
试验环境水下声信号的特征提取方法
2024-05-08 07:41王红滨王永乐何鸣薛垚
哈尔滨工程大学学报 2024年3期
王红滨, 王永乐, 何鸣, 薛垚
(1.哈尔滨工程大学 计算机科学与技术学院, 黑龙江 哈尔滨 150001; 2.电子政务建模仿真国家工程实验室, 黑龙江 哈尔滨 150001)
水下声音信号预处理技术隶属于水声学领域,随着我国军事需求的不断攀升,其重要性也随之提高。然而,水下检测设备接收到的原始信号混入了环境噪声、机械噪声、螺旋桨噪声、水动力噪声等,再加上目前水下生态环境的复杂性,这些都给声音预处理工作带来了很大的困难。听觉感知机制和听觉模型对水下辐射噪声处理工作有着较多贡献。在听觉机制下,声信号的主观描述特征很容易区分,但这与舰船目标类型和声源特征之间的关系还有待研究,所采用的算法也需要大量试验的支持。对于水下目标的辐射噪声特性有许多研究。KIM等[1]运用短时傅里叶变换表示低频音调向量,结合压缩感知技术检测水下目标辐射噪声,达到了良好的试验效果。董博文等[2]以复杂海洋环境中的舰船与水下航行器结构的声辐射、声传播研究作为基本出发点,通过数值仿真方法,分析水下噪声特性。对于水下试验环境反演方法的研究也有许多,Munk等[3]对射线模型在海水中声传播的时间展开研究,将该时间作为传播准确参量。Voronovich等[4-5]将海洋声层析与绝热简正波理论紧密结合,并据此形成简正波的传播时间与相位和水平折射等多种方法。Skarsouli[6]则另辟蹊径,利用接收信号到达的峰值抵达时间和声速二者之间形成的扰动实现反演。刘福臣等[7]为了解决未知环境下声速剖面表示的局限性,通过利用不同参数的多项式拟合计算和模信号反演相结合的方式,来对声速剖面进行反演。Bonnel 等[8]为了处理分解在浅水传播的频率低于500 Hz的低频瞬态信号,提出了一种非线性的,基于物理的信号处理方法。窦雨芮等[9]通过运用简正波方法,研究不同声速剖面对声传播最佳深度的影响。
目前,随着深度学习的发展,各种对深度学习在音频领域的相关研究也在不断开展。Latif等[10]使用深度学习进行心音异常心跳检测。Mohammed 等[11]用卷积神经网络模型实现语音病理学的检测和分类。Hemavathy等[12]提出了一种基于深度学习的DL-HDBT(deep learning-based hybrid dynamic biased track)方法,用来在水声传感器网络中识别网络的最佳中继节点及跟踪拥堵的节点。Shiliang等[13]总结了水声信号的特征分析和提取方法、常用的水声目标分类方法以及识别方法。罗夏云等[14]使用MFCC处理船舶水下噪声信号,将水声信号转换为MFCC特征向量。Tran等[15]提出了一种通过梅尔频谱图和尺度图提取丰富的声信号特征方法,并结合机器学习分类器对钻孔机的钻孔故障声音进行分类。陈文青[16]通过试验发现线性预测倒谱系数(linear predictive cepstral coefficient, LPCC)也是一种很好的研究信号时域特征的方法。曾赛等[17]利用水下目标多模态深度学习分类识别法来完成水声探测的分类任务。
目前,水下目标声信号的研究需要借助水下探测设备。设备接收到的原始信号是低信噪比信号,这些信号混入了环境噪声,需要对这些信号进行特征提取工作,使提取出的特征更加准确的反映出信号的特点。本文提出了基于梅尔频谱倒谱系数(mel-frequency cepstral coefficient,MFCC)及线性预测编码(linear predictive coding, LPC)的特征加权组合的特征提取方法,在保留水下声信号特性的同时极大地发挥了不同特征处理方法的优势。
1 特征加权组合方法模型架构
LPC特征表示方法和MFCC特征表示方法可以进行水下声信号的特征提取。LPC特征表示方法具有计算量小、易于实现的优点,但其缺点是抗噪声性能差。MFCC特征表示方法则能够较好地反映出人耳的听觉特性,在抗噪性方面要优于LPC特征表示方法,但是其计算精度的要求要高于LPC特征表示方法。另外,在MFCC处理高频声音的时候,其精度会比没有处理低频声音精准。
基于以上2种方法的优缺点,本文提出了特征加权组合表示方法,水下声信号同时用2个方法进行处理,其中一个信号经过预加重、分帧、加窗、快速傅里叶变换(fast fourier transform, FFT)、梅尔滤波器组的处理后得到MFCC特征表示,同样的信号再经过预加重、功率谱、临界带分析、自回归模型处理后得到LPC特征表示。对2种矩阵使用特征加权组合方法进行处理得到新的特征矩阵。然后把提取出的特征矩阵使用映射插值算法映射为行列大小相同的矩阵。特征加权组合方法的总体处理过程如图1所示。
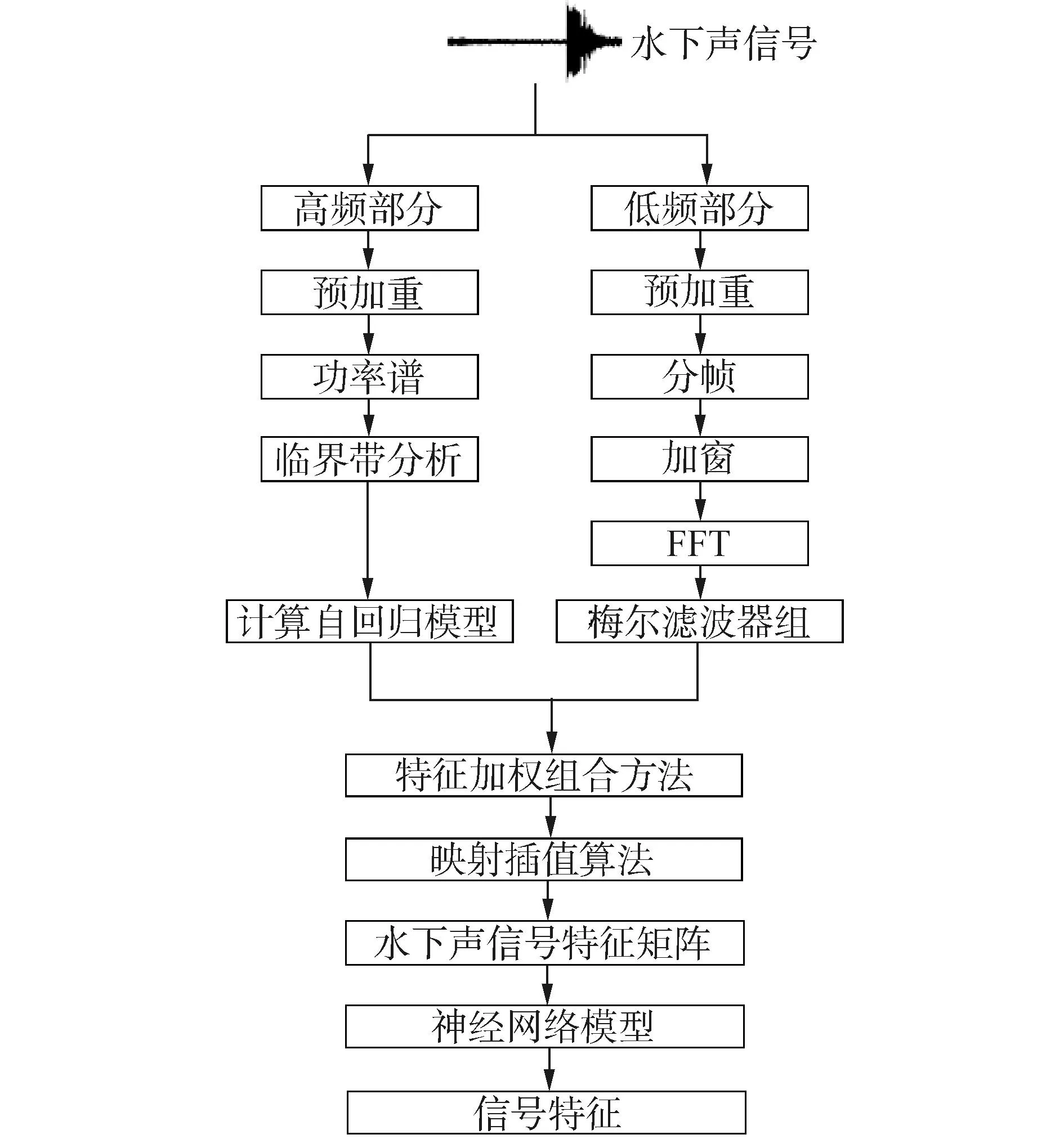
图1 特征加权组合方法Fig.1 Combination of weighted feature method
1.1 MFCC+LPC的特征加权组合
LPC是基于线性预测理论的声音识别特征参数之一。计算音频信号的LPC的过程可以理解为求音频信号的P阶线性预测的过程,ai为预测系数,s(n)为s(n-i)的估算值。其中心思想是对过去P个时刻音频信号的采样值进行线性组合去逼近下一时刻的采样值。评判的标准就是预测误差,即下一时刻的具体采样值取决于当前的预测误差是否已经达到了极小值,如果达到了极小值,则下一刻的采样值就可以用此时的预测值来代替,具体计算公式为:
(1)
线性频率f与M频率之间的转换公式为:
M(f)=2 595lg(1+f/700)
(2)
式中:M代表梅尔(Mel)频率;频率f的单位是1 Hz,代表M频率与以Hz为单位的实际物理频率之间的参考点。将频率转换到Mel域后,可以根据特定频带中的临界带宽设计一个中心频率在Mel频域上同样呈线性分布、通带之间具有重叠部分的三角形带通滤波器。由于这个带通滤波器的中心频率在物理频域中是非线性的,因此它可以用来模拟人类耳蜗基底膜对实际物理频率的非线性感知。假如将带通滤波器组的中心频率按Mel频率刻度均匀分布,音频信号的特征就可以被理解为带通滤波器组中各个滤波器所释放的信号能量,使用该特征再经过进一步计算,就可以将其转化为后续声音特征提取的输入特征。对于其中的每个滤波器,在Mel频率范围内,具有相同的带宽。三角滤波器组的作用是让通过它们的声音信号能够去除掉关于谐波的干扰,变得更加平滑,同时,还对水下声音信号中的共振峰有着突出显示的作用。
本文对声压数据特征提取后,根据MFCC及LPC的不同权重,设计了若干试验,利用各个特征处理方法的优缺点,探索出最适合目标环境的权重值,将权重值与经归一化处理后的特征矩阵相乘,以达到对特征加权的目的。并将最终确定的MFCC及LPC所占的比例用于接下来的试验中。本文还发现,不同阶数的取值对特征提取也具有一定的影响,当取较小的阶数值时,两者的融合效果较好。本文的试验中MFCC及LPC的阶数选取为1,通常声音数据的阶数默认选取为13,但由于处理声音的特殊性,本文对阶数进行了调整,也可以根据不同的环境采取不同的阶数值。同时,采样率选取为1 MHz。该值与录制水声信号时的值一致。
1.2 映射插值算法
现有的卷积神经网络结构对输入为固定大小的图像向量有着非常好的处理效果。受此启发,假设把音频特征向量映射成最适合该网络输入的大小,那么在进行模型训练的时候也会得到更高的准确率。MFCC表示的特征矩阵为A,LPC表示的特征矩阵为B,由于它们的计算方式不同,所以A和B的2个维度并不相同。经过维度统一后,A和B连接成了一个维度不均匀的特征矩阵。为了解决维度均匀的问题,本文使用了映射插值算法,该算法的目的是把A和B组成的特征矩阵统一映射为行数和列数都相同且矩阵中的元素均为0~255。
具体映射的方法如下:分别对MFCC方法表示的特征矩阵和LPC方法表示的特征矩阵进行放缩,设放缩前的MFCC方法表示的特征矩阵为M,M经坐标映射后变为M′,放缩前的LPC方法表示的特征矩阵为L,L经坐标映射后变为L′。m为映射后矩阵的长度,n为其宽度,具体为:
(3)
(4)

2 试验结果与分析
2.1 数据集与试验设置
本文中使用的是对河口水库数据集,该数据集是2021年5月27日实验室在浙江省德清县对河口水库录制的音频数据。本文用到的样本数约56 643条,按照0.15的划分比例,其中训练集样本数约48 146条,测试集样本数约8 496条数据,每条数据时长约为100 ms。
脉冲信号不仅是主动式水声跟踪及水声通信系统的常用信号形式,也是鱼雷声自导信号的基本形式[18]。本文选取2种常用的脉冲信号类型,分别是单频矩形脉冲信号(continuous wave, CW)及线性调频信号(linear frequency modulation, LFM)。CW信号有CW90K、CW100K、CW110K 3种。LFM信号有LFM 80-90k、LFM 90-100k、LFM100-110k 3种。所有信号的脉冲宽度均为10 ms,脉冲周期为100 ms。
图2为数据集中选取的1条CW及1条LFM信号的时域图、频谱图及时频谱图,可以从频谱图中直观地看到较亮的部分为水声换能器发射的信号。

图2 LFM90-100k的图形Fig.2 LFM90-100k′s waveform
录制水下声信号的具体试验步骤如下:
1)母船在发射端深度x(取值1、3、5、7、9 m)处布放CTD(conductivity temperature depth)测量仪及水声换能器,CTD仪会记录深度及时间信息等。水声换能器发射CW及LFM作为信号源。
2)目标船开出距母船150 m处,并在水深y处布放水听器,水听器是将接收到的声信号转换成电信号的换能器。
3)母船发射3种LFM及3种CW信号。
4)目标船接收声信号,并将数据存储到计算机中。
5)循环以上步骤直到遍历完所有的发射端深度及发射信号类型。
试验具体态势图如图3所示。

图3 试验数据采集态势Fig.3 Experimental data collection scheme
2.2 模型选择
本文试验所采用的模型为ResNet18,该模型由8个残差块组成,每个残差块有2个卷积层,加上1个开始的卷积层共有17个卷积层。网络末尾处有一个全连接层,组成了18层网络,也是模型名称的由来。本文使用了ResNet18模型预训练参数,对网络的输入及输出等全连接层进行了调整,以满足本文的样本输入要求。
2.3 特征加权组合权重选择试验
本文对声压数据进行特征提取后,根据MFCC及LPC的不同权重比例,设计了若干试验。MFCC占比分别为0.9、0.8、0.7、0.6、0.5、0.4、0.3、0.2、0.1,与其对应的LPC占比分别为0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9,共9组配比方案。
本文按照权重方案对CW110k在不同深度下录制的信号进行分类,9组试验的10轮模型拟合情况如图4所示。其中,图例中的m1l9代表MFCC占比0.1,LPC占比0.9,其他的标识以此类推。折线图中横坐标为10轮训练的索引,纵坐标为测试集准确率。

图4 不同特征加权组合方法的试验比较Fig.4 Comparation of different combination method of weighted features
从图4可以看出权重组合m1l9训练准确率在第6轮次达到了最大值,且10轮次大多数的准确率都高于其他折线。本文接下来的试验选取的也是该组权重组合。从权重的选择来看,LPC方法更加适合处理本文试验环境下的水声数据,LPC在语音领域中能高效地提取声道特性,语音参数的估计较为准确,当应用到水声数据时也展现了它的优势。权重值的选取是动态的,可根据不同的环境特性进行选择。但如果单独使用LPC而不使用MFCC效果反而不好,试验结果说明两者结合才能达到更好的特征提取能力。
2.4 特征提取试验结果比较
特征加权组合方法主要试验流程如下:
1)将水下声音信号使用MFCC方法进预处理后输入ResNet网络进行分类试验。
2)将水下声音信号使用LPC方法进预处理后输入ResNet网络进行分类试验。
3)对水下声音信号采用端到端的方式输入ResNet网络进行分类试验。
4)使用特征加权组合方法对声音信号预处理,然后输入到ResNet网络中进行分类试验,
5)比较1)~4)分类的准确率。
试验结果如下,其中环境1为14∶45—16∶28录制的数据,环境2为19∶03—18∶16录制的数据,基线(Base)代表声音信号未做任何特征提取操作。
从表1可以看出MFCC+LPC特征权重组合方法对由CW组成的水下声信号特征的提取质量有提升。对于CW90k环境分类准确率最低提升1.85%,最高提升2.13%。对于CW100k环境分类准确率最低提升1.42%,最高提升2.76%。对于CW110k环境分类准确率最低提升0.42%,最高提升3.42%。综合来看,CW平均提升2%。

表1 不同深度的CW信号的试验比较Table 1 comparison of CW signals at different depths %
从表2可以看出MFCC+LPC特征权重组合方法对由CW组成的水下声信号特征的提取质量有提升。对于信号LFM80~90 kHz,环境分类准确率最低提升2.82%,最高提升2.95%。对于信号LFM90~100 kHz,环境分类准确率最低提升1.95%,最高提升2.66%。对于信号LFM100~110 kHz,环境分类准确率最低提升0.14%,最高提升1.68%。综合来看,LFM信号平均提升2.03%。

表2 不同深度的LFM信号的试验比较Table 2 comparison of LFM signals at different depths %
综合表1及表2,本文提取的方法可以更好地描述水下声信号的特征。两者的特征加权组合方法是有效的。本文还发现LFM信号环境分类准确率要高于CW信号环境分类准确率,具体如图5所示,横坐标为10轮训练的索引,纵坐标为测试集准确率。图5中拟合程度最好的3条曲线均为LFM信号。说明LFM信号提取的特征更适合处理深度分类任务,这也与LFM的特性有关。CW为测距脉冲,LFM为测深脉冲,更加适合反映目标的深度信息。

图5 LFM及CW特征提取试验比较Fig.5 Comparation of LFM and CW′s feature detection
3 结论
1) 为了解决维度均匀的问题,本文使用了映射插值算法,该算法的目的是把MFCC及LPC组成统一的特征矩阵。
2)本文选取了比较典型的单频及调频信号对特征提取方法进行验证,特征提取的是否精准无法进行客观评判,所以借助深度及环境分类试验进行验证。本文利用ResNet18微调模型对水下声信号进行分析时,发现特征加权组合方法的操作是有必要的。它可以更好地对时频谱中的有效特征进行描述,而过滤掉噪声信号。
3)本文还进行了消融试验,提出的特征提取方法普遍好于仅使用MFCC或LPC的特征处理方法。CW做深度分类任务时的准确率平均提升2%,LFM做深度分类任务时的准确率平均提升2.03%。试验结果表明方法是可做进一步推广的。
4)本文提出的特征提取方法对LFM信号在深度分类任务下处理的结果要好于CW信号处理的结果。再次说明了LFM要比CW更适合做深度分类任务。还可以在此基础上做进一步研究,提升CW的特征提取能力。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2018年19期)2018-11-14
中国交通信息化(2018年5期)2018-08-21
自动化学报(2017年11期)2017-04-04
电子制作(2017年22期)2017-02-02
电子制作(2017年19期)2017-02-02
系统工程与电子技术(2016年7期)2016-08-21
噪声与振动控制(2015年4期)2015-01-01
