
基于融合模型的联合站能耗优化技术研究
2024-05-03 09:00高岩大庆油田有限责任公司第五采油厂
石油石化节能 2024年4期
高岩 (大庆油田有限责任公司第五采油厂)
目前,我国大部分陆上油田的开发已经进入中后期,地面生产设施逐渐完善,但投产设计规模与现阶段的处理规模往往存在较大出入,耗能大于产能,油气损耗及无用功耗逐渐加剧,能源浪费现象日益严重[1]。其中,联合站作为地面集输系统的主要组成部分,具有采出液汇集、原油脱水、采出水处理及气工艺处理等诸多功能,是油气田开发中油气消耗、电能消耗的重要环节,运行过程中存在资源利用不合理、设备负荷率低等问题[2-3]。
1 联合站清洗数据
以大庆某采油厂联合站为例,工艺流程为井口来液通过站内汇管输送至三相分离器进行油、气、水分离。分离出的气,一部分进入加热炉系统,为站内日用、掺水加热、原油加热等提供能量,一部分进入气处理系统,处理合格后的干气外输;分离出的水进入水处理系统,通过过滤、沉降、增压、回注,完成注水流程;含水油先后进入电脱水器和沉降罐分离、净化,待原油含水率低于0.5%时外输至炼厂。2022 年1 月1 日—12 月31 日,以天为单位,共收集各项运行参数365 条,包括但不限于原油密度、来液含水率、汇管压力、出站压力、汇管温度、出站温度、加热炉耗气量、外输泵耗电量等。
1.1 数据校验
首先,对数据进行完整性检验,识别缺失类型和缺失字段,计算每种参数的缺失数量和缺失比例。缺失统计结果见图1。可见原油密度、含水率和外输泵耗电量参数的缺失数量较大,这是由于原油取样化验存在周期性,站内外输泵为两用一备,当运行外输泵检修时,电表在记录和远传上存在数据缺失。

图1 数据缺失统计结果Fig.1 Statistical results of data missing
其次,对数据中的重复值进行检验,联合站异常数据箱线图法检验结果见图2。即对数据报表中相邻日期内属性值相同的记录进行识别,共得到21条重复数据,将重复数据合并,共得到有效数据344 条。
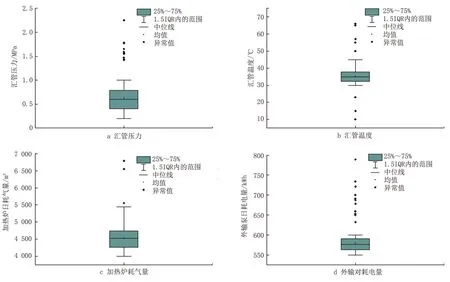
图2 联合站异常数据箱线图法检验结果Fig.2 Test results of box plot method of abnormal data from combined station
最后,对数据中的异常值采用箱线图法检验,存在异常值的数据类型有汇管压力、汇管温度、加热炉耗气量和外输泵耗电量[4-7]。其中:除加热炉耗气量外,其余数据的均值大于中位数,表现为正偏态;加热炉耗气量表现为负偏态。考虑到汇管直接连接三相分离器,分离器的承压能力有限,故要求汇管压力不大于1 MPa,对于大于1 MPa 的10 个异常值采用中位数0.60 MPa 替代。该站所属区块的原油凝点为25 ℃,为实现流动保障,汇管温度应高于凝点3~5 ℃,其中有5 个异常点温度大于50 ℃,3 个异常点温度小于23 ℃,可能与现场传感器数据漂移有关,将异常点采用中位数34.8 ℃替代。加热炉日耗气量和外输泵日耗电量分别存在3个、11 个异常点,虽然处理液量和环境温度的变化,均会影响站内水力和热力消耗,但异常点不符合现场实际工况,故对其分别采用中位数4 522 m3和57 kWh 替代。
1.2 数据重构
联合站数据中的缺失值较为集中,采用三次样条曲线,建立合适的分段函数,对缺失信息进行重构。以外输泵耗电量为例,2022 年3 月1—30 日的数据存在2 处缺失,分别为3 月15 日和3 月23 日,通过Spline 函数完成光滑曲线构建,并根据横坐标的缺失日期确定相应的耗电量,绘制外输系统电量的三次样条曲线(图3)。最终,得到3 月15 日和3月23 日的耗电量分别为572 kWh 和563 kWh,重构数据位于前一个数据和后一个数据的发展趋势上,具有较高的精确度。对于其余缺失值的数据重构,采用相同方法。

图3 外输泵耗电量的三次样条曲线Fig.3 Cubic spline curve of power consumption of external pump
2 能耗相关性分析
涉及联合站的能耗指标有单位液量综合能耗、单位液量气耗、单位液相电耗、单位原油气耗、单位原油电耗等。考虑到采出水处理系统中涉及分压注水和加热掺水流程,气处理系统中涉及再生塔、重沸器和换热器等,故在此采用单位液量综合能耗作为联合站能耗评价的综合性指标。
将单位液量综合能耗作为参考序列,将经数据清洗后的因素作为比较序列,采用灰色关联法验证不同因素与单位液量综合能耗的关系,灰色关联度结果见图4(分辨系数取0.5)。
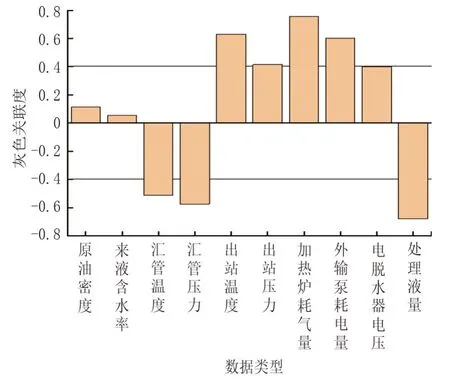
图4 不同因素的灰色关联度Fig.4 Grey correlation degree of different factors
单位液量综合能耗与加热炉耗气量的关联度最大(0.757 1),两者为强正相关。这是由于一方面气耗用于加热站内原油脱水,决定着处理深度,另一方面气耗用于加热站外掺水,与流动保障密切相关,这也直观体现了热力损失在总能耗中占比较大的特点。单位液量综合能量与处理液量的关联度也较大(-0.678 9),两者为强负相关。这是由于该联合站的设计规模与实际处理液量差较多,处理液量增大,设备负荷率会显著提升,但能耗不会显著增加,故两者呈负相关。单位液量综合能耗与原油密度和来液含水率的关联度较小,均呈极弱正相关。
筛选灰色关联度大于0.4 的数据作为影响联合站单位液量综合能耗的关键因素,按照灰色关联度绝对值从大到小排列,依次为加热炉耗气量、处理液量、出站温度、外输泵耗电量、汇管压力、汇管温度、出站压力和电脱水器电压等。
3 数据回归
为增加数据的扩展能力,实现未来任意时刻单位液量综合能耗的预测,将上述筛选得到的8 个自变量作为输入,将单位液量综合能耗作为输出,代入支持向量机(SVM)模型进行机器学习。在344条数据中任意抽取80%作为训练集,20%作为测试集,训练集用于寻找最优超参数,形成最佳SVM 模型,测试集用于验证SVM 模型的准确性和鲁棒性。其中,超参数的寻优采用网格搜索法,设置惩罚因子∈[0,100],不敏感参数∈[0,10]。对SVM 模型的网络结构及核函数类型采用试算法确定,隐含层节点数和核函数类型优选结果见图5。随着隐含层节点数的增加,训练误差逐渐减小,核函数为Radial basis 函数,隐含层节点为22 时,均方误差最小,为6.50×10-3。最终,确定SVM 的模型结构为8-52-1 型。

图5 隐含层节点数和核函数类型优选Fig.5 Number of hidden layer nodes and kernel function type preference
为验证SVM 模型对于单位液量综合能耗预测结果的准确性,采用前馈神经网络(BP)模型、随机森林(RF)模型进行对比,以均方误差EMS、均方根误差ERMS和相关系数R2等三个统计学指标进行模型评价,评价指标对比结果见表1。其中,BP 模型在训练阶段的拟合效果较好,与SVM 模型的训练效果相当,但在测试阶段BP 模型的MSE 较训练阶段高出了一个数量级,说明BP 模型出现了过拟合现象,模型只是记住了数据类型和数值,从中未学到自变量与因变量之间的非线性关系;RF 模型在训练阶段和测试阶段的表现相对较好;SVM 模型的预测效果最佳,在对未知测试集数据进行预测时,未出现明显的过拟合和欠拟合现象,模型具有强鲁棒性和泛化性。

表1 不同模型评价指标对比Tab.1 Comparison of evaluation indicators of different models
4 能耗优化
在满足约束条件的前提下,以单位液量综合能耗最低为目标函数,将生产参数代入粒子群算法,以加热炉耗气量、出站温度、外输泵耗电量、汇管压力、汇管温度、出站压力等为决策变量,实现优化调整[8-10]。
约束条件如下:①三相分离器应满足压力约束,进站压力不低于0.2 MPa;②三相分离器水相出口的含油质量浓度不超过1 000 mg/L,油相出口的含水率不高于10%,以分别满足后续含水油和采出水的处理要求;③沉降罐出口应满足原油含水率小于0.5%;④汇管温度应高于原油凝点3℃,以保证原油在热力条件下顺利进站,不产生凝管现象;⑤出站温度应低于原油初馏点,以保证原油进入外输泵后不影响泵的吸入,如出站温度过高还会对管道防腐层造成剥离影响。
粒子群算法流程具体步骤如下:①初始化粒子群算法的种群数量、问题维度和最大迭代次数,将每个粒子的位置定义为待优化的决策变量,种群数量等于粒子个数,问题维度等于决策变量个数;②将目标函数作为适应度函数,计算随机生成种群位置下的粒子适应度值,根据适应度值,计算种群中的个体极值位置和全局极值位置;③利用公式更新粒子的位置和速度;④判断是否达到最大迭代次数,如是则结束算法,输出最佳适应度值对应的决策变量,如否则返回第②步进行重新计算。
单一时段的运行数据优化结果见表2(优化前为现场数据,优化后为预期数据)。优化后,预期各项优化参数均有所降低, 按照工业电价0.8 元/kWh,燃料价格3.0 元/m3核算,每天可减少运行费用887.8 元,全年预计可节约26.6 万元,节能效果显著。

表2 运行数据优化前后对比Tab.2 Comparison of operating data before and after optimization
5 结论
1)通过灰色关联度分析,得到影响联合站单位液量综合能耗的关键因素从大到小依次为加热炉耗气量、处理液量、出站温度、外输泵耗电量、汇管压力、汇管温度、出站压力和电脱水器电压等。
2)在核函数为Radial basis 函数,SVM 模型结构为8-52-1 时对单位液量综合能耗的训练及预测效果最高,模型精度优于BP、RF 等对比模型。
3)通过粒子群算法优化后,出站温度、出站压力、加热炉耗气量、外输泵耗电量等参数持续降低,预计全年节约运行费用26.6 万元,节气、节电效果明显。
猜你喜欢
日用电器(2021年7期)2021-08-17
煤气与热力(2021年6期)2021-07-28
煤气与热力(2021年6期)2021-07-28
数字技术与应用(2020年7期)2020-08-21
石油工业技术监督(2020年3期)2020-06-03
科学导报·学术(2019年18期)2019-10-21
伴侣(2018年9期)2018-09-19
电力勘测设计(2017年4期)2017-09-08
西南石油大学学报(自然科学版)(2016年6期)2017-01-15
护士进修杂志(2015年21期)2015-03-19
