
基于通道权重分配的铁路物资仓储库区物体分类识别方法
2024-05-20 08:29陈世君孙梦飞
林业机械与木工设备 2024年3期
陈世君, 孙梦飞
(国能朔黄铁路发展有限责任公司,河北 沧州 062350)
随着近年来我国市场经济的发展,铁路物流行业得到了突飞猛进的发展,我国“一带一路”[1]倡议与《“十四五”现代物流发展规划》[2]发布,加快了铁路货运行业的高质量发展。在我国铁路行业高速发展的进程中,铁路轨道线路与辅助设备的检修对保障铁路安全高效运输有着重要的作用,由于我国铁路里程较长,设备与设施复杂,铁路检修作业繁重,因此需要强有力的检修物资供应系统,这对铁路检修所需货物的运输效率提出了更高的要求。随着智能技术的不断发展,计算机技术、人工智能等领域的不断创新,在国家倡导的工业4.0的战略布局下[3],越来越多的制造业厂商开始研制替代重复性人力劳动的智能化作业系统,铁路检修物流企业也开始向现代物流企业转型升级。
铁路检修所需要的货物种类数量多,检修生产物流在仓储、配送方面流程复杂,存在铁路紧急抢修的情形,需要无人叉车AGV配合人工协同工作。大多数铁路系统使用射频识别(RFID)技术[4]与二维码结合实现检修仓储库区中货物的识别,这种方法可以通过识别二维码获取货物位置信息,但存在对大件物体扫描不方便、需要定期维护等问题。随着人工智能技术的快速发展,基于计算机视觉的物体识别快速发展,相比于RFID技术,视觉识别具有准确率高,硬件成本低的优点。目前,基于计算机视觉的识别方法在铁路检修场景下取得了一定的成果,例如传统的目标检测按照灰度特征、边缘特征、纹理特征等图像特征进行目标分割,往往采用聚类方法[5]、基于相关阈值的方法[6]、基于区域的方法[7]等,但这类按图像特征分割图像的方法对噪声比较敏感,识别准确率和效率相对比较差。目前基于深度学习的仓储物体检测也是一个新兴的研究方向, R-CNN两阶段检测算法采用大规模的卷积神经网络应用,通过生成候选框、提取特征、SVM分类和定位回归4个步骤进行训练[8]。Girshick等[9]基于候选区域的提取方法提出Fast R-CNN,同时网络通过双层分支输出,其训练速度和测试速度较R-CNN有较大提升。Ren等[10]进一步提出了Faster R-CNN在Fast R-CNN 基础上添加区域建议网络,替代了传统的特征提取方法,提高了网络的训练速度。Redmon等[11]提出了由卷积层和FC层构成的单阶段YOLO(You Only Look Once)目标检测算法,先在最顶层特征图中标出边界框,之后就可以对每个类别概率进行预测,最后激活函数就可以得到最终信息。Liu等[12]提出SSD(Single Shot Multibox Detector)算法,将Faster R-CNN中提取多种候选区域作为感兴趣区域的思想与YOLO中回归的思想结合,一定程度上解决YOLO算法对小目标识别以及尺度不敏感的缺陷。王玉伟等[13]提出一种基于边缘检测的箱体货物检测算法,利用训练好的RCF边缘检测模型得到箱体边缘信息,再对边缘信息进行图像处理得到箱体货物边缘与定点坐标实现箱体货物定位。但是该算法对仓储场景智能化、无人化要求较高,应用到实际复杂的仓储场景中存在困难[14]。金秋等[15]将FasterR-CNN模型应用到仓储物体检测,使用ZFNet网络进行特征提取,实现了对仓储环境中的物体的粗定位。但是由于早期CNN网络特征提取能力较弱,导致模型检测精度较差[16]。刘江玉等[17]、陈亮杰等[18]基于FasterR-CNN模型进行仓储托盘检测,使用VGG16进行训练,准确率得到提高但网络结构复杂导致检测速度降低。陈亮杰等[19]将单阶段SSD检测算法应用于仓储环境,基本实现仓储明显物体检测,但该算法在复杂仓储环境中仍然存在漏检情况,算法的鲁棒性不足。李天剑等[20]将DenseNet与SSD进行融合,设计出改进的SSD算法模型对仓储托盘进行检测,但是对于仓储场景中存在的光线较暗、托盘易被遮挡等复杂情况,算法的检测精度不高。
综上所述,在铁路检修仓库中进行物体识别方面主要存在以下问题亟待解决:铁路检修仓储环境复杂、许多工作场景需要工人与叉车配合协调工作,工人与货物、车体之间相互遮挡,对后续物体识别造成较大影响。结合铁路检修仓库作业的现实情况,本文基于深度学习算法,设计对铁路检修仓储场景中的货物、人、叉车等准确识别方法,更好地实现检修货物的高效搬运。YOLOv8算法不仅可以定位和分类图像中的多个对象,还可以输出边界框[21]。本文的研究工作重点是利用数字图像对铁路检修仓储中的货物、工人、叉车进行识别,从铁路检修仓储图像中提取视觉特征,并通过分析目标物体特征来预测物体的类别。
1 YOLOv8网络结构与优化
1.1 YOLOv8网络架构
为了追求更低的成本和更高的搬运效率,智能仓储叉车AGV通常搭载轻量化的处理器,计算能力有限,因此需要轻量、高效的深度学习网络来完成目标识别任务。YOLOv8是一种双路径的轻量化目标识别网络,提供了目前最先进的目标检测性能,借助先前YOLO模型的支持,运行得更快、更准确,同时为目标检测、实例分割、图像分类等多种任务提供了统一的框架。YOLOv8使用了与YOLOv5[22]类似的主干网络,延续了CPS模块并做了一些更改,用C2f模块(具有两个卷积的跨阶段部分)代替C3模块,结构如图1所示。YOLOv8的Backbone中使用C2f模块将高级特征与上下文信息相结合提取视觉特征提高检测精度,实现了进一步的轻量化,同时沿用了YOLOv5中的SPPF模块,在不影响检测精度的情况下获得更快的检测速度。

图1 主干网络部分模块结构图
Neck网络位于Head网络与骨干网络之间,主要用来特征融合以在不同尺度下都可以获取丰富的语义信息,在YOLOv8中采用FPN+PAN结构。通过FPN(Feature Pyramid Network,特征图金字塔网络)[23]可以融合高分辨率的浅层结构和具有丰富语义的深层结构;而PAN(Path Aggregation Networks,路径聚合网络)[24]自底向上传达强定位特征,两者结合对不同分辨率大小的检测层进行融合,方便实现各个尺寸的目标检测。YOLOv8的Head部分使用一个无锚模型和一个解耦的头来独立处理对象、分类和回归任务。这种设计允许每个分支专注于其任务,提高了模型的整体准确性。在YOLOv8的输出层中,使用Sigmoid函数作为对象分数的激活函数,表示边界框包含对象的概率,它将Softmax函数用于类概率,表示对象属于每个可能类的概率。YOLOv8使用CIoU和DFL损失函数进行边界框损失,并使用二进制交叉熵进行分类损失,基本网络结构如图2所示。但是YOLOv8在对多种类小目标进行检测时容易受图像背景和噪音的干扰,铁路检修仓库背景复杂,检测目标种类多、尺寸不固定,需要对原始YOLOv8网络进行改进。
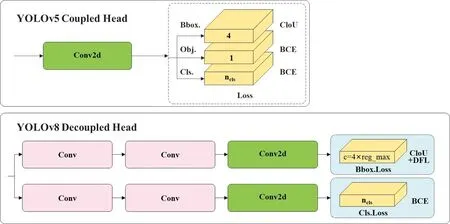
图2 Head网络结构图
1.2 YOLOv8算法改进
1.2.1 注意力机制
本文针对铁路检修仓储库区人员物货物复杂问题,将SE(Squeeze-and-Excitation)注意力模块[25]融入到 YOLOv8网络中,以提升网络的特征提取能力。
SE注意力模块是一种通道注意力模块,主要通过对输入的特征进行压缩与激励,在压缩过程中,通过全局平均池化操作将输入的特征图压缩成向量,然后通过全连接层映射到较小的向量,如图3中Fsq定义如下:
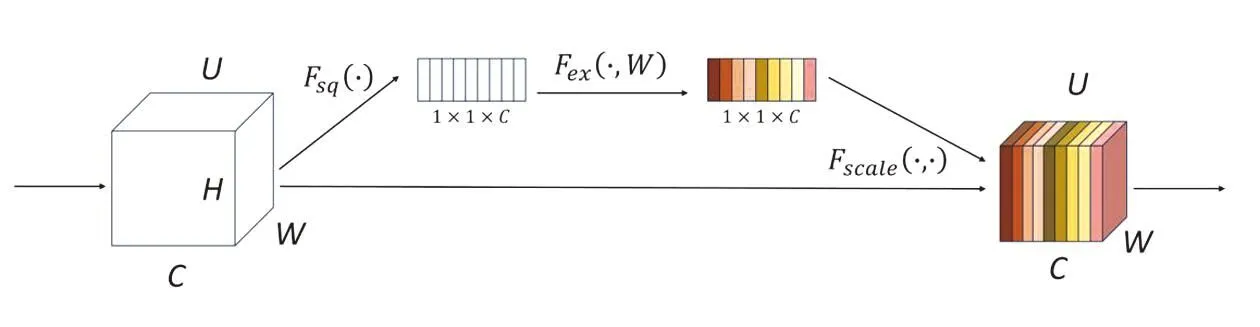
图3 Squeeze-and-Excitation模块
(1)
(2)
为了利用压缩过程中汇集的信息,需要通过激励操作捕获通道依赖性。采用了两层全连接构成的门机制,第一个全连接层把通道压缩降低计算量,再通过一个RELU非线性激活层,第二个全连接层恢复通道数,再通过Sigmoid函数激活得到权重s,将其与原始输入特征图相乘,得到加权后的特征图。
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
(3)
(4)
通过SE注意力机制,模型可以自适应地学习到每个通道的重要性,提高模型的表现能力,通过学习自适应的权重,使模型更加关注有用的通道信息。铁路检修仓储场景复杂,识别目标种类多,SE注意力模块可以让网络自动地选取最具代表性的特征进行分类,提高神经网络的分类性能。SE注意力模块结构如图4所示。

图4 SE注意力模块结构
1.2.2 改进的网络结构
通过引入SE模块,深度学习网络可以自适应地学习图像不同通道的重要性。C2f模块在YOLOv8中负责将高阶语义特征与低阶细节特征融合,本文在C2f模块和SPPF模块中添加SE注意力模块,通过注意力模块中的全局平均池化层对每个通道特征进行降维,通过全连接层将特征映射到注意力权重,最后通过Sigmoid激活函数将注意力权重限制在0到1之间。在特征金字塔PANet网络结构中,跨层连接主干网络的特征信息,由于低层的主干信息含有较多的背景干扰信息,可能导致所融合的特征信息含有较多的无效信息,所以我们在特征提取网络中添加SE注意力机制,使网络能够聚合有效的低层特征信息,提高模型对特征的关注能力,进一步提高模型分类的能力,改进的网络整体结构图如图5所示。
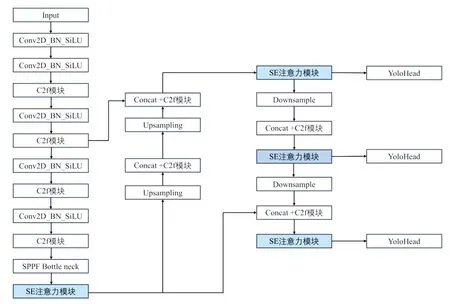
图5 改进的YOLOv8算法网络结构图
1.2.3 损失函数优化
损失函数(Loss Function)[26]是衡量模型预测值和真实值之间差异的函数,在训练期间,模型会尝试最小化损失函数的值,从而提高模型的准确性。YOLOv8采用的现有的边界框回归的损失函数CIoU[27]和DFL[28]损失函数,在不同的预测结果下具有相同的值,降低了边界框回归的收敛速度和精度。
MPDIoU(Minimum Point Distance based IoU)[29]是一种用于边界框回归的损失函数,它通过最小化预测边界框和真值边界框之间的点距离来计算IoU,简化了两个边界框之间的相似性比较计算过程,计算公式如下:
d12=(x1B-x1A)2+(y1B-y1A)2
(5)
d22=(x2B-x2A)2+(y2B-y2A)2
(6)
(7)
其中(x1A,y1A),(x2A,y2A)表示A的左上点和右下点的坐标;(x1B,y1B),(x2B,y2B)表示B的左上点和右下点的坐标;w和h表示图像的宽度和高度。
2 铁路仓库数据集
2.1 铁路仓库数据集的构成
在设计铁路检修仓库数据集时,通过大量现场调研以及咨询业内相关人士,构建出铁路仓库数据集类别及出现频率,如表1所示。

表1 铁路检修仓储数据集类别及出现频率
2.2 铁路检修仓库数据集构建
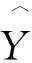
(8)
铁路检修仓库数据集的标注工作采用Labelimg软件进行。在标注完成后对标注图片进行筛查去除等,确保数据集图片准确可靠。铁路检修仓库数据集包括4类检测目标:AGV(叉车类)、goods(货物类)、people(工作人员类)、shelves(货架类)去除冗余图像后获得共计1 000张图片,保存为jpg格式,选取各类型图片文件夹前70%作为训练集,后30%作为验证集。数据集包含正常光照下采集的铁路检修仓库图像、光照不足的暗光线图像、背景干扰大的图像,不同条件下采集的图像可以提高检测模型的鲁棒性。铁路检修仓库的部分数据集如图6所示。

图6 铁路检修仓库图像数据集
3 实验结果与对比分析
3.1 实验环境
本实验环境为python3.10、pytorch1.10、cuda11.3,实验配置为 GPU:RTX 4060,显存8 GB。本文设定样本的整个训练过程为200个epoch,前50个epoch采用冻结训练方式,后150个epoch进行解冻训练,网络训练时参数优化方法选择随机梯度下降法。
3.2 评价指标
为了验证模型的有效性、准确性和稳定性,本文实验采用检测精度mAP(Mean Average Precision)和召回率(Recall)作为检测效果的评价指标。混淆矩阵(Confusion Matrix)用于评估模型的分类性能,通常是一个2×2的矩阵,行表示实际标签类别,列表示模型预测类别,混淆矩阵中的四个元素分别是:真正例(True Positive,TP)、假正例(False Positive,FP)、真反例(True Negative,TN)、假反例(False Negative,FN),如表2所示。

表2 混淆矩阵
检测精度mAP:AP是评价模型精准度的指数,可以反映模型局部性能,mAP是平均精度均值,n为目标检测的类别数,计算公式如下:
(9)
(10)
召回率:指分类模型正确预测为正例的样本数占实际正例样本数的比例,计算公式如下:
(11)
3.3 实验结果对比分析
为了验证提出的改进模型的优越性,本文使用4类检测目标:AGV(叉车类)、goods(货物类)、people(工作人员类)、shelves(货架类)作为训练集。数据集分别在YOLOv8和改进的YOLOv8网络模型中进行训练,如图7所示结果表明,在训练结果中,改进的YOLOv8比原始YOLOv8具有更好的收敛效果,损失值更小,这表明改进后的YOLOv8模型检测性能得到提升。
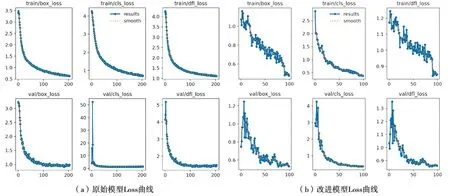
图7 Loss曲线
YOLOv8在检测过程中存在漏检的情况,改进后的YOLOv8可以检测到原始网络模型错检的对象,提高了检测性能,两个模型检测结果对比如图8所示。实验结果表明,该模型能够成功地对铁路检修仓库中的工作人员、AGV、货物与货架进行识别。

图8 检测结果
Recall-confidence curve(RCC)曲线图是目标检测中用于评估算法性能的一种方法,该曲线显示了模型在不同置信度阈值下的召回率与置信度之间的关系。从图9中可以看出,改进前的YOLOv8模型所有分类只能达到92%;图13中可以看出,改进后的模型所有分类能到达97%。说明本文提出的改进后的模型分类性能得到了显著提升。

图9 模型RCC曲线图对比
4 结束语
铁路检修仓储库区环境复杂、布局变动幅度大,AGV在库区执行搬运任务时对与环境周围的物体分类识别非常重要。本文提出了一种基于改进YOLOv8卷积神经网络的铁路检修仓储库区物体识别方法YOLOv8-S,通过加入SE注意力机制模块与改进损失函数使网络自动选取最具代表性的特征进行分类,提高神经网络的检测与分类性能。测试结果表明,模型召回率为83.7%,平均均值精度达到87.6%,与原始YOLOv8相比,YOLOv8-S的召回率提高了3.8个百分点,平均均值精度提高了4.3个百分点。本文提出的方法识别精度高、分类准确,检测效果优于已有的YOLOv8模型,通过检测铁路检修仓库中的常见物体,可以实现高效智能的货物运输,大大降低铁路检修仓库中的人工成本,解决当前铁路检修仓储库区复杂环境影响AGV搬运货物的问题。
猜你喜欢
小猕猴智力画刊(2022年11期)2022-11-28
云南画报(2021年12期)2021-03-08
小天使·一年级语数英综合(2020年11期)2020-12-16
学生天地(2020年34期)2020-06-09
当代工人(2019年24期)2019-01-17
铁道通信信号(2018年7期)2018-08-29
电子制作(2016年19期)2016-08-24
通信电源技术(2016年4期)2016-04-04
设备管理与维修(2016年5期)2016-03-16
工程建设与设计(2016年3期)2016-02-27
