
采用边界对比学习的三维激光点云场景分割算法
2024-05-09 03:15刘婷婷宋家友
电光与控制 2024年5期
张 迪, 刘婷婷, 宋家友
(1.郑州西亚斯学院计算机与软件工程学院,郑州 451000; 2.郑州大学信息工程学院,郑州 450000)
0 引言
由于二维影像数据容易受到视角、光照、旋转和尺度等因素的影响,在对复杂的结构、地形和场景进行重建时,存在效率低和误差大的问题[1-2],激光点云技术应运而生,通过发射激光扫描目标,并接收反射激光的强度和回波次数等信息来获取目标的三维坐标,完成对目标的模型重构,从而获取三维空间中各类目标的分布情况,被广泛应用于测绘、三维重建、文物保护、产品质量控制、智慧城市和无人驾驶等领域[3]。与二维影像建模相比,三维激光点云数据包含更符合真实目标的空间信息,具有测量效率高、数据精度高和便于非接触式测量等优势。随着计算机硬件性能的大幅提升和人工智能技术的飞速发展,以卷积神经网络为基础的深度学习算法在目标检测、分类和语义分割等任务上取得了极好的效果[4-5]。然而,由于三维激光点云具有数据量大、排列散乱和无拓扑关系等特点,存在云语义分割准确率较低的问题,相关的研究仍然面临着严峻的挑战。
采用深度学习技术的三维激光点云语义分割通常有两种方法[6]:第一种是将点云转化为三维体素进行特征提取和分割预测,把非结构化的点云数据转化成结构化三维体素,如同处理二维影像数据,使用卷积神经网络提取特征,但会损失原始三维激光点云中的空间信息,导致检测精度整体下降;第二种是基于三维激光点云的分割方法,直接从原始点云中提取特征,能够保留三维空间中的位置信息,针对特征编码的感受野大小也不会受到卷积核影响,可以实现较高的检测精度。面向三维激光点云数据的语义分割任务旨在给点云中的每一个点分配一个语义标签,类似图像分割中逐一像素分类[7]。然而,由于三维空间中的点云密度不一致,不像二维图像中的像素能够均匀分布,会给局部区域点的判别带来挑战。其次,点云中的点是随机排列,很难找到任意点之间的连续性,所以类似图像中的卷积运算不适用于点云的深度学习任务;另外,分割任务需要先提取点云的高层次语义特征,再通过特征解码对每个点进行语义预测,但是如何整合全局特征并分配给逐一像素点是一个技术难点。PointNet作为一项开创性的方法[8],首次将深度网络应用于三维激光点云处理领域,以简单的结构、轻量的网络参数以及高效的运算速率在点云分类和分割任务上取得了卓著的成果。但是,PointNet网络设计的初衷没有考虑到点云局部信息的提取,即前文中提到的点云连续性的问题,随后其改进的模型PointNet++通过学习二维卷积神经网络中卷积叠加增大了感受野,并根据固定的半径搜索任一点邻域来提取局部特征,同时考虑点云邻域关系和空间特征信息,成为了点云深度学习的通用框架。
在三维激光点云场景分割领域中,边界预测的优劣直接决定了分割效果的好坏,既需要对场景中复杂多样的目标做出准确判别,又需要对紧挨的点云进行精准预测。一些相关研究已经意识到边界的重要性,尝试采用显示边界预测或者局部聚合模块来提升边界分割的准确性[9]。但是这些方法在很大程度上增加了模型的复杂性,对整体性能的提升却非常有限。本文以PointNet++网络为基础主干网络,引入了边界对比学习(Boundary Contrastive Learning)框架,加强了三维激光点云场景分割任务中边缘点云的特征提取和学习,通过耗费少量模型空间和时间资源,提升了三维激光点云场景分割模型的边界预测精度。在大型场景的三维激光点云数据集上进行的广泛评估表明,相较于其他几种算法,本文算法的分割性能具有明显的优越性。
1 三维激光点云场景分割网络
针对点云边界模糊、分布密集以及语义类别难以区分的问题,本文设计了基于边界对比学习的三维激光点云场景分割网络,它是一个端到端训练的模型,输入为大场景激光扫描后的原始点云数据,每个点的数据都是一个三维空间坐标,利用PointNet++作为主干网络进行下采样的特征编码和上采样的特征解码,再输出每个点的语义标签,并逐点预测目标类别,实现场景整体分割。在下采样阶段,不同尺度的点云特征会先通过边界点,并挖掘出模糊的边界点,然后利用对比学习损失函数对边界点的预测进行建模,设计了边界预测分割效果的指标,增大了不同语义类别的边界点距离,最终实现边界点的精准分割。分割网络框架如图1所示。
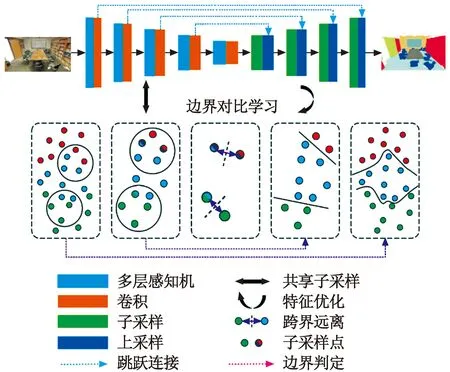
图1 提出的分割网络框架Fig.1 Framework of the proposed segmentation network
由图1可知,该框架以轻量级网络PointNet++作为基础主干网络,可以快速、高效地分割点云数据,其中的分组采样扩大了模型感受野来提取局部特征,进一步提升了网络性能。
1.1 主干网络PointNet++
PointNet++借鉴了二维图像分割网络的设计思想,针对多层次的三维激光点云分割,以分组采样形式处理在任一点邻域空间中的一组点。本文通过底层邻域空间的距离度量,把点集分割成重叠的局部区域,然后利用小邻域的局部特征来获取精细的空间结构,再分组到更大的单元继续处理,从而生成更高层次的特征,最终获得整个点集的高层语义特征。
PointNet++由大量具有层级结构的集合抽象层构成,分别为采样层(Sampling Layer)、分组层(Grouping Layer)和点网层(PointNet Layer)。
1) 采样层。给定输入点{x1,x2,…,xn},使用迭代最远点采样法找出m个点,并组成输入点的子集{xi1,xi2,…,xim},其中,xij是点集{xi1,xi2,…,xij-1}外距离最远的点。
2) 分组层。输入是大小为N×(d+C)的点集(N为点数,d为点的维数,C为每个点特征的维数)和大小为N′×d的一组质心的坐标,输出是大小为N′×L×(d+C)点集组(N′为采样后的点数,L为质心点邻域的点数),每组对应一个局部区域,L在不同的组之间会有所不同。
3) 点网层。输入是大小为N′×L×(d+C)点的局部区域,输出数据大小为N′×(d+C′)(C′为处理后的特征维数)。该层能够提取每个中心点附近聚集的三维激光点云的局部特征,再经过集合抽象层提取特征后,通过解码网络与跳跃连接整合所有特征,最后获取针对每个点的语义标签预测。
1.2 边界分割
当前边界分割的研究方向大多集中在改进分割的整体指标,如平均交并比(mean Intersection over Union,mIoU)、整体准确度(Overall Accuracy,OA)和平均准确度均值(mean Average Precision,mAP),导致点云分割的边界质量通常被忽略。本文的思路与仅给出边界定性结果的相关研究不同,而是引入了量化指标衡量边界分割,在三维激光点云的标注数据中,如果在其邻域中存在具有不同语义标签的点,将其视为边界点。类似地,对于模型预测,如果附近存在具有不同预测标签的点,本文将一个点视为预测边界点。具体来说,将点云记为χ,将第i个点记为xi,其局部邻域为Θi=Θ(xi),对应的真实标签为li,模型预测标签为pi。进一步将标注点云中的边界点集记为Bl={xi∈χ|∃xj∈Θi,lj≠li},将预测结构中的边界点集记为Bp={xi∈χ|∃xj∈Θi,pj≠pi}。
本文将Θi的邻域半径设置为0.1。为了衡量边界分割结果,一种直观的方法是计算边界区域内的平均交并比,即mIoU@boundary。为了比较模型在边界和非边界(内部)区域的性能,计算内部区域的平均交并比,即mIoU@inner。平均交并比在整个点云χ上可计算为
(1)
式中:K为所有语义标签的类别总数;Η(·)为一个逻辑运算函数。
根据mIoU定义,计算边界和内部区域的平均交并比,即
MmIoU@boundary=mIoU(Bl)
(2)
MmIoU@inner=mIoU(χ-Bl)
(3)
其中,χ-Bl表示三维激光点云中某一目标内部的点集,与边界点集互补。
然而,mIoU@boundary和mIoU@inner没有考虑模型预测分割中的错误边界。受二维实例分割的边界 IoU的启发,为了更好地进行评估,本文引入了分割预测边界与标注数据边界之间的对齐指标BIoU。需要先找到分割点集的边界点集,其后进行交并比计算,具体定义为
(4)
1.3 边界对比学习
对比学习是一种自监督学习理论,在缺少标签的情况下,通过让模型学习数据点的相似或不同,从而得到数据集的一般特征。本文模型针对三维激光点云的边界点进行对比学习,通过损失函数优化网络模型参数,加强网络在三维激光点云中不同语义类别边界点的特征编码。本文遵循了被广泛使用的对比学习损失函数InfoNCE及其泛化来定义边界点的对比优化目标。具体而言,对于一个边界点xi∈Bl,鼓励学习到的表示方式与其来自同一类别的相邻点更相似,并且不同于来自不同类别的其他相邻点,损失函数定义为
(5)
式中:fi为任一xi的某一尺度特征;d(·,·)为距离测量函数;τ为控制对比学习中的温度。
损失函数定义的对比学习只关注边界点。首先,本文考虑来自真实数据的所有边界点Bl,如同前文描述。然后,对于每个点xi∈Bl,将其正、负点的采样限制在其局部邻域Θi内。在强约束的空间限制下,可得到xi的正对,如{xj∈Θi∧lj=li},而其他相邻点,即{xj∈Θi∧lj≠li},是负对。对比学习正是通过损失函数拉近了同类边界点之间的距离,增大了异类边界点的特征差异,从而实现边界对比学习的效果。因此,对比学习增强了跨语义边界的特征识别,对于改进边界区域的分割具有重要意义。

(6)
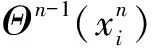
(7)
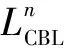
2 实验与结果分析
2.1 数据集
激光雷达(LiDAR) 是利用发射激光束探测目标位置、外形和速度等信息的系统[10]。语义场景理解对于各种应用都非常重要,需要对其附近的表面和物体有细粒度的了解,LiDAR能够提供环境的精确几何信息,是目前主流自动驾驶汽车传感器套件的重要组成部分。本文所采用的三维激光点云场景分割数据集SemanticKITTI正是来自汽车LiDAR的完整360°视野下密集的点云标注,图2展示了该数据集的示例场景。

图2 SemanticKITTI数据集示例Fig.2 Example of SemanticKITTI dataset
SemanticKITTI是用于三维激光点云语义分割的大型户外场景数据集,源自KITTI Vision Odometry Benchmark,使用激光雷达Velodyne-HDLE64 LiDAR进行收集。该数据集由22个序列组成,本文将分割序列00~10作为训练集,11~21作为测试集,分别提供了23201个用于训练的点云和20351个用于测试的点云。另外,如图3所示,该数据集共有25个类,其中6个类是重复的,具有移动或非移动属性。本文将不同移动状态的类合并,并忽略分数很少的类,最后对剩下19个类进行训练和评估。

图3 SemanticKITTI数据集类别示意Fig.3 Schematic diagram of SemanticKITTI dataset categories
在评价准则方面,本文使用交并比(IoU)对各类别三维激光点云场景的分割效果进行评价,并使用平均交并比(mIoU)和每秒处理的帧数(FPS)对分割算法的整体性能进行评估。
2.2 实验设置
本文算法使用基于深度学习的Pytorch框架搭建网络模型,训练和测试均在Ubuntu 20.04系统中进行,采用了Python 3.8环境,12 GiB的NVIDIA RTX2080Ti显卡。在设置训练的相关超参数时,采用Adam优化器作为网络优化方法,对参数进行优化和更新[11]。设置动量值为0.9,初始学习率为0.001,采用指数衰减方法控制学习率变化,Batch size为2,迭代次数为1000。
2.3 对比实验
为了验证提出的基于边界对比学习的三维激光点云场景分割算法的有效性,与PointNet++、SPLATNet[12]、 RangeNet++[13]、 SqueezeSegV3[14]以及Point-Voxel[15]这5种算法进行了对比实验,给出了在19个不同语义类别的点云场景上分割的IoU,得到的实验结果如表1所示;同时,通过mIoU和FPS来评估算法的整体性能,得到的实验结果如表2所示。

表1 不同算法在19个类别点云场景上分割的实验结果
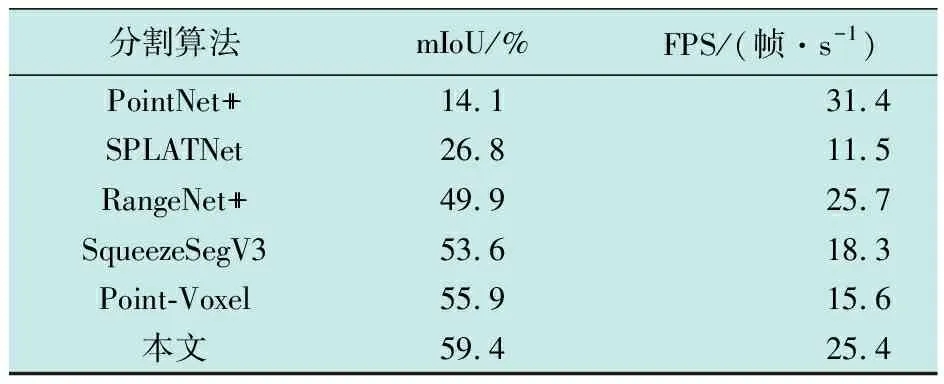
表2 不同算法整体性能的实验结果
从表1的分割结果可看出,在总计19个语义类别中,本文算法在11个类别的点云分割上的IoU达到了最高,5个类别的IoU次高,剩余3个类别的指标也是位列前三,且与最佳性能均非常接近,如 Road和Fence类别的点云,由于其他物体的遮挡,且边界相对难以界定,所以本文算法的指标相较于其他对比算法,没有突出的优势。但是,在一些完整和边界清晰的类别上,如Car、 Truck和Parking等,本文算法的IoU提升十分明显。从表2的实验结果可看出,采用本文算法的精度均明显优于其他几种对比算法,mIoU达到了59.4%,运算效率也较高,FPS达到了25.4 帧/s,在保证较高分割精度的前提下,依然表现出了较高的运算效率,突出了轻量级主干网络PointNet++的优势,从而验证了本文算法整体性能的优越性。
为了直观展示本文算法在边界分割上的提升情况,图4客观地展示了场景1~3的三维激光点云场景分割真实标注与预测结果的对比。
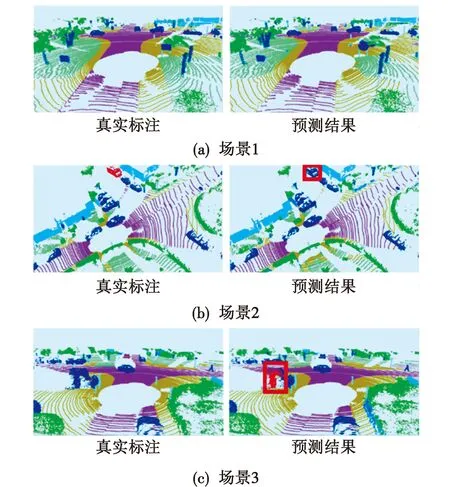
图4 实验结果可视化展示Fig.4 Visualization display of experimental results
由图4可知:场景1是点云分割整体较优的结果,对各个类别的预测以及边界的判断都十分准确,肉眼上观察与真实标注几乎没有差异;场景2的预测结果出现了部分偏差,针对汽车点云的类别预测错误,但从边界上看,汽车整体的轮廓是精确分割的,说明本文算法针对类似完整的对象时,尽管会遇到类别错分,但物体的三维轮廓建模依然准确;场景3的分割效果则不尽如人意,错分物体的边界难以界定,类别也出现了错误,说明本文算法依然存在局限和提升空间,针对场景点云中边界难以界定的对象分割是未来研究的巨大挑战。
2.4 消融实验
为了进一步验证所提边界对比学习框架对三维激光点云分割网络的提升效果,本文做了一组消融实验进行对比,建立了基础分割网络PointNet++与在不同尺度增添边界对比学习的消融模型,从最底层的特征尺度(5次下采样后的子场景三维点云特征,记为S5)逐次向网络最顶层(1次下采样后的子场景三维点云特征,记为S1)添加边界对比学习,得到的消融实验结果如表3所示。

表3 消融实验结果
从表3的结果可看出,随着边界对比学习在不同尺度进行特征加强,网络的整体性能依次提高。在基础的PointNet++网络上添加S5尺度的边界对比学习时,提升幅度最大,但整体指标相较于对比算法仍然没有竞争力,主要是受到分割网络编码和解码的影响,最底层的三维点云子场景特征增强很难对原始的点云空间和预测空间起到决定性作用。因此本文通过在不同尺度进行边界对比学习,对不同语义类别点云的特征进行了充分区分,最终的性能也得到逐步提高,实验结果也与理论分析相符。
3 结束语
针对传统点云场景分割通常忽略边界的问题,本文提出了一种基于边界对比学习的三维激光点云场景分割网络,以PointNet++作为基础主干网络,通过降采样和分组卷积学习场景点云的高层语义特征,再结合跳跃连接进行上采样输出点云的整体分割预测。同时,针对不同尺度的点云特征,引入了边界对比学习算法,以迭代的方式定义子场景的边界点,再利用损失函数进行对比学习,增大不同类点的距离,增强了对场景中不同语义标签对象的边界学习,并提升了网络的分割准确性。通过在大型公开的三维激光点云场景分割数据集上进行实验,得到的实验结果证明了本文算法在点云边界分割上具有更优的分割效果,最后的消融实验也验证了本文算法在性能上有大幅提升。
猜你喜欢
儿童时代·幸福宝宝(2021年11期)2021-12-21
测绘学报(2021年11期)2021-12-09
激光技术(2021年5期)2021-08-17
证券法律评论(2018年0期)2018-08-31
新校长(2016年8期)2016-01-10
商事法论集(2014年1期)2014-06-27
外语学刊(2014年6期)2014-04-18
电脑与电信(2014年6期)2014-03-22
中国中医药现代远程教育(2014年16期)2014-03-01
食品科学(2013年8期)2013-03-11
