
大数据Hadoop集群下Sqoop数据传输技术研究
2024-05-23 08:37:16周少珂郭璇张振平付媛冰
河南科技 2024年6期
关键词:大数据
周少珂 郭璇 张振平 付媛冰
摘 要:【目的】Hadoop系统是大数据分布式集群系统,其开源的生态圈中有众多功能组件,通过在大数据Hadoop集群系统上部署Sqoop组件,将本地关系型Mysql数据库中的数据和Hive数据仓库中存储的数据进行快速导入导出,进一步研究数据传输性能。【方法】首先在企业服务器上部署配置Hadoop分布式集群系统,其次在该集群上部署Sqoop组件并测试与Mysql数据库和Hive数据仓库的连通性,最后使用Sqoop技术测试本地Mysql数据库和Hive数据仓库之间的导入和导出。【结果】通过Sqoop技术能够更加便捷快速地从本地Mysql数据库上传到Hadoop集群系统,与传统方式下先将本地Mysql数据库中数据导出TXT文档格式后再使用Hive数据仓库的Load数据批量加载功能相比,在时间和效率方面大为提升。【结论】验证了Sqoop组件在Hadoop集群中部署运行的正确性,为大数据技术学习者提供一定程度的参考借鉴。
关键词:大数据;Hadoop;分布式集群;Sqoop
中图分类号:TP311 文献标志码:A 文章编号:1003-5168(2024)06-0025-04
DOI:10.19968/j.cnki.hnkj.1003-5168.2024.06.005
Research on Sqoop Data Transmission Technology Based on Big Data Hadoop Cluster
ZHOU Shaoke GUO Xuan ZHANG Zhenping FU Yuanbing
(College of Information Science and Engineering, Henan Vocational College of Applied Technology, Zhengzhou 450042, China)
Abstract:[Purposes] The Hadoop system is a big data distributed cluster system with numerous functional components in its open source ecosystem. By deploying the Sqoop component on the big data Hadoop cluster system, the data in the local relational MySQL database and the data stored in the Hive data warehouse can be quickly imported and exported, further studying the data transmission performance. [Methods] This article first deploys and configures the Hadoop distributed cluster system on the enterprise server, and then deploys the Sqoop component on the cluster and tests its connectivity with the MySQL database and Hive data warehouse. Finally, this paper uses Sqoop technology to test the import and export between the local MySQL database and Hive data warehouse. [Findings] Through Sqoop technology, it is more convenient and fast to upload data from the local MySQL database to the Hadoop cluster system. Compared to traditional methods of exporting data from the local MySQL database to TXT document format and then using the Hive data warehouse's Load data batch loading function, the technology greatly improves time and efficiency. [Conclusions] This paper verifies the correctness of deploying and running Sqoop components in Hadoop clusters, providing a certain degree of reference for big data technology learners.
Keywords: big data; Hadoop; distributed clustering; Sqoop
0 引言
Hadoop起始于2002年Apache項目中的Nutch项目。开发者通过学习和借鉴Google的开源GFS、MapReduce、BigTable三篇论文,开发创建出Hadoop项目。随着技术的发展,Hadoop版本已经发展到Apache Hadoop 3.3.6[1]。
目前,Hadoop生态圈发展日益完善,其中包括HDFS分布式文件系统、MapReduce计算模型、Zookeeper协调一致性服务、Hbase列式数据库、Hive数据仓库、Flume日志采集、Sqoop数据泵等众多生态圈中的组件[2]。Sqoop组件功能是完成关系型(如Mysql、Oracle)和大数据集群型(如Hbase)数据库、Hive数据仓库、HDFS分布式文件系统之间数据导入导出的存储[3]。
1 Hadoop集群部署
Hadoop项目整体包括底层的大数据分布式集群部署和上层的大数据应用开发,本研究主要针对底层大数据分布式集群部署进行研究。在Hadoop分布式集群部署中可以分为三类:单机版Hadoop集群;伪分布式Hadoop集群;完全分布式Hadoop集群。其中完全分布式集群部署是真实集群环境,前两类集群仅仅作为初学者进行学习的参考。
本研究使用三台Linux系统进行Hadoop分布式集群系统配置[4]。在运行CentOS7.5发行版的三台Linux系统服务器上进行完全分布式Hadoop集群系统部署。
首先,进行分布式集群中的Java环境变量的基础配置。由于Hadoop项目的底层环境为Java,因此需要在三台服务器中的/etc/profile目录下配置JDK1.8环境变量。在配置完毕后需要使用Source命令对文档进行刷新,使用Java -version命令查看JDK的具体版本信息是否正确。在配置部署前需将各主机防火墙进行关闭,SeLinux功能禁用,并配置使用本地Yum软件源,同时分别修改主机名为Hadoop01、Hadoop02、Hadoop03,其中Hadoop01为主节点(即NameNode节点),Hadoop02和Hadoop03为从节点(即DataNode节点),并修改主机名和IP地址的映射。
其次,在三台CentOS7.5系统服务器节点上配置六个文档,分别为:hadoop-env.sh文档;core-site.xml文档;yarn-site.xml文档;mapred-site.xml文档;hdfs-site.xml文档;master-slave文档。该文件主要保存和记录分布式集群数量和名称,使集群成为统一运行整体。该文件中需把所有DataNode数据节点的主机名添加至文件中,且每个DataNode数据节点名称单独占用一行记录[5]。
再次,对Hadoop分布式集群系统NameNode控制节点在Shell终端环境下进行Hadoop namenode format格式化命令操作。在格式化节点过程中不要进行多次操作,以免造成NameNode节点和DataNode节点不同步,影响系统的稳定性,通过使用Start-all.sh命令启动集群。
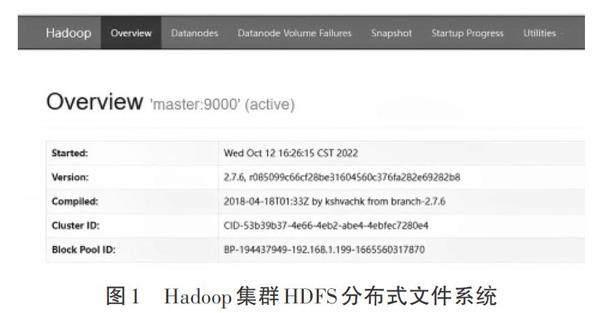
最后,Hadoop分布式集群系统运行成功后,就可以随机选择任何一台主机进行测试,有两种方式进行测试。一种是浏览器Web界面登录方式。使用浏览器输入http://主节点IP地址(或域名):50070,进入HDFS分布式文件系统界面,如图1所示。另一种是通过Shell终端命令方式。输入“JPS”“hadoop fs –ls / ”等命令。
2 Sqoop配置部署
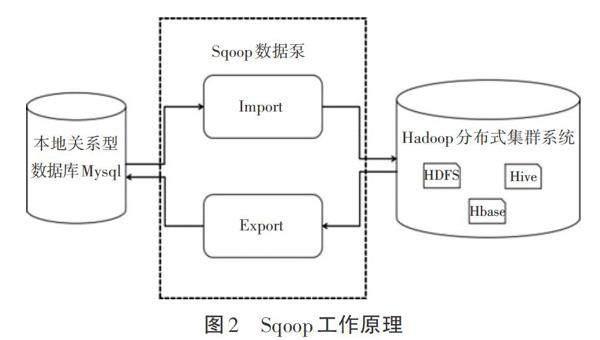
Sqoop组件是Hadoop系统生态圈中的组件之一,也称作“数据泵”。主要是本地关系型(如Mysql、Oracle)数据库和大数据Hadoop集群中的非关系型(如Hbase)数据库、Hive数据仓库、HDFS分布式文件系统之间数据的导入导出,Sqoop组件技术更加方便数据之间传输的高效性和便捷性。在Hadoop分布式集群系统、Hive数据仓库、Mysql关系型数据库已正确完成部署后,本研究以Linux系统中Mysql本地数据库和Hadoop分布式集群中的Hive数据仓库二者为研究对象,进行数据间的传输测试,其Sqoop组件工作原理,如图2所示。
Sqoop组件是开源免费的,可以在开源镜像站中下载,本研究使用Sqoop-1.4.7.bin__hadoop-2.7.6.tar.gz压缩包,Sqoop版本为1.4.7。为了避免操作权限的影响,Linux操作系统中使用root管理员权限身份操作,在Hadoop完全分布式集群(三台服务器)运行的基础上,通过Hadoop01(即Master节点)进行Sqoop组件的安装部署。
①上传服务器Sqoop组件。使用将SecureCRT远程登录软件,将Sqoop压缩包上传至/root目录下,并将/root/Sqoop-1.4.7.bin__hadoop-2.7.6.tar.gz压缩包解压到/usr/local/src目录。将解压后生成的Sqoop-1.4.7.bin__hadoop-2.7.6文件夹更名为Sqoop。
②修改并配置Sqoop环境。复制Sqoop-env-template.sh模板,并将模板重命名为Sqoop-env.sh。修改Sqoop-env.sh文件,添加Hdoop、Hbase、Hive等组件的安装路径。
④配置连接Mysql数据库。为了使Sqoop能够连接MySQL数据库,需要将Mysql-connector-java-5.1.46.jar文件放入Sqoop的lib目录中。该jar文件版本需要与MySQL数据库的5.7版本相对应,否则Sqoop导入数据时会报错。
⑤测试Sqoop组件连接Mysql数据库。在Master服务器节点上启动Hadoop分布式集群系统,测试Sqoop组件是否能够正常连接Mysql数据库。使用“sqoop list-databases --connect jdbc:mysql://hadoop01:3306/ --username root -P Mysql数据库密码”命令,能够查看到MySQL数据库中的information_schema、hive、mysql、performance_schema、sys等数据,说明Sqoop可以正常连接MySQL数据库。
⑥测试Sqoop组件连接Hive数据仓库。为使Sqoop能够连接Hive,需要将Hive组件/usr/local/src/hive/lib目录下的hive-common-2.0.0.jar放入Sqoop安装路径的lib目录中,該jar包为内部调用普通库函数时所需要使用的包。
通过以上六步的配置,完成了Hadoop分布式集群系统中Sqoop组件的安装部署,并能够使用Sqoop相关命令进行本地Mysql数据库和Hive数据仓库的连接。其中Hive数据仓库并非数据库而是一种数据库引擎,通过Hive将数据存储在HDFS分布式文件系统中。
3 Sqoop功能测试
根据Sqoop组件功能,其测试包含两个方面。一方面是,将本地Mysql数据库中的数据进行导出,通过Sqoop技术再次将该数据导入到Hive数据仓库中。另一方面是,将Hive数据仓库中的数据导出,通过Sqoop技术再次将该数据导入到本地Mysql数据库中。测试完成后,通过实际的运行结果,验证Sqoop配置的正确性和性能。
①创建Mysql数据库和数据表的样本数据。使用Root管理员权限身份登录Linux本地系统的Mysql数据库,创建Example数据库和样例Student表,该表格有Snumber学号主键列和Sname姓名列。“create table Student(Snumber char(9) primary key,Sname varchar(10));”并向该表格中插入三行详细数据“insert into Student values(‘01,‘ZhangSan);”“insert into Student values(‘02,‘LiSi);”“insert into Student values(‘03,WangWu);”
②创建Hive数据仓库中的Example数据库和Student数据表。在运行的Hadoop分布式集群系统中启动Hive数据仓库并创建Example数据库“hive> create database sample;”进而创建Student数据表“hive> create table Student(Snumber STRING,Sname STRING) row format delimited fields terminated by ‘| stored as textfile;”此时Hive中的Student数据表是使用“|”进行、列之间的分割,并最终以textfile文件格式进行数据存储,此时Hive中的数据库和表格格式已创建完成。
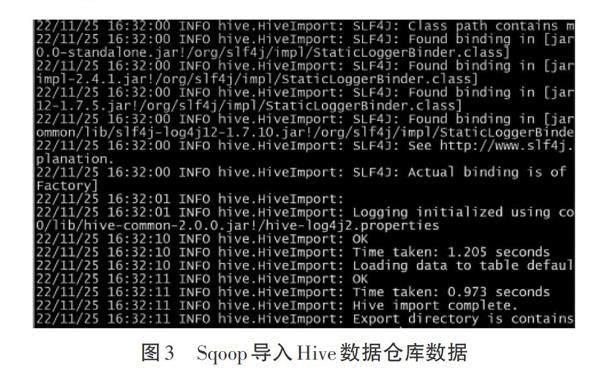
③将本地Mysql数据导出,导入Hive数据仓库测试。本地Mysql数据库中已创建数据库和数据表,并插入部分行数据,所以可以直接在Master服务器中使用“sqoop import--connectjdbc:mysql://master:3306/Example --username root --password Password123!(数据库密码) --table student --fields-terminated-by ‘| --delete-target-dir --num-mappers 1 --hive-import --hive-database Example --hive-table Student”命令进行测试。其中数据库密码设定符合密码复杂度即可,在该命令底层运行过程中会转换成一个MapReduce计算模型的工作任务,如图3所示。
④将Hive数据仓库导出,导入本地Mysql数据测试。由于Mysql数据库中已插入部分数据,因此需要先删除表格中的数据,但无须删除表格框架结构,使用命令“mysql>use Example; mysql>delete from Student;”在Master节点中使用“sqoop export --connect jdbc:mysql://master:3306/Example?useUnicode=true &characterEncoding=utf-8 --username root --password Password123!(数据库密码) --table Student --input-fieldsterminated-by ‘| --export-dir /user/hive/warehouse/Example.db/Student/*”命令。在从Hive导出数据过程中,底层需要转换为MapReduce计算模型的程序进行调用系统程序,因此是以MapReduce程序进行运行。Hive数据仓库中的数据成功导入到本地Mysql数据库中的过程,如图4所示。
4 结语
Sqoop组件是Hadoop系统生态圈中的组件之一,其主要功能是进行本地数据和Hadoop分布式集群系统中数据间的传输。通过Sqoop技术能够更加便捷、快速地从本地Mysql数据库上传到Hadoop集群系统,与传统方式下将本地Mysql数据库中数据导出TXT文档格式后,再使用Hive数据仓库的Load数据批量加载功能相比,在时间和效率方面大为提升。下一步,可以在此基础上运用海量数据,从使用Sqoop技术导入和Hive的Load批量加载两个方面,将数据导入到Hive数据仓库中进行对比研究,并进行性能优化。
参考文献:
[1]刘晓莉,李满,熊超,等.基于Hadoop搭建高可用数据仓库的研究和实现[J].现代信息科技,2023,7(1):99-101.
[2]李霄扬,朱恒.基于HHS的离线数据分析平台的设计与实现[J].电脑知识与技术,2023,19(10):75-77.
[3]吴建.基于Linux的Hadoop集群搭建的探索与实现[J].物联网技术,2023,13(7):134-137,141.
[4]王建军,张英成,战非,等.基于Sqoop的高校海量结构化数据导入研究[J].无线互联科技,2018,15(20):52-53.
[5]周少珂,王雷,崔琳,等.大数据Hadoop技术完全分布式集群部署[J].工業控制计算机,2021,34(8):101-103.
猜你喜欢
新闻世界(2016年10期)2016-10-11 20:13:53
科技视界(2016年20期)2016-09-29 10:53:22
中国记者(2016年6期)2016-08-26 12:36:20
