
基于机器视觉的芯片字符区域分割和定位算法*
2024-04-29 05:49陈甦欣赵安宁罗乐文
组合机床与自动化加工技术 2024年4期
陈甦欣,赵安宁,罗乐文
(合肥工业大学机械工程学院,合肥 230009)
0 引言
芯片是工业生产中重要元器件,它的辨别主要依靠芯片表面的激光字符,这是由字母和数字组合而成,反映出芯片基本参数。芯片表面字符对于它的分选显得尤为重要[1]。现在分选的任务主要依靠人眼进行识别,而芯片作为一种微小的元器件,利用人工的方式效率低下且精度不高,无法满足现代工业生产的需求[2]。
芯片字符区域的定位是分选的前提。为了提高定位的精度和效率,学者们提出了许多针对性的方法[3-9],其中机器视觉作为一种灵活、准确的手段,能够满足实际的工业生产需求。杨桂华等[3]通过模板匹配法进行字符定位,基于字符块和模板的匹配关系,利用形状匹配出新模板获得二者的转换矩阵,最后定位字符区域,但这种方法所针对的实验对象要具有明显外部特征。于凯旋等[4]利用轮廓检测法定位出感兴趣区域,提出一种改进的帧插法进行区域匹配,但容易受到外界环境干扰,影响定位精度。钟彩等[5]提出了一种利用支持向量机的字符定位方法并利用LBF模型进行区域分割,但是定位时间较长且存在一定误差。朱旋[6]利用一种改进的YOLOv2模型,通过边界框预测的方式对中文字符快速定位,但是模型训练成本较高,需要大量数据集支持,难以用于实际工业生产中。潘勇等[7]利用纹理特征和区域灰度变化,实现对区域的定位,但是定位区域对现场光线强度有一定要求。张倩等[8]通过改进概率霍夫变化进行区域粗定位,再利用投影法进行精确字符定位,但是针对直线效果不好的图像,定位精度有所缺失。巢渊等[9]利用角点提取算法结合凸包检测算法对芯片字符进行定位,但仅对形状规则QFN封装芯片有较高定位精度,应用对象比较有限。
为解决以上问题的缺点,受巢渊等[9]提出的方法启发,在此基础上进行优化改进,增加改进的区域生长算法分割芯片图像,通过最大内接矩形算法对芯片字符区域进行粗定位,再利用一种改进的凸包算法提取完整的字符区域。本文以工业生产中直插芯片为载体,设计了一套基于机器视觉方法定位芯片字符区域的系统。
1 系统方法
视觉系统采集平台与采集芯片图像如图1a和图1b所示。

(a) 实验采集平台 (b) 采集的芯片图像
算法流程为:
(1)图像预处理阶段。为了提高图像的质量,减少拍摄过程中外界环境的干扰对实验结果产生的误差。首先对图像进行灰度化处理;再进行图像滤波降噪;最后进行形态学处理去除图像中的光斑。
(2)图像分割与提取阶段。直插芯片因为引脚的存在,图像轮廓呈现出不规则的图形,为了分割图像和背景,减少实验干扰并便于字符区域粗定位,利用一种改进的区域生长算法,以改进的Canny算法提取的芯片轮廓边缘像素点为种子点,以自适应阈值为生长准则将图像和背景分割。
(3)字符粗定位阶段。利用最大内接矩形算法确定芯片表面区域并将区域坐标回传原芯片图像,最后实现字符区域粗定位。
(4)字符定位阶段。使用一种改进凸包检测算法,具体流程为:使用Harris角点算法提取字符角点,筛选排除干扰角点,然后提取关键角点形成初步凸包线,将外部角点纳入区域并修整凸包线,最后使用最小外接矩形算法完成字符区域定位。
2 分割与定位方法
2.1 图像预处理
由于相机、光源设备等硬件和外部采集环境因素,获取的图像会受到噪声干扰,导致实验结果有一定的误差,所以要进行图片的预处理。为了减少图像色彩的干扰,提高处理效率,首先进行图像灰度化处理。利用双边滤波去除现场环境的噪声影响,进一步提高图像质量,保留边缘细节。利用伽马变换对图像进行增强,提升其对比度。为了能在短时间中获取目标图像最佳阈值,减少图像亮度和对比度的影响,使用最大类间方差法获取目标的二值化图像[10]。最后采用形态学操作,去除图像中的光斑、缺口、空洞等干扰获取最终的结果,同时调整图像处理阈值获取去除字符图像。预处理图像如图2a所示。

(a) 预处理图像 (b) 8邻域示意图
2.2 改进的区域生长算法
预处理后的图像仍会存留少量干扰,对后续的算法实验产生误差,同时因为芯片引脚存在,导致图像呈现不规则的形状,无法用圆或者矩形去约束并分离目标和背景。为了能够完整的分割芯片图像和背景图像,需要采用区域生长法进行分割。但是原有算法以单像素点作为生长点且以8邻域(如图2b所示)平均像素值作为生长准则,导致传统区域生长算法分割效率低,分割效果差。针对如上情况,本文提出一种改进的区域生长算法,主要对①算法种子点选取;②算法生长准则这两方面进行如下改进。
2.2.1 改进的Canny算法
为解决传统区域生长算法生长效率问题,本文采用图像边缘像素点来代替单个像素点进行区域生长。Canny算法是提取图像边缘所广泛运用的算法,他能够识别图像中弱边缘和强边缘并结合位置关系,综合给出图像整体边缘信息,但是该算法会识别噪声点的边缘,导致图像出现空洞现象,严重影响后续算法处理的效果,如图3a所示。为消除Canny算法的噪声空洞,本文采用一种改进的Canny算法。为避免在消除空洞的过程中消除图像边缘主干结构,需要对边缘主干和空洞进行区分。对图像闭合曲线进行像素值累加计算,其中图像边缘主干部分的像素值之和最大,空洞部分像素值之和较小。为进一步筛选图像边缘并去除图像空洞,在改进的算法中引入8连通链码(如图2c所示)。改进的算法具体步骤为:

(a) Canny算法 (b) 改进的Canny算法
步骤1:首先选定每一个图像闭合曲线上任一个像素点作为起点,再选定逆时针方向作为追踪方向,根据选定点的8邻域像素值,挑选其中紧邻中心的像素点作为下一次判断的中心点并使用8连通链码记录这次选定过程的像素点方位;
步骤2:不断进行上一步操作并对图像上每一个闭合曲线的像素点进行累加统计,像素点统计数目为N,根据每次选取下一个像素点的方位记录8连通链码;
步骤3:设立像素点数目阈值Ny,若N未超过阈值,则将此段标记为图像空洞,对此处记录像素点方位的8连通链码反向解码并按照顺序删除像素点。
使用改进后算法输出的图像边缘完整且无明显空洞,如图3b所示。同时将算法获得的边缘像素点纳入区域生长的堆栈中,边缘像素点标记为已生长点,边缘像素点外的点标记为待生长点。
2.2.2 改进的生长准则
传统的区域生长算法在其生长迭代过程中,根据像素点的8邻域像素点的平均灰度值决定,容易导致生长不完全问题[11]。为了改善这种现象,使用一种改进的自适应阈值生长算法进行处理。

(1)

(2)

(3)
若满足式(3),则将区域纳入生长区域中,否则不进行生长。分割后图像如图3c所示。
2.3 字符区域粗定位
芯片是一种微小器件,在没有固定的条件下,它的角度和位置难以把控,所以需要对芯片字符进行粗定位。芯片去除引脚的表面近似矩形,利用最大内接矩形算法,提取空白芯片表面的最大矩形空间,并回传实际坐标和偏转角度给芯片图像,利用仿射变换算法调整角度并提取字符区域。如图3d所示。
2.4 字符区域定位
针对字符区域形状不规则或者有小角度偏转角的问题,本文提出了一种利用Harris角点检测算法和改进的凸包检测算法来定位字符区域。
2.4.1 Harris角点检测
图像中像素值的局部最大峰值构成了Harris角点,它主要用于检测图像中线段的端点或者两条线段交点。本文利用OpenCV函数库中的cornerHarris()函数进行角点检测,提高权重系数以增加角点数量,最后形成归一化的系数图像。如图4a所示。

(a) Harris角点图像 (b) 凸包线形成示意图
2.4.2 改进的凸包线算法
凸包是图形学常用概念,将二维平面的点集最外层连接起来构成的凸多边形称为凸包。利用凸包可以进行多边形的逼近,针对于规则或者不规则的图形都具有良好的效果。Graham算法是常用的凸包检测算法,该算法会以逆时针的顺序找出凸包上的点,但是过多的特征点和过长的运算时间导致精度和效率不高,不能满足现实工业生产要求。为了解决以上缺点,本文提出了一种改进的凸包检测算法,具体算法步骤为:
步骤1:干扰角点筛选。粗定位后的图像存在噪声干扰,这导致使用Harris角点检测算法后的图像不仅拥有字符区域的角点,非字符区域也存在少量干扰角点。为了消除非字符区域的干扰角点,提高定位的精度和效率,利用区域匹配的方法筛选干扰角点。利用构造的区域遍历整张图像,当区域中角点数量小于等于设定角点数量N时,删除该区域中的所有角点。根据获取图像大致的像素尺寸比例,设置长宽比为2∶1的3种区域,尺寸分别为:20×10、30×15、40×20。根据实验效果,最后选择尺寸为40×20的区域并设定角点数量N为4个;
步骤2:关键角点选取。为了提高凸包线形成效率,需要迅速找出凸包线的关键角点。将角点分布于坐标轴上,从图像的上侧、下侧、左侧、右侧向图像中心扫描,直到接触的第一个角点为关键角点,分别为X值最小点Xmin,X值最大点Xmax,Y值最小点Ymin,Y值最大点Ymax。以X值最小点Xmin为基准向图像中心扫描6列像素列,筛选出6列中Y值最小和最大的点Pxi1和Pxa1,同理再分别以X值最大点Xmax,Y值最大点Ymax和最小点Ymin为基准找到Pxi2、Pxa2、Pyi2、Pya2、Pyi1、Pya1。若有重合位置的点则略过,最后一共能获得不大于12个关键角点。根据点位在坐标系的分布,逆时针顺序选取连接,形成初步凸包线。示意图如图4b所示;
步骤3:凸包线构成。为了提高凸包线生成效率,减少算法的计算量,以左上侧凸包线形成为例。以X值最小点Xmin和Pxi1构成矩形对角线绘制矩形空间。对角线将空间分为左上侧区域A和右下侧区域B。提取凸包线外侧区域A中所有的角点,按照逆时针顺序连接,直到区域A中所有的角点纳入所包围区域中,连接方法为:每次将一个角点纳入凸包区域中,并且重新构成凸包线,重新筛选出存在于新凸包线外部的角点,继续上个步骤,最后将左上侧凸包线构成。同理完成剩下区域的凸包线,最终所有的角点都在凸包线包围区域中。如图4c所示;
步骤4:凸包线拟合。完全形成的凸多边形应该约束在一个规则的区域中。本文最后利用最小外接矩形算法对整个区域进行拟合,获取芯片字符定位区域。如图4d所示。
3 实验验证与分析
本文算法主要采用C+ +编程语言并且调用OpenCV库实现,代码实现环境为:Ubuntn18.04,Intel Core i9处理器,软件编译器为Visual Studio 2017。实验将使用传统凸包检测算法、文献[9]算法和本文算法进行定位精度和定位时间的对比。实验图片来自某公司实验平台拍摄图片,为保证对比实验结果准确性,减少随机性带来的误差,芯片图像的拍摄条件应保持一致,偏转角度保持在-5°~5°之间且进行多组实验。设立8个组别,每个组别设置10张图像,其中组别1~4为字符区域规则图像,5~8组为字符区域不规则图像,统计8组图像在3种算法下的定位精度平均值和定位时间平均值。定位精度对比如表1所示。
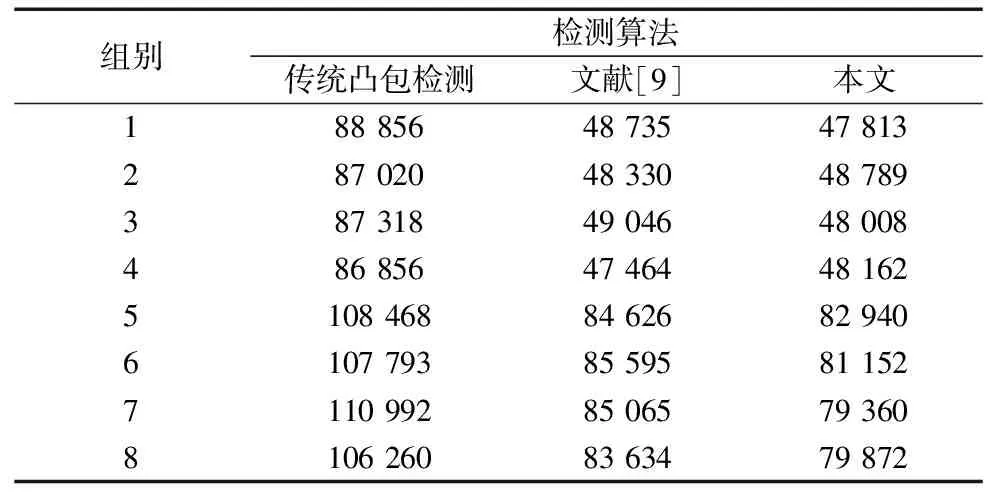
表1 定位精度结果对比 (pixel×pixel/张)
传统凸包检测算法效果图如图5a所示,文献[9]凸包检测算法效果图如图5b所示,本文算法与上述两种算法的对比效果图和右上角局部放大图如图5c和5d所示。

(a) 传统凸包检测 (b) 文献[9]凸包检测
分别检测3种算法在1~8组的定位时间并建立表格。定位时间对比如表2所示。

表2 定位时间结果对比 (ms/张)
实验结果表明,文献[9]算法和本文算法在定位精度和定位时间上都优于传统的凸包检测算法。根据定位精度对比实验结果,针对规则字符区域,文献[9]算法和本文算法都能实现较高精度的定位,但是对于非规则字符区域,本文的算法定位精度较文献[9]算法定位精度提高约5.3%。在定位时间对比方面,本文算法使用了最多12个关键点绘制凸包线比文献[9]使用4个关键点绘制凸包线所使用的时间更少,效率提高约15.4%。综上所述,本文算法在芯片字符区域的定位中表现出了良好的综合性能,整体满足工业生产的实际要求。
4 结论
为解决芯片分选工作中字符区域的定位精度低、效率低的问题,本文提出了一种改进区域生长算法结合改进的凸包检测算法进行字符区域分割和定位。开展了如下工作:
(1) 针对获取图像进行预处理,利用一种改进的Canny算法提取无空洞图像边缘,以芯片边缘像素点为种子点,改进的12邻域加权平均灰度值为生长准则将图像和背景进行分割。
(2)利用最大内接矩形算法提取芯片表面字符区域坐标并提取字符区域,实现字符区域粗定位。
(3)使用Harris角点检测算法提取区域角点,再利用一种改进凸包检测算法进行筛选干扰角点、选取关键角点、凸包线构成、凸包线拟合。
实验结果表明,所设计的定位算法能够定位芯片表面字符区域并拥有一定的精度和效率,能够满足现代工业生产需求。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
北京航空航天大学学报(2019年9期)2019-10-26
民用飞机设计与研究(2019年2期)2019-08-05
少儿美术(快乐历史地理)(2018年7期)2018-11-16
中国军转民(2018年2期)2018-09-10
电子技术与软件工程(2018年10期)2018-07-16
电子科技(2016年12期)2016-12-26
系统工程与电子技术(2016年4期)2016-08-24
