
基于HPO-LSTM的柴油机NOx虚拟预测技术研究
2024-04-29 11:32潘恒斌官维潘明章梁科文涛姜淑君
车用发动机 2024年1期
潘恒斌 官维 潘明章 梁科 文涛 姜淑君
摘要: 在严格的排放法规面前,柴油机后处理系统发挥了不可估量的作用,而获取NO x 排放是后处理系统中SCR装置得以正常工作的前提之一。建立一种使用猎人猎物优化(HPO)算法优化长短期记忆(LSTM)网络的虚拟预测模型,实现对柴油机NO x 排放准确预测,以代替现有物理传感器或作为并行装置监控其运行。试验在柴油机测功机上进行,在高度瞬态的柴油机运行周期内,输入了若干种便于获取且与NO x 形成密切相关的参数至模型中,结果表明:该优化后的网络应用于测试集和全新的未知瞬态工况时,与未优化网络的预测结果相比,RMSE分别提高了29.1%和23.4%, R 2分别大于和接近0.95,预测结果与传感器测量值呈现高度相同的变化趋势,满足了车载运用和准确性的需求,验证了该方法的可行性。
关键词: 柴油机;氮氧化物;预测;猎人猎物优化算法;长短期记忆网络
DOI : 10.3969/j.issn.1001-2222.2024.01.011
中图分类号: TK421.5 文献标志码: B 文章编号: 1001-2222(2024)01-0067-09
自从19世纪末柴油机问世以来,其便以热效率、经济性和可靠性等方面的优势广泛应用于商用车领域和工业机械中。然而柴油机在排放方面的劣势不容忽视,而排放法规日益严苛,2019年7月试点实施的国六排放标准更是对柴油机主要排放物NO x 和PM提出了新的要求。
NO x 虚拟预测是针对车辆实时排放控制要求而发展起来的一种新技术。传统的物理传感器受限于造价高昂和瞬态实时测量性能不佳等因素,在后处理系统中应用存在一些弊端;而NO x 虚拟技术通过构建模型,可以精准地输出目标值与若干输入量之间的关系,具有快速动态响应和离线预测能力。该模型可以是根据经验或模型标定拟合成的多项式函数,亦可是无法获取内部详细演算规律的黑箱模型。这种技术逐渐引起人们的关注,因为它能够弥补传统物理传感器的不足,提供实时且准确的NO x 排放预测值。
精准地预测柴油机主要排放物便可以获取实时的燃烧动态,进而对缸内燃烧进行闭环反馈控制。通过调节喷油器的相关参数改善燃烧状态量,从而达到降低排放的目的。此外,在SCR系统中为了保证NO x 和氨之间处于理想的化学计量比,提高还原反应的效率,避免出现NO x 的不完全还原或氨的过量生成, 需要对下游的NO x 浓度进行精准测量,为尿素喷射量的确定提供依据。综上所述, NO x 虚拟预测技术在后处理系统中的应用具有巨大潜力。
针对NO x 的排放预测,众多学者进行了大量研究。在排放物产生机制的建模方面,Jung Dohoy等[1]将燃油喷雾进行分区,用完整的发动机循环直接预测NO x 排放,结果显示两者变化基本一致,但由于分区较多,循环仿真耗时较多,故计算速度较慢。Andersson等[2]以Zeldovich机理为基础,以喷油和进气参数作为输入还原缸内燃烧过程,但是由于模型过于理想化,仅在部分小负荷工况下预测结果较吻合,其余工况不理想。
在经验拟合建模方面,Lopez等[3]利用缸压信号和进气浓度基于经验公式进行NO x 排放建模,由于输入参数量不足,表征的燃烧有效信息有限,稳态工况下测量误差就达10%,瞬态工况下则更大。Ebner等[4]基于缸压开发NO x 虚拟传感器,模型是一个二次多项式函数,与某型号NO x 物理传感器相比,它在一个循环内的响应时间更快,可预测的工况范围更广,但是其预测精度不佳,仅能反映出NO x 的变化趋势。除多项式回归模型外,利用神经网络预测污染物排放值的方法在过去二十年间得到了广泛研究[5-8]。Atkinson等[9]提出基于循环神经网络(RNN)来估算柴油机和汽油机的瞬态NO x 排放,从结果直观看出对柴油机的预测效果明显优于汽油机。通用汽车公司[10]提出一种基于前馈神经网络算法的NO x 排放预测方法,提取了与NO x 排放相關性较大的5个燃烧状态参数作为输入,以NO x 排放作为输出来训练网络,并在模型中加入动态补偿项以提高加速工况中NO x 排放精度,结果表明总体预测精度仍有待提升。Alcan等[11]采用基于Sigmoid的具有外源输入的非线性自回归(NARX)模型来预测稳态和瞬态循环下给定输入集的NO x 排放,生成不同参数值的模型来分析对参数变化的敏感性,并提出了一种易于解释的映射的参数选择方法来找到最佳建模参数;但试验结果表明,所获得的大多数模型的稳态和瞬态验证精度仅高于80%和70%。Tang等[12]以油耗、负荷和柴油混合比为输入参数,建立了生物柴油发动机排放性能的双隐层BP神经网络模型,得到了NO x 排放预测值和试验值随燃油消耗量的变化曲线,结果表明NO x 排放的预测结果在燃油消耗量低时与试验结果吻合良好,相关系数 R 很高,但是该预测值会随着燃油消耗量的增加而逐渐偏离试验值,仅能确保两者趋势一致。
在前馈神经网络中,参数传递具有单向性,最终输出只依赖于当前输入,该网络处理的对象是具有一定因果关系的一组随机变量之间的数值关系。而发动机输入参数为时序数据,长期处理此类数据往往具有局限性。在深度学习中,模型的选择取决于数据类型与研究目的,以循环神经网络(RNN)为代表的模型常用于处理该类序列数据。RNN神经元不仅可以接收其他神经元的信息,还能从自身提取信息,这就形成了有环路的网络结构,反馈值随时间反向传播,算法按照时间逆序将误差往前传递作为 附加网络进行输入。考虑到RNN网络处理长时间序列的局限性,本研究使 用RNN模型的改进LSTM模型,将其离线训练完毕后对柴油机下游的NO x 排放进行实时的虚拟预测。此外,猎人猎物优化算法是近两年提出的智能优化算法,具有优化迭代迅速、收敛效果显著的优势,该算法的使用旨在高效准确寻找全局最优的LSTM超参数组合,避免单一模型陷入局部最优解,最终达到提高预测精度的目的。
1 试验
1.1 试验平台
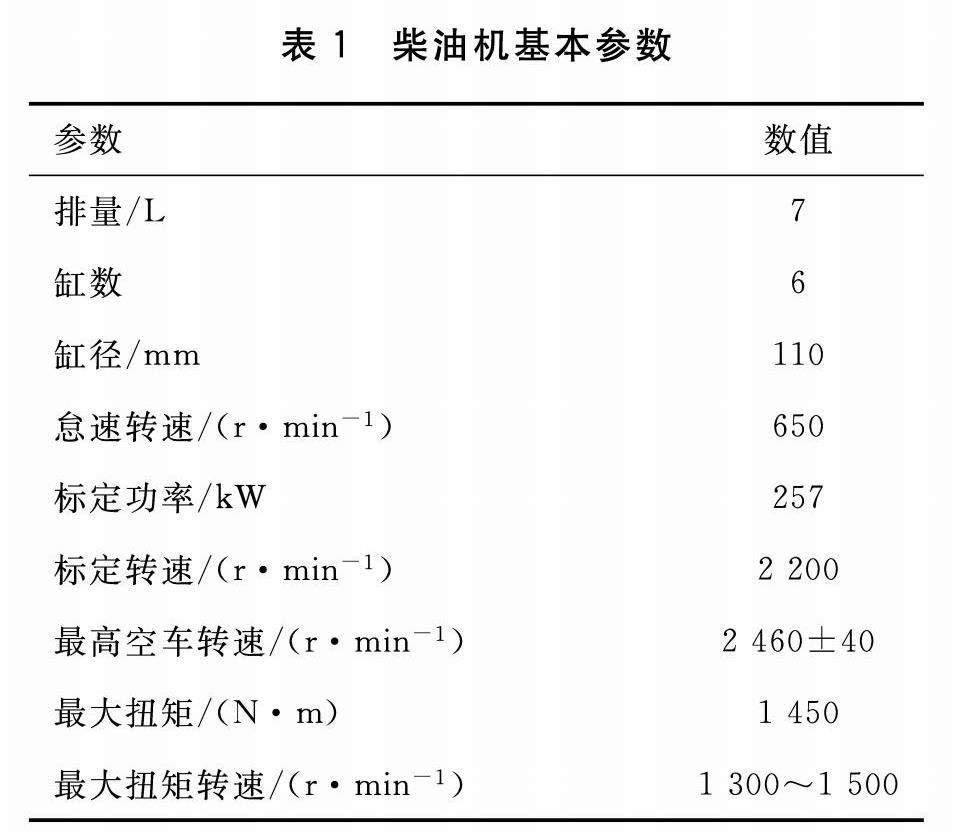
试验台架由增压水冷式高压共轨柴油机、瞬态交流电力测功机、AVL735油耗仪、AVL PUMA台架测试系统和AVL AMA气体排放分析仪等组成。柴油机的基本参数如表1所示,试验台架示意见图1。
1.2 工况选取及数據获取
根据中国现行的污染物排放限值及测量的相关法规进行了世界统一瞬态试验循环(WHTC)测试,全程1 800 s。为了防止数据量过少产生过拟合或数据量太大模型收敛时间长的情况,设定测试采样频率为0.1 s,可获取约18 000个瞬态工况点的数据。此外为了验证模型的泛化能力,以欧洲瞬态循 环(ETC)测试作为验证工况,全程同样1 800 s,采样频率仍为0.1 s,得到约18 000个瞬态工况点数据。
需要指出的是,柴油机SCR系统启动温度约为200 ℃,柴油机在冷起动状态下尿素喷射装置处于禁用状态,此时估算NO x 的排放值是无意义的。因此在进行循环测试之前,对柴油机在最高转速点和 转矩点进行了约5 min的充分预热,紧接着操控台架进入WHTC循环程序,与此同时开始记录数据。
上述数据是通过标定套件(INCA-ETAS数据采集和MDA数据分析)来获取的,结合现有的传感器等设备采集了8个预选输入变量:进气流量、进气总管下游氧含量、废气温度、进气温度、增压压力、轨压、转速、当前循环喷油量,还采集了需预测的输出量NO x 排放值。
2 LSTM 模型建立
2.1 RNN 循环神经网络
如前所述,前馈神经网络中由于信息的单向传递性,各输入和输出之间彼此相互独立,其数值在时间线上并无关联,且数据的顺序具有任意交换性。该特点使得模型加快了获得各输入与输出间的非线性关系,但同时会牺牲模型拟合的准确性。特别是对于柴油机NO x 排放值这类典型的时间序列,它在某瞬态工况点是受过去连续时刻内多因素的共同作用,用前馈神经网络处理时无法直接利用过去的信息,因此需要采用以RNN为代表的神经网络模型处理时间序列预测的问题。RNN的结构中隐藏层之间有节点的连接,当前隐藏层内的神经元由此刻的输入以及前一个隐藏层的输出组成,构成了闭环的模型,可存储过去时刻的信息,使其具有短期记忆功能,这就确保了过去时刻与当前时刻的关联性。
然而RNN模型存在以下的缺点:首先是某一时刻的输出只与上一时刻有关,但实际上柴油机的燃烧是一种动态过程,其NO x 在某一时刻的排放是过去连续时刻多变量累积的结果;其次在训练的过程中随着输入量的增多网络结构会展开得更长,反向传播算法无法避免产生梯度消失和梯度爆炸的问题[13]。RNN神经网络仅具备短期记忆功能,而按照柴油机的连续运行时间所构成的工况点是较长时间序列,因此引出了RNN模型的改进结构——LSTM模型。
2.2 LSTM 长短期记忆网络
LSTM模型是RNN模型的变体,但特殊的结构使其具备处理长期和短期时间序列的功能。它总体结构与RNN类似,只是隐藏层有所差别且更为复杂,它的隐藏层结构如图2所示。
由图2可知, LSTM隐藏层中创造性地提出了4个交互层,即包括3个Sigmoid和1个tanh的激活函数,前者的功能是把从前的输入值压缩到0~1之间,“1”即为保留,“0”即为舍弃,这样可达到选择性通过信息的目的。而长时间的记忆功能的实现是归功于处于上方从左贯通至右的“传送带”,这条线上只有简单的线性交互层,确保了过去信息的流通并基本保持不变。
LSTM的隐藏层包括遗忘门、输入门、输出门和记忆细胞单元,它们各自的激活函数对过去的信息进行筛选后汇入至“传送带”继续进行信息的传递。从左至右各单元及涉及的公式如下:
1) f t 是遗忘门,用于决定 t -1时刻的信息量 h t-1 有多少能流入到 t 时刻状态 C t ,公式为
f t=σ W f · h t-1,x t +b f 。 (1)
式中: σ= 1 1+e-x ; W f是权重矩阵,其维度由输入和隐藏层的维度决定; b f是偏置项。
2) i t 是输入门,用于决定 t 时刻的输入量 x t 有多少能保留至 C t ,公式为
i t=σ W i · h t-1,x t +b i 。 (2)
3) t 是候选记忆细胞单元,输入量经过tanh函数生成了一个候选值向量,公式为
t= tanh W C· h t-1,x t +b C 。 (3)
4) C t 是记忆细胞单元, t 时刻的短时记忆 t 和历史时刻的长记忆 C t-1 会被共同加入到这个状态中,遗忘门的存在可以使长久前的记忆得以保留,输入门的存在使得 t 时刻关键的信息被读取,这就是LSTM隐藏层结构的关键所在,其公式为
C t=f t · C t-1+i t · t 。 (4)
5) o t 是输出门,用于决定 t 时刻的记忆细胞单元 C t 的信息有多少能输出到此刻的隐藏层输出 h t ,其公式为
o t=σ W o · h t-1,x t +b o 。 (5)
6) LSTM隐藏层最终输出 h t ,公式为
h t=o t · tanh C t 。 (6)
2.3 建立 LSTM 模型
2.3.1 数据预处理与预选变量的选取
测量设备长时间使用会造成短暂异常或失灵,因而产生较大测量误差,为了不让这些异常值对模型预测结果造成影响,务必对其进行剔除。
在工程上使用3 σ 准则处置:设一组数据为 X 1, X 2,X 3,…X n ,平均值为 ,与均值的差为 d i= X i- (i=1,2,…n) ,即有下式:
σ= ∑ n i=1 d2 i n-1 。 (7)
若某数据与均值的差满足 d i >3σ ,就认为此为粗大值,须予以剔除。
此外,各输入参数间量级差别过大及量纲的差异性减缓了模型迭代处理的速度,故还需要对输入量进行归一化处理,使所有的值落在[0,1]区间。
X i= X i-X min X max -X min 。 (8)
式中: X i 是归一化后的值。在最后输出预测值之前还需要返回原量纲的值,即反归一化:
X i=X i X max -X min +X min 。 (9)
本次采集数据共选择了8个对NO x 生成具有潜在影响的预选变量,但对于神经网络而言,输入的参数种类过多会造成维度太大,影响处理速度,反之则会影响模型预测精度。为了平衡其中的利弊,实践中一般选择5个左右更具典型性的预选变量作为输入。在统计学中,相关系数是衡量两种变量间相关性程度的指标,其取值范围是[-1,1],绝对值越大时相关性程度越高,常见的有Pearson系数和Spearson系数。Pearson系数对数据集本身要求较高,且强调的是两个数据集间线性相关的程度,而此次分析中关注的是NO x 与其他预选变量间的单调关系,而非严格的线性关系,因此均采用Sperson系数进行分析,得到了如图3所示的相关性热图。
以图3中的关联度排序作为依据,选取增压压力、进气流量、廢气温度、循环喷油量和轨压作为输入。尽管转速的关联度排名从理论上得出的结论是靠后的,但是该指标反映柴油机在任一时刻的运转情况,是无法替代的重要参数,因此也需将其作为输入,至此共有6个预选变量被选取作为模型输入参数。
2.3.2 训练集与测试集的划分
训练集选取的原则是选择的范围尽可能涵盖柴油机运行的典型工况,以复现出任何瞬态,使网络具有更佳的泛化能力。WHTC循环测试是联合国欧洲经委会GRPE小组制定的全球技术法规第4号定义的瞬态发动机测功表,涵盖了全球统一的重型认证发动机尾气排放程序,再现了欧盟、美国和日本等国家和地区具有代表性的驾驶工况。因此选用采集的WHTC循环的18 492个瞬态工况点对应的6个预选变量,将前150 s符合粗大误差的异常工况点剔除后,剩余的工况点按照70%、30%划分为训练集和测试集(见图4)。训练方法采用自适应时刻估计(adam)学习算法。
2.3.3 基于网格搜索式的参数确定
在LSTM网络中,参数可分为模型参数和超参数两种:前者是在模型训练时随着梯度下降法自动更正的参数,包括隐藏层各个门的权重矩阵及偏倚系数等;后者指的是训练前就已经被设置为某一固定值的参数,包括LSTM层数、每层神经元数量、最大迭代次数和初始学习率等。超参数是模型训练过程的依据,因此对其进行最优化的选取,可显著提高模型学习的效果,以获得更佳的预测能力。
网格搜索法是确定超参数的手段之一,通常是每种超参数均在合理数值范围内且按照一定间隔进行选取,并进行若干次训练,从而尽可能遍历多种超参数组合,本质上是一种穷举法[14]。最后用评价指标评价,进而选择最优项。常用的评价指标有:均方根误差RMSE、平均绝对误差MAE、决定系数 R 2,具体公式如式(10)~式(12)所示。
RMSE= 1 n ∑ n i=1 y i-y ~ i 2 , (10)
MAE= 1 n ∑ n i=1 y i-y ~ i , (11)
R2=1- ∑ n i=1 y i-y ~ i 2 ∑ n i=1 y i-y i 2 。 (12)
式中: y i 是实际值; y ~ i 是预测值; n 是工况点数目。
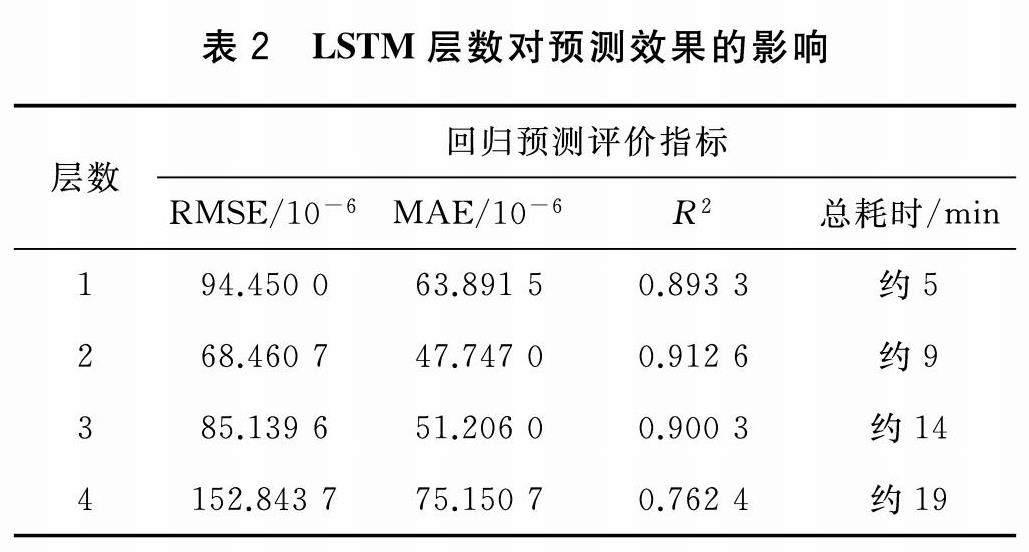
第一步确定LSTM层数,当按经验指定其余超参数并保持其不变的情况下,从第1层开始进行训练并在测试集上进行预测。重复若干次并记录每次预测评价指标,取平均值后继续逐一增加层数,重复此步骤。一共进行了4层的训练,得到的评价指标如表2所示。
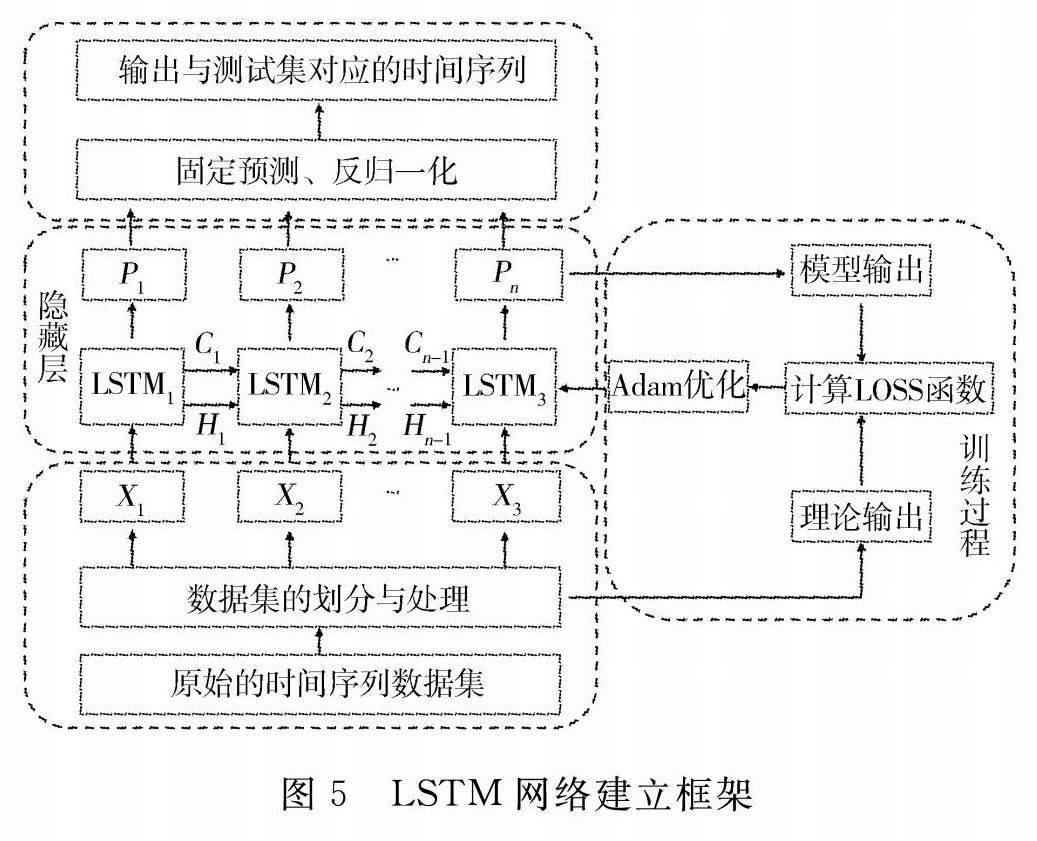
由表中数据可知,当层数为2时RMSE和MAE值最低, R 2最接近1,且总耗时适中,因此LSTM层数设定为2。对于其余的超参数,在合理数值范围内进行多层网格搜索:每层神经元数量从[20,50]按10的步长搜索;初始学习率从[0.002,0.005]按0.001的步长搜索;最大迭代次数从[150,300]按50的步长搜索。由此遍历了64次搜索后,最终确定当每层神经元数量均为40,初始学习率为0.004及最大迭代次数为250时评价指标最佳。整个网络的建立过程如图5所示。
按照上述方式选取的超参数组合训练完毕后,模型应用在测试集的预测效果和残差统计分布区间如图6和图7所示。由图6和图7可见,模型初步具备了预测总体趋势的能力。仅66%的工况点落在[-50,50]的残差区间,且在尖端点上误差仍然较大,这也是仍有8%的工况点落在[-100,100]区间外的主要原因。若将训练完毕的网络模型用于全新工况的预测,结果将无法达到预期,这体现出网格搜索法的局限性。由于待选择的超参数有4组,每组均有选取的范围,且搜索步长有一定的间隔,所以极有可能无法捕捉到全局最优组合,得到的只是局部最优解。综上,采用一种优化算法——猎人猎物算法(HPO)优化LSTM的超参数,通过该算法搜寻目标范围内最优的超参数组合,使模型得到令人满意的预测精度。
2.3.4 基于猎人猎物优化算法的超参数确定
猎人猎物优化算法(HPO)是Naruei[15]等在2021年提出的基于种群优化算法,灵感来源于大自然一个群体中捕食者捕食猎物的行为。算法的实现步骤如下:
1) 将所有群体成员的初始位置随机设为 x = x 1 ,x 2 ,…x n ,同时各自的目标函数设置为 O = O 1,O 2,…O n ;其中每个成员的位置 x i 与适应度 O i 由式(13)和式(14)确定:
x i= rand p,d ub-lb +lb , (13)
O i=f x → 。 (14)
式中: p 是种群个数; d 是需优化的超参数个数; ub 和 lb 分别是各超参数的上下界; f(x → ) 在该算法中是一个求解模型中训练集RMSE的函数,它是整个算法运行的依据,显然最终的目标是求解适应度函数的最小值,并在最大迭代次数后输出。实践中无法通过一次迭代获取超参数的最优组合,因此定义了由探索和开发两个步骤组成的多次搜索机制:探索强调的是算法随机搜索的行为,确保了算法不会陷入局部最优解;开发是在探索到目标区域时停止对全局的随机搜索,进一步对该区域深度挖掘。
2) 针对猎人的更新机制,该算法提出式(15):
x i,j t+1 =x i,j t +0.5[ 2CZP pos( j)-x i,j t + 2 1-C Zμ (j)-x i,j t ] 。 (15)
式中: x i,j(t+1) 和 x i,j(t) 分别是猎人下一次迭代位置和当前位置; P pos (j) 是猎物位置; μ (j) 是种群所有成员位置的平均值; Z 是由式(16)决定的适应性参数。
P=r 1 <C; IDX = P= =0 ;
Z=r 2 IDX +r 3~ IDX 。 (16)
式中: r 1 和 r 3 是[0,1]内的随机向量; r 2是[0,1]内的随机数; P 和IDX是满足等式条件的索引值; C 是决定了探索或开发两者占比的平衡参数,由式(17)计算得到。
C=1-i 0.98 I Max 。 (17)
式中: i 是此时迭代次数; I Max是最大迭代次数。从开始至迭代完全结束 C 的值将从1减少到0.02,这意味着算法由探索至开发的逐渐转变。
3) 为了求出猎物的位置 P pos,先根據式(18)计算所有成员位置的平均值 μ ,
μ= ∑ n i=1 x i n ; (18)
再根据式(19)计算猎物群体的 n 维欧氏距离,
D i = ∑ n j=1 x i,j-μ j 2 ; (19)
最后根据上文提及的猎人捕食的思维,选择距离群体最远的个体作为目标猎物,因此有
P pos =x i 。 (20)
式中: i 是 D(i) max对应的指标。为了缩短算法收敛时间,根据实际狩猎场景提出了衰减机制:
k best=ceil C×p 。 (21)
式中: p 是种群个数; k best在开始时为 p ,结束时为1,为此改用式(22)得到猎物位置。
P pos =x j 。 (22)
式中: j 是 D(k best) max中括号内对应的指标。
4) 如前所述,目标猎物意识到被猎人锁定后会尽力逃脱至安全位置,提出式(23)更新猎物位置。
x i,j t+1 =T pos( j)+CZ cos 2π r 4 × T pos( j)-x i,j t 。 (23)
式中: x i,j(t+1) 和 x i,j(t) 分别是猎物下一次迭代位置和当前位置; T pos (j) 是安全位置; r 4是[0,1]内的随机数。
5) 至此,猎人和猎物的初始位置及更新机制已给出,最后一步是给出一个判断依据,使算法选择走猎人或是猎物的路线。因此,引入一个取值在[0,1]内的随机数 r 5和一个设值为0.1的选择参数 β 。当 r 5< β 时,算法走猎人的路线,即由式(15)更新位置;反之算法走猎物路线,即由式(23)更新位置。
結合目前的数据规模,为避免程序运行时间过长,设定该算法的种群数量为20,最大迭代次数为40;对于待优化的各超参数上下限,每层神经元数量是[10,200],初始学习率是[0.001,0.200],最大迭代次数是[100,300]。优化的流程如图8所示。
当优化程序运行完毕后,可以得到如图9所示的进化曲线。图9表明当迭代进行至15次时适应度衰减至最低点并达到稳定,此时对应的超参数如下:第一、二隐藏层神经元数目为100和30,初始学习率是0.015,最大迭代次数是255。随后将上述训练完毕的网络模型应用至测试集中,所得到的在测试集上的预测效果和残差分布见图10和图11。
从测试集的预测结果直观看出,当采用HPO优化得出超参数组合,模型对数据的拟合效果有显著提升,尖端点的预测效果得到明显改善。从评价指标来看, R 2由原来的0.927 8提高到0.963 5,RMSE由原来的65.439 8优化到46.347 9,优化了29.12%,这表示模型对于输入数据的理解和学习能力更强,可更好拟合真实情况。而从直方图得知,落在[-50,50]残差区间的工况点从66.2%提升至了85.5%,左右两端的长尾现象有所缓和,离群值数量已然降低。结果表明:HPO算法的优势在于由各超参数的上下限决定的探索空间内,猎人或猎物可以在该范围进行随机性移动和选择,并且衰减机制的存在保证了算法必定会收敛,每一次迭代的超参数组合会被保留,并从中选择适应度最小的作为全局最优解输出。
3 结果对比与评估
为了进一步验证模型的泛化能力,在测试集的基础上引入另一种全新的工况,即ETC工况,以此测试如前所述的两种训练完毕的模型应对未知工况的预测精度。与此同时,建立一个相同网络架构的BP模型与现有模型进行横向对比,将其层数、每层隐藏层的神经元数目、最大迭代次数和初始学习率等设置成与优化后的LSTM模型一致;再建立一个NARX模型,将其输入和输出延迟步数设定为1,隐藏层结构也与优化后的LSTM模型一致,两者的训练集均为图4中WHTC工况选定的部分。4种模型的预测结果、残差绝对值构成的散点图以及评价指标如图12和表3所示。
由预测图和评价指标得知,BP模型和NARX模型在面对长时间序列问题时预测情况较不理想,大于400的残差值占有相当的比例。这是由于这两种模型缺乏门控机制和记忆单元导致无法捕捉和存储长期依赖关系,以及在反向传播算法训练时可能遇到了梯度消失或爆炸的问题,这些因素都将导致预测精度的降低。对于未知工况,LSTM网络的泛化能力得到了有力证明,预测精度的下降在合理范围内,尤其是优化后的LSTM网络其RMSE比未优化的提高了23.4%, R 2接近于0.95,残差的绝对值普遍在200以内且离群值的比例占比很低,预测值与传感器实测值的轨迹相当近似。
4 结束语
柴油机NO x 排放是典型的连续型数值变量,因此提出了应用于时序预测的LSTM网络模型。将各预选变量对NO x 产生及变化的相关程度排序,选取了废气温度、增压压力、进气流量、轨压、循环喷油量和转速作为输入变量。采用了网格搜索法对LSTM网络的各超参数进行选取,并对WHTC工况剔除异常值的工况点进行训练和测试,初步验证了模型的预测能力,结果表明在测试集上取得了较为一般的预测精度。
为了进一步提高模型的预测准确性,避免陷入局部最优解,提出了HPO算法对LSTM超参数组合进行更为合理的选择。将使用HPO优化得到的组合模型再次应用于WHTC工况的测试集进行验证,结果表明此次的模型预测精度取得了进一步的改善, R 2由原来的0.927 8提高到0.963 5,RMSE也优化了29.1%。
最后引进ETC工况,将6个变量分别作为BP模型、NARX模型、网格搜索得到的LSTM模型和经HPO优化后的HPO-LSTM模型的输入。经对比得出BP模型和NARX模型预测效果有限,而HPO-LSTM模型在该工况下仍保持良好的预测精度,与未优化的LSTM模型相比, R 2由原来的0.908 3提高到0.949 5,RMSE优化了23.4%,具备预测未知瞬态工况下NO x 排放的能力。
参考文献:
[1] Jung Dohoy,Assanis Dennis.Quasidimensional Modeling of Direct Injection Diesel Engine Nitric Oxide,Soot,and Unburned Hydrocarbon Emissions[J].ASME J. Eng. Gas Turbines and Power,2006,128(2):388-396.
[2] Ericson C,Westerberg B,Andersson M,et al.Modelling diesel engine combustion and NO x formation for model based control and simulation of engine and exhaust aftertreatment systems[C].SAE Paper 2006-01-0687.
[3] Arrègle Jean,López J,Guardiola Carlos,et al.Sensitivity Study of a NO x Estimation Model for On-Board Applications[C].SAE Paper 2008-01-0640.
[4] Winkler-Ebner B,Hirsch M,Del Re L,et al.Comparison of virtual and physical NO x -sensors for heavy duty diesel engine application[J].SAE International Journal of Engines,2010,3(1):1124-1139.
[5] 周斌,谭达明,魏道远,等.基于神经网络的内燃机排放预测方法的研究[J].内燃机学报,2001,19(4):361-364.
[6] Perhinschi M G,Wayne W S,Clark N,et al.Neural Network Modeling of Emissions from Medium-Duty Vehicles Operating on Fisher-Tropsch Synthetic Fuel[C].SAE Paper 2007-01-1080.
[7] 胡杰,林峰,王天田,等.基于神经网络最小偏二乘法的柴油机NO x 排放预测模型[J].内燃机学报,2015,33 (6):510-515.
[8] 邹浪,何超,李加强,等.基于机器学习的柴油机颗粒物浓度预测[J].车用发动机,2020(2):84-92.
[9] Atkinson C M,Long T W,Hanzevack E L.Virtual sensing: a neural network-based intelligent performance and emissions prediction system for on-board diagnostics and engine control[J].Progress in Technology,1998,73(301-314):2-4.
[10] Wang Y Y,He Y,Rajagopalan S.Design of Engine-Out Virtual NO x Sensor Using Neural Networks and Dynamic System Identification[J].SAE International Journal of Engines,2011,4(1):828-836.
[11] Alcan G,Unel M,Aran V,et al.Predicting NO x emissions in diesel engines via sigmoid NARX models using a new experiment design for combustion identification[J].Measurement,2019,137:71-81.
[12] Tang D,Xu Y C,Yao S D,et al.Prediction of emission performance in a diesel engine fuelled with bio-diesel based on double-hidden layer BP neural network[J].Applied Mechanics and Materials,2013,278:370-373.
[13] 梁宏涛,刘硕,杜军威,等.深度学习应用于时序预测研究综述[J/OL].计算机科学与探索:1-21.[2023-05-27].http://kns.cnki.net/kcms/detail/11.5602.TP.20230310.0857.002.html.
[14] 王鑫,吴际,刘超,等.基于LSTM循环神经网络的故障时间序列预测[J].北京航空航天大学学报,2018,44(4):772-784.
[15] Naruei I,Keynia F,Sabbagh Molahosseini A.Hunter-prey optimization: Algorithm and applications[J].Soft Computing,2022,26(3):1279-1314.
NO x Virtual Prediction Technology of Diesel Engine Based on HPO-LSTM
PAN Hengbin1,GUAN Wei1,PAN Mingzhang1,LIANG Ke1,WEN Tao1,JIANG Shujun2
(1.School of Mechanical Engineering,Guangxi University,Nanning 530004,China;2.Wuxi Institute of Technology,Wuxi 214121,China)
Abstract: In the face of strict emission regulations, the diesel engine post-treatment system plays an immeasurable role, and the acquisition of NO x emissions is one of the prerequisites for the normal operation of SCR device in the post-treatment system. A virtual prediction model that used hunter-prey optimization (HPO) algorithm to optimize long short term memory(LSTM) network was established to accurately predict NO x emissions of diesel engine in place of existing physical sensors or as a parallel device to monitor their operation. The test was carried out on a dynamometer of diesel engine. During the highly transient operation cycle of diesel engine, several parameters that were easy to obtain and closely related to NO x formation were input into the model. The results show that, compared with the prediction results of non-optimized network, RMSE increases by 29.1% and 23.4%, and R 2 is greater than and close to 0.95 respectively when the optimized network is applied to the test set or to a new unknown transient condition. The prediction results show a highly identical trend with the measured values of sensor, which meets the requirements of on-board application and accuracy and hence verifies the feasibility of this method.
Key words: diesel engine;NO x ;prediction;hunter-prey optimization algorithm;long short term memory network
[編辑: 潘丽丽]
收稿日期: 2023-07-26; [HT6H]修回日期: 2023-10-26
基金项目: 国家自然科学基金面上项目(22172038);广西重点研发计划 (桂科AB21220059,桂科AB22080085)
作者简介: 潘恒斌(1999—),男,硕士,主要研究方向为柴油机排放控制;601570994@qq.com。
通讯作者: 姜淑君(1980—),女,高级工程师,硕士,主要研究方向为内燃机燃烧排放;956671743@qq.com。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
汽车与新动力(2019年5期)2019-11-07
汽车观察(2019年2期)2019-03-15
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
汽车与新动力(2015年1期)2015-02-27
汽车与新动力(2013年6期)2013-03-11
汽车与新动力(2012年4期)2012-03-25
汽车与新动力(2012年2期)2012-03-25
