
基于异质图卷积神经网络的论点对抽取模型
2024-05-25 01:02刘议丹朱小飞尹雅博
浙江大学学报(工学版) 2024年5期
刘议丹,朱小飞,尹雅博
(重庆理工大学 计算机科学与工程学院,重庆 400054)
论点对抽取(argument pair extraction,APE)属于对话式论辩,目的是为了从2 个相关的文章中抽取出交互式的论点对,是论辩挖掘中的新兴任务[1-5].Cheng 等[6]首次在同行评审和反驳中提出论点对抽取任务,因为同行评审和反驳中包含丰富的论点.它主要包含以下2 个步骤:1)从评审段和反驳段中识别出论点;2)判断2 个论点是否属于同一个论点对.
Cheng 等[6]将论点对抽取任务分解为序列标注任务和句子对分类任务,通过多任务学习框架来同时优化这2 个子任务.由于仅采用多任务学习的方式没有充分利用2 个段落的独特特征以及段落之间句子的交互信息.Cheng 等[7]提出注意力引导的多层多交叉模型,隐式建模2 个段落句子间的关系,将句子对分类任务视为表格填充任务,采用2D-GRU 来更新表格的表示.Bao 等[8]提出相互指导的框架,通过评审段识别出的论点来指导反驳段论点的识别,反之也可以通过反驳段识别出的论点来指导评审段论点的识别.Bao 等[9]认为之前的工作建模的都是句子级别的交互,忽略了对论点级别交互的建模,提出具有两阶段的机器阅读理解(machine reading comprehension,MRC)框架.
尽管上述论点对抽取算法取得了一定的效果,但任务存在以下2 个问题.1)没有充分建模评审段和反驳段句子之间的交互信息.2)忽略了对评审段及反驳段内句子的相对位置进行建模.为了解决上述2 个问题,本文提出基于异质图卷积神经网络的论点对抽取模型(heterogeneous graph convolutional neural network for argument pair extraction,HGCN-APE).在评审段和反驳段中构建异质图,定义2 种不同类型的节点、4 种不同类型的边,通过关系图卷积神经网络来更新节点的表示.除此之外,设计位置感知句子对生成器,建模评审段和反驳段内句子的相对位置信息.
总的来说,本文的贡献主要可以分为以下几个方面.
(1)针对以往基于图的论点对抽取工作,难以充分建模评审段和反驳段句子间的交互关系问题,构建异质图,定义2 种不同类型的节点及4 种不同类型的边,区分段落内和段落间句子的交互信息.
(2)考虑到评审段和反驳段论点先后顺序有联系,设计位置感知的句子对生成器,采用旋转位置编码来建模段落内和段落间句子的相对位置信息.
(3)在RR-passage 和RR-sumbmission-v2 数据集上的实验结果表明,本文提出的模型优于所有的基线模型.为了促进论辩挖掘中论点对抽取的研究,将代码进行开源:https://github.com/ElevateSpirit/HGCN-APE.
1 相关工作
1.1 论辩挖掘
论辩挖掘的目的是从具有辩论性的文本中自动提取出论点[5],近年来受到了越来越多的学者关注.它在现实生活中有着广泛的应用,如司法庭审[10]、AI 辩论[11]、写作助手[12]等.目前对论辩挖掘的研究主要可以分为2 个方面:独白式论辩和对话式论辩.以往的工作大多集中在独白式论辩的研究,而相比于独白式论辩,在现实生活中对话式论辩更常见.Ji 等[13]基于在线辩论平台的数据构建数据集,提出交互式论点对识别任务.Yuan 等[14]提出使用外部知识来增强交互式论点对识别,在上下文中对实体和路径进行编码,以获得实体的嵌入和路径表示.Shi 等[15]提出对比学习框架,去除文档中与论点识别不相关的信息.Cheng 等[6]在同行评审的反驳中提取论点对抽取任务,将论点对抽取分解为序列标注和句子匹配任务,通过多任务学习框架同时优化这2 个子任务.Cheng 等[7]提出注意力引导的多层多交叉模型,隐式建模2 个段落句子之间的关系.Bao 等[8]提出互指导框架,构建句间关系图,显示建模2 个段落句子之间的关系.Bao 等[9]将论点对抽取视为两阶段阅读理解任务,将识别出的论点作为问题,在另一个段落中查询与之匹配的论点对.
1.2 图神经网络
图神经网络(graph neural network,GNN)包括图卷积网络(graph convolutional network,GCN)[16]、图注意力网络(graph attention network,GAT)[17]、关系图卷积网络(relational graph convolutional network,RGCN)[18]等,得益于其强大的表示能力,在许多自然语言处理(NLP)任务中表现出优异的性能.Wang 等[19]将关系图卷积网络应用于方面情感分析中.Hu 等[20]提出基于异构图神经网络的方法,用于半监督短文本分类.
最近,图神经网络已经应用到了论点对抽取领域.Yuan 等[14]提出利用外部知识来提升论点对抽取的效果,在在线论坛数据集上构建论证知识图.Bao 等[8]在评审反驳段落中构建句间关系图,通过图卷积网络更新节点的表示.与以往基于图的论点对抽取工作不同,本文构建的图是异质的,定义了不同节点的类型及边的类型,通过关系图卷积神经网络建模句子之间的复杂关系.
2 模型简介
2.1 问题定义
给定评审段落 V={v1,v2,···,vm}和反驳段落B={b1,b2,···,bn},其中 m 和 n分别表示评审段中有m个句子,反驳段中有 n个句子.在每个段落中,可以将句子划分为论点和非论点,评审段落中的论点,反驳段落中的论点,其中 lv和 lb分别表示评审段中有 lv个论点,反驳段落中有 lb个论点.论点对抽取的目的是从评审段落和反驳段落中匹配讨论同一个话题的论点其中 lp为评审反驳段中论点对的个数.提出的HGCN-APE 模型架构如图1 所示.

图1 HGCN-APE 模型架构Fig.1 Model architecture of HGCN-APE
2.2 句子编码器
对句子中每个词的表示进行加权求和,得到最终句子的表示.这样做的目的是充分利用句子中每个单词的语义信息:
为了提升模式的泛化能力,引入Dropout[23]策略,随机丢弃网络中部分神经元间的连边:
通过上述步骤,可以得到评审段落和反驳段落中每个句子的表示:
为了捕获每个段落句子之间的上下文信息,将评审段和反驳段中所有句子的表示输入到BiLSTM[24]中,把前项和后项的表示拼接在一起,得到上下文感知的句子的表示:
2.3 异质图卷积层
在得到评审段落和反驳段落中所有句子的表示后,为了建模段落内部和段落之间句子的复杂关系,构建异质图,如图2 所示.
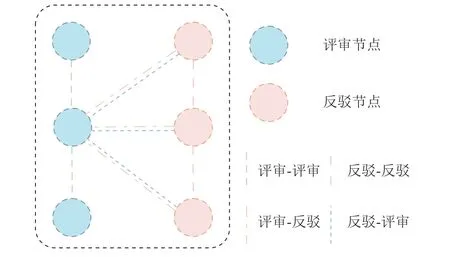
图2 HGCN-APE 异质图构建Fig.2 Heterogeneous graph construction of HGCN-APE
2.3.1 异质图构建 如图3 所示,在构建的异质图中,包含了2 种类型的节点,分别是评审段落中的句子节点和反驳段落中的句子节点以及4 种不同类型的边.
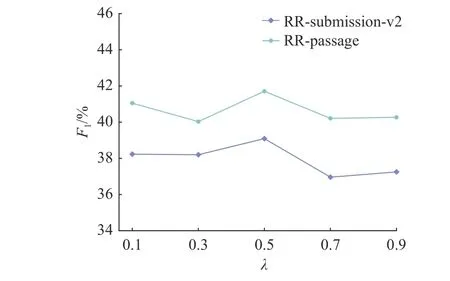
图3 HGCN-APE 超参数 λ的影响Fig.3 Effect of HGCN-APE hyper-parameterλ
评审-评审边.评审-评审边用于建模评审段内部句子之间的关系,评审段中相邻2 个句子之间有连边.
反驳-反驳边.反驳-反驳边用于建模反驳段内部句子之间的关系,反驳段中相邻2 个句子之间有连边.
评审-反驳边.评审-反驳边用于建模评审反驳段可能属于同一个论点对句子之间的关系,用评审节点的表示来增强反驳节点的表示.参考Bao 等[8]的工作,利用NLTK 对评审段和反驳段中的每个句子进行分词处理,并去除停用词,只有当去除停用词的2 个句子之间的共现词数量大于2 时,才会有连边.
反驳-评审边.反驳-评审边的目的是用反驳段节点的表示去增强评审段节点的表示.
2.3.2 异质图聚合 在构建好异质图后,使用句子编码器得到的评审段落中每个句子的表示以及反驳段落中每个句子的表示,分别初始化图中评审节点的表示和反驳节点的表示.
使用关系图卷积网络(relational graph convolutional network,RGCN)[18]来更新节点的表示:
2.4 位置感知句子对生成器
在论文投稿过程中,当审稿人给出评审意见后,作者会针对审稿人提出的意见进行回复.事实上,作者会按照审稿人提出评审意见的顺序进行回复,然而以往的工作忽略对相对位置信息的建模.
采用旋转位置编码(rotary position embedding,RoPE)[25],建模评审段和反驳段内句子间的相对位置关系:
式中:PEv∈Rm×2d,PEb∈Rn×2d分别为融合相对位置编码的评审段句子的表示和反驳段句子的表示.
将评审段和反驳段中两两句子的表示拼接在一起,构成 m×n的表格,用于句子对预测:
式中:T∈Rm×n×d为表格的表示,Wp∈Rd×4d,bp∈Rd为可训练的参数,[ ;]表示拼接操作.
BiLSTM 层和异质图卷积层可堆叠多层来更新表格的表示,不同层之间采用残差连接,并进行层归一化:
式中:l为堆叠的层数,LayerNorm(*)表示层归一化.
2.5 预测层
2.5.1 论点预测 给定评审段的句子序列 V={v1,v2,···,vm}和反驳段中的句子序列bn}以及它们对应的标签论点预测的目的是给每一个句子分配一个标签,是序列标注问题,通过条件随机场(conditional random field,CRF)[26]来实现.
具体来说,以评审段的句子序列为例(反驳段的预测类似),计算观测序列和标签序列之间的得分:
计算给定 V下标签 Yv的条件概率:
CRF 的损失函数可以定义为
通过同样的步骤,可以得到反驳段论点识别的损失 Lb.论点预测的损失函数由2 部分组成,分别是评审段的论点预测损失 Lv和反驳段的论点预测损失 Lb,
2.5.2 句子对预测 句子对预测的目的是判断评审段和反驳段中两两句子是否属于同一个论点对,是二分类问题.通过多层感知机(multi-layer perceptron,MLP),得到句子对概率分布:
式中:Tij为评审段中第i 个句子和反驳段中第j 个句子在表格中的表示,Pij为这两个句子属于同一个论点对的概率.使用交叉熵损失,计算预测值与真实值的偏差:
式中:yij∈{0,1}为句子对的真实标签,0 表示2 个句子不属于同一个论点对,1 表示2 个句子属于同一个论点对.
2.6 模型优化及预测
模型最终的损失函数包含2 个部分:论点预测和句子对预测.采用多任务学习的方式同时优化这2 个损失,最终的损失函数定义为
式中:λ为超参数,用于调节2 个子任务损失的权重.
参照Cheng 等[6-7]的工作,最终论点对的预测由2 个子任务的结果组合而来.具体来说,只有当识别出的评审段论点和反驳段论点 满足如下条件时,这2 个论点才属于同一个论点对.
式中:I为指示函数.
3 实验分析
3.1 实验设置
3.1.1 数据集和评估指标 采用论点对抽取广泛应用的评审-反驳数据集(review-rebuttal,RR)[6]来评估模型的性能,该数据集收集了ICLR 上的4 764 篇评审反驳对.它包含2 个版本:RR-Passage 和RR-Submission-v2.每一个版本按照8∶1∶1的比例,划分为训练集、验证集和测试集.在RRPassage 中,同一篇文章的论点对均包含在训练集、验证集或者测试集中的一个;在RR-Submission-v2 中,同一篇文章的论点对可能同时分布在训练集、验证集和测试集中.数据集的统计结果如表1 所示,表中,Nvb为评审反驳对数,Ntr为训练集数,Ndev为验证集数,Nt为测试集数,Nf为句子总数,Na为论点总数,Ns为论点句子总数。
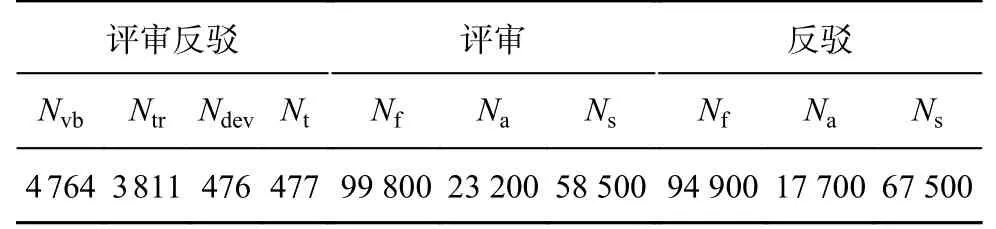
表1 论点对抽取数据集统计Tab.1 Statistics of argument pair extraction dataset
在论点预测、句子对预测、论点对预测上的评估指标均采用精确率P(precision)、召回率R(recall)和F1.
3.1.2 基线模型 为了验证提出模型的有效性,与以下的基线模型进行比较.
1)MT-H-LSTM-CRF[6].MT-H-LSTM-CRF 将论点对抽取任务分解为序列标注任务和句子对预测任务,通过多任务学习框架来同时优化这2 个子任务.
2)MLMC[7].MLMC 提出多层多交叉编码器模型来充分建模2 个段落句子之间的关系,将句子对预测视为表格填充问题,引入注意力损失来更好地预测论点对.
3)MGF[8].MGF 是互指导框架,包含评审指导和反驳指导.先识别出评审段中的论点,再将该论点拼接到反驳段中,找出与之匹配的论点,反之亦然.
4)MRC-APE-Bert[9].MRC-APE-Bert 将论点对抽取任务视为两阶段阅读理解任务:第1 阶段先识别出评审段和反驳段中的所有论点,第2 阶段将每个识别的论点作为查询,在另一个段落中找与之匹配的论点.由于MRC-APE[9]使用Longformer[27]对句子进行编码,为了公平比较,本文采用其Bert 版模型作为基线.
3.2 实验简介
HGCA-APE 模型基于Pytorch 实现,使用BERT-Base-Uncased 作为基准模型,在训练过程中冻结它们的参数.采用AdamW[28]优化器优化模型,使用余弦退火策略在每个轮次后调整学习率.训练轮数设置为25,批处理大小设置为1.在2 个数据集上的超参数 λ均设置为0.5,堆叠层数 L设置为3,图卷积的层数设置为1,丢弃率设置为0.5.所有的实验均用不同的随机种子运行5 次,最终结果为5 次实验的平均值.
为了验证提出模型的有效性,在2 个基准数据集RR-submission-v2 和RR-passage 上进行实现,与一系列的基线模型进行比较.
如表2 所示为模型在论点对抽取及2 个子任务上的结果.表中,“—”表示这些基线模型没有将论点对抽取任务视为序列标注和句子对预测任务,最好的结果用加粗表示,次优的结果加“_”.从表2 可以看出,本文模型在2 个基准数据集上的结果均达到了最优的结果,在RR-submissionv2 数据集上提升了3.63%,在RR-passage 数据集上提升了13.28%.
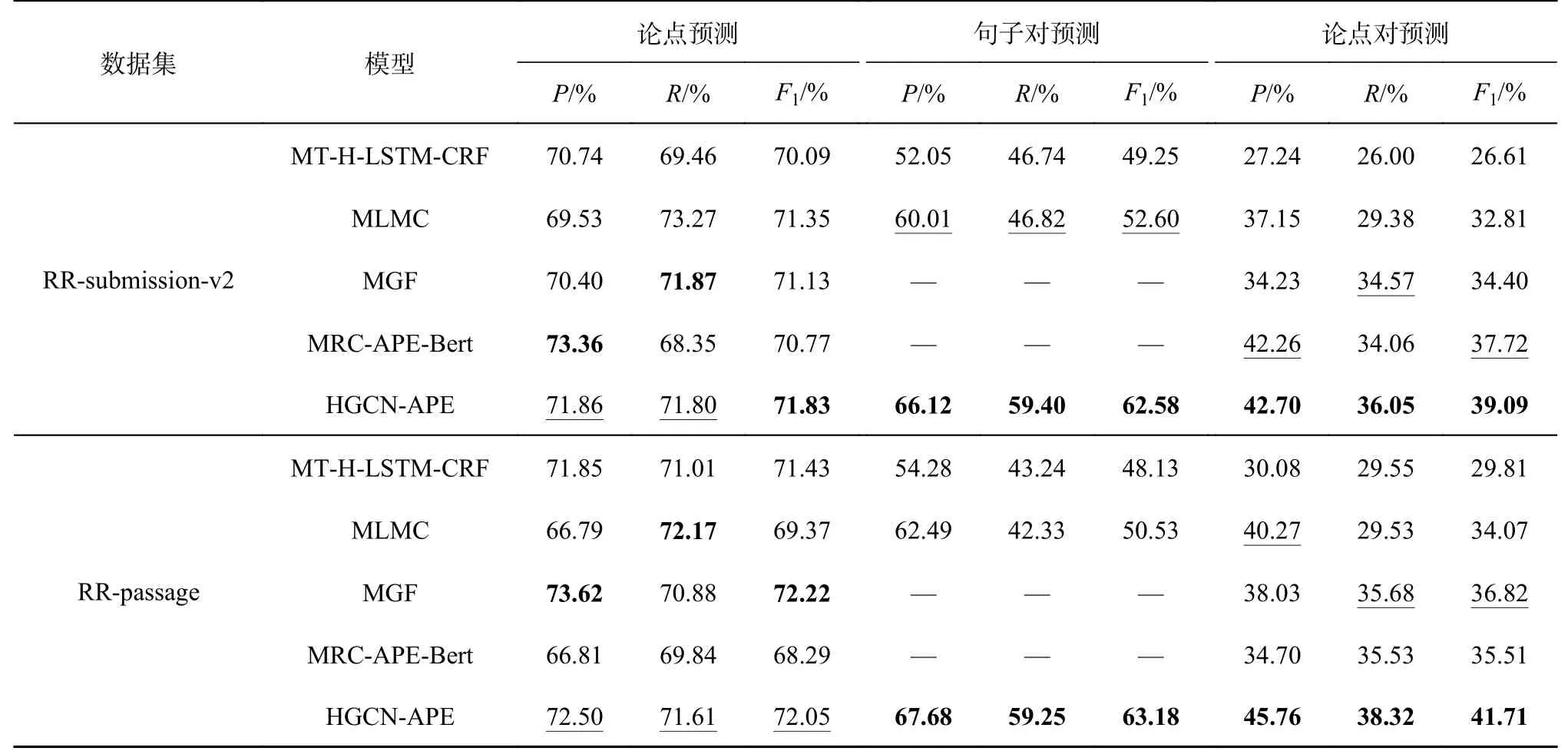
表2 HGCN-APE 在RR-passage 和RR-submission-v2 数据集上的性能对比Tab.2 Comparison of performance of HGCN-APE on RR-passage and RR-submission-v2 dataset
本文模型在论点预测性能方面不如MGF,在句子对预测子任务上的性能均优于其他基线模型.一个可能的原因是通过共现词构建的异质图,能够很好地建模潜在属于同一个论点对句子之间的关系,也可能引入噪音,即有连边的2 个句子可能不属于同一个论点对,这会影响模型在论点预测子任务上的性能.
3.3 消融实验
为了探究构建的异质图及位置感知句子对生成器的有效性,移除模型的某一部分进行消融实验.
w/o v2v 表示去掉异质图中的评审-评审边,即图中不再建模评审段内句子之间的关系.
w/o b2b 表示去掉异质图中的反驳-反驳边,即图中不再建模反驳段内句子之间的关系.
w/o v2b 表示去掉评审-反驳边,即反驳段中的句子将不再建模评审段句子的信息.
w/o b2v 表示去掉反驳-评审边,即评审段不再建模反驳段句子的信息.
w/o pos 表示去掉评审段和反驳段句子的相对位置信息.
如表3 所示为去掉模型中某一模块后,在RRPassage 数据集论点对抽取上的性能.可以看出,去掉任意一个模块,模型的性能均有所降低,证明了模型的有效性.具体来说,在异质图中,去掉评审-反驳边和反驳-评审边模型的性能,比去掉评审-评审边及反驳-反驳边下降的性能更多,进一步表明在论点对抽取任务中,难点在于建模2 个段落句子之间的关系.在去掉位置编码之后,模型性能有所下降,说明有必要建模句子之间的相对位置.
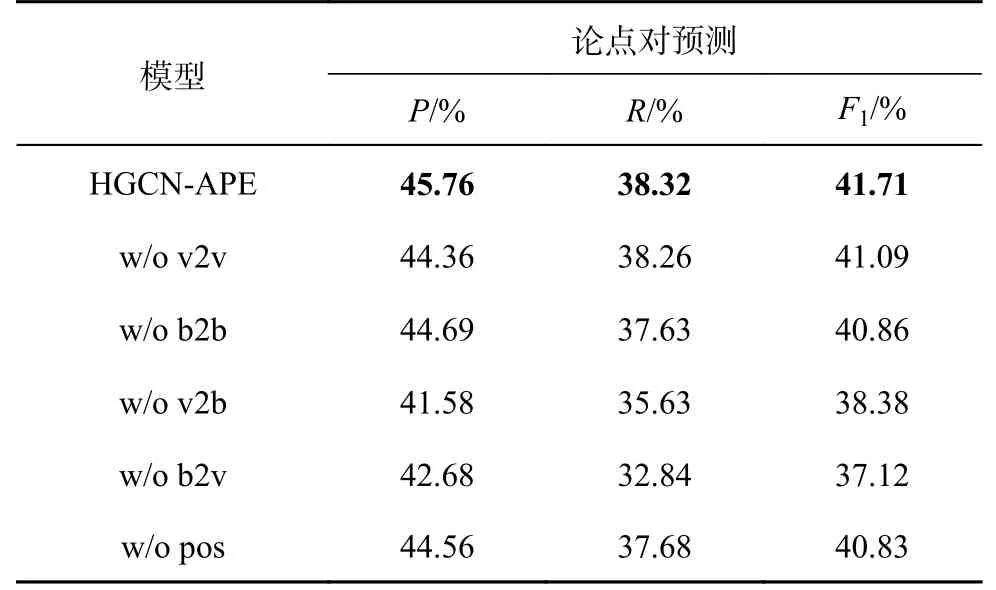
表3 HGCN-APE 在RR-passage 数据集上的消融实验Tab.3 Ablation study of HGCN-APE on RR-passage dataset
3.4 参数敏感性实验
超参数 λ控制2 个子任务权重的大小,如图3所示为不同 λ对模型性能的影响,随着 λ 的增大,论点预测子任务的权重越来越大,句子对预测的任务的权重越来越小.当 λ=0.5 时,2 个子任务的权重一样,同时模型在2 个数据集上的性能均达到最佳,这说明论点预测和句子对预测在论点对抽取中是同等重要的.
为了探究不同堆叠层数 L对模型性能的影响,将 L设置为1~5,步长为1,在2 个数据集上验证不同 L对模型性能的影响,实验结果如表4 所示.可以看出,随着 L的增大,模型在论点对抽取任务上的性能不断提升,当 L=3时模型在2 个数据集上的效果最佳,之后模型的性能不断降低.这是因为当 L过小时,模型不能捕获句子之间的复杂关系;当 L过大时,模型可能引入更多的噪音,导致性能降低.
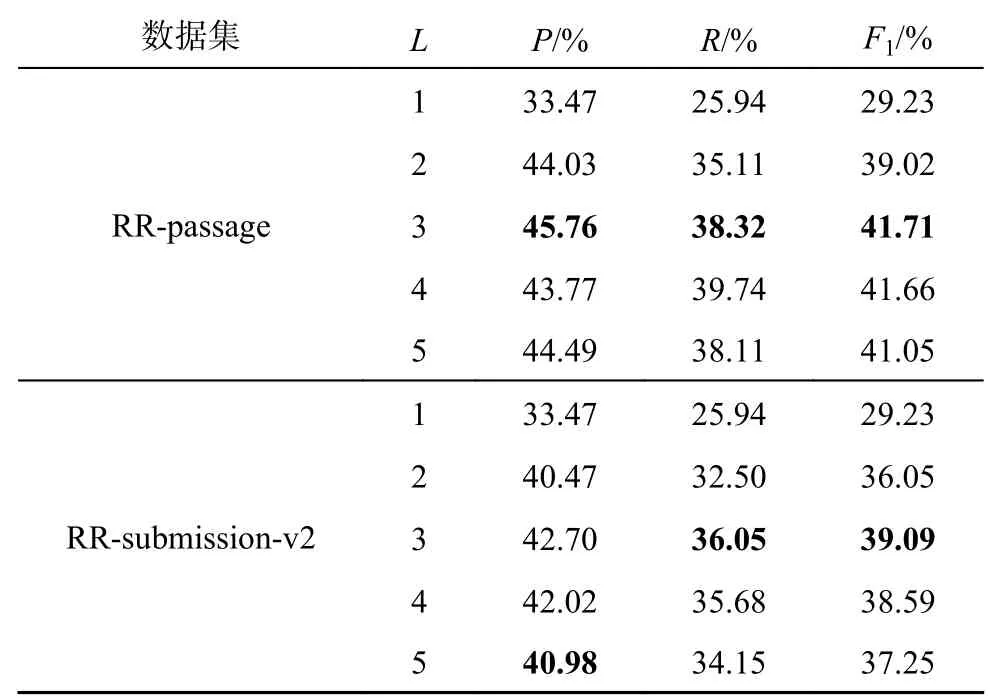
表4 HGCN-APE 超参数 L的影响Tab.4 Effect of HGCN-APE hyper-parameter L
3.5 学习曲线实验
如图4 所示为模型在训练过程中的收敛情况.随着训练轮数N 的增加,模型在2 个数据集上的F1随着增大,损失不断减少.当训练轮数达到20 的时候,F1到达峰值,之后随着训练轮数的增大,F1在峰值上下抖动.尽管20 轮之后,损失不断降低,但是没有带来性能的提升,可能是因为模型在验证集上过拟合了.

图4 HGCN-APE 在RR-passage 和RR-submission-v2 数据集上的损失和性能对比Fig.4 Comparison of loss and performance of HGCN-APE on RRpassage and RR-submission-v2 dataset
3.6 案例研究实验
为了更加直观地查看HGCN-APE 模型在论点预测和论点对预测上的预测结果,在RR-submission-v2 数据集的测试集上随机挑选3 条数据进行展示,结果数据如表5 所示.

表5 HGCN-APE 案例研究Tab.5 Case study of HGCN-APE
从表5 可以看出,在第1 条样本中,HGCNAPE 错误地将评审段中的第6、7 句话识别为论点,这导致在论点对预测过程中,错误地将评审段中的6、7 句话与反驳段中的第1~7 句话识别为一个论点对.在第2 条样本中,HGCN-APE 将第17 句话识别为论点,实际上第16、17 句话是一个完整的论点,这表明HGCN-APE 存在论点边界难以识别的问题,主要体现在2 个方面:1)当一个论点包含多个句子时,只将部分句子识别成论点;2)多个连续的论点被识别为一个论点.第3 条样本完全预测正确.
4 结 语
本文提出基于异质图卷积神经网络的论点对抽取模型,定义2 种不同类型的节点、4 种不同类型的边,能够有效地建模评审段落和反驳段落内部句子之间的关系、段落之间潜在属于同一个论点对句子之间的关系.设计位置感知的句子对生成器,捕获段落内句子间的相对位置.实验结果表明,本文提出的模型优于现有的基线模型.由于目前主要建模的是评审段落和反驳段落句子之间的交互,模型在论点预测上不能取得最好的效果,接下来将探究如何更好地建模论点级的交互.
猜你喜欢
小学阅读指南·低年级版(2020年9期)2020-10-12
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
阅读(快乐英语高年级)(2020年9期)2020-01-08
散文诗(2017年17期)2018-01-31
数学物理学报(2017年5期)2017-11-23
读写算(下)(2016年11期)2016-05-04
云南师范大学学报(自然科学版)(2015年5期)2015-12-26
中央民族大学学报(自然科学版)(2015年2期)2015-06-09
物理实验(2015年10期)2015-02-28
