
动态专利技术网络视域下技术集群识别*
2024-04-25 01:45刘玉林菅利荣
情报杂志 2024年4期
刘玉林 菅利荣
(1.南京航空航天大学经济与管理学院 南京 211106;2.安徽商贸职业技术学院电子商务学院 芜湖 241002)
近年来,科学技术作为最重要的生产力要素,在国家经济社会发展中发挥了越来越重要的作用[1]。各个国家为了获得技术优势,围绕技术资源展开了前所未有的竞争[2]。当然,这种竞争已经从单一技术竞争转向技术集群竞争,因为对属性功能等特征高度相似的技术集群进行研究,能够了解技术领域的层次结构,挖掘技术机会,发现技术发展规律,预测技术未来趋势,使国家和企业在技术研发和竞争中获得优势[2-3]。
1 相关研究与问题描述
当前,对技术集群的研究已经取得了一些进展。Jiang H等研究发现技术集群的发展是一个动态过程,受到技术变化和市场竞争等内外部因素的影响,并在调查美国技术集群的基础上,提出了技术集群存在生命周期的特点[3]。Ibrahim S等认为当技术在一定时间和空间上形成聚集分布时,将产生技术集群[4]。张月等从前人的研究成果中发现技术集群是促进经济动态发展的源泉[5],刘慧等对技术集群的概念进行界定,并提出技术集群对产业集群的三种作用力,包括提供动力、提升竞争力和强化保障力等[6]。
与此同时,通过专利分析开展技术集群的研究已经引起了相关研究者的广泛关注。因为专利是集技术情报、经济情报、商业情报于一体的知识载体,具有及时、可靠、内容详尽等显著特点[7],被视为技术原始信息来源,从而具有较高的商业价值,专利分析为技术研发、技术政策和技术战略等决策提供了重要信息[8]。在专利分析中,使用专利网络作为可视化分析工具,往往有助于分析技术相似性和技术发展趋势等[9]。为此,刘玉林等通过构建专利网络分析技术集群的演化,发现核心技术集群之间存在很好的更新替换机制[2]。潘微微等通过专利网络中的关键节点与关键路径分析,发现技术演进通常经历萌芽期、成长期、成熟期和衰退期等四个时期[10]。
虽然国内外对技术集群研究取得了一定的进展,部分研究者基于专利网络对技术集群演化分析进行了探索,但往往构建的网络是静态的,对技术集群的识别方法研究非常少。为此,本文构建动态专利技术网络,并提出一种有效的技术集群识别方法,从而更好地帮助企业和技术研发人员分析技术集群特征和预测技术集群发展趋势等。
广义上,技术集群是指在创新过程中由于群体技术的内在关联性和技术势差,各创新因子在流动中产生连锁、协同效应,并与技术相关的社会各种要素反馈互动,形成以集群为特征的集合[5-6]。狭义上,属性功能上高度相似的技术聚集在一起形成集合,称之为技术集群[2]。在本文中,仅研究群体技术的连锁和协同效应带来的技术研发和投资决策价值,故采用技术集群的狭义定义。在技术集群中,影响连锁和协同效应的创新因子统称为技术因子[2,5-6]。Noh等研究表明专利文献通常包含通用词和术语两类词语,通用词表现出与技术因子的无关性,而术语则表达某个专业知识,具有较高与技术因子相关性[2,11]。Yoon等认为属性和功能作为专利文本中重要的术语词语,能够通过自然语言处理方法提取,并进一步证实了属性和功能代表专利文本特征的唯一性[2,12]。在调查美国约16 000项专利后,Dewulf等发现属性表示系统的特定特性,在语言表达上与名词相关,而功能表示系统的适当操作,在语言表达上与动词相关[2,13]。Yoon等进一步发现属性和功能常常以二元关系的形式出现,即属性用“形容词+名词”形式表示,功能用“动词+名词”形式[2,12]。因此,在技术集群识别中,可将“形容词+名词”组合作为属性技术因子,“动词+名词”组合作为功能技术因子,选择属性和功能技术因子作为专利文本特征,以此准确把握技术集群的创新因素。
同时,陈悦等研究发现一个技术域是由若干个表达不同技术主题的技术群构成,其中整个技术域变化可以通过专利申请等指标测度,具体技术群可利用网络中社区探测算法检测[14]。事实上,在构建的动态专利技术网络中,节点聚类后形成簇,同一簇中专利节点连接紧密,而簇与簇之间的专利节点连接稀疏[15],且可通过社区检测发现网络中的专利簇[14]。由于每个专利节点是一个技术点的创新体现,节点聚类成簇实质上是属性和功能技术因子相似的技术形成集群,即“专利成簇,技术成群”。因此,一个技术域的技术集群识别问题,可视为动态专利技术网络中社区检测问题。
2 研究方法
采用自注意力机制学习出专利文档特定词向量,融合属性和功能技术因子等先验信息生成专利技术向量,计算专利技术相似度后构建动态专利技术网络,采用带节点增量的Louvain算法识别技术集群,具体步骤见图1。

图1 整体研究框架
2.1 专利技术相似度
在专利文档特定词向量学习中,以采集的目标专利集为语料库,通过word2vec生成通用词向量后[16-17],融合自注意机制更新通用词向量[18],学习出特定词向量,最后采用余弦相似度计算出专利技术相似度。
自注意力机制(self-attention mechanism)通过计算词与词之间的相似性,可以将句子中任意两个词联系起来,捕获其中的语义关系[19-20]。自注意力机制的主要计算过程如式(1)所示。
(1)
其中,qi、ki和vi为通过word2vec生成的原始词向量在三个不同的空间映射,即查询向量、健向量和值向量。DK表示kTi的维度,qikTi表示qi与kTi的点积。
在学习出专利文档特定词向量基础上,融合专利属性和功能技术因子等先验信息,采用组合拼接生成专利技术向量[19],具体如式(2-4)所示。
(2)
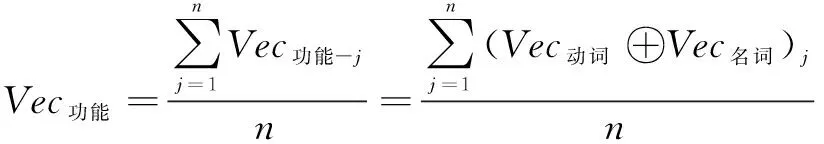
(3)
Vecpatent=Vec属性⊕Vec功能
(4)
其中,Vec属性为专利属性技术因子向量,m表示在某个专利文本中属性技术因子组合数。Vec属性-i表示在该专利文本中第i个属性技术因子向量,该向量由对应的形容词向量与名词向量组合拼接而来。Vec功能为专利功能技术因子向量,n表示在某个专利文本中功能技术因子组合数。Vec功能-j表示在该专利文本中第j个功能技术因子向量,该向量由对应的动词向量与名词向量组合拼接而来。Vecpatent为专利技术因子向量,该向量由对应的专利属性技术因子向量与专利功能技术因子向量组合拼接而来。⊕含义为拼接。
计算技术相似度时,余弦相似度是常用的方法[21-22],计算方式见式(5)所示。
(5)
其中,cosθA_C是专利A和C的技术相似度值,VecA-patent和VecC-patent是专利A和C的专利技术向量。
2.2 动态专利技术网络
当计算出专利技术相似度值后,将专利作为节点,专利间技术相似度值作为权重,可构建专利技术加权网络,如图2(a)所示。当然,如果将专利技术加权网络直接用于技术集群的识别,其中权重值较小的专利节点连接意味着技术相似度较小,并不能准确衡量技术聚集效应。因此,需要设定阈值对边进行筛选,去除网络中低权重边,保证有连接的专利对具有较好的技术相似度,有助于提高技术集群识别的准确性[15],如图2(b)所示。
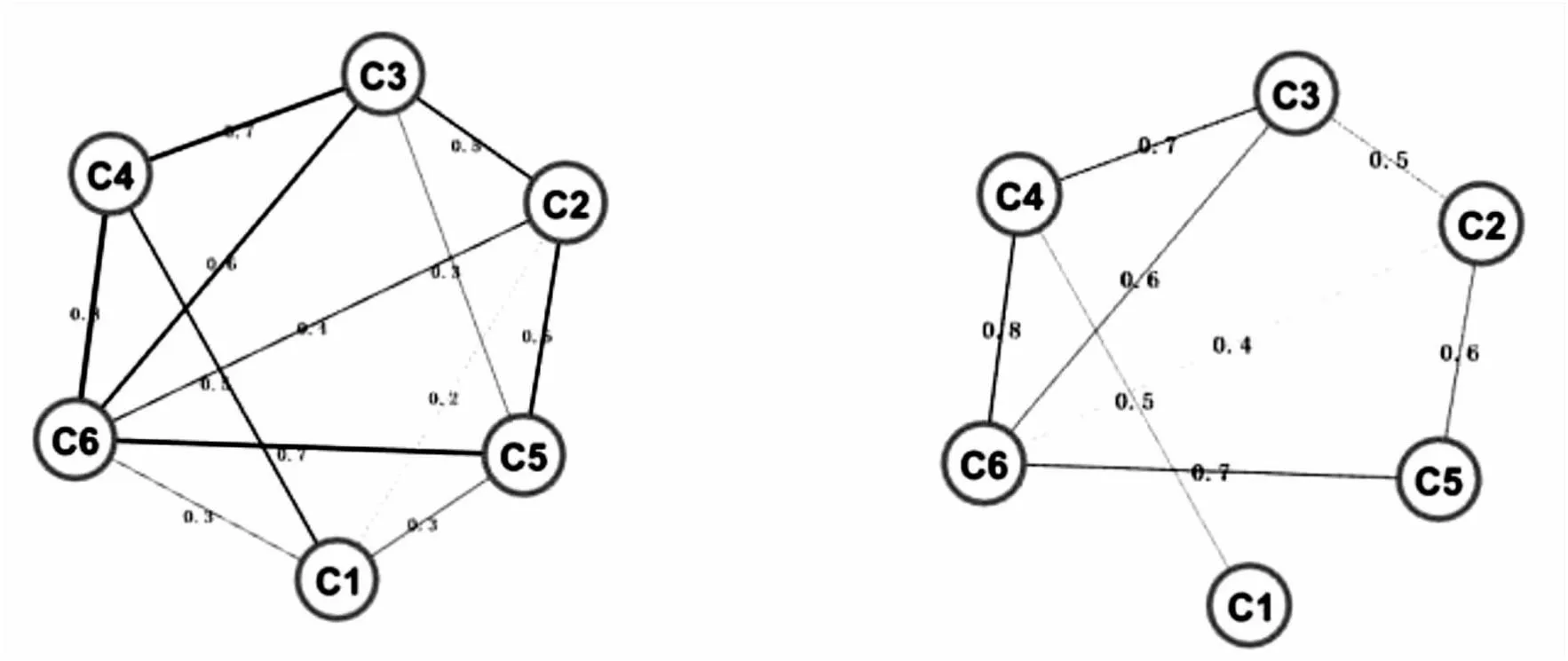
(a) 未设定阈值的加权网络 (b)设定阈值后的加权网络(以阈值=0.4为例)
定义动态专利技术网络G={G1(V1,E1,W1),…,Gt(Vt,Et,Wt),…},其中Gt(Vt,Et,Wt)是t时刻采样的动态专利技术子网络,Vt为t时刻网络Gt的节点集合,Et为t时刻网络Gt的边集合,Wt为t时刻网络Gt的边权重集合。以图3为例,G={G1(V1,E1,W1),G2(V2,E2,W2),G3(V3,E3,W3)},t2时刻网络G2的节点集合为{C1,C2,C3},边集合为{(C2,C3)},权重集合为{W23}。需要说明的是,时刻t可以根据研究需要,将分辨率定为天、月、年等。当然,越小的分辨率,构建的动态专利技术网络所能呈现的技术演化细节越丰富。
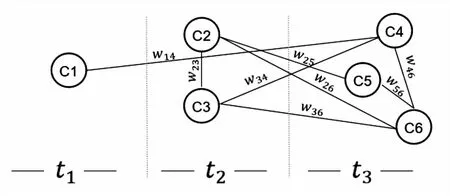
图3 动态专利技术网络示例
2.3 技术集群识别
在动态专利技术网络中,采用带节点增量的Louvain算法检测网络社区,即识别技术集群。带节点增量的Louvain算法思想为:首先,采用Louvain算法对当前时刻采样的网络节点进行社区划分;其次,在下一个时刻统计新增的节点,将新增的节点加入当前时刻网络后,形成新的网络;最后,通过Louvain算法对新的网络社区进行重新划分。
带节点增量的Louvain算法步骤如下:
Step 1:将当前时刻ti时刻网络Gi中每个节点视为一个单独的社区,即节点数与社区数相同。
Step 2:依次将每个节点分配给网络中的社区,计算社区前后的模块度增益ΔQ,并记录ΔQ最大值ΔQmax。如果ΔQmax>0,则将节点i分配给ΔQmax所在的社区;如果ΔQmax≤0,则节点i保持原社区不变。其中,ΔQ定义见式(6)所示。
(6)
其中,∑in是社区C中所有边权重之和,∑tot是连接至社区C的所有权重之和,kj,in表示节点j连接至社区C中节点的权重和,kj表示节点j的权重和,m表示网络中的边总数。
Step 3:重复Step 2,直到网络中社区不再变化。
Step 4:将同一社区中所有节点压缩成为一个新节点,社区内边的权重转化为新节点的点权重,社区间边权重转化为新节点之间边权重。
Step 5:重复Step 1-4,直到整个网络的模块度不再发生变化。此时,记录ti时刻网络Gi中社区划分结果。
Step 6:将ti+1时刻新的节点,加入到ti时刻网络Gi后,形成新的网络Gi+1。
Step 7:重复Step 1-5,记录ti+1时刻网络Gi+1中社区划分结果。
Step 8:重复Step 6-7,直到所有的时刻网络社区均被划分完成,并记录所有时刻网络社区划分结果。
3 实证分析
3.1 数据来源
电商数据技术将成为国家战略发展和企业技术研发投资的热门领域,本文选择美国电商数据技术作为研究对象,希望给国内企业和技术人员研发工作带来启发和帮助。通过Derwent Innovation专利数据库采集美国电商数据技术专利,检索表达式为“CTB=(electronic ADJ commerce) OR CTB=(e-commerce) OR CTB=(network ADJ marketing) OR CTB=(shopping ADJ online) OR CTB=(electronic ADJ transaction) OR CTB=(electronic ADJ payment) AND AIC=(G06)”,将申请国确定为美国(US),进一步筛选摘要中含关键词“data”的专利。采集完成后两位电商领域专家对数据集进行人工判别删除非电商数据技术专利,并对数据进行去重、缺失值处理等预处理,最终进入分析范围的美国电商数据技术专利为1 450条,专利申请日期时间跨度为首个专利申请时间至2021年12月31日。
3.2 计算专利技术相似度
选择专利中的摘要作为文本对象[23-24],通过word2vec生成通用词向量,融合自注意机制更新后学习出特定词向量,进一步融合专利技术中属性和功能技术因子等先验信息,生成专利技术向量,通过余弦相似度计算专利技术相似度。为了获得可靠的动态专利技术网络,需要分析超参数值变动对所构建动态专利网络的指标影响程度,因此采用敏感性分析优化超参数值。其中,根据相关文献研究[15,25],加权网络聚类系数能够反映同类聚集程度,可用于测度网络群聚性。本文选择网络聚类系数作为动态专利网络构建效果的评价指标,开展相关超参数敏感性分析。
如图4所示,根据不同超参数值下加权网络聚类系数的变化,采用肘点法[26],设定通用词向量维度为50,特定词向量维度为30,word2vec模型中滑动窗口数为5。根据设定的超参数值计算专利技术相似度值,结果见表1。

表1 专利技术相似度值
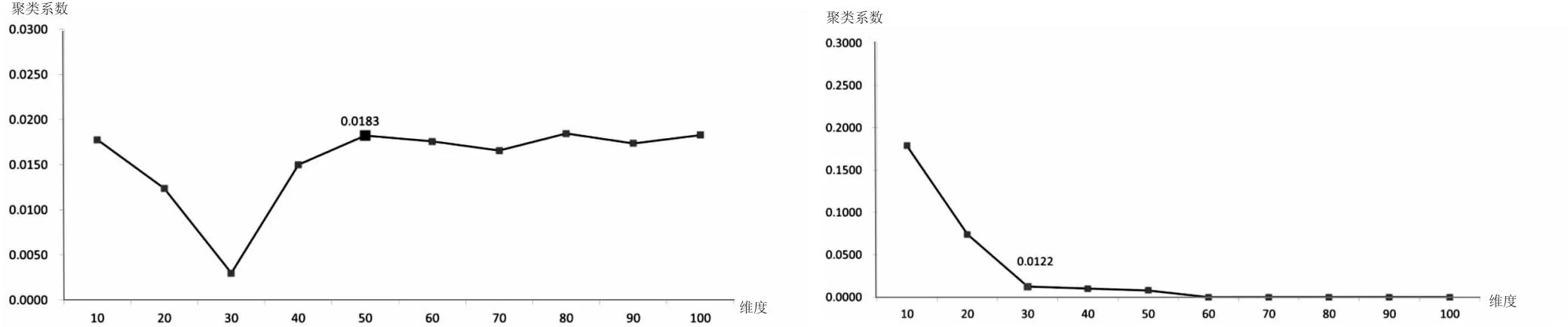
(a)通用词向量维度 (b)特定词向量维度
3.3 构建动态专利技术网络
按照研究方法中动态专利技术网络的定义,以专利为节点,以技术相似度值为权重,以年为单位,在Gephi中绘制美国电商数据动态专利技术网络,如图5所示。需要说明的是,设定阈值为0.5对低权重边进行删除,确保有连接的专利对具有较好的技术相似度。图5中,美国电商数据动态专利技术网络共有802个专利节点,631条边,网络聚类系数为0.0192。在Gephi中启动时间线可对图5进行时间演化演示和指标数值分析。
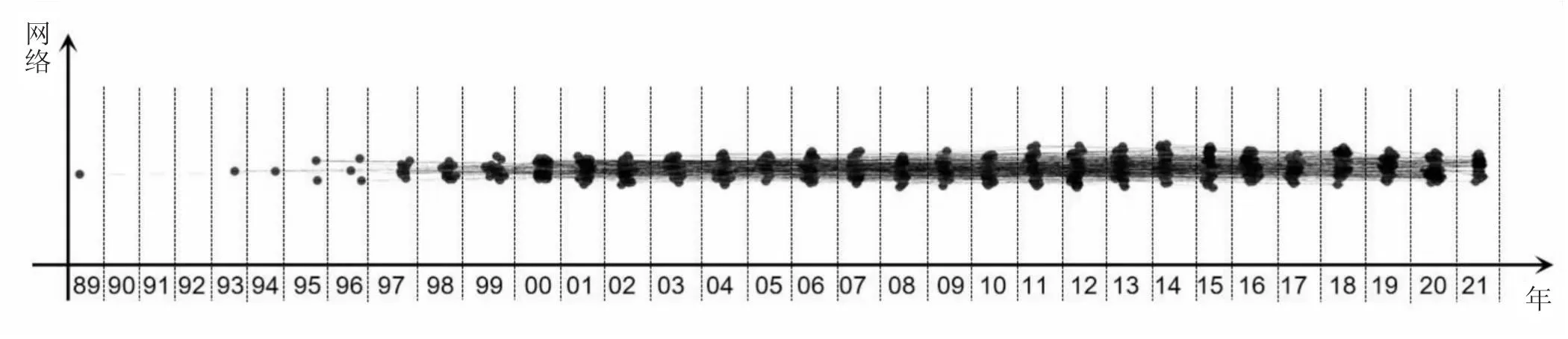
图5 美国电商数据动态专利技术网络
3.4 识别专利技术集群
采用研究方法中带节点增量的Louvain算法检测美国电商数据动态专利技术网络中的社区结构,共检测到12个社区,即发现12个技术集群,同时结合专利技术节点的属性和功能技术因子特征为技术集群主题画像,结果如表2所示。

表2 美国电商数据动态专利技术网络社区结构与技术集群
结合表2和图5所示,自1989年开始的33年发展中,美国电商数据技术共形成了12个技术集群cluster 01-12,技术集群中聚集的专利技术节点数已达273个,占网络专利节点数之比为34%,占技术域专利数之比为18.8%,表明目前美国电商数据技术中已经存在一定比例且属性功能上高度相似的技术聚集,这一技术聚集而成的12个技术集群将会促进美国电商数据技术群体间的连锁和协同效应,进而带来更多的技术研发和投资决策价值。
在Gephi中,对图5启动时间线分析技术集群的演化事件[10,25]。由图5可得,所有的技术集群中专利技术节点数随着时间发展呈增加趋势,根据文献[3,25,27]的研究表明12个技术集群均都处于生长期,且2/3技术集群生长期超过20年。同时,技术集群cluster 03在演化中出现技术集群融合事件,即两个技术集群交叉融合后形成一个新的技术集群。该技术集群融合事件发生在2020年度,其中一个技术集群分支03-1发展时间跨度为[2001,2019],2019年专利技术节点数为22个,另一个技术集群分支03-2发展时间跨度为[2009,2019],2019年专利技术节点数为13个,两个技术集群分支03-1和03-2在2020年度汇聚后融合形成技术集群03。在美国电商数据技术集群中发现了一个技术集群融合事件,是本文通过动态专利技术网络分析技术集群的一大特点。在文献[10,25,27]中 ,相关研究表明技术集群发展是一个动态过程,包括萌芽、生长、成熟和衰退等不同生命周期阶段。在美国电商数据技术集群中,未发现有技术集群处于衰退期,所有的技术集群历经萌芽期后,目前均处于生长期,尚未达到成熟期,表明美国电商数据技术发展呈现新兴活跃态势。
在表2中,为技术集群主题画像是本文研究过程中融合属性和功能技术因子特征的另一个重要运用。在美国电商数据技术中,12个技术集群主题体现了以下特点:a.具有技术研究领域的完备性。从技术主题分布看,美国电商数据技术集群涵盖了电商数据技术全领域链,其中既有数据识别、数据采集、数据存储、数据分析和数据应用等前后衔接技术链,又有数据系统、数据设备、数据安全和数据效用等上下联动技术链。b.形成齐头并进、相辅相成的发展格局。从发展时间分布看,12个技术集群萌芽期均处于21世纪初,此时正值大数据技术和行业高速发展的时期,美国电商数据技术也随之蓬勃发展。同时,从图5观察发现技术集群之间也存在一定稀疏的连接关系,说明12个技术集群并非孤立发展,也有互动促进。c.体现核心引领、辅助支持的发展方式。从节点规模分布看,技术集群cluster 06为数据系统技术研发,技术集群cluster 03为数据设备技术,其中cluster 03由电子设备与云设备两个集群分支聚融合而成。技术集群cluster 03和06中专利技术节点数合计114个,占技术集群节点数之比达41.7%,且均从2001年开始萌芽发展,由此可见数据系统和设备技术研发是近30年来美国电商数据技术发展的核心。当然,数据存储、数据安全等其他10个技术集群所含专利技术节点数虽然远远少于数据系统和设备技术集群,但因其研究领域广泛、技术发展迅速和市场潜力巨大等,对近30年来美国电商数据技术发展也起到了辅助支撑的作用。
4 结 论
本文通过构建动态专利技术网络,采用社区检测的方法识别技术集群。以美国电商数据技术为例,进一步验证了本方法的有效性:a.本研究方法能够有效的识别技术集群。在美国电商数据技术中共发现节点规模不等、技术主题不一的12个技术集群。b.本研究方法能够动态的发现集群变化。总体上美国电商数据技术发展处于新兴活跃态势,技术集群03数据设备技术由两个技术集群分支03-1电子设备和03-2云设备融合而成。c.本研究方法能够为技术集群主题画像。美国电商数据技术集群包括数据系统技术、数据设备技术、数据安全技术等技术主题。
本研究的主要贡献在于:a.通过word2vec生成通用词向量后,融合自注意机制更新通用词向量,学习出的特定词向量能够含有特定专利的语义。b.在学习出的特定词向量基础上,融合专利技术中属性和功能技术因子等先验信息,生成的专利技术向量含有更丰富的专利语义,据此计算出的专利技术相似度更加贴切。c.构建的动态专利技术网络能够发现更多的技术集群特点,比如技术集群生命周期变化和融合发展情况等。
当然,本文还存在一些不足之处,比如文中动态专利技术网络构建以年为单位,可以探索月、天等不同时间分辨率下的构建效果,以及验证技术集群识别是否存在变化等。为此,希望本文能够抛砖引玉,吸引更多研究者关注动态专利技术网络构建和技术集群识别研究。
猜你喜欢
水运工程(2022年7期)2022-07-29
汽车工程师(2021年12期)2022-01-18
冶金设备(2019年6期)2019-12-25
军事运筹与系统工程(2019年4期)2019-09-11
传感器世界(2019年4期)2019-06-26
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
河南科技(2014年16期)2014-02-27
焊管(2013年11期)2013-04-09
