
基于机器学习算法构建酱卤肉货架期预测模型
2024-05-16 03:34张慧娟黄千里徐宝才
食品研究与开发 2024年9期
张慧娟,黄千里,徐宝才
(合肥工业大学食品与生物工程学院,安徽合肥 230009)
货架期建模是食品预测微生物学的一个新兴领域。一般的货架期模型通过详细了解特定产品的腐败动力学,根据供应链中的环境条件数据实时预测产品状态。然而,肉制品货架期模型的建立以试验数据为主,只针对单一因素变化预测,无法判断多种因素变化对货架期的影响。现有的研究中,已有将机器学习算法或统计学习方法用于建立食品货架期模型,例如薛建新等[1]以软化为分类指标,分别采用非线性的最小支持二乘向量机(least square support vector machine,LSSVM)模型和线性的偏最小二乘回归三层贝叶斯概率(probabilistic latent semantic-latent dirichlet allocation,PLS-LDA)模型建立不同货架期沙果的分类模型;赵策等[2]以电子鼻设备对梨核进行采样,结合机器学习算法对3 个等级黑核梨进行分类,为皇冠梨进行品质检测。以上研究均需要通过开展wet-lab 试验获得原始数据。
肉制品科学发展过程中积累了大量研究数据,利用数据挖掘技术对这些数据进行分析和挖掘,进一步发现变化规律和趋势,有助于制定更科学、精准的保鲜策略。文本挖掘是从文本数据中获取有价值信息和知识,并通过计算机发现以前未知的新信息的方法,包括信息检索、信息提取和数据挖掘等过程[3]。Thavorn 等[4]在Web of Science 数据库中通过对生鲜农产品保质期延长技术进行科学计量和文本挖掘,以解决水果保藏问题。Luong 等[5]采用关键词搜索、专家咨询和文本挖掘相结合的方法研究肉制品的腐败发生时间与储藏条件、微生物因素、肉品类型等各个影响因素间的关系。
本文将机器学习算法和文本挖掘技术融入酱卤肉制品货架期预测研究中,基于原始数据收集,通过机器学习算法,以货架期为目标变量,通过多种特征(包括包装方式、储藏温度、保鲜剂种类和二次杀菌方式)来构建预测酱卤肉制品的货架期模型。首先通过比较各种编码方法,并选择效果较优的方法作为非数量特征的编码方式。继而比较多种分类算法,选择性能最优的模型,并分析最优模型在不同货架期分类中的表现。最后,对最优模型在实际产品(酱牛肉和盐水鸭)中的性能进行测试,分析应用潜能,以期为食品生产、加工和销售等领域提供有价值的指导。
1 材料与方法
1.1 原料、试剂与设备
牛腱肉、整鸭白条、卤料、葱、姜、八角、茴香:市售;生抽、老抽:佛山市海天调味食品股份有限公司。
乳酸链球菌素(Nisin)、聚赖氨酸(均为分析纯):浙江新银象生物工程有限公司;壳聚糖(分析纯):阿拉丁生化科技股份有限公司;平板计数琼脂(plate count agar,PCA)培养基:广东环凯微生物科技有限公司。
洁净工作台(AlphaClean 1300):力康精密科技(上海)有限公司;微生物培养箱(DR-H20):广东德瑞检测设备有限公司。
1.2 数据来源
酱卤肉制品的文献数据均来自于Web of Science核心数据库和中国知网(China National Knowledge Internet,CNKI)。因酱卤肉制品种类较多,单一检索无法得到完全结果,建立复合检索式:“stewed beef” OR “braised beef” OR “spiced beef” OR “sauce beef” OR “stewed chicken” OR “boiled chicken” OR “roast chicken” OR “braised chicken” OR “spiced chicken” OR “smoked chicken” OR “salted chicken” OR “stewed duck” OR “boiled duck” OR “roast duck” OR “braised duck” OR “spiced duck” OR “brine duck” OR “salted duck” OR “hemp duck” OR “stewed pork” OR “boiled pork” OR “braised pork” OR “spiced pork” OR “stewed meat” OR “boiled meat” OR “braised meat” OR “Yao meat”;时间跨度为2000 年至2022 年,文献类型选择“article”,一共检索到6 384 篇文献。在CNKI 数据库中主题检索:“酱卤肉” OR “卤牛肉” OR “酱牛肉” OR “烧鸡” OR “盐水鸭” OR “扒鸡” OR “肉冻” OR “肴肉”,一共有328 个结果。继而基于以下标准对所获文献进一步筛选:1)研究对象为酱卤肉;2)明确酱卤肉制品储藏条件;3)研究包括储藏期间细菌总数的测定;4)仅保留研究性论文。经整理,最终获得119 篇与酱卤肉制品货架期研究相关的文献,共收集样本量271 例。肉制品微生物的生长和繁殖受多种因素的影响,包括贮藏温度、包装方式、保鲜剂种类和二次杀菌方式等,具体详见表1。
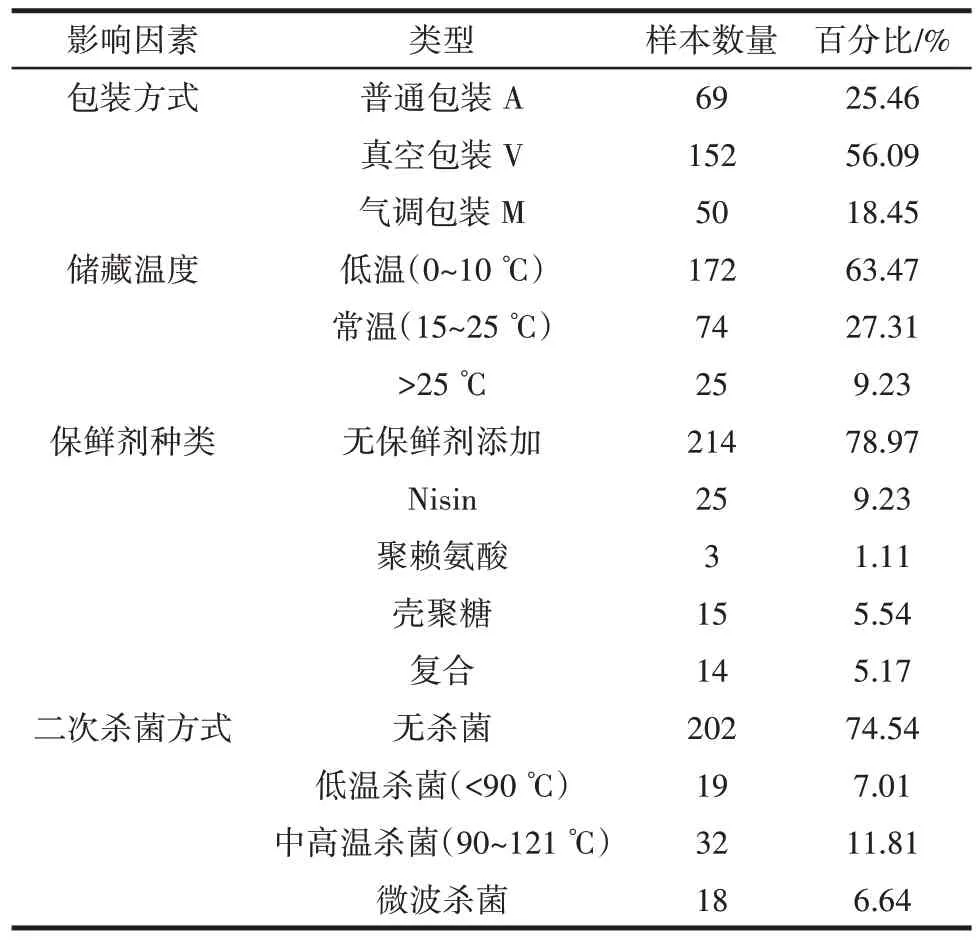
表1 原始数据集中不同影响因素组成Table 1 Different influencing factors composition in original dataset
1.3 数据整理
为便于运用机器学习构建酱卤肉制品货架期预测模型,需要对样本数据进行整理。首先,将货架期(微生物总数达到105CFU/g 的时间)设为目标变量,并将其分为8 个等级,其中货架期在1~5 d 内为Ⅰ级,6~10 d 内为Ⅱ级,11~15 d 内为Ⅲ级,16~20 d 内为Ⅳ级,21~25 d 内为Ⅴ级,26~30 d 内为Ⅵ级,31~60 d 内为Ⅶ级,>60 d 为Ⅷ级。其次,考虑的影响因素为包装方式、储藏温度、保鲜剂种类和二次杀菌方式,将这4 个因素设为特征变量。
由于很多机器学习算法要求输入数据是数值型,因此需要将非数值型变量转换为数值型变量[6]。分别采用5 种不同的编码方式对特征变量赋值,包括JamesStein、BaseNEncoder、TargetEncoder、OrdinalEncoder、PolynomialEncoder。(https://www.kaggle.com/code/arashnic/an-overview-of-categorical-encoding-methods)。
1.4 模型构建
为构建酱卤肉制品货架期预测模型,选用5 种机器学习算法,包括随机森林算法(RandomForest)[7]、逻辑回归(LogisticRegression)[8]、K 最近邻算法(K-nearest neighbors,KNN)[9]、多层感知机分类器(multilayer perceptron classifier,MLPClassifier)[10]和XGBoost[11]。开发语言为Python 3.7.16,利用scikit-learn 库的train_test_split 函数,将数据集按照70%用于训练和30%用于测试的比例进行随机划分。为优化模型参数,采用网格搜索法(GridSearchCV)来在所有候选参数组合中选择最佳参数[12]。此外,使用5-折交叉验证法(Cross-Validation)来验证模型准确度,这种方法将整个数据集分成5 份,每次选择其中1 份作为测试集,剩余4 份作为训练集;通过计算模型在测试集上的得分,并记录每次迭代的分数,最后对这些分数求平均值。比较不同模型的平均交叉验证得分,可以判断哪种模型在预测酱卤肉制品货架期方面表现最佳[13]。
1.5 模型评价
为评估、比较不同模型的综合能力和性能,更好地为酱卤肉制品行业提供有效的货架期预测模型,选取准确度(Accuracy)、精确度(Precision)、召回率(Recall)和F1-score 为评价指标。此外,使用受试者工作特征曲线(receiver operating characteristic curve,ROC)来分析模型的预测效能,以及曲线下面积(area under curve,AUC)来判定预测能力的大小,AUC 值越大,表明模型的预测能力越强[14]。相关性能指标的定义和计算方法如下:
1)准确度(Accuracy):分类正确的样本占总样本个数的比例。
2)精确度(Precision,查准率):分类正确的正样本个数占分类器判定为正样本的样本个数的比例。
3)召回率(Recall,查全率):分类正确的正样本个数占总的正样本个数的比例。
4)F1-score:精确度和召回率的调和平均值,兼顾了分类模型的准确率和召回率。
1.6 模型验证
为验证模型在预测不同类型酱卤肉制品货架期方面的准确性和稳定性,选择两种广泛消费的酱卤肉制品(酱牛肉和盐水鸭)为对象,选取4 个影响因素(包装方式、储藏温度、保鲜剂种类和二次杀菌方式)的不同水平,制作酱牛肉和盐水鸭。通过对这些不同处理条件下制作的实际样品的货架期进行测试,能够更好地了解模型在实际应用中的优缺点,从而为未来研究和模型改进提供方向。
1.6.1 酱牛肉制作
将5 kg 牛腱肉放入清水中浸泡3 h,每隔1 h 换一次水,去除血水和杂质。然后,把牛腱肉切成合适大小的块状,用适量生抽、老抽进行腌制,放入冰箱隔夜取出。腌制后的牛肉焯水,撇去浮沫。制备卤料,把卤料放入水中加热,水温升至65~70 ℃放入焯水后的牛肉,小火煮制时间为3~4 h。煮制完成后取出牛肉并于室温下冷却。将酱牛肉样品分别浸泡在Nisin、ε-聚赖氨酸、壳聚糖溶液中20 min,捞出后沥干,立即进行真空包装和托盘包装,分别在4 ℃和25 ℃下储藏。
1.6.2 盐水鸭制作
选择市售的鸭肉,把八角、茴香炒制过的盐涂擦在鸭体内腔和体表,堆码腌制。然后,将干腌后的鸭肉放入制备好的卤水中进行湿腌。将湿腌后的鸭胚放入4 ℃冷库里滴挂12 h 后再进行煮制。煮制过程中加葱、姜、八角,待水煮沸后,将鸭放入锅中,加热升温至85 ℃时小火闷煮60 min,即可起锅[15]。将盐水鸭样品分别浸泡在Nisin、ε-聚赖氨酸、壳聚糖溶液中20 min,捞出后沥干,立即进行真空包装和托盘包装,分别在4 ℃和25 ℃下储藏。
1.6.3 微生物数量测定
根据GB/T 4789.2—2022《食品安全国家标准食品微生物学检验菌落总数测定》方法测定保鲜剂处理后的酱卤肉和盐水鸭的菌落总数。
2 结果与分析
2.1 酱卤肉制品的货架期分布
不同储藏条件下,酱卤肉制品的货架期,即细菌总数达到105CFU/g 时间差异较大。所收集的数据显示,酱卤肉制品最长的储存时间为270 d,而常温条件下,大多数酱卤肉制品在第1 天细菌总数就超过了规定值。根据前期收集的酱卤肉制品货架期数据,对其进行分析,结果如图1 所示。

图1 酱卤肉制品的货架期分布图Fig.1 Shelf-life distribution chart of marinated meat products
由图1 可知,酱卤肉制品的货架期主要集中在Ⅰ级至Ⅵ级。其中,Ⅱ级(6~10 d)的货架期占比最高,共有75 个样品。这表明大部分酱卤肉制品的货架期在10 d以内,这可能与酱卤肉制品的保鲜方式和食品安全要求有关[16]。此外,从Ⅰ级到Ⅲ级的货架期分布来看,随着货架期的延长,样品数量逐渐减少。这可能表明,为了满足市场需求和保证食品安全,生产商和经销商倾向于选择较短的货架期。然而,也有一定数量的样品具有较长的货架期(Ⅶ级和Ⅷ级)。这些较长货架期的产品可能采用了更为先进的保鲜技术或特殊的加工工艺,以确保产品在长时间内保持良好品质[17]。这部分产品可能适用于远程运输或长期储存的场景,以满足不同市场的需求。可见,大部分酱卤肉制品的货架期较短,且随着货架期的延长,样品数量逐渐减少。这一现象可能与保鲜技术、市场需求和食品安全等多种因素有关。因此,在构建货架期预测模型中,将考虑4 个主要影响因素,包括包装方式、储藏温度、保鲜剂种类和二次杀菌方式。
2.2 模型构建
2.2.1 不同特征编码方法的效果比较
由于影响货架期的4 个主要影响因素为分类特征,因此在建模之前需要对它们进行特征编码,将分类特征转换为数值特征,以便于模型的训练和预测[18]。为了找到适合本研究的特征编码方法,对5 种编码方法进行比较,包括JamesStein、BaseNEncoder、TargetEncoder、OrdinalEncoder、PolynomialEncoder。这些编码方法各自具有不同的特点和优势,可以满足不同的建模需求和数据特征[19]。不同特征编码方式对模型训练和预测的准确率影响见图2。
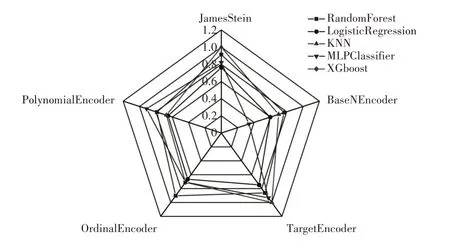
图2 不同编码方法的效果比较Fig.2 Comparison of the effects of different encoding methods
从图2 可以看出,JamesStein 编码在多数机器学习方法中表现较好,特别是在随机森林算法(Random-Forest)和KNN 中,准确率分别为0.91 和1.00(最高准确率)。TargetEncoder 编码在MLPClassifier 和LogisticRegression 中表现较好,准确率分别为0.93 和0.75。OrdinalEncoder 和PolynomialEncoder 编码在某些机器学习方法中表现较好,但在其他方法中准确率较低。BaseNEncoder 编码在大多数情况下表现一般,但在随机森林方法中的准确率为0.77,相对较高。可见,不同编码方法的表现有明显差异,选择合适的特征编码对于提高预测准确性至关重要。由于JamesStein 编码在大多数情况下具有较高的准确率,在后续的机器学习过程中使用JamesStein 编码作为特征编码方法。
2.2.2 不同预测模型的性能比较
为比较不同机器学习算法在目标数据集上的表现,分析RandomForest、KNN、逻辑回归(LogisticRegression)、多层感知机分类器(MLPClassifier)、XGboost在数据集上的预测性能,结果如图3 所示。
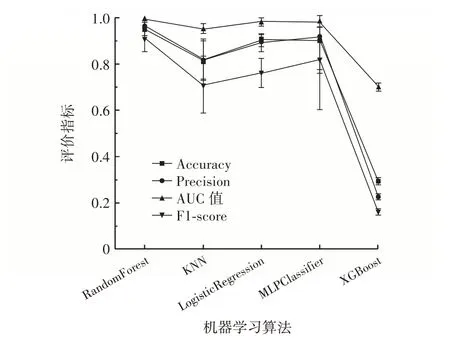
图3 不同预测模型的性能(准确度、精确度、AUC 值和F1-score)比较Fig.3 Comparison of performance(accuracy,precision,AUC and F1-score)of different prediction models
由图3 可知,随机森林在准确度(Accuracy)、精确度(Precision)、AUC 和F1-score 指标上的表现均优于其他方法,分别为0.95、0.97、0.99 和0.91,显示出较好的预测性能。逻辑回归和多层感知机分类器次之。K最近邻算法的F1-score(0.71)相对较低。XGBoost 在本试验中表现较差,准确度、精确度、AUC 和F1-score均较低,其精确率仅为0.23。
首先,RandomForest 表现出最佳的预测性能,这可能归因于它的集成学习策略,通过组合多个决策树来降低过拟合风险和提高预测准确性[20]。LogisticRegression 和多层感知机分类器(MLPClassifier)具有相似的较高准确度,表明它们在预测货架期方面具有一定潜力。然而,逻辑回归通常对线性可分问题有较好的处理能力,而货架期预测可能涉及非线性关系。相较而言,多层感知机分类器(基于神经网络的方法)可能更适合捕捉数据中的复杂模式[21]。KNN 在AUC 值上表现较好,但在准确度和F1-score 上相对较低。这可能与该方法对异常值和噪声敏感有关[22]。KNN 的实际应用中,可能需要进一步优化K 值和距离度量方式以提高预测性能。XGBoost 在本试验中表现较差,未来可以尝试使用网格搜索或贝叶斯优化等技术对模型参数进行调优[23]。总之,不同机器学习算法在预测酱卤肉制品货架期方面有其独特的优势和局限性。综合试验结果,由于随机森林算法(RandomForest;主要参数:n_estimators=500,min_sam-ples_leaf=1,random_state=200)在准确度、精确度、AUC 和F1-score 方面均表现出较好的性能,选其进行酱卤肉制品货架期的预测和后续的验证试验。
2.2.3 较优模型的性能分析
为进一步分析所构建的随机森林模型在不同货架期分类上的表现,基于不同类的预测结果构建混淆矩阵,如图4 所示。
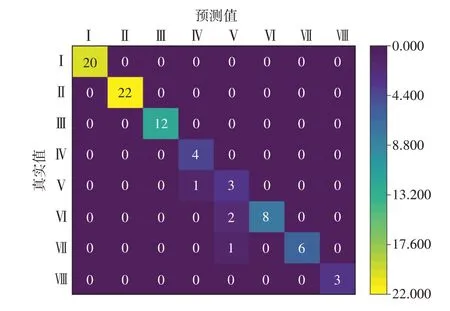
图4 随机森林模型在货架期预测中各等级的表现(混淆矩阵图)Fig.4 Performance analysis of random forest model on shelf-life prediction across different levels:A confusion matrix visualization
从图4 对角线元素可以看出,模型在Ⅰ、Ⅱ、Ⅲ、Ⅳ和Ⅷ类别上的预测准确性较高,这表明模型对这些货架期分类的预测能力较强。然而,在Ⅴ、Ⅵ和Ⅶ类别上表现次之。观察混淆矩阵的非对角线元素可见,在Ⅴ和Ⅵ类别上存在一定程度的预测误差。例如,Ⅴ类别中有2 个样本被错误地预测为Ⅵ类别,Ⅵ类别中有1 个样本被错误地预测为Ⅴ类别。可能因为这些类别的样本数量较少,模型在学习过程中未能充分捕捉到这些类别的特征[24];也可能是由于这两类货架期数据之间存在一定的相似性,导致模型在区分这些类别时出现困难。此外,酱卤肉制品的货架期也受到制作过程和制作环境的影响。例如,低温真空包装的酱卤肉制品的货架期主要集中在16~20 d,而低温普通包装的卤牛肉货架期在20 d 左右[25]。然而,针对烧鸡的储藏试验表明,真空包装低温储藏后仅1 d 细菌总数就超过了临界值[26]。随机森林模型在不同货架期分类上的预测性能存在差异,这可能与研究中提到的货架期与制作过程和制作环境之间的关系有关。基于这些可能的原因,未来可以尝试相应策略,如采用过采样或欠采样方法来平衡各个等级的样本数量,从而提高模型在这些等级上的预测性能[27];将与制作过程和制作环境相关的特征纳入模型;进一步挖掘各个等级之间的差异,以便更好地理解模型在预测货架期时可能遇到的挑战。随机森林模型在货架期预测中的ROC 分析见图5。
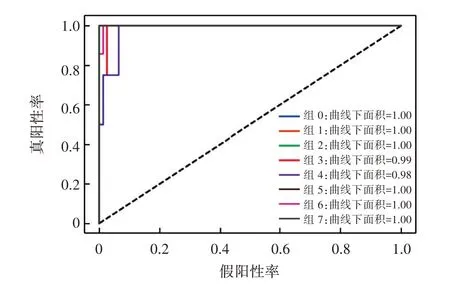
图5 随机森林模型在货架期预测中各等级的ROC 分析Fig.5 ROC for random forest model in shelf-life prediction across different levels
从图5 可以看出,随机森林模型在8 个货架期分类中的整体表现非常优秀。其中,除了Ⅳ和Ⅴ类别的AUC 值分别为0.99 和0.98 之外,其他类别的AUC 值均达到了1.00。AUC 值较高意味着模型具有较好的分类性能和预测能力[28]。结合前面的混淆矩阵结果,可以看出随机森林模型在大部分货架期分类上的预测准确性较高。然而,结合混淆矩阵结果,在Ⅳ和Ⅴ类别上,模型的预测性能略有下降。考虑到这两个类别的货架期为21~30 d(21~25 d 范围内为Ⅴ级,26~30 d范围内为Ⅵ级),这两个类别之间的特征分布可能存在一定的重叠,导致模型难以区分这两个类别[29]。可见,结合ROC 曲线的AUC 值和混淆矩阵结果,对于现有数据集,随机森林模型在不同货架期分类上的表现尚佳。
2.3 模型验证
为测试所构建的随机森林模型在实际产品的货架期预测中的表现,选择两种广泛消费的酱卤肉制品(酱牛肉和盐水鸭)为对象,选取4 个影响因素(包装方式、储藏方式、保鲜剂和二次杀菌)的不同水平,制作酱牛肉和盐水鸭。对这些不同处理条件下制作的实际样品的货架期进行测定,并与预测值进行比较,结果见图6。

图6 酱牛肉实际货架期与随机森林模型货架期预测对比Fig.6 Comparison for the actual shelf-life of marinated beef and the shelf-life prediction of random forest model
如图6 所示,在酱牛肉中的测试结果显示,在储藏温度为0~4 ℃的条件下,酱牛肉在普通包装和真空包装下的预测货架期与实际货架期一致,符合预测范围。然而,当使用壳聚糖作为保鲜剂时,货架期的实际值与预测值存在一定差异。这可能与壳聚糖作为一种天然的抗菌剂,在加工过程中对货架期的影响更为显著,导致模型的预测效果相对较差。在25~30 ℃的储藏条件下,模型对货架期的预测表现较为准确,实际货架期与预测值基本相符。这说明,随机森林模型在预测室温条件下酱卤肉制品的货架期方面具有较高的准确性。
对盐水鸭样品进行的货架期测试结果见图7。
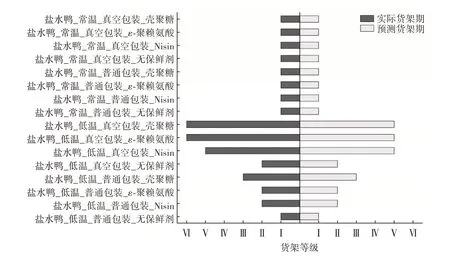
图7 盐水鸭实际货架期与随机森林模型货架期预测对比Fig.7 Comparison for the actual shelf-life of salted duck and the shelf-life prediction of random forest model
由图7 可知,除两例外,随机森林模型在其他情况下都能够准确预测。在低温储藏条件下,保鲜剂的使用以及包装方式都对货架期产生了明显影响,延长了盐水鸭的保质期,这与文献[30]中的研究结果相符。普通包装下,加入保鲜剂可以显著延长盐水鸭的货架期,而真空包装进一步提高了货架期。在室温条件下,不论包装方式和保鲜剂的使用,盐水鸭的货架期均显著缩短,这表明环境温度对货架期具有重要影响。
3 结论
在本研究基于原始数据收集,通过机器学习方法,构建了一个预测酱卤肉制品的货架期模型。此模型以货架期为目标变量,基于多种特征(包括包装方式、储藏温度、保鲜剂种类和二次杀菌方式等)来预测酱卤肉制品的货架期。通过比较多种编码方法,选用"James-Stein"编码作为特征数据的编码方式,以便更好地应对分类变量的多样性。在比较了多种分类算法的表现后,本研究选定了随机森林作为最优模型。进一步法分析了随机森林模型在8 个货架期分类中的表现,证实了模型的优越性能,表明模型在预测酱卤肉制品货架期方面具有较高的可靠性。为验证模型在实际产品中的表现,本研究选取了两种广泛消费的酱卤肉制品(酱牛肉和盐水鸭)作为试验对象,通过对不同处理条件下制作的实际样品的货架期进行测定,并与预测值进行比较,发现随机森林模型在预测酱牛肉和盐水鸭的货架期方面具有较高的准确性。
猜你喜欢
中国调味品(2023年9期)2023-09-11
阅读(快乐英语中年级)(2023年2期)2023-03-05
金桥(2022年9期)2022-09-20
中国调味品(2021年10期)2021-10-15
海峡姐妹(2019年2期)2019-03-23
中国生殖健康(2019年9期)2019-01-07
食品界(2016年10期)2016-09-10
中国粮油学报(2016年1期)2016-02-06
食品工业科技(2014年7期)2014-03-11
中国质量与标准导报(2014年2期)2014-02-28
