
基于灰数描述的不确定工时作业车间E/T调度优化*
2024-04-29 06:03陈开院熊禾根
组合机床与自动化加工技术 2024年4期
陈开院,熊禾根
(武汉科技大学a.冶金装备及其控制教育部重点实验室;b.机械传动与制造工程湖北省重点实验室,武汉 430000)
0 引言
工件的加工工时由于设计的经验性、加工设备的实时状态、操作工人的实时状态等原因,使得实际操作时的加工工时具有波动性和不确定性。因此生产调度方案在实际生产运作中不可避免会产生偏离,在面向订单的制造系统中,这种偏离可能体现得更为严重,进而影响订单的按期交货。另一方面,在进行交货期制定时,除了按确定时间点设定交货期的方式,另一种常用的方式是给订单设定一个合理的交货时间窗,在给定时间窗内交货,既不影响客户的生产,也不至于增加库存的成本。
针对工件加工工时不确定的调度问题,现有研究主要使用概率分布、区间数和三角模糊数来建立相应的调度模型。张洁等[1]采用埃尔朗分布模拟加工时间,设计一种基于交货期偏差容忍度的滚动调度策略;杨宏安等[2]通过区间可能度比较法分析工件完工时间区间与交货期窗口的各种关系进行求解;LI等[3]提出一种基于概率和偏好比的区间排名方法,用于精确的区间计算;彭运芳等[4]用三角模糊数进行建模,利用均值去模糊化结合改进遗传算法对调度问题提供解决方案;刘琦等[5]基于模糊规划理论,采用“中间值最大隶属度”的算法对调度问题进行求解。对于提前/拖期调度问题(earliness/tardiness,E/T),WODECK等[6]考虑单机调度中的E/T调度问题,提出一种用序列块代表搜索集合的Tabu搜索算法求解。
模糊数方法在处理工时不确定的调度问题方面取得了显著成效。然而,在数据处理过程中,去模糊化方法对权重和隶属度的选择非常敏感。为克服这一问题,研究中引入了灰色理论,该理论使用区间灰数来描述加工工时的不确定性,并利用灰数的白化权函数描述区间内每个数的取值概率。通过白化权函数将区间灰数转化为确定值,从而建立相应的灰色理论调度模型。
基于前人的已有研究,对具有工时不确定性和交货期窗口的作业车间E/T调度问题(job shop earliness and tardiness scheduling problem with uncertain processing-times and due-wind-ows,JSSP/ET_UPD)进行研究,基于灰色理论建立了问题的数学规划模型,提出了遗传算法与局部搜索结合的求解算法。在目标函数中考虑工件提前和拖期惩罚,以该函数值最小使工件尽可能在交货期窗口内完成,同时为保证机器资源的充分利用,还将机器空闲的成本包含在目标函数中。
1 问题描述
1.1 JSSP/ET_UPD问题描述
所提出的JSSP/ET_UPD问题可描述如下:有n个工件需要在m台机器上加工,每个工件含有若干道加工工序,工件的工艺路线预先指定;各工序在指定的机器上加工,加工工时为非确定值。每个工件均设定有一个交货期窗口[Ei,Ti],若工件在设定的交货期窗口内按完工,则没有惩罚;否则,若工件提前或者拖期完工,将产生相应的惩罚。此外,若机器在加工过程中出现空闲,也将产生相应的惩罚。问题的目标是寻找一个优化的调度方案,使完成所有工件的总成本(惩罚)最小。该问题其他一些基本假设为:
(1)所有工件零时刻可开始加工;
(2)所有机器零时刻可用,不考虑机器故障和维护;
(3)所有工件等权重,且相互独立,不存在约束关系;
(4)同一时刻,一台机器只能加工一个工件;
(5)同一时刻,一个工件只能被一台机器加工;
(6)工件的加工路径中机器不可重入;
(7)一道工序一旦开工,在其加工过程中不允许被中断和被抢占。
1.2 不确定工时的灰数描述
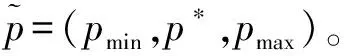
(1)
根据期望值法去模糊数化,将其转为确定加工时间,表示为:
(2)
由于该方法在对不确定工时转为确定值进行算法求解时,难以考虑到加工时间的所有分布信息,因此提出一种工时的灰数描述方法。灰数是灰色理论的基本单元,通常把只知道大概范围而不知道确切值的数称为灰数,灰数常记作“⊗”。与模糊理论不同,灰色理论着重研究的是外延明确而内涵不明确的问题。对于工时不确定性而言,显然,其外延(即工件的工时)是明确的,但内涵(即工时的确切取值)是不明确的。因此,采用灰数对不确定工时进行描述是合理的。
基于不确定工时的三角模糊数表示,灰色理论下的加工时间可表示为区间灰数⊗∈[pmin,pmax],对应的白化权函数表达式为:
(3)
(4)
之后通过灰色模拟[8]产生服从F分布的实际时间加工时间,在[0,1]之间通过均匀分布产生随机变量μ,再求得F-1(p)的值,即为灰色理论下模拟出的实际加工时间⊗p。
(5)
⊗p=F-1(p)
(6)
1.3 基于灰数描述的JSSP/ET_UPD问题模型
为方便描述及数学模型的建立,定义相关符号以及相关决策变量,如表1所示。

表1 相关符号及其含义
工件若未在交货期窗口完成交货,提前或者拖期完成都会造成一定的成本损失,机器处于空载状态时也会造成不必要的损失。因此综合考虑拖期/提前成本以及机器空闲成本,将目标函数定义为:
min⊗Z=⊗G+⊗M
(7)
式中:⊗G为工件的提前/拖期成本,⊗M为机器空闲成本,均由灰数表示;其表达式为:
式中:CE为提前惩罚,CT为拖期惩罚,CM为机器空闲惩罚。并根据相关定义,给出如下约束条件:
⊗cij≤⊗si(j+1)
(8)
max{sij,⊗si′j′≥min{ ⊗cij,⊗ci′j′}
(9)
mij≠mij′
(10)
⊗cij=⊗sij+⊗pij
(11)
约束(8)对应工件指定的工艺路线要求,约束(9)表示同一时刻一台机器只能加工一个工件,约束(10)表示机器不可重入;约束(11)保证工序能够连续加工,既不被中断也不被抢占;约束(8)和约束(11)保证工件在同一时刻只能被一台机器加工。
2 算法设计
遗传算法作为一种元启发式算法,是一种群体智能搜索算法,有着很强的大范围搜索能力,但在局部深入搜索能力方面有所欠缺。因此,为改善遗传算法求解问题的性能,将遗传算法与局部搜索相结合,设计了求解JSSP/ET_UPD问题的混合遗传算法,算法流程图如图1所示。求解过程中先通过遗传算法进行全局搜索,滞留现象到一定程度时,调用局部搜索对当前最优解进行优化,并根据滞留代数对局部搜索的邻域大小和搜索次数进行动态调整,具体如图2所示。

图1 算法流程图 图2 动态局部搜索策略
2.1 遗传算法设计
遗传算法方面,各算子及控制参数具体设计为:
(1)编码与解码。采用基于符号的编码方式,每一条染色体包含所有工件的加工工序。以3×3 Job Shop问题举例,一条随机生成的染色体为[3,1,2,2,1,3,1,3,2],用工件序号表示基因。解码过程中,根据工件号在染色体中重复出现的次数找到对应工件的加工工序,并将其置入对应机器上加工,直至所有工件加工完成,解码过程结束。
(2)选择操作。利用轮盘赌策略,该策略会根据每个个体的适应度来确定其被选中的概率,适应度越高的个体被选中的概率就越大。为了确保种群有更好的进化方向,采用精英保留策略[9],将适应度最好的个体直接保留到下一代。
(3)交叉与变异操作。采用基于POX算子[10]的交叉方式;为保证种群多样性,避免陷入局部最优,采用翻转变异[11]。
(4)确定交叉变异概率。区别于文献[5]基于种群适应度的动态交叉概率,针对种群中的每个个体分别设置交叉概率(Pc)和变异概率(Pm),并根据其适应度值进行动态调整,赋予适应度差的个体更高的交叉和变异概率,对于适应度较好的个体则赋予较小的概率,以保证有益基因个体能够传承至下一代。具体步骤为:
步骤1:给定交叉、变异概率的Pc,Pm基准值;
步骤2:计算种群中个体l的适应度,将其记作Zl;
步骤3:个体l的动态交叉概率Pc(l)及变异概率Pm(l)表示为:
式中:S为种群规模。
2.2 局部搜索部分
设z为滞留代数,当遗传算法求解过程中滞留代数z>5,则调用局部搜索尝试对最优个体进行寻优;若z>10,则对局部搜索的参数进行动态调整。
根据文献[12],调度方案的优劣与工件的不确定程度有关,因此在局部搜索的邻域设计中,选择不确定程度不一致的多道工序设计为邻域,将邻域里不确定程度不同的多道工序重新排序。通过改变局部序列调整整体调度方案,尝试找出更好的调度方案。具体步骤为:
步骤1:获取当前最优个体,通过其对应的模糊调度模型或灰色理论模型,将不确定的加工时间转化为确定值。利用该值表示工序加工时间的不确定程度,通过该值的大小,将最优个体中的所有工序均匀划分为工序加工时间不确定程度不同的两个集合;
步骤2:从步骤1中生成的集合分别选择等量的工序置为邻域,通过对邻域内已选中工序的加工顺序进行局部调整,来改变最优个体对应的整体调度方案及其适应度值,然后保持邻域不变,对邻域内的工序局部调整20次,得到该邻域下的20个邻域解。将本次生成的邻域加入禁忌表,以及20个邻域解中的最优解记录在集合G中;
步骤3:对步骤2重复t次,选择未在禁忌表中的邻域结构,利用该邻域再次对初始最优个体进行邻域搜索,获取搜索结果。最终得到t个邻域结构和t个邻域结构下所对应的最优解,记录在集合G中。获取集合G;
步骤4:将G中的最优个体g与初始最优个体进行适应度值比较,若适应度值优于初始最优个体,则将g置为当前最优个体,进行下一次算法迭代;否则不变,直接进入下一次迭代。
假设最优个体包含的总工序数量为q,则该算法中局部搜索策略如图2所示。当滞留代数z<10时,该算法可能处于初始阶段,滞留现象出现时能够更容易找出更优解,同时考虑到求解计算量,因此给予较大的邻域空间对和较少的邻域生成次数进行搜索;当滞留代数z>10时,该算法可能处于中后期的迭代过程中,此时最优解已经获得了一个较好的排序方案,难以找到更优解,采用较小的基因片段,增加邻域生成次数,增加搜索次数,以找出更优解。
3 算例仿真
3.1 实验设计
(1)算例选择。为便于实验结果的分析比较,仿真算例选自于相关文献。所选算例包括两种规模:6工件6机器(6×6)和10工件10机器(10×10),各4个算例。算例来源如表2所示,具体数据见对应文献。

表2 算例来源
表3和表4给出算例Case1每个工件的加工信息及其工件的交货期窗口。
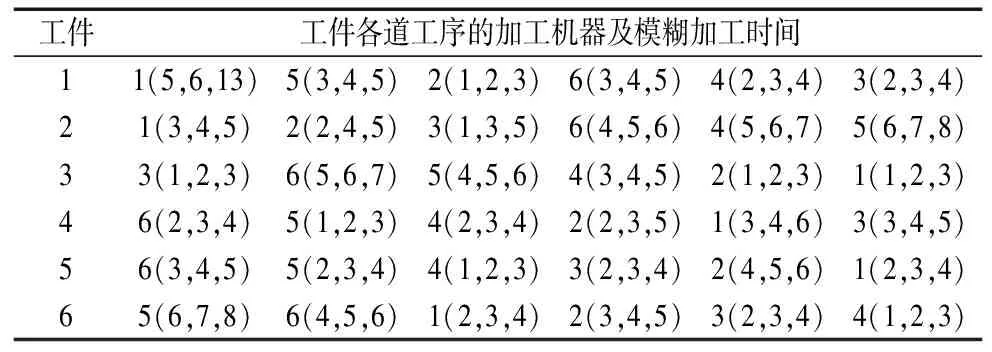
表3 6×6算例Case1工件加工信息

表4 6×6算例Case1工件交货期
(2)实验方案。仿真调度包含3个实验,具体为:
①实验1:基本遗传算法[5]与混合遗传算法性能对比实验。针对表中所列案例,工时不确定性用三角模糊数描述,采用基本遗传算法与本文提出的混合遗传算法进行仿真调度。每个算例均在两种算法下进行20次独立的仿真调度,对每次仿真调度所获得的最优解进行统计分析,以比较两种算法的求解性能。
②实验2:不确定工时三角模糊数描述与灰数描述模型下性能对比实验。针对表中所列案例,工时不确定性分别用三角模糊数和灰数描述,采用本文提出的混合遗传算法进行仿真调度。每个算例均在两种描述模型下进行20次独立的仿真调度,并对每次仿真调度所获得的最优解进行统计分析,以比较两种描述模型下的求解性能。
③实验3:不确定工时三角模糊数描述与灰数描述模型下调度方案稳定性对比实验。针对实验2的40次仿真调度所得到每一个最优解,分别采用对应的描述模型(三角模糊数或灰数)进行20次工时随机抽样,并按最优解染色体进行解码,可获得每个最优解在每次随机抽样工时下的总成本。对每个最优解20次抽样总成本的均值进行统计分析,以比较两种描述模型下的调度方案的稳定性。
(3)实验参数实验环境及参数设置。运行环境:Windows 10操作系统,内存8 G,CPU 2.8 GHz;采用python编程;参数设置如表5所示。
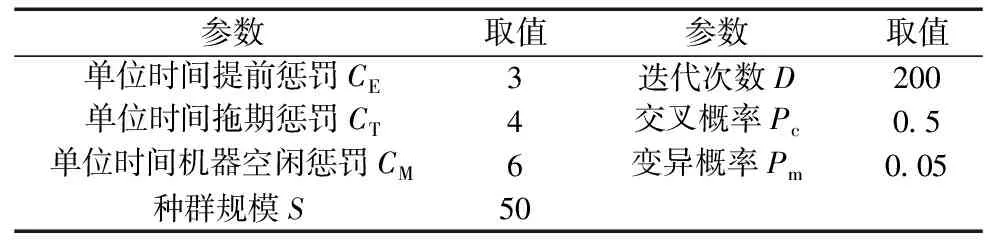
表5 参数设置
3.2 实验结果及分析
(1)实验1结果及分析。为了验证算法的有效性,进行了20次仿真实验,其中6×6和10×10的算例的最优值进化曲线如图3所示。实线为混合遗传算法的进化曲线,虚线为文献[5]提出的遗传算法进化曲线,这些曲线在20次仿真结果中变化趋势基本相同。
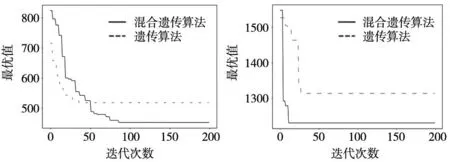
(a) Case1 (b) Case2
通过对算法的最优值进化曲线进行分析,可以得出结论:在解决小规模问题时,混合遗传算法通常在50代左右就能够收敛并获得最优解,相比基本遗传算法,混合遗传算法具有更好的收敛能力;在大规模问题中,虽然混合遗传算法的收敛速度略慢于基本遗传算法,但其能够获得更好的最优解。
为了更准确地评估混合遗传算法的优化效果,采用以下评估准则:假设使用基本遗传算法得到的仿真结果的平均值为b,混合遗传算法后得到的平均值为h,则可以通过以下公式计算出相对百分比偏差RPD1为:
通过相对百分比偏差RPD1的值可知,混合遗传算法在大规模的案例中,对于最优值的优化程度更为明显,其相对百分比偏差基本大于10%。
(2)实验2结果及分析。结合灰色理论,采用区间灰数对不确定工时进行描述,建立相应的灰色理论调度模型。其仿真结果如表6所示,并将其仿真结果绘制成图4的小提琴图,以显示其仿真结果的分布情况。

(a) Case1 (b) Case2

表6 算法测试及模型测试结果
与算法评估准则相同,假设灰色理论下得到的仿真结果的均值为r,则相对百分比偏差RPD2:
利用该值进行比较,灰数模型在不同数据规模上的优化效果不一,但总体而言,在数据规模较大的案例中,能够获得更好的优化效果的可能性更大,最大的相对百分比偏差能够达到10%以上。
结合表6算法测试及模型测试结果中的相对百分比偏差与图4的小提琴图分布情况可以发现,基于灰色理论的建模方法,其仿真结果表现为分布较为集中,相比三角模糊数模型,其方差表现也更为优异。总体而言,在处理大规模和大数据问题时,灰色理论表现出更为显著的优化效果,且具有更高的稳定性。
通过对表6的数据和图4的小提琴图进行分析,发现算例Case1的仿真结果优化程度也较为明显,因此本研究以算例Case1为例,分别用模糊数模型和灰色理论调度模型,结合表3、表4的原始数据进行算例仿真,得到对应调度甘特图如图5所示。

(a) 模糊数模型最优结果甘特图
分析甘特图可以发现,与模糊数模型相比,灰数模型所得到的甘特图在工件最大完工时间和机器的空载时间方面都有所改善,从而降低目标函数值,总成本也能因此减小。
(3)实验3结果及分析。实验结果如表7所示,根据方差分析,灰色理论下描述的不确定加工时间作业车间调度模型稳定性和适应性明显更高。灰色理论建立的模型可以弥补模糊数模型在计算过程中无法考虑实际加工时间分布的限制。该模型将加工时间区间内所有可能取值的概率表述在模型中,并通过白化权函数将区间灰数转化为确定值,实现对优化求解的支持。

表7 模型稳定性测试结果
在实际生产过程中,由于各种不确定因素导致加工时间出现波动,使得调度方案出现偏差。而灰色理论模型能够更全面地利用已知信息,尽可能地利用先前已有的加工时间分布情况,因此在面对加工时间波动时,具有更强的稳定性和更好的适应性。
结论:使用三角模糊数转为灰数,并通过三角模糊数构建白化权函数,能够更全面地考虑到数据的不确定性,从而在调度问题中获得更加稳定的决策结果。相比于三角模糊数用均值转换为确定值的方法,这种方法可以更充分地利用数据的特征,提高决策的精度和可靠性,从而获得更优的调度结果。
4 结束语
对单一的遗传算法的稳定性和精度进行改进,将局部搜索融入遗传算法,测试改进前后算法的求解质量和收敛速度。分析用模糊数描述的不确定加工时间的作业车间模型,通过灰色理论对不确定加工时间的调度问题重新建模仿真,分别对两种模型进行仿真测试。仿真结果表明,灰色理论能够有效地应用于不确定加工工时的调度问题中,相对于三角模糊数模型,灰色模型能够考虑到更多已知信息,提高调度决策地和适应性稳定性。
猜你喜欢
军民两用技术与产品(2021年6期)2021-10-14
吉林大学学报(理学版)(2020年3期)2020-05-29
职工法律天地·上半月(2020年1期)2020-03-02
统计与决策(2018年18期)2018-10-17
自动化学报(2018年7期)2018-08-20
周口师范学院学报(2016年5期)2016-10-17
系统工程与电子技术(2016年2期)2016-04-16
华东理工大学学报(自然科学版)(2014年2期)2014-02-27
郑州大学学报(理学版)(2013年2期)2013-03-11
河南工程学院学报(自然科学版)(2010年3期)2010-11-27
