
基于领域不变特征的跨库微表情识别
2024-05-19 10:16尹梦涛杨亚璞
电脑知识与技术 2024年9期
尹梦涛 杨亚璞
摘要:针对跨库微表情识别中因训练和测试样本特征分布不一致而造成的识别效果不理想的问题,提出一种基于域内不变特征和域间不变特征(Intra-domain and Inter-domain Invariant Features,IIDIF) 整合的跨库微表情识别的领域泛化方法。IIDIF使用知识蒸馏框架获取傅里叶相位信息作为域内不变特征,通过对齐源域特征之间的二阶统计量作为域间不变特征,同时设计一个不变特征损失将域内不变特征和域间不变特征整合为领域不变特征。在三个广泛使用的微表情数据集CASMEⅡ、MMEW以及SMIC上的实验表明,IIDIF方法的平均准确率为55.37%,优于现有主流的领域自适应和领域泛化方法,验证了所提出的IIDIF方法在跨库微表情识别任务上的优越性。
关键词:跨库微表情识别;域内不变特征;域间不变特征;领域泛化
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2024)09-0027-05
开放科学(资源服务)标识码(OSID)
0 引言
微表情是人们试图隐藏内心真实情绪时所产生的一种自发式面部表情,通常持续时间只有0.04~0.2 s,且变化强度很低[1]。微表情可以准确反映人们真实的心理状态和情绪,无法伪造也不能抑制,在商务谈判、刑侦和心理疾病治疗等领域上具有广泛的应用前景[2]。
近些年来,研究人员在微表情识别任务上提出了许多有效的方法,如能有效提取微表情外观特征的三个正交平面的局部二值模式(LBP-TOP)[3];能准确计算面部细微动作变化特征,并通过时空信息进行微表情识别的光流法[4]等。最近,随着深度学习的发展及其在面部表情识别[5]上的成功应用,深度学习方法也被应用于微表情识别任务[6]。如用于捕获微表情序列细微时空变化的时空卷积递归网络(STRCN)[7]等。
虽然微表情识别研究已经取得了显著的进展,但现有大多数微表情识别方法的训练和测试样本都来自遵循相同特征分布的同一个数据集,而在许多实际应用中,用于训练和测试的微表情样本可能来自不同的数据集。不同数据集的种族、性别、摄像设备等会有所不同,這破坏了训练和测试样本之间的特征分布一致性。在这种情况下,上述微表情识别方法的性能可能会急剧下降。因此,一部分研究人员开始关注训练和测试样本来自不同数据集的跨库微表情识别这一具有挑战性的课题。目前,研究人员大多采用领域自适应方法解决训练集(源域)和测试集(目标域)特征分布不一致的问题。领域自适应方法是迁移学习方法[8]的一种,尝试利用源域中丰富的标记样本信息,通过减少数据集之间的特征偏差来促进对目标域的学习。
然而,领域自适应方法依赖一个强有力的假设,即目标域数据可用于模型适应,这在实际场景中并不总是成立。在许多应用中,目标数据在部署模型之前很难获得,甚至是未知。对此,一部分研究者尝试使用领域泛化方法解决此问题。领域泛化方法的一个显著特点是在训练过程中,目标域是未知的。具体来说,领域泛化的目标是利用来自单个或多个相关但不同的源域数据进行模型训练,使模型能够很好地推广到任何未知的目标域[9]。自2011年研究者们开始探索领域泛化以来,已经提出大量的方法来解决此问题,包括增加数据多样性的数据增强[10]、通过模拟多个任务来学习一般可转移知识的元学习等[11]。领域不变特征学习[12]也是一种主流的领域泛化方法,旨在从不同领域中学习领域不变的特征表示或者对特征进行解耦以获取更有意义的泛化特征,从而有利于跨域泛化。
领域泛化方法虽然更有利于模型的实际应用,但它比领域自适应方法更难以实现,目前与跨库微表情识别相关的领域泛化方法研究工作相对较少。为了更好地利用领域泛化技术解决跨库微表情识别存在的问题,本文提出了一种基于域内和域间不变特征的跨库微表情识别方法(Intra-domain and Inter-domain Invariant Features,IIDIF) 。本文将域内和域间两种不变特征整合为领域不变特征进行模型训练。对于域内不变特征,IIDIF通过知识蒸馏框架捕获对数据进行傅里叶变换之后的高级内在语义,对于域间不变特征,IIDIF利用相关性比对来对齐源域的特征分布,同时设计增加了一个发散损失函数来最大化发散两种不变特征之间的距离,以保证使更多不同的域内和域间不变特征参与模型训练。最后通过实验验证了该方法的有效性。
1 IIDIF模型及方法
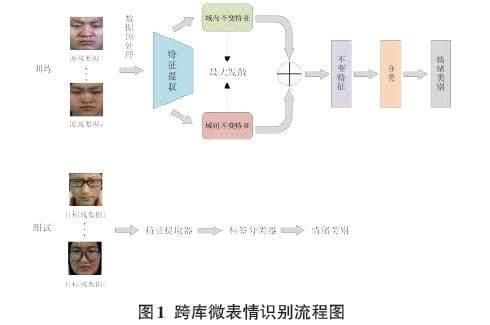
为了提高仅利用微表情源域样本训练出的模型在未知微表情目标域上的识别性能,本文从领域泛化的角度出发,设计了基于域内和域间不变特征的跨库微表情识别算法,跨库微表情识别流程图如图1所示。
在模型训练阶段,首先对训练数据进行预处理,然后利用特征提取器分别提取域内不变特征和域间不变特征,并在最大化两种不变特征之间的距离后,将其整合为领域不变特征进行分类。
1.1 域内不变特征提取
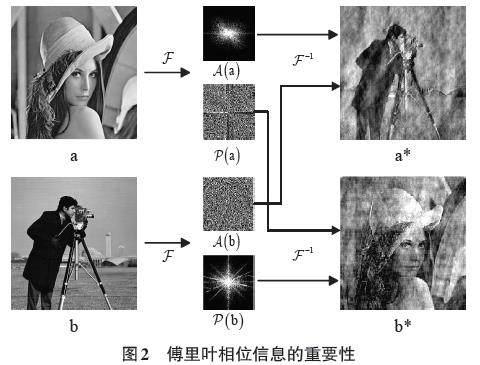
信号由振幅信息和相位信息两部分组成。在信号的傅里叶谱中,相位分量保留了原始信号中的大部分高级语义,而振幅分量主要包含低级统计信息。相位信息的重要性如图2所示。
在图2中,对图片a和b进行离散傅里叶变换。对于单通道尺寸大小为M×N的图像数据[x],其傅里叶变换[Fx]为:
[Fxu,v=m=0M-1n=0N-1xm,ne-j2πmMu+nNv] (1)
式中:[u]和[v]为频率变量,[Fx]振幅分量和相位分量可以分别表示为:
[Axu,v=R2xu,v+I2xu,v12] (2)
[Pxu,v=arctanIxu,vRxu,v] (3)
其中,[Rx]和[Ix]分别表示[Fx]的实部和虚部。
通过上式可以得到a和b相应的幅值信息[Aa]、[Ab]和相位信息[Pa]、[Pb],保持幅值信息不变,交换两幅图的相位信息,最后对重新组合的图像信息进行离散傅里叶逆变换,得到两幅新的图像a*和b*。从结果中可以看出,a*与b相似,b*与a相似,从而说明傅里叶相位包含更多原来图像的信息。
傅里叶相位信息作为一种领域不变特征已经引起许多研究者的关注。例如,Xu等人[13]提出了一种基于傅里叶变换的领域泛化框架,利用傅里叶相位特征不易受域变化影响的特点,从频谱相位分量中学习更多信息以帮助模型获得域内不变的特征。
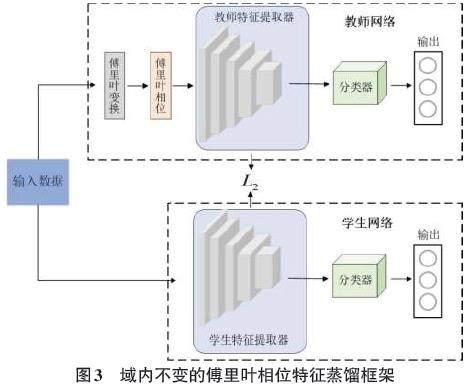
本文利用知识蒸馏框架获取域内不变的傅里叶相位特征信息。知识蒸馏(Knowledge Distillation,KD) 是一种鼓励在不同网络中包含特定特征的教师—学生训练框架。域内不变的傅里叶相位特征蒸馏框架如图3所示。
将输入教师网络数据[x]的傅里叶相位表示为[x],使用[x,y]训练教师网络后,在教师网络训练完成之后,使用特征知识蒸馏来引导学生网络学习傅里叶相位信息。经过蒸馏引导后,学生网络参数[ws]可以表示为:
[ws=argminwx,yL1fx;w,y+L2FeaSx,FeaTx] (4)
式中:[L1?,?]为神经网络中常用的交叉熵损失函数,[f?;w]为学生网络,[w]为学生网络中的参数,[FeaS]和[FeaT]分别为学生网络和教师网络的特征提取器,[L2]为使学生网络特征接近教师网络特征的均方误差损失函数。
1.2 域间不变特征提取
仅使用傅里叶相位特征可能不足以获得足够的分类判别特征。因此,本文利用多个训练域中包含的跨域知识来探索域间不变特征。具体来说,给定两个域[Si]和[Sj],对它们的二阶统计量(协方差)进行对齐,域间对齐损失函数[L3]为:
[L3=14d2Ci-Cj2F] (5)
式中:[?2F]为平方矩阵Frobenius范数,[Ci]和[Cj]分别为[Si]和[Sj]的协方差矩阵。针对本文跨库微表情识别任务只有单个源域的情况,通过使用随机参数在源域上进行采样,得到与源域具有不同特征分布的随机域,之后将源域与随机域进行域对齐训练以获取域间不变特征。
1.3 领域不变特征整合
由于域内不变特征和域间不变特征之间可能存在重复和冗余,为了能尽可能利用更多不同的不变特征,定义一个发散损失函数[L4],通过利用L2距离函数最大化发散域内不变特征[z1]和域间不变特征[z2]之间的距离,以提取更多有利于泛化的不变特征,发散损失函数[L4]公式表示为:
[L4z1,z2=-z1-z222] (6)
汇合公式(4) ,(5) ,(6) ,可以得到IIDIF完整的优化目标:
[ws=argminwx,yL1fx;w,y+λ1L2FeaSx,FeaTx+λ2L3+λ3L4z1,z2] (7)
式中:[λ1]、[λ2]、[λ3]分别为域内不变特征学习、域间不变特征学习以及发散损失函数的超参数,模型通过调整平衡超参数以获得更好的分类性能。
2 实验结果与分析
2.1 数据集预处理
本文在三个公开的微表情数据集上进行实验,分别是CASMEⅡ数据集[14]、MMEW数据集[15]以及SMIC数据集[16]。由于不同微表情数据集之间的情绪类别不统一,为了更好地进行泛化实验,需要对微表情数据集的情绪类别进行重新标注。考虑到3种微表情数据集的情绪类别和实验设置的合理性,本文对实验涉及的3个微表情数据集进行以下重新组织和标注:
1) 对于CASMEⅡ数据集,舍弃类别为“其他”的情绪样本,将“厌恶”“压抑”“悲伤”“恐惧”样本标记为“消极”,将“快乐”样本标记为“积极”,“惊讶”样本的标签保持不变。
2) 对于MMEW数据集,舍弃类别为“其他”以及数量较少的“愤怒”情绪样本,将“悲伤”“厌恶”和“恐惧”样本标签标记为“消极”,将“快乐”样本标记为“积极”,“惊讶”样本的标签保持不变。
3) 对于SMIC数据集,保持原有的“消极”“积极”以及“惊讶”情绪样本类别不变。
重新标注和排序后,每个数据集中的样本数量如表1所示。
由于微表情数据集的样本数量较少,不足以支撑模型训练,因此需要对数据样本进行扩增以增加实验的可靠性。为避免丢失特征细节,仅对微表情序列的起始帧和顶点帧图片采用旋转和镜像翻转这两種方法进行扩增。由于微表情数据集中不同情绪类别的数量相差过大,为避免因样本类别不均衡而造成的实验性能下降,对样本数量较少的类别,将其顶点帧前一帧或者后一帧图像同样视作样本顶点帧,以实现大致平衡不同类别样本数量的目的。经过扩增之后的微表情数据集的样本数量信息如表2所示。
2.2 跨库微表情实验设置
本文实验基于CentOS Linux release 7.6.1810(CORE) 操作系统进行,CPU为Intel(R) Xeon(R) Gold 6226R、GPU为NVIDIA GeForce RTX 3090,实验环境为Python 3.8和CUDA 11.0,深度学习框架为PyTorch 1.7.0。
实验选取三个微表情数据集中的任意2个分别作为源域和目标域进行跨库微表情识别实验,共有6种组合,实验方案如表3所示。
其中:C为CASMEⅡ数据集,S为SMIC数据集,M为MMEW数据集,“→”两边的字母分别为源域和目标域。
2.3 消融实验
2.3.1 模型结构消融实验
本文研究基于领域不变特征的跨库微表情识别,领域不变特征包括域内不变特征和域间不变特征。为了验证这两种不变特征以及加入不变特征损失函数后对模型性能的提升效果,以M→C跨库微表情识别任务为例,设计了如下消融实验,消融实验结果如表4所示,其中“√”表示添加本文模型的相应部分,“—”表示没有添加本文模型的相应部分。
从表4的结果可以看出,同时使用域内和域间两种不变特征的模型识别准确率为57.94%,比仅使用域内不变特征或者域间不变特征的模型识别准确率分别提升了3.12%和1.02%。加入使两种不变特征之间距离最大化的不变特征损失后,识别准确率提升了0.93%。可见,本文提出的方法能有效提升模型在跨库微表情识别上的泛化性能。
2.3.2 超参数消融实验
本文中,[λ1]、[λ2]、[λ3]分别是域内不变特征、域间不变特征以及不变特征损失对应的三个超参数,超参数设置的不同会直接影响模型识别的性能。为了验证三个超参数对实验结果的影响,通过改变一个超参数并固定另外两个超参数的方式设置消融实验,三个超参数取值分别设置为0.01、0.1、1、10。M→S跨库微表情识别任务超参数灵敏度实验结果如图4所示。
从图4中可以看出,当超参数[λ1]=1、[λ2]=10、[λ3]=1时,准确率最高,泛化效果最好。
2.4 对比实验
为验证本文所提方法的有效性,分别选择与主流的领域自适应方法和领域泛化方法进行比较。选取的领域自适应方法有DDAN[17]、BNM[18]、BSAN[19]、BEDA[20],领域泛化方法有DANN[21]、Vrex[22]、ANDMask[23]、DDG[24]、DRM[25]。所有方法均选择ResNet18为骨干网络,在CASMEⅡ、MMEW和SMIC三个数据集上的6种跨库组合下评估性能。
观察表5中不同方法在6组跨库微表情实验任务中的结果可知,本文提出的方法在C→S、S→C、S→M以及M→S四种跨库任务上达到最优的效果,且在六组跨库任务实验中的平均准确率为55.37%。在与领域自适应方法的结果比较中,本文所提方法的平均准确率相较于DDAN、BNM、BSAN、BEDA分别提升了2.86%、3.37%、3.02%和1.41%。同时本文方法在跨库微表情识别上的平均准确率相较于其他主流的领域泛化方法也有了显著的提升,平均准确率相较于DANN、Vrex、ANDMask、DDG、DRM分别提升了4.83%、4.10%、2.93%、2.03%和1.47%。从实验结果上来看,本文方法相比于其他先进算法性能提升较为明显,可以有效提高跨库微表情识别精度。
3 结论
本文从更有利于微表情识别模型的实际应用角度出发,提出一种基于领域不变特征的跨库微表情识别的领域泛化方法。该方法整合了域内和域间两种不变特征,并利用L2函数最大化两种不变特征之间的距离,以保证使用更多的不变特征信息参与模型训练。通过在3个微表情数据集的6组跨库识别任务上的实验结果表明,该方法的性能明显优于其他领域泛化和领域自适应方法。未来的研究可以考虑将更多类型的域内不变特征和域间不变特征结合起来,以达到更好的泛化性能。
参考文献:
[1] 于明,钟元想,王岩.人脸微表情分析方法综述[J].计算机工程,2023,49(2):1-14.
[2] 周伟航,肖正清,钱育蓉,等.微表情自动分析方法研究综述[J].计算机应用研究,2022,39(7):1921-1932.
[3] PFISTER T,LI X B,ZHAO G Y,et al.Recognising spontaneous facial micro-expressions[C]//2011 International Conference on Computer Vision.November 6-13,2011.Barcelona,Spain.IEEE,2011:1449-1456.
[4] HAPPY S L,ROUTRAY A.Fuzzy histogram of optical flow orientations for micro-expression recognition[J].IEEE Transactions on Affective Computing,2019,10(3):394-406.
[5] 曾晴,曾小舟,申静.基于多层卷积神经网络的人脸表情识别方法[J].电脑知识与技术,2023,19(9):13-15.
[6] ZENG X M,ZHAO X C,ZHONG X Y,et al.A survey of micro-expression recognition methods based on LBP,optical flow and deep learning[J].Neural Processing Letters,2023,55(5):5995-6026.
[7] XIA Z Q,HONG X P,GAO X Y,et al.Spatiotemporal recurrent convolutional networks for recognizing spontaneous micro-expressions[J].IEEE Transactions on Multimedia,2020,22(3):626-640.
[8] 魏小明.基于遷移学习VGG-16的微表情识别[J].电脑知识与技术,2023,19(1):31-34.
[9] WANG J D,LAN C L,LIU C,et al.Generalizing to unseen domains:a survey on domain generalization[J].IEEE Transactions on Knowledge and Data Engineering,2023,35(8):8052-8072.
[10] LU W,WANG J D,CHEN Y Q,et al.Semantic-discriminative mixup for generalizable sensor-based cross-domain activity recognition[J].Proceedings of the ACM on Interactive,Mobile,Wearable and Ubiquitous Technologies,6(2):65.
[11] LI D,YANG Y X,SONG Y Z,et al.Learning to generalize:meta-learning for domain generalization[J].Proceedings of the AAAI Conference on Artificial Intelligence,2018,32(1):3490-3497.
[12] LI Y,GONG M M,TIAN X M,et al.Domain generalization via conditional invariant representations[J].Proceedings of the AAAI Conference on Artificial Intelligence,2018,32(1):3579-3587.
[13] XU Q W,ZHANG R P,ZHANG Y,et al.A fourier-based framework for domain generalization[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).June 20-25,2021.Nashville,TN,USA.IEEE,2021:14383-14392.
[14] YAN W J,LI X B,WANG S J,et al.CASME II:an improved spontaneous micro-expression database and the baseline evaluation[J].PLoS One,2014,9(1):e86041.
[15] BEN X Y,REN Y,ZHANG J P,et al.Video-based facial micro-expression analysis:a survey of datasets,features and algorithms[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2022,44(9):5826-5846.
[16] LI X B,PFISTER T,HUANG X H,et al.A Spontaneous Micro-expression Database:inducement,collection and baseline[C]//2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG).April 22-26,2013.Shanghai,China.IEEE,2013:1-6.
[17] WANG J D,CHEN Y Q,FENG W J,et al.Transfer learning with dynamic distribution adaptation[J].ACM Transactions on Intelligent Systems and Technology,11(1):6.
[18] CUI S H,WANG S H,ZHUO J B,et al.Towards discriminability and diversity:batch nuclear-norm maximization under label insufficient situations[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).June 13-19,2020.Seattle,WA,USA.IEEE,2020:3941-3950.
[19] ZHU Y C,ZHUANG F Z,WANG J D,et al.Deep subdomain adaptation network for image classification[J].IEEE Transactions on Neural Networks and Learning Systems,2021,32(4):1713-1722.
[20] YANG J F,PENG X Y,WANG K,et al.Divide to adapt:mitigating confirmation bias for domain adaptation of black-box predictors[C]//International Conference on Learning Representations, ICLR, 2023:1-21.
[21] GANIN Y,USTINOVA E,AJAKAN H,et al.Domain-adversarial training of neural networks[M]//Domain Adaptation in Computer Vision Applications.Cham:Springer International Publishing,2017:189-209.
[22] KRUEGER D,CABALLERO E,JACOBSEN J,et al.Out-of-distribution generalization via risk extrapolation (REx)[C]//International Conference on Machine Learning, ACM, 2021: 5815-5826.
[23]PARASCANDOLO G, NEITZ A, ORVIETO A, et al. Learning explanations that are hard to vary [C]//9th International Conference on Learning Representations, OpenReview.net, 2021:1-24.
[24] ZHANG H L,ZHANG Y F,LIU W Y,et al.Towards principled disentanglement for domain generalization[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).June 18-24,2022.New Orleans,LA,USA.IEEE,2022:8014-8024.
[25] ZHANG Y F,WANG J D,LIANG J,et al.Domain-specific risk minimization for domain generalization[C]//Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining.August 6 - 10,2023,Long Beach,CA,USA.ACM,2023:3409-3421.
【通聯编辑:唐一东】
