
知识元视域的技术元抽取及技术机会识别*
2024-04-25 01:45王金凤阎竞博冯立杰林国义
情报杂志 2024年4期
王金凤 阎竞博 冯立杰 李 康 林国义
(1.上海海事大学中国(上海)自贸区供应链研究院 上海 201306;2.上海海事大学经济管理学院 上海 201306;3.上海海事大学物流工程学院 上海 201306;4.上海海事大学物流科学与工程研究院 上海 201306;5.桂林电子科技大学商学院 桂林 541004)
技术创新作为提高企业核心竞争力的不二法宝[1],其中,技术机会识别是精准开展技术创新的关键[2]、知识挖掘是技术机会识别的前提与核心环节[3]。随着技术迭代速度的日益加快,加之急剧膨胀的海量技术知识,传统的经由人工进行知识挖掘预判技术机会变得愈加困难[4]。因此,直面数量日益庞杂的技术知识,如何在把握技术发展趋势的同时准确识别新的技术机会继而降低创新风险,成为企业亟待解决的一个重要现实问题[5]。本文将构建一种从知识元视角出发的技术元抽取与技术机会识别路径,基于技术元理论在收集并处理数据的基础上,挖掘技术知识中影响技术创新的技术要素并抽取要素间的关系,继而进行子技术类别研判和技术机会识别,旨在为企业精准预判技术机会、不断提升创新效率提供有益的参考。
1 相关工作概述
为了简化知识获取的难度,有学者引入知识元理论[6],将知识元视为组成知识的具有独立性、完整性和单一性的最小单元作为知识管理的出发点[7],尝试建立了基于知识元的分层描述结构和线性描述结构的语义描述模型[8]。利用资源描述框架(Resource Description Framework,RDF),以主体(Subject)、谓词(Predicate)和客体(Object)构成的
专利文本作为技术知识的重要载体,其中蕴含的丰富技术信息是技术机会分析的关键数据源[14],最常用的方法是基于机器学习算法对文本内容中的关键技术信息进行挖掘,进而完成潜在技术机会的识别[15]。其中,可通过关键词挖掘技术创新机会[16],或利用SAO语义分析方法对结构化专利文本进行创新要素间的关系研究[17]。然而,在此过程中难以厘清具体创新要素的属性及归类,同时也难以准确全面地对创新要素之间的复杂关系进行准确完整的诠释。
而深度学习方法可以实现在精准抽取技术知识中包含的创新要素及其关系的同时[18],克服过分依赖专家参与难以保证抽取结果客观性的缺陷[19]。程为等[20]使用BERT模型和ERNIE模型对南海维权证据知识元进行识别;Meng F等[21]构建了基于BERT-BiLSTM-CRF模型用于知识元中的实体抽取;Hou J等[22]构建了BERT模型用于知识元中的关系抽取。同时,相较于利用规则或模板进行知识元抽取,基于深度学习的方法在自动化程度和精确度方面具有更加优异的性能[23]。然而,在构建深度学习模型进行知识抽取时,还需引入一种针对专利文本中技术要素间的关系进行统一标注的规则对其整理和分类,从而更好地开展技术机会的识别。综上,由于现有知识元抽取和技术机会识别方法自身存在的局限性,其研究结果的准确性和客观性有待进一步完善。因此,本文从知识元视角出发进行技术元抽取与技术机会识别,引入了深度学习、链路预测、支持向量机等方法展开了分析。
2 研究设计
基于上述分析,本文提出一种知识元视角下的技术元抽取与技术机会识别研究路径,如图1所示。

图1 研究框架
a.技术元抽取过程采用的方法主要包括:
①确定检索式并从专利数据库中搜索相关专利,然后依据专利说明书文本构建技术元语料库。
②构建基于对抗训练的BERT-BiLSTM-CRF模型以抽取具象技术领域的技术要素,同时构建BERT模型抽取技术要素间的关系,然后将前述结果以技术元三元组表示并建立知识网络。
③分别运用Word2Vec和K-means算法,构建基于语义向量的技术要素子技术识别方法并进行技术要素词聚类,然后对聚类结果进行分析,确定子技术的名称。
b.技术机会识别过程采用的方法主要包括:
①根据现有技术要素间的关系,利用链路预测方法研判技术元知识网络中要素之间的潜在关系。
②利用SVM算法对潜在关系进行分类以确定其类别,得到潜在的技术元三元组。
③对前述潜在关系进行有效性识别,进而依据识别结果,结合现有三元组,完成对子技术创新机会的预判。
3 技术元抽取
本文在知识元的基础上引申出了技术元的概念。技术元是技术组成的基本单元,反映了技术包含的基本信息,不仅包含技术要素实体,同时包含技术要素间的关系。因此,本文对技术元进行抽取以实现对技术知识的全面获取与管理。
3.1 数据的收集及预处理
为了保证全面准确地获取目标技术所涵盖的技术信息,首先需要制定数据收集与预处理方案,如图2所示。
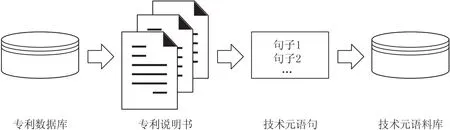
图2 数据收集及预处理
首先,针对目标技术制定专利检索式,从专利数据库中检索相关专利,并去除重复、无关专利。其次,在检索到的专利中获取专利说明书,并提取文本内容。最后,对得到的文本进行数据清洗,去除无意义的数字、符号等噪声数据,并对文本进行分句处理以构建技术元语料库。
3.2 技术要素和技术要素间关系的抽取
技术元抽取包括技术要素抽取和技术要素间的关系抽取。
为便于计算机处理,本文将技术元以
3.2.1技术要素的抽取
首先,研判技术要素的类别并加以标注。然而,有鉴于不同技术大多分属不同的类别,加之目前尚没有可供遵循的通用标注规则,所以,本文引入FENG L.J.等[24]针对专利提出的多维技术创新图谱中的9个创新维度对技术要素进行了标注。相关维度的具体含义见表1。

表1 多维技术创新图谱的创新维度划分
其次,在完成技术要素的维度标注后,构建基于对抗学习的BERT-BiLSTM-CRF模型进行技术要素抽取。具体流程如图3所示。

图3 技术要素抽取过程
技术要素的抽取过程主要包括:
一是BERT层的构建。本文使用基于双向Transformer编码构建的预训练语言模型BERT,可以精准捕捉到句子的特征信息[25]。经过双向Transformer编码后可得到句子字符级特征向量序列X=(x1,x2,…,xn)。
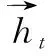
三是CRF层的构建。在完成技术要素抽取后,本文利用条件随机场(conditional random fields,CRF)处理BiLSTM的输出,同时借鉴相邻标签中的关系进行序列标注,进而可得到最优的预测序列[27]。
四是基于FGM对抗训练方法的数据特征增强。为了提高技术要素抽取模型的性能,本文引入对抗训练方法使数据特征增强,即通过引入噪声对样本增加扰动的方式,提高模型的泛化性和鲁棒性[28]。
c.对模型进行评估。即在完成技术要素的识别后,还需以准确率P、召回率R、F1值评估模型的优劣,具体计算公式如下:
(1)
(2)
(3)
其中,TP表示预测类型与实际类型相同的数量,FP表示预测类型与实际类型不同的数量,FN表示实际类型与预测类型不同的数量。
3.2.2技术要素之间的关系抽取
首先,为了抽取前述技术要素之间的关系,简化要素间关系标注的难度,本文引入FENG L.J.等[24]针对专利提出多维技术创新图谱中的9种创新法则对技术要素之间的关系进行了标注,相关创新法则的具体含义见表2。

表2 多维技术创新图谱的创新法则
其次,利用BERT模型抽取技术要素之间的关系。具体流程如图4所示。

图4 技术要素之间的关系抽取过程
在图4中,利用BERT模型抽取技术要素之间的关系主要包括:
一是与命名要素识别过程中的BERT操作相同,通过Transformer编码得到字符级特征向量序列X=(x1,x2,…,xn)。
二是将编码得到的字符级特征向量序列输入到全连接层中,并将字符级别的特征向量转换为句子级别的特征向量。然后利用ReLU激活函数进行线性变化。
三是将全连接层输出的结果输入到softmax 层中,利用softmax函数进行关系分类,并将多分类输出值转换为[0,1]的概率分布。
四是待关系抽取完成后,本文以准确率P、召回率R、F1值评估模型的优劣。
最后,将技术元以三元组形式表示,并将得到的技术元三元组以技术知识网络的形式保存,便于后续开展技术知识分析。
3.3 子技术类别的研判
在技术元抽取基础上,还需将技术要素进一步整理和分类。对此,本文构建了一种基于语义向量的技术要素子技术类别研判方法,利用Word2vec提取技术要素的词向量,利用K-means算法对技术要素进行聚类,并结合聚类结果对子技术进行命名。子技术类别的研判过程如图5所示。
依据图5中对子技术类别的研判,在具体实施中:
a.获取技术要素的词向量。为了获取技术要素词的语义信息,本文选用Word2vec模型中的Skip-gram模型提取技术要素词的词向量[29]。主要包括:
一是对提取的技术要素构建用户词典,并利用Python中的jieba工具包对包含技术要素的技术元语句进行分词处理。
二是将分词后的语句输入到Word2Vec模型中,并利用skip-gram模型进行训练,得到各词的语义向量。
三是将技术要素词与得到的词向量匹配,得到具有语义信息的技术要素词向量。
b.对技术要素词进行聚类。在获取具有语义信息的技术要素词向量基础上,还需利用K-means算法对技术要素词进行聚类[30]。主要包括:
一是对于Word2vec模型所提取出的技术要素词向量序列V=(v1,v2,…,vn),可通过将技术要素词划分到k个子集中判定子技术的类别。
二是在聚类过程中,对于一个类Vi=(vl,vl+1,…,vk)以技术要素词vi到所属类的中心距离之和为损失函数,μl表示第l个类的质心,则最优目标函数为:
(5)
c.为了提高聚类的有效性,还需对k的取值进行实验,同时选取可解释性最佳的k值作为聚类个数,最终完成对子技术的命名。
4 技术机会识别
4.1 基于链路预测的潜在关系识别
在技术知识抽取基础上,还需对现有的技术知识网络进行分析,进而识别相应的技术机会。在具体实施中,鉴于链路预测方法能够准确预判未来技术的发展方向,本文首先利用随机游走算法对整个技术元网络进行计算,并以Cos+指标确定技术要素间是否具有潜在关系[31];然后根据Cos+指标的计算结果,在去除Cos+小于0.5的连边后,将剩余连边作为具有要素间潜在关系的连边,并作为蕴含未来技术发展方向的技术信息予以保留。
4.2 基于SVM算法的潜在关系分类
SVM是一种性能优越的分类算法,相较于朴素贝叶斯、逻辑回归等模型具有更好的效果[32]。因此,在识别技术要素间的潜在关系后,为了提高技术机会识别的客观性,本文利用SVM算法对识别出的具有潜在关系的技术要素进行了分类。
4.3 技术机会的预判
在完成潜在关系识别和潜在关系分类基础上,还需进一步预判具象技术的创新机会。在具体实施中:
a.识别技术要素潜在关系的有效性。识别完成后,还需对识别出的潜在技术元三元组进行筛选,以判断其是否具有技术创新价值。
b.进行技术机会分析。在对技术要素潜在关系进行有效性识别基础上,还需结合现有技术元三元组和识别出的潜在技术元三元组,完成对技术机会的识别,具体流程如图6所示。

图6 技术机会的识别
图6中,TE表示技术要素;TR表示现有技术要素间的关系类型;TR'表示预测得到技术要素间的潜在关系;具有同样形状的TE表示其同属于一个子技术。
5 案例应用
水质浊度检测技术在水域治理中起着举足轻重的作用,亟待进行技术创新。因此,本文将以水质浊度检测技术创新机会识别为例,对本文提出的方法进行验证。
5.1 水质浊度检测技术专利数据获取与预处理
5.1.1水质浊度检测技术专利数据的获取
本文选用壹专利检索分析数据库进行专利检索。
首先,本文确定检索式为:“TA=(浊度检测) AND (TA=(水) OR TA=(水质)) AND (TA=(装置) OR TA=(方法) OR TA=(设备) OR TA=(传感器)) and (IPC=(G) OR IPC=(C))”。在数据库中检索到381条专利数据。
其次,通过人工阅读并剔除与水质浊度检测无关或关系不大的专利后,共得到355条专利数据。
最后,提取355条数据的专利说明书文本。
5.1.2水质浊度检测技术专利的预处理
为保证技术元抽取的效果,在标注数据之前还需要进行文本的预处理。
首先,利用正则表达式去除专利说明书文本中无意义的字符和数字。
其次,利用SnowNLP对专利文本进行断句处理,拆分标识符为中文句号。其中,文本段落应小于300字符,若超出300字符则利用正则表达式对句子切分,多余部分视为另一个句子。
最后,构建技术元语料库,并删除语料库中重复且句子长度小于10的句子。
经预处理后,本文共从355篇专利说明书文本中提取出11 787条语句。
5.2 水质浊度检测技术元抽取
为便于进行技术元的自动化处理,本文利用语义描述模型将技术元表示为三元组形式,见表3。

表3 水质浊度检测技术的技术元表示
本文构建了相关模型进行技术要素和要素间关系的抽取。
5.2.1水质浊度检测技术的技术要素抽取
据前文所述,本文构建了基于对抗学习的BERT-BiLSTM-CRF模型用于技术要素抽取。
首先,依据专利说明书,本文从前述提取出的11 787条语句中选取了1 624条以人工方式对技术要素进行了BIO标注,具体标注方式如图7所示。

图7 水质浊度检测技术要素的BIO标注
其次,对技术要素的抽取结果进行定量评估。本文以8∶2比例划分训练集与测试集,用于该模型的训练与测试。经训练后,该模型在测试集上的精确度为0.789、召回率为0.784、F1值为0.786,抽取效果较好。
再次,将本模型与三种命名要素识别模型进行对比,具体结果见表4。结果表明,本文构建的模型在技术要素抽取上优于其他三种模型。
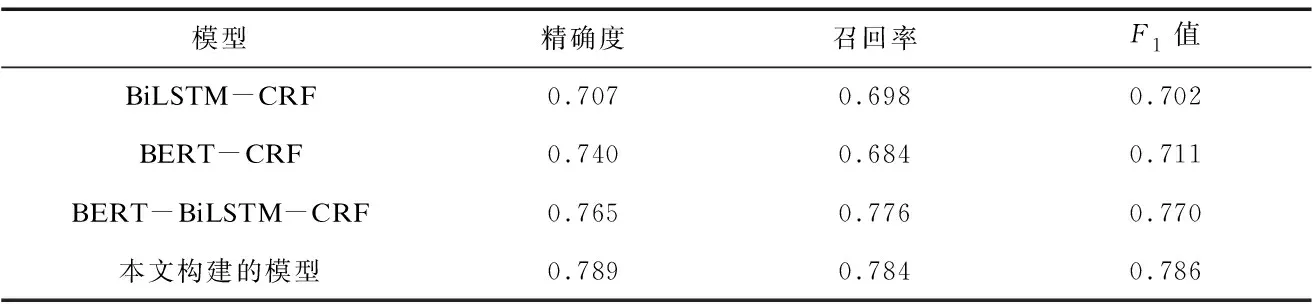
表4 水质浊度检测技术要素识别模型的有效性比较
最后,利用训练完成的技术要素抽取模型进行要素抽取。在抽取完成后,为了保证抽取的质量,还需进行人工去重与消岐,最终共得到3 672个所属不同类别的技术要素,具体分析结果见表5。

表5 水质浊度检测技术要素抽取的结果
5.2.2水质浊度检测技术要素关系抽取
首先,采用BERT模型进行技术要素间关系抽取。本文从前述提取出的11 787条语句,对其中1 624条语句以人工方式进行了技术要素关系标注。
其次,对技术要素关系的抽取结果进行定量评估。本文以8∶2比例划分训练集与测试集,用于BERT关系抽取模型的训练与测试。经训练后,该模型在测试集上的精确度为0.727、召回率为0.712、F1值为0.719,抽取的效果较好。
再次,利用训练完成的抽取模型抽取技术要素间的关系。为保证识别质量,还需进行人工去重并删除无意义要素间的关系组,最终共识别出5 348条关系,具体结果见表6。

表6 技术要素之间关系抽取的结果
最后,为便于对技术元进行管理,还需将前述结果导入到Neo4j图数据库进行存储,进而得到技术元知识图谱。
5.3 水质浊度检测技术的子技术识别
有鉴于前文中抽取的技术要素仅为单独的个体,为了提高技术知识的管理效率,还需进一步分析每个个体的子技术类别。
5.3.1技术要素词向量的获取
首先,将识别的技术要素定义为用户词典,鉴于同一要素可能对应不同的技术要素类别,因此在构建用户词典时本文从前述3 672个所属不同类别的技术要素中共筛选到3 360个唯一技术要素词。
其次,利用Jieba分词将技术元语料库进行分词处理,分词后的句子作为Word2Vec模型的输入,然后利用skip-gram模型对完成分词的句子进行训练,并输出分词后句子中每个词的词向量。
最后,将技术要素词与Word2Vec模型输出的词向量进行匹配,进而得到技术要素词向量。
5.3.2技术要素词的聚类
在完成技术要素词向量提取后,还需利用K-means算法进行技术要素词聚类。此外,为了提高聚类效果,本文对不同聚类数k,聚类所得到的结果进行比较后发现,当聚类数k=5时,聚类结果的可解释性最好。
在聚类后,本文对聚类结果进行分析,并对子技术类别进行命名,结果见表7。

表7 水质浊度检测技术子技术类别的识别结果
由表7可以看出技术要素词主要聚类在以下5个方面:
一是子技术1表征的浊度检测装置结构。浊度检测装置结构[33]作为浊度检测技术中最常见的一类技术,因此包含技术要素的数量最多。二是子技术2表征的控制系统。控制系统[34]包含电路控制、光路控制、信号传输控制等,是浊度检测技术中的重要技术之一。三是子技术3表征的检测相关功能。主要涉及到浊度检测的一些其它功能[35]。四是子技术4表征的检测用组件。在进行浊度检测时常常需要一些部件辅助浊度检测[36]。五是子技术5表征的检测方法。检测方法作为水质检测技术的核心内容,在检测不同环境水样时需要灵活选用不同的方法[37]。
5.4 水质浊度检测技术机会分析
5.4.1水质浊度检测技术要素的潜在技术元三元组确定
本文利用链路预测算法识别技术元间的潜在关系。通过对现有的5 348个技术元三元组进行技术要素之间潜在关系的确定,本文共识别出了2 409个具有潜在关系的技术要素,然后利用SVM算法将识别出的技术要素划分为九大类,以此确定潜在关系所属的具体类别,进而可得到技术要素的潜在技术元三元组。
5.4.2水质浊度检测子技术机会分析
针对识别出的技术类别中所包含的潜在技术元三元组,结合现有的技术元三元组,对前文识别出的5个子技术类进行技术机会分析。
5.4.3水质浊度检测子技术类技术机会确定
在前述分析基础上,本文以得到的3个子技术类的技术机会为例进行分析,见表8。

表8 水质浊度检测技术机会
由表8可以看出水质浊度检测子技术类的技术机会主要包括:
一是水质浊度检测装置结构子技术的技术机会——友好化检测装置。友好化产品设计作为未来技术发展的重要发展方向之一,同样也适用于水质浊度检测技术装置。必然的,操作友好化[38]、视觉友好化[39]、环境友好化[36]等是目前浊度检测装置的重要发展方向。
二是水质浊度检测控制系统子技术的技术机会——智能控制。智能控制一直以来作为水质浊度检测装置的研发重点,同样也是值得重点关注的技术机会。为了满足不同时间、空间和环境等条件的限制,需要利用现有或研发新的控制技术实现对浊度检测装置的智能控制[34],进而实现更精确的水质浊度检测。
三是水质浊度检测控制系统子技术的技术机会——智能检测。与智能控制相同,智能检测是水质浊度检测技术重要的研发方向。随着计算机、传感器和通讯等技术的不断发展,检测技术将不再局限于传统水质的浊度检测[37],急需更便捷、更准确地进行检测的方法。同时,在水质浊度检测基础上,还可尝试利用机器学习算法实现对水质浊度的预测[40],从而为进一步提升水质监测与管理水平提供可资借鉴的参考思路。
在完成技术机会识别后,可根据现有技术元三元组,结合潜在技术元三元组制定相应的技术方案,进而实现水质浊度检测技术产品的创新研发。
6 结论与展望
综上所述,为了弥补已有技术机会识别文献中对技术知识抽取方法研究的不足,提高分析结果的客观性,本文提出了一种依托知识元理论开展技术元抽取与技术机会识别的方法。首先根据知识元理论引出技术元的概念,为技术知识管理提供理论支持,并利用基于对抗训练的BERT-BiLSTM-CRF模型进行技术要素抽取,利用BERT模型进行技术要素间关系抽取,识别出完整的技术元三元组;其次,利用基于语义信息的技术要素聚类方法识别相关技术的子技术类别;再次,利用链路预测方法,结合SVM算法,识别技术要素间的潜在关系,并发现技术机会;最后,以水质浊度检测技术为例验证了本框架的有效性。
本文在简化技术知识获取难度的同时,拓展了技术创新理论的研究范畴。为了简化技术知识获取的难度,本文依托知识元理论,通过引入多维技术创新图谱对技术要素及其关系进行了标注归类,并构建了相应的深度学习模型,既弥补了已有技术机会识别文献中对技术知识抽取方法研究的不足,又弥补了过分依赖专家参与难以保证分析结果客观性的缺陷。同时,在提升技术机会分析客观性的同时,也弥补了原有利用链路预测方法进行技术分析的不足。但是,本研究也存在一定的局限性。尽管本文依据链路预测结果,对潜在的技术机会进行了分析,但由于识别出的潜在技术元三元组较多,一定程度上会受专业知识所限,难以快速准确识别。因此,在未来的研究中还需进一步对识别出的技术机会进行量化评价,以提高技术机会识别的自动化程度和客观性。
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31
供水技术(2022年1期)2022-04-19
云南化工(2021年6期)2021-12-21
山西大学学报(自然科学版)(2021年1期)2021-04-21
海峡姐妹(2020年3期)2020-04-21
五邑大学学报(自然科学版)(2019年3期)2019-09-06
NBA特刊(2018年17期)2018-11-24
海峡姐妹(2018年6期)2018-06-26
酒·饮料技术装备(2018年1期)2018-04-28
儿童时代·快乐苗苗(2017年6期)2018-03-09
