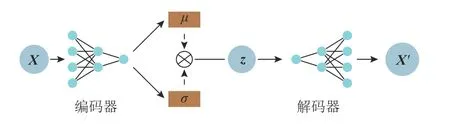
图3 变分自编码器的神经网络结构Fig.3 Neural network structure of variational auto-encoder
经典VAE 模型中,图片像素归一化后为(0,1.0),因此需要在解码器部分加上Sigmoid 函数,将生成值的取值范围限制为 (0,1.0).对于一般数据,取值范围不定,根据3.1.2 节所示的方法将数据标准化后,取值范围不限定在 (0,1.0),因此需要去掉Sigmoid 函数.
神经网络的其他部分设置如下:学习率为1×10-5,模型优化器为AdamOptimizer,激活函数为Relu,神经元数设置为40 和2,重构损失函数为均方误差.神经元数对生成的数据和查询准确率无明显影响,但神经元数过多会增加不必要的训练时间开销,神经元数过少则不利于梯度下降和损失函数收敛.
3.2.2 损失函数 经典VAE 的损失函数由重构损失和KL 损失2 部分构成,如式(7)所示.在模型训练的过程中,由于不同批数据分布相似但不完全相同,容易导致VAE 后验崩塌(posterior collapse)的问题,即散度消失,重构部分过早达到ELBO 上界.
针对该问题,参考文献[25],给KL 项乘上权重系数 kl_coef,从0 到1.0 逐渐增大,并乘上放大倍数 m,此处设置 m=10.如此可以使得梯度下降速度放缓,留出部分下降空间给重构损失.经过实验测试,改进后的训练拟合效果更好,查询准确率更优.
3.3 数据生成
GVAE 通过多个全连接层层学习数据的隐含变量得到模型,读取模型网络的变量.将标准高斯分布变量 z输入到模型中,拟合原数据分布数据,生成数据的样例如下所示:
这是符合标准高斯分布的2×4 的随机数字矩阵 z.根据3.1.3 节的数据分组所示,矩阵行数为2 表示2 组,即生成2 ×1 000 条数据,列数为4 表示生成数 据的维度.
3.4 聚合查询
根据不同查询字段训练模型后,通过聚合查询语句的查询字段,从模型库中选取对应查询类的模型.根据适当的采样比例,生成小批量数据,对数据进行逆变换,并保存到数据库中,最后查询数据,计算查询相对误差.聚合查询过程如算法 2 所示.
4 实验与分析
4.1 实验设置
实验环境为Intel(R)Core(TM)i7-7700HQ CPU;16 GB 内存;500 GB 硬盘;操作系统为Windows 10;采用Visual Studio Code 2019 编辑器和Python 3.10 语言版本,使用Pytorch 实现生成模型的搭建.
1)实验数据集.选用2 个数据集进行实验,分别为 Beijing PM2.5 真实数据集和TPC-H 合成数据集.
a)Beijing PM2.5 数据集.该数据集包含了美国驻北京大使馆的PM2.5 数据的信息和北京首都国际机场的气象数据.数据集包括年月日、PM2.5、气温、压强和风向等字段,字段类型多样.共43 824 条数据.控制不同列的偏态系数为0~1.0,间距为0.2,总共5 份数据集.
b)TPC-H 数据集.获取TPC-H 数据生成工具,通过调整参数和比例,设置偏态系数为0~1.0,间距为0.2,生成5 份合成数据集.每份数据集包括多个表,如订单(orders)和供应商(supplier).每个表包含特定字段,模拟真实世界的企业数据仓库.每一份合成数据集都是500 万条,支持多种分组聚合查询.
2)查询语句.针对不同数据集的不同字段,执行分组聚合查询和条件查询语句,如下所示.
a)Beijing PM2.5 数据集
其中,CONST为判断条件的具体数值.
3)评估指标.对实验数据集进行测试,主要考虑训练时间和查询准确率.查询准确率使用如式(3)所示的相对误差进行计算.
4)实验过程.
a)数据分布拟合效果的实验.
通过计算真实数据和生成数据的累积分布函数(CDF),观察模型拟合数据分布的效果.
b)不同模型方法的比较.
为了更好地体现GVAE 对偏态数近似聚合查询的优越性,选择VAE-AQP 和CWGAN 模型方法与GVAE 进行比较,对比不同模型方法在同偏态系数下的查询相对误差.
c)消融实验.
以GVAE 模型方法为基础,将选择编码方式为标签编码还是独热编码、标准化或者归一化对聚合查询准确率的影响,分别记为GVAE(E)和GVAE(O)、GVAE(S)和GVAE(N).
将是否增加GVAE 模型中改进的两部分,Sigmoid 层和KL 损失改进,分别记为GVAE(M)和GVAE(KL),开展消融实验,能够更好地体现该算法对偏态数据近似聚合查询的优越性.
d)其他实验.
测试其他变量,如不同维度或不同采样比例对聚合查询相对误差的影响.
4.2 实验结果与分析
4.2.1 数据分布拟合效果实验 为了度量原始数据分布和生成数据分布之间的相似性,选用连续列的kolmogorov-smirnov(KS)统计量[26]来评估,如下所示:
式中:F1和 F2分别为原数据和生成数据的概率分布函数(CDF),sup为上确界.基于KS 统计量,比较生成数据与真实数据的CDF.如图4 所示为真实数据集G 和合成数据集R 的GVAE 方法生成数据分布与原始数据分布的CDF 曲线.图中,X 为数据标准化后的取值,Y 为对应取值的概率累积值.

图4 不同数据集的CDFFig.4 CDF for different datasets
图4(a)、(b)的 KS统计量分别为0.04 和0.03,这表示真实数据和生成数据CDF 之间的最大差异小,说明2 个分布之间的相似程度很高.
4.2.2 不同模型方法的比较 根据4.1 节的查询语句,多次查询真实数据和生成数据,计算不同的评估指标.
如图5(a)、(b)所示为PM2.5 数据集和TPCH 数据集,分别统计在不同偏态系数的不同规模的数据集,近似聚合查询的相对误差平均值.对比GVAE、VAE-AQP 和CGWAN 模型方法,针对不同偏态系数的数据,近似聚合查询有更小的查询相对误差,且随着偏态系数的提高,相对误差增大的幅度不超过2%,上升趋势更平缓,查询结果的相对误差偏移更小.

图5 不同偏态系数查询的相对误差Fig.5 Relative errors for queries with different bias coefficients
4.2.3 消融实验 如图6(a)、(b)所示,分别测试PM2.5 数据集和TPC-H 数据集对不同条件下的GVAE 模型计算不同偏态系数下的数据聚合查询误差,如4.1 节的消融实验所示设置变量,可以看出不同变量对聚合查询相对误差的影响.

图6 不同数据集和偏态系数的消融实验Fig.6 Ablation experiment with different dataset and skewed coefficient
在相同消融条件下,GVAE(N)的查询相对误差比GVAE(S)高3%~5%,影响明显.
4.2.4 其他实验 如图7(a)所示,在数据维度T >6的情况下,GVAE 模型方法能够保持较小的相对误差,CWGAN 和VAE-AQP 的相对误差比GVAE 高.GVAE 与这2 种模型方法相比,随着数据维度的增加,查询时间和查询准确率都有明显优势.GVAE 有确定的学习下界ELBO,便于衡量是否停止训练.CWGAN 无法衡量何时达到纳什均衡并停止训练.VAE-AQP 相对于CWGAN 有更小的相对误差,但如图7(b)所示,在相对误差相近的前提下,CWGAN 和VAE-AQP 的训练时间比GVAE 长.这是因为在预处理阶段已经将偏态数据处理为更适合模型学习的数据,每一组数据的分布相似,学习时的误差下降更快,训练时间更短.

图7 不同维度下的模型比较Fig.7 Model comparison in different dimensions
如图8 所示,对于不同规模的数据集PM2.5和TPC-H,Q1、Q2、Q3分别为4.1 节查询语句b)中的第4、5、6 条查询语句.在GVAE 方法中其他参数不变的情况下,Rq与采样比例(sampling rate,SR)没有明显关系.查询的误差会小幅度波动,波动幅度小于0.5%.
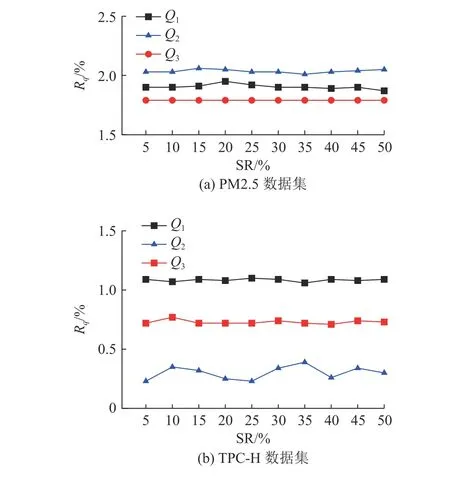
图8 不同采样比例的相对误差Fig.8 Relative error of different sampling rate
当模型生成数据时,只能生成分组基数的整数倍,提高抽样比例只会增加生成数据的组数,生成数据分布几乎不变,所以相对误差不会大幅波动.
5 结 语
本文提出基于变分自编码器的数据近似查询处理优化方法,在数据预处理阶段通过数据编码和数据标准化,根据不同字段将偏态数据分层分组,便于GVAE 方法更好地训练拟合的数据分布.加入了对损失函数的优化,避免过拟合.实验结果表明,与对比算法相比,该方法对偏态分布数据的聚合查询有更低的查询误差.
利用GVAE 方法学习偏态数据分布迅速,损失函数很快就收敛到一个定值,难以衡量是否训练完成.下一步将深入研究为何导致其快速收敛,寻找新的衡量指标判断训练是否结束.
猜你喜欢
数码设计(2020年16期)2020-12-08
高师理科学刊(2020年1期)2020-11-26
新世纪智能(语文备考)(2020年4期)2020-07-25
江苏科技大学学报(自然科学版)(2018年6期)2018-02-15
电子技术与软件工程(2016年8期)2016-07-10
中兴通讯技术(2016年2期)2016-03-24
财经理论与实践(2015年2期)2015-04-16
集美大学学报(自然科学版)(2015年6期)2015-03-03
北方经贸(2014年8期)2014-09-21
语文知识(2014年4期)2014-02-28
