
基于YOLOv5s-AntiUAV的反无人机目标检测算法研究
2024-05-09 03:15赵良军郑莉萍
电光与控制 2024年5期
谭 亮, 赵良军, 郑莉萍, 肖 波
(四川轻化工大学计算机科学与工程学院,四川 宜宾 644000)
0 引言
随着无人机(UAV)被广泛应用于城市管理和民生领域,其“滥飞”即“黑飞”已严重威胁公共安全[1],在复杂背景下对不同尺度的无人机进行实时检测是亟待解决的问题。传统技术(如雷达、音频、无线电等)[2-3]难以实时检测无人机特征,而基于深度学习的方法虽可提供多尺度特征提取,但飞行状态下的尺度变化和复杂场景仍造成小尺度无人机检测困难。
王凯等[4]通过改进特征提取网络,融合注意力机制和RFB-S,并使用Focal Loss增强算法的小目标检测能力;张宁等[5]将有效因子与YOLOv4算法的PANet结构融合,用融合因子L-α控制信息传递,改善了特征融合过程中相邻层间不平衡的问题;蒋心璐等[6]提出的Pest-YOLOv5算法提高了农业害虫的小目标检测精度,但在复杂的田间环境下仍有误检和漏检情况发生;张上等[7]提出的LUSS-YOLO算法可通过网络重构和使用VariFocal Loss提高小目标的检测精度,但漏检率仍然较高;董亚盼等[8]提出的注意力机制和张浩然等[9]提出的数据增强方法虽在特定场景提高了检测精度和速度,但对其他场景适用性不强。
因此,为解决复杂飞行场景中无人机尺度变化引起的小目标检测难题,本文选用了先进的目标检测算法YOLOv5s,并进行3项改进:引入结合深度超参数卷积的Slim-Neck[10]范式,以平衡模型检测准确性和推理速度;引入SPD-Conv[11]模块,增强模型在低分辨率图像中小物体的检测性能;优化损失函数,使用Alpha-CIoU Loss[12]替换CIoU Loss,提升模型在小目标数据集上的泛用性。
1 设计反无人机目标检测算法
1.1 引入结合深度超参数卷积的Slim-Neck范式
为了在检测侵入式无人机时平衡检测模型的准确性和速度,本文在YOLOv5s算法的颈部网络引入文献[10]提出的Slim-Neck新范式,并将部分普通卷积替换为超参数化深度卷积DO-Conv模块,这种结合更好地平衡了模型的准确性和推理速度,同时降低了模型的复杂度,实现了更高的计算效益。传统的CNN为提高检测速度,需要逐步传递空间信息到通道,但压缩空间和通道数的扩展会导致部分语义丢失;而Slim-Neck范式中的轻量级卷积GSConv以较低的时间复杂度保留了每个通道之间的隐藏连接,时间复杂度表示为
(1)
式中:O为时间复杂度;W、H分别为输出特征图的宽度和高度;U1·U2为卷积核的大小;C1为每个卷积核和输入特征图的通道数;C2为输出特征图的通道数。
GSConv模块结构如图1所示。
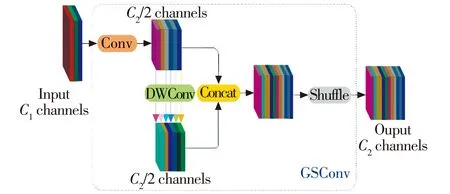
图1 GSConv 模块结构示意图Fig.1 GSConv module structure
由图1可知,先将C1通道的输入经过普通卷积Conv转化为C2通道,并进行深度卷积DWConv后用Concat和Shuffle操作将2个卷积结果对应通道拼接起来。GSConv通过统一交换通道的策略,无需额外信息便降低了计算复杂度。基于GSConv模块,通过一次性聚合的方法设计了跨阶段部分网络模块VoVGSCSP,简化了结构并提升了推理速度。
YOLOv5s-AntiUAV网络模型结构如图2所示,组合GSConv、VoVGSCSP和DO-Conv模块,形成了适用于本文改进算法的颈部网络范式。

图2 YOLOv5s-AntiUAV网络模型结构Fig.2 Architecture of YOLOv5s-AntiUAV network
图2中:L1~L30 代表YOLOv5s-AntiUAV算法结构的层数;Conv表示卷积;k为卷积核的尺寸大小;s为卷积核在输入特征图上滑动的步长大小;p是在输入特征图的边缘周围添加额外的像素值大小;C3*3表示卷积核的大小为3×3,C3*3 False表示在卷积操作中没有使用填充,C3结构见图1;n×Bottleneck 代表有n个Bottleneck模块;Conv2d是一个二维卷积操作;SPD-Conv表示文献[11,13]提出的用于低分辨率图像和小物体新CNN构建块;Detect表示检测端;MaxPool2d指池化操作,减小特征图的尺寸;if true表示条件为真,则通过 ShortCut操作,将输入特征和输出特征之间通过跳跃连接直接相加。
为了提升YOLOv5s-AntiUAV网络性能和表达能力,本文在范式中将普通卷积替换为超参数化的深度卷积DO-Conv模块,以增强特征提取能力。DO-Conv模块通过使用额外的可学习参数扩展了卷积运算的表达能力,与传统卷积不同,它使输出特征的某个通道仅受限于输入特征的一个通道和相应的权重,而不受其他输入通道影响。深度卷积则独立应用于单个输入通道,保持较低的计算成本,同时捕获通道的空间信息,生成中间特征图,其运算过程见图3。
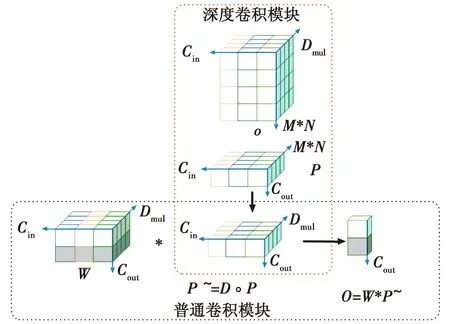
图3 深度超参数卷积运算过程Fig.3 Deep hyperparameter convolution operation process
图3中,深度卷积算子∘首先被应用于深度卷积内核D和输入特征P,生成转换后的特征P~=D∘P。接下来,常规卷积运算符*被应用于常规卷积内核W和中间变量P~,生成转换后的特征Ο=W*P~。因此,深度超参数化卷积的输出可以表示为Ο=W*(D∘P)。M和N为输入向量的空间维度,Cin为输入向量的通道数,Cout为输出的通道数,Dmul=M*N,表示深度卷积的感受视野。然而,使用传统卷积作用于输入特征P的M*N区域,卷积核的数量Cout*(M*N)*Cin。在DO-Conv中,分别使用了2个权重D∈R(M*N)*Dmul*Cin和W∈RCout*Dmul*Cin,且Dmul≥M*N,所以DO-Conv中的权重参数比传统卷积参数多(M*N)*Dmul*Cin,故其能够更好地实现特征提取,同时保持计算效率。
1.2 引入SPD-Conv模块
高分辨率图像因含有丰富细节,能够在CNN中跳过一些操作而仍学到有效特征。然而,对于检测小目标或模糊图像等复杂任务,现有CNN构建块面临着丢失细节和无法学到有效特征的挑战。跨步卷积和池化卷积在处理这些复杂任务时可能会丢失重要细节信息,影响模型性能。对于小物体或模糊图像,直接跳过操作会导致关键细节丢失,使模型难以准确学习到关键特征,影响任务表现。
为解决上述问题,本文借鉴了文献[11,13]提出的新CNN构建块SPD-Conv,用于低分辨率图像和小物体,替代了原有的YOLOv5s算法的跨步卷积层和池化层。为了优化YOLOv5算法的CBS卷积层,本文在普通卷积Conv(k=3,s=1)和深度超参数卷积DO-Conv(k=3,s=1)后结合了SPD-Conv模块,结构如图4所示。
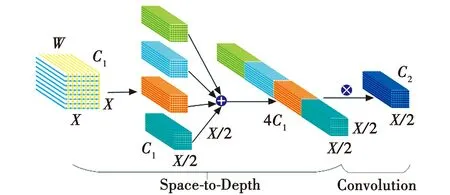
图4 SPD-Conv模块结构Fig.4 SPD-Conv module structure
文献[11]将SPD-Conv中Space-to-Depth模块的步长设置为1,有效避免了跨步卷积和池化造成的信息丢失,增强了模型在低分辨率图像中小物体的检测性能,因此更适用于侵入式无人机的检测。再使用步长为1的Convolution卷积加强模型在细粒度特征上的保留能力,避免因卷积步数的大小而导致的特征信息丢失。

如图4所示,输入原始特征图W,每个特征图按比例因子l对W进行下采样,再将这些特征子图根据通道维度进行连接,得到特征图W~,W~与W相比,前者比后者在空间维度上少了一个比例因子,而在通道维度上增加了2个比例因子,然后在Space-to-Depth模块之后增加一个步长为1结合了C2滤波器的卷积层,对特征图W~进行进一步变换。
1.3 损失函数优化
在对飞行中的无人机进行检测时,常常受到树木、建筑物和飞鸟等物体的遮挡,同时,无人机尺度的变化也会影响精确检测。YOLOv5s算法采用CIoU Loss作为损失函数,是在DIoU Loss的基础上增加了回归框长宽的损失,使预测框更加接近真实框。然而,针对小目标,CIoU Loss在目标框上计算的重叠区域相对较小,导致CIoU Loss值较小,进而影响模型对小目标的学习能力。其次,因CIoU Loss考虑了目标框中心点距离,所以,中心点回归误差可能较大,影响对目标的定位。同时,对于小目标,规范化项相对较大,造成损失值偏大,进而影响模型学习和收敛速度。
针对上述问题,本文引入Alpha-CIoU Loss来替换YOLOv5s中的CIoU Loss。Alpha-CIoU Loss在CIoU Loss的基础上引入了超参数α,以平衡目标框重叠部分和非重叠部分。通过调整α值,增强了小目标的重要性,提高了对小目标的学习能力,从而改善了小目标的检测性能。Alpha-CIoU Loss的引入使得模型更加稳健和灵活,可调整目标框重叠和非重叠部分的重要性。此外,该损失函数考虑了目标框中心点距离和宽高差异,通过调整参数,能够更精确地定位目标,特别对小目标定位更为重要,提高了模型的定位准确性。Alpha-CIoU Loss在实验中证明不会增加训练推理时间,反而能够提高模型在目标数据集上的鲁棒性,优于其他损失函数,其算式为
(2)
式中,β和ν分别表示为
(3)
(4)
式中:RIoU表示真实边界框和预测边界框之间的交叉比例;b为预测边界框的中心点;bgt为真实边界框的中心点;欧氏距离ρ(·)表示了两个边界框中心点之间的最小闭合盒子的对角线长度;π为圆周率;wgt、hgt分别为真实边界框的宽度和高度;w、h分别为预测边界框的宽度和高度。
2 实验结果及分析
2.1 数据集的建立
本文的实验数据集Anti-UAV由自建数据集Our-Anti-UAV的1732幅图像和公开数据集DUT-Anti-UAV[14]的6000幅图像组成。
其中,Our-Anti-UAV数据集融合步骤如图5所示。

图5 Our-Anti-UAV数据集融合步骤示意图Fig.5 Schematic diagram of fusion steps of Our-Anti-UAV dataset
首先,从公开的无人机“黑飞”视频中人工截取无人机影像的原始数据,统一裁剪成大小为64像素×64像素的图像,然后用PyTorch框架进行数据预处理生成HDF5文件。随后,100维噪声输入到生成式对抗网络[15]的生成网络中,并将HDF5文件读取到判别网络中进行判别。若判别网络认为数据是伪造的,则进行反向传播,动态调整生成网络和判别网络参数,直到生成网络生成的图像被判定为真实,判别网络能准确识别生成器生成的图像为伪造。训练好的模型参数保存后,用其生成无人机图像,结果如图6(a)所示。最后,使用泊松融合算法将生成的无人机图像与不同背景图像随机融合。融合后的数据使用Labelimg软件标注,并与部分DUT-Anti-UAV数据集合并,部分图像示例见图6(b)。最终形成的Anti-UAV数据集图像共7732幅,以7∶3的比例随机分为训练集和验证集。

图6 Anti-UAV数据集部分图像示例Fig.6 Image examples from the Anti-UAV dataset
由COCO数据集划分目标检测的大中小目标定义可得:小于32像素×32像素为小目标,介于32像素×32像素和96像素×96像素之间为中等目标,大于96像素×96像素为大目标。同时,本文设置高、低分辨率图像阈值为720像素×640像素。大于720像素×640像素为高分辨图像,反之则为低分辨率图像。分析Anti-Drone数据集的目标尺寸分类和高、低分辨率图像分类情况如图7所示。
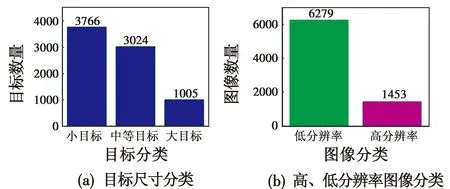
图7 Anti-UAV数据集分析Fig.7 Analysis of the Anti-UAV dataset
从图7可以看出,本文实验数据集,低分辨率下的小目标无人机占比最大,符合低分辨率小目标实验要求。
2.2 实验环境分析
本文的实验环境平台为自主配置服务器,使用64位Windows10操作系统,处理器为Intel®CoreTMi7-8700K CPU@3.70 GHz,32 GiB运行内存,NVIDIA GeForce RTX 2080Ti GPU,12 GiB显存。在Pycharm里用Python编写代码,并调用OpenCV-Python、Torch、Pandas等第三方所需库,进行模型的训练和检测,所构建的网络模型均基于PyTorch深度学习框架,开发环境为PyTorch 1.12.1、CUDA 11.3、Python3.8。
2.3 实验评价指标
实验以检测速度(FPS)、精确率(P)、召回率(R)、平均精确率(AP)、平均精确率均值(mAP)作为模型定量评价指标来衡量模型检测的准确性,其定义本文不再赘述。
2.4 消融实验
为了评估本文提出算法的性能,通过增减优化模块验证各模块对算法性能的影响。表1为消融实验结果,其中,将基线算法YOLOv5s标记为O,引入SPD-Conv模块记为Ⅰ,优化损失函数记为Ⅱ,结合深度超参数化的Slim-Neck范式记为Ⅲ。A~G分别代表引入Ⅰ、Ⅱ、Ⅲ后形成的新算法。
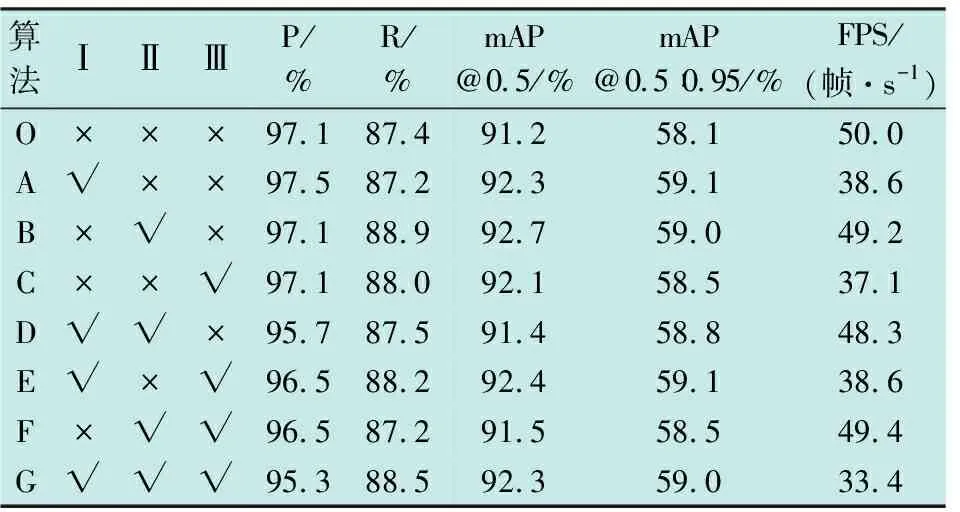
表1 消融实验结果
由表1可知,尽管组合后的算法在检测速度上略低于基线算法,但在mAP上均高于YOLOv5s。因此,每个优化模块都对检测无人机产生了积极影响。
2.5 与经典算法进行对比实验
为验证本文的YOLOv5s-AntiUAV算法在侵入式无人机检测方面的先进性,与其他经典目标检测算法进行了对比实验。使用参数量、FPS和mAP@0.5这3项性能指标进行对比,结果见表2。
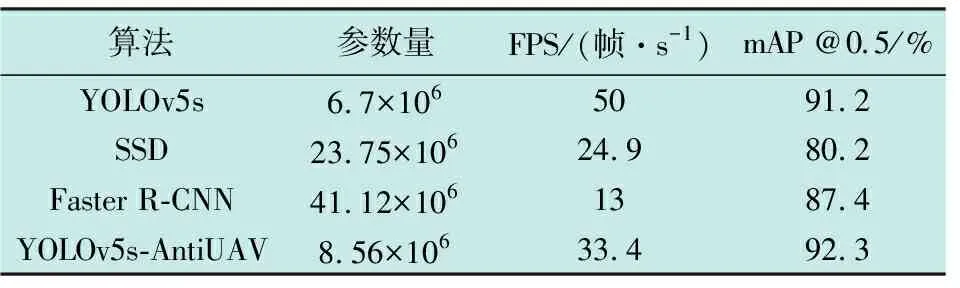
表2 对比实验
由表2可知,在Anti-UAV数据集上,改进后的算法相对于SSD和Faster R-CNN算法,在参数量上分别减少了15.19×106和32.56×106;FPS达到了33.4 帧/s。与YOLOv5s算法相比,改进后的算法参数量增加了1.86×106,FPS降低了16.6 帧/s。综合对比发现,改进算法的 mAP@0.5相较于原YOLOv5s算法、SSD和Faster R-CNN分别增长了1.1、12.1和4.9个百分点,因此,本文提出的改进算法在mAP@0.5评价指标上具有最高精度,并满足实时性需求。图8展示了4种算法在低分辨率场景下对小目标的检测结果。

图8 不同算法的检测结果Fig.8 Detection results of different algorithms
由图8可知,在干扰背景下,本文改进算法对目标的置信度高于其他算法,再次验证了本文算法的有效性。
2.6 损失函数分析
为验证损失函数Alpha_CIoU模块对网络的有效性,将其替换为SIoU[16]、WIoU[17]和Focal_EIoU进行效果对比,对比结果见表3。

表3 损失函数分析
从表3中可以看出,损失函数SIoU、WIoU、Focal_EIoU的P值均低于损失函数CIoU,并且这3种损失函数的mAP效果不如损失函数CIoU。然而,Alpha_CIoU损失函数在所有评价指标上都优于上述4种损失函数,表明在无人机检测中其性能更出色。
2.7 迁移实验
本文使用VisDrone2019[18]数据集来验证算法的广泛性和可迁移性。在经过300轮训练后,本文改进算法和YOLOv5s算法在VisDrone2019数据集上的mAP@0.5对比结果如表4所示。

表4 迁移实验
由表4可以看出,改进算法相较于YOLOv5s算法,mAP@0.5值提升了4.5个百分点,且改进后的算法对于数据集的每一个类别的AP值均高于基线算法,验证了本文改进算法在小目标检测领域的泛用性,两种算法的检测结果示例见图9。

图9 迁移实验图像检测对比Fig.9 Comparison of image detection in ransfer learning experiments
3 结束语
通过分析传统的反无人机检测方法的特点,并为解决侵入式无人机小目标错检和漏检问题,基于YOLOv5s算法进行改进。通过引入Slim-Neck范式增强特征提取能力并保持计算效率;在网络的骨干和颈部部分引入SPD-Conv模块,减少特征信息丢失,提升在低分辨率图像中小目标的检测性能;另外,优化损失函数以增强算法的鲁棒性。本文提出的YOLOv5s-AntiUAV算法在自建数据集上mAP@0.5达到了92.3%,满足实时检测需求,表明其有效性。在VisDrone2019数据集上的迁移实验结果显示,本文算法对于复杂背景下的小目标检测效果更佳,具有广泛适用性。
猜你喜欢
艺术家(2023年8期)2023-11-02
红外技术(2022年11期)2022-11-25
电子产品世界(2022年9期)2022-05-30
小哥白尼(军事科学)(2022年2期)2022-05-25
北京航空航天大学学报(2021年9期)2021-11-02
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
艺术科技(2018年2期)2018-07-23
北京航空航天大学学报(2018年1期)2018-04-20
CHIP新电脑(2016年3期)2016-03-10
