
移动社交网络用户的浏览隐私保护
2024-05-22 00:21王元茂欧阳婷
新乡学院学报 2024年3期
王元茂,欧阳婷
(安徽中医药大学 医药信息工程学院,安徽 合肥 230012)
移动社交网络为人们在网络空间中的活动提供了重要的服务。在人工智能背景下,黑客可以更容易获取企业社交网络管理系统中的用户信息,并使用人工智能的学习能力来预测和应对网络防火墙。为了保护隐私安全,需要设计一种移动社交网络用户浏览隐私的保护方法。卫新乐等[1]结合现代社交网络中恶意用户十分分散的特点,在保证普通用户隐私安全的前提下,建立数学模型,提出跨平台的恶意用户检测方案。通过数据多源预处理,对安全联邦提升树算法进行改进,得到了较好的保护效果。于群等[2]给出一种差分隐私保护方法,在该框架下,利用敏感数据脱敏替代的方式,去除个体特征,保留电力负荷数据的个体机制,生成对抗网络的判别器来获取负荷数据的静态特征。周治平等[3]使用深度神经网络梯度算法,对引入的噪声进行处理,同时分解算法内的梯度矩阵,建立低维特征子空间矩阵,并在输入特征的基础上,提高算法的训练精度,有效提高了不同模型之间的差距。结合上述文献,本文设计移动社交网络用户浏览隐私保护方法,以进一步提高用户隐私算法性能。
1 设置用户浏览隐私度量标准
为了更好地了解和保护用户的隐私,识别潜在的隐私风险,需要明确用户浏览隐私的度量标准。本文的隐私度量标准是通过时间间隔给出用户的隐私移动轨迹。设用户浏览范围内有两个点M1(x1,y1)和M2(x2,y2),则用户浏览信息轨迹的斜率为
用户浏览范围内的两个点之间的斜率比为
其中ki表示用户在第i 个浏览阶段的浏览斜率[4-5]。在相似性区域内,不同浏览阶段的斜率越接近,用户所浏览的数据轨迹就越接近。
用户浏览的轨迹函数[6-7]为
其中x 表示浏览区间大小。
设用户浏览信息轨迹斜率对应夹角a 的正切值为
夹角越小,用户浏览内容的隐私性就越强。
在该模型下,可以得到用户浏览隐私度量标准,即用户浏览的敏感信息占总浏览内容的比例。在社交网络中存在大量的个人信息和敏感数据,为了保护用户的个人隐私权益,应确保用户浏览的内容中敏感信息的比例不超过三分之一,即选取社交网络中敏感信息比例阈值为30%。
2 隐私信息分类模型
对社交网络用户的浏览信息以及用户信息进行分类,确定需要保护的范围。先计算一个点与其他点的欧氏距离,再选出距离这个点较近的几个点,然后统计这些相对较近的点所属分类的最大比例[8-9]。最终的分类决策模型如图1 所示。为了简化模型,图1中忽略了坐标信息。在图1 中,最小的圆圈内是最先被决策分类的。在第一阶段中,从三角形、圆形和正方形中任选一种作为被分类的点。例如选择正方形作为分类依据,则在第二阶段中,就对正方形的大小型号进行区分。选择最大型号的正方形后,继续在外围(第三阶段)的区域内选择正方形的颜色(黑或白)[10]。以此类推,每个阶段的信息都在前一个阶段分类的基础上进一步细分和区分,构建层层细化的信息分类模型。通过选择隐私信息的不同属性逐级分类信息,实现信息被更加精细的分类和整理,使信息更具有层次,更加结构化。

图1 分类决策模型
第一阶段是最困难的阶段,这是因为社交网络中通常存在大量的浏览信息,需要结合用户浏览隐私度量标准,计算浏览信息与用户信息之间的相似性。相似性系数为
其中Xm和Ym分别表示浏览信息与用户信息的第m个属性信息。δm越大表明浏览信息与用户信息越相似。为了提高分类的准确性,较大的相似性系数都要被统计在分类模型内[11-12]。
其中P(u)表示移动社交网络用户在浏览数据时被推断出正确轨迹的概率。P(u)的计算公式[13]是
其中L(u)和L(q)分别表示移动用户在不同分类模型内的隐私浏览轨迹。P(u)的值越高,则信息分类模型的分类精度就越高。
3 社交网络用户浏览隐私保护算法
下面设计基于人工智能技术的社交网络用户浏览隐私保护算法。
步骤1:初始化用户信息的真实位置Mq(x1,y1),记录用户信息浏览位置,划定坐标原点,并定义循环变量i=1[14-15]。
步骤2:判定待测信息是否为隐私信息。如不是隐私数据,则继续寻找其他待测信息;如是隐私数据,就计算虚假轨迹区域。轨迹数目为
其中σp表示用户角度[16]。
步骤3:计算虚假轨迹圆心位置。
热点区域中心代表用户浏览数据中的重要位置或兴趣区域。为了保护用户在重要位置的隐私,避免细粒度的位置信息泄露,在轨迹数目的基础上,将选择热点区域中心为圆心,将社交网络用户浏览隐私保护的范围定义为一个圆。圆心Od(Ox,Oy)位置定义为
其中xm和ym表示虚假位置在随机区域的坐标。
步骤4:计算控制增量并进行标准化处理。
步骤5:判断移动社交网络用户随机位置是否为虚假位置。如果是,则输出匿名保护结果;如果不是,则重新定义循环变量i。
依据上述步骤画出的流程如图2 所示。
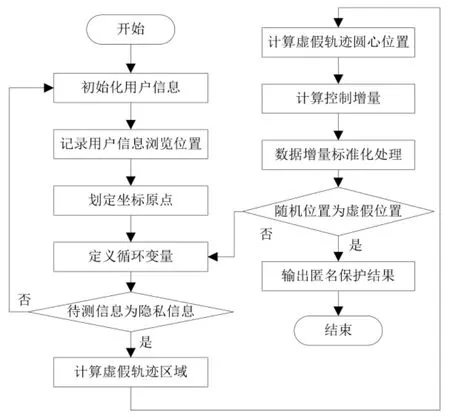
图2 隐私保护算法
4 实验研究
4.1 实验环境与参数设置
在本实验中,选取Jester 数据集中的10 000 条用户历史行为记录作为实验数据,随机选择其中的80%作为训练集,剩余20%作为测试集。对训练集中的数据进行扰动用户历史行为的操作。使用Windows7 操作系统和Matlab 软件编辑代码。
建立攻击模型,假定攻击者获知用户的部分浏览情况,并可以截获移动社交网络用户向服务器发送的查询信息。攻击者通过计算某用户浏览轨迹与实际浏览移动速度之间的距离(用户浏览轨迹指移动社交网络用户在使用移动应用或浏览器期间所产生的记录和跟踪的行为路径,包括用户浏览的页面、点击的操作、访问的位置等。实际浏览移动速度表示用户在实际操作中快速浏览移动应用或浏览器界面的速度,例如在屏幕滑动时的滑动速度。距离指攻击者计算用户实际浏览移动速度与用户界面内的轨迹之间的差距),判断用户界面内的轨迹是否真实轨迹。如果两者之间的差距较大,攻击者就怀疑用户界面内的轨迹是模拟的或伪造的,而不是实际行为产生的真实轨迹。
在实验中,初始化移动社交网络用户浏览隐私的参数如表1 所示。表1 中设置了3 种参数:σ表示用户角度划分,即用户浏览轨迹的预设数目;Qr表示用户真实位置与随机位置的距离,它是一个范围参数;Pm表示在虚假轨迹所在区域用户真实位置被查找到的概率。
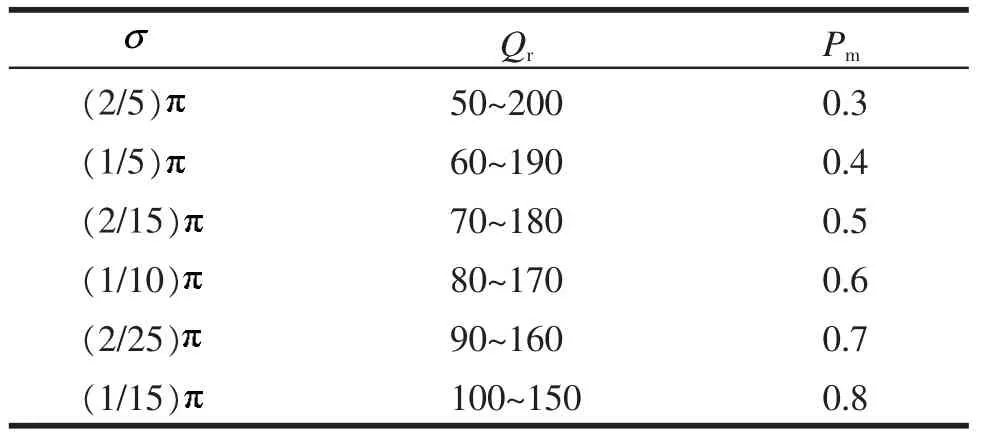
表1 实验参数
4.2 实验结果
在上述实验参数下,测试文中设计的移动社交网络用户浏览隐私保护方法,并与纵向联邦学习方法、云计算应用方法和深度神经网络算法相比较。
4.2.1 隐私保护度分析
结合表1 所示的6 个Pm参数值,σ 值统一设置为(2/5),Qr值为50~200。测试在不同Pm数值下上述几种算法的隐私保护度的变化,并对比隐私保护效果。结果如图3 所示。

图3 隐私保护度
由图3 可知,随着Pm增大,隐私保护度整体呈现出逐渐增加的趋势。当Pm为0.3 时,本文算法的隐私保护度为0.4,其他3 种算法的隐私保护度均小于0.4。当Pm值为0.8 时,本文算法的隐私保护度已经增加至0.69,纵向联邦学习方法的隐私保护度为0.47,云计算应用方法的隐私保护度为0.56,深度神经网络算法的隐私保护度为0.59。结合上述数值可知,Pm参数越大,算法在保护用户隐私方面的效果就越好。
4.2.2 匿名时延差异分析
通过上述实验,在保证实验结果最优的前提下,可确定本实验中的Pm为0.8。设置Qr为50~200,对比在不同角度参数之下,4 种算法匿名时延的差异。结果如图4 所示。

图4 4 种算法的匿名时延
由图4 可知,当角度参数σ 为/15 时,本文算法的匿名时延为2.47 s,纵向联邦学习方法的匿名时延为3.17 s,云计算应用方法的匿名时延为3.21 s,深度神经网络算法的匿名时延为3.16 s。当角度参数增加至2/5 时,本文算法的匿名时延为1.78 s,纵向联邦学习方法的匿名时延为2.00 s,云计算应用方法的匿名时延为2.41 s,深度神经网络算法的匿名时延为2.32 s。可见,角度参数值越大,各种方法的匿名时延均越小。
4.2.3 算法匿名成本
结合隐私保护度以及匿名时延分析的实验结果,设置Pm为0.8,σ 为/15,对比在不同Qr下,4种算法的匿名开销差异。结果如图5 所示。由图5 可知,当距离参数为50~200 时,本文算法的匿名开销为30.6,纵向联邦学习方法的匿名开销为36.1,云计算应用方法的匿名开销为34.7,深度神经网络算法的匿名开销为31.4。当Qr降低至100~150 时,本文算法的匿名开销仅仅只有7.1,纵向联邦学习方法、云计算应用方法和深度神经网络算法的匿名开销则分别降低至17.5、14.7 和12.3。由此可见,距离参数值越小,算法的匿名开销就越小。
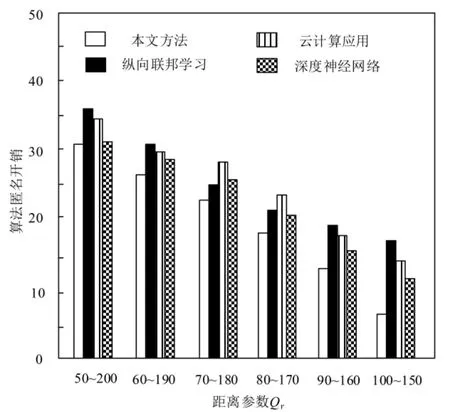
图5 4 种算法的匿名开销
综合对比以上数据可知,在参数相同时本文算法的隐私保护度大于其他3 种算法,且匿名时延与匿名开销相对较小。可见,本文算法优于其他3 种方法。
5 结束语
文中给出了一种基于人工智能背景的移动社交网络用户浏览隐私保护方法。实验结果显示,其在隐私保护度、匿名时延以及算法匿名开销等方面均具备良好的性能。在今后的相关研究中,可以从现实场景多变性以及用户特殊性等方面入手,以实现更快速、灵活的隐私保护。
猜你喜欢
英语世界(2023年6期)2023-06-30
意林彩版(2022年2期)2022-05-03
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
第一财经(2020年4期)2020-04-14
电子制作(2019年23期)2019-02-23
测控技术(2018年6期)2018-11-25
文苑(2018年17期)2018-11-09
现代装饰(2018年5期)2018-05-26
中国三峡(2017年2期)2017-06-09
