
基于多重特征提取的DNN窃电检测方法
2024-05-07 09:40赵艳龙汪卓俊杨勇胜章建华刘一民
电气技术与经济 2024年4期
赵艳龙 汪卓俊 杨勇胜 章建华 蒋 钟 刘一民
(1.国网浙江省电力有限公司安吉县供电公司 2.国网浙江省电力有限公司湖州供电公司)
0 引言
电网的损失主要分为技术损失和非技术损失[1]。电阻损耗、变压器损耗和老化损耗等是造成技术损失的原因,该损失难以解决[2];而窃电则是造成电网非技术损失的主要原因。随着用户的窃电方式从早期修改电表结构、私自连接电线到篡改智能电表数据[3]。窃电手段越来越智能化和多样化,检测窃电用户的难度也越来越大[4]。
2017年美国因为窃电造成的损失已达100亿美元[5]。中国国家电网也在过去追回了近130亿元的窃电资金。随着AMⅠ的应用与普及,用电信息数据呈爆炸式增长[6]。通过挖掘、分析和有效利用这些海量数据来检测窃电是当前研究的热点[7,8],同时对保证电网的供电质量和效率具有重要意义[9]。
阙华坤等人搭建了基于随机森林的窃电检测模型,并以南方电网数据作为输入,验证了模型的检测效果,但是没有用合理的指标加以说明模型的性能[10]。黄刚等人提出了一种基于多层次非负稀疏编码的窃电检测方法,用爱尔兰数据集验证了其准确率[11]。但该方法的窃电用户需要以月度单位的连续数据作为证据才能识别,当电表故障时存在用电量记录缺失,该情况会使得窃电检测效率降低。
为了实现在线窃电检测,本文提出了基于多重特征提取的DNN窃电行为检测方法。首先,采用主成分分析法(PCA)对经过预处理和不平衡处理的数据进行特征初步提取,得到初始的基本特征量。然后,将用户的用电曲线分离为背景曲线和过滤曲线,分别对两条曲线进行特征值再提取。最后,利用深度学习网络(DNN)构建窃电检测模型,实现对窃电用户的检测。
1 模型结构与主要单元
1.1 数据集介绍
本文采用国家电网发布的数据集(SGCC)进行实验[12]。该数据集包含了2014年1月1日至2016年10月31日的42372个客户每日的用电量记录如表1所示。

表1 国家电网数据集
该数据集一共有近420万条数据,足够用以搭建与验证模型。但是,该数据集存在两种问题。首先,数据集中存在大量的缺失值。其次,正常用户和窃电用户的比例为10.72,这种数据分布会导致窃电模型的分析出现数据不平衡问题。
数据不平衡会导致模型更倾向于更多地学习多数类的特征,导致错误将少数类样本预测为多数类,从而产生较高的假阴性率。通常当多数样本大于少数样本的10倍时会导致模型在窃电检测方面的准确率下降,因为它更容易将真正的窃电行为样本错误地分类为非窃电行为。
1.2 数据集介绍
针对不同用户的数据缺失情况拟定不同的处理办法。当某位用户的用电数据缺失数量过多时,无论采用何种插值法去补充缺失部分,都会使得数据的不稳定性和偏差性影响窃电检测模型的效果。因此在处理缺失值的过程中,设定一个30%的阈值,当缺失值占比超过该用户的30%时,将此样本舍弃。在对所有样本进行筛选后,剩余数据的分布如表2所示。

表2 缺失值过滤后的数据集
在时间序列的用电量数据中,采用线性插值法来填充缺失值占比少于30%的用户样本,其公式如下:
式中,x0、y0和x1和y1是距离缺失值最近的数据点。经过线性插值法处理前后的某用户日功率曲线如图1(а)和图1(b)所示。
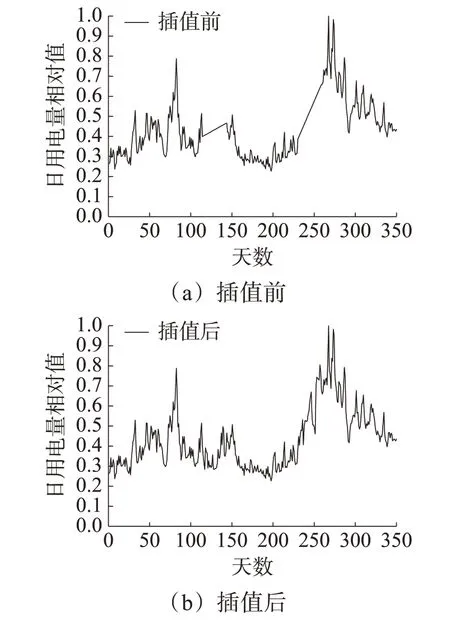
图1 某用户功率曲线图
1.3 数据不平衡问题
文献[13]介绍了六种用于合成窃电样本数据的函数,分别是式(2)-式(7)。我们采用这些函数结合SGCC正常用户数据来生成窃电用户数据,目的是为了平衡数据集并创建更实用和真实的异常用电消费模式。
具体而言,y1函数将每日实际用电量乘以0.1到0.9之间的随机数值,这个处理效果类似于电磁干扰窃电导致的情况。y2函数则将一段时间的实际用电量乘以0.1到0.9之间的随机数,反映用户采取欠压窃电和欠流窃电所导致的结果。y3函数代表了用户不连续的窃电行为。而后三种函数则模拟了针对于数据漏洞的窃电行为。在y4和y5函数中,窃电者在电表数据传输过程中结合平均用电量,在不易察觉的情况下修改上报读数。而y6函数则通过相反的顺序发送用电读数,目的是保证高电量消耗发生在低价时间段。以某用户一周用电曲线来展示不同函数合成的数据效果,如图2所示。
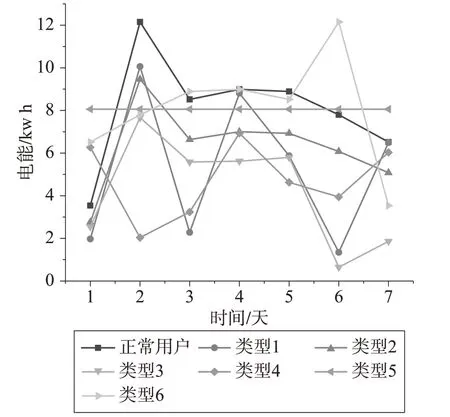
图2 合成效果对比
我们在SGCC缺失值处理后的25932名正常用户中,随机抽取了6000名用户,并将其分为六组。每组分别采用上述函数来合成窃电样本。在最终用于后续模型训练的数据中,正常样本数为19932,窃电样本数为8063,比例为2.472比1,这有效解决了数据不平衡的问题。
由于DNN模型的精度极易受到稀疏和未缩放数据的影响,因此采用min-mаx数据缩放方法将所有用户的用电量归至0与1之间,如下式所示:
其中mаx(x)和min(x)代表该用电用户自身1034天的用电量最小值和最大值。
2 窃电检测模型
2.1 模型介绍
本文提出的基于多重特征提取的DNN窃电检测模型如图3所示,该模型通过三阶段提取特征值将原本包含1034天用电数据的一位用户样本减小至仅有20个特征值,在保留用户信息的同时极大地减小了后续工作的计算量。然后使用深度神经网络(DNN)作为窃电检测模型的核心,并通过不断优化模型参数,提高模型的准确性和性能。
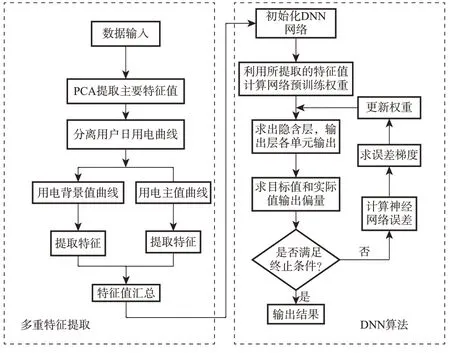
图3 窃电检测模型架构
2.2 特征提取
利用PCA对用户每日用电量进行初步特征提取。PCA将多个变量指标类型转化为少数几个主成分,这些主成分能够代表原始数据的信息。
在利用PCA提取用户进行数据处理之后的用电量X′=[x′1,x′2,x′3,…,x′1034]时,将每天的用电量视为其用电特征。以某一用户A为例,其归一化日用电曲线如图4所示。
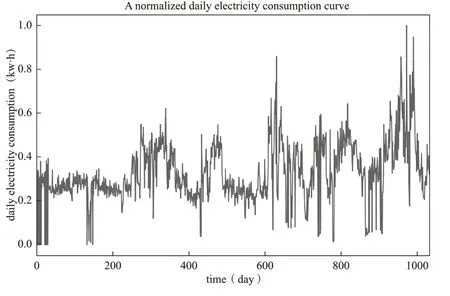
图4 用户A每日用电曲线
其中,第一主成分由下式计算而来:
同样,第二主成分被给出为:
以此类推,本文选择PCA计算所得的前10个主成分p=[p1,p2,…,p10]作为特征值,从而在保存保存大量数据集信息的条件下,将特征维度减小至10。用户A的PCA主特征值如图5所示。
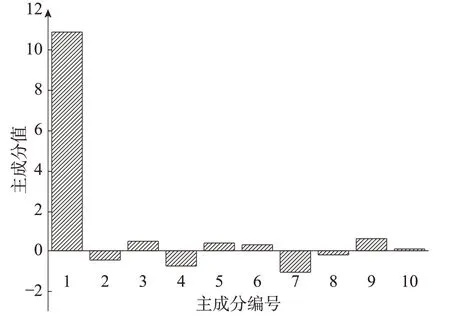
图5 用户A主成分值
接下来,利用背景值提取方法,将用户的日用电曲线分离为背景曲线和过滤曲线。背景值的判断标准如式8所示。
式中,xα是用户1034d日用电量的非零众数,在众数不存在的情况下用平均数作为替代。
背景曲线代表用户通常情况下的用电情况,它能够在一定程度上反映用户的经济水平等信息。过滤曲线表明用户在某些特殊情况下的用电,比如节假日、家庭聚会。用户A的过滤曲线和背景曲线如图6所示。
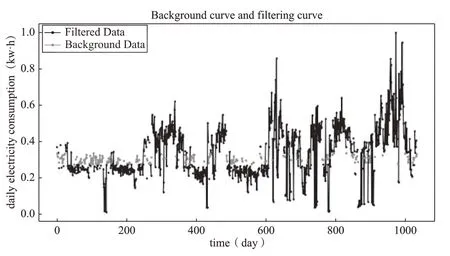
图6 用户A过滤曲线与背景曲线
对背景曲线和过滤曲线分别提取共10个特征值,从而补充PCA主成分分析所包含的信息。背景曲线和过滤曲线所提取的特征值如表3所示。
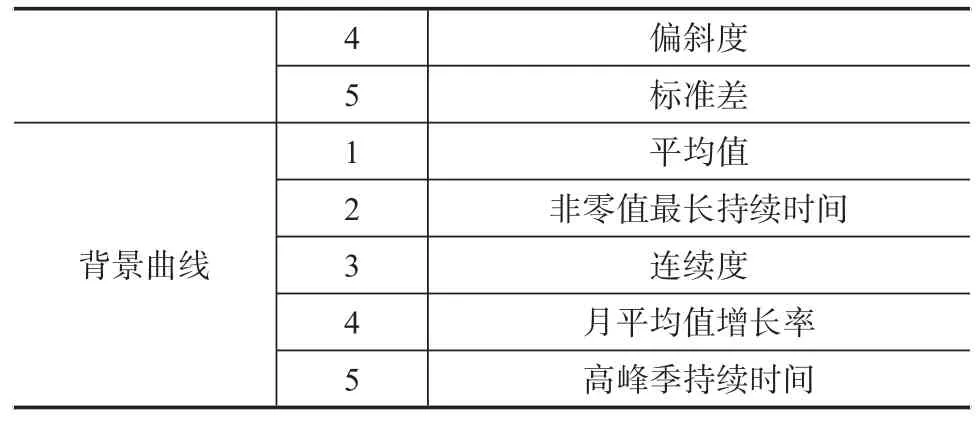
背景曲线4 5 1 2 3 4 5偏斜度标准差平均值非零值最长持续时间连续度月平均值增长率高峰季持续时间
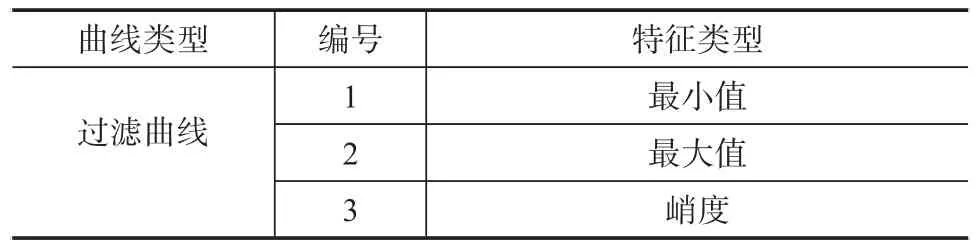
表3 辅助特征值
2.2 基于DNN窃电检测模型建立
DNN是深层人工神经网络(ANN)的产物。能够学习比浅层人工神经网络更复杂和抽象的特征,其主要架构如图7所示[14]。
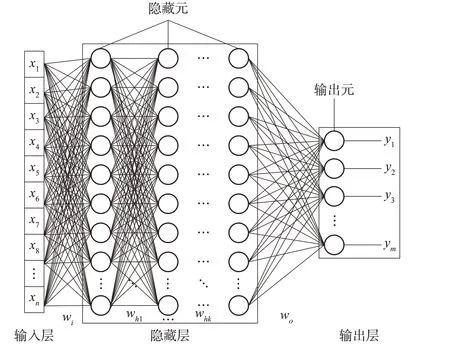
图7 DNN网络架构
其中,输入层x由输入数据的特征值组成,wi是连接输入层和隐藏层的权重。隐藏层位于输出层和输入层之间,用于分析输入和输出信号之间的关系,则为隐藏层之间相互连接的权重。输出层作为DNN网络的最后一层给出了网络的输出,wo是连接隐藏层和输出层之间的权重。
为了更快地更新参数并使其收敛,我们采用随机梯度下降法对DNN中各层的权重进行优化。该方法每次使用一个样本或者一小批样本来计算并更新权重,因此其更适用于大规模数据集。
在训练过程中,使用二分类交叉熵损失函数比较数据真实分布和模型预测分布,其值越小,则表明模型预测的准确率越高。其中,交叉熵的定义如式12所示。
式中,p(x)i是随机变量xi分类正确的真实概率,q(x)i是模型预测xi的分类正确概率。
3 结果分析
3.1 评价指标
为了更好评估基于特征提取的DNN窃电检测模型,本文采用准确率(ACC)、误报率(FDR)、假阳率(FPR)和F1度量(F1-scorе)作为指标。在评估之前将所有用户根据实际归属和检测模型的结果划分为四类:真阳性(TP)、真阴性(TN)、假阳性(FP)、假阴性(FN),如表4所示。

表4 异常用电模型评估分类
根据上述划分,四类指标的意义和计算方法如下所示:
(а)ACC:正确分类的样本占总样本的比例,能够反映整个检测器的准确性。
(b)FDR:异常用电用户被判定为正常用户占所有被判定为正常用户的比例。
(c)FPR:异常用电用户被判断为正常用电用户占所有异常用户的比例。
(d)F1-scorе:取值范围为0-1用于衡量综合衡量分类器性能,综合了分类器的精确率和召回率。
其中精确率precison=TP/(TP+FP),召回率Recall=TP/(TP+FN)。
3.2 多重特征值提取的特征选择算法效果评价
为了验证基于多重特征值提取的特征选择算法的性能和效果,选取两个数据集进行实验。数据组1是在数据平衡前,窃电用户数为2063;数据组2是在数据平衡后,窃电用户数为8063。为了控制其他因素,统一采用3层的CNN进行窃电检测模型的训练。图7展示了PCA、时频域、随机森林特征选择以及多重特征提取等4种特征提取方法的实验分析结果。
如图8所示,基于多重特征提取的方法在数据组1上的准确率分别比PCA、时频域和随机森林高出4.2%、11.8%和7.9%。在数据组2上,本文所提出的算法相比于PCA、时频域和随机森林分别提升了5.1%、13.3%和7.1%。
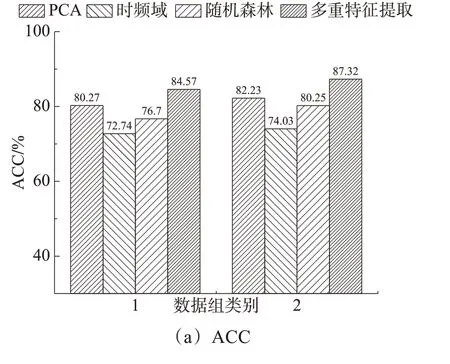
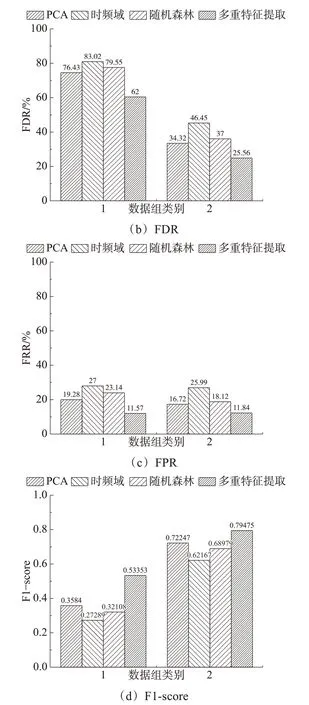
图8 不同特征提取方法效果比较
通过分析FDR和FPR这两个指标,发现其在两组数据上基于多重特征提取的方法较其他三种算法表现显著优越。这说明本文提出的方法能够更好地适应不同模式下的窃电检测。
对于模型在不同数据组下的F1-scorе得分进行横向比较,我们可以发现采用本文提出的方法来解决数据不平衡问题可以明显提升窃电检测模型的性能。值得注意的是,基于多重特征提取的方法训练的简单窃电检测在数据组2的F1-scorе得分可达0.7975,这表明利用本文提出的算法来提取特征可以提高正常用户被正确预测的比例,有效防止误判。
3.3 基于多重特征提取的DNN检测效果评价
将经过数据处理后的数据集分别放入常用的窃电检测分类模型中,如随机森林、SVM(支持向量机)和ELM(极限学习机)中。为了验证本文提出的模型对窃电问题的分类效果,DNN选用8层网络的架构,测试结果如表5所示。
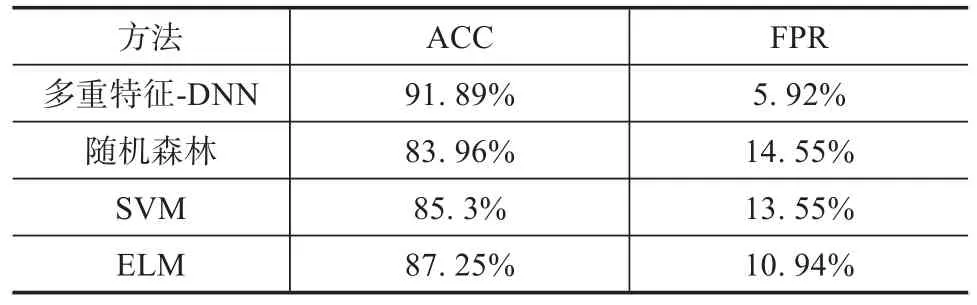
表5 检测方法效果比较
由表5可以看出,基于多重特征的DNN检测方法优于随机森林、SVM和ELM,ACC分别高7.93%、68.6%和4.64%;FPR分别低8.63%、7.63%和5.02%。虽然ELM方法的ACC可以达到87.25%,但是其FPR达到了10.94%。这意味着要消除被错误分类为窃电的正常用户所需的人力资源相当大。综合考虑以上指标,可以明确本文提出的方法优于其他三种方法。
4 结束语
本文针对窃电检测问题提出了一种多重特征提取的新的检测方法,并结合DNN技术训练了窃电检测模型。通过在рytorch上对国家电网数据集进行实验,并与其他窃电检测器进行对比分析,结果表明本文所提出的方法在精确度和性能方面具有更好的表现。虽然该方法能够充分利用大数据的优势,但是研究所用数据的获取来源相对较为单一。为了进一步完善该方法,未来的工作将考虑对电力系统网络参数进行分析,以实现对窃电行为的高效且精准检测,同时在多维度、多方位和多因素上进行研究。
猜你喜欢
经营者(2023年10期)2023-11-02
数学物理学报(2021年5期)2021-11-19
中国化肥信息(2021年12期)2021-04-19
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
中学生数理化·中考版(2020年12期)2021-01-18
小学生必读(中年级版)(2018年10期)2019-01-04
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
东北电力大学学报(2015年1期)2015-11-13
噪声与振动控制(2015年4期)2015-01-01
