
蒙陕接壤区煤层顶板涌水水源智能判别方法
2024-04-28 07:05孙钧青曾一凡尚宏波王甜甜
煤田地质与勘探 2024年4期
王 皓,孙钧青,曾一凡,尚宏波,王甜甜,乔 伟
(1.煤炭科学研究总院,北京 100013;2.中煤科工西安研究院(集团)有限公司,陕西 西安 710077;3.陕西省煤矿水害防治技术重点实验室,陕西 西安 710077;4.中国矿业大学(北京) 国家煤矿水害防治工程技术研究中心,北京 100083)
黄河流域中段蒙陕接壤区是我国重要的煤炭生产基地,在能源保供中具有不可替代的战略地位[1-2]。区域内煤炭资源高强度开采下采动裂隙发育并沟通上覆多个含水层,不可避免地引发顶板水害问题[3-4],因此,煤层顶板水害防治一直是蒙陕接壤区矿井安全生产亟待解决的难题。快速准确地判别顶板涌水水源是煤层顶板水害防控的前提[5-6],传统的矿井水源判别方法主要有水位观测法、水化学法[7]、示踪法[8]等。
近年来,随着数学理论和计算机的发展,利用水化学法进行水源判别的方法日趋成熟,主要集中在多元统计法[9]、非线性分析法[10]、模糊数学[11]和机器学习[12]等领域。Cui Mengke[13]、曲兴玥[14]和Zhang Haitao[15]等分别利用动态权重、马氏距离和Fisher 判别法构建了矿井涌水水源判别模型。与传统方法相比,机器学习算法在处理非线性、高维数据中更具优势,且具有较强的自适应性[16]。韩忠[17]、纪卓辰[18]等分别将主成分分析法(Principal Component Analysis,PCA)和BP(Back Propagation,BP)神经网络、Logistic 回归方法相结合,使得判别更加快速准确;郝谦等[19]将随机森林(Random Forest,RF)判别模型与支持向量机(Support Vector Machine,SVM)、极限学习机(Extreme Learning Machines,ELM)判别模型进行比较,证明了RF 具有更高的预测精度和鲁棒性。机器学习问题常涉及到寻找全局最优解或近似最优解,而传统的单点优化方法容易陷入局部最优解,因此,常用群体智能优化算法对机器学习模型进行优化[20]。侯恩科[21]、于小鸽[22]等分别使用自适应粒子群算法(Adaptive Particle Swarm Algorithm,APSO)和自适应鲸鱼算法(Ameliorative Whale Optimization Algorithm,AWOA)对ELM 神经网络进行了改进,判别效果都得到了显著增强;黄敏[23]、胡友彪[24]等分别使用混沌麻雀搜索和粒子群算法对RF 模型进行了改进。人工鱼群算法(Artificial FishSwarms Algorithm,AFSA)作为一种新型的智能仿生算法,具有原理简单、搜索能力强等优势,在诸多领域均有着广泛应用[25-26]。Jia Dongyao 等[27]使用AFSA 改进RF,提高了细胞的分类性能;李旭鹏等[28]建立了基于AFSA-RF 的流型识别模型,其识别精度与稳定性高于未优化的RF 模型。
因此,笔者以蒙陕接壤区的3 个矿井为研究对象,将常规无机指标和总有机碳(Total Organic Carbon,TOC)、UV254、水样溶解性有机质(Dissolved Organic Matter,DOM)荧光光谱等有机指标作为判别依据,采用PCA对数据集进行特征降维,使用人工鱼群算法对随机森林的子树数目、树深和内部节点分裂所需的最小样本数进行寻优,通过引入遗传机制提高AFSA 的全局搜索能力,建立PCA-AFSA-PF 煤层顶板涌水水源判别模型,以提高模型预测性能,以期为煤层顶板涌水水源的准确判别提供新方法。
1 研究区地质与水文地质概况
研究区域为蒙陕接壤区从东北至西南走向的3 个典型矿井:A 矿、B 矿和C 矿(图1)。研究区矿井位于鄂尔多斯盆地之次级构造单元陕北斜坡及伊陕单斜区,总体形态呈向NW 或NWW 微倾的单斜构造或近水平地层,无落差较大的断层和明显的褶皱构造,无岩浆岩活动痕迹;岩体结构以整块或层状结构为主,饱水砂层影响岩体稳定,局部地段易发生矿山工程地质问题。此外,研究区地处毛乌素沙漠,地表绝大部分被第四系松散沉积物覆盖,地貌以风蚀风积沙漠丘陵和沙漠滩地为主,容易接受地表水和大气降雨补给;总体地势北部较高,向南逐渐降低;区域内较大水系有无定河及其支流纳林河。
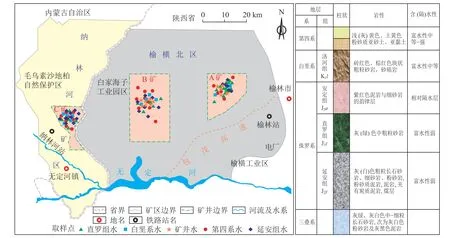
图1 研究区位置及地层Fig.1 Location and stratigraphic column of the mines in the Inner Mongolia-Shaanxi border region
研究区矿井的含煤地层均为侏罗系延安组,地层结构相似(图1),其主要含(隔)水层自上而下为:第四系孔隙含水层,白垩系洛河组孔隙-裂隙含水层,侏罗系安定组相对隔水层,侏罗系直罗组和延安组裂隙含水层[29]。第四系孔隙发育,富水性强;白垩系结构疏松且易于接受第四系的补给,富水性相对较好;直罗组与白垩系之间有安定组相对隔水层且裂隙不发育,富水性较弱;延安组裂隙不发育,且泥质含量随埋深的增加而增加,渗透性逐渐变差。
研究区矿井在建设过程中存在煤层及其直接顶板富水的问题,煤矿掘进工程遇到一定阻碍;未来回采过程中直接充水水源为顶板砂岩裂隙水,间接充水水源为白垩系砂岩孔隙裂隙水;周边矿井基建阶段主要防治水问题集中在井巷工程接近煤层顶板及煤层过程中涌水量较大,顶板富水性较强等方面,可以预见,后续施工过程中会面临松散沙层、白垩系志丹群、直罗组砂岩含水层一系列防治水问题。
因此,本文以第四系含水层、白垩系含水层、直罗组含水层和延安组含水层为研究对象,利用水化学分析和机器学习等手段,研究不同含水层水样水质之间的差异。
2 水化学测试实验与分析
2.1 水样采集与测定
本次共采集研究区水样92 组,包含地下水水样80 组,矿井水水样12 组。地下水水样自上而下包括第四系水样22 组、白垩系水样11 组、直罗组水样24 组和延安组水样23 组;矿井水水样12 组用于判别模型的验证。使用2.5 L 聚乙烯采样瓶进行水样的采集,严格执行装水、密封、贴标等采样步骤,采集后及时进行测定与分析。
参考现行的GB/T 14848-2017《地下水质量标准》[30],利用电感耦合等离子体质谱仪,对水样的常规指标进行检测,选取K++Na+、Ca2+、Mg2+、Cl-、S、HC和TDS 这7 项无机指标进行后续分析。
需要测定的有机指标为TOC、UV254和DOM 三维荧光数据。使用multi N/C 2100 专家型总有机碳/总氮分析仪进行TOC 的检测;使用Evolution 60 紫外可见光度计检测254 nm 处的紫外吸收值。使用荧光分光光度计(HITACHI F-7000)进行DOM 荧光数据的提取:设置仪器扫描速度为1 200 nm/min;激发波长(Excitation Wavelength,EX)为200~420 nm,间隔为5 nm;发射波长(Emission Wavelength,EM)为240~600 nm,间隔为2 nm;为去除环境噪声,使用超纯水作为空白,校正水的拉曼散射。
2.2 水化学特征
DOM 荧光图谱包含5 个区域,分别表示5 种有机物类型(图2),其中,Ⅰ区代表酪氨酸,Ⅱ区代表色氨酸,Ⅲ区代表疏水性有机酸,Ⅳ代表含色氨酸的类蛋白质,Ⅴ区代表海洋性腐植酸[31]。利用平行因子法从所有水样的荧光数据中提取出2 种组分,如图2 所示,经分析:组分1(C1)具有1 个激发峰(265 nm)和1 个发射峰(400 nm),包含了疏水性有机酸和类腐植酸,且以后者居多;组分2(C2)具有4 个激发峰(225 nm/250 nm/280 nm/295 nm)和1 个发射峰(308 nm),包含了酪氨酸和含色氨酸的类蛋白质。水样各指标的检测结果及提取的有机组分浓度见表1。
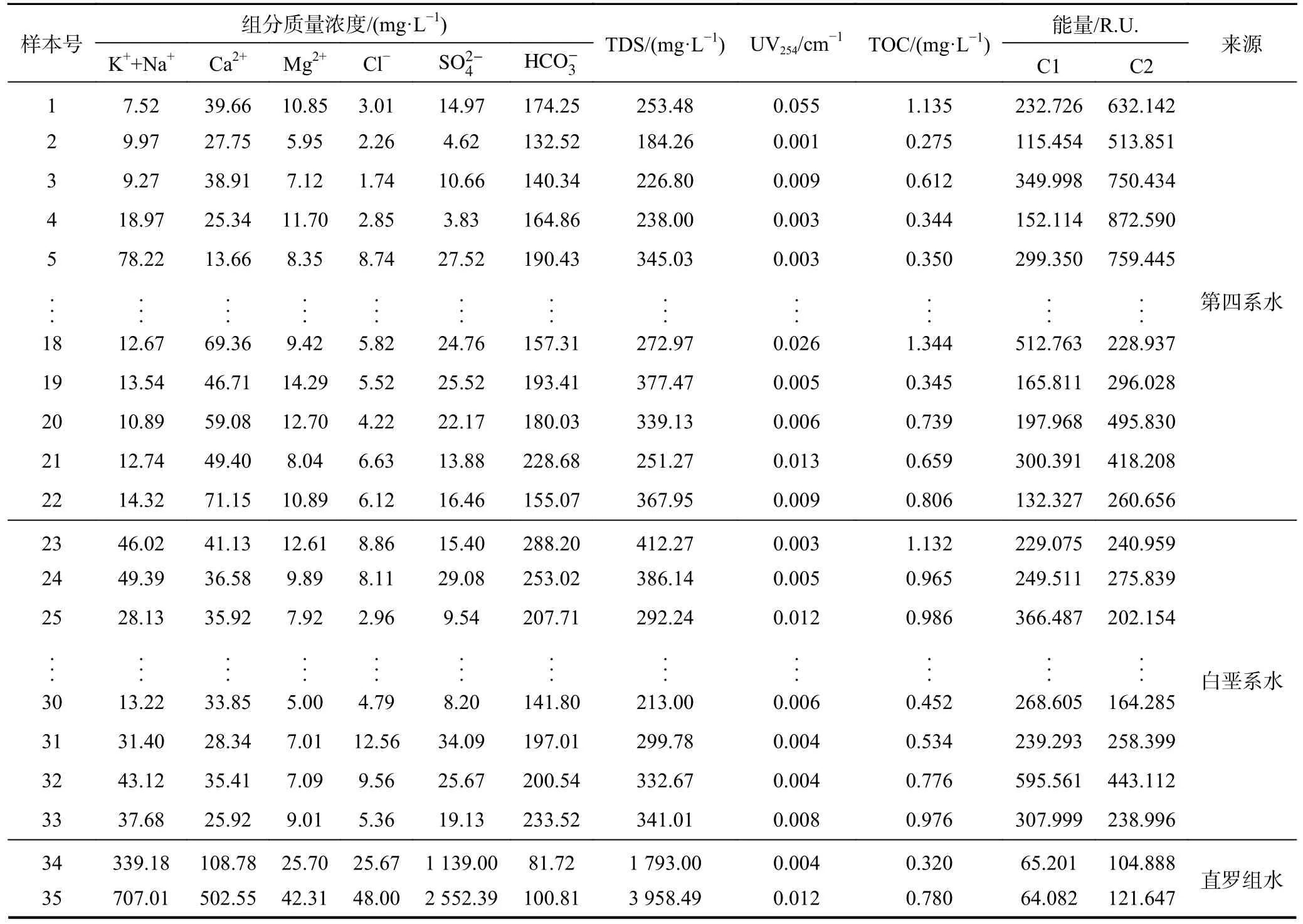
表1 水样测试结果Table 1 Water samples analysis findings

图2 DOM 各组分三维荧光图谱Fig.2 Three-dimensional fluorescence spectra of various components of dissolved organic matter (DOM)
为分析采集水样的水化学特性,利用测试得到的表1 中92 组水样数据,分别绘制水化学Piper 三线图和水样各指标散点柱状图,如图3、图4 所示。
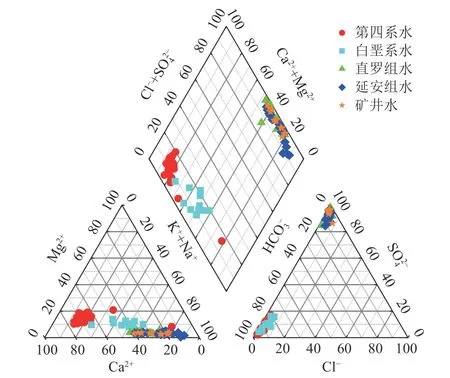
图3 水化学Piper 三线图Fig.3 Hydrochemical Piper trilinear diagram
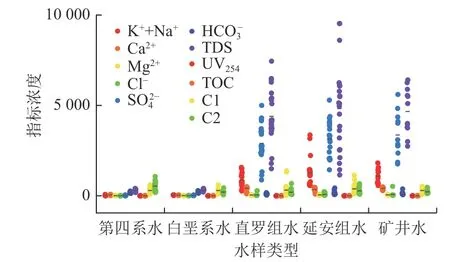
图4 水样各指标散点柱状图Fig.4 Scattered point column for various indicators of water samples
由图3 可知,第四系水样中阳离子以Ca2+为主,其次为Mg2+和K++Na+;阴离子以 HC为主,其次为S和Cl-,表现为HCO3-Ca 型水,与大气降水相似,个别水样K++Na+浓度较高,表明井田范围内第四系水的补给和运移条件存在不均一性。白垩系含水层水样以HCO3-Ca·Na 和HCO3-Na·Ca 型水为主,与第四系较为接近,这是由于第四系底部局部发育离石组隔水层,但其分布不均,结构松散且局部存在天窗,所以白垩系含水层易于接收其上覆含水层补给;同时,白垩系水中Na+浓度略有升高,这是沉积岩的风化水解、交代作用、混合作用等综合作用的结果。直罗组、延安组和矿井水的水样均分布于水质菱形图右上部,水化学类型主要为SO4-Na 和SO4-Na·Ca,以碱及强酸为主,表明因蒸发浓缩和溶滤作用,造成因补给排泄缓慢,径流条件差,矿化度较高,水质类型复杂化的现象;这也表明这2 个含水层与浅层第四系水力联系较差,这主要与安定组的隔水作用有关。综合来看,不同水样的水化学类型受到地质条件和水-岩相互作用的共同影响,由于水-岩相互作用是一个复杂而漫长的过程,因此,本研究未考虑水-岩相互作用对水源判识的影响,主要以水样检测结果为数据基础,对水源判别方法进行研究。
结合表1 和图4 进行分析可知,无机指标K++Na+、Ca2+、Mg2+、Cl-、S的浓度和TDS 在白垩系至直罗组增加明显,在直罗组至延安组增加不明显,延安组个别水样的无机指标浓度甚至低于直罗组;UV254和TOC 总体上随着含水层埋深的增加而降低,但延安组部分水样其浓度明显偏高,这主要是由于该地层含有较多的煤炭,地下水在通过这些含煤地层时,溶解并携带了较多的有机物;C1 的浓度在不同含水层中没有明显区分;第四系水样中C2 的浓度较高,这是由于第四系埋深较浅,有利于生物质的积累与保存以及微生物的生长。矿井水的各指标浓度大小与直罗组水、延安组水相似。
为进一步分析水样中各指标的相关性,利用表1 中前80 组水样数据,绘制各指标相关系数矩阵热力图,如图5 所示。
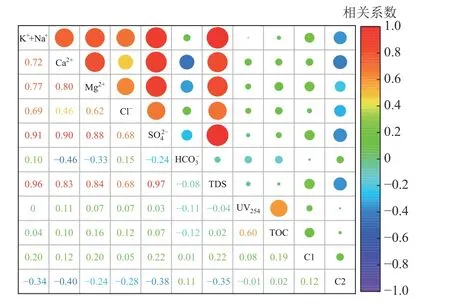
图5 相关系数矩阵热力图Fig.5 Thermodynamic diagram of correlation coefficient matrix
在矩阵热力图中,圆圈越大,颜色越接近橙色表示相关性越强。因此,由图5 可知,各指标之间具有明确的相关性,其中 S与K++Na+、Ca2+、Mg2+、TDS 具有较强的正相关性;K++Na+与Ca2+、Mg2+、Cl-、TDS 具有较强的正相关性;Ca2+、Mg2+与TDS 也具有较强的正相关性。C2 分别与K++Na+、Ca2+、S、TDS 呈现出了明显的负相关性,这表明数据集存在信息冗余,若直接用这11 种指标进行水源识别,会增加判别模型的复杂度和计算量,降低最终的判别效率和准确度。
3 PCA-AFSA-RF 水源判别模型原理及构建
3.1 数据降维
如前所述,判别指标之间较强的相关性会增加分析的复杂程度,因此,本文使用PCA 对判别指标数据集进行降维。分别记K++Na+、Ca2+、Mg2+、Cl-、S、HC、TDS、UV254、TOC、C1、C2 为X1、X2、X3、X4、X5、X6、X7、X8、X9、X10、X11,选取前80 组地下水水样作为训练样本,由此得到一个80×11 的数据矩阵X。对矩阵X进行主成分分析,得到其KMO(Kaiser-Meyer-Olkin)值和Bartlett 检验结果[32]。其中,KMO 值为0.770,这表明数据中的变量间有足够的共同变异量。Bartlett 检验包括近似卡方、自由度和显著性水平:其中,近似卡方为943.711,表明观测到的相关性与完全随机的偏差很大,说明数据集中的变量之间存在较强的相关性;自由度为55,意味着数据集中包含了相当数量的变量;显著性水平为0,这也支持变量之间存在相关性的结论,因此,可以认为在这个数据集的变量之间存在足够的相关性,适合进行主成分分析。
图6 为数据集的PCA 碎石图,由图可知,随着成分数的增加,特征值逐渐减小,在第6 个成分后不再有明显变化;各指标总方差解释见表2,可以看出前6 个主成分F1-F6的方差累计贡献率达到了94.393%,包含了原始数据集的绝大部分信息,因此,选取主成分个数为6,前6 个主成分的数学表达式如下:

表2 总方差解释Table 2 Total variance interpretations
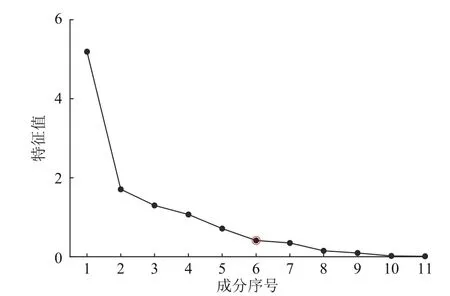
图6 PCA 碎石图Fig.6 PCA macadam
将矩阵X中的值代入式(1)中,得到一个大小为80×6 的矩阵F,该矩阵即为降维后的数据集,使用该数据集进行后续的模型训练。
3.2 改进随机森林(RF)算法的基本原理
RF 算法具有较好的鲁棒性和非线性建模能力[19],但需要调节的参数较多,传统的参数调优过程又较为耗时且不易找到最佳,会影响水源判别的准确率。因此,利用人工鱼群算法(Artificial Fish Swarm Algorithm,AFSA)对RF 的决策树数目(n_estimators)、树深(depth)和内部节点分裂所需的最小样本数(n_split)进行寻优。令每条人工鱼的状态(当前位置)Xi=(n_estimators,depth,n_split),人工鱼当前位置的食物浓度(适应度)Yi=f(X)为K折交叉验证后RF 分类器的平均准确率[33]。
人工鱼群的寻优机制包括觅食、聚群、追尾和随机4 种行为[34]。觅食行为基于局部搜索机制,每条人工鱼评估当前位置的适应度,并与邻近位置进行比较,若邻近位置适应度更高,则向该方向移动,否则随机选择新方向进行探索。聚群行为模仿鱼群中个体间的互动,当个体发现周围同伴处于更优位置时,向邻近同伴的中心位置移动。当个体发现邻域内存在显著高适应度的同伴时,会直接向此位置移动,即执行追尾行为。此外,每条鱼以一定概率随机移动(随机行为),这在一定程度上提高了鱼群的探索能力。为了平衡这些行为对人工鱼个体移动决策的影响,设置每种行为的权重均为0.5。
虽然AFSA 具有较强的收敛能力和适应性,但在搜索过程中,个体的移动和选择机制还是会导致个体陷入局部最优解或徘徊在搜索空间的某个区域。因此,本文在人工鱼群算法中引入遗传机制,遗传机制包括个体的选择、交叉和变异3 个过程[35]。个体选择确保了优秀个体的遗传信息得以保留,交叉和变异通过促进遗传信息的混合重组和引入新的遗传变异,来增加种群的多样性。通过这3 个过程,遗传机制既保证了种群向更优解进化,也有效避免鱼群因过度同质化而陷入局部最优解。
1)选择操作
选择操作的目的是根据适应度从当前种群中选择生存能力高的个体,用以参与下一代的繁殖。
其中,fj(t)为群体中的其他个体;每个个体以概率(t)被选为父代个体。
2)交叉操作
通过交叉操作来组合不同个体的优点,产生新的优秀个体。
其中,δ取值区间为0~1,本文取0.8。
3)变异操作
变异操作用于增加种群的多样性,这里采用非对称高斯变异[36],通过下式实现:
为了使绝大多数随机数落入均值加减一个标准差的范围内,设置高斯变异系数 ε为0.5。
3.3 改进耦合模型基本框架
图7 为改进PCA-AFSA-RF 水源判别模型流程图。首先对原始的水样指标数据进行预处理,该过程分为数据标准化和主成分提取两步。为了使数据充分参与模型训练,采用K折(K=1,2,···,K)交叉验证法进行数据集的划分,将第K折作为训练集,其余K-1 折作为验证集,如此重复K次,这种方法无需人为划分训练集与验证集,还可以避免欠拟合或过拟合的发生。在随机森林模型中,对训练集的水样进行随机采样,得到多个训练子集,针对每个训练子集,使用基尼指数(Gini)选择最佳的决策树分裂点,使用分类回归树(Classification and Regression Trees,CART)算法递归地将数据集分裂成更小的子集来构建决策树,根据所有决策树的投票结果对验证集的水样进行类别预测。利用AFSA 对RF 的决策树数目(n_estimators)、树深(depth)和内部节点分裂所需的最小样本数(n_split)进行寻优:首先对AFSA 中所有人工鱼的位置进行初始化;将每条人工鱼的位置传递至RF 模型,RF 模型将K次交叉验证中验证集水样的平均判别准确率作为人工鱼的适应度返回;AFSA 根据每条人工鱼适应度执行觅食、聚群、追尾和随机4 种行为,进行位置和适应度的初步更新;根据适应度选出参与繁殖的父代,对父代个体进行交叉操作,用新的子代个体代替父代;随后对新种群进行变异操作,每个个体以0.5 的概率参与变异;当迭代次数t达到最大值T时,算法终止。整个过程在PyCharm2021 环境中使用Python 语言实现。
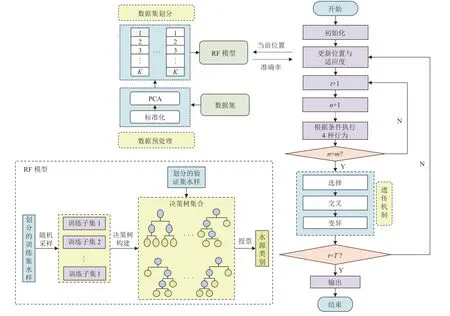
图7 改进PCA-AFSA-RF 水源判别模型流程Fig.7 Flow chart of the improved PCA-AFSA-RF water-source discriminant model
使用准确率(Accuracy,Ac)、精确率(Precision,Pr)、召回率(Recall,Rc)和F-measure 指数(f1_score,f1)对模型的性能进行评估,具体含义如下:
由于需要判别的水样有4 种类别,因此,这里N取4。对于上述4 个性能指标,计算所有K次迭代的平均值作为模型的输出。
4 改进PCA-AFSA-RF 水源判别模型应用
4.1 PCA-RF 水源判别模型性能
在利用PCA 对水化学数据降维后,直接使用RF 模型进行学习,由此构建PCA-RF 判别模型,这里对n_estimators,depth和n_split这3 个参数不做限制,为了符合训练集和验证集的划分原则,取交叉验证的折数(K)为4 和5,选效果最优值。此外,为了与PCA-RF水源判别模型的性能进行对比,本文使用SVM、多层感知机(Multilayer Perceptron,MLP)和ELM 分别构建PCA-SVM、PCA-MLP 和PCA-ELM 水源判别模型:对PCA-SVM 使用线性核函数,最大迭代次数为300;PCAMLP 中使用拟牛顿法优化器,激活函数为Logistic;PCA-ELM 的中间层神经元数目为5。结果见表3,可以看出PCA-RF 判别模型的Ac、Pr、Rc和f1分别为83.00%、83.17%、80.42%和79.57%,远高于其他3 种算法,此时K=4。同时,使用上述4 种模型对80 个训练水样进行回代预测,实验显示PCA-RF、PCA-SVM、PCA-MLP 和PCA-ELM 水源判别模型分别出现了5、25、7 和28 个误判,回代准确率分别为93.75%、68.75%、91.25%和65.00%,对直罗组水和延安组水的区分尤为不佳。通过对比,PCA-RF 水源判别模型的各个性能指标均优于其他3 种模型,因此,后续用AFSA 对PCA-RF 水源判别模型进行优化。
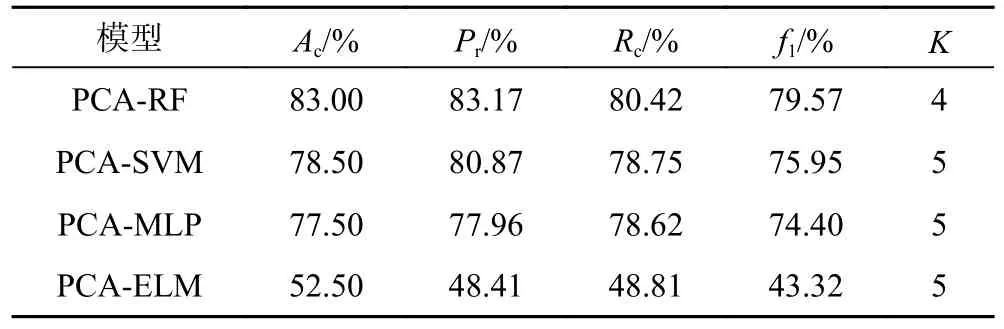
表3 4 种水源判别模型性能对比Table 3 Performance comparison of four water-source discriminant models
4.2 改进PCA-AFSA-RF 水源判别模型
在PCA-AFSA-RF 水源判别模型中,设置AFSA 的最大迭代次数T为100,n_estimators范围为1~200,depth范围为1~50,n_split范围为2~10,人工鱼可视范围为5,步长为4,拥挤度因子为0.5,交叉验证的折数K为4,整个过程在PyCharm2021 环境中使用Python 语言实现。在AFSA 的诸多参数中,鱼群数量的多少直接影响到搜索空间的覆盖程度和搜索效率,因此,分别设置鱼群数量m为10、15、20、30、50,其迭代结果如图8所示。由图可知,在100 次的迭代过程中,鱼群数目为15、20、30 和50 时均在判别准确率为92.18%处达到了收敛,其中鱼群数目为20 时收敛速度最快,其最佳参数组合为n_estimators=17,depth=37,n_split=5;鱼群数目为10 时达到了收敛但并未收敛到最优,这是由于数目过小而陷入了局部最优。
为更直观地体现PCA-AFSA-RF 水源判别模型的优势,绘制了同一水样数据集下PCA-RF 和PCAAFSA-RF 判别模型的性能,如图9 所示。可以看出,PCA-AFSA-RF 水源判别模型的4 个判别性能指标分别达到了92.18%、91.11%、87.58%和88.82%,较PCARF 水源判别分别提高了9.18%、7.94%、7.16%和9.25%。
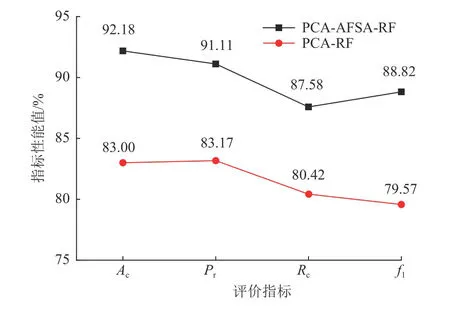
图9 PCA-AFSA-RF 与PCA-RF 水源判别模型性能对比Fig.9 Performance comparison of PCA-AFSA-RF and PCA-RF water-source discriminant models
为深入分析PCA-AFSA-RF 水源判别模型的拟合效果,分别用上述两个模型对80 个水样进行回代,结果如图10 所示,由图可知:PCA-AFSA-RF 水源判别模型出现了2 个误判,分别将17 号(第四系水)和60 号(延安组水)水样误判成白垩系水和直罗组水,回代准确率为97.5%;PCA-RF 水源判别模型出现了5 个误判,分别将17 号(第四系水)、30 号(白垩系水)、32 号(白垩系水)、66 号(延安组水)、76 号(延安组水)水样误判为白垩系水、第四系水、第四系水、第四系水和直罗组水,回代准确率为93.75%。

图10 PCA-AFSA-RF 和PCA-RF 水源判别模型回代判别结果Fig.10 Back substitution results of PCA-AFSA-RF and PCA-RF water-source discriminant models
4.3 模型验证
为进一步验证文中建立的PCA-AFSA-RF 水源判别模型的泛化能力和可靠性,对12 个待测的矿井水水样进行判别,同时与PCA-RF 判别模型进行对比。其中,1-3 号矿井水水样分别取自A 矿井下HF2-1、HF7-2、YS5-2 号探放水钻孔,探放水钻孔终孔层位位于直罗组含水层中下段;4-5 号矿井水水样取自A 矿井下掘进巷道涌水点。结合现场实际判定1-3 号矿井水水样来自直罗组含水层,4-5 号矿井水水样来自延安组含水层。6-10 号矿井水水样分别取自B 矿井下ZJ2、ZJ3、ZJ6、ZJ8、ZJ9 号探放水钻孔,探放水钻孔穿过2 号煤层2~3 m 终孔,终孔层位位于延安组含水层。11-12 号矿井水水样分别取自B 矿副立井巷道出水点。通过对井下探放水钻孔出水层位及巷道出水点分析可知,6-10 号矿井水水样来自延安组含水层,11 号矿井水水样来自直罗组含水层,12 号矿井水水样来自延安组含水层。记直罗组水为Z,延安组水为Y,具体判别结果见表4。

表4 矿井水水样判别结果Table 4 Discriminant results of water samples from mines
对表4 进行分析可知,PCA-AFSA-RF 判别模型将A 矿1-3 号矿井水水样判别为直罗组水(Z),4-5 号矿井水水样判别为延安组水(Y);将B 矿6-10 号和12 号矿井水水样判别为延安组水(Y),11 号矿井水水样判别为直罗组水(Z),该模型判别结果与现场实际分析的水源类别相一致。而PCA-RF 判别模型出现了2 个误判,分别将5 号矿井水水样误判为直罗组水(Z),将11 号矿井水水样误判为延安组水(Y)。综合分析,文中建立的PCA-AFSA-RF 煤层顶板涌水水源智能判别模型具有较好的可靠性,可为煤层顶板涌水水源的智能判别提供新方法。
5 结论
a.由不同来源水样的无机水化学指标及TOC、UV254和荧光光谱等有机指标构建了水样数据集,使用PCA 对水样数据集进行降维,构建PCA-AFSA-RF 煤层顶板涌水水源智能判别模型。
b.实验显示,构建的PCA-RF 模型的准确率为83.00%,高于PCA-SVM、PCA-MLP 和PCA-ELM 模型。利用AFSA 对PCA-RF 模型中的决策树数目、树深和内部节点分裂所需的最小样本数的最佳组合进行寻优,交叉验证的准确率达到了92.18%,较PCA-RF 判别模型提高了9.18%。
c.利用PCA-AFSA-RF 和PCA-RF 水源判别模型对训练集水样进行回代及对12 个待测矿井水水样进行判别,结果表明,PCA-AFSA-RF 水源判别模型具有更好的准确性和泛化能力,可为煤层顶板涌水水源的判别提供新的方法。
d.后续将深入考虑水文地质、工程地质、采矿活动以及水-岩作用对煤层顶板涌水水源判别的影响。同时,通过现场定期采样,不断更新和扩大训练集水样,以动态调整模型参数与结构,确保建立的判别模型的长效性。
符号注释:
b和c分别为随机森林寻优参数的上下限;C为待判别的水源类别个数;fi(t)为第i个人工鱼个体在第t代的适应度值;fj(t)为第j个人工鱼个体在第t代的适应度值;K为交叉验证折数;m为设定的人工鱼群数量;Mi'i'为实际为类别i'且预测为类别i'的水样数量;Mi'j'为实际为类别i'而预测为类别j'的水样数量;Mj'i'为实际为类别j'而预测为类别i'的水样数量;n为当前循环中的人工鱼数目;N(0,α) 为服从均值为0、标准差为α的正态分布随机数;(t)为第i个人工鱼个体在第t代被选择的概率;Pri'为类别i'的精确率;Rci'为类别i'的召回率;t为人工鱼群算法当前的迭代次数;T为设置的人工鱼群算法最大迭代次数;xi(t)和xi(t+1)分别为第i个人工鱼个体在第t代和第t+1 代的位置;xj(t)和xj(t+1)分别为第j个人工鱼个体在第t代和第t+1 代的位置;α为高斯变异的标准差;ε为高斯变异系数;δ为交叉操作中的交叉系数。
猜你喜欢
中国煤炭(2023年12期)2024-01-04
煤炭学报(2022年10期)2022-11-11
河北地质(2021年3期)2021-11-05
辐射防护通讯(2019年3期)2019-04-26
绿色科技(2018年24期)2019-01-19
意林(儿童绘本)(2018年10期)2018-11-08
河北地质(2016年1期)2016-03-20
中国水能及电气化(2016年11期)2016-02-28
中国学术期刊文摘(2016年1期)2016-02-13
天然气勘探与开发(2015年1期)2015-02-28
