
基于改进积分梯度的黑盒迁移攻击算法
2024-05-11 03:35:12王正来关胜晓
计算机工程与应用 2024年9期
王正来,关胜晓
中国科学技术大学信息科学技术学院,合肥 230026
目前深度学习已广泛应用于生活的方方面面,例如人脸识别、自动驾驶、文本翻译、机器人技术等。随之而来,网络模型的安全性成为了数据工作者关注的重点,研究者发现了对抗样本的存在,即在输入中添加微小、人眼难以察觉的、经过精心设计的扰动制作成对抗样本输入分类模型就可以改变模型的预测结果[1]。深度学习的各种任务方向都发现了对抗样本的存在,包括目标检测、图像分割、文本分类、强化学习等,并可以将样本从数字世界转移到物理世界中进行物理对抗攻击[2]。使用妆容迁移来生成人脸对抗样本可以防止面部信息被不正当的人脸系统识别[3]。给交通指示牌照射精心设置的激光就可以引起自动驾驶识别系统出错进而造成安全事故[4]。因此,对于攻击方法和对应防御方法的研究有着重要的现实意义。
攻击方式主要分为白盒攻击和黑盒攻击,区别在于是否可以访问模型的具体信息。白盒攻击常用算法包括FGSM[5]、C&W[6]、PGD[7]等,而非理想的攻击对象一般处于黑盒模式,无法得知具体的结构,也不能得到模型返回的梯度等信息。黑盒攻击分为查询和迁移两种,基于查询的攻击需要多次访问模型输出,易引起监控者警觉,而迁移攻击主要基于对抗样本的迁移性,即针对不同层数、激活函数、超参数和训练集的神经网络生成的对抗样具有稳健的攻击性,在代理模型上生成的对抗样本可以误导其他未知模型。
目前攻击算法迁移性能普遍不高,近几年为提高对抗样本的迁移性,研究者聚焦于优化更新梯度方向,比如将动量项整合到迭代过程中[8],摆脱不良的局部最优,或者引入输入多尺度变换[9],使梯度方向更准确。但是基于梯度的方法存在固有的缺陷,当输入图片的特征进入饱和区时,单纯计算一点的反向梯度较小。其他的研究基于归因技术更改神经元注意力进行操作,提高内部失真,如FIA[10]、NAA[11]、ATA[12]等,但是所用归因技术指代性不够。Huang 等人[13]将积分梯度[14](integrated gradients)引入对抗攻击,提出了目前最先进的TAIG算法,并证明其同时从优化目标函数、修改注意力、平滑决策面三个方面进行攻击。TAIG 有两种版本,基于直线积分的TAIG-S和基于直线区间随机采样路径的TAIG-R。积分梯度是一种归因技术,用来显示原图中每个像素对预测结果的影响程度,但是其存在以下问题:一是默认输入已进入饱和区,将路径限定于基线到输入的有限路径内来计算路径上的梯度累积,但是真实输入却并未饱和,其忽略了线段外区域的有效梯度累积,使归因图丧失了大量有效信息;二是目前还没有优秀的基线,一般凭经验选取为全0图,但是对于模型来说并非不含任何信息;三是高维神经网络在小尺度上快速抖动会导致路径中单个点的梯度计算出现误差,从而生成的归因图含有较多噪点,而不同模型倾向于关注相似的区域,特征外过量噪点限制了TAIG算法的攻击性能。
为了解决以上问题,本文改进了积分梯度,提出无限路径的扩展积分梯度EIG(extended integrated gradients)和信息熵基线。在IG的基础上额外融合输入到真实饱和区的梯度累积,更明确了指代输入中每个像素的重要性,用EIG 替换TAIG 算法中的积分梯度可以明显提升其攻击性能;信息熵基线针对每个模型单独训练,使模型没有任何倾向。并基于此提出了一种改进积分梯度的对抗样本生成方法IIGA,其具有比TAIG更强的攻击性和迁移性能。图1 展示了该算法通过攻击ResNet 来迁移攻击其余模型的例子,IIGA 使用基于信息熵基线的EIG生成的梯度结果,同时在路径计算中引入梯度平滑[15],在每一点周围区间高斯采样,通过多输入平均可以抑制梯度噪点,大大提升了算法迁移性。

图1 IIGA迁移攻击Fig.1 Transferable attack of IIGA
本文贡献总结如下:
(1)提出了无限路径的扩展积分梯度EIG,可以生成更高质量的归因图并提升TAIG性能。
(2)提出了信息熵基线,针对每个模型单独训练,以很少的代价确保基线的无信息。
(3)提出了一种迁移攻击算法IIGA,基于EIG 和信息熵基线的梯度结果进行平滑,过滤梯度噪声,具有更高的白盒和黑盒迁移性能。
(4)通过大量的实验验证了提出的改进积分梯度攻击算法的优越效果。
1 相关工作
1.1 积分梯度
在做出决断时,人类倾向于借助物体的某些特征并分配注意力,同样,因为神经网络的高维非线性使模型解释非常困难,归因技术可以用来显示输入图片中每个像素对最终输出结果的影响,即通过归因图来表示模型分配给每个像素的注意力大小。
常用的归因技术包括直接梯度、CAM[16]、Grad-CAM[17]、LRP[18]等,积分梯度[14]是一种路径方法,结合了直接梯度和LRP分而治之的思想,在输入到基线值的路径上对梯度进行积分来构建更精确的归因结果,避免了饱和问题,可以生成更细致的归因图。
路径方法描述如下:定义一个映射函数f:ℝn→ℝk,表示一个深度网络,xe∈ℝn为输入图片,y∈ℝk为输出,经过softmax 归一处理之后可以表示不同类别置信度。令起始点为x′,定义一个路径函数γ:[0,1]→ℝn,表示从起始点γ(0)=x′到终点γ(1)=xe的路径。路径法沿γ(α)对函数梯度进行积分,α∈[0,1],则输入xe第i维的路径积分梯度为:
积分梯度法是路径方法中的一个特例,沿着直线进行积分,即γ(α)=x′+α(xe-x′),α∈[0,1]。其公式表达如下:
所有路径方法都满足不变性、敏感性、线性和完整性定理,而积分梯度法同时还满足保对称性,即交换两个参数的位置会保持输出结果不变,这样多个特征不需要按照固定的模式输入归因系统,可以减少预处理步骤,因此积分梯度法是路径方法中最优的选择。
1.2 黑盒迁移攻击
对抗样本的概念最先由Szegedy 等人[1]提出,对于分类器f,给定输入x和真实标签l。找到一个微小扰动δ,满足‖δ‖p≤ε,ε为约束,‖· ‖p为Lp范数,生成xadv=x+δ,使得f(xadv)≠l。
黑盒攻击是找到对抗样本最困难的攻击场景,不能获得模型的内部细节和梯度,主要分为基于查询和基于迁移两种方式。基于迁移的攻击使用更加广泛,使用代理模型制作对抗样本,与黑盒模型隔绝,管理员无法通过监控访问来规避攻击。
FGSM[5]是经典的一次攻击算法,攻击速度快,C&W[6]是一种优化方法,定义了多种约束函数将非线性约束转化可求解形式,但是两种算法对抗样本迁移性都较差。近年来针对梯度提出了多种改进方法,MI[8]将动量项整合到迭代过程中,来稳定更新方向,提供攻击可迁移性。SI-NI[9]引入缩放不变性来进行数据增强和Nesterov accelerated gradient 来跳出局部最优解,进行更好的优化。VMI[19]在每次迭代过程中不直接使用上轮累积的梯度,而是对梯度进行方差调整,进一步稳定更新方向。SM2I[20]提出了新的动量方法空间动量,对输入进行随机变换并利用不同区域的特征来生成更加稳定的梯度结果。还有一些研究引入注意力机制修改模型中间层或者针对归因图进行优化,可以提升攻击的迁移性。因为不同优秀的模型所关注的特征是类似的且集中于人类视觉观察的特征区域,因此针对修改共同关注的注意力区域可以提升对抗样本的迁移性。FIA[10]引入聚合梯度来获得输入的特征区域,指导破坏主导模型决策的重要特征。ATA[12]将通过反向传播梯度估计不同特征对模型方向的重要性,对同一层所有特征图通道求和并经过ReLU滤除负特征。AOA[21]与ATA类似,利用LRP的变体来计算归因图,并提出了几种抑制注意力的优化目标函数。TAIG[13]基于积分梯度,从有限路径中提取模型的注意力并作为攻击的优化方向,达到了目前的最佳,但是还有很大的提升空间。
针对迁移性的研究虽然有一定成果但是迁移攻击成功率依然不够理想。针对梯度的改进方法未考虑梯度饱和问题,而引入注意力的优化策略使用的归因技术指代粗糙,不能聚焦于模型所共同关注的部分。本文提出的算法可以同时弥补这两个方面的不足。
2 本文方法
本文优化了积分梯度,提出了扩展积分梯度的归因方法EIG和信息熵基线,并基于此提出了一种改进积分梯度的对抗攻击方法IIGA,可以大幅度提高白盒攻击和黑盒迁移攻击的性能,下面详细介绍该方法的具体实现过程。
2.1 改进积分梯度
2.1.1 扩展路径
积分梯度本质就是防止输入图片进入饱和区从而导致梯度为零,但是真实图片并不一定进入饱和区。在基线到输入之间的有限路径理想化地认可这一设定,而更准确的方法是在原来路径的基础上加上输入xe到真实饱和点x∞的补充区间,其中x∞=γ(+∞),存在基线到输入路径延长线的无穷远处,则延长区间上的归因补充为:
本文提出了扩展路径的积分梯度EIG,EIG 包括两个部分,一个是α∈[0,1],另一个是α∈[1,ω],其中ω趋近于无穷:
虽然扩展路径趋近于无穷,在实际计算的时候会很快进入饱和区,ω取一个大于2 的整数即可,在实际计算过程中采用离散形式,m为离散量,其离散形式为:
图2(a)展示了用ResNet50预测输入图片,当α从0(采用0基线)经过1(原图)到ω=3(接近饱和区)时,样本预测为目标类别的置信度,同时为了测量不同的路径范围对预测结果的影响,图(b)计算了每个点梯度的l2范数,可以看出α在2.5 之后目标类别置信度和反向梯度才逐渐趋近于0,将不同分段产生的归因图展示如图2(d)~(f)所示,(f)表示的EIG 综合了额外路径的信息,比(d)代表的IG更好地显示了归因像素位置和强度。

图2 不同路径区段结果Fig.2 Results for different path segments
并且将扩展积分替换TAIG算法的积分梯度可以明显提升TAIG攻击的效果,具体结果见3.2和3.3节。
2.1.2 信息熵基线
除了积分路径,基线值x′也非常重要,表示中性的、不含任何信息的输入量。目前对于基线的研究并不多,大多数都是以人类直觉作为参考,在图像任务中一般使用全黑图、全白图和随机值,在自然语言领域采用全零向量。然而从模型的视角来说,这些基线并非是中性的,比如区分黑夜和白天任务,使用全黑或全白基线的模型有各自不同倾向性。有研究[22]指出基线的选择对模型解释效果会产生显著影响,基线代表模型功能缺失性的参考点,选择恒定颜色的基线会使模型丧失对该颜色的关注度,而如果特征位于该颜色范围则会遭到模型的忽略。因此积分梯度采用更恰当的基线会得出更真实的关注度,有助于在对抗攻击任务中产生更准确的扰动方向。
熵代表随机变量不确定度的度量,为了解决以上缺陷,可以用信息熵[23]来度量输入对特定模型的信息携带量:
根据积分梯度的定义,基线相对于模型来说不包含任何信息量,因此最优的基线应该携带最少的信息量,用以下公式来表示:
在具体实现的过程中可以在0 基线的基础上简单地通过几轮迭代来降低H(x),图3展示了0值基线(全黑图)和信息熵基线输入分类模型的预测结果,横坐标包含1 000个不同类,纵坐标为经过归一化之后的输出置信度,可以看出0值基线输入模型依然会有自己倾向的类别,表明含有一定信息,与基线的定义不匹配,而信息熵基线各类别的置信度大致相当,模型不能得出任何结果。

图3 不同基线预测结果Fig.3 Different baseline prediction results
2.2 基于改进积分梯度的攻击算法
改进积分梯度衡量了直接与网络模型预测结果相关像素的敏感度,而反向更改这些输入像素点的值可以抑制模型输出某一类别的倾向,在特征世界里变相擦除了不同模型判别某一类别所共同依赖的特征。本文提出了IIGA 攻击算法,与TAIG 的思想类似,针对图像特征区域进行攻击。
但是IIGA并不是直接将生成的改进积分梯度结果作为优化方向,因为神经网络是高维的,其函数的导数在小尺度上会快速抖动,而基于ReLU激活函数使网络不是连续可导[15],这导致计算的积分梯度存在许多噪点,并随机分布在图片的各个区域。这些散布在无关区域的噪点导致在样本迁移时影响了大量不相关的区域,而对真实公共部分特征的关注不够,造成攻击其他模型时成功率下降。
针对以上问题IIGA 引入平滑梯度操作来滤去噪点。在原始输入x的邻域内进行高斯采样,具体地,加入高斯随机噪声,分别计算不同输入的积分梯度,平滑之后的积分梯度取平均值:
其中,p为高斯采样的样本数,N(0,σ2)是均值为0,标准差为σ的高斯噪声。平滑梯度的本质就是输入大量相近的图片求平均来抑制高维神经网络的快速波动。图4 展示了图片使用不同积分梯度计算的结果,IG 和EIG采用信息熵基线相比0基线关注的特征区域更加明显。加入梯度平滑操作之后归因图中无关区域的噪点显著减少,而结合信息熵基线和平滑梯度的归因图(e)、(i)将关注点都集中于鸟本身区域。
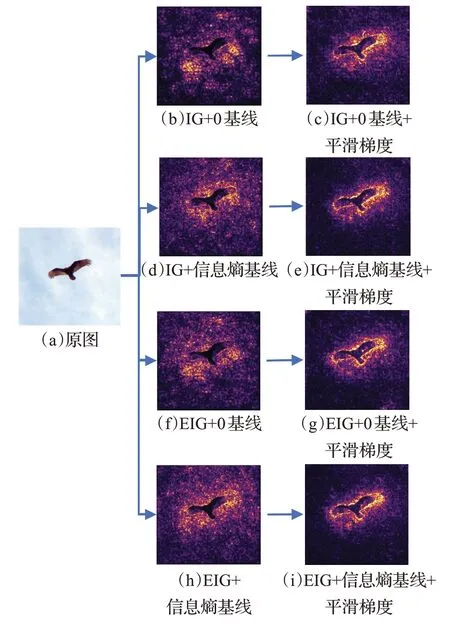
图4 积分梯度归因图Fig.4 Integrated gradient attribution map
经过平滑之后的积分梯度相比现有方法更加有效的衡量了图片的注意力,在IIGA迭代攻击中引入动量,攻击形式如下:
其中,μ为动量系数,动量项的引入可以在迭代过程中摆脱不良的局部最大值,稳定更新方向。ε为扰动系数,sign(·) 为裁剪函数,将数据限定在真实像素范围内。因为计算出的IG 矩阵元素大小不均,为了限制其无穷范数,裁剪函数提取积分梯度方向,将一步扰动ε均分为多步小扰动形式,T为划分步数,则每次的扰动距离为ε/T。在实际攻击过程中,为了减少计算量,可以判断每一小步是否攻击成功,如果不成功则再重新计算更新方向进行下一小步的更新,攻击成功则跳出循环。
算法伪代码见算法1,先初始化参数并依靠几轮迭代生成信息熵基线,攻击时在每次迭代攻击中在单个点周围采样p次,求计算的改进梯度积分的平均,并且通过动量融合上一轮梯度的信息来优化对抗样本。
算法1改进积分梯度算法(IIGA)
输入:分类模型f,图片x,真实标签l,更新步数T,离散路径分段m,积分扩展系数ω,标准差σ,高斯采样数p,动量系数μ。
输出:对抗样本xadv。
3 实验
本章设计实验来验证改进积分梯度算法攻击的性能,首先介绍实验使用的数据集、模型、对比方法等,然后比较白盒模式下的攻击效果,以及黑盒迁移攻击性能,最后比较算法中超参数取值对攻击效果的影响。
3.1 实验设计
(1)数据集。本文使用的数据集为从ImageNet[24]挑选的1 000 张图片,并且保证所有分类模型都可以正确预测结果,这样可以忽略不同模型分类准确度的差异,只关注算法本身在不同结构模型上的攻击效果。
(2)模型。为了公正合理地评判不同攻击方法的优劣,被测模型分别选择CNN 结构的模型ResNet-50[25]、InceptionV3[26](简称Inc-V3)、EfficentNet B3[27](简称Effi-B3)。基于Transformer架构的分类模型Swin Transformer[28](简称Swin)和MViTv2[29]。以及结合卷积的Transformer架构、Convolutional Transformers[30](简称CvT),分别选取各种模型的版本为Swin-B,MViTv2-B 和CvT-13,所有模型均在ImageNet数据集上进行训练。
(3)基线算法。白盒攻击模式下比较算法包括FGSM、C&W、ATA、AOA、FIA、TAIG-S 和TAIG-R。在黑盒模式下,基线算法包括迁移性较强的算法SI-NI、ATA、AOA、VMI、FIA、SM2I、TAIG-S、TAIG-R,同时还包括EIG版本的TAIG。固定IIGA方差σ=0.15,μ=0.9。
(4)评测指标。评测指标包括:
①攻击成功率:攻击成功样本数/总样本数量;
②平均攻击耗时:每个样本的平均生成时间。
实验代码采用PyTorch 框架编写,硬件平台采用两块NVIDIA GeForce RTX 3090。
3.2 白盒攻击
黑盒迁移攻击是依赖白盒算法攻击代理模型生成的对抗样本去攻击未知模型,而一般方法白盒攻击和迁移攻击相互矛盾,在代理模型上攻击成功率越高则迁移性较差。而IIGA 因为关注了准确的注意力特征,可以减轻两者之间的权衡,在白盒和黑盒两种模式都取得优异的性能。
将改进算法与流行的白盒攻击方法进行比较,实验采用单步攻击,即对原图只进行一轮扰动更新,限定相同的最大扰动距离ε为8/255,这样可以抛弃其他因素,比较算法本身计算更新方向的优劣,而如果采用多步攻击,大多数算法都可以取得接近100%的成功率。TAIG和IIGA的分段值m都设置为20,平滑梯度采样数p设置为25,ω为4。
检验不同算法分别单步攻击ResNet-50、Inc-v3、Effi-B3、Swin、MViTv2-B 和CvT-13,攻击成功率见表1。从表中可以得出,在白盒模式下,将TAIG中的积分梯度更换为扩展积分梯度EIG 可以明显地提升其白盒攻击的成功率,TAIG-S攻击ResNet-50准确率提升了13个百分点以上。所提出的IIGA算法超过了所有对比的白盒方法,比TAIG-S攻击准确率平均高12个百分点,比TAIG-R高9个百分点,达到了目前的SOTA。

表1 不同攻击算法单步攻击模型的成功率Table 1 Success rate of single-step attack models of different attack methods 单位:%
3.3 黑盒迁移攻击
迁移攻击是一种常用的黑盒攻击方式,具有隐蔽性高,不需要查询模型等优点。所有算法都基于迭代的方法,限定同样的迭代次数T=5,扰动ε=8/255,攻击代理模型ResNet-50,所有算法都达到了100%左右的成功率,将攻击成功的对抗样本迁移攻击其他模型,这样可以过滤掉失败样本对检验结果的干扰。TAIG 和IIGA的参数设置与3.2节保持一致。
表2比较了不同算法迁移攻击成功率,可以看到将IG替换为EIG的TAIG两种版本算法的迁移性能都有一定的提高,分别提高了2~4个百分点。IIGA攻击所有模型都取得了最佳的效果,平均迁移攻击成功率超过SI-NI的12个百分点,TAIG-R的6个百分点,提升明显。

表2 攻击代理模型生成对抗样本的迁移攻击成功率Table 2 Transferable attack success rate for attack agent models generating adversarial samples 单位:%
3.4 攻击耗时
本文统计了不同算法制作单张对抗样本的平均耗时,攻击ResNet-50 模型,限定ε=8/255,T=1,m=20,p=25,ω=4,结果见表3。每个方法的计算时间有一定差别,除去加法等基本计算的时间,主要花费在输入模型计算反向梯度的次数上,FGSM、C&W、AOA、ATA和FIA每次迭代输入计算一次梯度反向传播,时间复杂度为O(T)。同理,因为每一次迭代都包含多次固定的梯度反向计算,SI-NI、VMI、SM2I的时间复杂度都为O(k·T),k为不同算法输入模型的次数。TAIG 在每一次迭代过程中进行m次梯度计算,时间复杂度为O(m·T),IIGA的时间复杂度为O(mpω·T),所有算法的时间复杂度都为O(T)。IIGA 因为系数相比于TAIG 更大,在实际耗时上不占优势,但是因为每一段的计算过程都一样,可以将多次输入组合成多batchsize的张量,降低输入模型的次数,因此并不会花费太多倍的时间。在实际测试中TAIG-R 处理一张图片为104 ms,而IIGA 为352 ms,大约为TAIG的3倍。

表3 单步攻击平均耗时Table 3 Average running time for single-step attack单位:ms
3.5 消融实验
IIGA 结合了扩展积分梯度、信息熵基线和梯度平滑,下面比较两种改进方法各自的提升效果。设置ε=8/255,m=20,p=25,ω=4,按照3.2 和3.3 节叙述的操作,分别比较扩展积分梯度使用0 基线、随机基线和信息熵基线,以及在各自种情况下加入平滑梯度操作的结果。如表4所示,分别比较白盒攻击和黑盒迁移攻击的平均成功率,相比于基线选择,平滑梯度得到的提升更大,而结合两种操作的IIGA 取得了最佳性能。随机基线因为是在[0,1]之间取值,输入到基线之间的点逐渐失去语义信息,不适合对抗攻击任务,而0 基线和信息熵基线都在0附近,输入与基线的插值相对于0成比例,图片的整体信息还在,则其梯度信息具有参考价值。

表4 消融实验Table 4 Ablation experiments单位:%
3.6 参数分析
这部分具体检验IIGA算法中不同参数对算法性能的影响。
(1)迭代步数T。固定IIGA 划分段m=20,扰动距离ε=8/255,高斯采样数p=25,ω=4,比较不同的迭代步数T下白盒攻击目标模型的成功率。具体如图5所示,横坐标为迭代轮数,纵坐标为攻击成功率,随着T的增加,成功率明显增强,经过4~5 轮左右的迭代结果逐渐趋近于饱和。
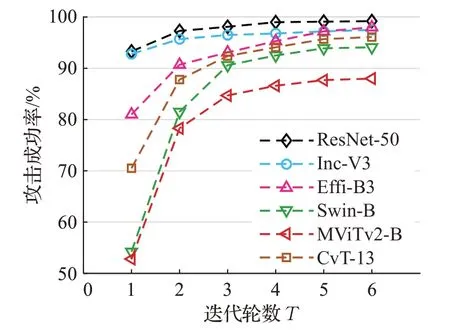
图5 不同迭代步数T 攻击成功率Fig.5 Attack success rate of different T
(2)扩展范围ω。固定ε=8/255,T=1,m=20,p=25。如图6所示,ω分别取值1、2、3、4、5、6,可以看出扩展范围越大,获得的积分梯度信息更准确,攻击准确率逐步提高,w=4 时趋近于稳定,综合考虑计算量,w可以取值4。

图6 不同扩展参数ω 攻击成功率Fig.6 Attack success rate of different ω
(3)分段数m。IIGA 采用离散方式近似计算积分梯度,固定ε=8/255,T=1,p=25,ω=4。图7 比较不同分段数m下白盒攻击的成功率,横坐标为m,纵坐标为攻击成功率,m分别取值为5、10、15、20、25和30。随着分段数划分得越多,攻击成功率有所提升,但需要的计算量会更高,m=10 时已经达到了可接受的结果。

图7 不同分段数m 攻击成功率Fig.7 Attack success rate of different m
(4)高斯采样数p。固定ε=8/255,T=1,m=20,ω=4,如图8所示,p分别取值5、10、15、20、25、30,可以看出高斯采样的数量与攻击效果存在明显的正相关关系,p值越大,平滑之后的积分梯度更精确,攻击准确率逐步提高,p=15 时趋近于稳定。
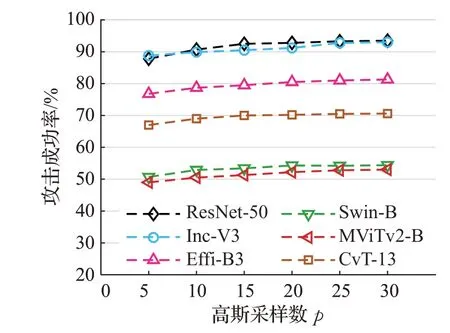
图8 不同高斯采样数p 攻击成功率Fig.8 Attack success rate of different p
4 结束语
本文针对现有算法的不足,改进了积分梯度,提出了扩展积分梯度EIG和信息熵基线,并提出了基于EIG、新基线和梯度平滑的对抗攻击算法IIGA。实验结果表明EIG可以生成比积分梯度更优秀的归因图,基于信息熵基线的IIGA算法对不同架构的模型都具有较强的白盒攻击和黑盒攻击成功率,单步攻击准确率超过了经典的白盒攻击算法,黑盒模式中大大提升了对抗样本的迁移能力,比TAIG 等目前最先进的一些算法表现更优秀。但是IIGA 引入了一些额外计算,在运行时间上处于劣势。后续将对归因技术引入对抗攻击进行更深入的研究。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29 03:15:16
中学生数理化·七年级数学人教版(2022年6期)2022-06-05 06:50:52
军民两用技术与产品(2022年1期)2022-06-01 06:28:50
北京心理卫生协会学校心理卫生委员会学术年会论文集(2018年1期)2018-05-10 09:49:08
数学大世界(2017年31期)2017-12-19 12:29:42
电子测试(2017年12期)2017-12-18 06:35:48
雷达学报(2017年6期)2017-03-26 07:52:58
池州学院学报(2015年3期)2016-01-05 01:13:00
继续教育研究(2014年1期)2014-02-27 16:10:18
