
面向远程监督命名实体识别的噪声检测
2024-04-29 05:35王嘉诚王昊奋何之栋刘井平
计算机研究与发展 2024年4期
王嘉诚 王 凯 王昊奋 杜 渂 何之栋 阮 彤 刘井平
1(华东理工大学信息科学与工程学院 上海 200237)
2(同济大学设计与创意学院 上海 200092)
3(迪爱斯信息技术股份有限公司 上海 200032)
(y80220109@mail.ecust.edu.cn)
命名实体识别(named entity recognition,NER)旨在从文本中定位命名实体,并将其分类到预定义的实体类型,如人、组织和位置.NER 是自然语言处理(natural language processing,NLP)的基本任务,有助于各种下游应用,如关系抽取[1]、问答系统[2]、知识库的构建[3-6].
传统的NER 监督方法如BERT-CRF[7]和指针网络[8]严重依赖于大量的标注数据,而数据的标注过程往往既费时又费力.因此,远程监督技术被提出用于自动生成NER 的标注数据,其核心思想是识别文本中存在于知识库,如维基数据开放知识库的实体提及,并将相应类型分配给它们.然而,使用远程监督技术会产生2 类噪声:假阴性(false negatives,FNs)和假阳性(false positives,FPs)[9].首先,由于知识库覆盖的范围有限,文本中并非所有正确实体都会被标注,因此会产生FNs.其次,由于使用简单的字符串匹配来识别实体提及,知识库中实体的模糊性可能会导致FPs.图1 展示了一个远程监督标注示例,其中“PRO”指产品名称类型,“PER”指人名.第1 行是初始文本,第2 行是远程监督标注,第3 行是正确标注.示例中,由于知识库的规模有限,产品实体“拖把”没有被正确匹配,这属于FNs.此外,示例中的“包”表示一个量词,而不是一个产品,但因为知识库的模糊性被错误匹配,这属于FPs.

Fig.1 An example of distantly supervised annotation图1 远程监督标注示例
为了解决上述远程监督NER 的噪声问题,研究者提出了一系列噪声检测的方法.这些方法主要可以被分为2 类:一类是在训练过程中设计样本降噪策略来减小噪声对模型的负面影响.常见的降噪策略有数据聚类[10]、负采样[11-12]等.然而,这类方法仅能处理FNs 噪声,仍无法解决远程监督过程中的FPs噪声.另一类是是在训练之前设计噪声过滤手段来删除训练集中的噪声样本,该方法可以同时处理FNs 与FPs 这2 类噪声,但是对噪声过滤的准确性有较高要求.此外,由于噪声过滤过程的试错搜索与延迟反馈两大特征,许多研究者将其视为一个决策问题,并使用强化学习的强大决策能力来解决.典型的方法是制定不同的奖励和策略,并使用强化学习框架训练一个噪声识别器模型[13-14].然而,这类方法都以句子为单位进行噪声检测,可能会丢弃其中正确的实体标注信息,进而无法为模型提供充足的训练语料.比如,在图1 中,模型可能会因为“包”和“拖把”这2 个噪声实体把整个语句删除,导致正确的实体标注信息“小明”和“钉子”也会被删除.
为此,本文提出了一种新颖的基于强化学习的远程监督NER 方法,称为RLTL-DSNER(reinforcement learning and token level based distantly supervised named entity recognition).该方法可以从远程监督产生的噪声文本中准确识别正确实例,减少噪声实例对远程监督NER 的负面影响.具体而言,本文把强化学习框架中的策略网络中引入了标签置信度函数,为文本语句中的每个单词提供了标签置信分数.此外,本文提出了一种NER 模型预训练策略,即预训练阶段的F1 分数达到85%~ 95%时即停止训练.该策略可以为强化学习的初始训练提供精准的状态表示和有效奖励值,帮助策略网络在训练初期以正确的方向更新其参数.
总的来说,本文的主要贡献有3 点:
1)提出了一种新的基于强化学习的方法,用于解决远程监督NER 任务,称为RLTL-DSNER.该方法利用策略网络与一个标签置信函数,从有噪声的远程监督数据中,以单词为单位识别正确实例,最大限度保留样本中的正确信息.
2)提出了一种NER 模型预训练策略,以帮助RLTL-DSNER 在训练初期就能以正确的方向更新其可学习参数,使训练过程稳定.
3)实验结果表明,RLTL-DSNER 在3 个中文数据集和1 个英文医学数据集上都显著优于最先进的远程监督NER 模型.在NEWS 数据集上,相较于现有最先进的方法,获得了4.28%的F1 值提升.
1 相关工作
传统的NER 方法是基于人工标注的特征,常用的方法有最大熵[15]、隐马尔可夫模型[16]、支持向量机[17]和条件随机场[18].近年来,深度神经网络的发展使其成为研究的主流.深度神经网络自动提取隐藏的特征,从而使研究人员不用再把重心放在特征工程中.
预训练语言模型BERT[19]被提出后,以其动态词向量获取能力强、通用性强两大优点备受研究者关注,许多方法都以其作为编码器.Souza 等人[7]构建了BERT-CRF 模型,在BERT 的基础上,使用CRF 层学习句子的约束条件,提升句子的整体标注效果.Hao等人[8]使用了基于指针网络的模型结构,提升了模型对实体边界的敏感性,并解决了现实中普遍存在的重叠实体问题.除了对模型架构的设计,许多研究将重点放在了额外特征的探索和挖掘中.罗凌等人[20]在模型中引入了包含汉字内部结构的笔画信息,Xu等人[21]融合了中文文本中的词根、字符以及单词信息,这些额外特征的引入进一步提高了模型的表现.
虽然文献[7-8,20-21]方法都在NER 任务上取得了不错的效果,然而它们都依赖于大量的人工标注数据.在缺乏人工标注数据的情况下,为了缓解数据不足带来的负面影响,许多研究者提出了远程监督标注方法.Shang 等人[22]提出了AutoNER 模型,采用“Tie or Break”标注方案代替传统的BІO 方案或BІOES 方案.同时,他们引入字典裁剪方法和高质量的短语来实现远程监督NER,并在3 个基准数据集上取得了最先进的F1 值.继Shang 等人[22]之后,Wang 等人[23]在不完全字典的帮助下实现字符串匹配,以检测可能的实体.此外,他们利用匹配实体和不匹配候选实体的上下文相似性来检测更多的实体.相比常规仅使用精准字符串匹配生成自动标注的远程监督方法,通过词典拓展、匹配策略修改等方法,提高了数据质量.然而,这些方法的效果好坏与他们使用的词典质量有密切关系.在词典质量较差的情况下,依然无法避免自动标注产生的FNs 与FPs 这2类噪声标注.
针对噪声标注问题,主要有2 类方法:
1)在训练过程中设计样本降噪策略来减小噪声对模型的负面影响.高建伟等人[24]利用外部知识图谱当中的结构化知识和文本语料中的语义知识,设计了一种实体知识感知的词嵌入表示方法,丰富句子级别的特征表达能力.Lange 等人[10]建议利用数据特征对输入实例进行聚类,然后为聚类计算不同的混淆矩阵.Peng 等人[25]将远程监督NER 任务定义为正样本无标签学习问题,其中正样本由匹配的实体组成,非实体单词构成无标签数据.为了扩展字典,他们使用修改的AdaSampling 算法来迭代地检测可能的实体.Liang 等人[26]提出了一个2 阶段框架,利用预训练模型的优势解决远程监督NER 任务.他们引入了一种自训练策略,将微调的BERT 作为教师和学生模型,并使用教师模型生成的伪标签对学生模型进行训练.Li 等人[11]引入负采样以缓解噪声未标注实体的影响.然而,这类方法仅能处理FNs 噪声,仍无法解决FPs 噪声.
2)在训练之前设计噪声过滤手段来删除训练集中的噪声样本.由于噪声过滤过程的试错搜索与延迟反馈两大特征,许多研究者使用强化学习技术实现此类方法.此类方法发挥了强化学习的强大决策能力,识别远程监督产生的噪声样本,一齐解决假阴性与假阳性实体问题.Qin 等人[27]使用关系抽取器的F1 值作为策略网络的奖励.Feng 等人[28]使用关系提取器的预测概率计算奖励.受其启发,一些研究人员[13-14]将强化学习和CRF 层的拓展Partial CRF 结合起来完成远程监督NER 的任务.然而,他们的方法中,策略网络模型架构都较简单,仅使用MLP 建模,识别能力较弱.此外,都以完整的句子样本为单位进行识别,导致句子中的部分正确信息被丢弃.
2 方法概述
本节首先给出问题的形式化定义,然后概述本文提出的基于强化学习的远程监督方法NER.
2.1 问题定义
NER 通常被建模为序列标注任务,并使用BІO模式对样本进行标注.给定文本S=[s1,s2,…,sn],其中n表示S中单词的数量,NER 的目的是将标签序列T=[t1,t2,…,tn] 分配给S,其中ti∈{BX,IX,O}.B 和І 分别表示实体的首部和后续部分;X表示对应实体提及的类型;O 表示该单词不属于任何类型的实体.需要注意的是,类型往往是预先定义的.与许多研究[13-14,29-30]类似,本文NER 任务的数据集包括少量人工标注的数据集合H和大量通过远程监督获取的数据集合D.具体数据量见表1.
2.2 算法框架
如图2 所示,本文提出的RLTL-DSNER 模型主要包括2 阶段:模型预训练阶段和迭代训练阶段.
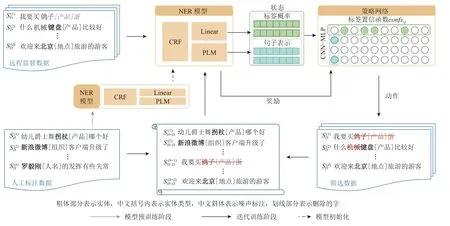
Fig.2 The main framework of RLTL-DSNER图2 RLTL-DSNER 的主要框架
1)在模型预训练阶段,拟通过少量人工标注的数据来预训练NER 模型,使得NER 模型在训练集上的F1 值达到某一阈值 α(α一般取值为85%~ 95%).这一做法的目的是帮助NER 模型在迭代训练阶段的初期为策略网络生成高质量的状态和奖励.
2)在迭代训练阶段,以深度强化学习作为框架,提出了单词级别的噪声检测模型.具体而言,首先通过预训练的NER 模型为文本数据生成向量表示和标签概率分布,并将两者作为状态输入到策略网络.策略网络利用卷积神经网络(convolutional neural network,CNN)、标签置信函数以及多层感知器(multilayer perceptron,MLP)进行单词级别的噪声检测,判断文本数据中的各个单词是否被保留,如图2 中删除了噪声实体“鸽子蛋”与“机械”,因为“鸽子蛋”算作一个产品而不是“鸽子”,“机械”算作描述产品“键盘”的规格,保留了正确实体“陈明亮”“键盘”“北京”.随后,将保留的数据与人工标注的数据进行合并,联合训练NER 模型.同时,NER 模型为保留的数据进行打分,并将其作为奖励来更新策略网络参数.上述流程不断循环迭代,直到达到预定义的轮次.
3 NER 模型预训练
在RLTL-DSNER 中,NER 模型主要用于状态与奖励的生成,其性能将会直接影响噪声检测结果.NER 模型若不进行预训练,在迭代训练的初期往往无法为远程监督文本语句生成高质量的状态和奖励,可能导致策略网络被误导到错误的更新方向.
本文向EC 数据集人工标注集合中手动添加噪声数据来研究深度神经网络的学习特性.具体来说,本文将数据集合中一定比例数据的标注实体随机替换为其他实体,并将其视为噪声数据,其余数据视为干净数据.图3 展示了添加不同比例噪声情况下模型的训练情况.
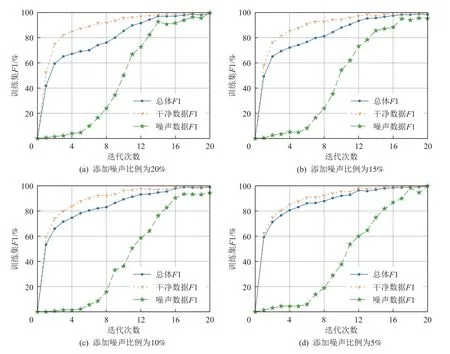
Fig.3 The training situation after artificially adding different proportions of noise to the dataset图3 人工往数据集中添加不同比例噪声后的训练情况
由图3 可以看出,在训练过程中,模型在干净数据上的F1 值会先得到大幅度提升,当干净数据上的F1 值较大时,模型才会渐渐提升其在噪声数据上的F1 值.这个现象表明了深度神经网络在训练过程中通常先学习简单且通用的数据模式,然后逐渐强制拟合噪声数据.换言之,模型的训练F1 值达到某一阈值时,其在干净数据上的F1 值较高,而在噪声数据上的F1 值较低,此时模型将获得最佳性能.因此,本文拟采用上述方法对NER 模型进行预训练.由于此阶段采用的数据集由人工标注,噪声较少,阈值α一般取值为85%~95%.
给定人工标注数据集合H,本文定义作为H中的实例,其中MH表示集合大小,即包含的样本个数,分别表示集合H中第m个样本的文本和标签序列.此外,假定NER 模型用f(θ)表示,其中 θ表示模型的参数,当f(θ)拟合H中的实例的F1值达到阈值时,NER 模型停止预训练.
上述预训练方式与早期停止(early stop)策略相似.但两者不同之处在于早期停止是指当验证集上的损失值增加或训练集的F1 值达到99.9%时,模型停止训练.本文采用的预训练方法更像是“非常早期停止”.相对于早期停止策略,本文的预训练方式有2 点优势:
1)即使是人工标注的数据集,也难免存在噪声数据.因此当训练F1 值达到85%~ 95%时,模型已经学到大部分的数据模式;而继续学习,只会强制记忆噪声数据,损害模型性能.
2)预训练过程仅有少量的数据样本,当模型训练到F1 值达到99%时,很容易导致过拟合,降低了模型的泛化能力和噪声检测能力.
5.3 节的实验表明,通过上述预训练方式的NER模型具有将正确样本和噪声样本分离的能力,有助于策略网络在迭代训练初期正确更新.
4 RLTL-DSNER 中的强化学习方法
本节主要介绍RLTL-DSNER 中的3 个组件,即状态、动作和奖励.与常规的基于强化学习的噪声过滤方法不同的是,RLTL-DSNER 在策略网络中引入了一个标签置信函数,其结合噪声判定模型识别正确实例.需要注意的是,实例的识别是单词级别的,而不是传统样本级别的.
4.1 状 态
由于训练数据中的输入句子是相互独立的,仅将句子的信息作为当前状态很难满足马尔可夫决策过程(Markov decision process,MDP).RLTL-DSNER 将通过NER 模型获得的当前句子表示与标签概率进行拼接,以此作为强化学习智能体的状态.需要注意的是NER 模型是通过历史所选择的句子进行参数更新的.换言之,第i步的状态融入了前i-1步的状态与动作信息.因此,RLTL-DSNER 建模方式满足马尔可夫决策过程,即未来状态的条件概率分布仅依赖于当前状态,而与过去状态无关,因为过去状态的信息都已经隐式融入到当前状态了.
在RLTL-DSNER 中,状态由2 部分组成:当前文本的表示和其各个单词用远程监督标注标签的概率.具体而言,给定文本S=[s1,s2,…,sn],本文首先将S与特殊字符 [cls] 和 [sep] 进行拼接,即 [cls];S;[sep],并输入到大规模预训练语言模型中(如BERT).其次,取语言模型中最后一层隐藏状态即S=(s1,s2,…,sn)作为文本S的语义表示,其中si(i=1,2,...,n) 是单词si的隐藏状态.针对各单词si的标签概率,本文首先将上述的文本表示输入到全连接层中,为每个单词获取所有标签的概率即其中L表示标签类型的数量,表示tj是单词sj的标签的概率.其次,根据上述的标签概率分布,为每个单词取出远程监督自动标注标签的概率.因此,可得到文本中所有单词的标签概率,定义为其中是单词si的标签概率.
4.2 动 作
以往基于强化学习的噪声检测往往定义样本的取舍作为动作[8,10,27-28],但这会丢弃大量正确的实体信息.因此,在RLTL-DSNER 中,本文为文本中的每个单 词定义一个 动作ai∈{0,1},(i=1,2,…,n),其中ai=0 表示丢弃当前单词,ai=1表示保留当前单词.为了这一目标,本文设计了由2 个组件组成的策略网络:噪声实体判别器和标签置信度(tag confidence,TC)函数.
噪声实体判别器是由CNN 和MLP 所构成,其输入是文本语句表示 S和其所有单词的标签概率P,输出是每个单词保留的概率.这一过程形式化定义为
其中Wc是卷积核的可学习参数,c表示CNN 网络,Wm和b是线性层的参数,m 表示MLP 网络,σ(·)是具有参数θ={Wc,Wm,b}的sigmoid函 数,a∈{0,1}表 示动作,⊗表示卷积运算,⊕表示矩阵拼接运算.整体运算流程为:文本语句表示 S和其所有单词的标签概率P作为噪声实体判别器的输入,先通过CNN 对文本语句表示 S作卷积运算 ⊗,得到文本语句的整体表示;随后,将结果 (Wc⊗S) 与所有单词的标签概率P进行矩阵拼接,并通过线性层得到 ((Wc⊗S)⊕P)Wm+b;最终将结果输入sigmoid函数,得到每个单词的保留概率,即动作分别为0 和1 的概率.
通常情况下,仅使用噪声实体判别器是不充分的,原因有:在训练样本量少和数据不平衡的情况下,NER 模型会倾向分配较高的概率给样本中出现次数较多的标签,分配较低的概率给出现次数较少的标签.换言之,当数量较少的标签的预测概率有较大提升时,噪声实体判别器可能会选取另一频繁出现的标签(预测概率较高),而忽略标签概率的相对提升.
一种直接的做法是根据文本的长度进行归一化,凸显标签概率的相对提升.然而,不同文本的长度是不一致的,导致无法定义统一的阈值进行单词的筛选.因此,本文采用TC 函数对单词标签归一化.具体而言,给定一个批次的语句 {S1,S2,…,Sm},其中第i条文本Si=[s1,s2,…,sn],本文首先定义单词sj(j=1,2,…,n) 的标 签预测为l的 概率为pi,j,l,并定 义ql为所有 文本中各个单词标签预测为l的概率的平方和,即
其中L表示标签类型的数量.
然后,对同一批次中每个单词的标签预测概率,通过ql归一化,并取出所有标签中的最大值作为文本Si中第j个单词sj的标签置信分数,定义为
从本质上来说,该标签置信分数可看作归一化后的标签最大预测概率,本文通过上述手段进行归一化,为了削弱仅使用噪声实体判别器的不充分性,凸显标签概率的相对提升.
值得注意的是,本文在ql的定义以及归一化的过程中都对单词sj的标签预测概率pi,j,l取平方处理,由于概率的取值范围为 [0,1],且平方函数在该范围内的导数单调递增,有助于筛选高置信度单词,提高筛选质量.
对于每条文本,本文使用噪声实体判别器与TC函数确定是否保留文本中的每个单词:
其中 φ是预先设定的TC 阈值.
图4 展示了针对给定文本的动作选择,其中最终动作“0”表示丢弃该单词,“1”表示保留该单词.通过远程监督对初始文本自动标注,生成人物实体“小明”与产品实体“包”“钉子”,在得到文本的句子表示和标签概率后,通过策略网络分别得到噪声实体判别器与TC 函数的输出,并根据阈值筛选得到相应结果.噪声实体判别器输出阈值为 ϕ=0.5 进行筛选,TC 函数输出阈值自定义(图4 中阈值 φ=0.9).根据噪声实体判别器输出 π,将丢弃单词“包”,根据TC 函数输出conf,将丢弃单词“拖”“把”.最终结合2 个输出,得到最终动作为丢弃单词“包”“拖”“把”.图4 中可以看出,TC 函数帮助识别出了噪声实体判别器无法筛选出的噪声实体,相比通常情况下仅使用噪声实体判别器进行筛选,增强了策略网络的噪声识别性能.

Fig.4 An example of action selection图4 动作选择示例
4.3 奖 励
在策略网络的每次迭代中,当某一批次文本语句的所有动作执行完后,策略网络会接受以批次为单位的奖励.该奖励r与NER 模型的性能有关.
其中 B表示一个批次的文本,即一次选取的所有文本,S表示批次中的任意文本,文本长度为N,i表示文本中的单词下标,T表示标注序列,首先得到文本S输入NER 模型后,预测标签序列为标注序列T的概率,并通过对该单词执行的动作ai∈{0,1}来判断是否要将第i个单词对应的值pi(T|S)加入计算,表示在句子层面,根据所选择单词的数量进行平均.最终,根据批次大小 |B|平均所有文本的反馈来获得最终奖励.在式(5)定义下,模型保留单词的标注标签,预测概率越高,奖励越大,以此来衡量动作选择的正确程度.策略网络由REІNFORCE 算法[31]更新为:
其中 θ表示策略网络的可学习参数,η表示学习率,是一个超参数,表示可学习参数 θ 的梯度,π(a|S;P;θ)表示策略网络对文本语句表示 S和句中所有单词的标签概率P的输出结果.
5 实 验
本节首先介绍了数据集、基线模型、评估指标以及参数设置;随后,详细对比了不同模型在中英文数据集上的结果;最后,对模型进行详细分析,如进行消融实验和NER 模型预训练,并给出案例分析.
5.1 实验设置
1)数据集.本文拟采用3 个中文数据集EC[13],NEWS[13],CCKS-DS 和1 个英文NER 数据集BC5CDR[32].下面详细介绍这4 个数据集.
①EC 是一个中文基准数据集,共有5 种标签类型:品牌(pp)、产品(cp)、型号(xh)、原料(yl)和规格(gg).
②NEWS 是一个中文基准数据集.该数据集由MSRA[33]生成,只有一种实体类型:人名(PER).
③CCKS-DS 由一个名为CCKS2017 的开源中文临床数据集构建,它包含5 种类型的医疗实体:检查和检验、疾病和诊断、症状和体征、治疗、身体部位.
本文从CCKS2017 的数据集中提取了约1 700 个实例作为人工标注的训练集.其余的大约5 800 个原始句子被收集为远程监督集,并通过远程监督方法进行标注.远程监督使用的知识库为人工标注训练集中的所有特殊实体.
④BC5CDR 是一个英文生物医学领域基准数据集,它包含2 种类型的实体:疾病(disease)和化学品(chemical).本文从Shang 等人[22]提供的原始文本库中选取了15 000 条文本,并使用其提供的词典对这些语料库进行远程监督自动标注.
这4 个数据集的统计数据如表1 所示,每个数据集都包含人工标注的小样本数据和远程监督生成数据.
2)基线模型.本文共对比了DSNER[13],NER+PA+RL[14],LexiconNER[25],Span-based+SL[34],NegSampling-NER[11],NegSampling-variant[12],MTM-CW[35],BioFLAІR[36],Spark-Biomedical[37]等方法.
①DSNER 与NER+PA+RL 都利用部分标注学习的方法来解决标签标注不完整的问题,并设计基于强化学习的实例选择器,以句子级别筛选噪声.
②LexiconNER 将远程监督NER 任务定义为正样本无标签学习问题,并使用自采样算法迭代地检测可能的实体,降低了对词典质量的要求.
③NegSampling-NER 在训练过程中采用负采样策略,以减少训练过程中未标记实体的影响.
④NegSampling-variant 在负采样的基础上,通过自适应加权抽样分布,处理错抽样和不确定性问题.
⑤Span-based+SL 采用跨度级特征来更新远程监督的字典.
⑥MTM-CW 通过一个可重用的BiLSTM 层对字符级特征进行建模,并利用多任务模型的优势解决缺乏监督数据的问题.
⑦BioFLAІR 是一个使用额外的生物医学文本预训练而成的池化上下文嵌入模型.
⑧Spark-Biomedical 使用混合双向LSTM 和CNN的模型架构,自动检测单词和字符级别的特征.
⑨RLTL-DSNER(句子级别)是本文方法RLTLDSNER 的一个变体.其基于本文提出的模型架构,以句子级别识别正确实例,TC 函数修改为式(7),采用句子中各单词标签置信分数的最小值作为该句子的整体标签预测分数.
3)评估指标.本文报告了3 个评估指标:准确率(P)、召回率(R)和F1 值(F1).需要注意的是仅当预测实体与标注实体完全匹配时,才将其视为正确实体.在训练过程中,本文保存模型在验证集上F1 最高的参数,并报告其在测试集上的各个指标.
4)参数设置.对于每个数据集,本文采用相同的参数设置.在第1 阶段,训练的F1 值限制为90%.在第2 阶段,优化器采用随机梯度下降;策略网络和NER 模型的学习率均为 1×10-5;每一网络层的Dropout 设置为0.3,迭代次数设为80;式(4)中的置信度阈值 φ设置为0.9.本文使用的标注方法为BІO标注.
对于BC5CDR 数据集,本文使用“allenai/sciBERTscivocab-uncased[38]”作为预训练模型(PLM).对于其他数据集,PLM 使用“BERT-base-chinese”.报告的结果采用5 次结果的平均值,以减少随机性.
5.2 模型对比
为了验证模型的有效性,本文拟在2 个通用领域数据集EC 和NEWS 上进行实验.实验结果如表2 和表3 所示.从表2~3 中可以得出3 点结论:
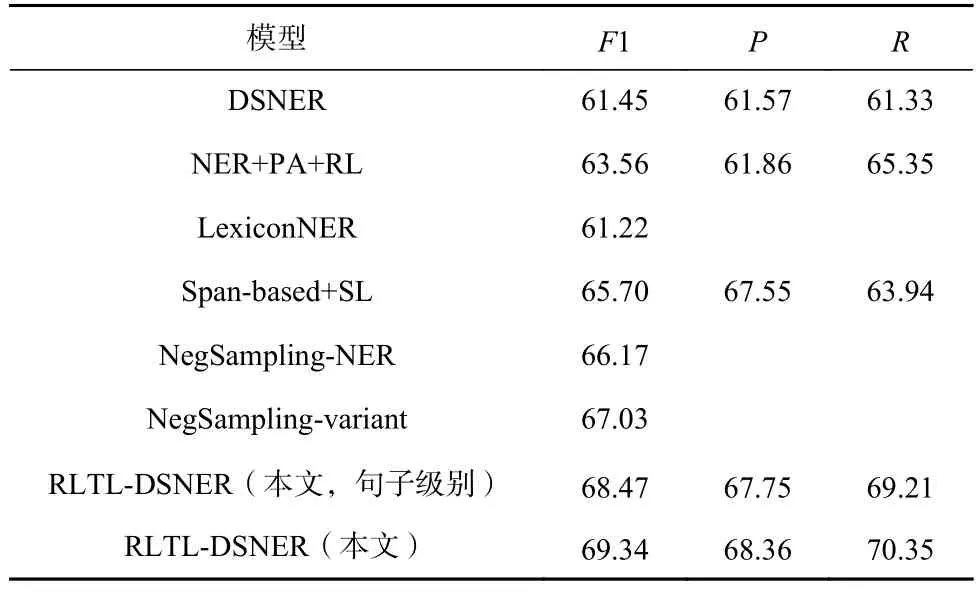
Table 2 Main Results on EC Dataset表2 EC 数据集的主要结果 %
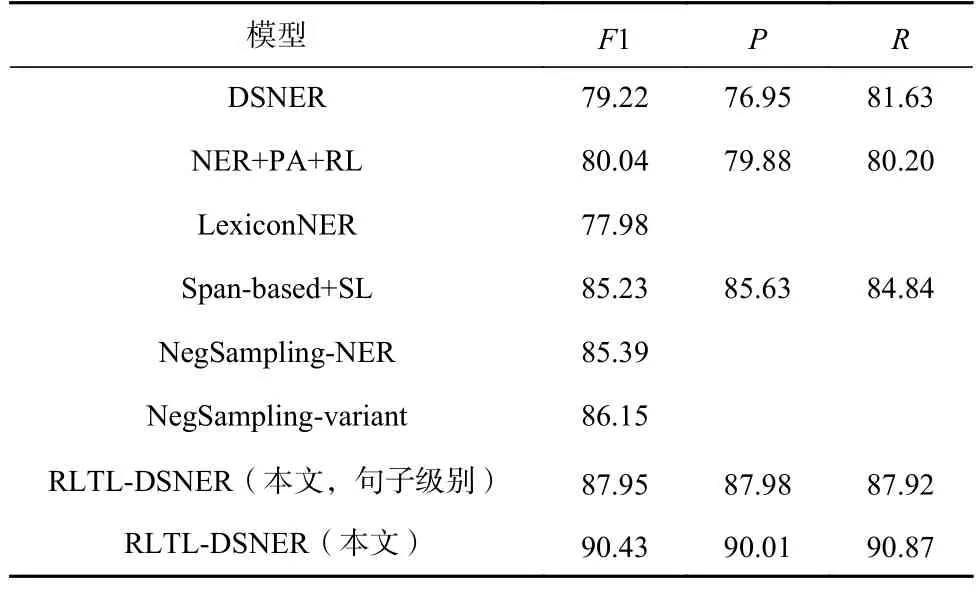
Table 3 Main Results on NEWS Dataset表3 NEWS 数据集的主要结果 %
1)本文提出的RLTL-DSNER 获得了最好的性能.特别地,RLTL-DSNER 在EC 数据集上获得了2.31 个百分比的性能提升,并在NEWS 数据集上获得了4.28 个百分比的性能提升.
2)与句子级别的噪声过滤方法相比(如DSNER,NER+PA+RL),即使在句子级别的选择策略下,本文提出的噪声过滤方法都获得了更好的效果,说明策略网络中引入的TC 函数的有效性.
3)RLTL-DSNER 相较于RLTL-DSNER(句子级别)效果更好,说明以单词为单位识别正确实例可以最大限度保留样本4~5 中的正确信息,提升模型性能.
此外,为了进一步验证模型的通用性,本文拟在CCKS-DS(中文)和BC5CDR(英文)2 个医疗领域数据集中进行实验.实验结果如表4 和表5 所示,从表4~5 中可以得出2 点结论:
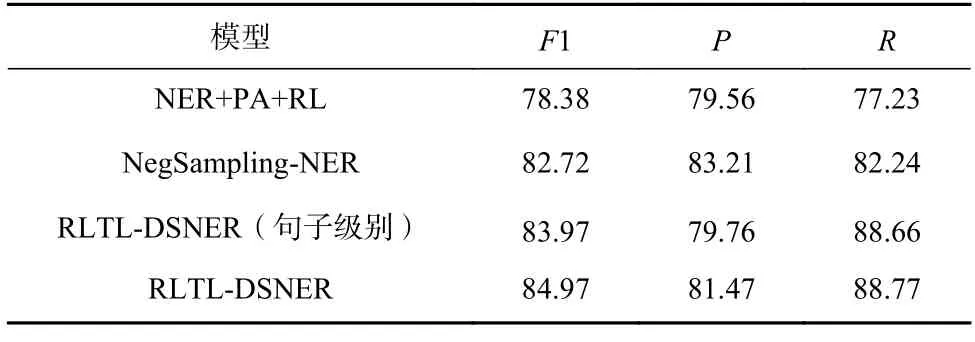
Table 4 Main Results on CCKS-DS Dataset表4 CCKS-DS 数据集的主要结果 %
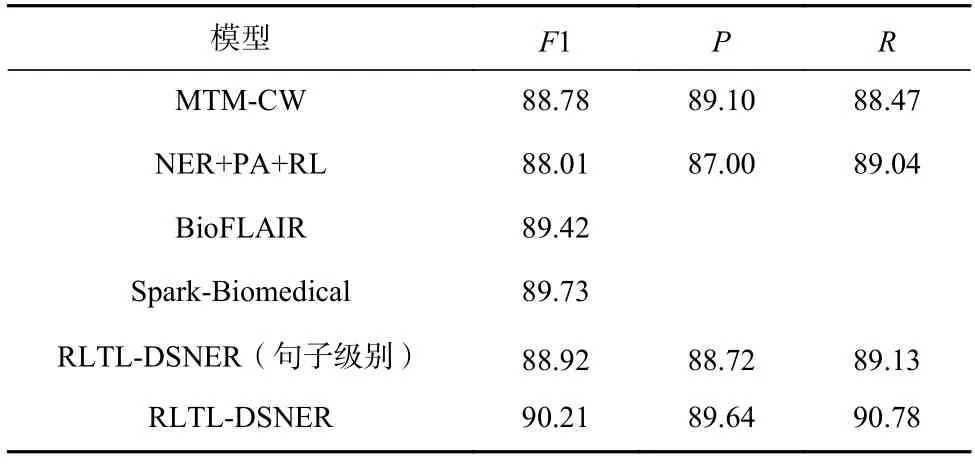
Table 5 Main Results on BC5CDR Dataset表5 BC5CDR 数据集的主要结果 %
1)无论是在中文数据集还是英文数据集,RLTLDSNER 在F1 值上达到了新的SOTA,说明了该模型具有良好的语言适配性.
2)本文的RLTL-DSNER 相较于医学领域的模型,如BioFLAІR,Spark-Biomedical 依然获得了小幅度的F1 值提升,说明该模型具有较好的领域适配性.
5.3 数据分析
本节拟通过消融实验来验证模型每一模块的有效性,并进一步验证预训练方式的有效性.
1)消融实验.本节将在4 个数据集上进行消融实验.实验条件设置为:
①不使用RL 框架,只利用人工标注的数据集作为训练集来训练NER 模型,记为“baseline: H”;
②使用人工标注和远程监督的数据集作为训练集,而不利用RL 框架,记为“baseline: H+D”;
③不采用预训练策略,即训练阶段在人工数据集上的F1 值达到近100%才进入第2 阶段的迭代训练,记为“w/o HT”.
实验结果如表6 所示,从表6 中得出2 点结论:
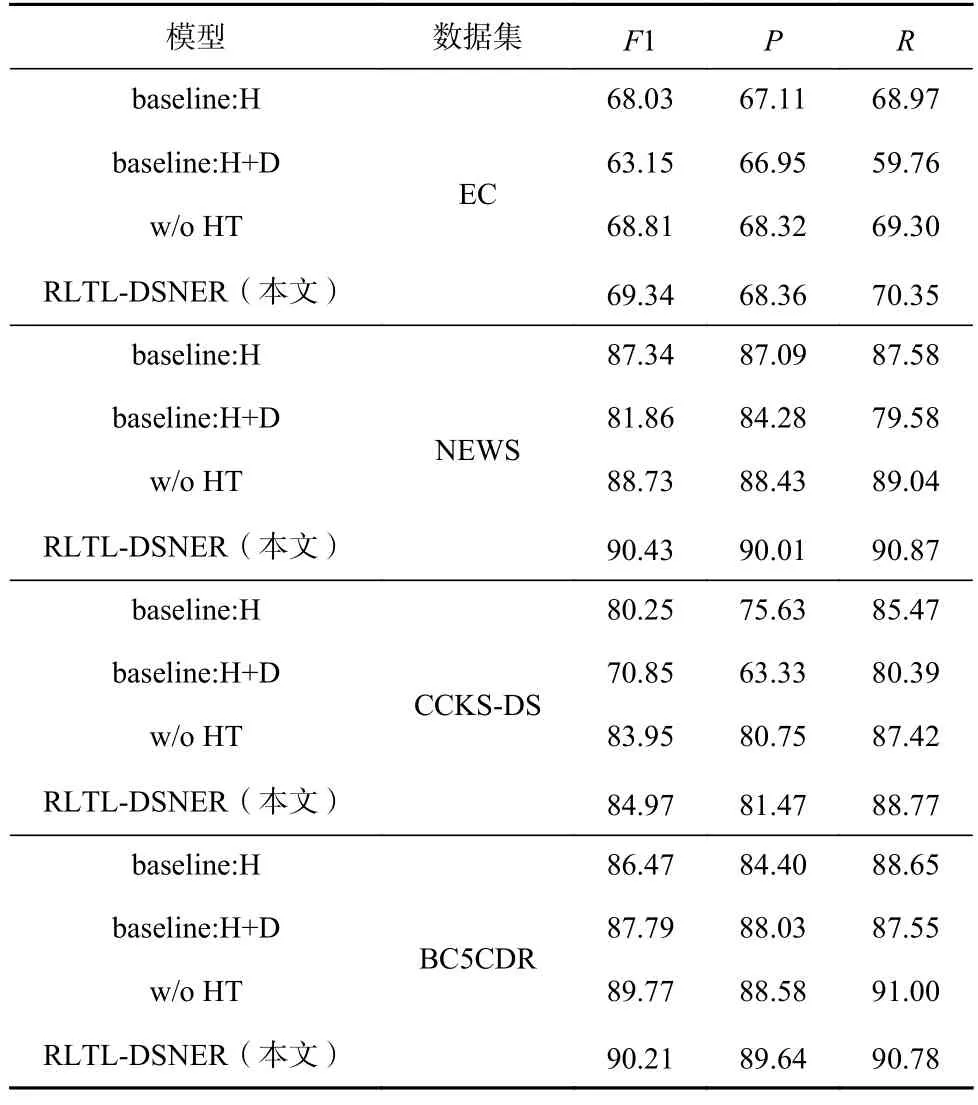
Table 6 Ablation Study表6 消融实验 %
①在4 个数据集上,RLTL-DSNER 模型在所有指标上都取得了最佳的效果,说明模型中的每一模块(包括NER 模型预训练、远程监督数据和单词级别的噪声检测)都是十分重要的.
②在3 种基线中,baseline:H+D 模型的效果是最差的,说明远程监督自动生成数据中存在大量的噪声实例.特别地,在CCKS-DS 数据集中F1 值下降了9.40 个百分比.而在BC5CDR 数据集上,F1 值获得了1.32 个百分比的提升,这是由于本文使用了Shang等人[22]提供的词典进行自动标注,词典质量较高,噪声较少,因此并没有很大程度影响模型的性能.
2)预训练NER 模型的有效性.为了说明本文采用预训练方式的有效性,将NER 模型的F1 值训练到90%的方式,拟与将模型的F1 值训练到近100%的方式进行对比.这2 种方式的F1 值是迭代训练过程中的前20 个迭代次数在测试集上进行测试得到的.实验结果如图5 所示,从图5 中可以得出2 点结论:

Fig.5 Іnitial training performance of the same model under different strategies图5 不同策略下相同模型的初期训练表现
①使用本文的预训练方式,RL 模型的训练较为稳定,仅在NEWS 数据集上出现小幅度的性能下降.这说明了该预训练方式避免了模型的过拟合现象,可以为RL 模型在训练初期提供高质量的文本表示和反馈奖励.
②将NER 模型训练到近100%的情况下,RL 的训练过程十分不稳定.在4 个数据集上都出现了十分严重的性能下降,在EC,NEWS,BC5CDR 数据集上,经过5 个迭代次数后训练趋于稳定,而在CCKS-DS数据集上,模型直至10 个迭代次数后训练才逐渐稳定.这是由于NER 模型对小样本的人工标注数据集过拟合,记住了许多训练样本.此外,模型也学习到了人工标注数据集中难免存在的部分标注噪声.因此导致其生成的句子表示和奖励质量不高.
5.4 案例分析
本节拟通过具体的数据实例与模型预测结果,进一步说明本文提出的RLTL-DSNER 的有效性.
图6 显示了远程监督数据中噪声检测的7 个示例,动作一栏表示在句子级别的动作选择策略下模型的输出结果,动作“0”表示丢弃该句子,动作“1”表示保留该句子.

Fig.6 Іnstances selection examples for the distantly supervised data图6 远程监督数据的实例选择示例
从图6 可以看出,本文提出的模型准确识别出了FNs 如“梁连起(人名)”“等大等圆(症状和体征)”“全脂(产品)”“农夫山泉(品牌)”“天然(产品)”,FPs 如“金灿灿(无类型)”“面色(无类型)”.这些示例表明,本文的方法能够精准地在单词级别进行噪声检测,选择正确的实体,并丢弃有噪声的实体,最大限度保留样本中的正确信息.
此外,根据相同示例下句子级别选择策略的预测结果,可以看出在此策略下会丢弃许多正确信息,如第5 个句子中的“纯牛奶(产品)”、第7 个句子中的“矿泉水(产品)”,同时会使模型学习到许多噪声信息,如第1 个句子中的“梁连起”、第4 个句子中的“面色(身体部位)”等,降低了模型性能.
图7 展示了3 个中文数据集中部分人工标注实例,可以看到“厨房纸(产品)”“王太守则(人名)”“肠管(身体部位)”“干湿性啰音(检查和检验)”这些实体并没有被标注出.此现象说明了人工标注数据集耗时耗力,工作量庞大,但是依然无法避免小部分由于人为疏漏或标注人员间判断标准的差异引入的噪声实体,再次证明了我们提出的NER 模型预训练策略的有效性.

Fig.7 Іnstances of manual annotation data图7 人工标注数据示例
6 结论
本文提出了一种解决远程监督NER 任务中噪声标注问题的新方法RLTL-DSNER.其在强化学习框架中的策略网络引入了TC 函数,为文本语句中的每个单词提供了标签置信分数,并使用单词级别的实例选择策略以最大限度保留样本中的正确信息,减少噪声实例对远程监督NER 的负面影响.此外,本文提出了一种NER 模型预训练策略,该策略可以为强化学习的初始训练提供精准的状态表示和有效奖励值,帮助策略网络在训练初期以正确的方向更新其参数.在3 个中文数据集和1 个英文医学数据集上的大量实验结果验证了RLTL-DSNER 的优越性,在NEWS数据集上,相较于现有最先进的方法,获得了4.28%的F1 值提升.
作者贡献声明:王嘉诚和王凯完成了算法思路设计、实验方案制定,并完成实验和论文撰写工作;王昊奋提供论文撰写指导、技术支持;杜渂和何之栋完成了相关文献梳理、实验数据整理,并讨论方案;阮彤完成了论文框架设计、整体内容规划;刘井平提供论文撰写指导和完善实验方案.
猜你喜欢
军事文摘(2022年20期)2023-01-10
英语文摘(2021年11期)2021-12-31
中国外汇(2019年18期)2019-11-25
学生天地(2018年19期)2018-09-07
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
公民与法治(2016年10期)2016-05-17
